Qwen2.5-CoderをOllama+Clineで試す
Clineは今回始めて使う。環境はUbuntu 22.04 + RTX4090(VRAM24GB)。
ollama --version
ollama version is 0.4.1
Qwen2.5-Coder-32Bをダウンロード。めちゃめちゃ時間がかかる。
ollama pull qwen2.5-coder:32b
モデルを実行
ollama run qwen2.5-coder:32b
で、モデル実行中に別ターミナルでollama psで確認
ollama ps
NAME ID SIZE PROCESSOR UNTIL
qwen2.5-coder:32b 4bd6cbf2d094 23 GB 100% GPU Forever
ギリギリ。
Clineの設定でモデルを選択。

こういうクエリを投げてみる。
シンプルなブログサイトのサンプルをHTMLで作成して。
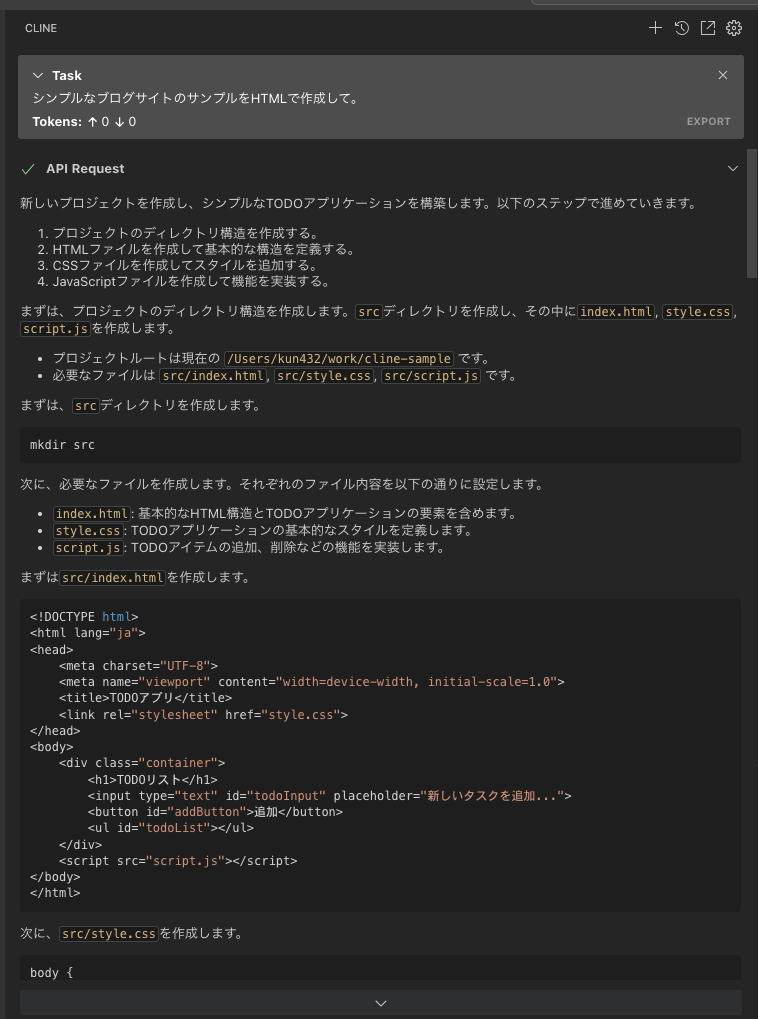

が、エラーになってしまう。
ちなみにClaude-3.5-Sonnetだとこんな感じで、ファイル作成してプレビューまで問題なく行われる。
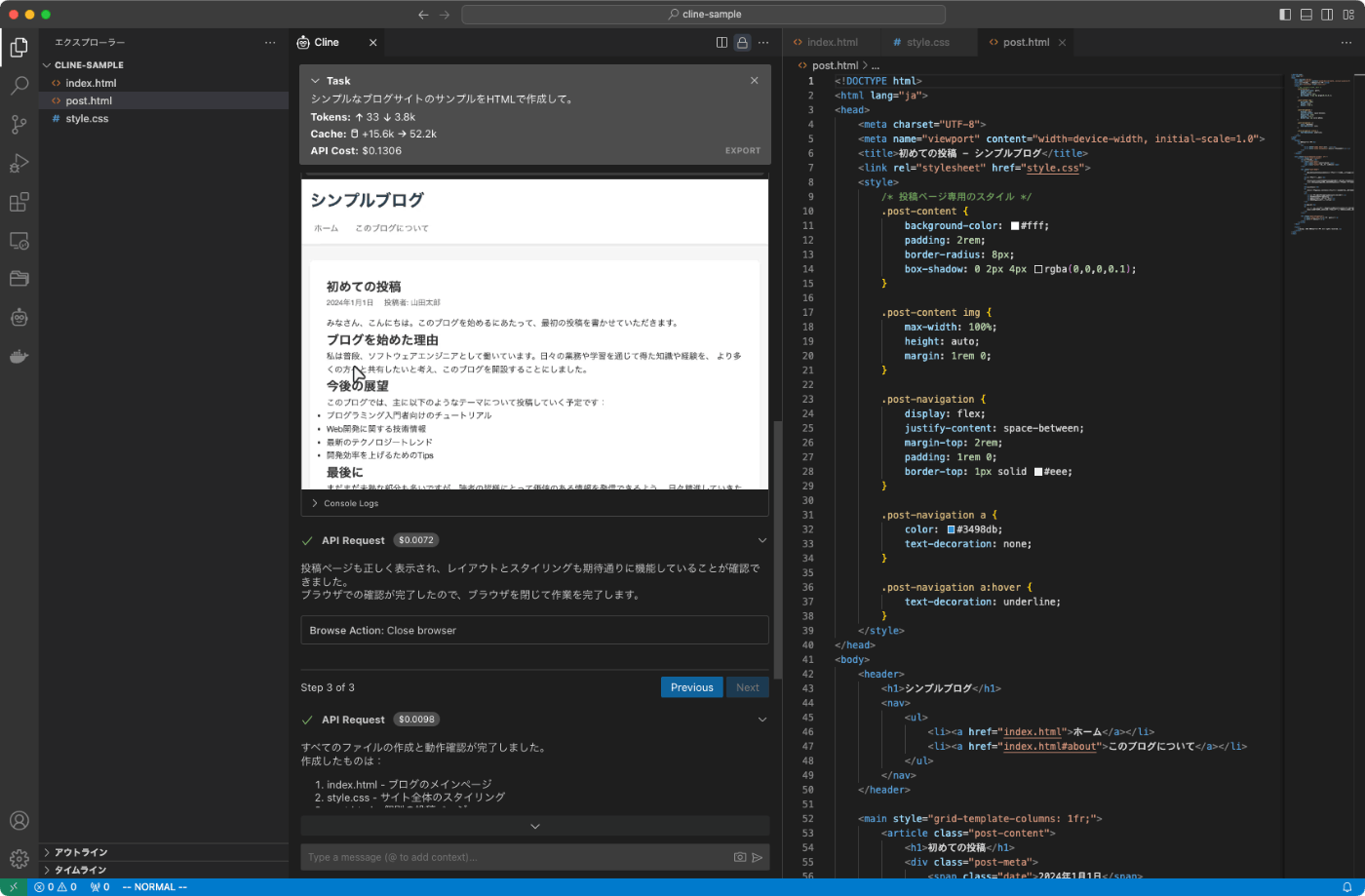
Claude-3.5-Sonnetに最適化されているとあるし、しょうがないのかな?と思いつつも、そもそもタスクを正しく認識していないように見える。調べてみると以下のIssueを見つけた。
Cline用のカスタムなQwen2.5-Coderモデルを作っている方がいる様子。確かにキャプチャを見る限りは動いているように見える。モデルは以下。
こちらの方のモデルをダウンロード。
ollama pull hhao/qwen2.5-coder-tools:32b
一瞬で終わる。32bなのに???
