Vertex Pipelines + KFPのArtifact(不)完全ガイド
はじめに
Google CloudのフルマネージドなMLパイプラインのサービスであるVertex Pipelinesが一般提供開始になりました(Vertex Pipelines一般提供のお知らせより)。
これにより、Googleから事前定義されたコンポーネントが公開されたり公式サンプルが公開されたりと、参照可能なコードが増えてきています。
また、非公式ではありますが日本語の解説記事(Vertex Pipelines で動く Kubeflow Pipelines のサンプルを公開しました)も公開されており、Vetex Pipelines+KFPを初めて見る分には敷居がとても低くなったように思います。
しかし、解説記事の今後の課題にもあるように、入出力に関するArtifactについての記載が少ないなと感じています。
@compnentのようなデコレータを利用する場合には以下のように関数の引数として宣言するだけなので意識する必要はないのですが、.yamlファイルを書きながらフルスクラッチで作っていく場合についてのドキュメントが見当たらず、使い方を理解するまでに時間を要しました。
この記事では、フルスクラッチなコンポーネントを作るときのArtifactの利用方法について解説をしてみたいと思います。
Artifactとは
Artifactについて話を進める前に、一度KFPのコンポーネントの入出力について整理をしてみます。
KFPの入力についてはドキュメントに記載されていますが、大別して2種類に分けられます。
-
Parameter:IntやFloat、Stringなどの値を直接渡すもの. 利用できる型の種類はpipeline_specのPrimitiveTypeで定義されておりINT,DOUBLE,STRINGの3種類 -
Artifact: Parameterだけでは表現できないようなより多くの情報を含める入出力。識別子や、値を保存するパス、メタデータを保持できるオブジェクト。
つまり、Artifactは数字や文字列だけでは表現するのが難しい時に利用するオブジェクトになります。
モデルやデータセットについて考えてみましょう。この2つは多くの場合通常の値よりも大きくなりがちでコンポーネント間でデータをそのまま転送するのは難しく、ユニークな名前をつけて一度外部ストレージに永続化してそのパスの情報を受け渡した方が実行効率が良いです。
さて、Kubeflow Pipelineで利用できる入出力についてどんなものがあるのでしょうか?
kfp==1.8.9時点で利用できる標準の入出力は以下のものになります
| type name | kind | PrimitiveType | description |
|---|---|---|---|
integer |
parameter | INT | 整数値を利用したいときに指定するtype |
int |
parmeter | INT |
integerのエイリアス |
double |
parameter | DOUBLE | 浮動小数点数を利用したい時に指定するtype |
float |
parameter | DOUBLE |
doubleのエイリアス。 |
string |
parameter | STRING | 文字列を利用したい時に指定するtype |
str |
parameter | STRING |
stringのエイリアス |
text |
parameter | STRING |
stringのエイリアス |
boolean |
parameter | STRING | ブール値を利用したい時に指定するtype。値の実態はStringなので, 利用の際は注意 |
bool |
parameter | STRING |
booleanのエイリアス。 |
dict |
parameter | STRING | 辞書として値を利用したいときに指定するtype。値の実態はJSONにパース可能な文字列 |
list |
parameter | STRING | リスト(配列)として値を利用したい時に指定するtype。値の実態はリストとしてパース可能な文字列 |
jsonobject |
parameter | STRING | dictのエイリアス |
jsonarray |
parameter | STRING | listのエイリアス |
model |
artifact | 保存したモデルに関する情報を保持するオブジェクト | |
dataset |
artifact | 保存したデータセットに関する情報を保持するオブジェクト | |
meterics |
artifact | Accuracyなどのモデルに関する評価値を保持するためのオブジェクト。key-valueとして値を保持できる | |
classificationmetrics |
artifact | クラス分類についての評価値についての情報を保持するためのオブジェクト。 | |
slicedclassificationmetrics |
artifact | ある特徴量単位で集計したクラス分類の評価値についてのオブジェクト。[1] | |
html |
artifact | HTMLとして保存したいデータを保持するオブジェクト | |
markdown |
artifact | Markdownとして保存したいデータを保持するオブジェクト |
また、Googleが用意しているカスタムなArtifactもあり、2021年11月末日では以下のものになります
- VertexModel
- VertexEndpoint
- VertexBachPredictionJob
- VertexDataset
- BQMLModel
- BQTable
表のnameにあたるものをcomponent.yamlのinputs/outputsのtypeとして宣言してあげれば、Artifactとして宣言することが可能になります
KFPによるArtifactの実装
Artifactを利用するための実装がKFPには用意されています。kfp.v2.components.types.artifact_typesの中に利用できるArtifactがあり、上記の表の実装が入っています。
基本的にkfp==1.8.9でArtifactを利用する際に意識をする必要があるのは、Artifactクラスのインスタンス変数だけです。
以下に各変数の役割とVertex Pipelinesでの実行時における役割を記載します
| 変数名 | 役割 | Vertex Pipelinesにおける役割 |
|---|---|---|
| name | Artifactの識別子 | Vertex Metadataに保存されるArtifactの識別子 |
| uri | アーティファクトの実態を保存するためのパス | 自動生成されるGCSのパスでここに保存したいデータの実態が置かれることを想定している |
| metadata | 任意のkey-value情報を保存するためのもの | 保存されているmetadataからUI上にレンダリングして可視化するためのもの |
Artifactを利用する流れ
さて、 Artifactについてなんとなく理解したところで、light weight component(@component)と比較してみます。
light weightなコンポーネントでは、関数を専用のデコレータでラップすることで作成します。
入出力については関数の引数として受け取るので、引数にArtifactのクラスをtype hintとして宣言してあげれば利用することが可能です。
例えば、データセットを入力として受け取り、訓練したモデルを出力として渡すコンポーネントについて考えてみます。
コード例
from kfp.v2.dsl import Input, Output, Dataset, Model, component
