promptfooを試す
promptfoois a tool for testing and evaluating LLM output quality.With promptfoo, you can:
- Systematically test prompts, models, and RAGs with predefined test cases
- Evaluate quality and catch regressions by comparing LLM outputs side-by-side
- Speed up evaluations with caching and concurrency
- Score outputs automatically by defining test cases
- Use as a CLI, library, or in CI/CD
- Use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API
The goal: test-driven LLM development instead of trial-and-error.
DeepL訳
promptfooはLLMの出力品質をテスト・評価するためのツールです。promptfoo を使用すると、以下のことが可能になります:
定義済みのテストケースで、プロンプト、モデル、RAGをシステマチックにテストする。
LLM出力を並べて比較することにより、品質を評価し、リグレッションを検出する。
キャッシュと並行処理で評価をスピードアップ
テストケースを定義することで、出力を自動的にスコアリング
CLI、ライブラリ、CI/CDとして使用可能
OpenAI、Anthropic、Azure、Google、HuggingFace、Llamaのようなオープンソースモデル、または任意のLLM API用のカスタムAPIプロバイダーを統合して使用します。ゴール: 試行錯誤に代わるテスト駆動型のLLM開発。
インストール
今回はdevcontainerで。
{
"name": "Node.js",
"image": "mcr.microsoft.com/devcontainers/javascript-node:1-20-bookworm"
}
promptfooインストール
$ npx promptfoo@latest
Getting Started
初期化
$ npx promptfoo@latest init
Anonymous telemetry is enabled. For more info, see https://www.promptfoo.dev/docs/configuration/telemetry
✅ Wrote promptfooconfig.yaml. Run `promptfoo eval` to get started!
promptfooconfig.yamlが生成される。初期状態はこんな感じ。
# This configuration compares LLM output of 2 prompts x 2 GPT models across 3 test cases.
# Learn more: https://promptfoo.dev/docs/configuration/guide
description: 'My first eval'