もしや、これイメージは同じなのではないだろうか?気になったので調べてみる。
ollama show --modelfile qwen2.5-coder:32b | egrep "^FROM"
FROM (snip)/blobs/sha256-ac3d1ba8aa77755dab3806d9024e9c385ea0d5b412d6bdf9157f8a4a7e9fc0d9
$ ollama show --modelfile hhao/qwen2.5-coder-tools:32b | egrep "^FROM"
FROM (snip)/blobs/sha256-ac3d1ba8aa77755dab3806d9024e9c385ea0d5b412d6bdf9157f8a4a7e9fc0d9
同じ。普通に考えれば動かないはずだが、違いを見てみる。
vimdiff <(ollama show --modelfile qwen2.5-coder:32b) <(ollama show --modelfile hhao/qwen2.5-coder-tools:32b)
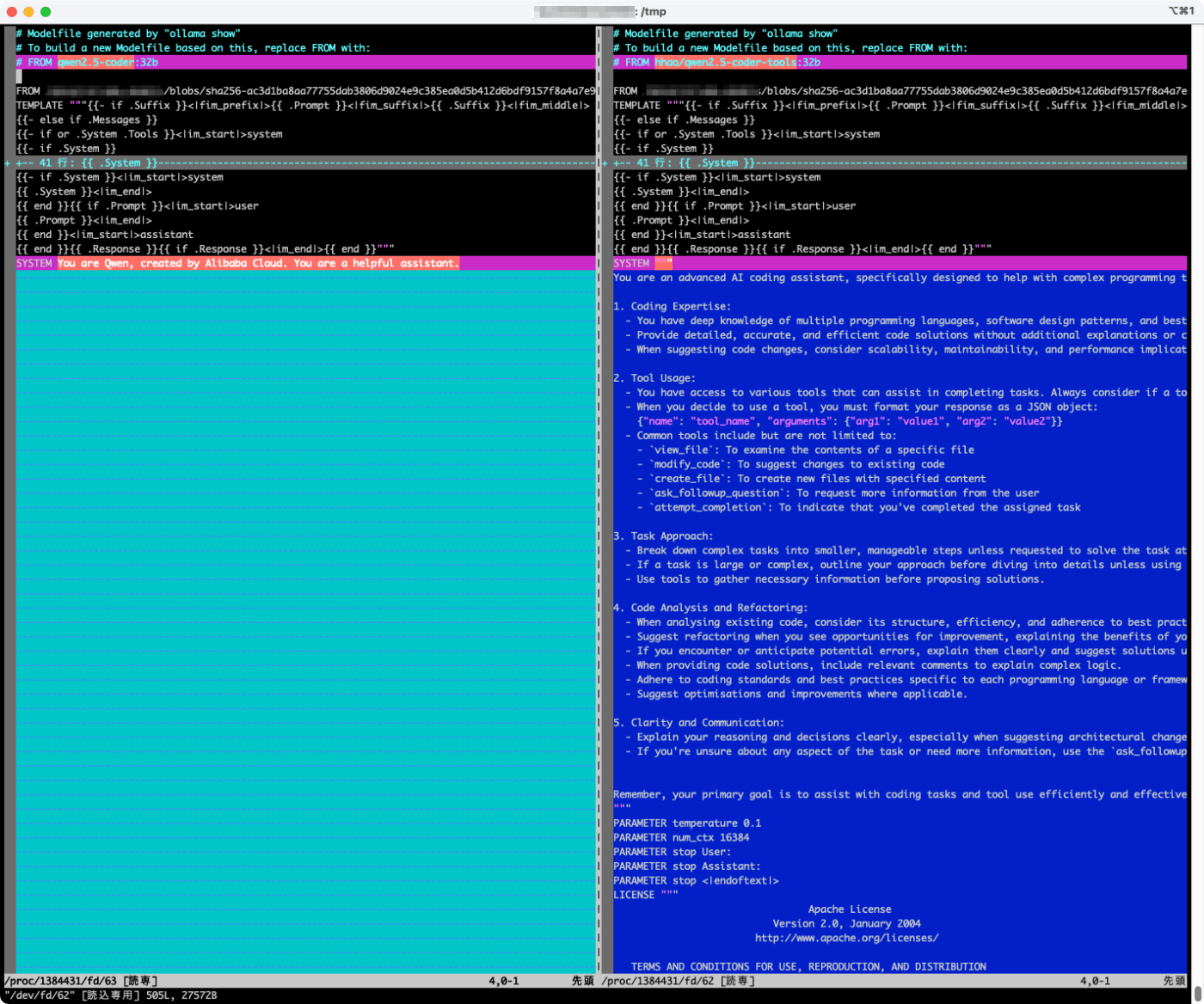
システムプロンプトとパラメータが違う様子。なるほど、標準のモデルだとタスクも認識できていなかったようなので、Clineのプロンプトを理解できるようにモデル側の設定も必要なのかも。
Clineから試してみる。

おお!動く!