@component
def sample(dataset: Input[Dataset], model: Output[Model]):
import pandas as pd
import joblib
from sklearn.linear import LinearRegression
dataset = pd.read_csv(dataset.path)
linear_regression = LinearRegression()
light weightなコンポーネントの場合には、componentとしてkfpがコンパイルして実行する際に諸々の準備をしてくれるので、特段意識する必要がなく使うことができます。
一方で、yamlファイルを作りコンテナを準備して実行するコンポーネントの場合には、kfpが準備してくれていること全てを実装時に準備する必要があります。
メインとなる処理の他に必要なものは下記の4つになります。
- 実行時メタデータ(executor_input)を読み込む
- executor_inputからArtifactを作成する
- Artifactのメタデータを更新する
- 更新したメタデータをパイプラインが検知できるようにファイルに書き込む
手順を一つずつ順番に見ていきます。
実行時メタデータ(executor_input)を読み込む
Vertex PipelinesでArtifactをコンポーネントの中で利用する際には、name、uri、metadataが必要になります。nameやuriをどのように取得したらよいでしょうか?
一度、ここでcomponent.yamlについて見ましょう。先ほどの例と同様にデータセットを入力として受け取り、訓練したモデルを出力として渡すコンポーネントについて考えてみます。
component.yaml
name: sample-training
inputs:
- {name: dataset, type: Dataset}
outputs:
- {name: model, type: Model}
implementation:
container:
image: gcr.io/deeplearning-platform-release/base-cpu
command:
- python
- main.py
args:
- {outputPath: dataset}
- {outputPath: model}
component.yamlではinputsとoutputにコンポーネントの入出力を定義して、その定義に渡したい値をimplementation.container.args にplaceholderとして記載する必要がありました。
ここでは、inputsにArtifactのDatasetをoutputsにArtifactのModelが宣言されていてoutputPathがコンポーネントに渡されるplaceholderとして宣言されているので、Artifactの値としてパスを渡していることがわかると思います。
ArtifactをVertex Pipelinesで利用する際にはnameとuriとmetadataが必要になります。
outputPathをプレースホルダーとして指定した場合にはuriに当たるものを取得することは可能ですが、他の2つは取得が不可能になります。
Artifactに必要な情報を全て取得できるPlaceholderにExecutorInputPlaceholderがあります。ExecutorInputPlaceholderで渡ってくるデータはpipeline_spec.ExecutorInputで定義されていますが、この定義から実際にどのような値が入ってくるかは少し分かりにくいと思います。
実際にkfp==1.8.9で設定できるParameterやArtifactを設定したcomponent.yamlを記載して確認すると以下のような値が取れます。
component.yaml
name: component
inputs:
- name: input_int
type: int
- name: input_double
type: double
- name: input_string
type: string
- name: input_bool
type: bool
- name: input_dict
type: dict
- name: input_list
type: list
- name: input_model
type: Model
- name: input_dataset
type: Dataset
- name: input_metrics
type: Metrics
- name: input_classification_metrics
type: ClassificationMetrics
- name: input_sliced_classification_metrics
type: SlicedClassificationMetrics
- name: input_html
type: HTML
- name: input_markdown
type: Markdown
outputs:
- name: output_int
type: int
- name: output_double
type: double
- name: output_string
type: string
- name: output_bool
type: bool
- name: output_dict
type: dict
- name: output_list
type: list
- name: output_model
type: model
- name: output_dataset
type: dataset
- name: output_metrics
type: metrics
- name: output_classification_metrics
type: classificationmetrics
- name: output_sliced_classification_metrics
type: slicedclassificationmetrics
- name: html
type: html
- name: markdown
type: markdown
implementation:
container:
image: sample-python
command: [python, /usr/src/main.py]
args:
- {executorInput: null}
上記のようなコンポーネントを指定した際には、executorInputには次のようなJSON形式の文字列が渡されます。
executor_input.json
{
"inputs": {
"artifacts": {
"input_classification_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.ClassificationMetrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/classification_metrics"
}
]
},
"input_dataset": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Dataset"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/dataset"
}
]
},
"input_html": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.HTML"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/html.html"
