InfluxDBを試す
そういえば昔ちょっと触ったなぁ、、、という記憶をもう一度呼び起こすために。。。。
いろいろな利用形態があるが、今回はローカルにセットアップできるOSS版を使用する。
InfluxDB オープンソース
時系列はInfluxDBオープンソースから始まります。
なぜInfluxDBオープンソースを使うのか
InfluxDBは、単一のバイナリで時系列の管理と分析を提供します。
- 素晴らしいものへの到達がより速く
- InfluxDBには、時系列データの作業を開始するためのツールがすべて1つのバイナリに含まれています。 データベースの旧バージョンでは、UIとダッシュボードツール、バックグラウンド処理、およびモニタリングエージェントが提供されています。 これらすべてにより、展開とセットアップが容易になり、セキュリティも強化されます。
- 深い洞察と分析
- クエリを構造化し、共通のロジックを簡単に共有できる関数やライブラリに分離することで、開発を迅速化できます。また、他のSQLデータストア(Postgres、Microsoft SQL Server、SQLite、SAP Hana)やクラウドベースのデータストア(Google Bigtable、Amazon Athena、Snowflake)を使用して、時系列データを拡充することもできます。
- 開発者の生産性を最大限に高めるよう最適化
- InfluxDBのすべて(取り込み、クエリ、ストレージ)が、統一されたAPIでアクセスできるようになりました。これにより、開発者はすべてをプログラムで制御できるため、より短期間で素晴らしい成果を出すことが可能になります。
InfluxDB の特徴
- APIとツールセット
- InfluxDBには、より多くの機能と少ないコードで素早く開始するためのAPIとツール一式が用意されています。
- データを収集、変換、視覚化するためのRESTful APIとクライアントライブラリセット(InfluxDB API、Arduino、C#、Go、Java、JavaScript、Kotlin、Node.js、PHP、Python、R、Ruby、Scala、Swift)
- Telegraf – 300以上のプラグインを備えたオープンソースのコレクターエージェント
- 時系列エンジン
- 大容量のデータワークロードをグローバルに大量に実行し、成長させます。
- シリーズの基数と高い処理能力により、毎秒数億件の時系列データを継続的に取り込み、変換
- バッチ処理とストリーミングにより、何百万ものソースからのデータの取り込みと結合が可能
- 高忠実度およびダウンサンプルされたデータの保持を管理するための柔軟なストレージ
- コミュニティとエコシステム
- InfluxDBは、クラウドおよびオープンソース開発者の大規模なコミュニティとエコシステムによってサポートされており、お客様の望む方法で作業できるよう支援します。
- AWS LambdaまたはInfluxDB CL
- Grafana、Google Data Studio、PTC ThingWorxに接続
- Postman を使用して InfluxDB API とやり取りします。
お客様の環境で動作
強力なインジェクションエージェント、クライアントライブラリ、APIのセットを使用すれば、あらゆる場所からデータを取得できます。
- Telegraf
- InfluxDBは、データベース、アプリケーション、システム、IoTセンサーからのメトリクスとイベントの収集と送信の両方にTelegrafを使用しています。Telegrafは、300以上のプラグインを備えたプラグイン駆動型のサーバーエージェントです。Goで記述されており、外部依存なしに単一のバイナリにコンパイルされ、必要とするメモリ容量は極めてわずかです。
- クライアントライブラリ
- InfluxDBは、強力なクライアントライブラリセットを介してアクセスできます。現在、Arduino、C#、Go、Java、JavaScript、Kotlin、Node.js、PHP、Python、R、Ruby、Scala、Swift用のクライアントライブラリがあります。これらのクライアントライブラリは、UIの新しいタブで簡単にアクセスできます。
- エッジおよび分散環境
- InfluxDB を使用すると、エッジデバイスからのデータの収集、処理、分析が可能になり、分散インフラストラクチャを最適化できます。また、InfluxDB API を使用して、エッジから InfluxDB インスタンスにデータを書き込んだり、その逆も可能です。これにより、分散環境内のあらゆるデータにアクセスできるようになります。
