データベースから読み込んだ本のタイトルのデータで国会図書館の NDL opensearch を使って書籍情報を照会しデータベースに書き込む。




tags: IRuby 国会図書館 NDL Nokogiri
このページは、「マンガサイトにつひての色々な事情 03 」の補足です。
コードは Ruby ですが、google colab 上に IRuby カーネルをセットして実行することを想定しています。(じゃなくても可能かもしれないですが、それ以外で Ruby プログラムを書いたことが無いために不明です。インターネット接続されていて Ruby が動くコンピューターであればということで後ほど、Android で検証してみるつもりです。[1])
セットアップ自体については、こちらを参考に。
Googlecolab を使って iRuby で selenium と chromium で徘徊する為に「Googlecolab を iRuby カーネル ... Ruby 2.5.1 で動作させて Selenium を使うための設定。」 の記事のなかでは chromium browser と selenium webdriver のセットアップを解説していますが、本記事においては webdriver などは不要です。"faraday" が別途必要です。
 簡単に云うと、本の ISBN 情報なしに、本の題名から書籍データ( ISBN を含む)を抽出したいということで、国会図書館サーチを使います。速度は特に気にしませんが、コンスタントに5万件以上照会したいので、リクエスト数にリミットが特にない国会図書館の NDL opensearch API が便利ということになります。
簡単に云うと、本の ISBN 情報なしに、本の題名から書籍データ( ISBN を含む)を抽出したいということで、国会図書館サーチを使います。速度は特に気にしませんが、コンスタントに5万件以上照会したいので、リクエスト数にリミットが特にない国会図書館の NDL opensearch API が便利ということになります。
国立国会図書館サーチ
OpenSearch URL > XML(RSS) | https://iss.ndl.go.jp/api/opensearch
https://iss.ndl.go.jp/api/opensearch に対してクエリを送信すると、検索結果が XML(RSS) で返されます。その XML(RSS) を Ruby のXMLパーサーのライブラリ Nokogiri を使って検索結果のひとつを抜き出して、 [tbl_bookdata] へ書籍データを書き込みます。
SQLite データベースから本のタイトルと著者を読みこんで、国会図書館サーチで書籍検索する。
ここでは、NDL searchのコード眺めます。
読み込むデータベースのテーブル mangathank.db > [tbl_manga]
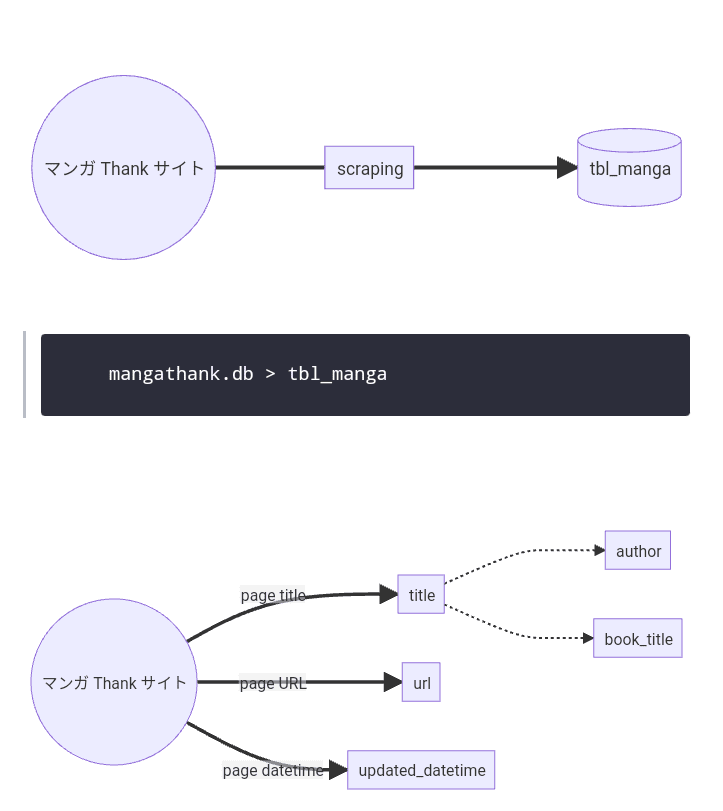
id INTEGER PRIMARY KEY,
title text,
url text,
updated_datetime datetime,
author text,
book_title text
詳細はこちら マンガサイト観測 1