prompts:
- "Write a tweet about {{topic}}"
- "Write a very concise, funny tweet about {{topic}}"
providers: [openai:gpt-3.5-turbo-0613, openai:gpt-4]
tests:
- vars:
topic: bananas
- vars:
topic: avocado toast
assert:
# For more information on assertions, see https://promptfoo.dev/docs/configuration/expected-outputs
- type: icontains
value: avocado
- type: javascript
value: 1 / (output.length + 1) # prefer shorter outputs
- vars:
topic: new york city
assert:
# For more information on model-graded evals, see https://promptfoo.dev/docs/configuration/expected-outputs/model-graded
- type: llm-rubric
value: ensure that the output is funny
コメントにある通り、2プロンプトを2つのモデルで比較、テストケースは3つということらしい。
とりあえず一旦このままで進めてみる。
OpenAI APIキーをセット
$ export OPENAI_API_KEY=XXXXXXXXXX
テストを実行してみる。
$ npx promptfoo@latest eval
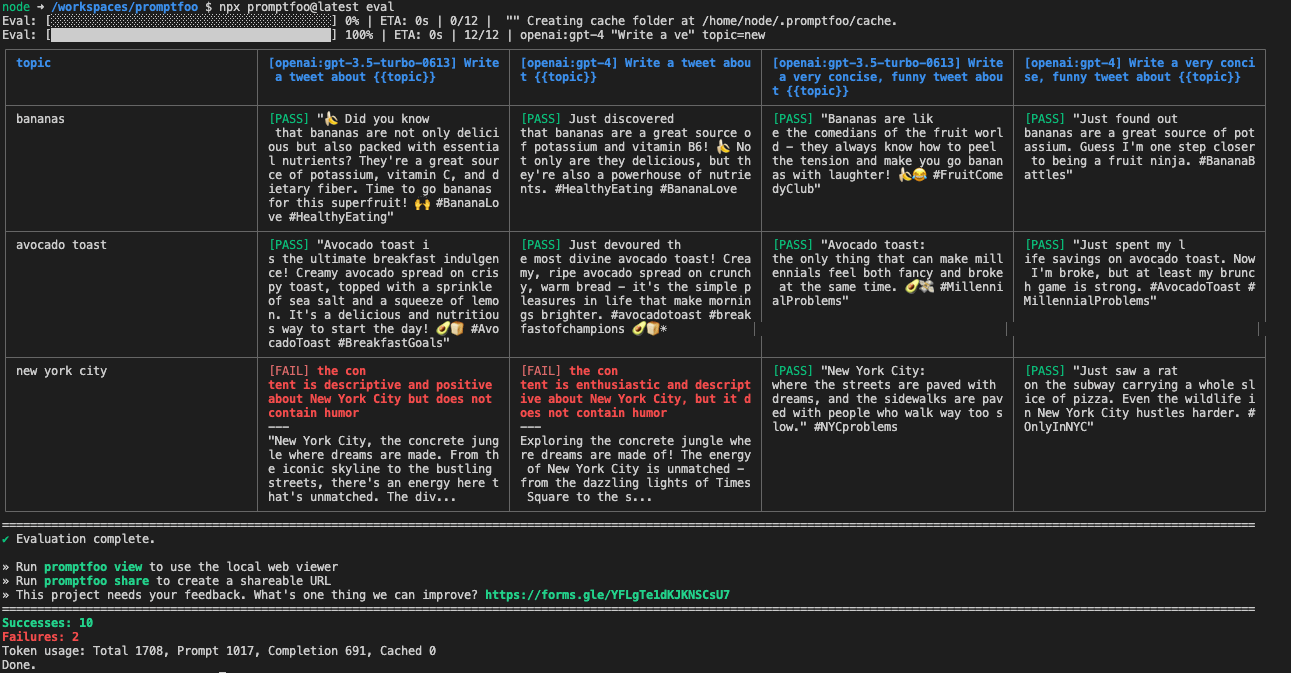
12のテストが行われている。assertで検証項目を指定する感じっぽい。なるほど。
テスト結果はブラウザベースでも見れる。
$ npx promptfoo@latest view
Server running at http://localhost:15500 and monitoring for new evals.
Open URL in browser? (y/N): y
Press Ctrl+C to stop the server

見やすくて良さそう。
設定ファイルは後で詳しく見るとして、Getting Startedにある例を少し見てみる。
プロンプト
prompts:
- 'Convert this English to {{language}}: {{input}}'
- 'Translate to {{language}}: {{input}}'
テストしたいプロンプトを記載する。{{}}は変数のプレースホルダーになる。テストケースの中で指定した内容で展開される。
以下のように別ファイルにしておくこともできる模様。