インストール
いろいろなインストール方法があるが、自分はdocker-composeを使おうと思う。
$ mkdir influxdb-test && cd influxdb-test
docker-compose.yamlの作成。作業ディレクトリ内で完結するように少しだけ書き換えてある。
$ vi docker-compose.yaml
services:
influxdb2:
image: influxdb:2
ports:
- 8086:8086
environment:
DOCKER_INFLUXDB_INIT_MODE: setup
DOCKER_INFLUXDB_INIT_USERNAME_FILE: /run/secrets/influxdb2-admin-username
DOCKER_INFLUXDB_INIT_PASSWORD_FILE: /run/secrets/influxdb2-admin-password
DOCKER_INFLUXDB_INIT_ADMIN_TOKEN_FILE: /run/secrets/influxdb2-admin-token
DOCKER_INFLUXDB_INIT_ORG: docs
DOCKER_INFLUXDB_INIT_BUCKET: home
secrets:
- influxdb2-admin-username
- influxdb2-admin-password
- influxdb2-admin-token
volumes:
- type: volume
source: influxdb2-data
target: /var/lib/influxdb2
- type: volume
source: influxdb2-config
target: /etc/influxdb2
secrets:
influxdb2-admin-username:
file: .env.influxdb2-admin-username
influxdb2-admin-password:
file: .env.influxdb2-admin-password
influxdb2-admin-token:
file: .env.influxdb2-admin-token
volumes:
influxdb2-data:
influxdb2-config:
$ echo "admin" > .env.influxdb2-admin-username
$ echo "admin" > .env.influxdb2-admin-password
$ echo "MyInitialAdminToken0==" > .env.influxdb2-admin-token
起動
$ docker compose up -d
Get started
InfluxDBを始めてみましょう
InfluxDB 2.7は、時系列データを収集、保存、処理、可視化するために構築されたプラットフォームです。 時系列データは、時間順にインデックスが付けられた一連のデータポイントです。 データポイントは通常、同じソースから行われた連続した測定値で構成され、時間の経過に伴う変化を追跡するために使用されます。 時系列データの例には、次のようなものがあります:
- 産業用センサー・データ
- サーバーのパフォーマンス指標
- 1分間の心拍数
- 脳内電気活動
- 雨量測定
- 株価
このチュートリアルでは、InfluxDB 2.7 への時系列データの書き込み、データのクエリ、データの処理とアラート、そしてデータの視覚化について説明します。
始める前に理解しておくべき重要な概念
InfluxDB を使い始める前に、InfluxDB における時系列データの構成と保存方法、およびこのドキュメント全体で使用されるいくつかの重要な定義について理解しておくことが重要です。
データ構成について
InfluxDBのデータモデルでは、時系列データをバケットと測定データに整理します。 バケットには複数の測定データを格納できます。 測定データには複数のタグとフィールドが含まれます。
- バケット(bucket): 時系列データが格納される場所。 バケットには複数の測定データを格納できる。
- 測定データ(measurement): 時系列データの論理的なグループ化。 与えられた計測における全てのポイントは同じタグを持つべきである。1つの測定データには複数のタグとフィールドが含まれる。
