LlamaIndexの新しいメモリ機能「Chat Summary Memory Buffer」「Simple Composable Memory」「Vector Memory」を試す
個人的には、LangChainよりもLlamaIndexのほうが好みなのだけど、不満があるとすれば会話履歴を保存しておくメモリ機能がかなり弱いところ。
公式にサポートしているのは以下のみ。
- SimpleChatStore: オンメモリで動作。ファイルから読み出し、ファイルへの出力はサポート。
- RedisChatStore: メモリストレージとしてRedisを使う
- AzureChatStore: メモリストレージとしてAzure Table StorageまたはCosmosDBを使う(最近追加されたっぽい)
LangChainだとこのインテグレーションは非常に豊富。
さらに、もう1つ、モデルの入力コンテキストサイズの制限を回避するためには一定量で古いものを消す・古いものを圧縮(要約)する、といったことも必要になるのだけども、こちらもとても弱い。
LangChainだとこういったことに対応するためのConversationBufferWindowMemoryやConversationSummaryBufferMemoryなど、メモリの実装だけでも複数の実装が存在する。
なのでメモリ機能の強化は嬉しいところ。今回紹介されているのは以下の2つ。
- Simple Composable Memory
- Vector Memory
あと、少し前に紹介されていた「Chat Summary Memory Buffer」についてもそう言えば試していなかったのであわせて試してみる。
(おさらい)LlamaIndexのメモリ機能
メモリを構成するのは2つのコンポーネント。
- メモリを保存するためのストレージへのインタフェース
- SimpleChatStore、RedisChatStoreなど
- 上記へのメモリの読み込み・書き込みおよびバッファの操作を行うインタフェース。
- ChatMemoryBufferなど
以前にも少しやっているのだけども、少しおさらい。
パッケージインストール。Arize Phonixでトレーシングも確認できるようにセットで。
!pip install llama-index llama-index-callbacks-arize-phoenix
!pip freeze | egrep "llama-|arize"
arize-phoenix==4.3.0
llama-index==0.10.43
llama-index-agent-openai==0.2.7
llama-index-callbacks-arize-phoenix==0.1.5
llama-index-cli==0.1.12
llama-index-core==0.10.43
llama-index-embeddings-openai==0.1.10
llama-index-indices-managed-llama-cloud==0.1.6
llama-index-legacy==0.9.48
llama-index-llms-openai==0.1.22
llama-index-multi-modal-llms-openai==0.1.6
llama-index-program-openai==0.1.6
llama-index-question-gen-openai==0.1.3
llama-index-readers-file==0.1.23
llama-index-readers-llama-parse==0.1.4
llama-parse==0.4.4
openinference-instrumentation-llama-index==1.4.2
OpenAIのAPIキーをセット
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
Arize Phoenixのトレーシングを有効化
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
🌍 To view the Phoenix app in your browser, visit https://XXXXXXXXXXXX-XXXXXXXXXXXXXXXX-XXXX-colab.googleusercontent.com/
📖 For more information on how to use Phoenix, check out https://docs.arize.com/phoenix
ではインデックスを作成。コンテンツは以下を使う。
コンテンツをテキストファイルでダウンロード。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
コンテンツからインデックスを作成。
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core import Settings
# 今回はデフォルトのLLMをgpt-4o、Embeddingはtext-embedding-3-largeとした
Settings.llm = OpenAI(model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-large")
Settings.node_parser = SentenceSplitter(chunk_size=400, chunk_overlap=100)
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents,
show_progress=True
)
chat_engineを作成。なお、メモリはchat engineかagentで有効化できる。query engine単体では使えない模様。
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(
token_limit=1000,
chat_store=chat_store,
chat_store_key="user1",
)
chat_engine = index.as_chat_engine(
memory=chat_memory,
similarity_top_k=5,
)
.chat_repl()でシンプルに試してみる。
chat_engine.chat_repl()
===== Entering Chat REPL =====
Type "exit" to exit.Human: オグリキャップの血統について教えて。
Assistant: オグリキャップの血統について以下の情報があります:
- 父: ダンシングキャップ
- 母: ホワイトナルビー
### 父系
- ダンシングキャップは種牡馬成績がさほど優れていなかったため、オグリキャップは突然変異や隔世遺伝で生まれたとする意見もあります。しかし、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評しています。
### 母系
- ホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めています。
### 兄弟
- オグリローマン: 1994年桜花賞優勝馬
- オグリイチバン: 種牡馬
- オグリトウショウ
オグリキャップはその血統背景からも注目される存在です。
Human: ダンシングキャップについてもっと詳しい情報はある?
Assistant: ダンシングキャップについての詳細は以下の通りです:
- 評価: 「ダートの短距離血統」として評価されています。
- 種牡馬成績: さほど優れていなかったため、オグリキャップの誕生は「突然変異」や「ネイティヴダンサーの隔世遺伝」とも言われています。
- 血統評論家の見解: 血統評論家の山野浩一は、ダンシングキャップを「一発ある血統」と評しています。ネイティヴダンサー系の種牡馬が時々大物を出すことから、オグリキャップもその一例と分析されています。
ダンシングキャップはその血統背景からも注目される存在であり、特にオグリキャップの誕生により再評価されることとなりました。
Human: ダンシングキャップの他の代表産駒を教えて。
Assistant: ダンシングキャップの代表産駒として特に有名なのはオグリキャップです。他の代表産駒についての情報は見つかりませんでした。オグリキャップがその中でも特に際立った存在であることがわかります。Human: なるほどね、じゃあほんとに突然変異っぽい感じだね
Assistant: そうですね。ダンシングキャップの種牡馬成績がさほど優れていなかった中で、オグリキャップのような名馬が誕生したことは、まさに「突然変異」や「隔世遺伝」といった特別な出来事だったと言えます。オグリキャップの存在がダンシングキャップの血統を再評価させるきっかけとなったのは興味深いですね。Human: 次にオグリキャップの戦績について教えてくれるかな?
Assistant: オグリキャップの戦績は非常に優れています。以下にその主な戦績をまとめます:### 地方競馬(笠松競馬場)
- デビュー: 笠松競馬場でデビュー
- 成績: 12戦10勝(8連勝を含む)
### 中央競馬
- 重賞勝利: 12勝(うちGI4勝)
### 受賞歴
- 1988年度: JRA賞最優秀4歳牡馬
- 1989年度: JRA賞特別賞
- 1990年度: JRA賞最優秀5歳以上牡馬および年度代表馬
- 1991年: JRA顕彰馬に選出
オグリキャップはその圧倒的な成績と人気で、多くのファンに愛され続けています。
Human: GI4勝ってのはどのレース?
Assistant: オグリキャップのGI勝利レースについての情報が一部不足していました。正確には、オグリキャップは以下のGIレースで勝利を収めています:
- マイルチャンピオンシップ(1989年)
- 有馬記念(1988年、1990年)
- 安田記念(1990年)
これらの勝利により、オグリキャップはその名を競馬史に刻みました。
Human: 有馬記念連覇してるんだ、すごいね
Assistant: はい、オグリキャップは有馬記念を1988年と1990年に勝利しています。特に1990年の有馬記念は、引退レースとして多くのファンの記憶に残る名勝負となりました。このレースでの勝利は「奇跡の復活」とも称され、オグリキャップの人気と伝説をさらに高めました。彼の競走馬としてのキャリアは、多くの人々に感動を与え続けています。Human: なんで奇跡の勝利って言われたの?
Assistant: 1990年の有馬記念でオグリキャップが「奇跡の勝利」と呼ばれた理由は以下の通りです:
限界説の中での勝利: オグリキャップは当時、限界説が唱えられており、競走馬としてのピークを過ぎたと見られていました。
レース展開: レース序盤は6番手につけ、第3コーナーから前方への進出を開始し、最終直線で先頭に立ちました。追い上げてくるメジロライアンとホワイトストーンを抑えて1着でゴールインしました。
ファンの支持: オグリキャップはファン投票で第1位に選ばれましたが、単勝馬券のオッズでは4番人気でした。このギャップも「奇跡」と呼ばれる一因です。
感動のラストラン: このレースはオグリキャップの引退レースであり、多くのファンが彼の最後の勇姿を見届けました。レース後には観衆から「オグリコール」が起こり、感動的なシーンが広がりました。
これらの要素が重なり、1990年の有馬記念でのオグリキャップの勝利は「奇跡の復活」「感動のラストラン」として語り継がれています。
Human: おお、それはすごいね、きっと盛り上がったんだろうね。
Assistant: はい、1990年の有馬記念は競馬史に残る名レースとなり、多くのファンが感動と興奮に包まれました。オグリキャップの奇跡の勝利は、競馬ファンだけでなく、多くの人々に感動を与えました。レース後の「オグリコール」や涙を流すファンの姿は、今でも語り草となっています。オグリキャップの物語は、競馬の枠を超えて多くの人々に愛され続けています。彼の勇姿とその奇跡の勝利は、競馬の魅力を象徴するものとして、今後も語り継がれていくことでしょう。
Human: わかったよ、参考になったよ、ありがとう。
Assistant: どういたしまして!お役に立てて嬉しいです。もし他にも質問や知りたいことがあれば、いつでも聞いてくださいね。Human: exit
会話のコンテキストが維持されているのがわかる。
メモリの中身を見てみる。
import json
# `chat_store_key`ごとに会話履歴が保存される
for i in json.loads(chat_store.json())["store"]["user1"]:
if i["content"] is not None:
if len(i["content"]) >= 50:
print("{}: {}...".format(i["role"], i["content"].replace("\n","")[:50]))
else:
print("{}: {}".format(i["role"], i["content"].replace("\n","")[:50]))
こんな感じで個々の発言や、あとchat_engineは裏でtool callingなども行っているので、その結果なんかも履歴として保存されている。
user: オグリキャップの血統について教えて。
tool: オグリキャップの父はダンシングキャップで、母はホワイトナルビーです。ダンシングキャップの種牡馬成績は...
assistant: オグリキャップの血統について以下の情報があります:- **父**: ダンシングキャップ- **母**...
user: ダンシングキャップについてもっと詳しい情報はある?
