Intel GPUを使用してLLMをfine tuningしたい (ipex-llmなど)
ipex-llmを用いることでIntel GPUでLLMを動かしたりfine tuningができると聞いたのでメモをします。
環境は以下の通り
- windows11
- miniforge
- Intel Arc a770
Intel Arc a770は4万中盤~5万円で16GB載ってます。かなり格安。
インストール手順は以下に従いました。
インストール手順はFor USの側、動作チェックはFor loading model from Hugging Faceで実行。
ちょいちょいtrnasformersのバージョン指定でインストールする手順書になっていますが、transformers==4.37.0が必須でした。ドキュメントによって4.36.0が指定されていましたが、4.37.0じゃないとqwen系のモデルは読み込めず、かといって最新版にしてもダメでした。
サンプルコードはbitsandbyteで4bit推論しています。
bnbがCPUでしか動かせないのでモデル変換がまあまあ重いです。
Qwen/Qwen2.5-14B-InstructならDL済みでも3分40秒かかりました。
ここはCPU推論だから仕方がないね。
load_in_8bitのオプションは無いらしい。 実行してもCUDAがないといわれるので本当に対応してなさそう?
シンプルな質問で試しました。
<|im_start|>system
You are a helpful assistant.日本語で回答してください<|im_end|>
<|im_start|>user
日本で最も高い山は何ですか?<|im_end|>
<|im_start|>assistant
日本で最も高い山は富士山です。富士山は標高約3,776メートルで、日本の象徴的な山として知られています。<|im_end|>
======
生成したトークン数: 71
処理にかかった時間: 1.33 秒
throughput(t/s):53.45
<|im_start|>system
You are a helpful assistant.日本語で回答してください<|im_end|>
<|im_start|>user
日本で最も高い山は何ですか?<|im_end|>
<|im_start|>assistant
日本で最も高い山は富士山です。標高は約3,776メートルです。<|im_end|>
======
生成したトークン数: 58
処理にかかった時間: 2.75 秒
throughput(t/s):21.07
思っていたより早く動きますね。
4万中盤で買ったGPUと考えればかなり格安で高性能。
もともとIntel君が同価格帯のRTX4060 8GBより高速と謳って発売されていた、宣言通りの速度ではある。
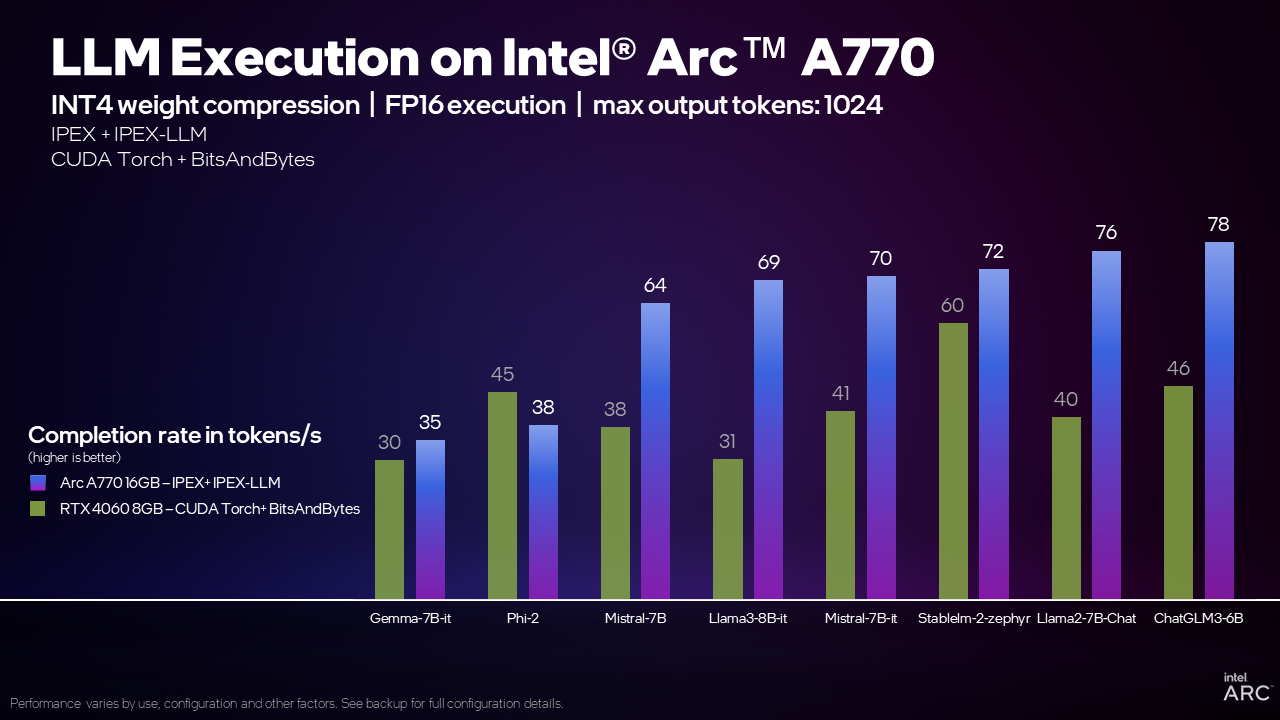
https://game.intel.com/us/stories/wield-the-power-of-llms-on-intel-arc-gpus/#:~:text=In this article%2C we’ll show you how to,with the Intel® Arc™ A770 16GB graphics card.