- タグ(tag): 値は異なるが、頻繁に変更されないキーと値のペア。 タグは各ポイントのメタデータを保存するためのもの。例えば、ホスト、場所、ステーションなど、データのソースを識別するためのもの。
- フィールド(field): 時間の経過とともに変化する値を持つキーと値のペア。例えば:温度、気圧、株価など。
- タイムスタンプ(timestamp): データに関連づけられたタイムスタンプ。 ディスクに保存され、クエリされるとき、すべてのデータは時間順に並べられる。
InfluxDBデータモデルの詳細な情報や例については、データ要素を参照してください。
重要な定義
以下は、InfluxDB を使用する際に理解しておくべき重要な定義です。
- ポイント: 測定値、タグキー、タグ値、フィールドキー、タイムスタンプによって識別される単一のデータレコード。
- シリーズ: 同じ測定値、タグキー、タグ値を持つポイントのグループ。
InfluxDB クエリ結果の例
https://docs.influxdata.com/influxdb/v2/get-started/#example-influxdb-query-results を 書き換えたもの使用するツール
このチュートリアル全体を通して、InfluxDB 2.7 とやりとりするために使用できる複数のツールがあります。以下に挙げる各ツールの例が提供されています。
- InfluxDBユーザインタフェース(UI)
influxCLI- InfluxDB HTTP API
InfluxDBユーザインタフェース(UI)
InfluxDBのUIは、InfluxDBとのやりとりや管理を行うためのウェブベースの視覚的なインターフェースを提供します。UIはInfluxDBに同梱されており、InfluxDBサービスの一部として実行されます。UIにアクセスするには、InfluxDBが実行されている状態で、ブラウザでlocalhost:8086にアクセスしてください。
influx CLI
influx CLIを使用すると、コマンドラインから InfluxDB 2.7 と対話したり管理したりすることができます。CLI は InfluxDB とは別にパッケージ化されており、別途ダウンロードおよびインストールする必要があります。CLI のインストール方法の詳細については、「influx CLI の使用」を参照してください。InfluxDB HTTP API
InfluxDB APIは、HTTP(S)クライアントを使用してInfluxDB 2.7とやりとりするためのシンプルな方法を提供します。このチュートリアルの例ではcURLを使用していますが、HTTP(S)クライアントであればどれでも動作します。
認証
InfluxDB 2.7 では、APIトークンを使用した認証が必要です。各APIトークンは、ユーザーとInfluxDBリソースに対する特定の権限セットに関連付けられています。

セットアップ
初期設定として以下を実施する。
- APIトークンの作成
- バケットの作成
これらは用意されている以下のツールのどれを使っても実施できる。
- InfluxDBユーザインタフェース(UI)
- influx CLI
- InfluxDB HTTP API
今回は、InfluxDBユーザインタフェース(UI)経由で行ってみる。
ブラウザで8086番ポートにアクセスするとログイン画面が表示されるので、.env.influxdb2-admin-|(username|password)で指定したユーザ名・パスワードでログイン。
ログイン画面が表示される。

左のメニューから"API Token"をクリック。
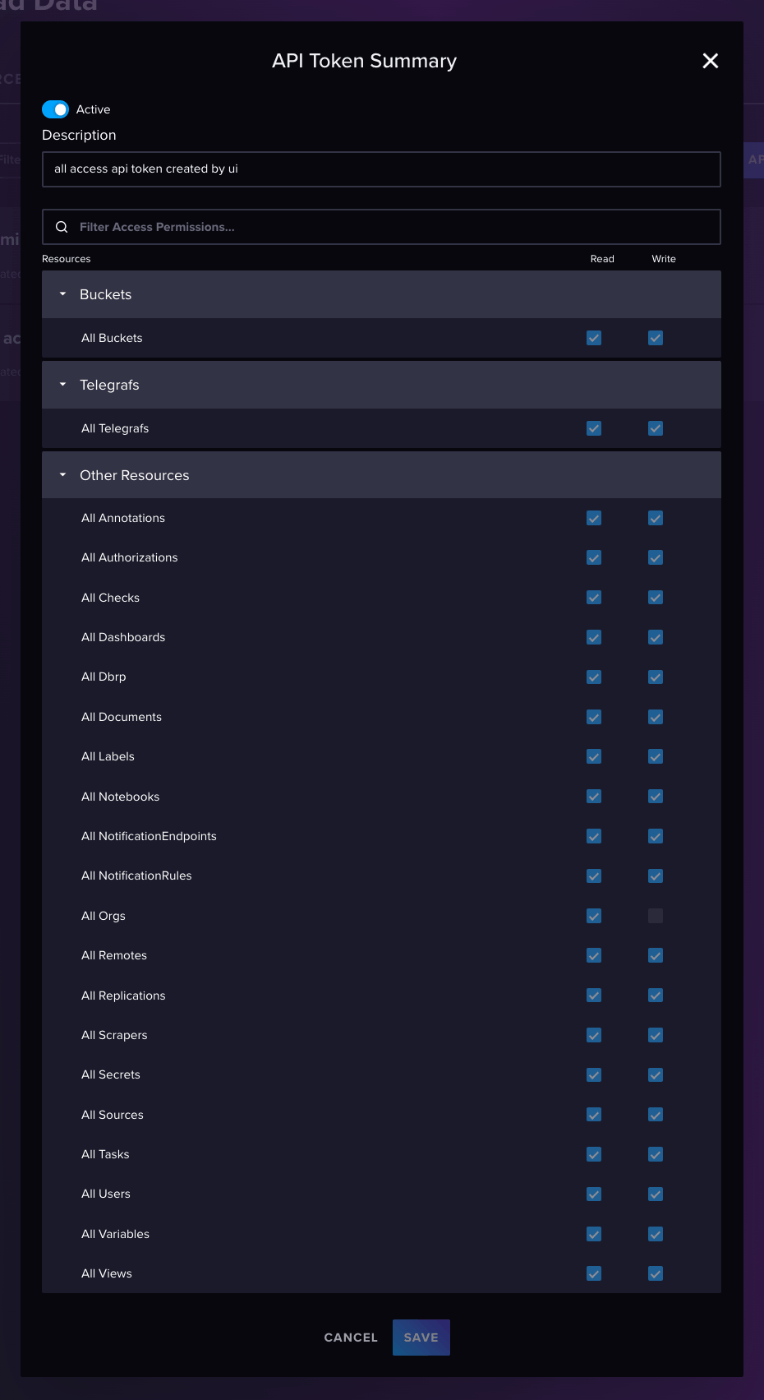
最初にファイルで用意しておいたものは"admin's Token"というフル権限を与えたAPIトークンになるが、これとは別にトークンを作成して使用することが推奨されている。"GENERATE API TOKEN"から"All Access API Token"をクリック。

APIトークンの説明を適宜入力して作成

作成された。再度表示はできないようなので何処かに控えておく。なお、自分の環境では"COPY TO CLIPBOARD"は動かなかったので直接コピペした。
作成されたAPIトークンを確認してみる。
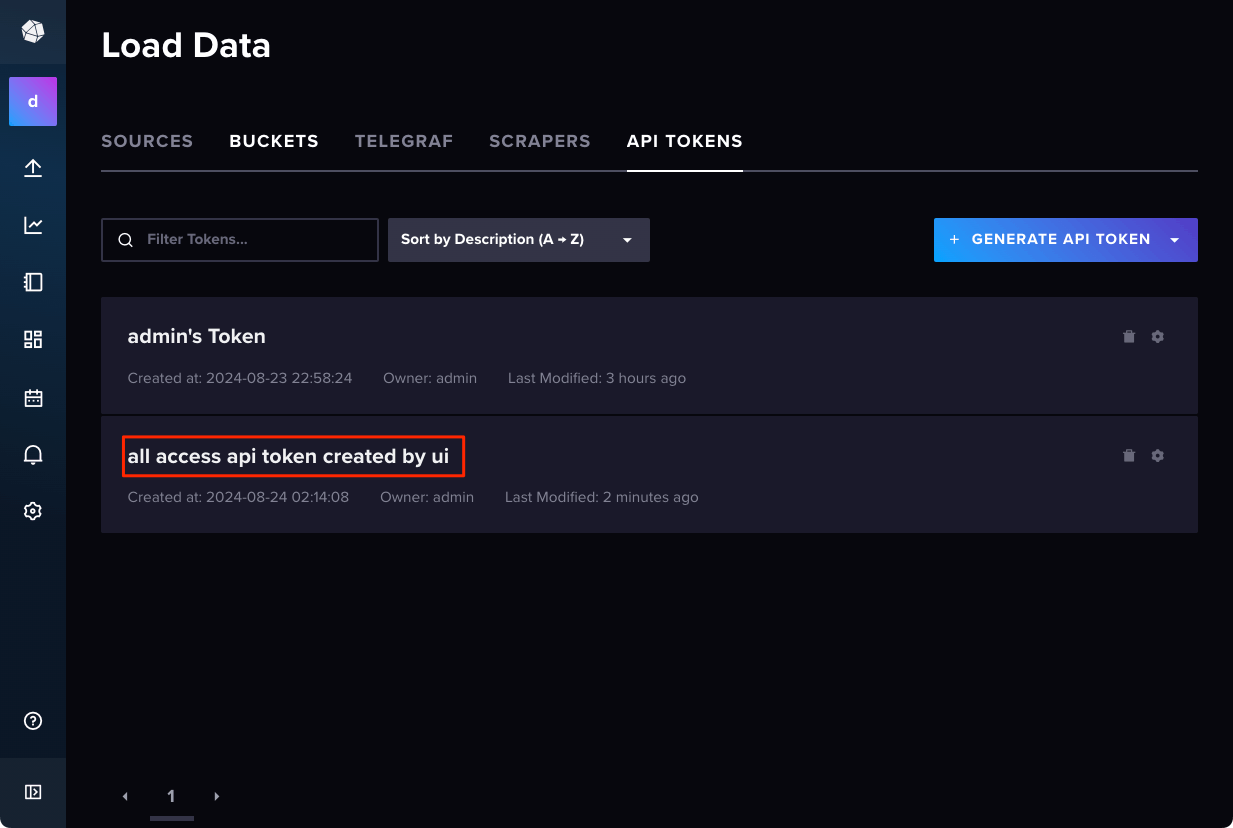