tool: ダンシングキャップは「ダートの短距離血統」として評価されており、その種牡馬成績はさほど優れていなかっ...
assistant: ダンシングキャップについての詳細は以下の通りです:- **評価**: 「ダートの短距離血統」として評...
user: ダンシングキャップの他の代表産駒を教えて。
tool: ダンシングキャップの代表産駒にはオグリキャップがいます。
assistant: ダンシングキャップの代表産駒として特に有名なのはオグリキャップです。他の代表産駒についての情報は見つ...
user: なるほどね、じゃあほんとに突然変異っぽい感じだね
assistant: そうですね。ダンシングキャップの種牡馬成績がさほど優れていなかった中で、オグリキャップのような名馬が...
user: 次にオグリキャップの戦績について教えてくれるかな?
tool: オグリキャップは競走馬として非常に優れた戦績を持っています。地方競馬の笠松競馬場でデビューし、8連勝...
assistant: オグリキャップの戦績は非常に優れています。以下にその主な戦績をまとめます:### 地方競馬(笠松競馬...
user: GI4勝ってのはどのレース?
tool: オグリキャップのGI勝利レースは、天皇賞(秋)です。
assistant: オグリキャップのGI勝利レースについての情報が一部不足していました。正確には、オグリキャップは以下の...
user: 有馬記念連覇してるんだ、すごいね
assistant: はい、オグリキャップは有馬記念を1988年と1990年に勝利しています。特に1990年の有馬記念は、...
user: なんで奇跡の勝利って言われたの?
tool: 1990年の有馬記念でオグリキャップが「奇跡の勝利」と呼ばれた理由は、彼が限界説が唱えられていた中で...
assistant: 1990年の有馬記念でオグリキャップが「奇跡の勝利」と呼ばれた理由は以下の通りです:1. **限界説...
user: おお、それはすごいね、きっと盛り上がったんだろうね。
assistant: はい、1990年の有馬記念は競馬史に残る名レースとなり、多くのファンが感動と興奮に包まれました。オグ...
user: わかったよ、参考になったよ、ありがとう。
assistant: どういたしまして!お役に立てて嬉しいです。もし他にも質問や知りたいことがあれば、いつでも聞いてくださ...
これをファイルに出力する場合はこんな感じ。
chat_store.persist(persist_path="chat_store.json")
逆に読み込む場合はこんな感じ。
chat_store = SimpleChatStore.from_persist_path(
persist_path="chat_store.json"
)
これを使って会話履歴を引き継ぐことができる。
token_limitは会話のコンテキストをどこまでチャットの中で保持するか?になる。あえて極端に小さな値をセットしてみる。
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(
token_limit=50, # 1000から50に変更
chat_store=chat_store,
chat_store_key="user1",
)
chat_engine = index.as_chat_engine(
memory=chat_memory,
similarity_top_k=5,
)
これでチャットしてみる。
chat_engine.chat_repl()
===== Entering Chat REPL =====
Type "exit" to exit.Human: オグリキャップの血統について教えて。
Assistant: オグリキャップの血統について以下の情報があります:
- 父: ダンシングキャップ
- 母: ホワイトナルビー
### 父系(ダンシングキャップ)
ダンシングキャップは種牡馬としての成績はあまり優れていませんでしたが、血統評論家の山野浩一は「一発ある血統」と評しています。ネイティヴダンサー系の種牡馬が時々大物を出すことがあり、オグリキャップもその一例とされています。### 母系(ホワイトナルビー)
ホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬で勝利を収めています。5代母のクイン>ナルビーは1953年の天皇賞(秋)を制しており、その子孫にはアンドレアモンやキョウエイマーチなどの>重賞勝ち馬がいます。### 兄弟
オグリキャップの兄弟には以下の馬がいます:
- オグリローマン: 1994年桜花賞優勝馬
- オグリイチバン: 種牡馬
- オグリトウショウ: デビュー前から話題を集めた馬
このように、オグリキャップは優れた血統背景を持ち、兄弟にも活躍馬が多くいます。
Human: ほう、すごいねー。
Assistant: ありがとうございます!何かお手伝いできることがあれば教えてくださいね。Human: 今何の話ししてたっけ?
Assistant: 特に特定の話題について話していたわけではありませんが、何か特定の話題について知りたいことや質問があれば教えてください。
会話がつながっていない。実際にトレースを見てみると、過去の会話履歴がチャットで渡されていない。つまりtoken_limitを超える履歴はチャットで使用されないということになる。これにより入力トークンサイズの制限を回避することができる。
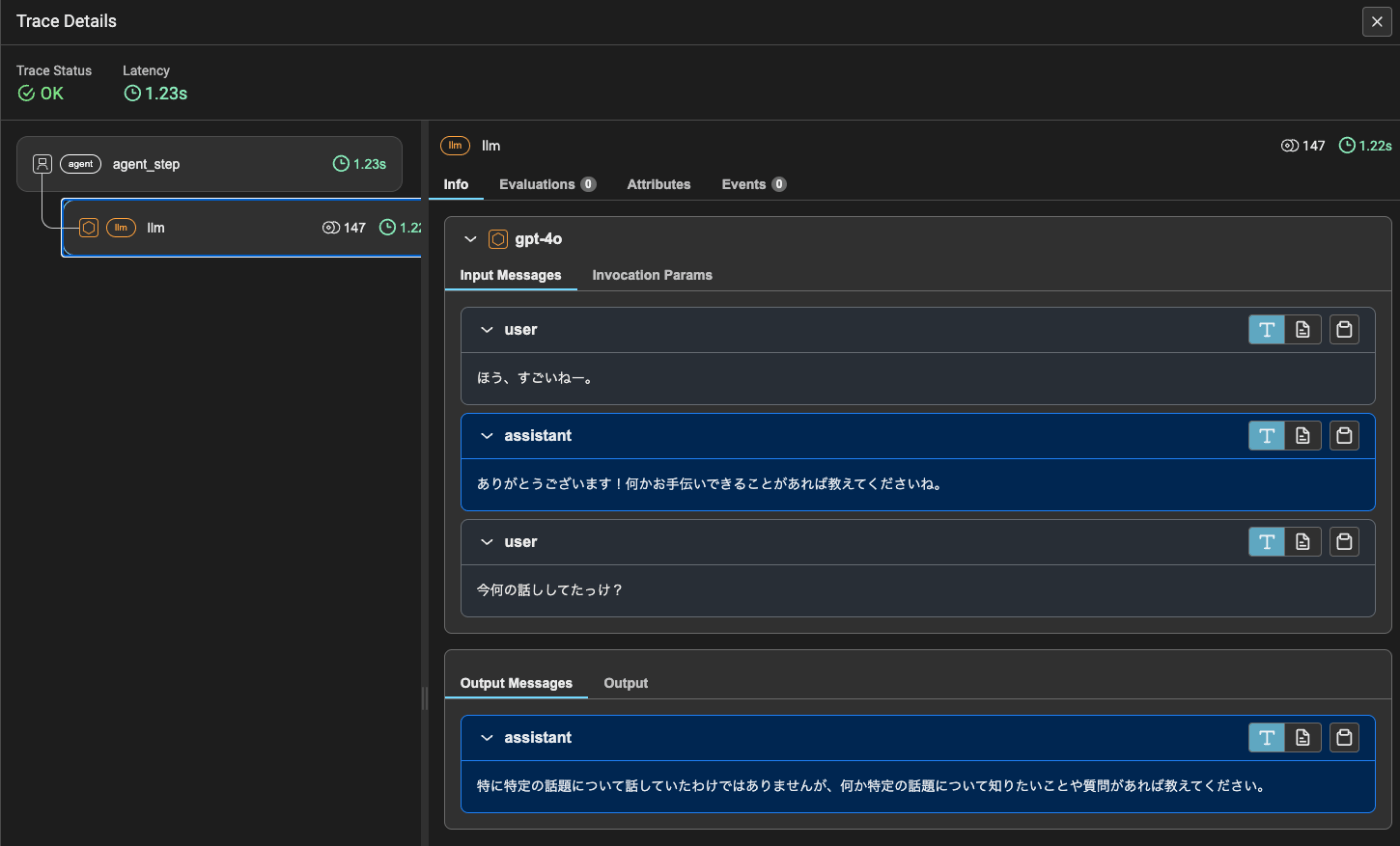
ちなみに少し余談だけども、この状態でチャット履歴を見てみると、きちんと会話履歴は残っている。
import json
for i in json.loads(chat_store.json())["store"]["user1"]:
if i["content"] is not None:
if len(i["content"]) >= 50:
print("{}: {}...".format(i["role"], i["content"].replace("\n","")[:50]))
else:
print("{}: {}".format(i["role"], i["content"].replace("\n","")[:50]))
>user: オグリキャップの血統について教えて。
tool: オグリキャップの父はダンシングキャップで、母はホワイトナルビーです。ダンシングキャップの種牡馬成績は...
assistant: オグリキャップの血統について以下の情報があります:- **父**: ダンシングキャップ- **母**...
user: ほう、すごいねー。
assistant: ありがとうございます!何かお手伝いできることがあれば教えてくださいね。
user: 今何の話ししてたっけ?
assistant: 特に特定の話題について話していたわけではありませんが、何か特定の話題について知りたいことや質問があれ...
