ADAS(Automated Design of Agentic Systems)
論文
落合プロンプトによる要約
どのような研究か?
この研究は、自動的にエージェントシステムを設計する新しい研究分野「自動エージェントシステム設計(ADAS)」を提案しています。特に、メタエージェントがコードでプログラミングすることで新しいエージェントを自動的に発見する手法を提案しています。
新規性(先行研究と比較して何が優れているか)?
従来の手法では、プロンプトの最適化や制御フローの学習に限定されていましたが、本研究ではチューリング完全な言語でエージェントシステム全体を定義し、自動的に発見することを可能にしています。これにより、プロンプト、ツール使用、制御フロー、およびそれらの組み合わせなど、あらゆる可能なエージェントシステムを理論的に発見できます。
技術や手法の肝は?
提案された「メタエージェント探索」アルゴリズムの核心は以下の通りです:
- メタエージェントが反復的に新しいエージェントをコードでプログラミングする
- 発見されたエージェントを評価し、アーカイブに追加する
- アーカイブを使用して、次の反復でさらに興味深い新しいエージェントを作成する
どのように有効性が示されたか?
以下の実験を通じて有効性が示されました:
- ARC(抽象化と推論コーパス)[1]論理パズルタスクでの性能評価
- 読解、数学、科学の質問、マルチタスク問題解決に関する4つの人気ベンチマークでの評価
- 発見されたエージェントの他のドメインやモデルへの転移可能性の評価
結果として、提案手法は手動で設計された最先端のエージェントを大幅に上回る性能を示しました。例えば、DROP[2]の読解タスクでF1スコアを13.6/100改善し、MGSM[3]の数学タスクで正確率を14.4%向上させました。
議論はあるか?
論文では以下の点について議論がなされています:
- ADASの安全性に関する考慮事項
- より高次のADAS、既存のビルディングブロックの活用、マルチ目的ADAS、新規性探索アルゴリズムなどの将来の研究方向性
- ADASが人間の組織や社会における複雑性の起源を理解するための洞察を提供する可能性
次に読むべき論文は?
この研究の基礎となる以下の論文を読むことをお勧めします:
- "AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence" by Jeff Clune (2019) - AI生成アルゴリズムの概念を提案しています。
- "Constitutional AI: Harmlessness from AI feedback" by Yuntao Bai et al. (2022) - 安全なAIシステムの開発に関する研究です。
- "FunSearch: Mathematical discoveries from program search with large language models" by Bernardino Romera-Paredes et al. (2024) - 大規模言語モデルを使用したプログラム探索に関する研究です。
これらの論文は、ADASの基礎となる概念や関連する技術について深い洞察を提供するでしょう。
エージェントを作るためのメタエージェント、というところか。
公式サイト
理解のため翻訳
エージェントシステムの自動設計
TL;DR
本稿では、強力なエージェントシステムの設計を自動的に行うことを目的とした、新たに形成されつつある研究分野であるエージェントシステムの自動設計(ADAS)について説明します。この分野では、新しいビルディングブロックを考案したり、それらを新しい方法で組み合わせたりすることを含みます。
私たちは、メタエージェント検索というシンプルかつ効果的なADASアルゴリズムを提示し、コードでプログラミングすることでエージェントが新規かつ強力なエージェント設計を考案できることを示します。