"All Access API Token"で作成すると、最初のトークンと同様にフル権限が与えられているのがわかる。これはどうも後からは変更できないようなので、細かく権限を設定したい場合は、"GENERATE API TOKEN"から"Custom API Token"を使用する必要がある模様。
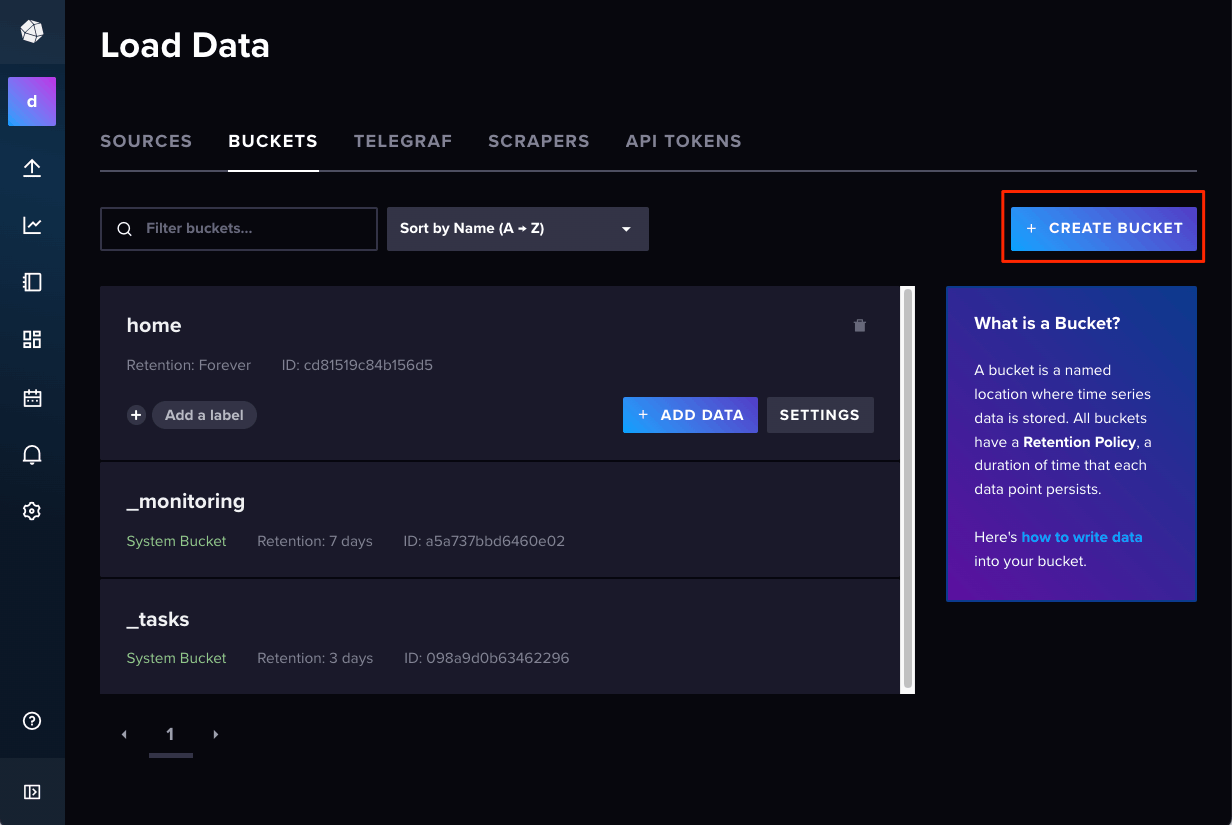
では次にバケットを作成する。左のメニューから選択することもできるし、上のタブから選択することもできる。

"CREATE BUCKET"をクリック
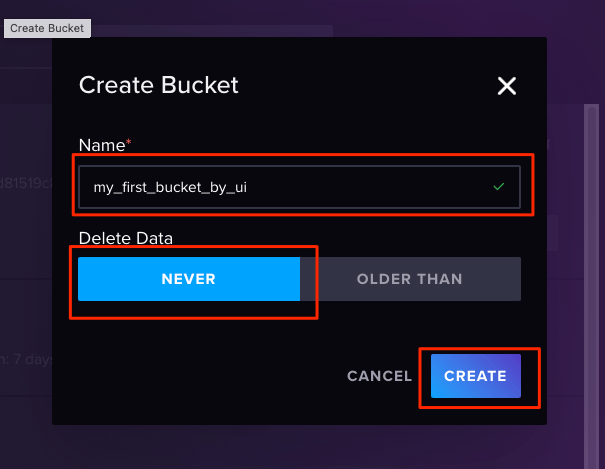
バケット名を入力。また、データの保持期間を設定することができる。今回は"NEVER"(永久に保存)を選択して、作成。
作成完了
データの書き込み
では実際に時系列データを書き込んでみる。データの書き込みには以下が使える。
- Influxユーザインタフェース (UI)
- InfluxDB HTTP API
- influx CLI
- Telegraf
- InfluxDBクライアントライブラリ
また、書き込むデータはラインプロトコルというテキストフォーマットである必要がある。
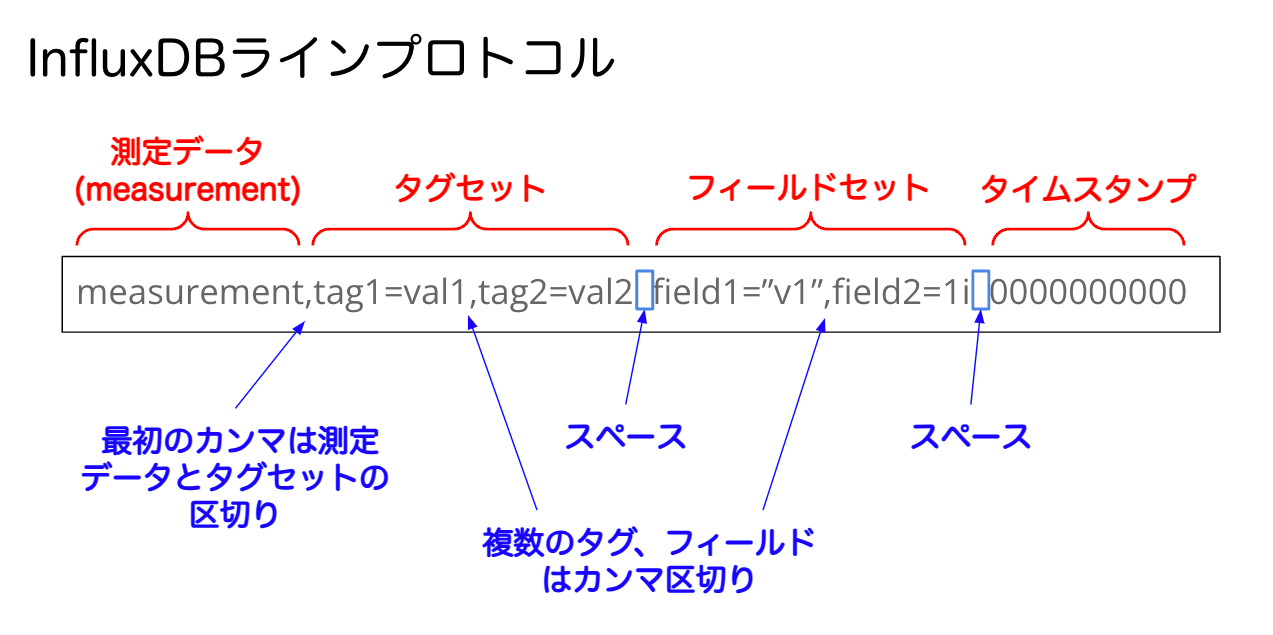
用意されている自宅センサーのサンプルを日本語にして、タイムスタンプも最近のもの(2024/08/25)に変えてみた。日本語が通るかどうかの確認も含めて。
home,room=リビング temp=21.1,hum=35.9,co=0i 1724572800
home,room=キッチン temp=21.0,hum=35.9,co=0i 1724572800
home,room=リビング temp=21.4,hum=35.9,co=0i 1724576400
home,room=キッチン temp=23.0,hum=36.2,co=0i 1724576400
home,room=リビング temp=21.8,hum=36.0,co=0i 1724580000
home,room=キッチン temp=22.7,hum=36.1,co=0i 1724580000
home,room=リビング temp=22.2,hum=36.0,co=0i 1724583600
home,room=キッチン temp=22.4,hum=36.0,co=0i 1724583600
home,room=リビング temp=22.2,hum=35.9,co=0i 1724587200
home,room=キッチン temp=22.5,hum=36.0,co=0i 1724587200
home,room=リビング temp=22.4,hum=36.0,co=0i 1724590800
home,room=キッチン temp=22.8,hum=36.5,co=1i 1724590800
home,room=リビング temp=22.3,hum=36.1,co=0i 1724594400
home,room=キッチン temp=22.8,hum=36.3,co=1i 1724594400
home,room=リビング temp=22.3,hum=36.1,co=1i 1724598000
home,room=キッチン temp=22.7,hum=36.2,co=3i 1724598000
home,room=リビング temp=22.4,hum=36.0,co=4i 1724601600
home,room=キッチン temp=22.4,hum=36.0,co=7i 1724601600
home,room=リビング temp=22.6,hum=35.9,co=5i 1724605200
home,room=キッチン temp=22.7,hum=36.0,co=9i 1724605200
home,room=リビング temp=22.8,hum=36.2,co=9i 1724608800
home,room=キッチン temp=23.3,hum=36.9,co=18i 1724608800
home,room=リビング temp=22.5,hum=36.3,co=14i 1724612400
home,room=キッチン temp=23.1,hum=36.6,co=22i 1724612400
ではデータを追加してみる。Web UIから。
"Bucket"画面を開いて、該当のバケットの"ADD DATA"から"Line Protocol"をクリック
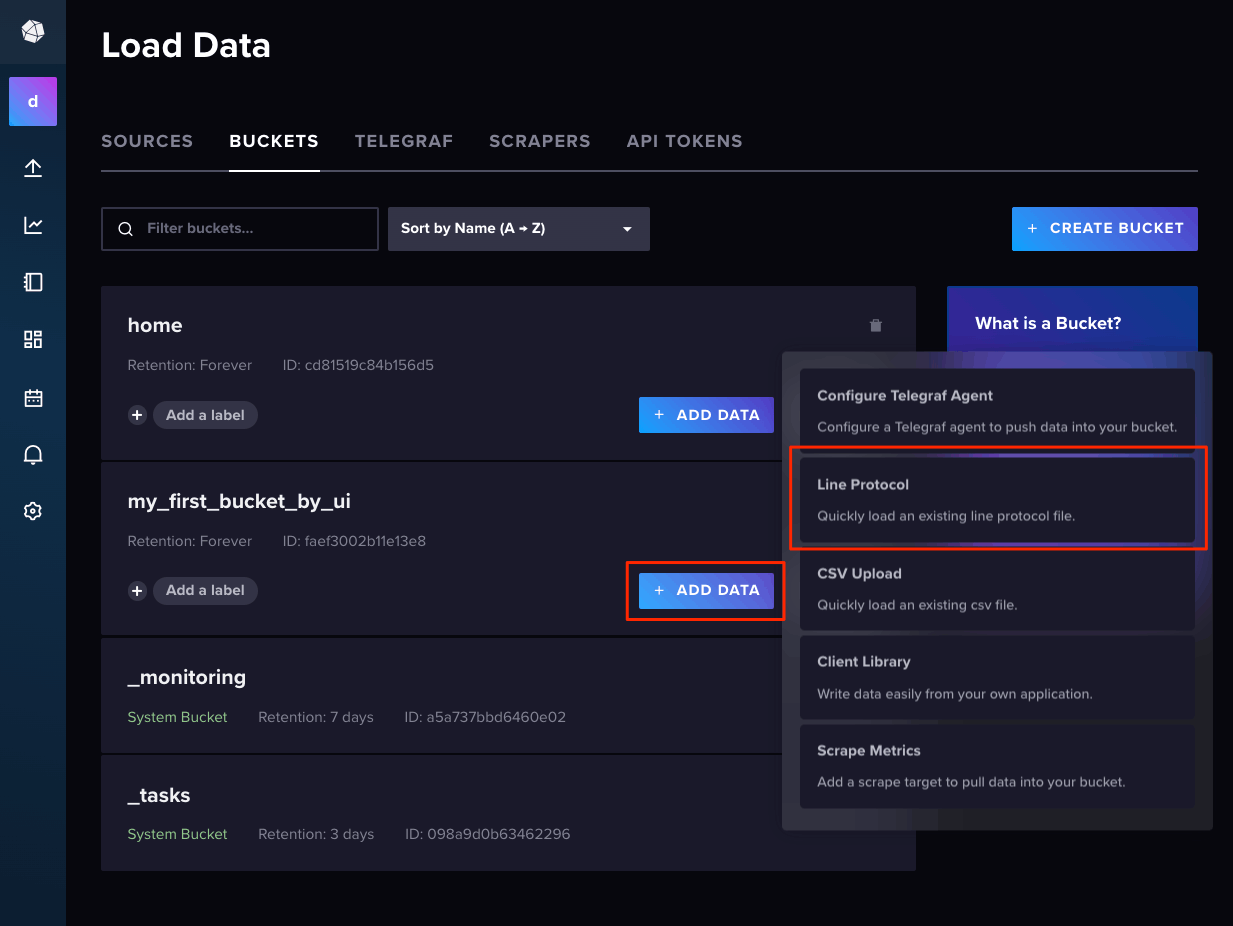