つまりChat Completion APIに投げる際に会話履歴を削っているのだということがわかる。
Chat Summary Memory Buffer
ChatMemoryBufferのtoken_limitにより入力コンテキストを一定量に制限することができるのは良いのだけども、当然ながら古い会話履歴は切り捨てられてしまうため、会話のコンテキストの一部が失われてしまうことになる。
ChatSummaryMemoryBufferはこの問題を回避するために、古い会話履歴を切り捨ててしまうのではなく「要約」することで、会話のコンテキストの欠落を緩和する。当然ながら「要約」が行われるので、LLMが呼ばれるという点については留意が必要。
ということでやってみるのだけども、これおそらくバグがある。
ここで会話履歴を要約するためのプロンプトを作ってるのだけども、chat_engineは裏でfunction callingを使ってインデックス検索を行っている。で、AssistantのTool Callのメッセージは msg.contentがNoneになる。例えばこんな感じ。
{
'additional_kwargs': {
'tool_calls': [
{
'function': {
'arguments': '{"input":"What ''did ''the ''author ''do ''growing ''up?"}',
'name': 'query_engine_tool'
},
'id': 'call_SUGsgqUD2SzECuJOUW5HA7tl',
'type': 'function'
}
]
},
'content': None,
'role': 'assistant'
}
これを文字列と結合しようとするとTypeError: unsupported operand type(s) for +: 'NoneType' and 'str'になる。
Issueはあげてあるので、v0.10.43以降で修正されるとは思うが、一旦ワークアラウンド的にこういう修正をいれる。ただし一旦モジュールインポートしてしまった後だと修正しても効かない気がするので、パッケージインストール直後に変更しておく。
(snip)
for msg in chat_history_to_be_summarized:
if msg.content is not None: # 追加
prompt += msg.role + ": " # 上に合わせてインデント
prompt += msg.content + "\n\n" # 上に合わせてインデント
(snip)
で実際はこんな感じで使う。
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatSummaryMemoryBuffer
import tiktoken
chat_store = SimpleChatStore()
# 要約用のモデルの設定
summarizer_model = "gpt-3.5-turbo-0125"
summarizer_llm = OpenAI(model_name=summarizer_model, max_toke=250)
# 要約するかどうかをトークン数でカウントするための関数(だと思う)
tokenizer_fn = tiktoken.encoding_for_model(summarizer_model).encode
chat_memory = ChatSummaryMemoryBuffer.from_defaults(
token_limit=50,
chat_store=chat_store,
chat_store_key="user1",
llm=summarizer_llm, # 要約に使うLLMを指定
tokenizer_fn=tokenizer_fn, # 要約時のトークンカウント用関数を指定
)
chat_engine = index.as_chat_engine(
memory=chat_memory,
similarity_top_k=5,
)
では実行してみる。
chat_engine.chat_repl()
===== Entering Chat REPL =====
Type "exit" to exit.Human: オグリキャップの血統について教えて。
Assistant: オグリキャップの血統について以下の情報があります:
- 父: ダンシングキャップ
- 母: ホワイトナルビー
### 父系(ダンシングキャップ)
ダンシングキャップは種牡馬としての成績はあまり優れていませんでしたが、ネイティヴダンサー系の種牡馬であり、時折大物を出すことがある血統です。血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評しています。### 母系(ホワイトナルビー)
ホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めています。5代母のクインナルビーは1953年の天皇賞(秋)を制しており、その子孫にはアンドレアモンやキョウエイマーチなどの重賞勝ち馬がいます。### 兄弟
オグリキャップの兄弟には以下の馬がいます:
- オグリローマン: 1994年桜花賞優勝馬
- オグリイチバン: 種牡馬
- オグリトウショウ: デビュー前から話題を集めた馬
オグリキャップはその血統背景からも注目される存在でした。
Human: ダンシングキャップについてもっと詳しい情報はある?
Assistant: ダンシングキャップは「ダートの短距離血統」として評価されていましたが、その種牡馬成績はあまり優れていませんでした。しかし、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評しています。ネイティヴダンサー系の種牡馬は時々大物を出すことがあり、オグリキャップもその一例とされています。ダンシングキャップの血統背景や競走成績についてさらに詳しい情報が必要であれば、追加の質問をしてください。
Human: ダンシングキャップの他の代表産駒を教えて。
Assistant: ダンシングキャップの代表産駒として最も有名なのはオグリキャップです。他の代表産駒についての情報が必要であれば、さらに詳しく調べることができます。Human: なるほどね、じゃあほんとに突然変異っぽい感じだね
Assistant: 確かに、Oguri Cap(オグリキャップ)はその血統からは予想しにくいほどの成功を収めた馬です。他の代表的な産駒についても知りたい場合は、さらに調べることができますので、どうぞお知らせください。Human: 次にオグリキャップの戦績について教えてくれるかな?
Assistant: オグリキャップの戦績は非常に優れたものでした。彼は1987年に地方競馬の笠松競馬場でデビューし、8連勝を含む12戦10勝という驚異的な成績を収めました。その後、1988年に中央競馬へ移籍し、重賞12勝(うちGI4勝)を達成しました。主な受賞歴としては、以下の通りです:
- 1988年度 JRA賞最優秀4歳牡馬
- 1989年度 JRA賞特別賞
- 1990年度 JRA賞最優秀5歳以上牡馬および年度代表馬
- 1991年 JRA顕彰馬
オグリキャップはその驚異的な戦績と人気から、日本競馬界において伝説的な存在となっています。
Human: GI4勝ってのはどのレース?
Assistant: オグリキャップのGI4勝のレース名は以下の通りです:
- マイルチャンピオンシップ
- 有馬記念
- 安田記念
- 天皇賞(秋)
これらのレースでの勝利が、オグリキャップの伝説的な地位を確立しました。
Human: ありがとう
Assistant: どういたしまして!他に何かお手伝いできることがあれば教えてください。Human: exit
トレーシングを見てみると、会話履歴が一定量のトークンを超えると、古い会話履歴の要約が行われて、以降の会話ではそれがシステムプロンプトとして設定され、会話のコンテキストの欠落を抑えているというのがわかる。
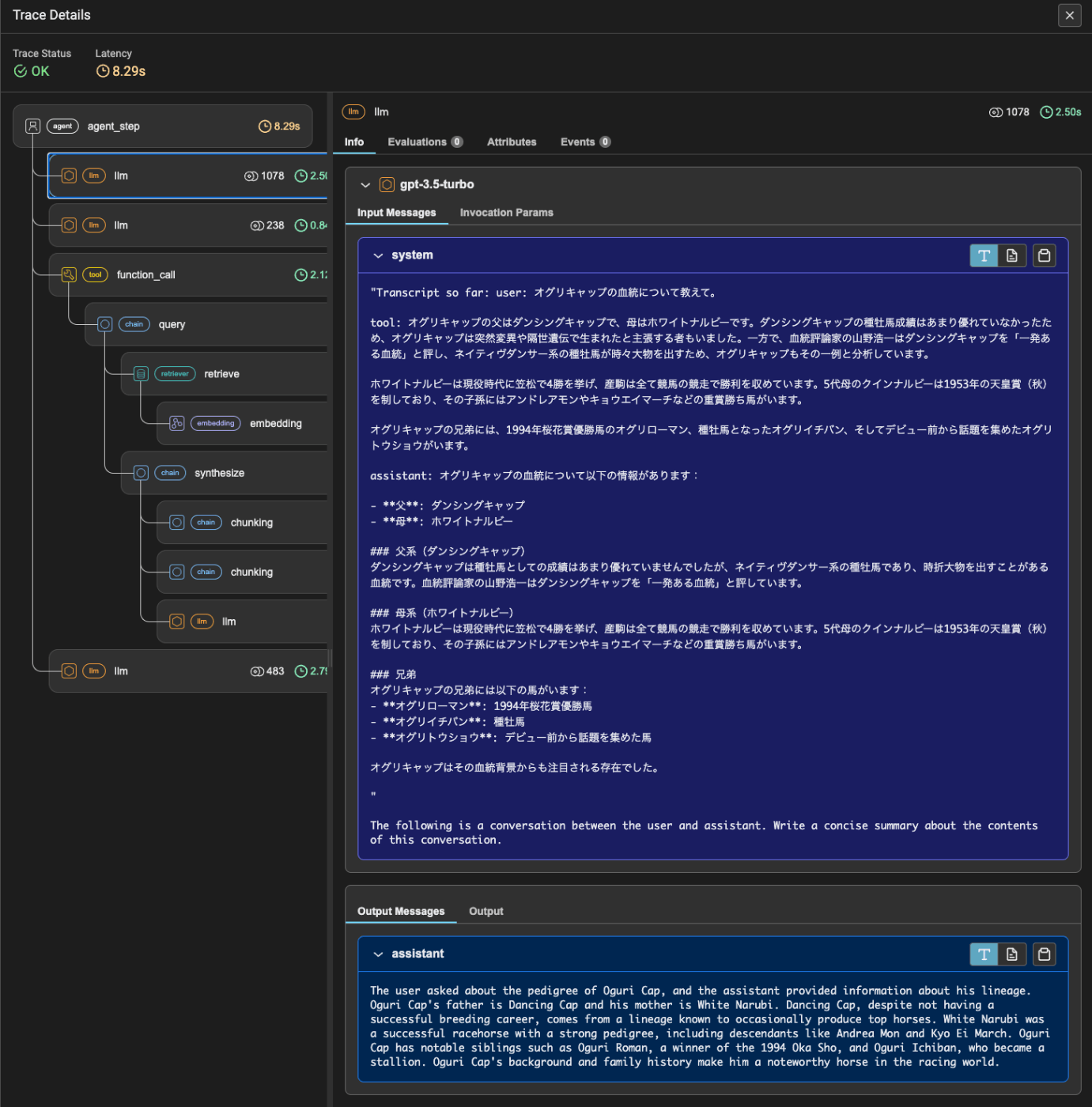

あと、要約時にも古い会話の要約は渡されているんだけども、会話が進むにつれて徐々に失われていく。この辺は致し方ないところではあるかも。


なお、ChatMemoryBufferと異なり、こちらはChat Storeの中身も書き換わる。
import json
json.loads(chat_store.json())["store"]["user1"]
[
{
'role': 'system',
'content': "The user inquired about the specific Grade 1 races that Oguri Cap won. The assistant provided the names of the four Grade 1 races that Oguri Cap won, which are the Mile Championship, Arima Kinen, Yasuda Kinen, and Tenno Sho (Autumn). These victories solidified Oguri Cap's legendary status in Japanese horse racing.",
'additional_kwargs': {
}
},
{
'role': 'user',
'content': 'ありがとう',
'additional_kwargs': {
}
},
{
'role': 'assistant',
'content': 'どういたしまして!他に何かお手伝いできることがあれば教えてください。',
'additional_kwargs': {
}
}
]
