GPT-3のファインチューニングを試す
公式の情報をもとに試してみる
ためしたいこと
架空のポケモンの名前を渡したら、そのポケモンのタイプを返してくれるモデルを作りたい。
質問:
ウミスズメのタイプを教えて?
タイプ:
期待する回答:
ひこう,みず
前提条件
- Open AIのAPIキーが必要。
- Open AIへの課金設定が必要(最初の無料期間ならいらないかも)。
- pipでopenaiをインストールしている必要がある。
データを用意する
これを使おう。
下準備
素材となるポケモンのデータはこんな感じ(最初の2件だけ抜粋した例)
[
{
"no": 1,
"name": "フシギダネ",
"form": "",
"isMegaEvolution": false,
"evolutions": [2],
"types": ["くさ", "どく"],
"abilities": ["しんりょく"],
"hiddenAbilities": ["ようりょくそ"],
"stats": {
"hp": 45,
"attack": 49,
"defence": 49,
"spAttack": 65,
"spDefence": 65,
"speed": 45
}
},
{
"no": 2,
"name": "フシギソウ",
"form": "",
"isMegaEvolution": false,
"evolutions": [3],
"types": ["くさ", "どく"],
"abilities": ["しんりょく"],
"hiddenAbilities": ["ようりょくそ"],
"stats": {
"hp": 60,
"attack": 62,
"defence": 63,
"spAttack": 80,
"spDefence": 80,
"speed": 60
}
},
]
これをOpenAIの学習に利用できるこんな感じのJSONLに変換したい。下の例はドキュメントに書いてるやつ。
{"prompt":"Company: BHFF insurance\nProduct: allround insurance\nAd:One stop shop for all your insurance needs!\nSupported:", "completion":" yes"}
{"prompt":"Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:", "completion":" no"}
キーはprompt(質問)とcompletion(回答)の2つ。
まずはjqコマンドでjsonとして規定に合うよう整形する。
cat pokemon_data.json | jq '.| map(.name |= . + "のタイプを教えて?\nタイプ:")|map({prompt:.name ,completion:.types| join(",")}) ' > pokemon.json
するとこんな感じになる。
[
{
"prompt": "フシギダネのタイプを教えて?\nタイプ:",
"completion": "くさ,どく"
},
{
"prompt": "フシギソウのタイプを教えて?\nタイプ:",
"completion": "くさ,どく"
},
]
しかしこれではまだ足りない。
学習に使うにはJSONではなくJSONL(JSON Lines)という形式に変換しないといけない。
これもjqコマンドでいける。
jq -c '.[]' pokemon.json > pokemon.jsonl
すると改行区切りのjsonl形式のデータが手に入る。
{"prompt":"フシギダネのタイプを教えて?\nタイプ:","completion":"くさ,どく"}
{"prompt":"フシギソウのタイプを教えて?\nタイプ:","completion":"くさ,どく"}
配列データを改行区切りで読み込むことで、全体をパースしなくても構造が分かって有利なのかもしれない。
openai のツールでデータを下準備する。
openai tools fine_tunes.prepare_data -f pokemon.jsonl
実行するといろいろ提案されるのでyesと答えて良しなにしてもらう。
- Your file contains 918 prompt-completion pairs
- Based on your data it seems like you're trying to fine-tune a model for classification
- For classification, we recommend you try one of the faster and cheaper models, such as `ada`
- For classification, you can estimate the expected model performance by keeping a held out dataset, which is not used for training
- There are 27 duplicated prompt-completion sets. These are rows: [447, 448, 449, 563, 629, 722, 724, 728, 730, 731, 733, 746, 767, 771, 801, 802, 803, 805, 806, 807, 815, 816, 849, 850, 852, 881, 910]
- More than a third of your `prompt` column/key is uppercase. Uppercase prompts tends to perform worse than a mixture of case encountered in normal language. We recommend to lower case the data if that makes sense in your domain. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
- All prompts end with suffix `のタイプを教えて?\nタイプ:`. This suffix seems very long. Consider replacing with a shorter suffix, such as `\n\n###\n\n`
- The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Based on the analysis we will perform the following actions:
- [Recommended] Remove 27 duplicate rows [Y/n]: Y
- [Recommended] Lowercase all your data in column/key `prompt` [Y/n]: Y
C:\Users\gabill\anaconda3\lib\site-packages\openai\validators.py:448: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
x[column] = x[column].str.lower()
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: Y
C:\Users\gabill\anaconda3\lib\site-packages\openai\validators.py:421: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
x["completion"] = x["completion"].apply(
- [Recommended] Would you like to split into training and validation set? [Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Wrote modified files to `pokemon_prepared_train.jsonl` and `pokemon_prepared_valid.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "pokemon_prepared_train.jsonl" -v "pokemon_prepared_valid.jsonl" --compute_classification_metrics --classification_n_classes 174
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string `のタイプを教えて?\nタ イプ:` for the model to start generating completions, rather than continuing with the prompt.