"ENTER MANUALLY"をクリックしてサンプルの一部をコピペ。なお、"Presicion"はタイムスタンプの精度を設定する箇所で、データの精度に合わせて変更する必要がある。UNIXタイムスタンプの場合は「Seconds」(秒)で設定する。"WRITE DATA"で保存。

以下のように表示されればOK
Influx CLIの場合。今回はDockerインストールなのでコンテナ内にCLIが含まれているのを使う。
$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
influxdb-test-influxdb2-1 influxdb:2 "/entrypoint.sh infl…" influxdb2 37 hours ago Up 37 hours 0.0.0.0:8086->8086/tcp, :::8086->8086/tcp
コンテナに入る。
$ docker compose exec -ti influxdb2 bash
以下コンテナ内で。
$ which influx
/usr/local/bin/influx
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
$ influx write \
--bucket my_first_bucket_by_ui \
--precision s "
home,room=リビング temp=22.2,hum=36.0,co=0i 1724583600
home,room=キッチン temp=22.4,hum=36.0,co=0i 1724583600
home,room=リビング temp=22.2,hum=35.9,co=0i 1724587200
home,room=キッチン temp=22.5,hum=36.0,co=0i 1724587200
home,room=リビング temp=22.4,hum=36.0,co=0i 1724590800
home,room=キッチン temp=22.8,hum=36.5,co=1i 1724590800
"
root@5dc02695ebff:/# echo $?
0
次にHTTP API。curlを使う。事前に確認しておく必要があるのは以下。
- InfluxDBのOrganization名
- APIキー
APIキーは上の方で作成したものを使う。Organization名はそもそも作った記憶がないので、今回だとデフォルトのものになる。以下で確認する。
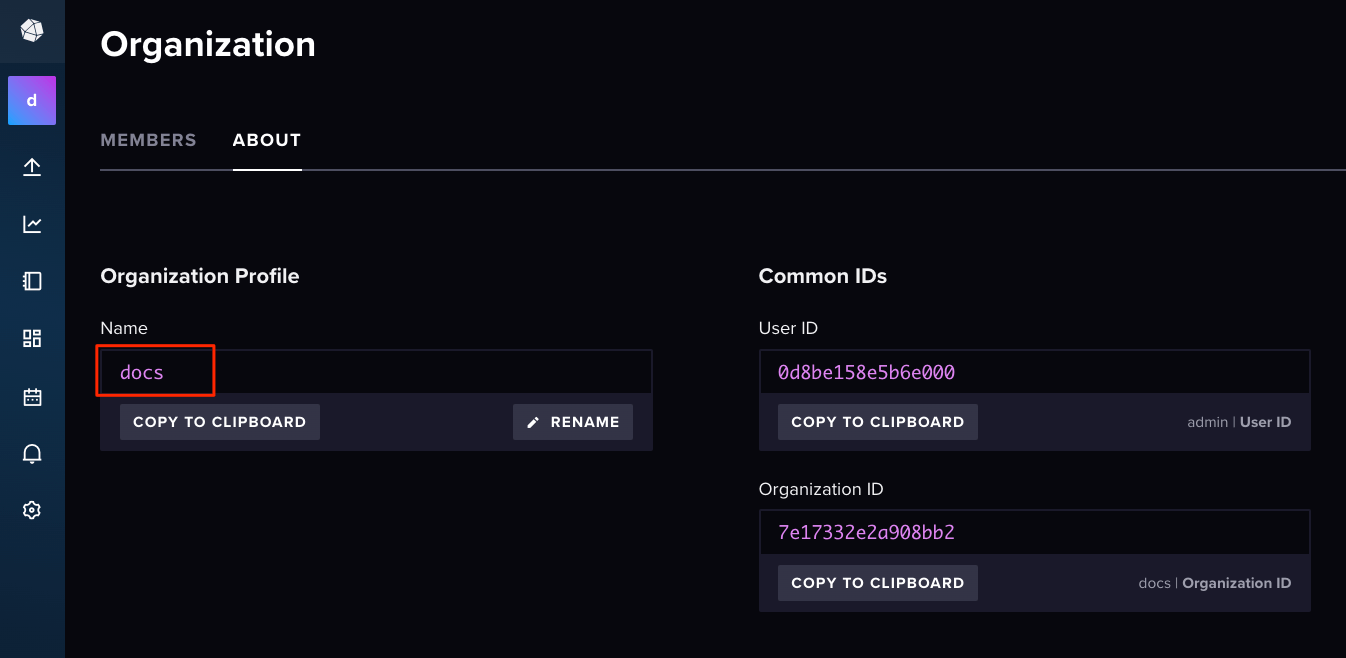
WebUIから"About"を開く。
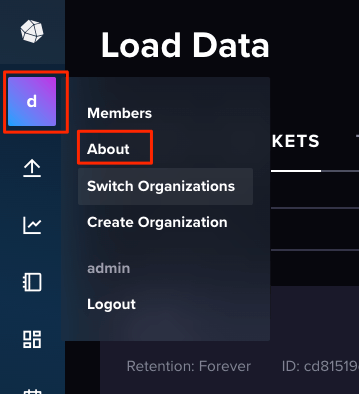
デフォルトはdocsというOrganization名になっている様子。
ではcurlでリクエスト送信。
$ export INFLUX_HOST=http://localhost:8086
$ export INFLUX_ORG=docs
$ export INFLUX_TOKEN=XXXXXXXXXX
$ export INFLUX_BUCKET=my_first_bucket_by_ui
$ curl -X POST "$INFLUX_HOST/api/v2/write?org=$INFLUX_ORG&bucket=$INFLUX_BUCKET&precision=s" \
--header "Authorization: Token $INFLUX_TOKEN" \
--header "Content-Type: text/plain; charset=utf-8" \
--header "Accept: application/json" \
--data-binary "
home,room=リビング temp=22.3,hum=36.1,co=0i 1724594400
home,room=キッチン temp=22.8,hum=36.3,co=1i 1724594400
home,room=リビング temp=22.3,hum=36.1,co=1i 1724598000
home,room=キッチン temp=22.7,hum=36.2,co=3i 1724598000
home,room=リビング temp=22.4,hum=36.0,co=4i 1724601600
home,room=キッチン temp=22.4,hum=36.0,co=7i 1724601600
"
$ echo $?