prompts: [prompt1.txt, prompt2.txt]
プロバイダー
LLMを指定する。
providers:
- openai:gpt-3.5-turbo
- openai:gpt-4
テストケース
tests:
- vars:
topic: bananas
- vars:
topic: avocado toast
assert:
- type: icontains
value: avocado
- type: javascript
value: 1 / (output.length + 1) # prefer shorter outputs
varsで変数を指定する。assertでテスト条件を記載する。
defaultTestを使うと全テスト共通のテストケースになるみたい。
defaultTest:
assert:
# Verify that the output doesn't contain "AI language model"
- type: not-contains
value: AI language model
# Verify that the output doesn't apologize, using model-graded eval
- type: model-graded-closedqa
value: must not contain an apology
- type: javascript
value: Math.max(0, Math.min(1, 1 - (output.length - 100) / 900));
コマンドラインいろいろ
テスト結果のファイルへの出力。スプレッドシート、JSON、YAML,HTMLで出力できる。
$ npx promptfoo@latest eval -o output.html
統計情報的なものは出ないけど、テストケースの結果が出力されるみたい。

プロンプトやモデルの指定はコマンドラインからも行える。
Write a tweet about {{topic}}
Write a very concise, funny tweet about {{topic}}
$ npx promptfoo@latest eval -p prompt1.txt prompt2.txt -r openai:gpt-3.5-turbo-0125 openai:gpt-4-turbo-preview
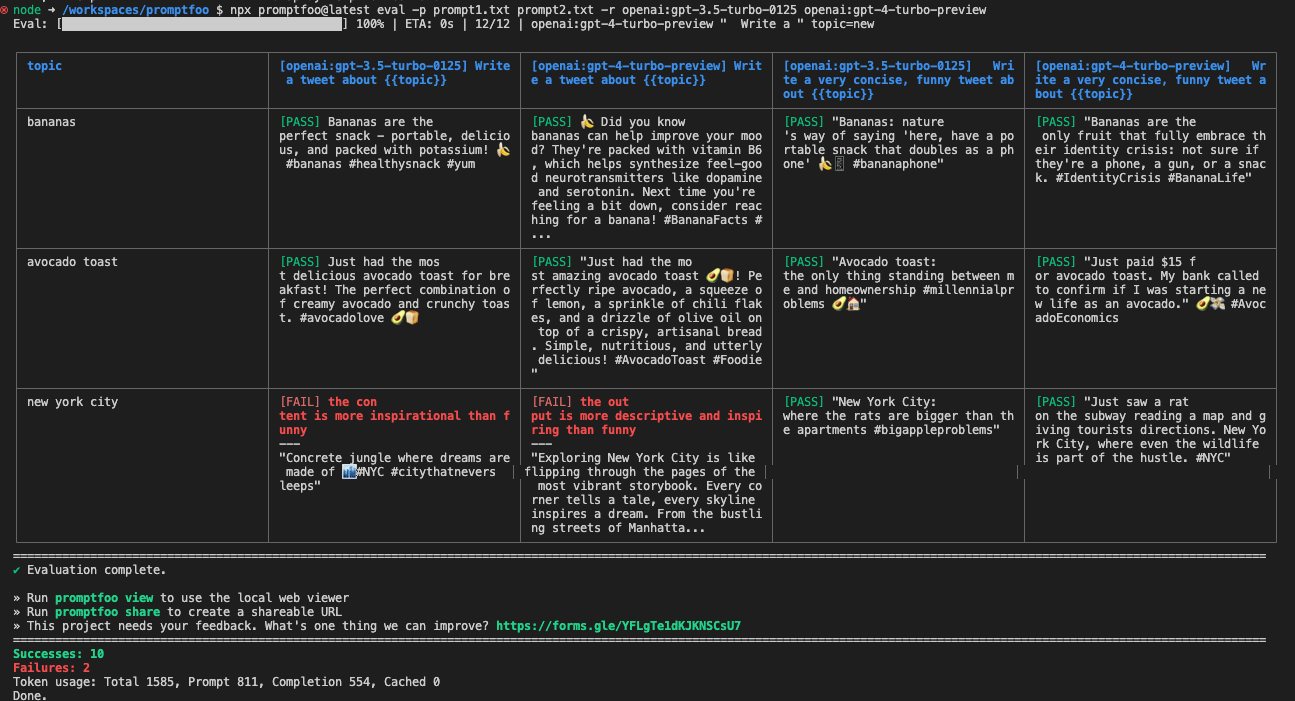
コマンドライン指定したものはpromptfooconfig.yamlの設定をオーバーライドする感じっぽいね。
設定
設定を色々見てみる。
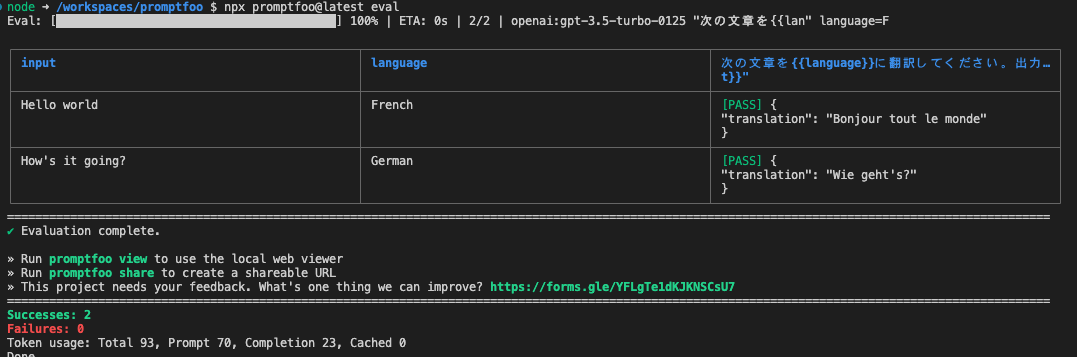
次の文章を{{language}}に翻訳してください。: "{{input}}"
prompts: [prompt1.txt]
providers: [openai:gpt-3.5-turbo-0125]
tests:
- vars:
language: French
input: Hello world
- vars:
language: German
input: How's it going?

