データから最適化なRAGの設定を探してくれる「RAGBuilder」を試す
ここで見つけた
GitHubレポジトリ
RAGBuilder
RagBuilderは、あなたのデータに最適化したProduction-Readyな検索拡張生成(RAG)設定を自動的に作成するツールキットである。RagBuilderは、さまざまなRAGパラメータ(例:チャンキング戦略:意味、文字など、チャンクサイズ:1000、2000など)のハイパーパラメータ調整を行い、テストデータセットに対してこれらの構成を評価することで、貴社のデータに最適なパフォーマンスを発揮する設定を特定する。さらに、RagBuilderには、さまざまなデータセットで優れたパフォーマンスを発揮した最先端のRAGテンプレートがいくつかあらかじめ用意されている。データを入力するだけで、RagBuilderが数分で実稼働環境向けのRAG設定を生成する。
機能
- ハイパーパラメータのチューニング: ベイズ最適化を使用して、最適なRAG構成(チャンキング戦略、チャンキングサイズ、埋め込みモデル、検索タイプなどの詳細なパラメータの組み合わせ)を効率的に特定する
- 事前定義済みのRAGテンプレート: さまざまなデータセットで優れたパフォーマンスを発揮した最先端のテンプレートを使用する
- 評価用データセットオプション: 合成テストデータセットを生成するか、独自のデータセットを提供するかを指定する
- 自動再利用: 適用可能な場合は、以前に生成された合成テストデータを自動的に再利用する。
- 使いやすいインターフェース: 直感的なUIで、RAG構成の設定、構成、レビューを行う。
デモ動画
単にRAGを構築する、ということではなくて、データに合わせて最適化なRAG設定を探してくれる、っていうのがポイントっぽく思えるが、どういう風にやるのだろう?
興味深いので試してみる。
インストール方法は
- インストールスクリプト(Win/Mac)
- Docker(docker-compose.yamlもある)
が用意されている。自分はLAN内のUbuntuサーバでDockerを使ってやってみる。
レポジトリクローン
$ git clone https://github.com/KruxAI/ragbuilder && cd ragbuilder
.envを雛形からコピー
$ cp .env-Sample .env
.envの中身はこんな感じ。
# Description: Environment variables for the project. Rename to .env file for use
OPENAI_API_KEY=XXXXXXXXX
MISTRAL_API_KEY=XXXXXXXXX
MIXPANEL_TOKEN=XXXXXXXXX
HUGGINGFACEHUB_API_TOKEN=XXXXXXXXX
COHERE_API_KEY=XXXXXXXXX
JINA_API_KEY=XXXXXXXXX
ENABLE_ANALYTICS=True
SINGLESTOREDB_URL=userid:password@host:port/dbname
PINECONE_API_KEY=XXXXXXXXX
GROQ_API_KEY=XXXXXXXXX
AZURE_OPENAI_API_KEY=XXXXXXXXX
AZURE_OPENAI_ENDPOINT=https://XXXXXXXXX.openai.azure.com/
OPENAI_API_VERSION=2024-02-01
GOOGLE_API_KEY=AIzaSyDN2-XXXXXXXXX
GOOGLE_CLOUD_PROJECT=projectid
GOOGLE_APPLICATION_CREDENTIALS=credentials.json # must be placed in the folder where docker is run
PGVECTOR_CONNECTION_STRING=postgresql+psycopg://langchain:langchain@localhost:6024/langchain
MILVUS_CONNECTION_STRING=http://localhost:19530 # ./milvus_demo.db
OLLAMA_BASE_URL=http://localhost:11434 #http://host.docker.internal:11434
RUN_CONFIG_TIMEOUT=240
RUN_CONFIG_MAX_WORKERS=16
RUN_CONFIG_MAX_WAIT=180
RUN_CONFIG_MAX_RETRIES=10
RUN_CONFIG_IS_ASYNC="true"
NEO4J_URI=bolt://localhost:7687## use bolt://neo4j:7687 if using docker for ragbuilder
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=ragbuilder
NEO4J_LOAD=true # set to false if graph is already loaded and you don't want to reload
SAMPLING_RATIO=0.10 # Sampling ratio: If set to 0.10, ~10% of original data will be sampled, and used for RAG building.
SAMPLING_SIZE_THRESHOLD=750_000 # If your source data is larger than this threshold, RAGBuilder will default to sampling.
SAMPLING_FILE_SIZE_THRESHOLD=500_000 # When sampling directories, individual files that are larger this threshold, will be sampled at file level.