0
最後にPython SDKで。
$ pip install influxdb-client
いろいろ書き方はあるようだけども、今回はデータをラインプロトコル文字列で定義してまるっと渡すようにしてみた。
from influxdb_client import InfluxDBClient
bucket = "my_first_bucket_by_ui"
org = "docs"
token = XXXXXXXXXX"
url="http://localhost:8086"
records = """
home,room=リビング temp=22.6,hum=35.9,co=5i 1724605200
home,room=キッチン temp=22.7,hum=36.0,co=9i 1724605200
home,room=リビング temp=22.8,hum=36.2,co=9i 1724608800
home,room=キッチン temp=23.3,hum=36.9,co=18i 1724608800
home,room=リビング temp=22.5,hum=36.3,co=14i 1724612400
home,room=キッチン temp=23.1,hum=36.6,co=22i 1724612400
"""
with InfluxDBClient(url, token) as client:
with client.write_api() as writer:
writer.write(bucket=bucket, org=org, record=records, write_precision='s')
重要なのはWebUIで追加するときと同様にwrite_precisionで時刻精度を指定すること。ここをきちんと指定しないと正しくタイムスタンプが認識されない。例えば上の例でwrite_precisionを指定しないと1970-01-01T00:00:01.724Zになってしまう。ここでちょっとハマった。
いろいろな書き込みの仕方は以下参照。
ただしどこにもwrite_precisionのことは書いてなくて、以下で見つけた。
InfluxDBでは、タイムスタンプなしでデータを送信すると受信したタイミングのタイムスタンプが付与されるようで、おそらくそれが一般的な使い方なのだろう。よって、上記のようなタイムスタンプを指定して複数データを登録するってのはどっちかというとレアケースなのかなと感じる(なのでこのあたりの記載がないのではないかと)
あとはタイムスタンプの精度によってフォーマットが違うというところもあるんだろうとは思うが、CLIやHTTP APIではきちんと指定されているので、ドキュメント的にちょっともやるところではある。
データのクエリ
次は登録したデータを参照してみる。データの参照には以下が使える。
- InfluxDB ユーザインタフェース
- InfluxDB HTTP API
- influx CLI
- InfluxDBクライアントライブラリ
- Chronograf
- Grafana
InfluxDBでデータを検索するための言語は2つある。
-
Flux
- InfluxDBやその他のデータソースからデータを照会し処理するために設計された関数型スクリプト言語
-
InfluxQL
- InfluxDBから時系列データをクエリするための、SQLに似たクエリ言語
- InfluxDB 0.X/1.Xの時系列データをクエリするために設計されている
- 現行バージョン(v2.7)で使うには「データベースと保持ポリシー (DBRP) 」とのマッピング設定が別途必要になる。
Fluxのほうが新しいように思える。ということで今回はFluxを使う。
Web UI
前提として
- Web UIでは、クエリ言語を使わないGUIによるクエリも可能。
- Web UIでクエリ言語を使う場合、対応しているのはFluxのみで、InfluxQLは使用できない。
まずはGUIで。Data Explorerのアイコンをクリック。
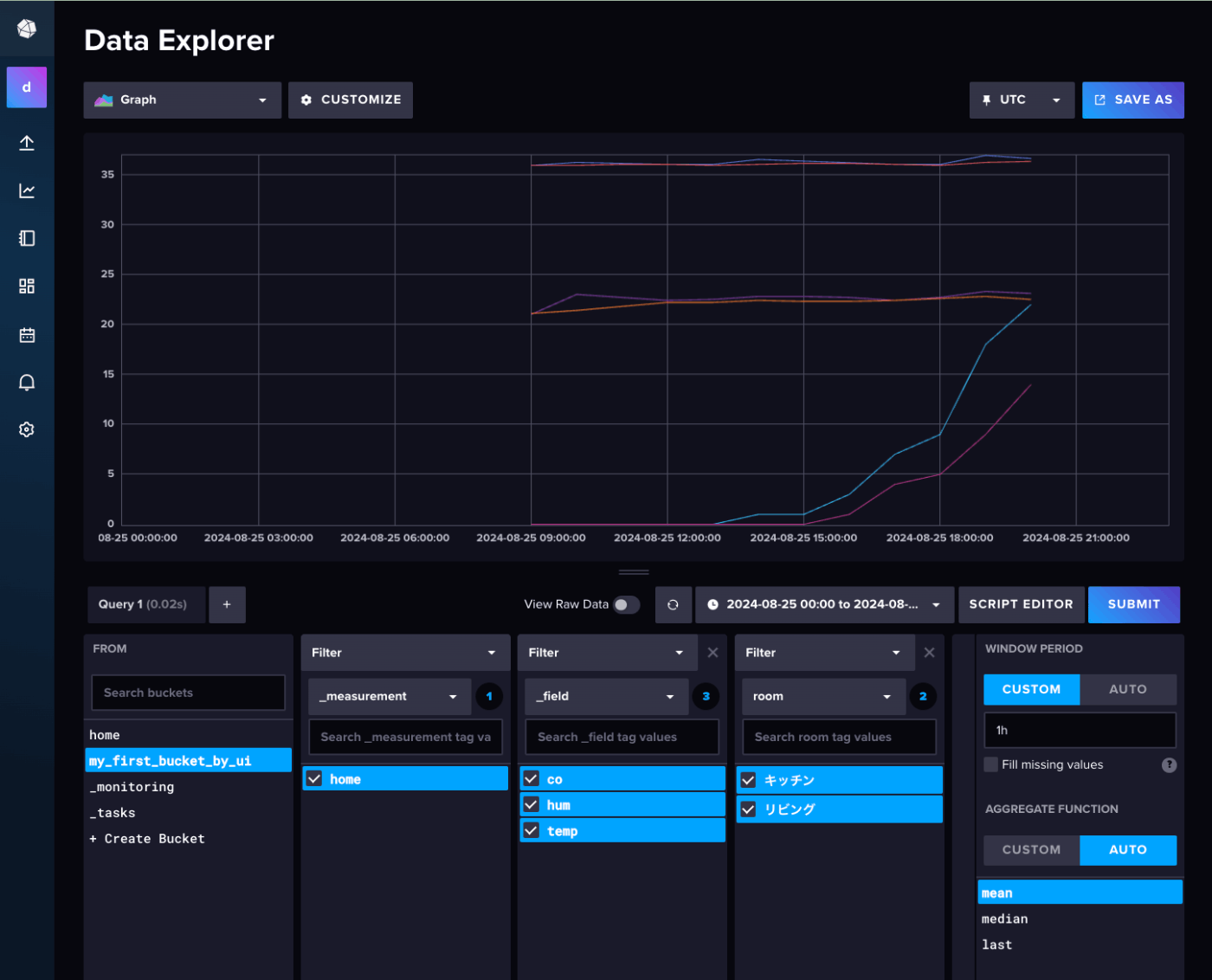
Data Explorerの画面が表示されるので、時間や条件でフィルタするとグラフが表示される。この機能をクエリビルダーというらしい。
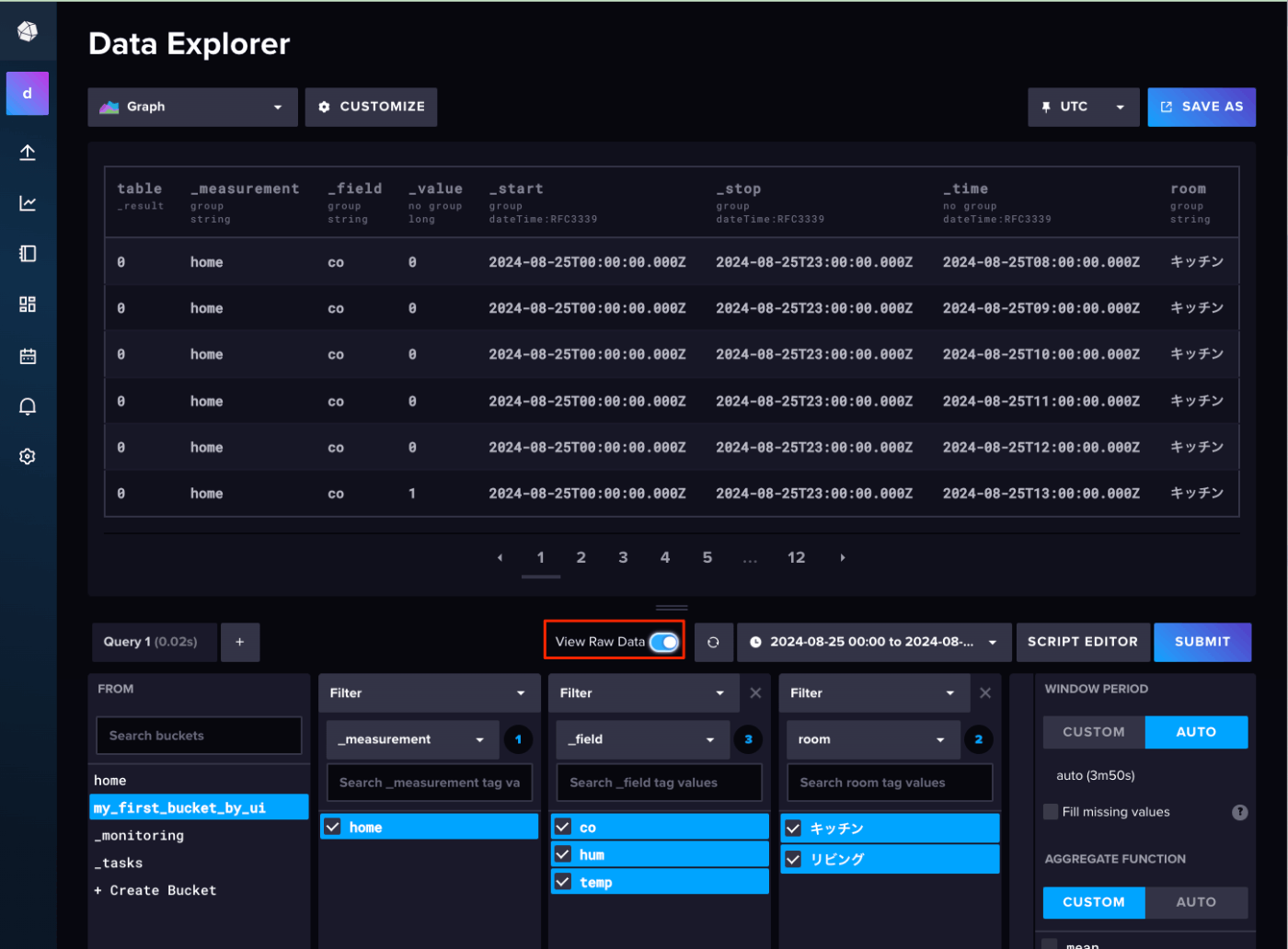
"View Raw Data"を有効にすると個々のデータが確認できる。
クエリビルダー、GUIでできるのはいいのだけども、ちょっとUIにクセがあるように個人的には感じた。
- 時間の指定で、UTC/ローカルを指定し忘れがち
- Window PeriodとAggregate Functionがデフォルトで自動で設定されるが、単純に実データを見たい場合にはちょっと余計
ということでFluxを使ってクエリしてみる。スクリプトエディタに切り替え。
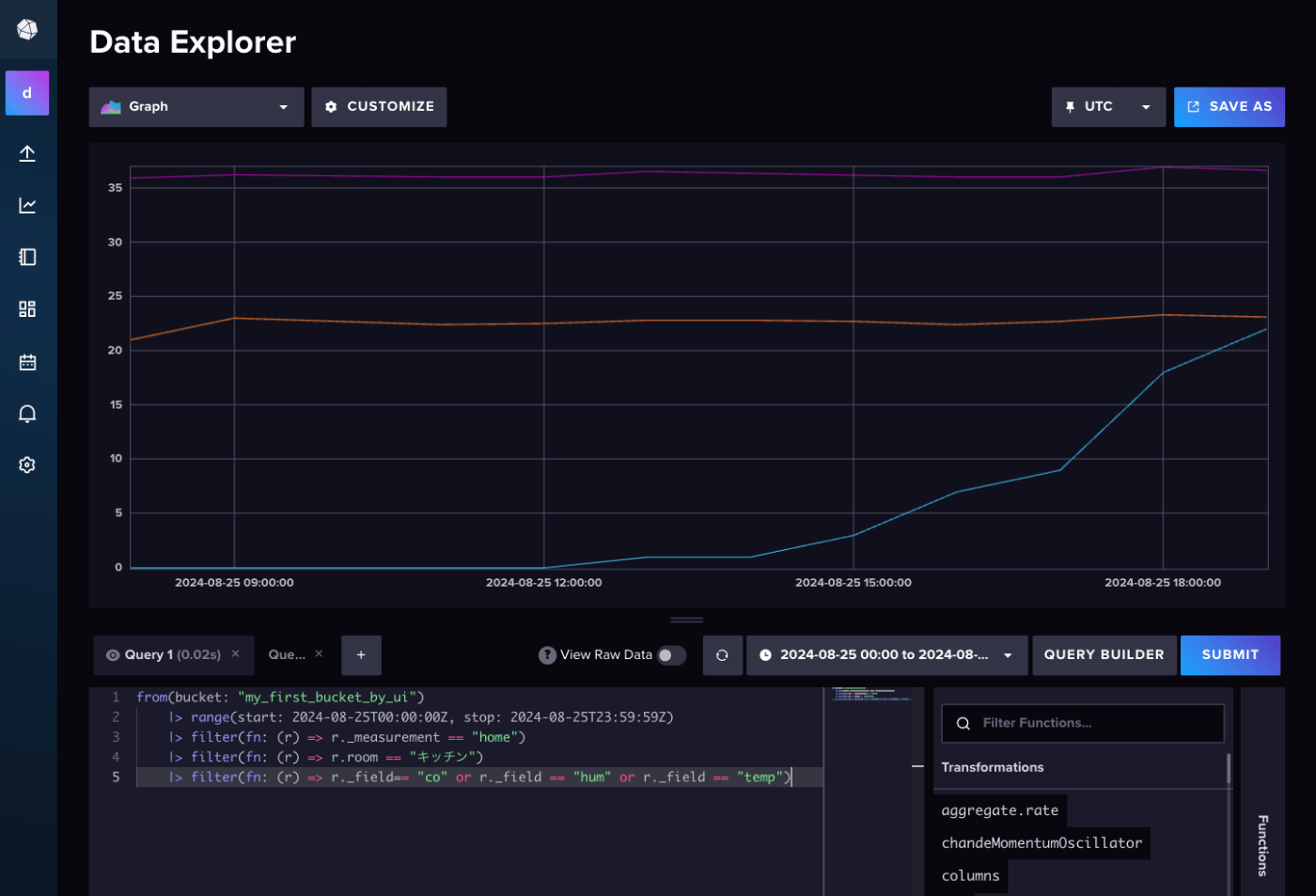
以下をコピペして"SUBMIT"(クエリビルダ実行時のクエリが残っている場合は上書き)
from(bucket: "my_first_bucket_by_ui")
|> range(start: 2024-08-25T00:00:00Z, stop: 2024-08-25T23:59:59Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "キッチン")
|> filter(fn: (r) => r._field== "co" or r._field == "hum" or r._field == "temp")

Fluxは以下の3つの関数で書けるらしい。
-
from()- バケットを指定
-
range()- 時間のスパンを指定。
- Fluxのクエリは特定の時間を指定する必要がある
-
filter()- 列の値に基づいてデータをフィルタする関数を定義する
- 各行は
rで、その各列はrのプロパティとして参照する。 - 複数のフィルタを適用できる
-
|>- シェルのパイプと同じような使い方
Influx CLI
Fluxの場合は上で書いたFluxクエリをそのまま渡すだけ。
$ influx query '
from(bucket: "my_first_bucket_by_ui")
|> range(start: 2024-08-25T00:00:00Z, stop: 2024-08-25T23:59:59Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "リビング")
|> filter(fn: (r) => r._field== "co" or r._field == "hum" or r._field == "temp")
'
Result: _result
Table: keys: [_start, _stop, _field, _measurement, room]
_start:time _stop:time _field:string _measurement:string room:string _time:time _value:int
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ------------------------------ --------------------------
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T08:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T09:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T10:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T11:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T12:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T13:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T14:00:00.000000000Z 0
