AIを使った画像編集が直感的にできる「MagicQuill」を試す
"Magic Quill" =「魔法の羽ペン」という意味らしい。
公式サイト
MagicQuill
インテリジェントなインタラクティブ画像編集システム
TL;DR
MagicQuill は、正確な画像編集を可能にするインテリジェントでインタラクティブなシステムです。
主な特徴:
- 😎 使いやすいインターフェース
- 🤖 AIによる提案
- 🎨 正確な局所編集
概要
画像編集は実用性の高いアプリケーションとして、多様なユーザーのニーズに応える必要があり、使いやすさが最優先されます。本研究では、ユーザーが迅速に創造力を形にできるよう設計された統合型画像編集システム MagicQuill を紹介します。
MagicQuill は、簡潔ながら機能的なインターフェースを備え、わずかな操作でアイデア(例: 要素の挿入、オブジェクトの削除、色の変更など)を表現できます。これらの操作は、マルチモーダル大規模言語モデル(MLLM)によってリアルタイムで監視され、プロンプトの入力を省略してユーザーの意図を予測します。最後に、強力な拡散モデル(ディフュージョンモデル)と、慎重に学習された2分岐プラグインモジュールを活用し、編集リクエストを正確に処理します。
上の動画がわかりやすいが、公式サイトにも例が多数あり、使い方のチュートリアルもあるので、そちらを見ると良い。
なお、HuggingFaceに試せるデモがある。
論文
Claude-3.5-sonnetによる落合プロンプトの結果
1. どんなもの?
MagicQuillは、直感的な操作で画像編集を可能にする対話型システムです。
このシステムは3つの主要コンポーネント - 編集プロセッサ、ペインティングアシスタント、アイデアコレクタ - で構成されています。
ユーザーは3種類のブラシストローク(追加、削除、色付け)を使って画像を編集でき、マルチモーダル大規模言語モデル(MLLM)がユーザーの意図を理解して適切なプロンプトを提案します。例えば、衣服の輪郭から新しいジャケットを生成したり、頭部のスケッチからフラワークラウンを追加したり、背景を削除したり、髪や花の色を変更したりといった多様な編集操作が可能です。
重要な特徴は、ユーザーが描いたストロークから意図を理解し、プロンプトを自動生成する点で、これによりユーザーは編集作業に集中できます。2. 先行研究と比べてどこがすごい?
従来の画像編集手法と比較して、以下の点で優れています。
まず、SmartEditなどの指示ベースの編集手法では、形状や色の正確な制御が難しく、意図しない領域まで変更されてしまう問題がありました。また、SketchEditのようなGANベースのスケッチ条件付け手法は、オープンドメインでの画像生成の品質が拡散モデルベースの手法に及びませんでした。BrushNetは、シームレスな画像インペインティングを実現しましたが、エッジと色の同時制御が困難でした。
本研究では、インペインティング分岐と制御分岐を組み合わせた二分岐アーキテクチャにより、エッジと色の両方を高精度に制御可能にしました。さらに、Draw&Guessと呼ばれる新しいタスクを導入し、MLLMを活用してユーザーの編集意図をリアルタイムで理解・予測することで、編集効率を大幅に向上させています。3. 技術や手法の肝はどこ?
本システムの技術的な核心は以下の3点です。
- 編集プロセッサ:ユーザーのブラシストロークを「エッジ条件」と「色条件」に変換し、これらを制御信号として使用します。インペインティング分岐では画像全体の一貫性を保ちながら編集領域を生成し、制御分岐では構造的なガイダンスを提供します。
- ペインティングアシスタント:LLaVAモデルをDraw&Guessタスク用に微調整し、ユーザーのブラシストロークから編集意図を推測します。特に、密にキャプション付けされた画像(DCI)データセットを活用して、エッジ密度に基づくマスク選択や、エッジオーバーレイによるブラシストロークのシミュレーションなど、独自のデータセット構築手法を開発しました。
- アイデアコレクタ:ReactJSベースのモジュラーコンポーネントとして実装され、GradioやComfyUIなど様々なプラットフォームとの互換性を確保しています。
4. どうやって有効だと検証した?