出力をassertでチェックする。
次の文章を{{language}}に翻訳してください。出力はJSON形式で。: "{{input}}"
prompts: [prompt1.txt]
providers: [openai:gpt-3.5-turbo-0125]
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-json
- vars:
language: German
input: How's it going?
assert:
- type: contains-json
指定できるassertionは以下。
いくつか試す。
prompts: [prompt1.txt]
providers: [openai:gpt-3.5-turbo-0125]
tests:
- vars:
language: French
input: Hello world
assert:
- type: javascript
value: output.toLowerCase().includes('bonjour') # JavaScriptで文字列が含まれているかを判定
- vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht?
threshold: 0.6 # コサイン類似度で一定のスコア以上かを判定
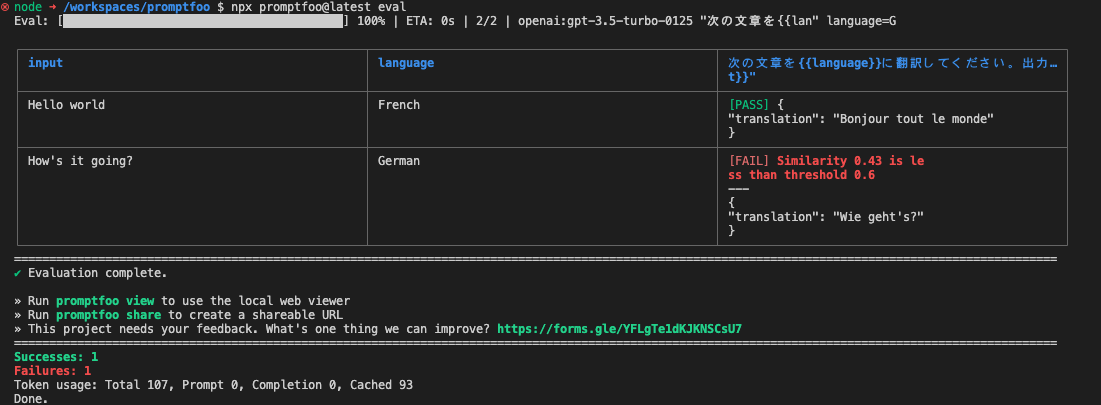
prompts: [prompt1.txt]
providers: [openai:gpt-3.5-turbo-0125]
defaultTest: # 全テストケース共通
assert:
- type: llm-rubric # `llm-rubric`を使うと自然言語で判定≒LLMに判定させることができる
value: 短すぎず、300文字程度の長さであること
tests:
- vars:
language: French
input: Hello world
assert:
- type: javascript
value: output.toLowerCase().includes('bonjour')
- vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht?
threshold: 0.6
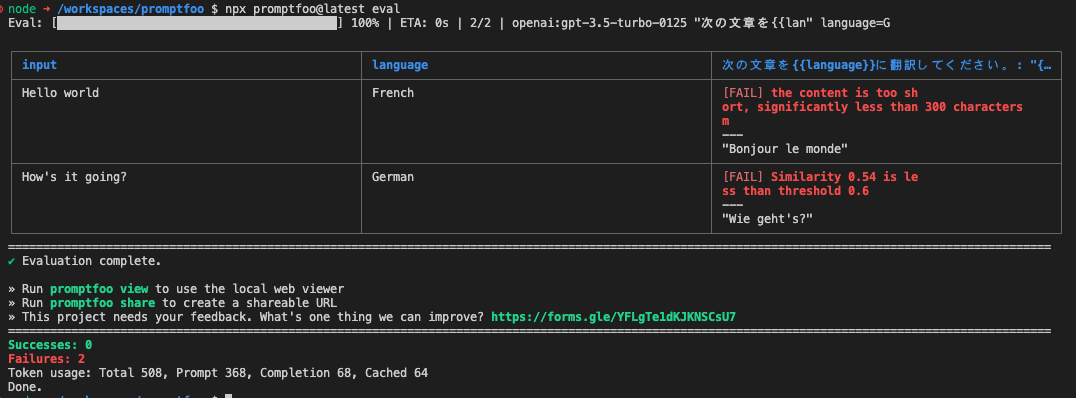
別ブロックから参照することもできる・・・
prompts: [prompt1.txt]
providers: [openai:gpt-3.5-turbo-0125]
tests:
- vars:
language: French
input: Hello world
assert:
- $ref: "#assertionTemplates/notTooLong"
- vars:
language: German
input: How's it going?