referred from https://github.com/ShengranHu/ADAS and translated into Japaneseメタエージェント検索では、「メタ」エージェントに新しいエージェントを反復的にプログラムし、そのタスクにおけるパフォーマンスをテストし、発見されたエージェントのアーカイブに追加し、このアーカイブを使用して、その後の反復におけるメタエージェントに情報を提供するように指示します。
発見されたエージェントの例

生成されたPythonコード
def forrward(self, taskInfo): # ステップ1:複数のFMモジュールを使用して、初期の候補ソリューションを生成 initial_instruction = 'ステップバイステップで考えて、コードを書いて課題を解いてください。' num_candidates = 5 # 初期の候補の数 initial_module = [FM_Module(['thinking', 'code'], 'Initial Solution', temperature=0.8) for _ in range(num_candidates)] initial_solutions = [] for i in range(num_candidates): thoughts = initial_module[i]([taskInfo], initial_instruction) thinking, code = thoughts[0], thoughts[1] feedback, correct_examples, wrong_examples = self.run_examples_and_get_feedback(code) if len(correct_examples) > 0: # 少なくとも1つの例で合格したソリューションのみを検討 initial_solutions.append({'thinking': thinking, 'code': code, 'feedback': feedback, 'correct_count': len(correct_examples)}) # ステップ 2: 各候補ソリューションについて、人間的なフィードバックをシミュレート human_like_feedback_module = FM_Module(['thinking', 'feedback'], 'Human-like Feedback', temperature=0.5) human_feedback_instruction = 'コードに対して人間的なフィードバックを提供してください。一般的な間違い、ヒューリスティックな修正、ベストプラクティスに焦点を当ててください。' for sol in initial_solutions: thoughts = human_like_feedback_module([taskInfo, sol['thinking'], sol['code']], human_feedback_instruction) human_thinking, human_feedback = thoughts[0], thoughts[1] sol['human_feedback'] = human_feedback # ステップ3:評価と的を絞ったフィードバックを行うエキスパートアドバイザーを任命 expert_roles = ['Efficiency Expert', 'Readability Expert', 'Simplicity Expert'] expert_advisors = [FM_Module(['thinking', 'feedback'], role, temperature=0.6) for role in expert_roles] expert_instruction = '以下のコードを評価し、改善に向けた的を射たフィードバックを提供してください。' for sol in initial_solutions: sol_feedback = {} for advisor in expert_advisors: thoughts = advisor([taskInfo, sol['thinking'], sol['code']], expert_instruction) thinking, feedback = thoughts[0], thoughts[1] sol_feedback[advisor.role] = feedback sol['expert_feedback'] = sol_feedback # ステップ4:フィードバックを解析し構造化することで、重複を避け、ソリューションを反復的に洗練させる max_refinement_iterations = 3 refinement_module = FM_Module(['thinking', 'code'], 'Refinement Module', temperature=0.5) refined_solutions = [] for sol in initial_solutions: for i in range(max_refinement_iterations): combined_feedback = sol['feedback'].content + sol['human_feedback'].content + ''.join([fb.content for fb in sol['expert_feedback'].values()]) structured_feedback = ' '.join(set(combined_feedback.split())) # 重複を回避 refinement_instruction = '構造化されたフィードバックを活用し、パフォーマンスを向上させるためにソリューションを改善してください。' thoughts = refinement_module([taskInfo, sol['thinking'], sol['code'], Info('feedback', 'Structured Feedback', structured_feedback, i)], refinement_instruction, i) refinement_thinking, refined_code = thoughts[0], thoughts[1] feedback, correct_examples, wrong_examples = self.run_examples_and_get_feedback(refined_code) if len(correct_examples) > 0: sol.update({'thinking': refinement_thinking, 'code': refined_code, 'feedback': feedback, 'correct_count': len(correct_examples)}) refined_solutions.append(sol) # ステップ5: 最も効果的なソリューションを選択し、アンサンブルアプローチを用いて最終決定を行う sorted_solutions = sorted(refined_solutions, key=lambda x: x['correct_count'], reverse=True) top_solutions = sorted_solutions[:3] # 上位3つのソリューションを選択 final_decision_instruction = '与えられた上記のすべての解決策を考慮した上で、慎重に検討し、コードを書いて最終的な答えを出してください。' final_decision_module = refinement_module(['thinking', 'code'], 'Final Decision Module', temperature=0.1) final_inputs = [taskInfo] + [item