システムの有効性は、以下の3つの側面から包括的に評価されました。
- 編集プロセッサの性能:LPIPS、PSNR、SSIMの定量的指標を用いて、SmartEdit、SketchEdit、BrushNetなどのベースラインと比較し、すべての指標で優れた性能を示しました。
- ペインティングアシスタントの予測精度:Draw&Guessタスクにおいて、LLaVA-1.5、LLaVA-Next、GPT-4oなどの最新のMLLMと比較し、BERT、CLIP、GPT-4の類似性スコアで優位性を確認しました。また、30人の参加者による評価では、86.67%が予測精度を4以上(5段階中)と評価しました。
- インターフェースの使いやすさ:システム使用性スケール(SUS)に基づく評価を実施し、複雑さと効率性、一貫性と統合性、使いやすさ、全体的な満足度の4つの次元で、ベースラインシステムを大きく上回る評価を得ました。
5. 議論はある?
論文では主に2つの課題について議論しています。
- スクリブル-プロンプトのトレードオフ:ユーザーが提供するブラシストロークが、プロンプトで指定された意味的内容から大きく逸脱する場合、品質が低下する問題があります。この問題に対しては、エッジ制御強度を調整することで部分的な緩和が可能です。
- 色付け-詳細のトレードオフ:条件付き画像インペインティングパイプラインがダウンサンプリングされた色ブロックとCNN抽出エッジマップを入力として使用するため、編集領域の構造的詳細が失われる可能性があります。これについては、色ブラシのアルファ値を調整することで、元画像の情報をより多く保持できることが示されています。