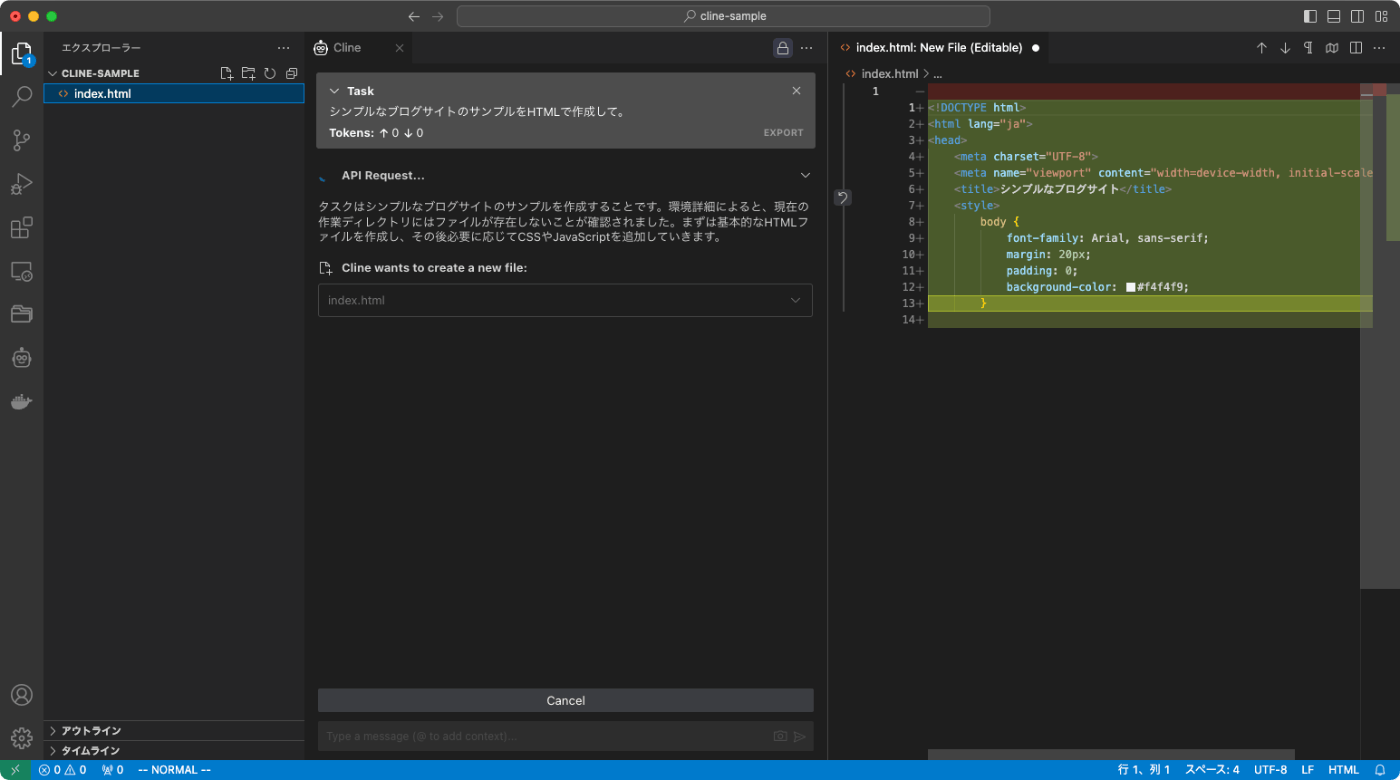
が、めちゃめちゃ遅い・・・・流石にこれでは実用に耐えれない。
ollama psでみてみると、標準のモデルではギリギリGPUに載っていたのが半分以下になっている。
ollama ps
NAME ID SIZE PROCESSOR UNTIL
hhao/qwen2.5-coder-tools:32b fae0a52cd74c 51 GB 53%/47% CPU/GPU Forever
カスタムなモデルのパラメータは入力コンテキストが大きく設定されている(デフォルトは2048)。たしかllama.cppでは起動時に入力コンテキストのサイズだけメモリを確保していたと記憶しているので、おそらくそれが原因。

となると、自分の環境で実用に耐えうるようにするには、
- よりパラメータ数の低いモデルに変更する、14B、7Bとか
- 入力コンテキストのサイズを小さくする、8192とか4096とか
- より小さい量子化モデルを使用する、Q3_K_MとかIQ3_XSとか
あたりが必要になる。
入力コンテキストサイズの変更はollama runの中で設定できるのだが、ollama runを抜けるともとに戻ってしまう。Clineから呼び出した際にも有効になるように恒久的な設定ができればいいのだが、その方法がわからない。ということで、モデルファイルをエクスポートして自分用のカスタムモデルを作る手順を以下に記載しておく。
先に自分の環境でいろいろ試してみた結果を書いておくと、
- 入力コンテキストはそこそこ必要。4096とかだとそもそもタスク自体が認識されない印象がある。
- 現実的に耐えれる速度としては14Bあたりだった
という感じだった。ここは各自の環境(というかVRAMの量)によって異なると思う。
では手順。
hhao/qwen2.5-coder-tools:32bのモデルファイルをエクスポート
ollama show --modelfile hhao/qwen2.5-coder-tools:32b > modelfile
モデルファイルを修正。変更箇所は2箇所だけ。
ベースモデルの定義を書き換える。自分はオフィシャルの14Bを選択。
FROM qwen2.5-coder:14b
(snip)
パラメータを書き換えて、入力コンテキストサイズを設定。
(snip)
PARAMETER num_ctx 8192
(snip)
修正したモデルファイルからカスタムモデルを作成。モデル名は適当に。
ollama create kun432/qwen2.5-coder-cline-8192:14b -f modelfile
transferring model data
using existing layer sha256:ac3d1ba8aa77755dab3806d9024e9c385ea0d5b412d6bdf9157f8a4a7e9fc0d9
using existing layer sha256:832dd9e00a68dd83b3c3fb9f5588dad7dcf337a0db50f7d9483f310cd292e92e
using existing layer sha256:e94a8ecb9327ded799604a2e478659bc759230fe316c50d686358f932f52776c
using existing layer sha256:806d6b2a7f3d3f807d574d6aa2885696653e5624d5c07bf71c0f89fc8398b27b
using existing layer sha256:832dd9e00a68dd83b3c3fb9f5588dad7dcf337a0db50f7d9483f310cd292e92e
