GPT-4の32Kモデルを使おうとした…がダメだった。
ファインチューニングがあまり期待した感じにならなかったので、巨大なプロンプトでぶん殴る方向性を試したくなった。
LlamaIndexやChatGPT Pluginのようにベクトル検索を組み合わせる方法もあるが、特定の知識をピンポイントで引っ張ってくるだけならAIじゃなくても電子辞書でも出来る。やはり複数の知識を組み合わせて総合的に判断してくれてこそ、知性と言えるだろう。32kの巨大なプロンプトでぶん殴ればそれが実現できそうな気がする。
学習情報を用意
コンテキストサイズ32Kをうまく活用したい。
ChatGPTが知らない情報が望ましい。
という訳でWikipediaの『機動戦士ガンダム 水星の魔女』のページを使うことにした。
このアニメのことをChatGPTは知らない。

学習のために加工したWikipediaのデータ。
このアニメを知らない人が読んでも何が何やらだと思う。
後で出てくる3つの質問に答えるには人間でもかなり苦労する。
プログラム
Googole Colab上にPythonで実装した。
シークレットキーの入力
from getpass import getpass
secret = getpass('Enter the secret value: ')
ライブラリのインストール
!pip install tiktoken
!pip install openai
ファイルのダウンロード
!mkdir ./data
!curl -L -o ./data/sui.txt https://gist.githubusercontent.com/kurehajime/1921410f6c06995f7501a2773582421e/raw/77ac788a2e54c53d0f9ceb771ac97276bcf34f46/sui.md
トークン数の確認
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4")
count = 0
with open('./data/sui.txt', 'r') as f:
for data in f:
count += len(encoding.encode(data))
print(count)
結果は29154トークン。
gpt-4-32kは32kのトークンが使えるが、これには解答のトークン数も含まれる。
だから少し余裕を見て大体30kトークン付近に抑えておく。
ファイル読みこみ
wiki = ''
with open('./data/sui.txt', 'r') as f:
wiki = f.read()
シークレットキーのセット
import openai
openai.api_key = secret
満を持してプロンプトを投げる。
質問の内容は3つ。
- のちに輸送会社の下働きをすることになるボブと決闘しホルダーになった人物が乗るモビルスーツを開発した企業の名前は?
- この作品におけるアーシアンはどのような存在ですか?
- プロスペラ・マーキュリーが目的を達成する上で必要となる人物を3人、障壁となる人物を3人、理由付きで挙げてください。
1の答えは『シン・セー開発公社』
「のちに輸送会社の下働きをすることになるボブ」とはグエルの偽名で、グエルと決闘したホルダーは主人公であるスレッタ、スレッタが乗る機体はエアリアル、エアリアルを作ったのはシン・セー開発公社。
複数の章から情報を数珠つなぎに引っ張ってこないと解答できない質問。
2の答えはちょっと難しい。虐げられた被害者でもあり、味方でも敵でもある。その辺の複雑さを上手いこと表現してくれることを期待している。
3の答えは…作品解釈に係るところなので答えは人それぞれだが、理由付きで答えるとなるとそれなりの読解力が必要とされる。
completion = openai.ChatCompletion.create(
model="gpt-4-32k",
messages=[
{"role": "user", "content": f"""
参考資料をもとに、以下の質問に答えてください。
* のちに輸送会社の下働きをすることになるボブと決闘しホルダーになった人物が乗るモビルスーツを開発した企業の名前は?
* この作品におけるアーシアンはどのような存在ですか?
* プロスペラ・マーキュリーが目的を達成する上で必要となる人物を3人、障壁となる人物を3人、理由付きで挙げてください。
参考資料
---
{wiki}
"""}
]
)
for cho in completion.choices:
print(cho.message.content)
実行したらエラー
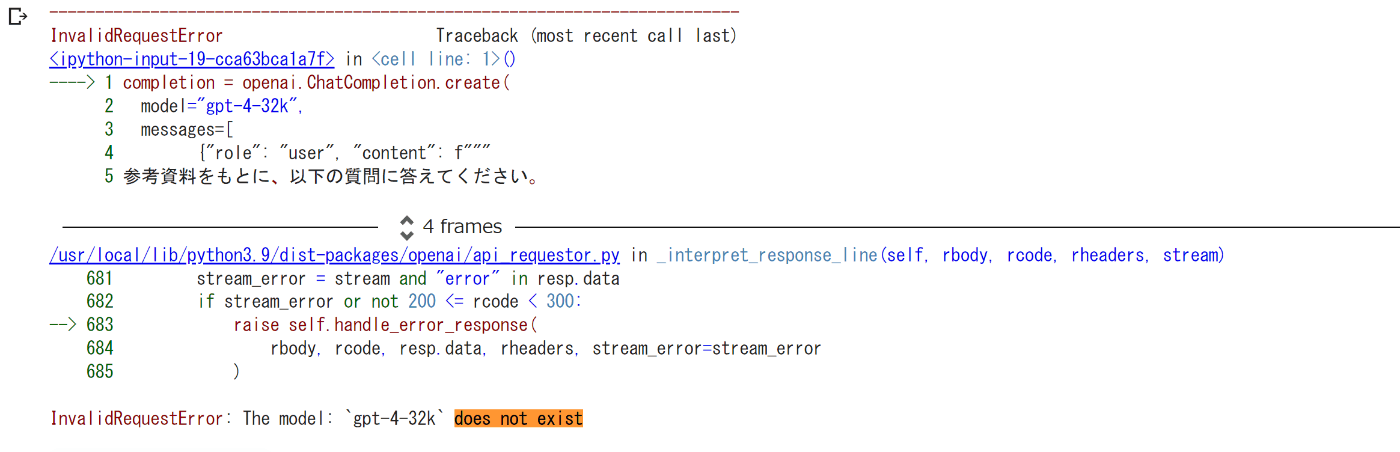
The model: gpt-4-32k does not exist
gpt-4-32kというモデルは存在しない、と。

いや公式サイトにも載ってるでしょ…と思いいろいろ調べてみたら、この公式フォーラムにたどり着いた。
WaitlistでGPT-4を使えるようになった人でも、32k版はまだ使えないらしい。
残念。
おわり。