レポジトリをみてみるとどうやらdocker-compose.yamlが用意されていて、Neo4jもセットアップされるようになっている模様。
ということで、OpenAI APIキーとdocker-compose.yamlに合わせて、.envを以下のように設定した。
OPENAI_API_KEY=sk-XXXXXXXXXXXX
ENABLE_ANALYTICS=True
NEO4J_URI=bolt://neo4j:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=ragbuilder
NEO4J_LOAD=true
SAMPLING_RATIO=0.10
SAMPLING_SIZE_THRESHOLD=750_000
SAMPLING_FILE_SIZE_THRESHOLD=500_000
あと、issueにも上がっているが、どうやらRAGBuilderのDockerイメージでgitが足りない模様。以下の1行を.envに追加する。
GIT_PYTHON_REFRESH=quiet
docker composeで起動する。初回は7GBぐらいダウンロードされるので結構重い。
$ docker compose up
(snip)
neo4j-1 | 2024-10-07 08:36:26.321+0000 INFO ======== Neo4j 5.22.0 ========
ragbuilder-1 | [INFO] 2024-10-07 08:36:29 - common.py - INFO: Started server process [1]
ragbuilder-1 | [INFO] 2024-10-07 08:36:29 - common.py - INFO: Waiting for application startup.
ragbuilder-1 | [INFO] 2024-10-07 08:36:30 - common.py - INFO: Application startup complete.
ragbuilder-1 | [INFO] 2024-10-07 08:36:30 - common.py - INFO: Uvicorn running on http://0.0.0.0:8005 (Press CTRL+C to quit)