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T15:00:00.000000000Z 1
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T16:00:00.000000000Z 4
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T17:00:00.000000000Z 5
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T18:00:00.000000000Z 9
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z co home リビング 2024-08-25T19:00:00.000000000Z 14
Table: keys: [_start, _stop, _field, _measurement, room]
_start:time _stop:time _field:string _measurement:string room:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T08:00:00.000000000Z 35.9
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T09:00:00.000000000Z 35.9
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T10:00:00.000000000Z 36
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T11:00:00.000000000Z 36
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T12:00:00.000000000Z 35.9
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T13:00:00.000000000Z 36
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T14:00:00.000000000Z 36.1
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T15:00:00.000000000Z 36.1
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T16:00:00.000000000Z 36
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T17:00:00.000000000Z 35.9
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T18:00:00.000000000Z 36.2
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z hum home リビング 2024-08-25T19:00:00.000000000Z 36.3
Table: keys: [_start, _stop, _field, _measurement, room]
_start:time _stop:time _field:string _measurement:string room:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T08:00:00.000000000Z 21.1
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T09:00:00.000000000Z 21.4
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T10:00:00.000000000Z 21.8
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T11:00:00.000000000Z 22.2
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T12:00:00.000000000Z 22.2
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T13:00:00.000000000Z 22.4
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T14:00:00.000000000Z 22.3
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T15:00:00.000000000Z 22.3
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T16:00:00.000000000Z 22.4
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T17:00:00.000000000Z 22.6
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T18:00:00.000000000Z 22.8
2024-08-25T00:00:00.000000000Z 2024-08-25T23:59:59.000000000Z temp home リビング 2024-08-25T19:00:00.000000000Z 22.5
--rawをつけるとCSVっぽく出力される
$ influx query '
from(bucket: "my_first_bucket_by_ui")
|> range(start: 2024-08-25T00:00:00Z, stop: 2024-08-25T23:59:59Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "リビング")
|> filter(fn: (r) => r._field== "co")
' --raw
#group,false,false,true,true,false,false,true,true,true
#datatype,string,long,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,long,string,string,string
#default,_result,,,,,,,,
,result,table,_start,_stop,_time,_value,_field,_measurement,room
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T08:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T09:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T10:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T11:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T12:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T13:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T14:00:00Z,0,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T15:00:00Z,1,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T16:00:00Z,4,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T17:00:00Z,5,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T18:00:00Z,9,co,home,リビング