NDL search --Ruby-プログラム-for-Googlecolab
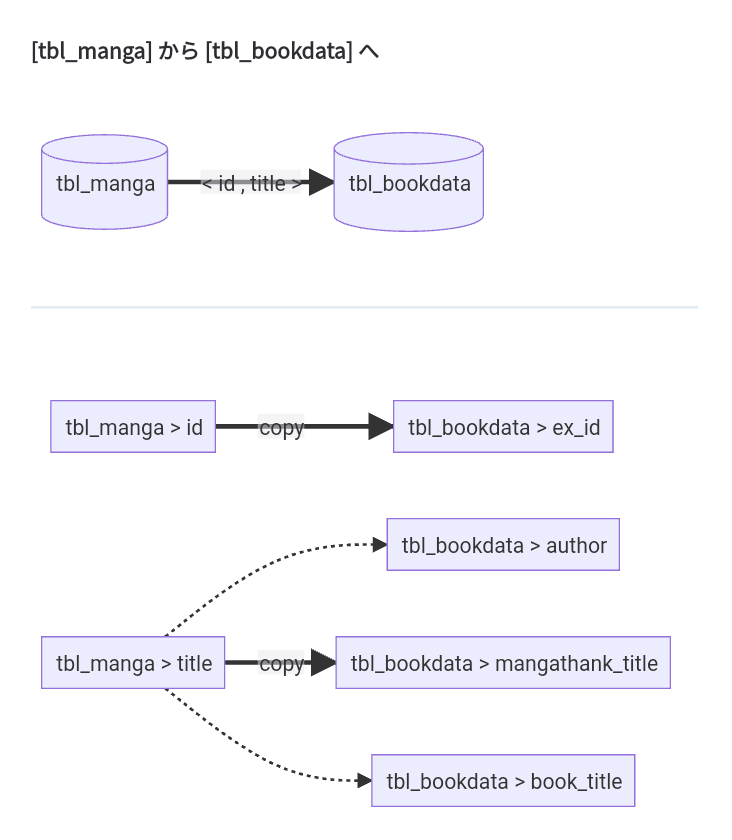
[tbl_manga] のカラム id, title を読み込んで 国会図書館 NDL サーチ で書籍データを照会して [tbl_bookdata]に書き込む。

bookdata.db > [tbl_bookdata]
id INTEGER PRIMARY KEY,
book_title text,
url text,
author text,
creatortranscription text,
volume text,
seriestitle text,
publisher text,
isbn text,
mangathank_title text,
ex_id integer
たとえば、
[田河水泡] のらくろ 漫画集 文庫版 第1巻
という tbl_manga の title の値の場合は、正規表現を使って、必要のない文字列を除去しタイトルと著者に分け NDL サーチにリクエストするクエリに組み込まれる。
NdlSearch インスタンスのクエリの中にはこのようにセットされる。
title = 'のらくろ 漫画集 1'
creator = '田河水泡'
レスポンスは xml で返されるが以下の html ページに記載された内容と同等になる。
国会図書館サーチ 'のらくろ 漫画集 1', '田河水泡' の検索結果
このような検索結果の情報が tbl_bookdata に書き込まれる。
tbl_mangaの title の値は、tbl_bookdata の mangathank_title にコピーされる。
同様に tbl_manga の id の値のは、 tbl_bookdata の ex_id にコピーされる。
OpenSearch URL > XML(RSS) https://iss.ndl.go.jp/api/opensearch
mediatype
1:本
2:記事・論文
3:新聞
4:児童書
5:レファレンス情報
6:デジタル資料
7:その他
8:障害者向け資料(障害者向け資料検索対象資料)
9:立法情報
mediatype => 1
cnt
出力レコード上限値
cnt => 1
#2021.7.13
require "faraday"
require 'nokogiri'
require 'sqlite3'
require 'time'
require 'date'
class NdlSearch
def get_book_info(title, creator = nil)
data = []
query = {
:mediatype => 1,
:cnt => 1
}
query[:title] = title
query[:creator] = creator if creator
if creator == ''
puts 'author :??'
end
puts
print "query :#{query}"
puts
puts
response = ndl_get('/api/opensearch', query)
xml = Nokogiri::XML(response.body)
xml.remove_namespaces!