また、ブラシストロークの曖昧性による解釈の誤りについても言及されていますが、ユーザー調査では、このような解釈エラーは合理的な試みとして理解されていることが報告されています。6. 次に読むべき論文は?
本研究の発展や関連分野の理解を深めるために、以下の論文が参考になります:
BrushNet(Ju et al., 2024) - プラグアンドプレイ型の画像インペインティングモデルの実装詳細についてControlNet(Zhang et al., 2023) - テキストから画像への拡散モデルに条件制御を追加する手法についてLLaVA(Liu et al., 2024) - マルチモーダル大規模言語モデルの視覚指示調整についてSmartEdit(Huang et al., 2024) - MLLMを活用した複雑な指示ベース画像編集についてDraw&Guess- 本研究で提案された新しいタスクの詳細な理解のためこれらの論文は、画像編集、マルチモーダルAI、ユーザーインターフェース設計の観点から、本研究の基盤となる重要な技術や概念を提供しています。
ここだよな
重要な特徴は、ユーザーが描いたストロークから意図を理解し、プロンプトを自動生成する点で、これによりユーザーは編集作業に集中できます。
一般的には、エリアなどを選択してプロンプト入力、という流れになると思うのだけど、ここをストロークだけで、っていうのが多分ユニークなのだと思う。
セットアップ
以下で実施
- Ubuntu22.04
- Python-3.11.5
- GPU: RTX4090(VRAM 24GB)
基本的に手順通りに進めれば良さげ。
レポジトリクローン
git clone --recursive https://github.com/magic-quill/MagicQuill.git && cd MagicQuill
MagicQuillのチェックポイントをダウンロードして展開。約30GBほどある。
wget -O models.zip "https://hkustconnect-my.sharepoint.com/:u:/g/personal/zliucz_connect_ust_hk/EWlGF0WfawJIrJ1Hn85_-3gB0MtwImAnYeWXuleVQcukMg?e=Gcjugg&download=1"
unzip models.zip
Python仮想環境を作成して有効化。READMEではcondaを使っているが、自分はvenvを使った。
python -m venv .venv
. .venv/bin/activate
GradioのUIパッケージをインストール
pip install gradio_magicquill-0.0.1-py3-none-any.whl