Once your model starts training, it'll approximately take 23.72 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.
すると2つのデータが出来上がった。
- pokemon_prepared_train.jsonl
- pokemon_prepared_valid.jsonl
いよいよファインチューニング開始。
まずはOPENAI_API_KEY という環境変数にOPENAPIのAPIキーをセットする。
Windowsの場合は
$env:OPENAI_API_KEY = "APIキー"
そして先程生成したpokemon_prepared_train.jsonlをdavinciモデル(一番高いやつ)をベースに学習開始!
openai api fine_tunes.create -t pokemon_prepared_train.jsonl -m davinci
なんかよくわからないが、途中で切断された。
Upload progress: 100%|███████████████████████████████████████████████████████████████████| 70.0k/70.0k [00:00<?, ?it/s]
Uploaded file from pokemon_prepared_train.jsonl: file-ごにょごにょ
Created fine-tune: ft-ごにょごにょ
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[2023-02-19 20:13:34] Created fine-tune: ft-ごにょごにょ
Stream interrupted (client disconnected).
To resume the stream, run:
openai api fine_tunes.follow -i ft-ごにょごにょ
メッセージにあるとおりの手順で再接続する。
openai api fine_tunes.follow -i ft-ごにょごにょ
なんかはじまった。2.5ドルかかるらしい。了解。
[2023-02-19 20:13:34] Created fine-tune: ft-ごにょごにょ
[2023-02-19 20:19:47] Fine-tune costs $2.51
[2023-02-19 20:19:47] Fine-tune enqueued. Queue number: 0
[2023-02-19 20:19:49] Fine-tune started
なんかできたっぽいぞ。
たかが1000件未満の学習で20分くらいかかった。
[2023-02-19 20:13:34] Created fine-tune: ft-ごにょごにょ
[2023-02-19 20:19:47] Fine-tune costs $2.51
[2023-02-19 20:19:47] Fine-tune enqueued. Queue number: 0
[2023-02-19 20:19:49] Fine-tune started
[2023-02-19 20:25:57] Completed epoch 1/4
[2023-02-19 20:29:23] Completed epoch 2/4
[2023-02-19 20:32:48] Completed epoch 3/4
[2023-02-19 20:36:15] Completed epoch 4/4
[2023-02-19 20:36:57] Uploaded model: davinci:ft-personal-2023-02-19-11-36-56
[2023-02-19 20:36:59] Uploaded result file: file-ごにょごにょ
[2023-02-19 20:36:59] Fine-tune succeeded
Job complete! Status: succeeded 🎉
Try out your fine-tuned model:
openai api completions.create -m davinci:ft-personal-2023-02-19-11-36-56 -p <YOUR_PROMPT>
深刻な問題が発覚
普通になんのチューニングもしてないChatGPTも期待した回答を返してくれる。