(snip)
neo4j-1 | 2024-10-07 08:36:31.710+0000 INFO Bolt enabled on 0.0.0.0:7687.
neo4j-1 | 2024-10-07 08:36:31.940+0000 INFO HTTP enabled on 0.0.0.0:7474.
(snip)
上記のように表示されれば起動している。ポートは
- RAGBuilderのGUI: 55003(中で8005にフォワードされている)
- Neo4jのGUI: 7474
- Neo4jのAPI: 7687
となっているので、55003番ポートでアクセスすると、RAGBuilderの管理画面が表示される。
"NEW PROJECT"をクリック
プロジェクトの説明とRAGのソースで使う文書の指定を行う。

- 説明は何でもよいが、どうも英語じゃないとダメそう?(ここが原因か?は明確にはわからないが、日本語の場合にこの後のプロセスでコケて、英語だと問題なく進めれた)
- ソースデータは、ディレクトリ/ファイルを指定するか、URLを指定する。
- ディレクトリ/ファイルの場合は、docker-compose.yamlのあるディレクトリにディレクトリなりファイルなりを置いておく(ここがそのままコンテナ側から見るとユーザのホームディレクトリになる。)
- URLの場合はそのままURLを入力
今回は以下をURLで指定することにする。
上記を入力するとさらに設定項目が増える。

ここで設定できる中身はこんな感じ。

右はまあ前処理だよね、左は「合成テストデータを生成する場合は、一貫性を保つため、サンプルデータセットに基づいて生成される」とあるのだが、ちょっと今の時点だと意味がわからない。
あと、更に下にオプションがある。

ドキュメントによると、
- 定義済みのRAGテンプレートを使用する - 選択すると、さまざまなデータセットや関連するユースケースで優れたパフォーマンスを示した定義済みのRAG構成テンプレートが含まれる。これらのテンプレートは、あなたのデータに対して評価され、各定義済み構成のパフォーマンス指標が提供される。
- カスタムRAG構成の作成 - 選択すると、チャンキング戦略、チャンキングサイズ、埋め込みモデル、取得タイプなどの詳細なパラメータに基づいて複数のRAG構成が生成される。このオプションでは、ベイズ最適化オプションを選択して、データに最適に近いRAG構成を効率的に特定することを推奨する。これについては、後ほど詳しく説明する。