assert:
- $ref: "#assertionTemplates/notTooLong"
assertionTemplates:
notTooLong:
- type: llm-rubric
value: not too long
のだけど自分の環境のせいかなんなのかわからないけど、ここは全然うまくいかなかった。
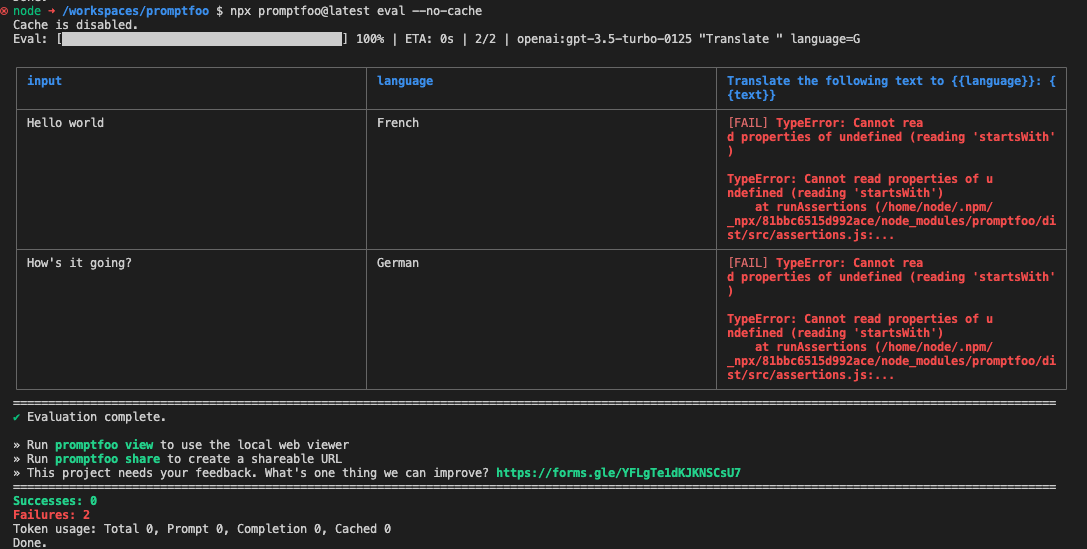
ほかにもいろいろありそうだけどこれぐらいで一旦おいておくか。
RAGの評価
RAGの評価は2ステップ
- 出力ベース
- 以下の2つ
-
Factuality(Correctness)
- LLMの出力が、提供された正解に基づいているかどうか
-
Answer relevance
- LLMの回答が、質問に対して適切か
-
Factuality(Correctness)
- 以下の2つ
- コンテキストベース
- 以下3つ
-
Context adherence(Grounding/Faithfullness)
- LLMの出力が、提供されたコンテキストに基づいているかどうか
-
Context recall
- 提供された正解がコンテキスト含まれているかどうか
-
Context relevance
- 質問に対してどれだけのコンテキストが必要か
-
Context adherence(Grounding/Faithfullness)
- 以下3つ
- カスタム
- 独自の基準を設けることもできる
んー、これをやるにはちょっと準備が必要
とりあえずまずはベクトルDBを作る。今回はQdrant Cloudを使った。
Qdrant Cloudで"promptfoo-sample"というクラスタを作成、APIキーも作成しておく。
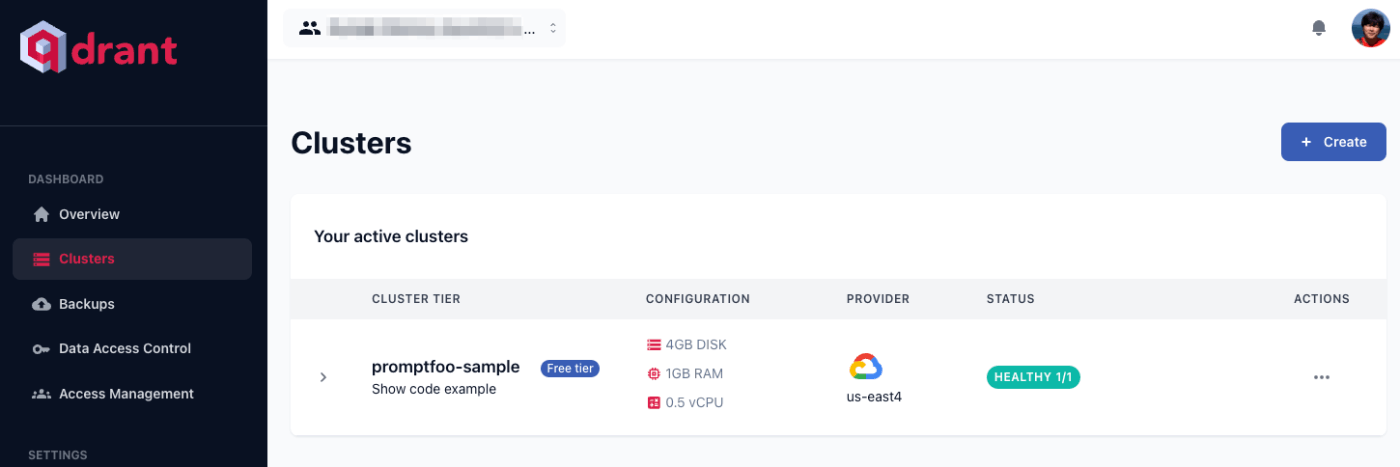
データは以下のQAを使用
ColaboratoryでQdrantに入れる。
!pip install openai qdrant-client
from qdrant_client import QdrantClient
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ["QDRANT_API_KEY"] = userdata.get('QDRANT_API_KEY')
os.environ["QDRANT_ENDPOINT"] = userdata.get('QDRANT_ENDPOINT')
qdrant_client = QdrantClient(
os.environ["QDRANT_ENDPOINT"],
api_key=os.environ["QDRANT_API_KEY"],
)
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!unzip dataset_.zip
import pandas as pd
df = pd.read_excel("dataset_.xlsx")
df.drop(columns=["ID", "カテゴリ2", "出典", "<参考>UMカテゴリタグ", "<参考>UMサービスメニュー\n(標準的な行政サービス名称)"], inplace=True)
df.rename(columns={
'サンプルID': 'ID',
'サンプル 問い合わせ文': 'Question',
'サンプル 応答文': 'Answer',
'カテゴリ1': 'Category',
}, inplace=True)
df["ID"] = "D" + df["ID"].astype(str).str.zfill(3)
df

from openai import OpenAI
from tqdm.auto import tqdm
def get_embedding(client, text, model="text-embedding-ada-002"):
response = client.embeddings.create(input=text, model=model)
return response.data[0].embedding
tqdm.pandas()