※ このセクションは動作確認が取れていません
次はllama-3のfine tuningを試したい。
※ このセクションは動作確認が取れていません
インストール関連は最初のところで終わってるものとして、axolotlとdatasetsをインストール。
ただし、git checkout 796a085の前にgitに安全なディレクトリとして登録する必要がありました。
かつ、axolotlのsetup.pyにxformersのインストール部分が残っていたので、31行目からxformersに関する部分をコメントアウト、最初のif分にはpassを追加しました。
try:
if "Darwin" in platform.system():
# _install_requires.pop(_install_requires.index("xformers==0.0.22"))
pass
else:
torch_version = version("torch")
_install_requires.append(f"torch=={torch_version}")
version_match = re.match(r"^(\d+)\.(\d+)(?:\.(\d+))?", torch_version)
if version_match:
major, minor, patch = version_match.groups()
major, minor = int(major), int(minor)
patch = (
int(patch) if patch is not None else 0
) # Default patch to 0 if not present
else:
raise ValueError("Invalid version format")
# if (major, minor) >= (2, 1):
# _install_requires.pop(_install_requires.index("xformers==0.0.22"))
# _install_requires.append("xformers>=0.0.23")
except PackageNotFoundError:
pass
git clone https://github.com/OpenAccess-AI-Collective/axolotl
# gitに安全なディレクトリとして登録
git config --global --add safe.directory E:/ipex/axolotl
cd axolotl && git checkout 796a085
# xformersなどの非対応ライブラリをインストールしないようにするためのrequirements.txt の差し替え
del requirements.txt
curl -L https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt -o requirements.txt
pip install -e .
# to avoid https://github.com/OpenAccess-AI-Collective/axolotl/issues/1544
pip install datasets==2.15.0
# requirementsに記載がありませんが、自環境では以下も必要でした。
pip install fastcore
また、axolotlインストール時に以下のエラーが出ました。
これはインストール時のパスの長さが長すぎることが原因のようです。
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: 'C:\\Users\\himak\\AppData\\Local\\Temp\\pip-install-umqgzv3m\\xformers_c02b591f56c64628a8d57eb3498bee87\\third_party\\flash-attention\\csrc\\composable_kernel\\client_example\\24_grouped_conv_activation\\grouped_convnd_bwd_data_bilinear\\grouped_conv_bwd_data_bilinear_residual_fp16.cpp'
HINT: This error might have occurred since this system does not have Windows Long Path support enabled. You can find information on how to enable this at https://pip.pypa.io/warnings/enable-long-paths
gpedit.mscの[ローカルコンピュータポリシー] → [コンピュータの構成] → [管理用テンプレート] → [システム] → [ファイルシステム]から「Win32 長いパスを有効にする」 を「有効」にしてください。

axolotl用のyamlはwindowsなのでcurlでDLした。
curl -L https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/llama3-qlora.yml -o llama3-qlora.yml
今回はサンプルのままトレーニングするので、DLしたyamlを用いてそのまま実行します。
accelerate launch finetune.py llama3-qlora.yml
※ このセクションは動作確認が取れていません
トレーニング実行前にaccelerateの設定が必要でした。
mkdir "%USERPROFILE%\.cache\huggingface\accelerate"
curl -o "%USERPROFILE%\.cache\huggingface\accelerate\default_config.yaml" https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml
このコマンドはaccelerate configの代替であり、確認したところ、accelerate configの後に以下のディレクトリにdefault_config.yamlが生成されていました。
C:\Users\〇〇〇\.cache\huggingface\accelerate\default_config.yaml
そもそもVisual Studio Build Tools 2019/2022とIntel oneAPI Base Toolkitのインストールが必要でした。
Visual Studio Build Tools 2022
なぜかDNSを変更しないとDLできなかった。俺のPC環境どうなってるんや?