今回は極端なトークン制限を設定しているが、実際にやるときにはある程度十分な値にする必要があるし、あと最終的には要約のトークンも含まれると思うのでそちらも踏まえて設定する必要がある。そして、要約が行われる場合は当然LLMが使用されるため、レスポンスが遅くなるという点に留意する必要がある。
Vector Memory
Vector Memoryは、会話履歴をベクトルDBに入れて、会話のターンごとにクエリに最も関連する過去の会話履歴を取得して、それを会話のコンテキストとするものらしい。ちょっと自分的にはユースケースやメリットがピンときていないのだけども。
ただ、これはちょっとChatMemoryBufferやChatSummaryMemoryBufferとは使い方が異なる様子。一旦はドキュメントにある通りの使い方を見てみる。
こんな感じでVectorMemoryを初期化する。
from llama_index.core.memory import VectorMemory
from llama_index.embeddings.openai import OpenAIEmbedding
vector_memory = VectorMemory.from_defaults(
vector_store=None, # デフォルトのオンメモリベクトルストアを使う場合は"None"にしておく
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 1},
)
今回はデフォルトのオンメモリベクトルストアを使う。ちなみに、他のベクトルストアを使う場合はベクトルストアモジュールにdelete_nodesメソッドが実装されている必要があるらしい。
ざっとレポジトリを検索した限り、これが実装されているのは、
- Qdrant
- Chroma
- LanceDB
- オンメモリベクトルストア
だけだったので、他のベクトルDBを使う場合には現時点では上記の3つしか対応してないということになりそう。
そしてベクトルストアを使うということはEmbeddingが必要になるのでこれも渡してやる必要があるし、ある種retriever的な使い方になるので、retrieverのパラメータも渡してやる感じ。
ではこのベクトルメモリに会話履歴を投入する。上で試した会話履歴を少しいじって登録用のデータを用意した。
from llama_index.core.llms import ChatMessage
msgs = [
ChatMessage.from_str("オグリキャップの血統について教えて。", "user"),
ChatMessage.from_str("オグリキャップは、父ダンシングキャップ、母ホワイトナルビーという血統です。兄弟にはオグリローマンなどがいます。", "assistant"),
ChatMessage.from_str("ダンシングキャップについてもっと教えて。", "user"),
ChatMessage.from_str("ダンシングキャップはネイティヴダンサー系の「ダートの短距離血統」として評価されていますが、種牡馬成績はあまり優れていません。", "assistant"),
ChatMessage.from_str("オグリキャップ以外のダンシングキャップの代表産駒は?", "user"),
ChatMessage.from_str("ダンシングキャップの産駒に目立った活躍馬はいません。オグリキャップが唯一の代表産駒と言えると思います。", "assistant"),
ChatMessage.from_str("じゃあ血統的にはほんとに突然変異と言ってもいいぐらいだね。", "user"),
ChatMessage.from_str("そうですね。オグリキャップは血統からは予想しにくいほどの成功を収めましたが、ネイティヴダンサー系の種牡馬は時々大物を出すという特徴があるようです。", "assistant"),
ChatMessage.from_str("次にオグリキャップの戦績について教えてくれるかな?", "user"),
ChatMessage.from_str("オグリキャップは、地方競馬の笠松競馬場でデビューし、8連勝を含む12戦10勝という驚異的な成績を収め、さらに中央競馬へ移籍後も、重賞12勝(うちGI4勝)という素晴らしい戦績を残しています。", "assistant"),
ChatMessage.from_str("勝利したGIレースについて教えて。", "user"),
ChatMessage.from_str("オグリキャップは次の4つのGIで勝利しています: マイルチャンピオンシップ(1989年)、有馬記念(1988年)、安田記念(1990年)、有馬記念(1990年)", "assistant"),
ChatMessage.from_str("有馬記念2回ってのはすごいね。", "user"),
ChatMessage.from_str("はい、特に1990年の有馬記念は、引退レースでの「奇跡の復活」として多くのファンの記憶に残る名勝負となりました。", "assistant"),
ChatMessage.from_str("なんで有馬記念は奇跡の復活って言われたの?", "user"),
ChatMessage.from_str("この年の秋、オグリキャップは惨敗続きであり、競走馬としてピークを過ぎたと見られていましたが、引退レースである有馬記念で低人気を覆して掌理したためです。", "assistant"),
]
for m in msgs:
vector_memory.put(m)
では検索してみる。
msgs = vector_memory.get("ダンシングキャップの血統は?")
msgs
[
ChatMessage(role=<MessageRole.USER: 'user'>, content='ダンシングキャップについてもっと教えて。', additional_kwargs={}),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>, content='ダンシングキャップはネイティヴダンサー系の「ダートの短距離血統」として評価されていますが、種牡馬成績はあまり優れていません。', additional_kwargs={})
]
msgs = vector_memory.get("有馬記念での成績はどうだった?")
msgs
[
ChatMessage(role=<MessageRole.USER: 'user'>, content='有馬記念2回ってのはすごいね。', additional_kwargs={}),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>, content='はい、特に1990年の有馬記念は、引退レースでの「奇跡の復活」として多くのファンの記憶に残る名勝負となりました。', additional_kwargs={})
]
クエリで検索すると、"user"/"assistant"の一連のペアで結果が返ってくる。ベクトルメモリ初期化時の{"similarity_top_k": 1}はペア数を指しているということになる。
なおメモリの消去は以下。
vector_memory.reset()
で、冒頭に記載した、
ただ、これはちょっと
ChatMemoryBufferやChatSummaryMemoryBufferとは使い方が異なる様子。
というところだけども、VectorMemoryにはchat_storeパラメータが存在せず、またVectorMemory自体がある意味chat_store的な要素も兼ねているように思えるので、例えばこんな感じでchat engineを作ったとする。
from llama_index.core.memory import VectorMemory
from llama_index.embeddings.openai import OpenAIEmbedding
vector_memory = VectorMemory.from_defaults(
vector_store=None,
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 1},
)
chat_engine = index.as_chat_engine(
memory=vector_memory,
similarity_top_k=5,
)
chat_engine.chat_repl()
===== Entering Chat REPL =====
Type "exit" to exit.Human: オグリキャップの血統について教えて。
Assistant: オグリキャップの血統について以下の情報があります。
- 父: ダンシングキャップ
- 母: ホワイトナルビー
父系
ダンシングキャップは種牡馬としての成績はさほど優れていませんでしたが、血統評論家の山野浩一は「一発ある血統」と評しています。
母系
ホワイトナルビーは現役時代に笠松で4勝を挙げ、その産駒は全て競馬の競走で勝利を収めています。
兄弟
オグリキャップの兄弟には以下の馬がいます。
- オグリローマン: 1994年桜花賞優勝馬
- オグリイチバン: 種牡馬
- オグリトウショウ
オグリキャップはその血統背景から、突然変異や隔世遺伝で生まれた競走馬と主張する者もいましたが、実際にはその血統の中に潜在的な競走能力が秘められていたと言えるでしょう。
Human: ダンシングキャップについてもっと詳しい情報はある?
Assistant: ダンシングキャップは「ダートの短距離血統」として評価されており、種牡馬成績はさほど優れていませんでした。しかし、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評しています。ネイティヴダンサー系の種牡馬は時々大物を出すため、オグリキャップもそのような金の鉱脈を掘り当てたと分析されています。Human: あれ、今なんの話してたっけ?