embedding_model = 'text-embedding-ada-002'
openai_client = OpenAI()
df['A_embedding'] = df["Answer"].progress_apply(lambda x: get_embedding(openai_client, x, model=embedding_model))
from qdrant_client.http.models import Distance, VectorParams
qdrant_client.create_collection(
collection_name="qa",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
from qdrant_client.http.models import Batch
for index, row in df.iterrows():
a_vector_arr = row["A_embedding"]
a_text_arr = row["Answer"]
doc_id = row["ID"]
qdrant_client.upsert(
collection_name="qa",
points=Batch(
ids=[index + 1],
vectors=[a_vector_arr],
payloads=[{"doc_id": doc_id, "text": a_text_arr,}]
)
)
これでQdrantに"qa"というコレクションが作成される。

お試し
from pprint import pprint
query = "母子手帳を受け取りたいのですが、手続きを教えてください。"
query_vector = get_embedding(openai_client, query, model=embedding_model)
search_result = qdrant_client.search(
collection_name="qa",
query_vector=query_vector,
limit=5,
)
for r in search_result:
print(r.id, r.payload["text"])
37 母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。
3 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。
▼詳しくはこちら
(自治体HP内関連ページのURL)
108 母子手帳をなくしたときは、再交付を受けてください。
お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。
お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。
申請の際はご本人確認できるものをお持ちください。
◆お問い合わせ
(自治体の担当課等の名称)
(電話番号)/(開庁時間)
36 産前は母子手帳以外の手続きは特にありません。
産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。
2 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。
▼詳しくはこちら
(自治体HP内関連ページのURL)
ではpromptfooに戻る。
retrievalのサンプルとして用意されていたのはpythonなので、devcontainerのイメージを作り直した。既存のdevcontainerにpython追加するでも良いと思うけど、自分的にはこちらのほうが慣れてるので。
{
"name": "Python 3",
"image": "mcr.microsoft.com/devcontainers/python:1-3.12-bookworm",
"features": {
"ghcr.io/devcontainers/features/node:1": {
"nodeGypDependencies": true,
"version": "lts",