以下にチェックを入れてインストールしました。

完了後の再起動が推奨されているので素直に従って再起動します。
Intel oneAPI Base Toolkit
注意書きは出ましたが、今回はVisual Studio側から触らないので無視します。

実行すると同じく完了後の再起動が推奨されているので、こちらも素直に従って再起動します
QLoRAは正常に動きました。
ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\alpaca-qlora
にあるalpaca_qlora_finetuning.pyを実行すればqloraは実行できます。
python ./alpaca_qlora_finetuning.py --base_model "meta-llama/Meta-Llama-3-8B-Instruct" --data_path "yahma/alpaca-cleaned" --output_dir "./ipex-llm-qlora-alpaca"
コマンドは同フォルダ内にある.shファイルの中にいろいろ書いてあります。
参考にしてみてください。
実行結果
(llm) D:\dev\ipex_test\ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\alpaca-qlora>python ./alpaca_qlora_finetuning.py --base_model "meta-llama/Meta-Llama-3-8B-Instruct" --data_path "yahma/alpaca-cleaned" --output_dir "./ipex-llm-qlora-alpaca"
The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable.
C:\Users\himak\.conda\envs\llm\Lib\site-packages\transformers\deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\torchvision\io\image.py:13: UserWarning: Failed to load image Python extension: 'Could not find module 'C:\Users\himak\.conda\envs\llm\Lib\site-packages\torchvision\image.pyd' (or one of its dependencies). Try using the full path with constructor syntax.'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
2025-04-04 20:16:07,832 - INFO - intel_extension_for_pytorch auto imported
Training Alpaca-LoRA model with params:
base_model: meta-llama/Meta-Llama-3-8B-Instruct
data_path: yahma/alpaca-cleaned
output_dir: ./ipex-llm-qlora-alpaca
batch_size: 128
micro_batch_size: 2
num_epochs: 3
learning_rate: 3e-05
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj', 'k_proj', 'o_proj', 'up_proj', 'down_proj', 'gate_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
training_mode: qlora
C:\Users\himak\.conda\envs\llm\Lib\site-packages\huggingface_hub\file_download.py:896: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
config.json: 100%|████████████████████████████████████████████████████████████████████████████| 654/654 [00:00<?, ?B/s]
model.safetensors.index.json: 100%|███████████████████████████████████████████████| 23.9k/23.9k [00:00<00:00, 3.98MB/s]
model-00001-of-00004.safetensors: 100%|████████████████████████████████████████████| 4.98G/4.98G [00:42<00:00, 116MB/s]
model-00002-of-00004.safetensors: 100%|████████████████████████████████████████████| 5.00G/5.00G [00:43<00:00, 115MB/s]
model-00003-of-00004.safetensors: 100%|████████████████████████████████████████████| 4.92G/4.92G [00:42<00:00, 116MB/s]
model-00004-of-00004.safetensors: 100%|████████████████████████████████████████████| 1.17G/1.17G [00:09<00:00, 117MB/s]
Downloading shards: 100%|████████████████████████████████████████████████████████████████| 4/4 [02:20<00:00, 35.01s/it]
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 3.87it/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 187/187 [00:00<?, ?B/s]
2025-04-04 20:18:32,988 - INFO - Converting the current model to nf4 format......