}
]
},
"input_markdown": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Markdown"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/markdown.md"
}
]
},
"input_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Metrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/metrics"
}
]
},
"input_model": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Model"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/model"
}
]
},
"input_sliced_classification_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.SlicedClassificationMetrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/dummy-op_{task_id}/sliced_classification_metrics"
}
]
}
},
"parameterValues": {
"input_bool": "1",
"input_dict": "{\"sample\": \"value\"}",
"input_double": 1,
"input_int": "1",
"input_list": "[1, 2, 3]",
"input_string": "test_string"
},
"parameters": {
"input_bool": {
"stringValue": "1"
},
"input_dict": {
"stringValue": "{\"sample\": \"value\"}"
},
"input_double": {
"doubleValue": 1
},
"input_int": {
"intValue": "1"
},
"input_list": {
"stringValue": "[1, 2, 3]"
},
"input_string": {
"stringValue": "test_string"
}
}
},
"outputs": {
"artifacts": {
"html": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.HTML"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/html.html"
}
]
},
"markdown": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Markdown"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/markdown.md"
}
]
},
"output_classification_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.ClassificationMetrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/output_classification_metrics"
}
]
},
"output_dataset": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Dataset"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/output_dataset"
}
]
},
"output_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Metrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/output_metrics"
}
]
},
"output_model": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.Model"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/output_model"
}
]
},
"output_sliced_classification_metrics": {
"artifacts": [
{
"metadata": {},
"name": "projects/{project_id}/locations/us-central1/metadataStores/default/artifacts/{一意に識別可能な乱数}",
"type": {
"schemaTitle": "system.SlicedClassificationMetrics"
},
"uri": "gs://temp_trial/{project_id}/{display_name}/component_{task_id}/output_sliced_classification_metrics"
}
]
}
},
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/executor_output.json",
"parameters": {
"output_bool": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_bool"
},
"output_dict": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_dict"
},
"output_double": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_double"
},
"output_int": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_int"
},
"output_list": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_list"
},
"output_string": {
"outputFile": "/gcs/temp_trial/{project_id}/{display_name}/component_{task_id}/output_string"
}
}
}
}
inputs/outputsにそれぞれにprimitiveな値はparametersとして、Artifactはartifactsとして必要な値が 詰め込まれた状態で渡されてくるので、これを適切にパースしてArtifactのインスタンスをコード内で作成することで、Artifactが作成できます。
executor_inputからArtifactを作成する
executor_inputを利用することで、Artifact作成に必要な値が取得できることを確認しました。
上記のexecutor_input.jsonを仮定して、outputsのArtifactのDatasetを作成することを考えてみましょう。executor_inputをパースして作成することができるのですが、kfpの中にArtifact作成の便利メソッドがkfpには用意されているので、それを利用した場合について説明をします.