Assistant: オグリキャップという競走馬に関する話をしていました。具体的には、レース前の体調やレース中の状況、関係者の見解などについて話していました。Human: exit
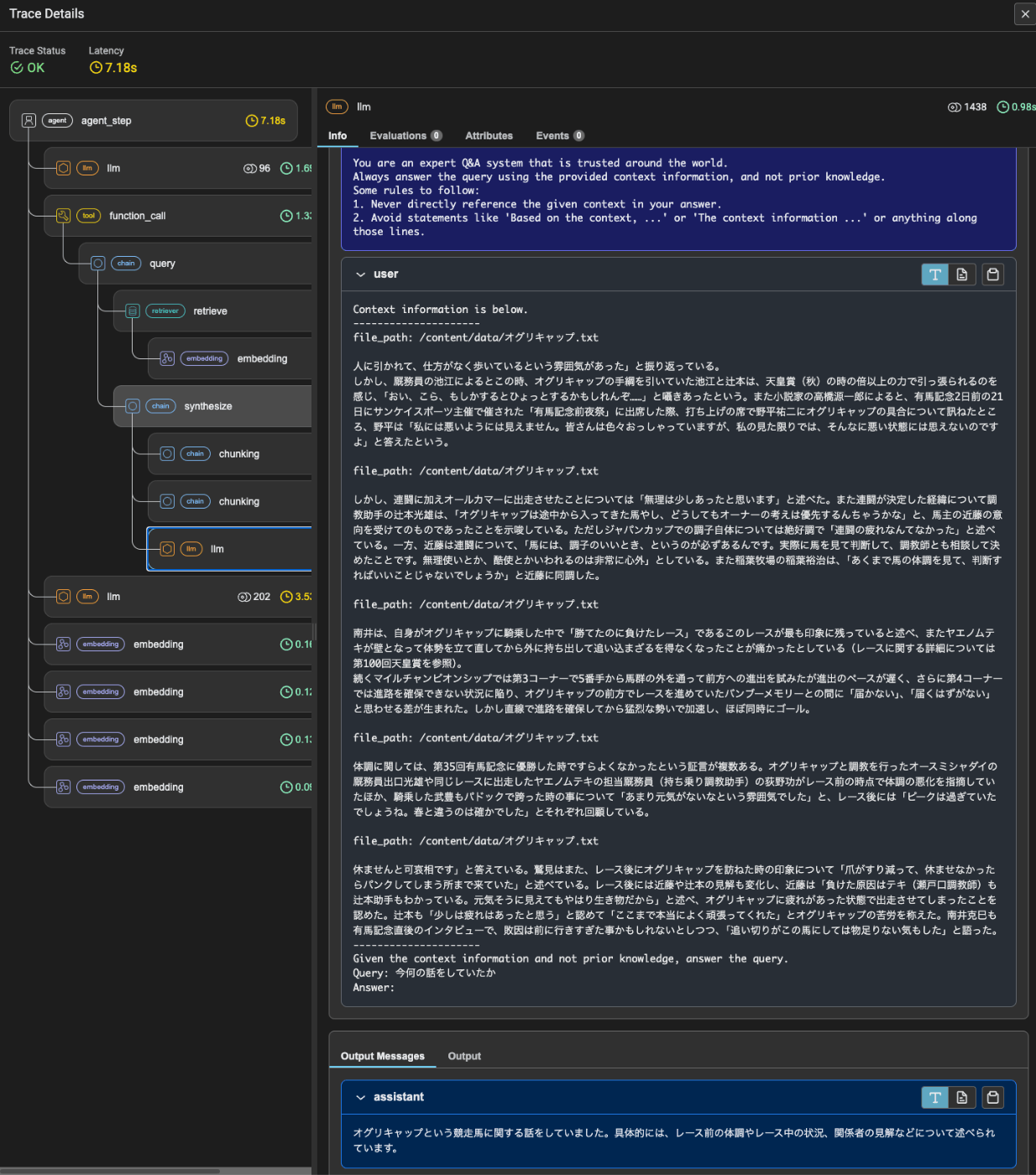
最後のメッセージを見ると、どうも会話履歴として使用されていないように見える。最後のクエリと回答の箇所のトレースを見てみる。
LLMへのリクエストを見ると、過去の会話履歴は含まれていない。そして「あれ、今なんの話してたっけ?」というクエリに対してインデックスを検索した結果から生成されたものであることがわかる。つまりメモリとして機能していない。

VectorMemoryから検索していると思われる箇所はここ。ただ、トレースの構成を見るに、この内容を踏まえた回答生成にはつながっていない。
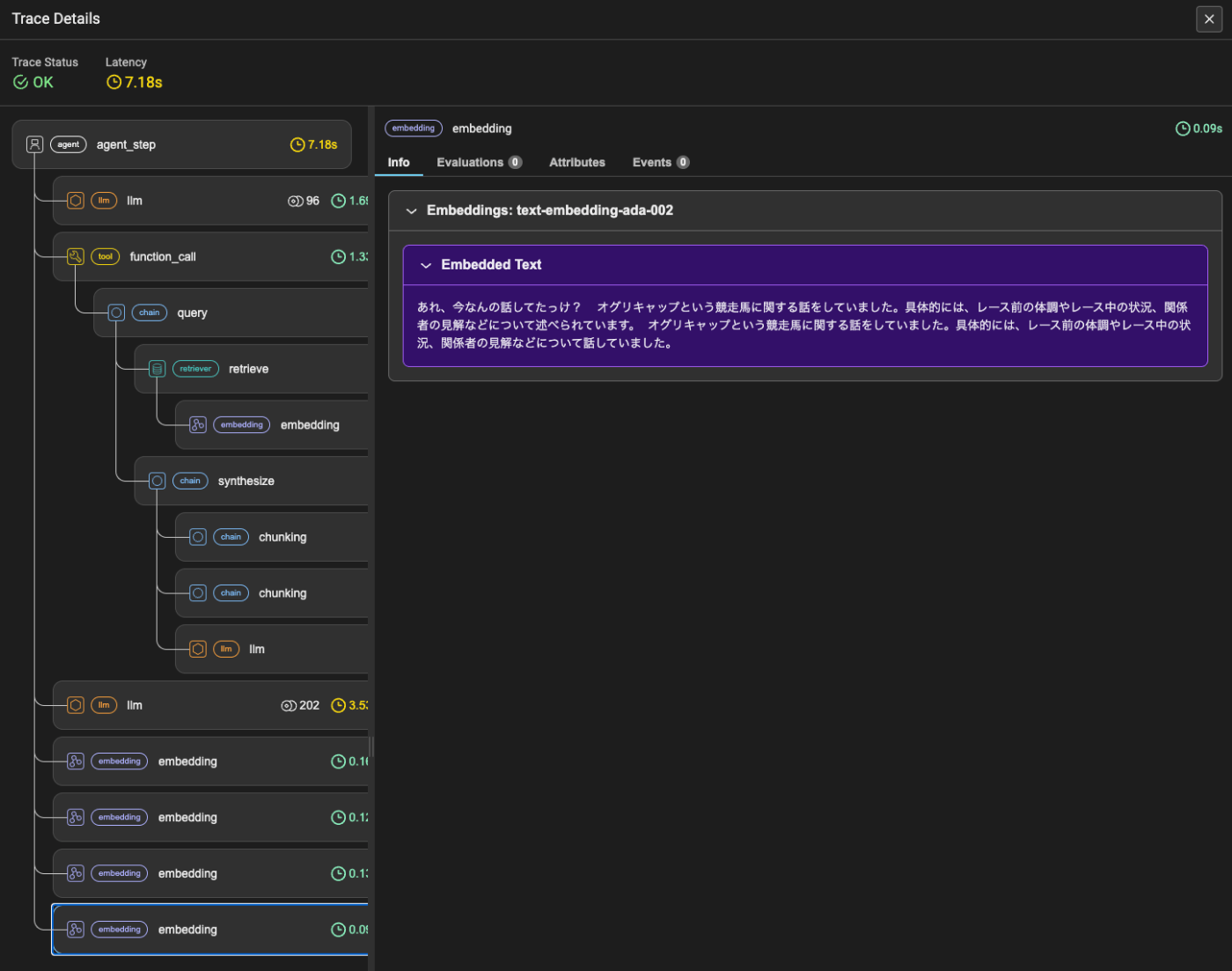
ということでこのVector Memoryはchat engineで会話履歴を保持するためのメモリとして使うものではなさそうで、おそらく次のSimple Composable Memoryと組み合わせて活用するものだと思われる。
Simple Composable Memory
SimpleComposableMemoryは、複数のメモリリソースをコンテキストとして使用する。
-
primary_memory- エージェントのメインの会話履歴として使用される
- 例:
ChatMemoryBuffer
-
secondary_memory_sources- システムプロンプトメッセージのみに注入される。
- 例:
VectorMemory
つまりprimary_memoryは直近の会話履歴を保持する短期記憶、secondary_memory_sourcesは過去の会話履歴から関連する会話を取得するというような長期記憶、というような使い方になり、主にエージェント向けを想定して作られている模様。

referred from https://docs.llamaindex.ai/en/stable/examples/agent/memory/composable_memory/#how-simplecomposablememory-works
では早速やってみる。ドキュメントで上げられているサンプルがいまいち実用的ではないように思えたので、なにかしら題材を変えたかったのだけど、良い題材を思いつかなかった。。。ので、今回はサンプルに従って、まずSimpleComposableMemory単体での動きを確認してみる。
まず以下の2つのメモリを用意する。
-
primary_memory:ChatMemoryBuffer -
secondary_memory_sources:VectorMemory
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer, VectorMemory
from llama_index.embeddings.openai import OpenAIEmbedding
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(
token_limit=1000,
chat_store=chat_store,
chat_store_key="user1",
)
vector_memory = VectorMemory.from_defaults(
vector_store=None,
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 1},
)
そしてVectorMemoryにいくつかのメッセージを登録しておく。
from llama_index.core.llms import ChatMessage
msgs = [
ChatMessage.from_str("あなたは親切なAIアシスタントです。", "system"),
ChatMessage.from_str("太郎さんの好物はラーメンです。", "user"),
ChatMessage.from_str("たしかに太郎さんはラーメンが大好きですよね。", "assistant"),
ChatMessage.from_str("花子さんの方はハンバーグが好きらしいですけどね。", "user"),
ChatMessage.from_str("花子さんの好みは太郎さんとは違うんですね。", "assistant"),
]
vector_memory.set(msgs)
そしてSimpleComposableMemoryを使ってこの2つのメモリをラップする。
from llama_index.core.memory import SimpleComposableMemory
composable_memory = SimpleComposableMemory.from_defaults(
primary_memory=chat_memory,
secondary_memory_sources=[vector_memory],
)
SimpleComposableMemoryの状態をそれぞれのメモリごとに確認してみる。
まず、primary_memory。
ChatMemoryBuffer(chat_store=SimpleChatStore(store={}), chat_store_key='user1', token_limit=1000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding 'cl100k_base'>>, allowed_special='all'))
まだ会話履歴はまだ空のまま。
次に、secondary_memory_sources。
composable_memory.secondary_memory_sources
[VectorMemory(vector_index=<llama_index.core.indices.vector_store.base.VectorStoreIndex object at 0x7af32f3f09a0>, retriever_kwargs={'similarity_top_k': 1}, batch_by_user_message=True, cur_batch_textnode=TextNode(id_='cbb4a09e-3ccc-49df-9f4f-e02fcbd0ba19', embedding=None, metadata={'sub_dicts': [{'role': <MessageRole.USER: 'user'>, 'content': '花子さんの方はハンバーグが好きらしいですけどね。', 'additional_kwargs': {}}, {'role': <MessageRole.ASSISTANT: 'assistant'>, 'content': '花子さんの好みは太郎さんとは違うんですね。', 'additional_kwargs': {}}]}, excluded_embed_metadata_keys=['sub_dicts'], excluded_llm_metadata_keys=['sub_dicts'], relationships={}, text='花子さんの方はハンバーグが好きらしいですけどね。 花子さんの好みは太郎さんとは違うんですね。', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'))]
こちらは最初に登録したメッセージのうちシステムメッセージ以外のメッセージが登録されているのがわかる。
ではSimpleComposableMemoryに会話履歴を登録する。putメソッドを使う。
from llama_index.core.llms import ChatMessage
msgs = [
ChatMessage.from_str("あなたは陽気で明るい日本語のAIアシスタントです。", "system"),
ChatMessage.from_str("次郎さんはアイスクリームが大好きらしいです。", "user"),
]
for m in msgs:
composable_memory.put(m)
再度primary_memoryとsecondary_memory_sourcesの状態を確認してみる。
composable_memory.primary_memory
ChatMemoryBuffer(chat_store=SimpleChatStore(store={'user1': [ChatMessage(role=<MessageRole.SYSTEM: 'system'>, content='あなたは陽気で明るい日本語のAIアシスタントです。', additional_kwargs={}), ChatMessage(role=<MessageRole.USER: 'user'>, content='次郎さんはアイスクリームが大好きらしいです。', additional_kwargs={})]}), chat_store_key='user1', token_limit=1000, tokenizer_fn=functools.partial(<bound method Encoding.encode of <Encoding 'cl100k_base'>>, allowed_special='all'))
composable_memory.secondary_memory_sources
[VectorMemory(vector_index=<llama_index.core.indices.vector_store.base.VectorStoreIndex object at 0x7ca7b644cf70>, retriever_kwargs={'similarity_top_k': 2}, batch_by_user_message=True, cur_batch_textnode=TextNode(id_='7ffb934e-bdf9-4465-b3aa-78a085468578', embedding=None, metadata={'sub_dicts': [{'role': <MessageRole.USER: 'user'>, 'content': '次郎さんはアイスクリームが大好きらしいです。', 'additional_kwargs': {}}]}, excluded_embed_metadata_keys=['sub_dicts'], excluded_llm_metadata_keys=['sub_dicts'], relationships={}, text='次郎さんはアイスクリームが大好きらしいです。', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'))]
composable_memoryに会話を登録すると、primary_memoryとsecondary_memory_sourcesの両方にメッセージが登録されるということがわかる。
でここからgetメソッドを使ってメモリを読み出してみる。composable_memoryからのメモリを取り出す場合はメッセージを与えてやる必要がある。
msgs = composable_memory.get("太郎さんの好きなものは何?")