とある。定義済みのものを使う、と、カスタムなものを使う、ってことなんだろうと思うけど、二者択一ではないのだよね・・・とりあえずデモの動画を見るとカスタムだけでやっているようなので、それにあわせてみる。最終的な設定はこんな感じで進めた。

カスタムを選択した場合は用意されているハイパーパラメータを個別に設定する画面になる。

ここの選択肢がとても多いのだけど、一番下にあるAdvanced Optimization Settingsのところをみてみると

どうやら、選択したハイパーパラメータの組み合わせを評価して、最も最適な組み合わせを抽出するということらしく、その際に、
- ベイズ最適化を使って、効率的に最適な組み合わせを抽出する
- すべての組み合わせを網羅的に評価して抽出する
の2種類を選べるということらしい。なるほど・・・・。
今回はOpenAIの設定しか入れていないし、多数の項目を含めるようにしても多分よくわからない気がしたので、設定項目を絞り込んで、ベイズ最適化の方を選択してみることにする。あと、"Number of Runs"は評価を行うイテレーションの回数っぽいのでこちらも少なめにしてみた。

次に評価の設定。ここでは、評価に使うフレームワークやモデルなどの設定に加えて、評価用データセットの指定ができる。評価用フレームワークは現時点ではRAGASのみとなっているが、DeepEval/ARES/TruLensなどにも対応する予定みたい。
また、評価用のデータセットは事前に用意していない場合はどうやらソースデータから作成もできる模様で、Advanced Settingsがおそらく評価データの「生成」に使用するモデルの設定だと思われる。

最後に設定の最終確認が出るので"CONFIRM"で進める。

こんな感じで処理が始まる。まずソースドキュメントのEmbeddingが生成され・・・

評価テスト用のデータが生成され・・・
エラーw
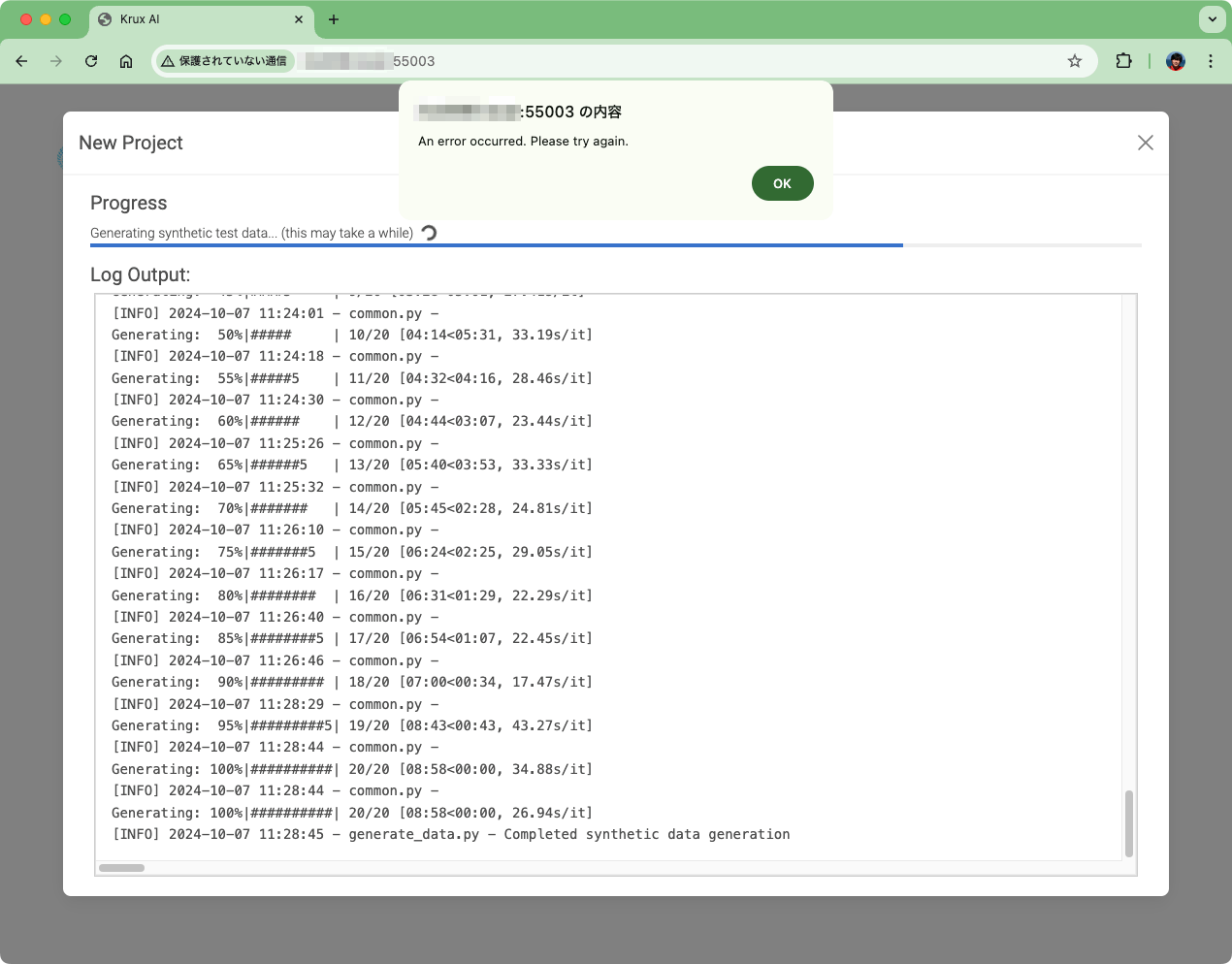
ただ、停止はしないみたいで、一応評価テストは行われているように見える。ちょいちょいPyTorchとかColBertのwarningsも見えるけど、そういうパラメータは選んだつもりはないのだけども。