kfp.v2.components.types.artifact_type.create_runtime_artifactは実行時にruntime_artifactを渡すことで、Artifactのインスタンスを作成してくれるものです。runtime_artifactは以下の構造を持つ辞書が想定されています。
{
"name": name_value,
"uri": uri,
"type": {"schemaTitle": Artifact.TYPE_NAME},
"metadata": {"key": "value"}
}
これを利用してArtifactを作成しようとした場合には、次のようなコードで作成が可能です
from kfp.v2.components.types.artifact_type import create_runtime_artifact
from kfp.v2.dsl import Dataset
executor_input = {...} # 上記のexecutor_inputが入ってきていると仮定
runtime_artifact = executor_input['outputs']['artifacts']['dataset']['artifacts'][0]
dataset: Dataset = create_runtime_artifact(runtime_artifact)
Artifactのメタデータを更新する
Artifactを利用するのにはいくつか理由がありますが、大きなメリットとしてメタデータを単体で管理することができることだと思います。例えば、ClassificationMetricsではmetadataに対してconfusion matrixをリストとして書き込むことで可視化をすることができます。
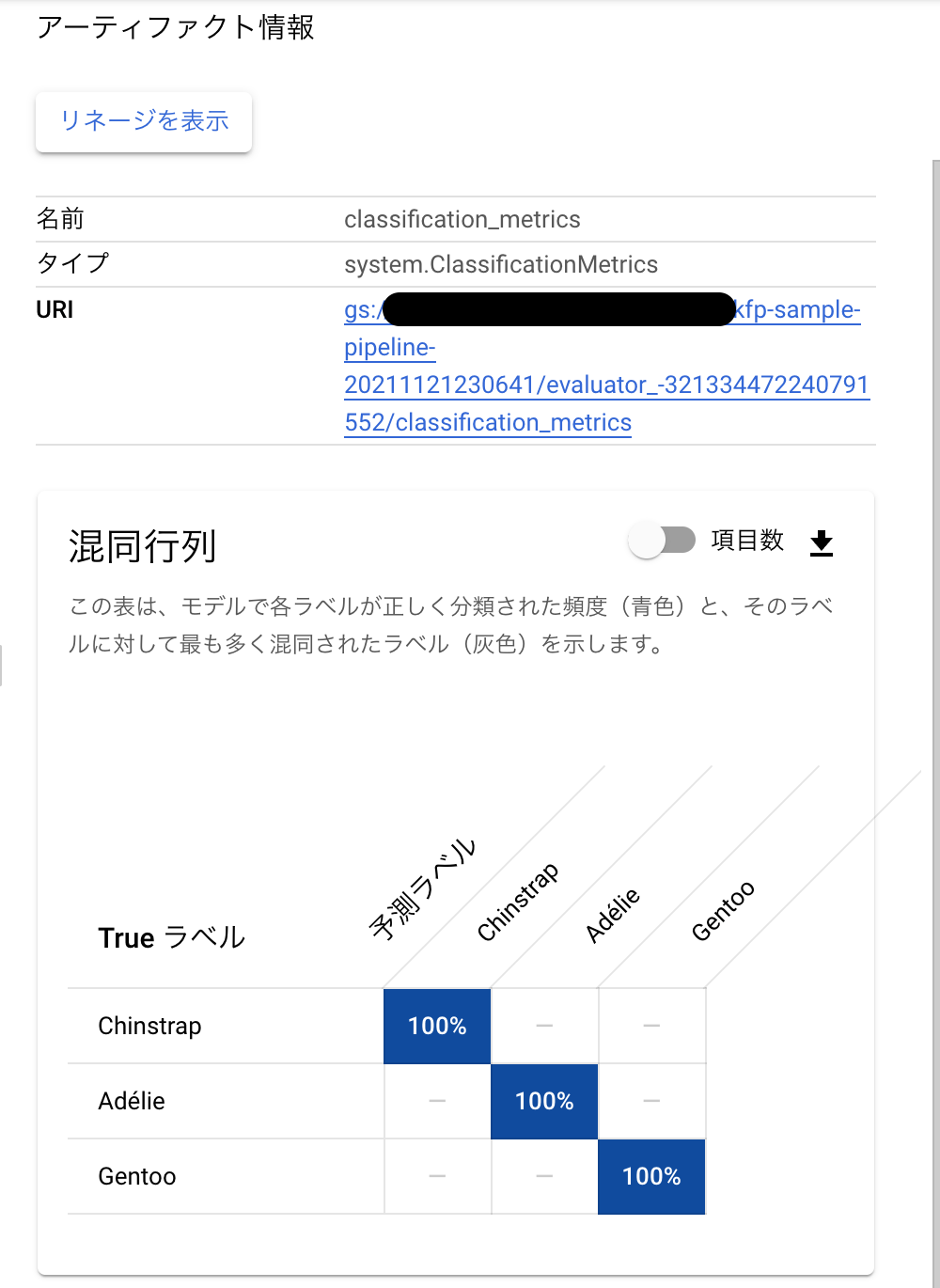
Vertex Pipelinesでは比較機能があり、指標比較のためにMetricsのmetadataにスコアなどを書き込む必要があります(比較のサンプルはGoogleの公式サンプルを参照するのが良いと思います)。
また、任意のメタデータなんかも書き込むことができるので次のようなことをUIにプロパティとして表示させることも可能です。

markdownとして作成されたArtifactはマークダウンファイルをレンダリングしてくれます。
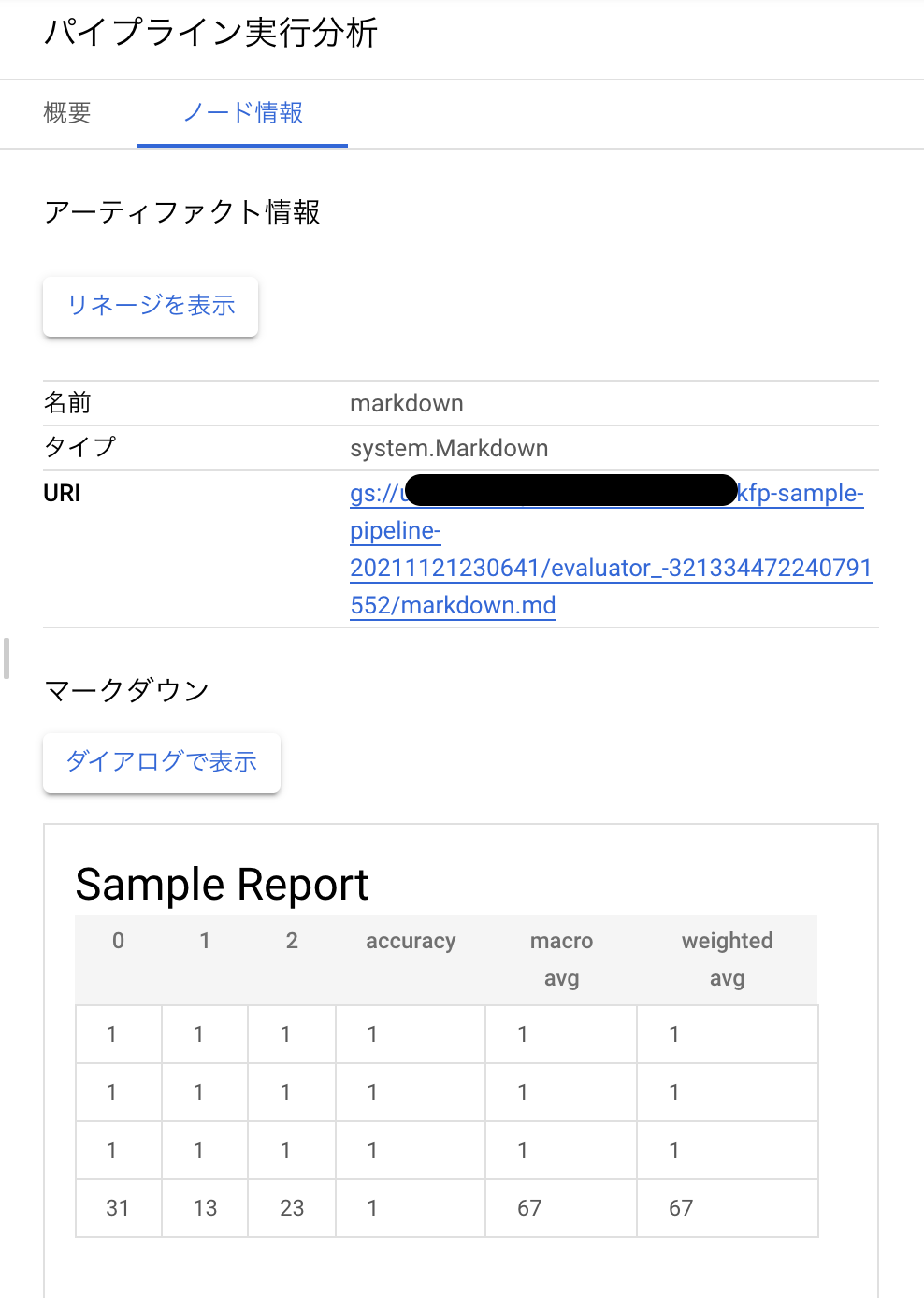