LLAVA環境をインストール
cp -f pyproject.toml MagicQuill/LLaVA/
pip install -e MagicQuill/LLaVA/
必要な残りのパッケージをインストール
pip install -r requirements.txt
でMagicQuillを起動、、、なのだが、自分の場合はUbuntuサーバはLAN内のリモートサーバなので、gradio_run.pyの以下の箇所を修正した。
(snip)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=7860) # hostを修正
# demo.launch()
では起動。
CUDA_VISIBLE_DEVICES=0 python gradio_run.py
ブラウザからアクセス。

なお、この時点でVRAMは約9GB使用していた。
Tue Nov 19 16:47:50 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 43C P8 6W / 450W | 9365MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1377 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1454 G /usr/bin/gnome-shell 15MiB |
| 0 N/A N/A 2616575 C python 9158MiB |
+-----------------------------------------------------------------------------------------+
ではチュートリアルに従って進めてみる。
サンプル画像として、ChatGPTで以下のような画像を生成した。


3種類のMagic Quill
基本は以下の3つの様子。
まず「+」がついているものを試す。画像をアップロード。

「+」がついている羽ペンアイコンが選択されている状態で、首元にネックレスのイメージでドローすると、上に"Necklace"として認識される。これで"Run"をクリック。

以下のようにネックレスが追加された画像が生成される。✔ と ✘ でこの編集を受け入れるかを選択する。
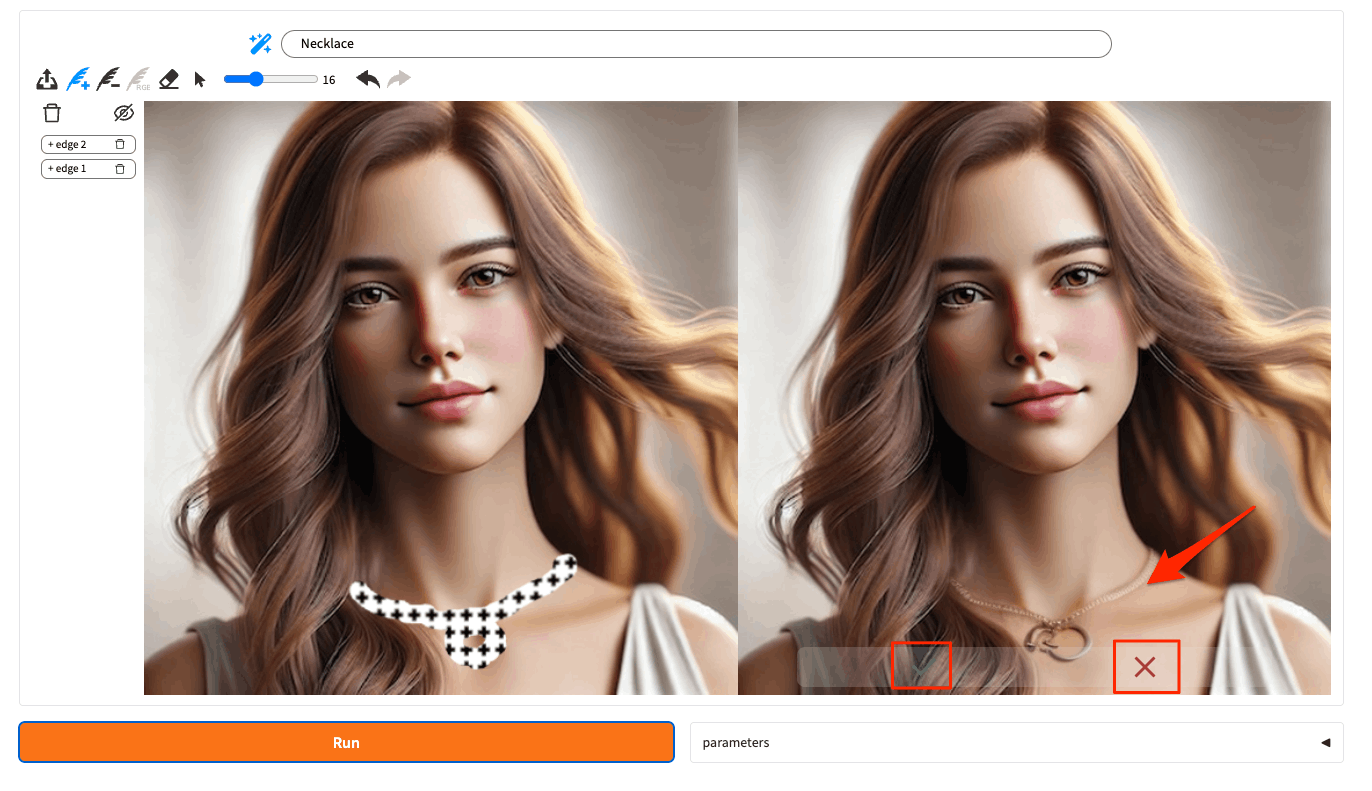
✔を選択すると右の画像が左に移って、ここから再度編集していくような形。
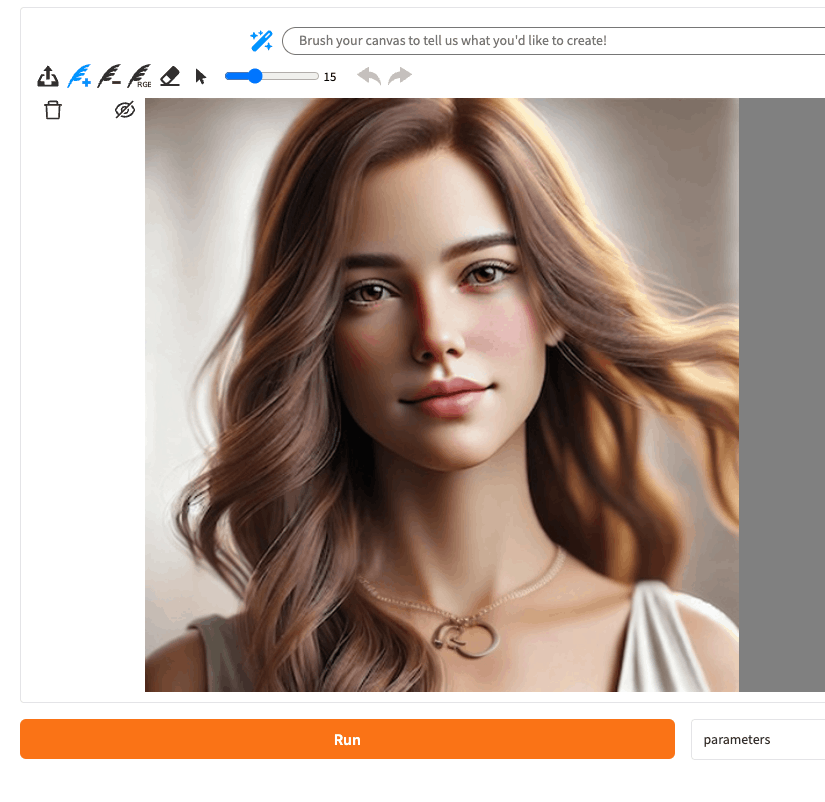
今度は「−」の羽ペンアイコンを選択して、ネックレスの中心部分をドローで囲んで"Run"。

囲んだ部分が削除される。✘で取り消すこともできる。

「RGE」の羽ペンアイコンは色を選択してドローすることで該当箇所の色を変更できる。

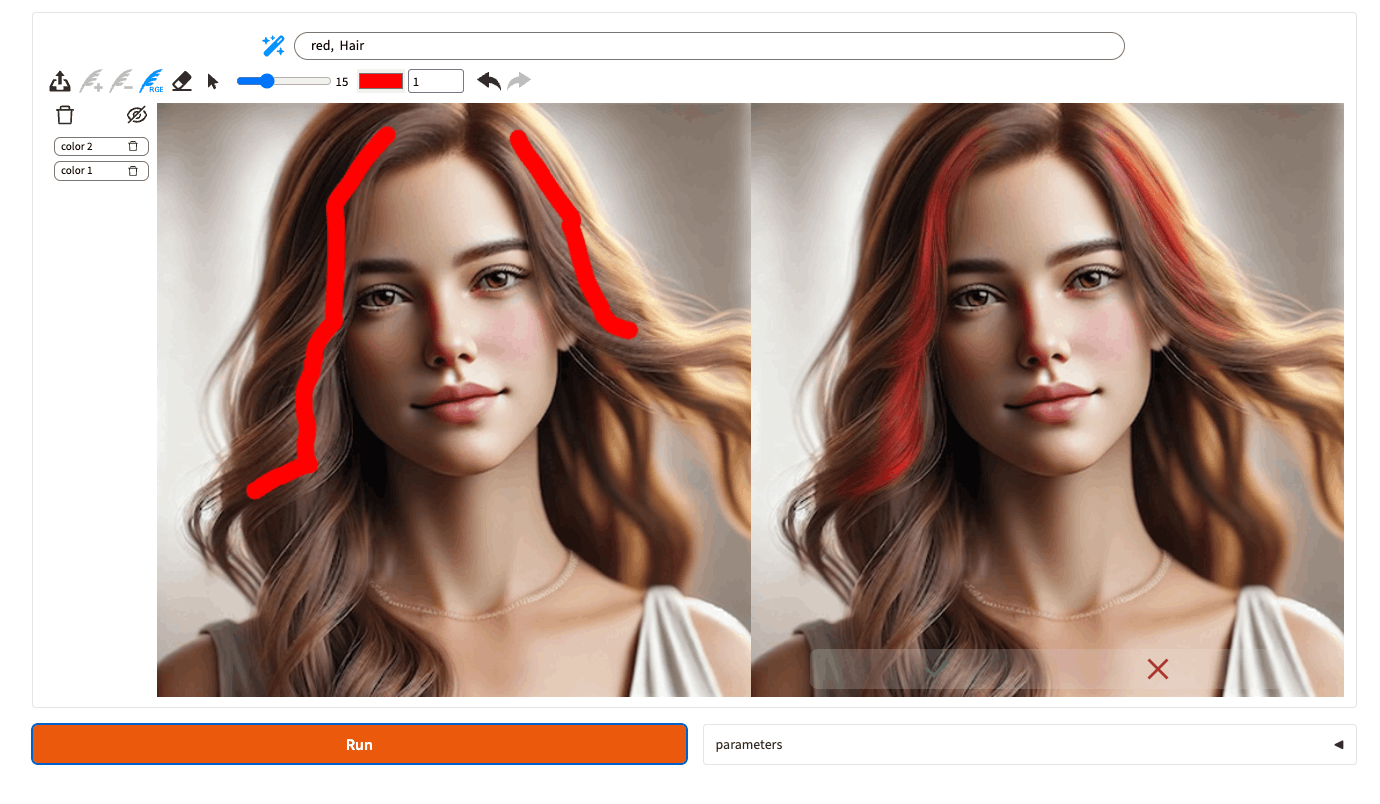