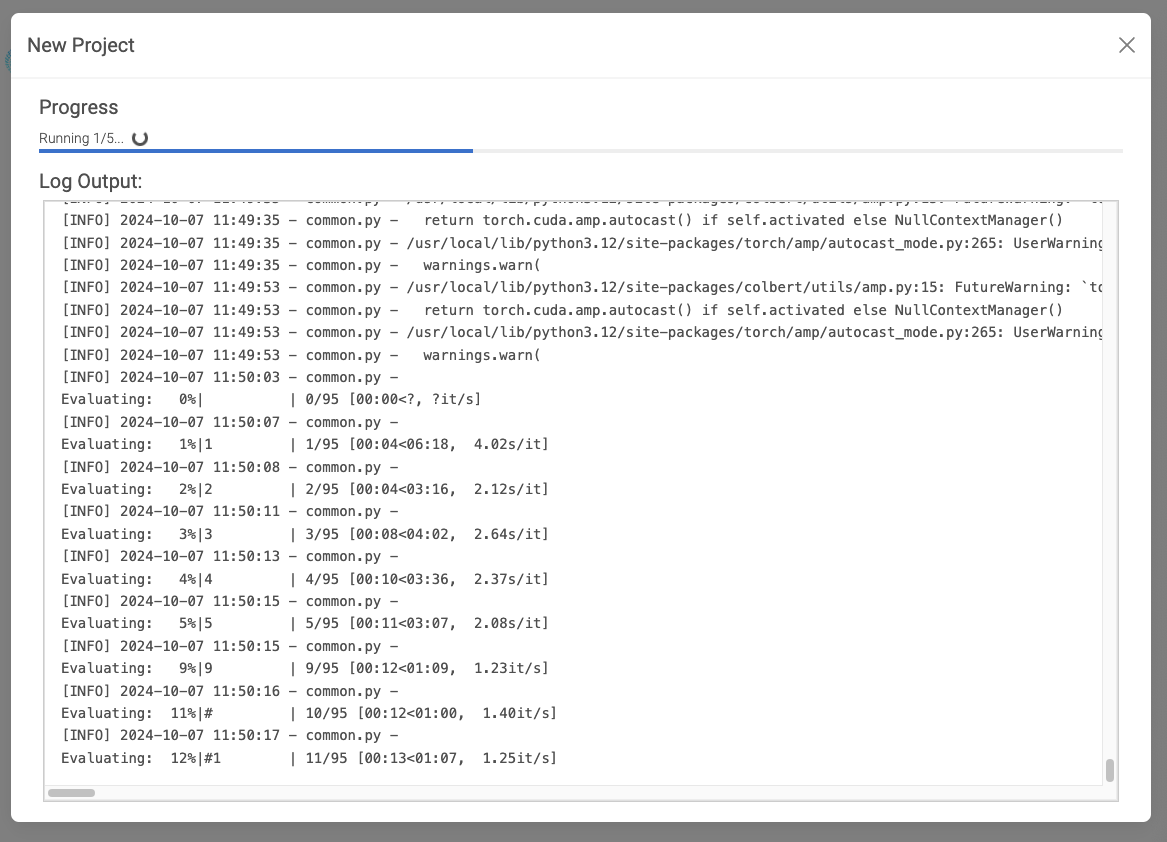
評価テストのここのイテレーションは結果が見れるみたいだけど、ここで結果に移動しちゃうとこの画面が見れなくなるようなので、一応最後まで待ってみる。
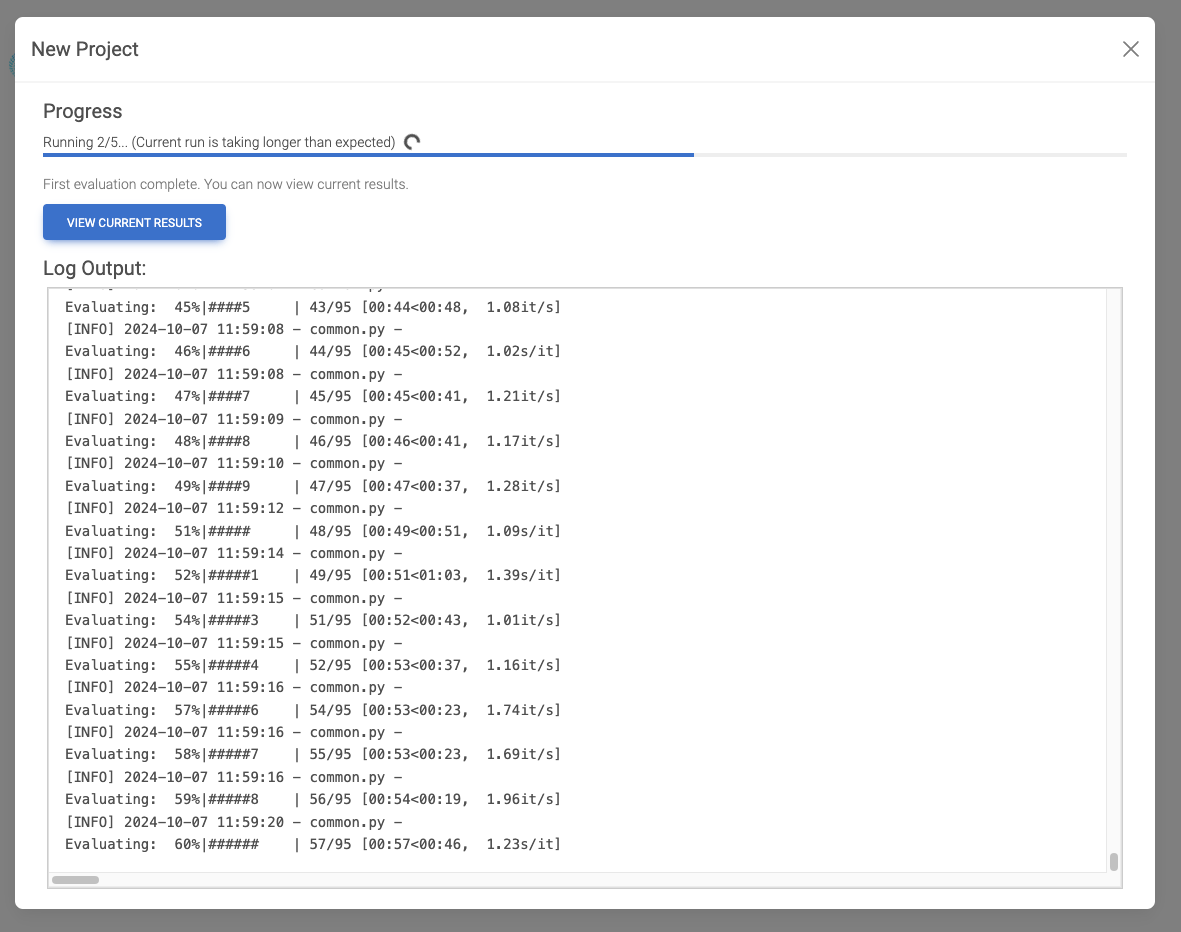
で、一応一通り終わったみたいだけど、まだRunningのまま・・・
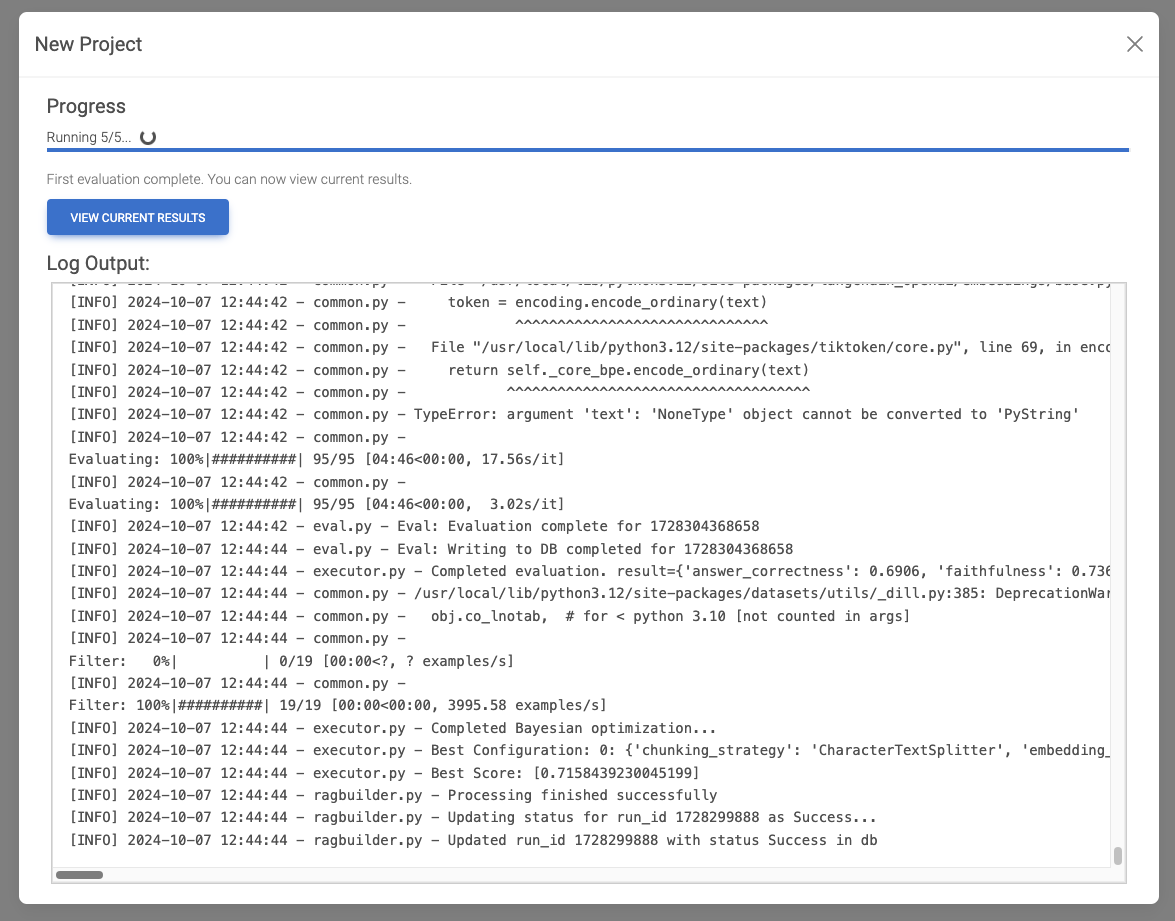
メッセージを見る限りはこれがベストの設定っぽい。colbertRetrieverとか有効にした記憶がないんだけどね。。。
[INFO] 2024-10-07 12:44:44 - executor.py - Best Configuration: 0: {'chunking_strategy': 'CharacterTextSplitter', 'embedding_model': 'OpenAI:text-embedding-3-large', 'search_kwargs': '10', 'chunk_size': 1700, 'n_retrievers': 2, 'retriever_0': 'parentDocLargeChunk', 'retriever_1': 'colbertRetriever'}:
[INFO] 2024-10-07 12:44:44 - executor.py - Best Score: [0.7158439230045199]
10分ぐらい待ってみたけど変わる気配がないので、この画面が閉じた。
ダッシュボードに戻ってリロードしてみると、結果が表示されている。

右の「View Results」をクリックしてみる。
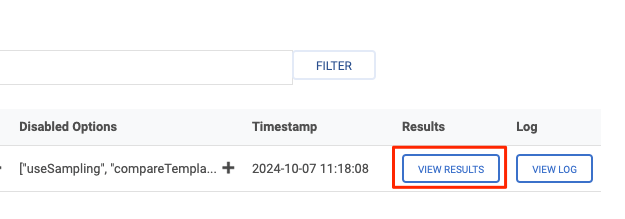
こんな感じでイテレーションごとの結果が表示されている模様。

- 各テストの設定
- Answer CorrectnessやContext Precision/Recallなどの評価メトリクスの数値
- トークン量とコスト
何かが表示されている。
ただ、イテレーションは5回にしていたはずだけど、4回分しか表示されていない、もしかすると途中エラーでコケていたのかな?