ここでは、executor_inputからArtifactを作成するで例示したデータセットにメタデータを追記する処理をコード例として書いておきます
import json
from kfp.v2.components.types.artifact_type import create_runtime_artifact
from kfp.v2.dsl import Dataset
executor_input = {...} # 上記のexecutor_inputが入ってきていると仮定
runtime_artifact = executor_input['outputs']['artifacts']['dataset']['artifacts'][0]
dataset: Dataset = create_runtime_artifact(runtime_artifact)
# metadataの書き込み
dataset.metadata['problem'] = 'classification'
# UIに表示したい都合で文字列にする。dictやlistは`[Object object]`のように描画されてわからなくなるので注意
schema = json.dumps({'body_mass_g': 'number',
'culmen_depth_mm': 'number',
'culmen_length_mm': 'number',
'flipper_length_mm': 'number',
'species': 'number'})
dataset.metadata['schema'] = schema
更新したメタデータをパイプラインが検知できるようにファイルに書き込む
さて、これまでの手順でArtifactを作成して、UIに描画するためにArtifactのmetadataプロパティを更新できるようになりました。
しかし、Artifactのメタデータの更新はコンポーネントの内部で閉じているためパイプライン側で更新を検知して、アップデートする必要があります。更新検知の仕組みは、executor_inputから渡ってくる指定したファイルパスに対して、Outputで指定した全てのArtifactについてJSONとして保存する必要があります。
例えば、datasetとmodelという2つのArtifactについて、以下のような辞書がJSONとして保存されることが期待されます.
{
"artifacts": {
"dataset": {
"artifacts": [