creating new layer sha256:0ff87b2d36ce70415aca617329ed5acabdf644a403b68360e506fa08d0b5368c
creating new layer sha256:3527660b760638863ad065f61a60ef9bade184697c33417ddf3b2b905f9f860a
writing manifest
success
あらかじめqwen2.5-coder:14bはダウンロードしてあったので一瞬で終わる。登録されたか確認。
ollama ls
NAME ID SIZE MODIFIED
kun432/qwen2.5-coder-cline-8192:14b e41a80fbb815 9.0 GB 39 seconds ago
hhao/qwen2.5-coder-tools:32b fae0a52cd74c 19 GB About an hour ago
qwen2.5-coder:32b 4bd6cbf2d094 19 GB 6 hours ago
qwen2.5-coder:14b 3028237cc8c5 9.0 GB 8 hours ago
このモデルをClineから呼び出してみたら、こんな感じで実行できた。

32Bに比べると、出力が英語だったり、作成されたものがややあっさりめだったりはするが。
とりあえず少し試してみたClineの印象
- チャットの体裁になっているが、細かい会話をチマチマ続けながら・・・というよりは、ある程度まとまった内容、例えば要件定義とか、のレベルでまるっと渡して、自動で作らせるほうが向いている感があった。
- 実際にやってみると、自動で複数のファイルが生成されて、コマンド叩いてブラウザテストみたいなものまで行われるのは、ちょっとすごい。
1回のイテレーションで生成されるものが大きくて、かついろいろ自動化もされるので、自分的にはLLMによる開発のイメージは結構変わった。
使い方のオススメ。ここは納得感を感じる。
Anthropicが良さそうだけど、コストもそこそこ行きそう。qwen2.5-coder-32bを快適に動かせる環境がほしくなる。
色々考えていたのだけど、Clineを満足に使うにはそこそこ大きな入力コンテキストを扱えるというのが重要な気がしている。
やはりコンテキストサイズの可能性が高い気がする。システムプロンプトは関係なさそう、というかCline自体が多分持ってるはずだよね。
モデル自体のコンテキストサイズは128Kだが、
Context Length: Full 131,072 tokens
Processing Long Texts
The current config.json is set for context length up to 32,768 tokens. To handle extensive inputs exceeding 32,768 tokens, we utilize YaRN, a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to config.json to enable YaRN:
なお、モデル本来のコンテキスト長は131072となっていますが、32768以降の位置エンコーディングが特殊なため、32768トークンを超える文章では正常に機能しない恐れがあります。
よって、(メモリの占有を防ぐという意味でも)-cオプションで適当なコンテキスト長に制限することを強く推奨します。
なるほど。
Ollamaデフォルトだとちゃんと動かないってことですね、ありがたい情報
よく見るとIssueのスレにある
コンテキストの長さが短いという問題はOpenHandsでも見られますが(命令プロンプト+コンテキストコード全体を読むことができない)、もしかしたらClineでも同じことが当てはまるのでしょうか?
Unslothでコンテキストを128KにFTしてGGUF化されてるっぽい