"nvmVersion": "latest"
}
}
}
再度必要なパッケージ等をインストール
$ npx promptfoo@latest
$ pip install openai
$ pip install qdrant-client
環境変数設定。Qdrant CloudのエンドポイントとAPIキーなど。
$ export QDRANT_ENDPOINT=https://XXXXXXXXXX.gcp.cloud.qdrant.io
$ export QDRANT_API_KEY=XXXXXXXXXX
$ export OPENAI_API_KEY=XXXXXXXXXX
ドキュメントを参考にretrievalのスクリプトを作成。call_apiがretrievalを行う関数。retrievalだけなので引数はクエリだけ渡せば良いと思ったのだけど、どうやらpromptfooは必ず3つ引数を渡してスクリプトを実行するようなので、クエリ以外は使わないけどドキュメント通りにしている。
import os
from openai import OpenAI
from qdrant_client import QdrantClient
embedding_model = "text-embedding-ada-002"
collection_name = "qa"
limit = 10
openai_client = OpenAI()
qdrant_client = QdrantClient(
os.environ["QDRANT_ENDPOINT"],
api_key=os.environ["QDRANT_API_KEY"],
)
def call_api(query, opttions, context):
try:
response = openai_client.embeddings.create(input=query, model=embedding_model)
documents = qdrant_client.search(
collection_name=collection_name,
query_vector=response.data[0].embedding,
limit=limit,
)
if(len(documents)):
output = "\n".join(f'{doc.payload["doc_id"]}: {doc.payload["text"].replace("\n","")}' for doc in documents)
else:
output = ""
result = {
"output": output,
}
return result
except Exception as e:
result = {
"error": f"An error occurred during processing: {e}"
}
テスト
$ python
>>> from retrieve import call_api
>>> call_api("母子手帳の手続きを教えて",None,None)
{'output': 'D003: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。▼詳しくはこちら(自治体HP内関連ページのURL)\nD037: 母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。\nD036: 産前は母子手帳以外の手続きは特にありません。産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。\nD108: 母子手帳をなくしたときは、再交付を受けてください。お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。申請の際はご本人確認できるものをお持ちください。◆お問い合わせ(自治体の担当課等の名称)(電話番号)/(開庁時間)\nD002: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。