"name": dataset.name,
"uri": dataset.uri,
"metadta": dataset.metadata,
]
}
"model": {
"artifacts": [
"name": model.name,
"uri": model.uri,
"metadta": model.metadata,
]
}
}
}
構造的には、executor_input.outputs.artifacts以下の構造とほぼ同じです(保存時にはtypeが除外されています)
この JSONのデータを、指定されているパスに書き込むことでパイプライン側への更新は完了となります。
指定されているパスはoutputFileという名前で、executor_input.outputs.outputFileに格納されています。
これまで作ってきたdatasetを例にして、コード例を示します
import json
from kfp.v2.components.types.artifact_type import create_runtime_artifact
from kfp.v2.dsl import Dataset
from pathlib import Path
executor_input = {...} # 上記のexecutor_inputが入ってきていると仮定
runtime_artifact = executor_input['outputs']['artifacts']['dataset']['artifacts'][0]
dataset: Dataset = create_runtime_artifact(runtime_artifact)
# metadataの書き込み
dataset.metadata['problem'] = 'classification'
# UIに表示したい都合で文字列にする。dictやlistは`[Object object]`のように描画されてわからなくなるので注意
schema = json.dumps({'body_mass_g': 'number',
'culmen_depth_mm': 'number',
'culmen_length_mm': 'number',
'flipper_length_mm': 'number',
'species': 'number'})
dataset.metadata['schema'] = schema
# ファイルに書き込むためのjsonを用意する
executor_output = {}
