【低コスト】OpenAI APIの「Flex processing」活用術:Batch APIレートでGPT-5を使う方法
はじめに
こんにちは!
現在,M1で就活中のYukiです.日頃は,医療AIの研究・開発を大学・インターン先で行っております.今回は,研究中に知ったOpenAI APIのコスト削減方法について共有します.この記事が,多くの方のお役に立てれば幸いです!
イントロダクション
OpenAI APIには「Flex processing」というサービスがベータ版としてあります.これは,APIリクエストの応答速度と引き換えに,利用料金をBatch APIレートまで大幅に抑える(半額程度)ことができるオプションです(こちらは以前からありましたが,筆者は最近になって初めて知りました).
これまで低コストでAPIを使用する選択肢としては「Batch API」がありました.しかし,個人的な意見ですがBatch APIは,
- リクエストをファイル(JSONL)にまとめてアップロードする必要がある.
- 処理完了が「24時間以内」と幅広く,いつ結果が返ってくるか予測しづらい.
- 既存のResponses APIやChat Completions APIとはリクエスト・結果取得の方法が異なり,試すための実装コストが高い.
といった特性があり,「サクッと試す」にはハードルがありました.
今回登場した「Flex processing」は,この問題を解決します.既存のResponses, Chat Completions APIなどのコードに service_tier="flex" というパラメータを1行追加するだけで,Batch APIレートの低コストの恩恵を受けられます.
この記事では,エンジニア向けにFlex processingの概要,具体的な使い方,そして利用時の注意点について詳しく解説します.
本記事では,以下のOpenAIのドキュメントを参考にしましたので,ご参考ください.
Flex processingとは?
Flex processingは,簡単に言えば「低速・低コスト」な処理モードです.
通常のリクエスト(service_tier="auto" またはデフォルト)が即時性を重視するのに対し,Flex processingはリソースの空き状況に応じて処理を行うため,応答時間は遅くなりますが,その分コストが削減されます.
💡 メリット:圧倒的な低コストと手軽さ
-
圧倒的な低コスト: トークンはBatch APIレートで価格設定され,さらにプロンプトキャッシュによる追加割引も適用されます.
-
実装の手軽さ: Batch APIのようにファイルI/Oや別エンドポイントを意識する必要がなく,既存のAPI呼び出しに service_tier="flex" を追加するだけで利用できます.
コストを最優先するタスク,例えば以下のようなユースケースに最適です.
- モデルの評価
- 大量のデータ拡張
- 非同期で実行するワークロード(夜間バッチなど)
- 研究開発や個人的な実験
⚠️ デメリットと制約
もちろんトレードオフも存在します.
- 低速な応答: 即時のレスポンスは期待できません.
- リソース不足の可能性: リクエストが集中した場合など,リソースが確保できずにエラー(429 Resource Unavailable)となる可能性があります.
- ベータ版: 現在はベータ機能としての提供です.
- 対応モデルが以下の3つで限定的です.
- gpt-5
- o3
- o4-mini
APIでの具体的な使用方法
実際の使用方法について説明します.Flex processingを利用するのは非常に簡単で,APIリクエスト時に service_tier="flex" パラメータを追加するだけです.
また,Flex processingは処理に時間がかかるため,OpenAI SDKのデフォルトタイムアウト(10分)を延長することが推奨されています.公式ドキュメントでは15分(900秒)への延長が例示されています.
from openai import OpenAI
client = OpenAI(
# デフォルトタイムアウトを10分から15分(900秒)に延長
timeout=900.0
)
response = client.responses.create(
model="gpt-5-mini",
instructions="あなたは有能なアシスタントです。",
input="こんにちは!",
service_tier="flex", # 変更点! "priority": レイテンシを優先する場合
)
print(response.output_text)
レスポンス(推論時間)の差
Flexがどの程度,Standardに比べて,遅くなるか検証しました.10回の試行の平均を以下に表で示しております.結果として,予想に反してFlexの方が速くなる結果となりました.
| Standard | Flex | |
|---|---|---|
| 平均のレスポンス時間 | 2.92 ± 0.86 [s] | 2.00 ± 0.80 [s] |
念のため,StandardとFlexの設定を見間違えていないか確認したり,何度か試行したりしましたが,同様の結果が得られました.ただし,これはあくまで特定の条件下での参考値であり,実行のタイミングなどによって結果は変動する点にご留意ください.
注意点
- リクエストタイムアウト (408 Request Timeout)
Flex processingを安定して運用するためには,特有のエラーケースを理解し,適切にハンドリングすることが重要です.前述の通り,Flex processingは低速です.複雑なタスクや非常に長いプロンプトの場合,SDKのデフォルトタイムアウト(10分)を超える可能性があります.
対策として,timeout パラメータでタイムアウトを十分に長く設定してください(例:timeout=900.0).
補足: OpenAI SDKは,408 Request Timeout エラーが発生した場合,デフォルトで2回自動的にリトライを行います.
- 使用可能な関数
Flex processingを使用する際は,以下の2つが使用できます.