msgs
[ChatMessage(role=<MessageRole.SYSTEM: 'system'>, content='あなたは陽気で明るい日本語のAIアシスタントです。\n\nBelow are a set of relevant dialogues retrieved from potentially several memory sources:\n\n=====Relevant messages from memory source 1=====\n\n\tUSER: 太郎さんの好物はラーメンです。\n\tASSISTANT: たしかに太郎さんはラーメンが大好きですよね。\n\n=====End of relevant messages from memory source 1======\n\nThis is the end of the retrieved message dialogues.', additional_kwargs={}),
ChatMessage(role=<MessageRole.USER: 'user'>, content='次郎さんはアイスクリームが大好きらしいです。', additional_kwargs={})]
わかりやすく出力させるとこう。
for idx, m in enumerate(msgs):
print(f"----- {idx} -----")
print(m)
----- 0 -----
system: あなたは陽気で明るい日本語のAIアシスタントです。Below are a set of relevant dialogues retrieved from potentially several memory sources:
=====Relevant messages from memory source 1=====
USER: 太郎さんの好物はラーメンです。
ASSISTANT: たしかに太郎さんはラーメンが大好きですよね。=====End of relevant messages from memory source 1======
This is the end of the retrieved message dialogues.
----- 1 -----
user: 次郎さんはアイスクリームが大好きらしいです。
SimpleComposableMemoryはメッセージを与えて取り出すと、secondary_memory_sourcesにある過去の会話履歴から類似の内容を取り出す、そしてprimary_memoryから取り出した会話履歴に、システムメッセージとして注入するということになる。
別のメッセージを与えてみる。
msgs = composable_memory.get("花子さんの好物は?")
for idx, m in enumerate(msgs):
print(f"----- {idx} -----")
print(m)
----- 0 -----
system: あなたは陽気で明るい日本語のAIアシスタントです。Below are a set of relevant dialogues retrieved from potentially several memory sources:
=====Relevant messages from memory source 1=====
USER: 花子さんの方はハンバーグが好きらしいですけどね。
ASSISTANT: 花子さんの好みは太郎さんとは違うんですね。=====End of relevant messages from memory source 1======
This is the end of the retrieved message dialogues.
----- 1 -----
user: 次郎さんはアイスクリームが大好きらしいです。
システムメッセージに含まれた過去の会話履歴だけが更新されているのがわかる。
もう一つ。
msgs = composable_memory.get("次郎さんの好物は?")
for idx, m in enumerate(msgs):
print(f"----- {idx} -----")
print(m)
----- 0 -----
system: あなたは陽気で明るい日本語のAIアシスタントです。
----- 1 -----
user: 次郎さんはアイスクリームが大好きらしいです。
既にprimary_memoryの会話履歴の中にある場合は、システムメッセージにはsecondary_memory_sourcesからの過去の履歴は含まれない、ということがわかる。
なるほど、確かに短期・長期の会話履歴として使えそうな雰囲気がわかる。
メモリを消去するには、VectorMemoryと同様にresetメソッドを使うが、primary_memory、secondary_memory_sourcesのそれぞれで消去、composable memory経由で両方まるっと消去というのができるっぽい。
ドキュメントで紹介されているパターンはprimary_memoryだけを消す、composable memory経由で両方消すというもの。
composable_memory.primary_memory.reset()
composable_memory.reset()
secondary_memory_sourcesだけ消すというのが例示されていないのでやってみる。
composable_memory.secondary_memory_sources[0].reset()
composable_memory.secondary_memory_sources[0].get()
[]
composable_memory.primary_memory.get()
[ChatMessage(role=<MessageRole.SYSTEM: 'system'>, content='あなたは陽気で明るい日本語のAIアシスタントです。', additional_kwargs={}),
ChatMessage(role=<MessageRole.USER: 'user'>, content='次郎さんはアイスクリームが大好きらしいです。', additional_kwargs={})]
こちらも問題なくできる。
では両方消す。
composable_memory.reset()
print(composable_memory.primary_memory.get())
print(composable_memory.secondary_memory_sources[0].get())
[]
[]
両方消えた。
SimpleComposableMemoryを使えば短期・長期で記憶を分けれるというような雰囲気はつかめたが、これを実際に使うにはどうすればいいか?
ドキュメントでは複数のエージェント間で長期記憶を共有する例が紹介されているので、これに従ってやってみる。
非同期を使用するのでnotebookのおまじない
import nest_asyncio
nest_asyncio.apply()
composable_memoryを使ったエージェントを定義。エージェントには、composable_memoryを使ったメモリと、シンプルな計算を行うツールを提供する。
from llama_index.llms.openai import OpenAI
from llama_index.core.tools import FunctionTool
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.memory import ChatMemoryBuffer, VectorMemory
from llama_index.embeddings.openai import OpenAIEmbedding
# composable_memoryを使ったメモリの定義
vector_memory = VectorMemory.from_defaults(
vector_store=None,
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 2},
)
chat_memory_buffer = ChatMemoryBuffer.from_defaults()
composable_memory = SimpleComposableMemory.from_defaults(
primary_memory=chat_memory_buffer,
secondary_memory_sources=[vector_memory],
)
# Agentのツールを定義
def multiply(a: int, b: int) -> int:
"""2つの整数を掛け算して、結果を整数で返す。"""
return a * b
def mystery(a: int, b: int) -> int:
"""2つの整数を処理する謎の関数。"""
return a**2 - b**2
multiply_tool = FunctionTool.from_defaults(fn=multiply)
mystery_tool = FunctionTool.from_defaults(fn=mystery)
# ツールとメモリを使用するエージェントの定義
llm = OpenAI(model="gpt-3.5-turbo-0613")
agent_worker = FunctionCallingAgentWorker.from_tools(
[multiply_tool, mystery_tool],
llm=llm,
verbose=True
)
agent = agent_worker.as_agent(memory=composable_memory)
ではこのエージェントに、質問してみる。
response = agent.chat("5と6を謎の関数に渡すと結果はどうなる?")
Added user message to memory: 5と6を謎の関数に渡すと結果はどうなる?
=== Calling Function ===
Calling function: mystery with args: {"a": 5, "b": 6}
=== Function Output ===
-11
=== LLM Response ===
5と6を謎の関数に渡すと、結果は-11になります。
もう一つ。
response = agent.chat("2 かける 3 は?")
Added user message to memory: 2 かける 3 は?
=== Calling Function ===
Calling function: multiply with args: {"a": 2, "b": 3}
=== Function Output ===
6
=== LLM Response ===
2かける3は6です。
どちらもツールを使ってエージェントが回答を生成しているのがわかる。
メモリを見てみる。少し出力が見にくいのでいじっている。
composable_memory.primary_memory
ChatMemoryBuffer(chat_store=SimpleChatStore(store={
'chat_history': [
ChatMessage(role=<MessageRole.USER: 'user'>,
content='5と6を謎の関数に渡すと結果はどうなる?',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content=None,
additional_kwargs={
'tool_calls': [
ChatCompletionMessageToolCall(id='call_2itmKKngGYojlvlbla0bUlKu',
function=Function(arguments='{\n "a": 5,\n "b": 6\n}',
name='mystery'),
type='function')
]
}
),
ChatMessage(role=<MessageRole.TOOL: 'tool'>,
content='-11',
additional_kwargs={
'name': 'mystery',
'tool_call_id': 'call_2itmKKngGYojlvlbla0bUlKu'
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='5と6を謎の関数に渡すと、結果は-11になります。',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.USER: 'user'>,
content='2 かける 3 は?',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content=None,
additional_kwargs={
'tool_calls': [
ChatCompletionMessageToolCall(id='call_Z5s49YuMdtRwYuCA3VfYYUqD',
function=Function(arguments='{\n "a": 2,\n "b": 3\n}',
name='multiply'),
type='function')
]
}
),
ChatMessage(role=<MessageRole.TOOL: 'tool'>,
content='6',
additional_kwargs={
'name': 'multiply',
'tool_call_id': 'call_Z5s49YuMdtRwYuCA3VfYYUqD'
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='2かける3は6です。',
additional_kwargs={
}
)
]
}
),
chat_store_key='chat_history',
token_limit=3000,
tokenizer_fn=functools.partial(<boundmethodEncoding.encodeof<Encoding'cl100k_base'>>,
allowed_special='all'))
composable_memory.secondary_memory_sources[0]
VectorMemory(vector_index=<llama_index.core.indices.vector_store.base.VectorStoreIndexobjectat0x7eb648fc9060>,
retriever_kwargs={
'similarity_top_k': 2
},
batch_by_user_message=True,
cur_batch_textnode=TextNode(id_='fe2fa265-7860-44e2-90a0-98c33830f96d',
embedding=None,
metadata={
'sub_dicts': [
{
'role': <MessageRole.USER: 'user'>,
'content': '2 かける 3 は?',
'additional_kwargs': {
}
},
{
'role': <MessageRole.ASSISTANT: 'assistant'>,
'content': None,
'additional_kwargs': {
'tool_calls': [
{
'id': 'call_Z5s49YuMdtRwYuCA3VfYYUqD',
'function': {
'arguments': '{\n "a": 2,\n "b": 3\n}',
'name': 'multiply'
},
'type': 'function'
}
]
}
},
{
'role': <MessageRole.TOOL: 'tool'>,
'content': '6',
'additional_kwargs': {
'name': 'multiply',
'tool_call_id': 'call_Z5s49YuMdtRwYuCA3VfYYUqD'
}
},
{
'role': <MessageRole.ASSISTANT: 'assistant'>,
'content': '2かける3は6です。',
'additional_kwargs': {
}
}
]
},
excluded_embed_metadata_keys=[
'sub_dicts'
],
excluded_llm_metadata_keys=[
'sub_dicts'
],
relationships={
},
text='2 かける 3 は? 6 2かける3は6です。',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'))
primary_memoryとsecondary_memory_resourcesの両方に会話およびツールの実行に関する内容が記録されているのがわかる。なお、secondary_memory_resourcesはクエリを与えるのが本来の使い方なので上記の参照の仕方では全ては表示されていないが、実際には以下の通り最初のクエリの会話履歴も入っている。
composable_memory.secondary_memory_sources[0].get("5と6を謎の関数に渡すと結果はどうなる?")