,,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T19:00:00Z,14,co,home,リビング
HTTP API
こちらも単純にクエリ用のエンドポイントにFluxクエリを投げるだけ。
$ export INFLUX_HOST=http://localhost:8086
$ export INFLUX_ORG=docs
$ export INFLUX_TOKEN=XXXXXXXXXX
$ export INFLUX_BUCKET=my_first_bucket_by_ui
$ curl --request POST \
"$INFLUX_HOST/api/v2/query?org=$INFLUX_ORG&bucket=$INFLUX_BUCKET" \
--header "Authorization: Token $INFLUX_TOKEN" \
--header "Content-Type: application/vnd.flux" \
--header "Accept: application/csv" \
--data 'from(bucket: "my_first_bucket_by_ui")
|> range(start: 2024-08-25T00:00:00Z, stop: 2024-08-25T23:59:59Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "リビング")
|> filter(fn: (r) => r._field== "co")
'
,result,table,_start,_stop,_time,_value,_field,_measurement,room
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T08:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T09:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T10:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T11:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T12:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T13:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T14:00:00Z,0,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T15:00:00Z,1,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T16:00:00Z,4,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T17:00:00Z,5,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T18:00:00Z,9,co,home,リビング
,_result,0,2024-08-25T00:00:00Z,2024-08-25T23:59:59Z,2024-08-25T19:00:00Z,14,co,home,リビング
Python SDK
from influxdb_client import InfluxDBClient
from influxdb_client.client.write_api import SYNCHRONOUS
bucket = "my_first_bucket_by_ui"
org = "docs"
token = XXXXXXXXXX"
url="http://localhost:8086"
client = InfluxDBClient(url=url, token=token, org=org)
query_api = client.query_api()
query = f"""
from(bucket: "{bucket}")
|> range(start: 2024-08-25T00:00:00Z, stop: 2024-08-25T23:59:59Z)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "リビング")
|> filter(fn: (r) => r._field== "co")
"""
tables = query_api.query(query)
for table in tables:
print(table)
for row in table.records:
print(row.values)
FluxTable() columns: 9, records: 12
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 8, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 9, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 10, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 11, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 12, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 13, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 14, 0, tzinfo=datetime.timezone.utc), '_value': 0, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 15, 0, tzinfo=datetime.timezone.utc), '_value': 1, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 16, 0, tzinfo=datetime.timezone.utc), '_value': 4, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 17, 0, tzinfo=datetime.timezone.utc), '_value': 5, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 18, 0, tzinfo=datetime.timezone.utc), '_value': 9, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
{'result': '_result', 'table': 0, '_start': datetime.datetime(2024, 8, 25, 0, 0, tzinfo=datetime.timezone.utc), '_stop': datetime.datetime(2024, 8, 25, 23, 59, 59, tzinfo=datetime.timezone.utc), '_time': datetime.datetime(2024, 8, 25, 19, 0, tzinfo=datetime.timezone.utc), '_value': 14, '_field': 'co', '_measurement': 'home', 'room': 'リビング'}
データの処理
Fluxクエリでは上記以外にもデータの処理(mapとかgroupなど)に便利な関数が用意されているが、ここは割愛。
データの可視化
InfluxDBのWebUI上でも可視化・ダッシュボードの作成ができる。
自分はこの部分をGrafanaでやろうと思うので、割愛。