ファインチューニングを試すまでもない。
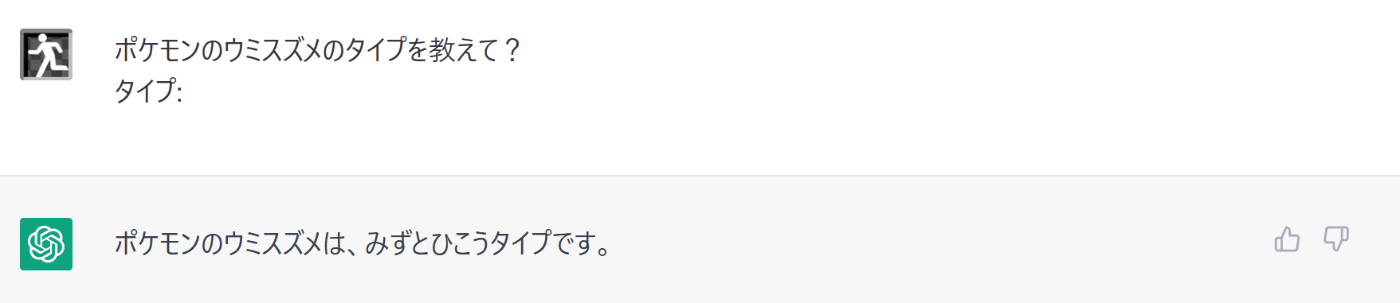
企画としては微妙な感じだが、とりあえずファインチューニングを試してみるのは継続してみよう。
微妙な名前を突っ込んだときの精度が違うかもしれないし。
というかウミスズメって実在するのか。
なるほど『みず・ひこう』っぽい感じがする。
さっそく試してみる
最初に普通のdavinciで答え、次にファインチューニングされたdavinciで回答する。
import openai
completion = openai.Completion.create(
model="davinci",
prompt="ウミスズメのタイプを教えて?\nタイプ:")
print("普通のdavinciの答え:" + completion.choices[0].text)
completion = openai.Completion.create(
model="davinci:ft-personal-2023-02-19-11-36-56",
prompt="ウミスズメのタイプを教えて?\nタイプ:")
print("改良されたdavinciの答え:" + completion.choices[0].text)
結果
普通のdavinciの答え: アダルト
屑ノコギリの卵
改良されたdavinciの答え: ノーマル,ひこう,ひこう
どうなんだこれ…。
普通のdavinciの回答が駄目駄目過ぎる…。
改良されたdavinciもみずタイプの情報が抜け落ち、ChatGPTよりやや微妙。
今回の結果
普通のdavinci <<< ファインチューニングされたdavinci < ChatGPT
といったところか。
ChatGPTはdavinciをちょっと改良した程度のものだと思ってたけど、だいぶ違うなぁ。
公式ドキュメントには
ファインチューニングは、より高品質の例でより優れたパフォーマンスを発揮します。基本モデルで高品質のプロンプトを使用するよりも優れたパフォーマンスを発揮するモデルを微調整するには、理想的には人間の専門家によって精査された、少なくとも数百の高品質の例を提供する必要があります。そこから、パフォーマンスは例の数が2倍になるたびに直線的に増加する傾向があります。通常、例の数を増やすことが、パフォーマンスを向上させるための最良かつ最も信頼できる方法です。
といったニュアンスの英文があるので、今回みたいな数百件のサンプルは最低レベルで、データを2倍4倍8倍に増やしていけばもっとマシになるらしい。
ポケモンの新作がもっともっと出てくるか、ChatGPTやGPT-4相当のAPIが提供されるのに期待するしかないか。
遊び終わったらお片付け。
モデルを消しておく。
$ openai api models.delete -i davinci:ft-personal-2023-02-19-11-36-56
{
"deleted": true,
"id": "davinci:ft-personal-2023-02-19-11-36-56",
"object": "model"
}
あーchatGPTには「ポケモンのウミスズメのタイプを教えて?」と頭に「ポケモンの」と付けたのに対して、ダビンチには「ウミスズメのタイプを教えて?」と尋ねてるからちょっとフェアじゃないか。
得られた情報
- 問題と答えが日本語計30文字くらいの一言質問を1000件くらい学習させると
- 費用は2.5ドルくらい。
- 学習時間は20分くらい。
- 精度はまぁマシになる。
今回は同じ形式の質問→答えをたくさん突っ込む感じで学習したけど、なんかもうちょっと雑に突っ込んだ知識を柔軟に組み合わせて回答してくれるのも試してみたいところ。
- AならばB
- BならばC
という学習を踏まえて - AはCですか?→Yes
と三段論法を展開するところを見てみたい。
改良されたdavinciの答え: ノーマル,ひこう,ひこう
これは回答の最後に停止シーケンスを用意してなかったのが原因かもしれない。
こういうの見るとほんとマルコフ連鎖だよなぁ。
Each completion should end with a fixed stop sequence to inform the model when the completion ends. A stop sequence could be , , or any other token that does not appear in any completion.\n###