[
ChatMessage(role=<MessageRole.USER: 'user'>,
content='5と6を謎の関数に渡すと結果はどうなる?',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content=None,
additional_kwargs={
'tool_calls': [
{
'id': 'call_2itmKKngGYojlvlbla0bUlKu',
'function': {
'arguments': '{\n "a": 5,\n "b": 6\n}',
'name': 'mystery'
},
'type': 'function'
}
]
}
),
ChatMessage(role=<MessageRole.TOOL: 'tool'>,
content='-11',
additional_kwargs={
'name': 'mystery',
'tool_call_id': 'call_2itmKKngGYojlvlbla0bUlKu'
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='5と6を謎の関数に渡すと、結果は-11になります。',
additional_kwargs={
}
)
]
では、過去の記憶を持ったエージェントが新しくセッションを行う、というのをやってみる。
まず、過去の記憶がない場合というのを擬似的に再現してみる。
llm = OpenAI(model="gpt-3.5-turbo-0613")
agent_worker = FunctionCallingAgentWorker.from_tools(
[multiply_tool, mystery_tool], llm=llm, verbose=True
)
agent_without_memory = agent_worker.as_agent()
response = agent_without_memory.chat(
"さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算はしちゃだめだよ。"
)
Added user message to memory: さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算はしちゃだめだよ。
=== LLM Response ===
申し訳ありませんが、私はユーザーの入力履歴を保持していませんので、再計算することはできません。もし結果を覚えていない場合は、再度謎の関数を実行して結果を確認してください。
エージェントの会話履歴も見てみる。
agent_without_memory.chat_history
[
ChatMessage(role=<MessageRole.USER: 'user'>,
content='さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算はしちゃだめだよ。',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='申し訳ありませんが、私はユーザーの入力履歴を保持していませんので、再計算することはできません。もし結果を覚えていない場合は、再度謎の関数を実行して結果を確認してください。',
additional_kwargs={
}
)
]
当然ながら記憶がない。そのうえで、再計算も禁止されたことでツールが使えないため、回答ができなくなってしまっている。
次に、上で使用した過去の記憶を使って、新しくエージェントを作成する。
llm = OpenAI(model="gpt-3.5-turbo-0613")
agent_worker = FunctionCallingAgentWorker.from_tools(
[multiply_tool, mystery_tool], llm=llm, verbose=True
)
composable_memory = SimpleComposableMemory.from_defaults(
# primary_memoryは初期化した新しいものを与える
primary_memory=ChatMemoryBuffer.from_defaults(),
# secondary_memory_sourcesは上で使用したものを使うが、
# 後ほど再度使うので、直接使わずにここではコピーしている
secondary_memory_sources=[
vector_memory.copy(
deep=True
)
],
)
agent_with_memory = agent_worker.as_agent(memory=composable_memory)
で質問してみる。
response = agent_with_memory.chat(
"さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算しないで答えて。"
)
Added user message to memory: さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算しないで答えて。
=== LLM Response ===
さっきの結果は-11でした。
response = agent_with_memory.chat(
"さっき計算した 2 かける 3の結果っていくつだっけ?再計算しないで答えて。"
)
実際にはどのようなことが起きているか?再度エージェントを設定しなして確認してみる。
llm = OpenAI(model="gpt-3.5-turbo-0613")
agent_worker = FunctionCallingAgentWorker.from_tools(
[multiply_tool, mystery_tool], llm=llm, verbose=True
)
composable_memory = SimpleComposableMemory.from_defaults(
primary_memory=ChatMemoryBuffer.from_defaults(),
secondary_memory_sources=[
vector_memory.copy(
deep=True
)
],
)
agent_with_memory = agent_worker.as_agent(memory=composable_memory)
エージェントのメモリに直接クエリを与えてgetしてみる。
agent_with_memory.memory.get(
"さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算しないで答えて。"
)
[
ChatMessage(role=<MessageRole.SYSTEM: 'system'>,
content='You are a helpful assistant.\n\nBelow are a set of relevant dialogues retrieved from potentially several memory sources:\n\n=====Relevant messages from memory source 1=====\n\n\tUSER: 5と6を謎の関数に渡すと結果はどうなる?\n\tASSISTANT: None\n\tTOOL: -11\n\tASSISTANT: 5と6を謎の関数に渡すと、結果は-11になります。\n\n=====End of relevant messages from memory source 1======\n\nThis is the end of the retrieved message dialogues.',
additional_kwargs={
}
)
]
もうちょっと見やすく。
print(
agent_with_memory.memory.get(
"さっき5と6を謎の関数で実行した結果っていくつだったっけ?再計算しないで答えて。"
)[0]
)
system: You are a helpful assistant.
Below are a set of relevant dialogues retrieved from potentially several memory sources:
=====Relevant messages from memory source 1=====
USER: 5と6を謎の関数に渡すと結果はどうなる?
ASSISTANT: None
TOOL: -11
ASSISTANT: 5と6を謎の関数に渡すと、結果は-11になります。=====End of relevant messages from memory source 1======
This is the end of the retrieved message dialogues.
システムプロンプトに、与えたクエリに関連する過去の会話履歴が含まれているのがわかる。
SimpleComposableMemoryが有効になったエージェントの.chatメソッドでは、内部で
- SimpleComposableMemory経由で、過去の会話履歴(secondary_memory_sources)からクエリに関連する会話を検索する
- この検索結果を含むシステムプロンプトを生成する
- 上記のシステムプロンプトを含んだ通常の会話履歴(primary_memory)とともに、クエリをLLMに送信する。
- LLMからの回答を新しい会話履歴として、SimpleComposableMemory経由でprimary_memoryとsecondary_memory_sourcesの両方に追加する
というような流れになると思われる。
まとめ
冒頭にも書いたけど、LlamaIndexのメモリ機能はLangChainなどに比べるととても弱いと感じていて、このあたりが強化されるというのは嬉しい。シンプルにChat Summary Memory Bufferが追加されただけでも使いやすくなると思う。あとはインテグレーションが増えればいいなと思う、DynamoDBとかね。まあ自分で実装すればいいという話でもあるのだけど、公式がサポートしてくれるほうが当然ながら嬉しい。
最近のLlamaIndexでよく聞くキーワードに"Agentic RAG"というのがあり、RAG向けと思われていたLlamaIndexでもエージェントに力を入れているという風に感じる。
チャットアプリなどではメモリは会話のコンテキストを維持するためには重要なのだけども、エージェントでも自分の生成した内容を過去の結果を踏まえて自己改善していく「Refrection」のプロセスにおいてメモリが使用される。
実際、この新しいメモリ機能は、以下の「エージェント向けにはどのようにメモリを作れば良いか?」というポストのフィードバックが踏まえられている様子。
なのでRAG向けと言われているLlamaIndexでも今後はエージェント周りの機能がいろいろと充実していくのではないかと思う。Vector MemoryとSimple Composable Memoryについてはそのための新しいメモリ機能という風に感じた。
ただ、上の方で少し書いているけども、Vector Memoryも、そして少し試してみたのだけどSimple Composable Memoryも、index.as_chat engineでは動かないように思える。
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer, VectorMemory, SimpleComposableMemory
from llama_index.core.llms import ChatMessage
vector_memory = VectorMemory.from_defaults(
vector_store=None,
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 2},
)
# インデックスに存在しない情報をsecondary_memory_sourcesにセット
vector_memory.set([
ChatMessage.from_str("ホワイトナルビーの父はなんという馬ですか?", "user"),
ChatMessage.from_str("ホワイトナルビーの父はシルバーシャークです。", "assistant"),
])
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(
token_limit=1000,
chat_store=chat_store,
chat_store_key="user1",
)
composable_memory = SimpleComposableMemory.from_defaults(
primary_memory=chat_memory,
secondary_memory_sources=[vector_memory],
)
chat_engine = index.as_chat_engine(
memory=composable_memory,
similarity_top_k=5,
)
response = chat_engine.chat("オグリキャップの血統について教えて")
print(response
オグリキャップの血統について以下の情報があります:
- 父: ダンシングキャップ
- 母: ホワイトナルビー
### 父系
- ダンシングキャップは種牡馬成績があまり優れていなかったため、オグリキャップは突然変異や隔世遺伝で生まれたとする意見もあります。しかし、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評しています。
### 母系
- ホワイトナルビーは現役時代に4勝を挙げ、その産駒は全て競馬で勝利を収めています。
### 兄弟
- オグリローマン: 1994年桜花賞優勝馬
- オグリイチバン: 種牡馬となった
- オグリトウショウ: その他の兄弟
オグリキャップの血統は、特に母系が優れており、兄弟も競馬で成功を収めています。
response = chat_engine.chat("母ホワイトナルビーの父は?")
print(response)
ホワイトナルビーの父はクモハタです。
secondary_memory_sourcesの情報が活用されていない。secondary_memory_sourcesを見てみる。
chat_engine.memory.secondary_memory_sources[0].get("母ホワイトナルビーの父は?")