▼詳しくはこちら(自治体HP内関連ページのURL)\nD450: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。▼詳しくはこちら(自治体HP内関連ページのURL)\nD252: 夜間・休日窓口の場合、母子手帳の証明や届書の受理証明書などの発行、 子どもに関する手当・助成の受付はしていませんので、通常窓口で手続き・申請してください。▼詳しくはこちら(自治体HP内関連ページのURL)\nD165: 母子手帳は住所が変わってもそのままお使いいただけます。再発行等の手続は必要ありません。◆お問い合わせ(自治体の担当課や子育てセンター等の名称)(電話番号)/(開庁時間)\nD349: 私立幼稚園の補助金の振込先口座は、申請書に記載されている保護者欄が一致していれば、父と母どちらでも可能です。\nD001: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。▼詳しくはこちら(自治体HP内関連ページのURL)'}
promptfooの設定。providersで上記のretrievalのスクリプトを実行する。まずはシンプルに、特定のキーワードが含まれているかをチェックする。
prompts: ["{{ query }}"]
providers: ['python:retrieve.py']
tests:
- vars:
query: 母子手帳を受け取りたいのですが、手続きを教えてください。
assert:
- type: contains-all
value: ['母子手帳','妊娠届','D001']
- vars:
query: 住民税の納税証明書を取りたい。
assert:
- type: contains-all
value: ['住民税','納税証明書','D659']
$ npx promptfoo@latest eval
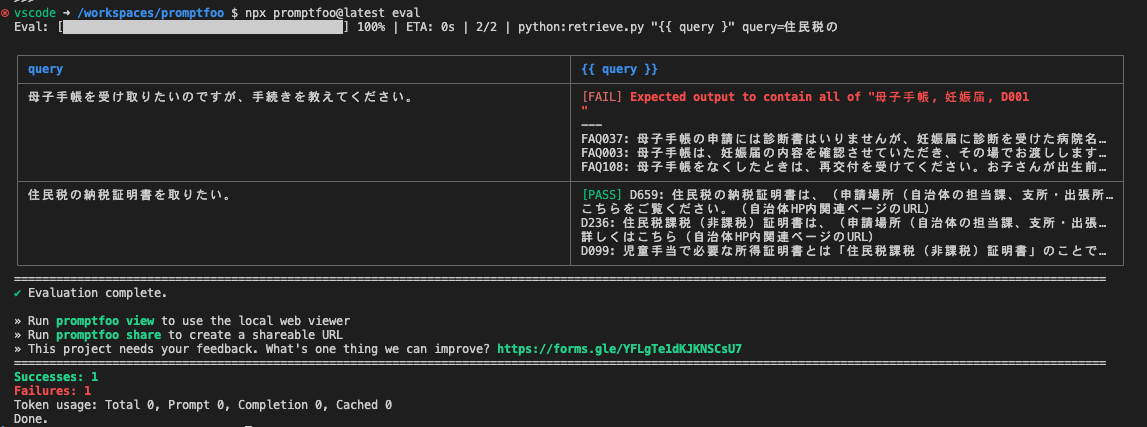
retrieval単体はこれで良さそう。じゃあretrieval+generationを両方評価しようと思って色々見てみたけど、結構難しそうと感じた。
- 本来providerはLLMを指定するもので、複数書くと別のテストケースとして実行される。
- ここに上記のようなスクリプトを指定してしまうと、LLMを指定できない。つまりLLMを使った評価はできない。
- retrievalの検索結果は、テストケースへの入力にする必要があるが、調べてみた限り、テストケースの入力をスクリプト実行などで動的に行う方法が見当たらない。
やるとするならば、
- クエリとコンテキストをあらかじめ用意しておく
- もしくは上記のスクリプト内でretrieval+generationした出力をテストする
になりそう。つまり動的にretrievalとgenerationをテストする、ってのは難しい印象。
改めて考え直してみたけど、promptfooは「プロンプト」に対して、「出力」の「テスト」を行うためのもの、という印象。
自分の今の考えでは、「評価」と「テスト」は少し違うと思っている。
- 評価: 定量的指標、例えば10段階評価とか。
- テスト: PASS or FAILみたいなバイナリ的な指標
promptfooは、出力を見ていてもわかるように「評価」ではなく「テスト」な感じのツールだと感じていて、context-recallなどよく使われる評価指標もテストのためにしきい値を設定して使うものになる。
なので「評価」として行いたい場合はragasなど別のツールを使う方が向いている気はする。
この辺は便利そうなんだけども、上述の通り「評価」とはちょっと違う感があるので、出力内容もあっさりな感じで、自分的にはもうちょっといろいろ情報が欲しいなというところ。
あくまでも個人の印象。自分の場合は、RAGの「評価(テスト含む)」を、細かく情報を取りつつ、動的・自動でやれないかな?というところが起点になっているので、求めてるものに合わなかっただけだと思う。
逆に、以下のようなケースには合うと思う。
- (RAGではない)LLM単体でのテスト
- (RAGを構成する前段階としての)プロンプト単体のテスト
評価で使おうと思うと、PASS/FAILに関係なく、評価指標の数字が出てほしいなという気がしている