items = xml.xpath('//item')
unless items.any? then
puts
puts 'ndl has no item'
data << {"totalResults"=>"0"}
else
#pp items.to_s
items.each do |item|
#puts
#puts item
book = {}
item.children.each do |c|
key = c.name
next if key == 'text'
val = "#{c.content}"
label = c.attribute("type")
if label
label = "#{label}".gsub(/^dcndl:|^dcterms:/,'')
book[label] ||= []
book[label] << val unless book[label].include?(val)
val = "#{label}:#{val}"
end
book[key] ||= []
book[key] << val unless book[key].include?(val)
end
book = book.map {|key,val| [key, val.join(',')]}.to_h
data << book
end
end
print 'data: '
puts data
puts
data
end
private
def ndl_get(path, pram)
con = Faraday.new(:url => 'https://iss.ndl.go.jp') do |f|
f.request :url_encoded
#f.response :logger
f.adapter :net_http
end
con.get path, pram
end
end
#DB
SQL =<<EOS
create table tbl_bookdata (
id INTEGER PRIMARY KEY,
book_title text,
url text,
author text,
creatortranscription text,
volume text,
seriestitle text,
publisher text,
isbn text,
mangathank_title text,
ex_id integer
);
EOS
count = 0
new_db = SQLite3::Database.open("bookdata.db")
db = SQLite3::Database.open("mangathank4.db")
new_db.execute(SQL)
temp_author = ''
temp_title = ''
51717.times do |api|
count += 1
puts
print count,' '
search_data = db.execute("select book_title,author,title,id from tbl_manga where id ='#{count}' ;")
*book_data = search_data.pop
#book_data[0] #=> book_title
#book_data[1] #=> author
#book_data[2] #=> title
#book_data[3] #==> id
mangathank_title = book_data[2].to_s.gsub(/\'/, "\'\'")
if book_data[2] == "null" then
p count
pp book_data
new_db.execute("insert into tbl_bookdata (id, book_title, author, mangathank_title, ex_id ) values('#{count}','book_title:nothing','author:nothing','#{mangathank_title}','#{book_data[3]}');")
else
author_data = book_data[2].to_s.slice(/((?<=\[).*?(?=\]))/)
#puts "author_dat:#{author_data}"
if author_data != nil
author_data.gsub!(/\ x\ /,' ')
author_data.sub!(/((?<=[\p{Hiragana}\p{Han}\p{Katakana}])x(?=[\p{Hiragana}\p{Han}\p{Katakana}]))/,' ')
author_data.gsub!(/\(|\)/,"\(" =>' ',"\)"=>'')
author_data.gsub!(/×/,' ')
author_data.gsub!(/\ &/,' ')
end
if /(\ )/.match(author_data) then
#/(\S+$)/.match(author_data)
#person = /(?<=['\ '])\S.*$/.match(author_data)
#str_array = person.to_s.split
str_array = author_data.to_s.split
person = str_array.pop
else
person = author_data.to_s
end
print("author_data: ", author_data , " person: " , person)
puts
num = book_data[2].to_s.slice(/((?<=第)\d+(?=巻|卷$))/)
#num = /((?<=第)\d+(?=巻$))/.match(book_data[0].to_s)
#book_data_0 = book_data[0].to_s.sub(/((?=第).*巻)/,'')
book_data_0 = book_data[2].to_s.gsub(/((?=第).*(巻|卷))/,'')
book_data_0.gsub!(/((?=第).*話)/,'')
book_data_0.gsub!(/(.(?<=\()文庫版(?=\)).)/,'')
book_data_0.gsub!(/(.(?<=\[)文庫版(?=\]).)/,'')
book_data_0.gsub!(/文庫版/,'')
book_data_0.gsub!(/(.(?<=\()完(?=\)).)/,'')
book_data_0.gsub!(/(.(?<=【).*(?=】).)/,'')
book_data_0.gsub!(/(.(?<=\[).+?(?=\]).)/,'')
book_data_0.lstrip!
book_data_0.rstrip!
if book_data_0 == temp_title then
if str_array then
person = temp_author
end
else
temp_title = book_data_0
temp_author = person
end
if num != nil then
num = num.to_i
book_data_0 += ' ' + num.to_s
end
#puts
#puts book_data[0]
#puts book_data_0
#puts
ndl_search = NdlSearch.new
onemore = 'true'
while onemore == 'true' do
res = ndl_search.get_book_info( book_data_0,person )
onemore = 'false'
if res == nil then
#puts "res: empty"
book_data_0.gsub!(/\'/,"\'\'")
puts book_data_0
new_db.execute("insert into tbl_bookdata (id, book_title, author, mangathank_title, ex_id ) values('#{count}','#{book_data_0}','#{author_data}','#{mangathank_title}','#{book_data[3]}');")
onemore = 'false'
else
res.each_with_index do |book,index|
#print "book : "
if book != "null" then
#puts "res:#{book}"
#puts "item:#{index}"
book.each do |key, val|
#puts "#{key}:#{val}"
if key == 'totalResults' then
#puts
#print "no match title name #{person} ",book_data[3],' '
book_data_0.gsub!(/\'/,"\'\'")
#puts book_data_0,person,mangathank_title
unless str_array.nil? then
if str_array.size > 0 then
person = str_array.shift
puts
print "#{person} ?"