- client.responses.create()
- client.chat.completions.create()
一方で,client.responses.parse()では,使用できないため,Structured outputsで使用する際は注意が必要です.この場合は,create()の関数でStructured outputsを指示することが必要です.
実際の料金比較(Batch/Flex/Standard/Priority)
Flex processingがBatch APIレートと同一であり,Standardティアの半額であることが価格表からも確認できます(価格は$1MトークンあたりのInput/Output料金).
| Input/Output Pricing | Batch | Flex | Standard | Priority |
|---|---|---|---|---|
| gpt-5 | 0.625/5.00 | 0.625/5.00 | 1.25/10.0 | 2.50/20.0 |
| gpt-5-mini | 0.125/1.00 | 0.125/1.00 | 0.25/2.00 | 0.45/3.60 |
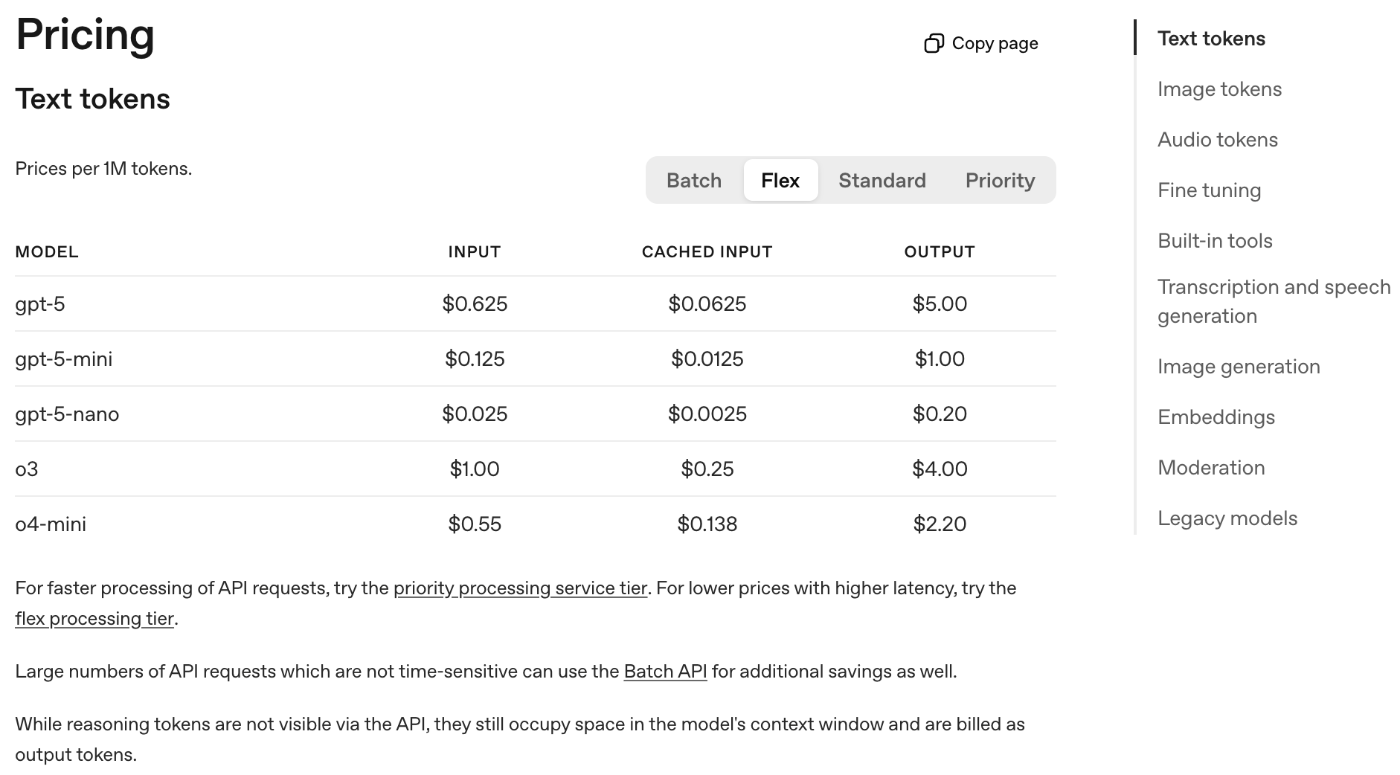
Flexの金額

通常の金額
参考にした料金のドキュメント
Priority processing
Priority Processingは,APIのレスポンス速度を最優先するモードです.これは割高ですが,レイテンシを重要視する環境で最適なものです.
まとめ
OpenAIの「Flex processing」は,API利用のコストと速度のトレードオフをユーザーが選択できるようにする機能です.
Batch APIのような大幅な実装変更を必要とせず,service_tier="flex" を指定するだけで低コスト化できる手軽さが最大の魅力です.
ベータ版ではありますが,gpt-5 や gpt-5-miniといった最新モデルを低コストで試せるのは手軽です.ユースケースが合致する場面では,積極的に活用してみてはいかがでしょうか.
追記
2025/11/02: レスポンス時間の章を追加
Discussion