ドロー時の推論の修正
一番最初の例にあった通り、ドロー時に推論が行われるが、これを修正することもできる。
まず「+」で線を2本ドローすると、”Path(小道)”として認識されているのがわかる。

次に「−」で線の間を塗りつぶすような感じで指定。まだ"path"として認識している。
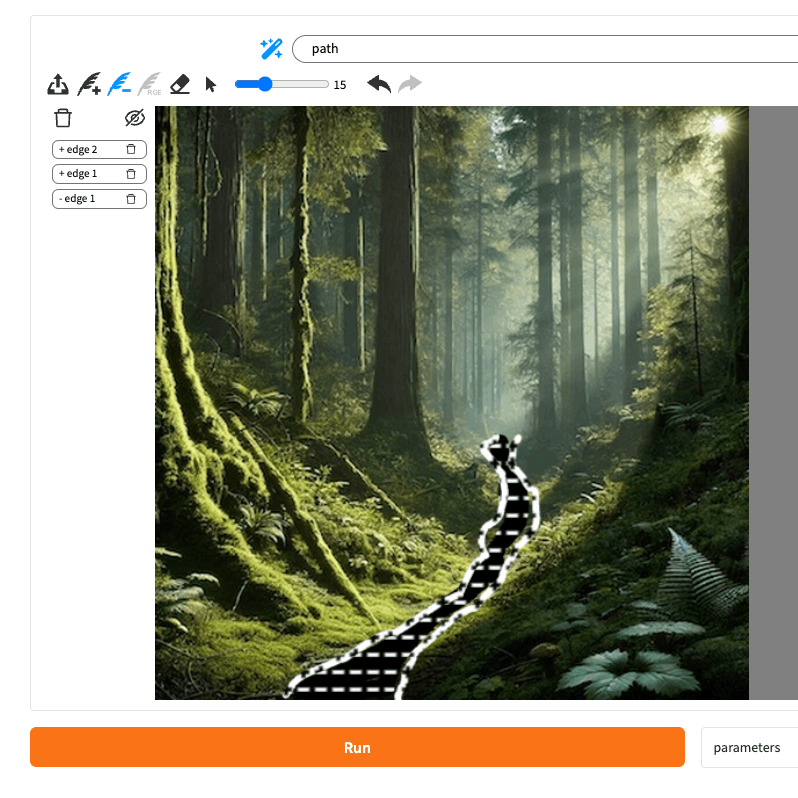
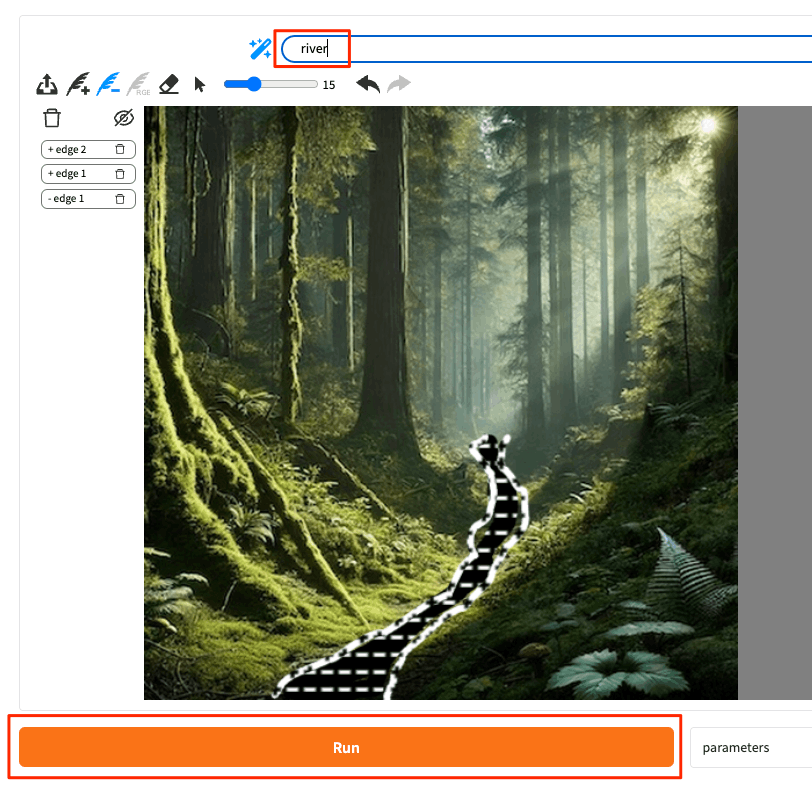
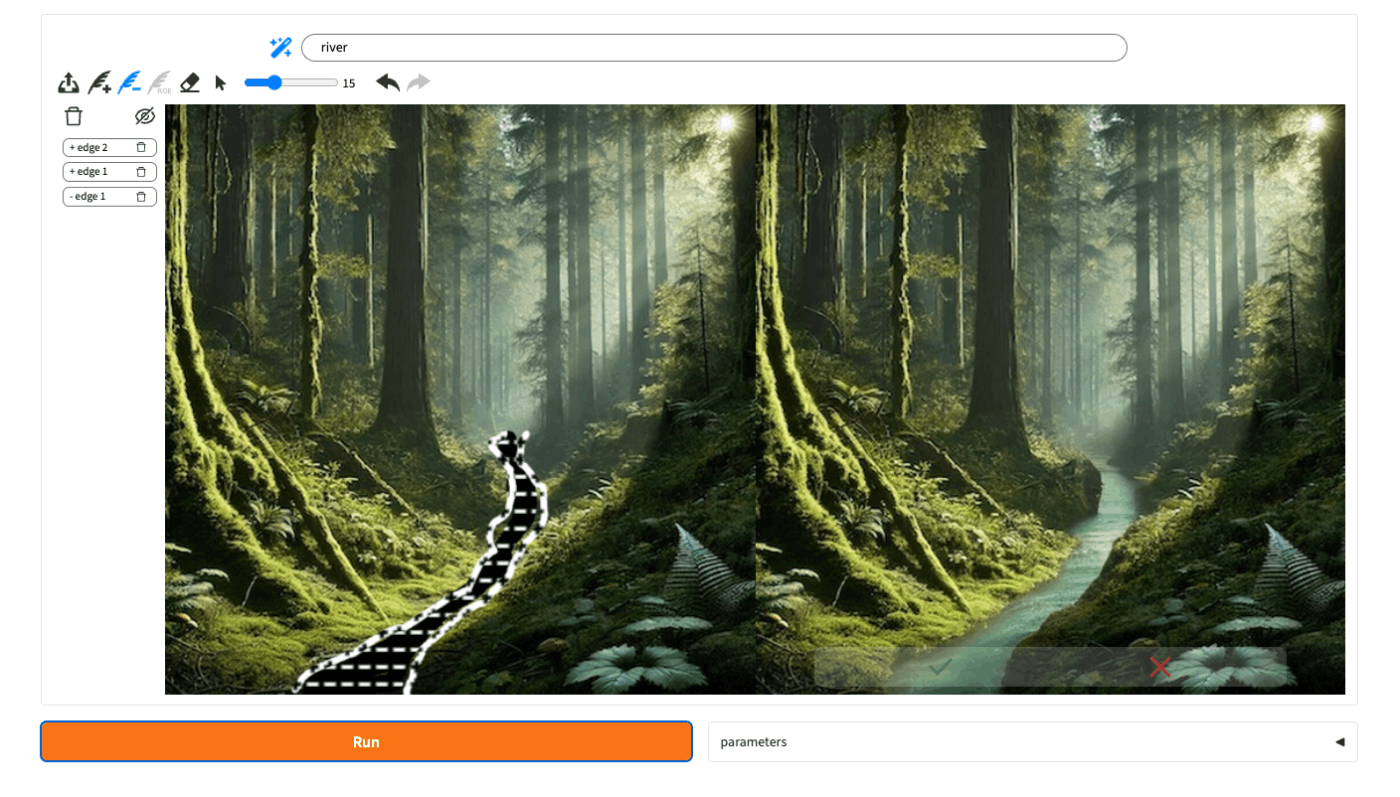
"river"に修正して、"Run"
川が追加された。
主な操作は上記のとおりだが、他のアイコンの意味や、また、細かいパラメータ指定などについても公式サイトに記載がある。使い方の例も豊富なので、参考になる。
なお、上記の終了時点でのVRAM使用量は以下。
Tue Nov 19 17:54:06 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 47C P8 7W / 450W | 13343MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1377 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1454 G /usr/bin/gnome-shell 15MiB |