tokenizer_config.json: 100%|██████████████████████████████████████████████████████| 51.0k/51.0k [00:00<00:00, 3.22MB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████████████████| 9.09M/9.09M [00:01<00:00, 7.82MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████████████████████| 73.0/73.0 [00:00<?, ?B/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Tokenizer loaded on rank 0
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): LowBitLinear(in_features=4096, out_features=4096, bias=False)
(k_proj): LowBitLinear(in_features=4096, out_features=1024, bias=False)
(v_proj): LowBitLinear(in_features=4096, out_features=1024, bias=False)
(o_proj): LowBitLinear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): LowBitLinear(in_features=4096, out_features=14336, bias=False)
(up_proj): LowBitLinear(in_features=4096, out_features=14336, bias=False)
(down_proj): LowBitLinear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
Lora Config: LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type='CAUSAL_LM', inference_mode=False, r=8, target_modules={'v_proj', 'up_proj', 'down_proj', 'o_proj', 'gate_proj', 'k_proj', 'q_proj'}, lora_alpha=16, lora_dropout=0.05, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={}, use_dora=False, layer_replication=None, training_mode='qlora')
Downloading readme: 100%|█████████████████████████████████████████████████████████████████| 11.6k/11.6k [00:00<?, ?B/s]
Downloading data: 100%|███████████████████████████████████████████████████████████| 44.3M/44.3M [00:01<00:00, 39.0MB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.16s/it]
Extracting data files: 100%|█████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 63.37it/s]
Generating train split: 51760 examples [00:00, 59587.09 examples/s]
trainable params: 20,971,520 || all params: 2,925,793,280 || trainable%: 0.7167806469225331
Map: 100%|██████████████████████████████████████████████████████████████| 49760/49760 [00:43<00:00, 1148.44 examples/s]
Map: 100%|████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1162.40 examples/s]
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3
wandb: You chose "Don't visualize my results"
wandb: Tracking run with wandb version 0.19.9
wandb: W&B syncing is set to `offline` in this directory.
wandb: Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
{'loss': 1.9383, 'learning_rate': 2.9999945367033285e-05, 'epoch': 0.0}
{'loss': 1.8817, 'learning_rate': 2.9999781468531096e-05, 'epoch': 0.01}
{'loss': 1.9449, 'learning_rate': 2.9999508305687345e-05, 'epoch': 0.01}
{'loss': 1.8327, 'learning_rate': 2.999912588049185e-05, 'epoch': 0.01}
{'loss': 1.8864, 'learning_rate': 2.9998634195730358e-05, 'epoch': 0.01}
{'loss': 1.7945, 'learning_rate': 2.9998033254984483e-05, 'epoch': 0.02}
{'loss': 1.7724, 'learning_rate': 2.999732306263172e-05, 'epoch': 0.02}
{'loss': 1.6614, 'learning_rate': 2.9996503623845395e-05, 'epoch': 0.02}
{'loss': 1.6509, 'learning_rate': 2.9995574944594622e-05, 'epoch': 0.02}
{'loss': 1.5805, 'learning_rate': 2.9994537031644263e-05, 'epoch': 0.03}
{'loss': 1.5833, 'learning_rate': 2.9993389892554893e-05, 'epoch': 0.03}
{'loss': 1.5486, 'learning_rate': 2.9992133535682725e-05, 'epoch': 0.03}
{'loss': 1.5369, 'learning_rate': 2.9990767970179558e-05, 'epoch': 0.03}
{'loss': 1.4397, 'learning_rate': 2.998929320599271e-05, 'epoch': 0.04}
{'loss': 1.3858, 'learning_rate': 2.998770925386495e-05, 'epoch': 0.04}
1%|▉ | 15/1164 [24:30<30:47:36, 96.48s/it]
trlを用いたQLoRAも実行できた。
ただし、モデル保存時にPermission deniedが出まくります。
checkpoint保存時のコードがWindowsと相性が悪そう?
事前にSFTTrainerのsave_stepsとmax_stepsとかから全ファイル生成しておけば無視はできそう。
小手先すぎるけど以下のようにして事前にフォルダを作っといたらよさそう。
i_max_steps=200
i_save_steps=100
for i_folder in range(i_max_steps//i_save_steps+1):
os.makedirs(os.path.join(dir_save, "checkpoint-{}".format((i_folder+1)*100)))
※ 以下は検証中
python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/qlora_finetuning.py内のSFTTrainerのoutput_dirに明示的にraw文字列の絶対パスを入力しておかないとPermission deniedで途中のcheckpointが保存されませんでした、
(llm) D:\dev\ipex_test\ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\trl-example>python ./qlora_finetuning.py --repo-id-or-model-path "meta-llama/Meta-Llama-3-8B-Instruct"
The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable.