puts
puts
onemore = 'true'
#sleep 0.2
break
else
new_db.execute("insert into tbl_bookdata (id, book_title, author, mangathank_title, ex_id ) values('#{count}', '#{book_data_0}','#{author_data}','#{mangathank_title}','#{book_data[3]}');")
onemore = 'false'
#sleep 0.2
break
end
else
new_db.execute("insert into tbl_bookdata (id, book_title, author, mangathank_title, ex_id ) values('#{count}', '#{book_data_0}','#{author_data}','#{mangathank_title}','#{book_data[3]}');")
onemore = 'false'
end
break
end
#puts "#{key}:#{val}"
if key == 'title' then
temp_author = person
puts "☆☆ #{count} ☆☆"
puts "#{key}:#{val}"
title = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("insert into tbl_bookdata (id, book_title, mangathank_title, ex_id ) values('#{count}', '#{title}','#{mangathank_title}','#{book_data[3]}');")
elsif key == 'author' then
author = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set author = '#{author}' where id = '#{count}';")
elsif key == 'creatorTranscription' then
creatortranscription = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set creatortranscription = '#{creatortranscription}' where id = '#{count}';")
elsif key == 'volume' then
volume = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set volume = '#{volume}' where id = '#{count}';")
elsif key == 'link' then
url = val
new_db.execute("update tbl_bookdata set url = '#{url}' where id = '#{count}';")
elsif key == 'publisher' then
puts "#{key}:#{val}"
publisher = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set publisher = '#{publisher}' where id = '#{count}';")
elsif key == 'ISBN' then
isbn = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set isbn = '#{isbn}' where id = '#{count}';")
elsif key == 'seriesTitle' then
seriestitle = val.to_s.gsub(/\'/, "\'\'")
new_db.execute("update tbl_bookdata set seriestitle = '#{seriestitle}' where id = '#{count}';")
onemore = 'false'
else
#new_db.execute("update tbl_bookdata set author = '', creatortranscription = '', volume = '', url = '', publisher = '', isbn = '', seriestitle = '' ;")
onemore = 'false'
next
end
end
else
onemore = 'false'
puts "error"
mangathank_title = book_data[2].to_s.gsub(/\'/, "\'\'")
new_db.execute("insert into tbl_bookdata (id, author, mangathank_title, ex_id ) values('#{count}','#{author_data}','#{mangathank_title}','#{book_data[3]}');")
end
end
end
end
end
end
bookdata.db から ISBN を抽出
100 個取り出す (python)
import sqlite3
import re
def extract_isbn(cur,tablename,temp_isbn,offset):
max = 100
counter = 0
if counter < max:
for i in range(10000):
if counter > max - 1:
counter = 0
break
else:
id = i + offset
isbn = cur.execute("SELECT isbn FROM %s WHERE id=?;"% tablename,[id])
for x in isbn:
if x != temp_isbn:
y = re.findall("(?<=\(\').+?(?=\'\,\))", str(x))
if y !=[]:
counter += 1
offset = id + 1
#print(str(counter)+':')
#print(id, end=' ')
print(*y)
temp_isbn = x
return offset
db_name = 'bookdata.db'
db = sqlite3.connect(db_name)
cur = db.cursor()
res =cur.execute("SELECT name FROM sqlite_master WHERE type='table';")
tablename = ''
for name in res:
#print(name[0])
tablename = name[0]
offset = 1
temp_isbn = ''
offset = extract_isbn(cur,tablename,temp_isbn,offset)
db.close()
100 個取り出す (Ruby)
require 'sqlite3'
def extract_isbn(res,offset)
max = offset + 100
counter = 0
res.each_with_index do |data,i|
if data[0] != nil then
if counter < offset then
counter += 1
puts i
next
end
if counter < max then
counter += 1
puts data[0]
else
offset = counter
break
end
end
end
return offset
end
db = SQLite3::Database.open "bookdata.db"
res = db.execute("select distinct(isbn) from tbl_bookdata ;")
offset = 0
offset = extract_isbn(res,offset)
db.close
ISBN を CSV に保存 (python)
import sqlite3
import re
import pandas as pd
db_name = 'bookdata.db'
db = sqlite3.connect(db_name)
cur = db.cursor()
res =cur.execute("SELECT name FROM sqlite_master WHERE type='table';")
tablename = ''
for name in res:
#print(name[0])
tablename = name[0]
res = cur.execute("SELECT distinct(isbn) FROM %s ;" % tablename)
isbn_list = []
for v in res:
#print(re.findall("(?<=\(\').*?(?=\'\,\))", str(v)))
isbn_list += v
db.close()
#print(isbn_list)
dict = {'isbn':isbn_list}
df = pd.DataFrame(dict)
# saving the dataframe
df.to_csv('isbn.csv')
ISBN を CSV に保存 (Ruby)
require 'sqlite3'
require 'csv'
db = SQLite3::Database.open "bookdata.db"
db.execute("select distinct(isbn) from tbl_bookdata ;") do |data|
if data[0] != nil then
CSV.open("isbn.csv","a") do |f|
f << [data[0]]
end
end
end
db.close
関連記事
-
32bit termux(armeabi) で nokogiri(1.8.1),faraday (1.5.1, 1.4.3)でテスト ↩︎
Discussion