なお、"RAG Config"の"+"をクリックすると、設定が見れる。
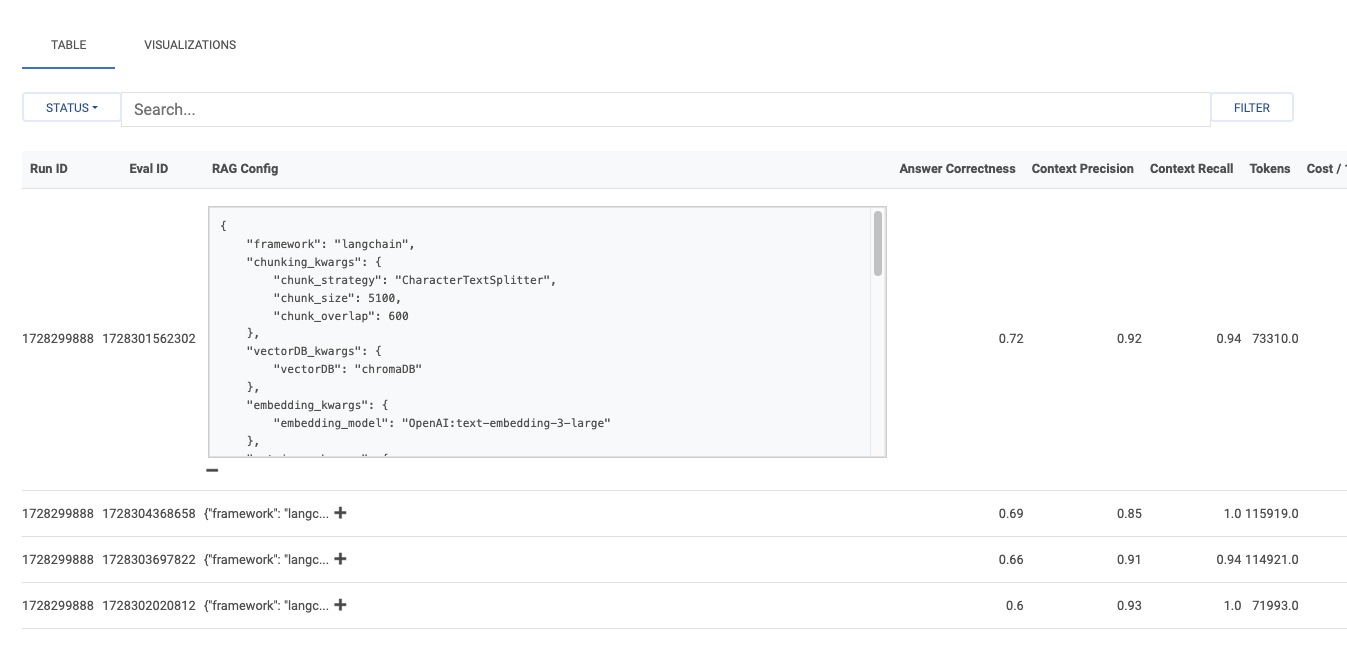
"VIEW DETAILS"をクリックしてみる。
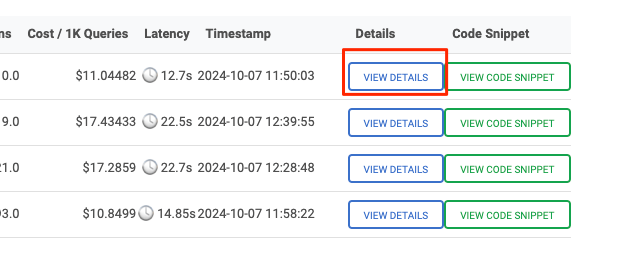
評価テストの実際の回答などが表示される。
元の画面に戻って"CODE SNIPPET"をクリックしてみる。
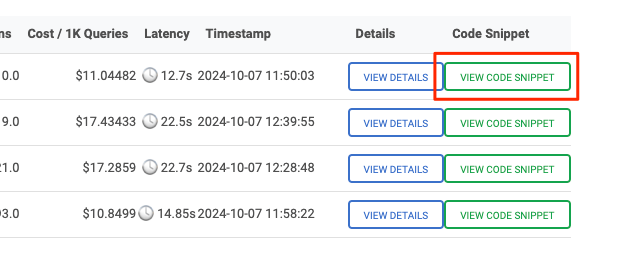
評価テストで使用されたパラメータに基づいたコードが生成される。あー、これはいいかもね。
上の"Visualization"タブをクリックすると、今回の評価テストの結果を可視化してくれる。

参考までに、今回の評価テストの結果を少しまとめておく。
| イテレーション | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| フレームワーク | LangChain | LangChain | LangChain | LangChain |
| チャンク分割戦略 | CharacterTextSplitter(サイズ5100、オーバーラップ600) | MarkdownHeaderTextSplitter | HTMLHeaderTextSplitter | CharacterTextSplitter(サイズ2000、オーバーラップ200) |
| ベクトルDB | ChromaDB | ChromaDB | ChromaDB | ChromaDB |
| Embeddingモデル | OpenAI:text-embedding-3-large | OpenAI:text-embedding-ada-002 | OpenAI:text-embedding-3-large | OpenAI:text-embedding-ada-002 |
| レトリーバ1 | vectorSimilarity(k:10) | vectorSimilarity(k:20) | vectorSimilarity(k:10) | vectorSimilarity(k:20) |