for solution in top_solutions for item in [solution['thinking'], solution['code'], solution['feedback']]] final_thoughts = final_decision_module(final_inputs, final_decision_instruction) final_thinking, final_code = final_thoughts[0], final_thoughts[1] answer = self.get_test_output_from_code(final_code) return answerARCで発見されたベストのエージェントをビジュアル化
referred from https://www.shengranhu.com/ADAS/ and translated into Japanese新しい研究分野:エージェントシステムの自動設計(ADAS)
referred from https://www.shengranhu.com/ADAS/ and translated into JapaneseADASの3つの主要コンポーネント。検索スペースは、ADASで表現できるエージェントシステムを決定します。検索アルゴリズムは、ADASの方法が検索スペースを検索する方法を指定します。評価関数は、パフォーマンスなどの目標に対してエージェント候補を評価する方法を定義します。
実験
referred from https://www.shengranhu.com/ADAS/ and translated into JapaneseARCチャレンジにおけるメタエージェント検索の結果。 (a) メタエージェント検索は、これまでの発見の記録を元に、高性能エージェントを段階的に発見します。 5回にわたってエージェントを評価し、保持されたテストセットの中央値と95%ブートストラップ信頼区間を報告します。 (b) ARCチャレンジにおけるメタエージェント検索が発見した最良のエージェントの視覚化。
referred from https://www.shengranhu.com/ADAS/複数の分野におけるメタエージェント検索と手作業で設計された最新エージェントの性能比較。メタエージェント検索は、すべての分野において、ベースラインよりも優れたエージェントを発見しています。テスト精度と、保持されたテストセットにおける95%ブートストラップ信頼区間を報告しています。検索は各分野ごとに個別に実施されています。
referred from https://www.shengranhu.com/ADAS/重要なのは、メタエージェント検索によって発見されたエージェントが、ドメインやモデルをまたいで転用された場合でも優れたパフォーマンスを維持するという驚くべき結果が常に観察されており、その頑健性と汎用性が示されていることです。ここでは、数学(MGSM)ドメインから非数学ドメインにトップエージェントを転送した際の、複数のドメインにわたるパフォーマンスを紹介します。数学ドメインでメタエージェント検索によって発見されたエージェントは、数学以外のドメインに転送された後、ベースラインのパフォーマンスを上回る、または同等のパフォーマンスを発揮することができます。テスト精度と95%ブートストラップ信頼区間を報告します。転送可能性に関するすべての結果は論文で入手できます。
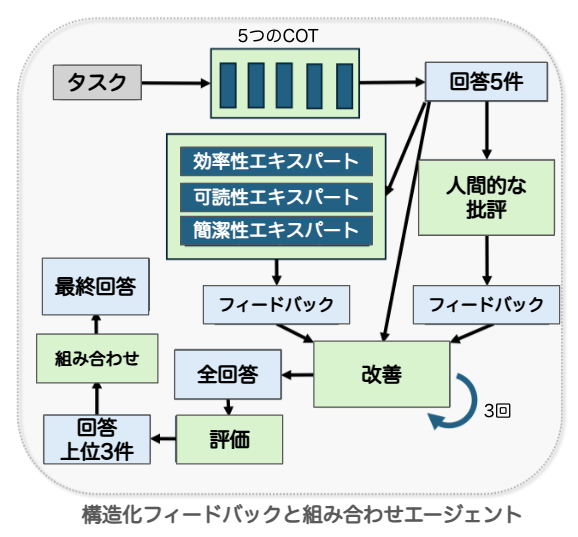

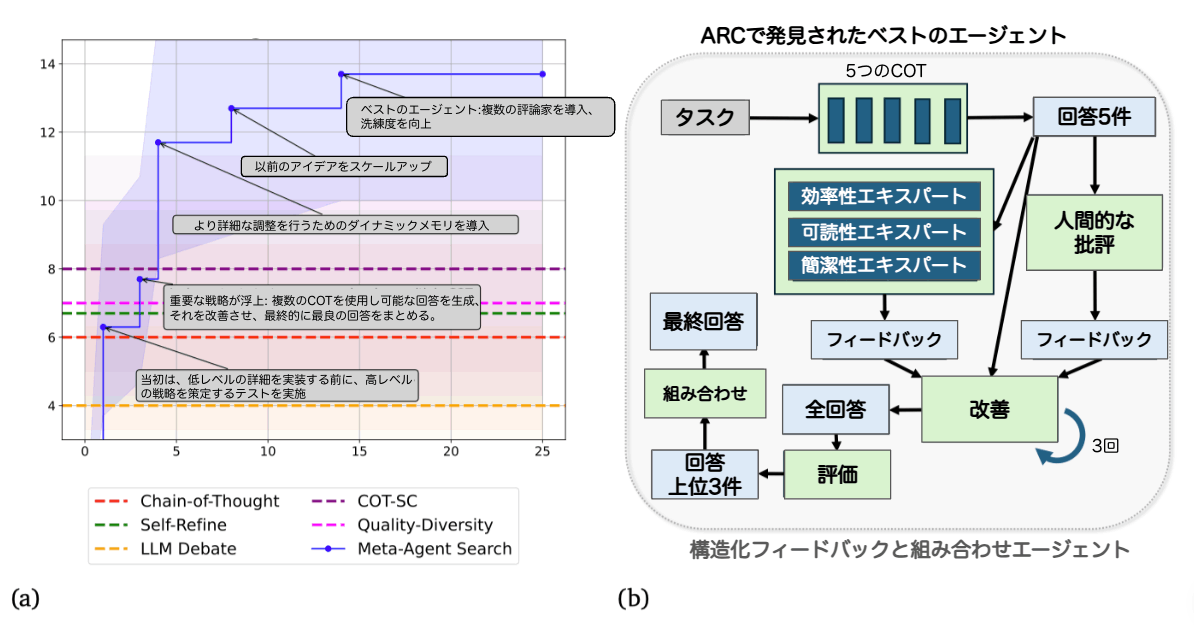
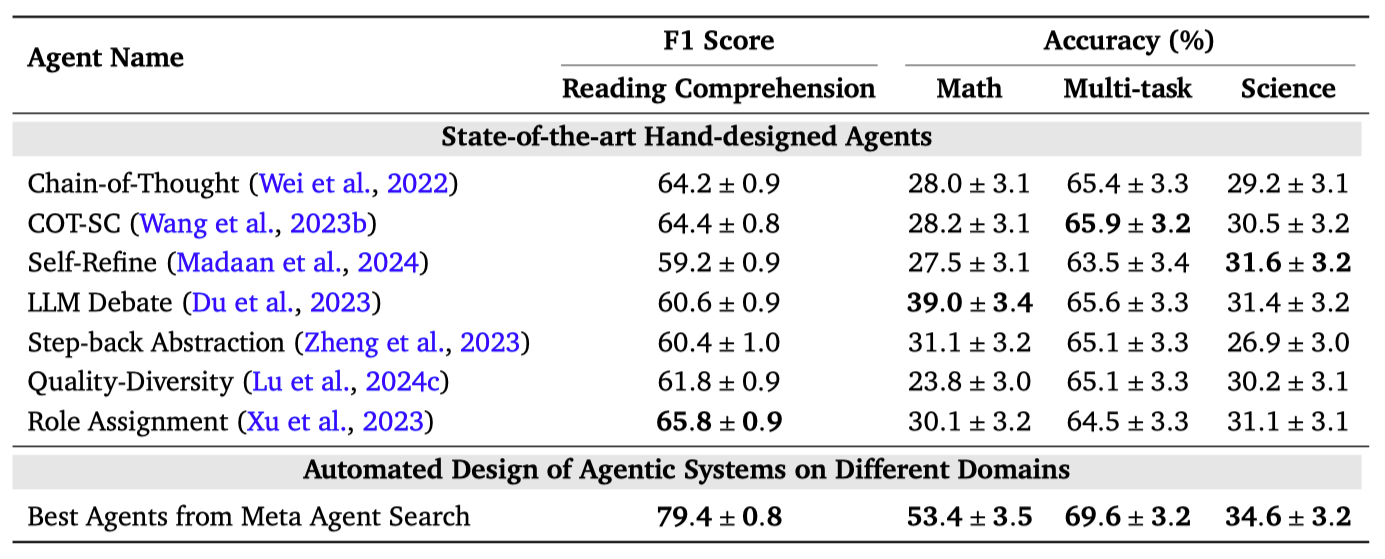
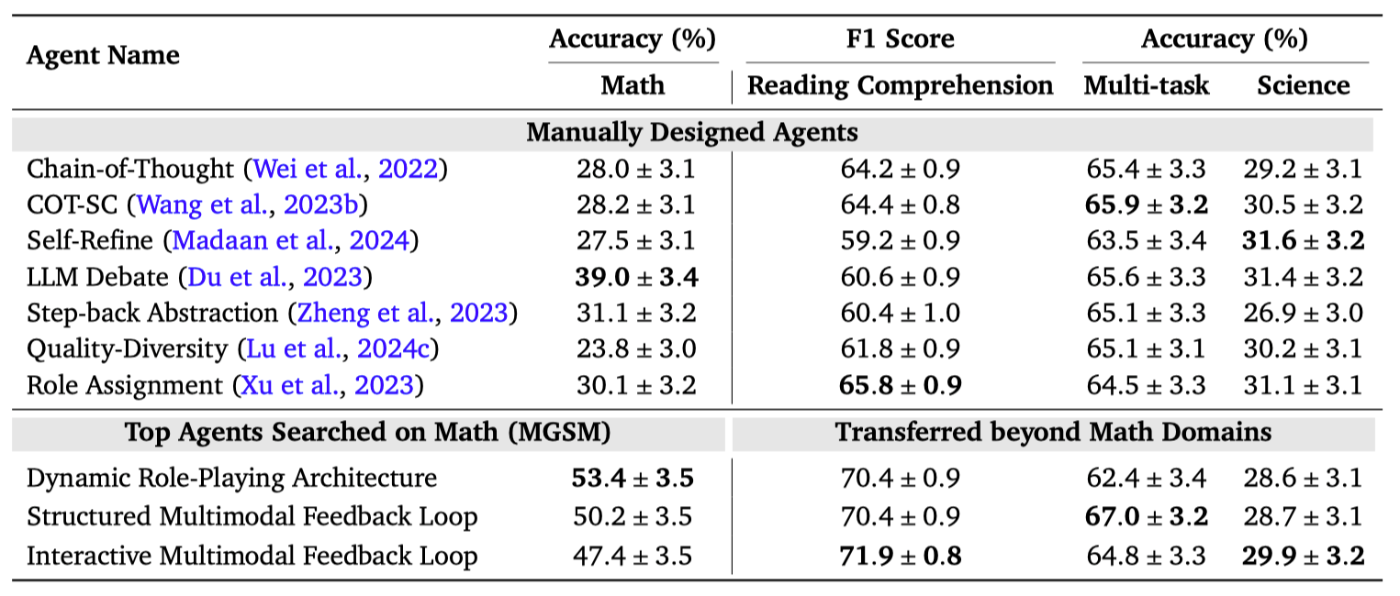
実験とかで書かれているエージェントのフロー図はADASによって検索・生成されたものであって、実際のロジックは一番最初のフロー図がそれ。