executor_outputs['artifacts'] = {}
executor_outputs['artifacts']['dataset'] = {
'artifacts': [
{
"name": artifact.name,
"uri": artifact.uri,
"metadata": artifact.metadata
}
]
}
# pipelineがmetadataの検知ができるようにoutputFileに書き込む
output_file = Path(executor_input['outputs']['outputFile']
output_file.parent.mkdir(parents=True, exist_ok=True)
with opne(output_file, "w") as f:
json.dump(executor_outputs, f)
これでVertex Pipelines上でArtifactの利用で必要な全ての処理が完了しました。
終わりに
yamlファイルを作って、モジュールを書くようなフルスタックのコンポーネントでArtifactを利用するために必要なことを書いてきました。ドキュメントが見当たらず途方に暮れてましたが、コードを読んでいくことでなんとか使えるようになりました。割としんどくもう一度同じ調査をしたくないので、今回記事にしてみました。
(不)完全ガイドとタイトルにしてるのは、公式な見解ではなくドキュメントがなかったので、コードを読んだり数十回から100回程度のジョブを投げては失敗しての試行錯誤で私が理解したことを記載しているからであり、正しいという保証は一切ないからです。
今回検証するに当たって、日本語の解説記事でkfp v2サンプルとして使えるコードを公開してくれており、解説記事のサンプルコードを利用させていただきました。
試行錯誤は、サンプルとして公開されているコードをArtifact利用のものに置き換えて実験をしており、PRを出してコードを参照可能なようにしようと準備しています。
サンプルコードの公開まで少し時間がかかりますが、コードが見たい方は少しお待ちいただければと思います。
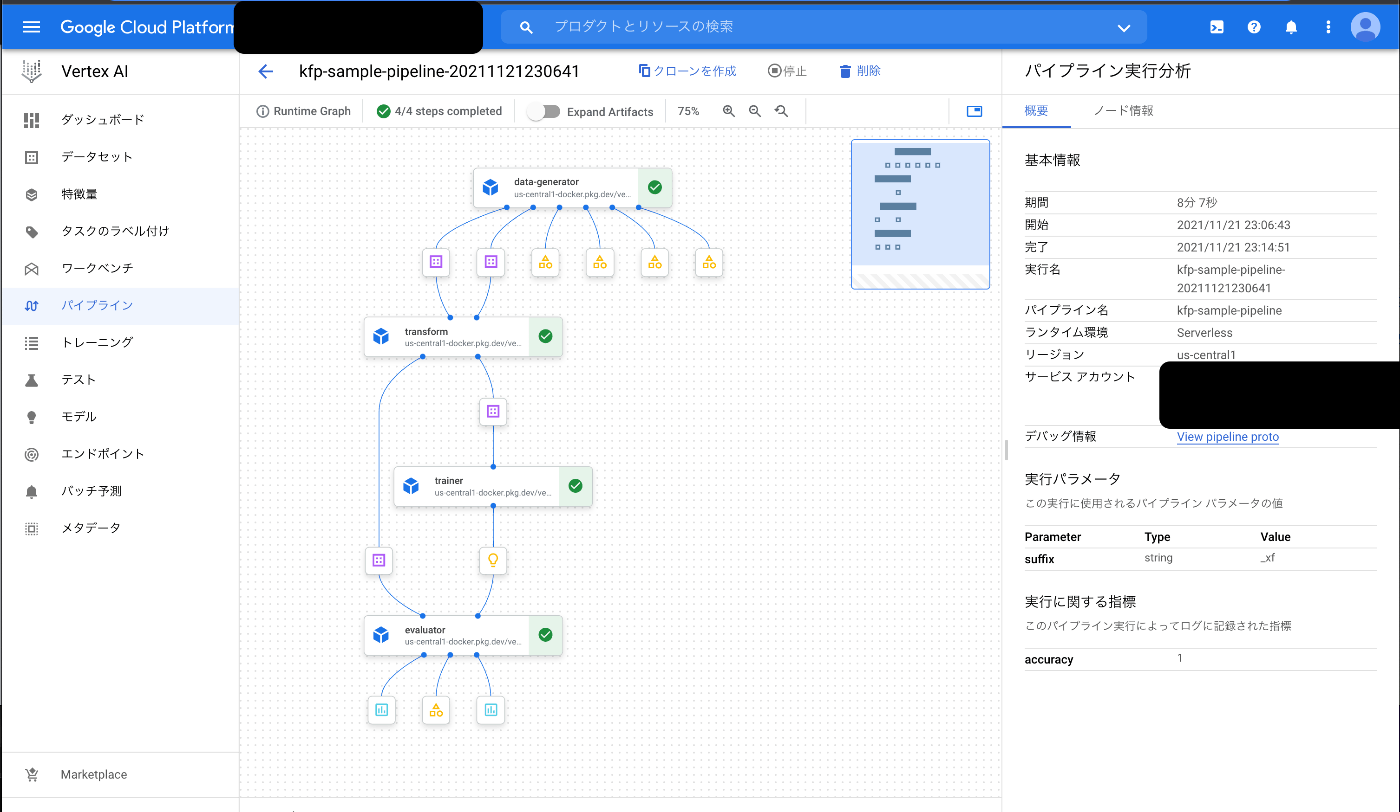
p.s. 実行結果はこんな感じです
脚注
-
sliceの考え方はAutomated Data Slicing for Model Validationを参照すると分かりやすいかも ↩︎
Discussion