| レトリーバ2 | bm25Retriever(k:10) | bm25Retriever(k:20) | bm25Retriever(k:10) | bm25Retriever(k:20) |
| レトリーバ3 | parentDocLargeChunk(k:10) | - | - | parentDocFullDoc(l:20) |
| レトリーバ4 | colbertRetriever(k:10) | - | - | - |
| LLMモデル | OpenAI:gpt-4o-mini | OpenAI:gpt-4o-mini | OpenAI:gpt-4o-mini | OpenAI:gpt-4o-mini |
| Answer Correctness | 0.72 | 0.69 | 0.66 | 0.6 |
| Context Precision | 0.92 | 0.85 | 0.91 | 0.93 |
| Context Recall | 0.94 | 1.0 | 0.91 | 1.0 |
実際のコストだが、ここは出力されている数値よりは低くて、実際には$6ぐらいかな。ただgpt-4o-miniで$6ならば結構使っていると思う。
所感
とりあえず現時点での個人的な感想
- RAGの難しいチューニングを色々なパターンで評価して、自動的に最適な値を見つけてくれるってのは確かに便利だし、網羅的じゃないアプローチが用意されているのは良いと思う。
- そしてその結果を踏まえたコードを生成してくれるというのも嬉しい
実装と評価は別々になっているのが多いと思うのだけども、ここがセットになっているというのが新しい気がするな、実際には出力されたコードをそのまま使うということにはならないとは思うけども。
で、まあまだ出来立てというのもあるのかなぁ?色々こなれていないところが多々ある
- ドキュメントが足りない
- 設定いろいろがわからない、というか、動かしてみないとわからないという感じ