| 0 N/A N/A 2616575 C python 13136MiB |
+-----------------------------------------------------------------------------------------+
GitHubのREADMEにもハードウェア要件が書いてあるが、15GBぐらいは必要な感じ。
ハードウェア要件
- MagicQuill を実行するには GPU が必要です。
- 即時プロンプト予測(「Draw&Guess」機能)には、約5GBのVRAM が必要です。
- 画像編集を行うには、約15GBのVRAM が必要です。
まとめ
ちょうどRecraftで画像生成を久々に試したところだったので、たまたま見つけたこれも試してみた次第。
画像生成・編集は、品質も重要だけども、UIもかなり重要だなと感じた。RecraftもUIかなり使いやすいと感じたけど、プロンプトでの指示はやはり間接的なのものであって、ドローツールで直接ビジュアルで指示できるってのが最も直感的に思える。タブレットでやりたくなるね。
ComfyUI用のカスタムノードも開発予定みたい。
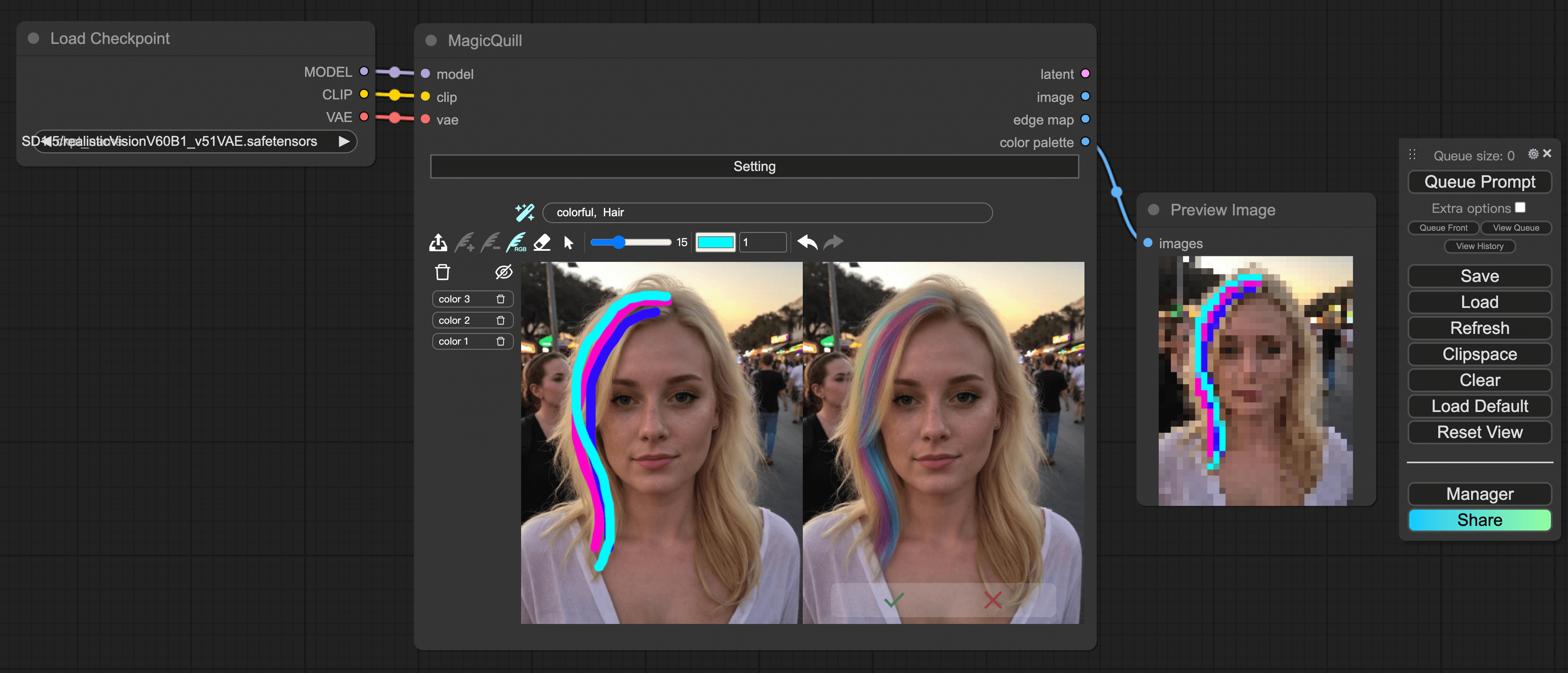
refered from https://github.com/magic-quill/magicquill
商用でこういうのができるものは既にあるのかな?