[
ChatMessage(role=<MessageRole.USER: 'user'>,
content='母ホワイトナルビーの父は?',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content=None,
additional_kwargs={
'tool_calls': [
{
'id': 'call_gvypKJ8TseHuMTl1idSmYUbk',
'function': {
'arguments': '{"input":"ホワイトナルビーの父は誰ですか?"}',
'name': 'query_engine_tool'
},
'type': 'function'
}
]
}
),
ChatMessage(role=<MessageRole.TOOL: 'tool'>,
content='ホワイトナルビーの父はクモハタです。',
additional_kwargs={
'name': 'query_engine_tool',
'tool_call_id': 'call_gvypKJ8TseHuMTl1idSmYUbk'
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='ホワイトナルビーの父は**クモハタ**です。',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.USER: 'user'>,
content='ホワイトナルビーの父はなんという馬ですか?',
additional_kwargs={
}
),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>,
content='ホワイトナルビーの父はシルバーシャークです。',
additional_kwargs={
}
)
]
secondary_memory_sourcesには含まれている。
でトレースを見てみると、primary_memoryは動作しているものの、secondary_memory_sourcesの内容をシステムプロンプトに設定できないっぽい。chat_engineは内部的にはretrieverがツールとして使用されるエージェントになっているのだけども、専用のQAプロンプトを持っていて、おそらくSimpleComposableMemoryはこのプロンプトを書き換えるということが出来ないのだろうと推測する。

シンプルに使いたいとしても、おそらくquery engineをツール化してエージェントでラップするような事が必要になるのではないかと思う。このへんとかを参考に、ちょっと試してみたけど、うまくいかないなぁ・・・
長期記憶・短期記憶ってのはエージェントじゃなくても活用できる要素はあるはずなので、シンプルに使えないのはちょっと残念ではある。
シンプルに使いたいとしても、おそらくquery engineをツール化してエージェントでラップするような事が必要になるのではないかと思う。このへんとかを参考に、ちょっと試してみたけど、うまくいかないなぁ・・・
多分notebookでいろいろやってたのでおかしくなってただけっぽい。改めてやり直したらできた。
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.memory import ChatMemoryBuffer, VectorMemory, SimpleComposableMemory
from llama_index.core.llms import ChatMessage
vector_memory = VectorMemory.from_defaults(
vector_store=None,
embed_model=OpenAIEmbedding(),
retriever_kwargs={"similarity_top_k": 2},
)
# インデックスにない情報をsecondary_memory_sourcesにセット
vector_memory.set([
ChatMessage.from_str("ホワイトナルビーの父はなんという馬ですか?", "user"),
ChatMessage.from_str("ホワイトナルビーの父はシルバーシャークです。", "assistant"),
])
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(
token_limit=1000,
chat_store=chat_store,
chat_store_key="user1",
)
composable_memory = SimpleComposableMemory.from_defaults(
primary_memory=chat_memory,
secondary_memory_sources=[vector_memory],
)
# インデックスからQuery Engineを作成
query_engine = index.as_query_engine(
similarity_top_k=5,
)
エージェントの設定
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.tools import FunctionTool
from llama_index.core.agent import FunctionCallingAgentWorker
# QueryEngineToolでquery engineをツール化
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name=f"oguricap_retriever",
description=f"競走馬「オグリキャップ」に関する情報を検索する",
),
)
agent_worker = FunctionCallingAgentWorker.from_tools(
[query_engine_tool],
verbose=True
)
# composable_memoryを使用したエージェントを作成
agent = agent_worker.as_agent(memory=composable_memory)
ではクエリを投げてみる。
response = agent.chat("オグリキャップの血統について教えて。")
Added user message to memory: オグリキャップの血統について教えて。
=== Calling Function ===
Calling function: oguricap_retriever with args: {"input": "\u8840\u7d71"}
=== Function Output ===
オグリキャップの父・ダンシングキャップは種牡馬成績がさほど優れていなかったため、突然変異や隔世遺伝で生まれた競走馬と主張する者もいました。一方で、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、オグリキャップもその一例と分析しています。母・ホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めています。5代母のクインナルビーは1953年の天皇賞(秋)を制しており、その子孫にはアンドレアモンやキョウエイマーチなどの重賞勝ち馬がいます。
兄弟には1994年桜花賞優勝馬のオグリローマン、種牡馬となったオグリイチバン、デビュー前から話題を集めたオグリトウショウがいます。
=== LLM Response ===
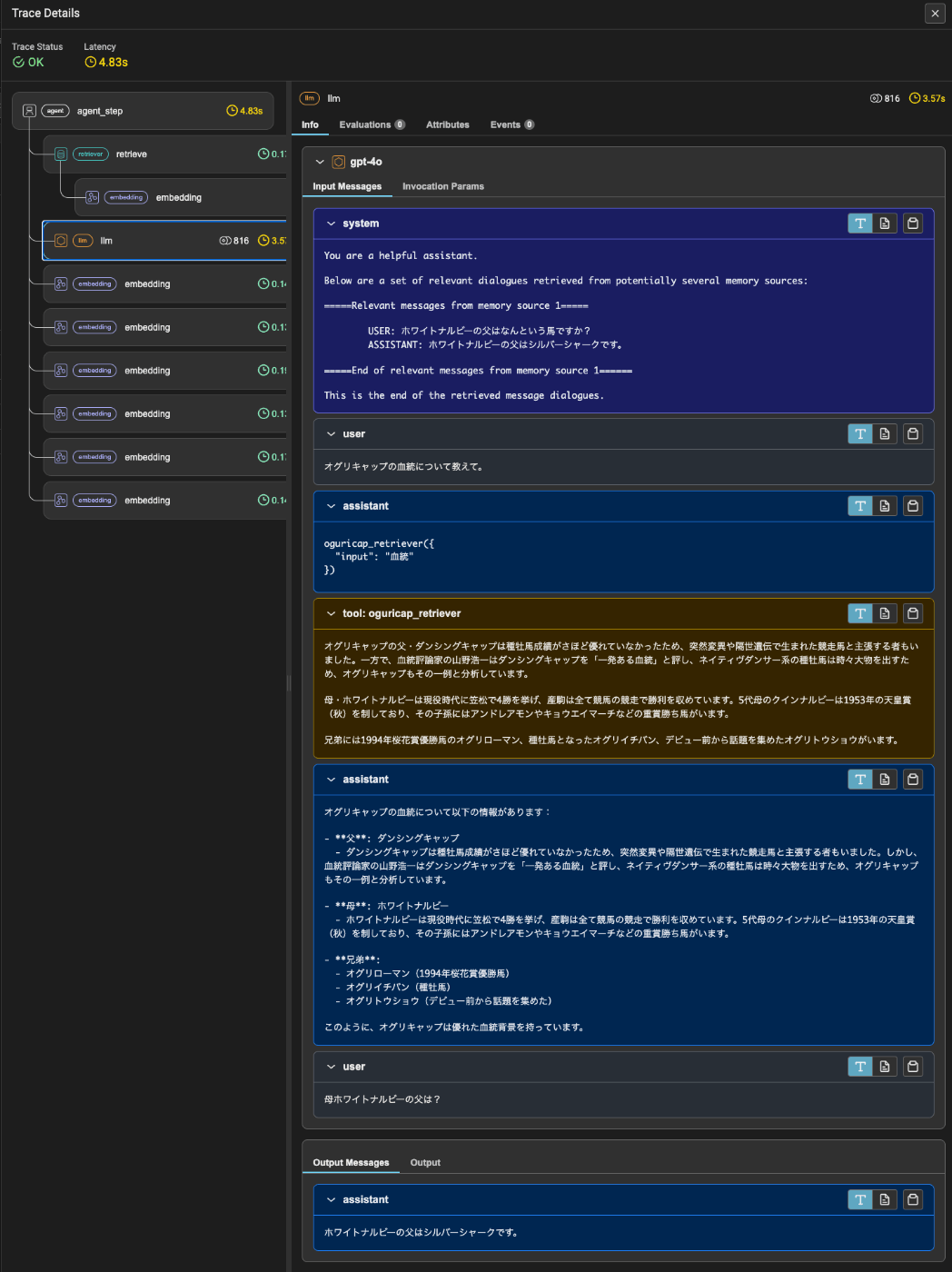
オグリキャップの血統について以下の情報があります:
父: ダンシングキャップ
ダンシングキャップは種牡馬成績がさほど優れていなかったため、突然変異や隔世遺伝で生まれた競走馬と主張する者もいました。しかし、血統評論家の山野浩一はダンシングキャップを「一発ある血統」と評し、ネイティヴダンサー系の種牡馬は時々大物を出すため、オグリキャップもその一例と分析しています。
母: ホワイトナルビー
ホワイトナルビーは現役時代に笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めています。5代母のクインナルビーは1953年の天皇賞(秋)を制しており、その子孫にはアンドレアモンやキョウエイマーチなどの重賞勝ち馬がいます。
兄弟:
オグリローマン(1994年桜花賞優勝馬)
オグリイチバン(種牡馬)
オグリトウショウ(デビュー前から話題を集めた)
このように、オグリキャップは優れた血統背景を持っています。
response = agent.chat("母ホワイトナルビーの父は?")
Added user message to memory: 母ホワイトナルビーの父は?
=== LLM Response ===
ホワイトナルビーの父はシルバーシャークです。
できたー
トレースを見てもちゃんとシステムメッセージに含まれていて、Query Engineを使わずに回答できているのがわかる。
そういえばLlamaIndexのエージェント、あまりちゃんと確認できていない。改めて確認してみる予定。