- よくわからないエラーが出るが、止めるほうがいいのか、続けるほうがいいのかがよくわからない
- ジョブの管理はCeleryあたりのジョブキューみたいな仕組みを入れたほうがいいんじゃないかな?エラーが起きるとジョブが残ってしまい(待ってたら終わるのかもしれないけど、待ってられない)、次のジョブを入れても実行されなかったりした。
- カスタムで指定していないものが使用されるのがよくわからない
- 結構コストはかかりそう。
- 今回いろいろパラメータを減らして、かつ、イテレーション回数を絞って、かつgpt-4o-miniみたいな安いモデルを使っても$6ぐらいかかった。ということはフルで回すと結構な金額に・・・
- なんとなくそれはRAGASのせいじゃないか?という勝手な推測。
- 自分は以前はよくRAGAS使っていたけど、バージョン上がるにつれてコストも上がっていく割に結果はそれほど、ってことを感じるようになったので、最近は自作の評価スクリプトをもっぱら使っている。
まあコストについては、いろいろ設定を変えながら都度評価して探していく(結果的にコストがかさむ)、最初に評価をたくさん回して(最初にコストがかさむ)最適な設定を得るか?の違いかなーという気がする。都度変えて実施するよりはマシなのかもしれない。
アプローチとしては面白いと思うので、ドキュメントなり安定性なり、そのあたりが揃ってからかなぁという風に感じた。
ところでNeo4jは何に使っているの?上の例でもChroma使ってたみたいだし、Neo4jのGUI見ても何もでてこない。。。
と思って、少し調べてみたら、たぶんこれ。
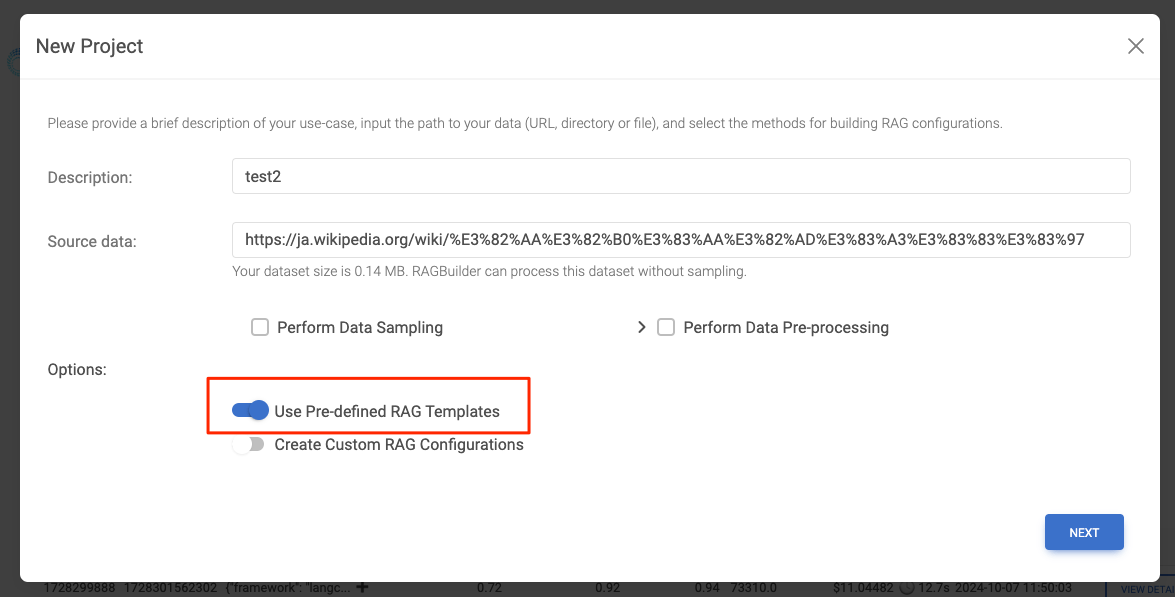
この"Use Pre-Defined RAG Templates"を設定すると、次の画面でどうやらグラフを使ったRAGが設定される模様。
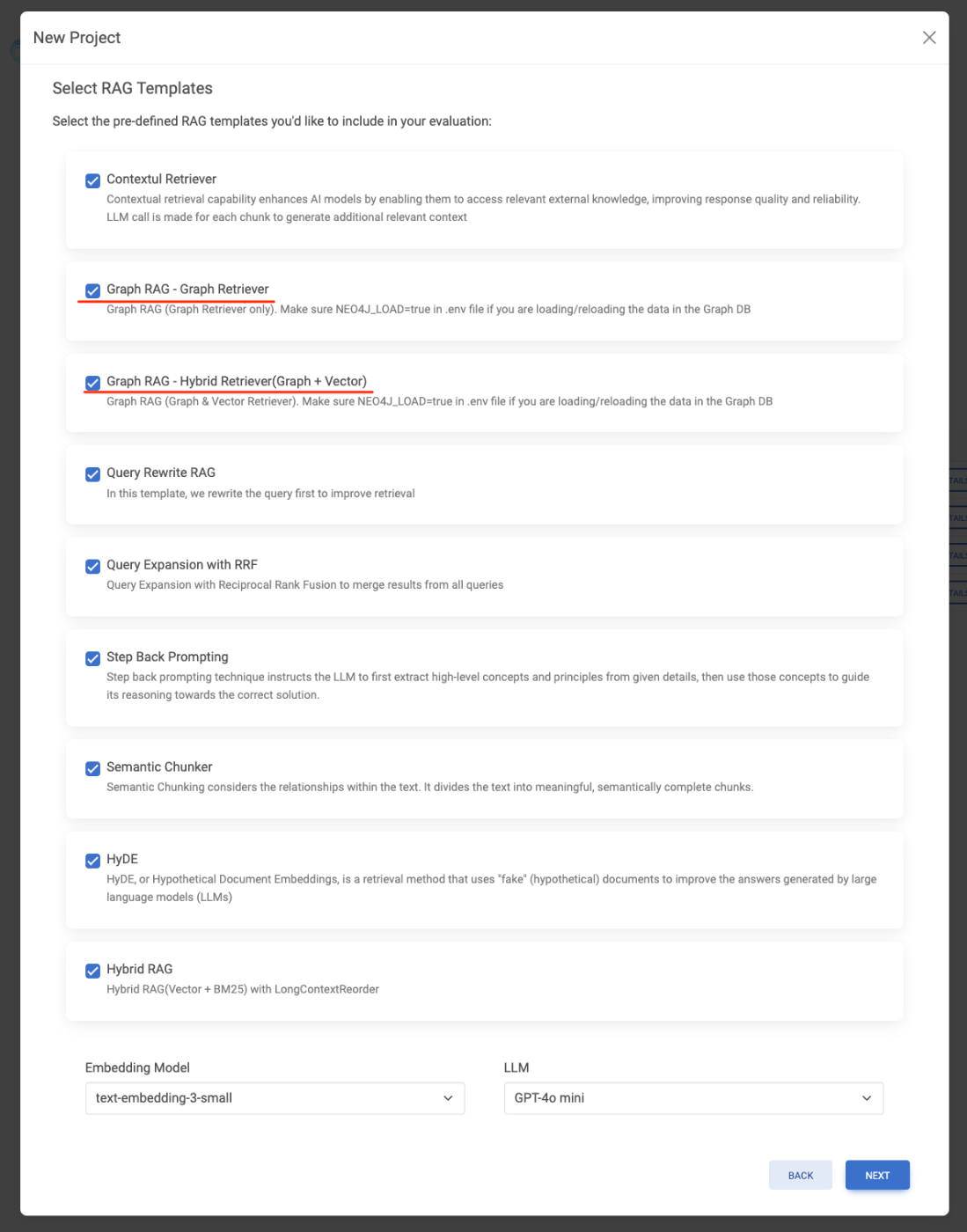
なるほどね、ここのオプション、なんで二者択一じゃないのか?と思ってたけど、選べるパラメータというか設定がそもそも違う感があるかな。