C:\Users\himak\.conda\envs\llm\Lib\site-packages\transformers\deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\torchvision\io\image.py:13: UserWarning: Failed to load image Python extension: 'Could not find module 'C:\Users\himak\.conda\envs\llm\Lib\site-packages\torchvision\image.pyd' (or one of its dependencies). Try using the full path with constructor syntax.'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
2025-04-05 04:04:55,040 - INFO - intel_extension_for_pytorch auto imported
C:\Users\himak\.conda\envs\llm\Lib\site-packages\huggingface_hub\file_download.py:896: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Map: 100%|█████████████████████████████████████████████████████████████████████████████████| 5176/5176 [00:04<00:00, 1224.35 examples/s]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 2.65it/s]
2025-04-05 04:05:18,650 - INFO - Converting the current model to nf4 format......
C:\Users\himak\.conda\envs\llm\Lib\site-packages\huggingface_hub\utils\_deprecation.py:100: FutureWarning: Deprecated argument(s) used in '__init__': dataset_text_field. Will not be supported from version '1.0.0'.
Deprecated positional argument(s) used in SFTTrainer, please use the SFTConfig to set these arguments instead.
warnings.warn(message, FutureWarning)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
C:\Users\himak\.conda\envs\llm\Lib\site-packages\trl\trainer\sft_trainer.py:289: UserWarning: You didn't pass a `max_seq_length` argument to the SFTTrainer, this will default to 1024
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\trl\trainer\sft_trainer.py:318: UserWarning: You passed a `dataset_text_field` argument to the SFTTrainer, the value you passed will override the one in the `SFTConfig`.
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\transformers\optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3
wandb: You chose "Don't visualize my results"
wandb: Tracking run with wandb version 0.19.9
wandb: W&B syncing is set to `offline` in this directory.
wandb: Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
0%| | 0/200 [00:00<?, ?it/s]C:\Users\himak\.conda\envs\llm\Lib\site-packages\torch\utils\checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.8609, 'learning_rate': 2e-05, 'epoch': 0.02}
{'loss': 1.7522, 'learning_rate': 1.7777777777777777e-05, 'epoch': 0.03}
{'loss': 1.5453, 'learning_rate': 1.555555555555556e-05, 'epoch': 0.05}
{'loss': 1.4665, 'learning_rate': 1.3333333333333333e-05, 'epoch': 0.06}
{'loss': 1.3515, 'learning_rate': 1.1111111111111113e-05, 'epoch': 0.08}
50%|████████████████████████████████████████████████▌ | 100/200 [05:08<05:20, 3.20s/it]Checkpoint destination directory D:\dev\ipex_test\ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\trl-example\outputs\checkpoint-100 already exists and is non-empty.Saving will proceed but saved results may be invalid.
C:\Users\himak\.conda\envs\llm\Lib\site-packages\peft\utils\other.py:581: UserWarning: Unable to fetch remote file due to the following error (ReadTimeoutError("HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)"), '(Request ID: 8890cc0a-d587-406b-819a-2856f9451123)') - silently ignoring the lookup for the file config.json in meta-llama/Meta-Llama-3-8B-Instruct.
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\peft\utils\save_and_load.py:154: UserWarning: Could not find a config file in meta-llama/Meta-Llama-3-8B-Instruct - will assume that the vocabulary was not modified.
warnings.warn(
C:\Users\himak\.conda\envs\llm\Lib\site-packages\torch\utils\checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.3035, 'learning_rate': 8.888888888888888e-06, 'epoch': 0.09}
{'loss': 1.2035, 'learning_rate': 6.666666666666667e-06, 'epoch': 0.11}
{'loss': 1.2249, 'learning_rate': 4.444444444444444e-06, 'epoch': 0.12}
{'loss': 1.1416, 'learning_rate': 2.222222222222222e-06, 'epoch': 0.14}
{'loss': 1.13, 'learning_rate': 0.0, 'epoch': 0.15}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [10:29<00:00, 3.17s/it]Checkpoint destination directory D:\dev\ipex_test\ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\trl-example\outputs\checkpoint-200 already exists and is non-empty.Saving will proceed but saved results may be invalid.
C:\Users\himak\.conda\envs\llm\Lib\site-packages\huggingface_hub\file_download.py:896: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
{'train_runtime': 800.7099, 'train_samples_per_second': 0.999, 'train_steps_per_second': 0.25, 'train_loss': 1.3979985904693604, 'epoch': 0.15}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [10:30<00:00, 3.15s/it]
TrainOutput(global_step=200, training_loss=1.3979985904693604, metrics={'train_runtime': 800.7099, 'train_samples_per_second': 0.999, 'train_steps_per_second': 0.25, 'train_loss': 1.3979985904693604, 'epoch': 0.15})
wandb:
wandb: You can sync this run to the cloud by running:
wandb: wandb sync D:\dev\ipex_test\ipex-llm\python\llm\example\GPU\LLM-Finetuning\QLoRA\trl-example\wandb\offline-run-20250405_040904-6nw4pxw8
wandb: Find logs at: wandb\offline-run-20250405_040904-6nw4pxw8\logs
要確認だけど、以下が主な問題点。windowsだとshutil.move(staging_output_dir, output_dir)に置き換えてあげたほうがよかったはず?
File c:\Users\himak\.conda\envs\llm\Lib\site-packages\transformers\trainer.py:2421, in Trainer._save_checkpoint(self, model, trial, metrics)
2418 os.rename(staging_output_dir, output_dir)
2420 # Ensure rename completed in cases where os.rename is not atomic
-> 2421 fd = os.open(output_dir, os.O_RDONLY)
2422 os.fsync(fd)
2423 os.close(fd)
sarashina2.2-3Bはhead_dimが160のため、ipex-llmでは対応していなかった。
ipex-llmではhead_dimが2のべき乗である必要があるようだ。
手動でconfing.jsonのhead_dim, num_attention_heads, num_key_value_headsを以下のように変更すれば読み込むこと自体はできる。
"head_dim": 256,
"num_attention_heads": 10,
"num_key_value_heads": 5,
ただし、padトークンが登録されていないため推論が実行できないので、以下を推論時に追記する必要があった。
generation_config.pad_token_id = 3
もちろん出力は壊れます。
<|system|> You are a helpful assistant.日本語で回答してください</s><|user|> 日本で最も高い山は何ですか?</s><|assistant|>、、 一定、 ユー、 ユー準準準準準準準準準準準準準準準準準準準準準準準準準準準準準準質問の準 httpieder " r r Tab{ Tab{ Tab{ 1 1{{{{{{{{{{{{ McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa McCa (以下略)
head_dimはattention時にいくつに分割するのかを決める値。
sarashinaもGQAを採用しているllamaアーキテクチャなので、attentionではQKVの重みをかけた後、Qはnum_attention_headsで、KVはnum_key_value_headsの数に分割される。
つまり、もともとは隠れ層の次元数hidden_size(2560) = head_dim(160) x num_attention_heads(16)になっていた。
その分割数を無理やり変えているので推論は正常にできなくなります。
あとから"q_proj", "k_proj", "v_proj"だけ学習させる土台にするならギリギリアリかも?
256次元に変更したら、python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/qlora_finetuning.pyでのトレーニング自体は完走した。
※ 未確認
上記TRLを用いて学習させたLoRAはPEFTのマージ用の関数を用いたら、結合した状態で保存できそう?
PEFTのドキュメントにも書いてあるけど、通常は
x: input
h: output
W: 重み(dxd次元)
LoRAアダプタの重みA: A(dxr次元)
LoRAアダプタの重みB: B(rxd次元)
で、h=Wx+BAxとすることで、元のLLMの重みdxdより小さいLoRAアダプタの重みdxrとrxdの重みのみを更新することで、学習を軽量化しているということかな?
マージ時は
A(dxr次元)・B(rxd次元)=W'(dxd次元)
を計算して、以下のようにマージするらしい。
Wmerge = W + W'
やり方はこれを参考にしてみたい。