Pythonの並列処理ライブラリ「Parsl」を試す
公式サイト
GitHubレポジトリ
Parsl - 並列スクリプトライブラリ
Parslは、Pythonの並列処理を単一のコンピュータを超えて拡張します。
Parslは、複数のコアやノードにまたがって、Pythonの並列実行機能とほぼ同様に使用できます。しかし、Parslの真の強みは、関数の複数ステップのワークフローを表現できることにあります。Parslは、関数を連結し、入力とコンピューティングリソースが利用可能になると各関数を起動します。
(snip)
まず、コンピューティングリソースの使用方法をParslに伝える方法を学ぶために、設定のクイックスタートから始めて、次に、アプリケーションで並列処理を最適に利用する方法を決定するために、並列コンピューティングパターンを調べてみてください。
ドキュメントの説明
なぜParslを使うのか?
ParslはPythonです
ParslプログラムのすべてはPythonで記述されています。ParslはPythonのネイティブ並列化アプローチと関数に従い、それらがどのようにワークフローに組み込まれ、どこで実行されるかはすべてPythonで記述されています。
Parslはどこでも動作します
Parslは、ラップトップから世界最速のスーパーコンピューターまで、あらゆる場所で並列処理を実行できます。ラップトップからスーパーコンピューターへのスケーリングは、多くの場合、リソース構成を変更するだけで簡単に行うことができます。Parslは、多くのトップスーパーコンピューター上でテストされています。
Parslは柔軟性があります
Parslは、多くの種類のアプリケーションをサポートしています。関数は、純粋なPythonでも外部コードを呼び出すものでも、シングルスレッドでもマルチスレッドでもGPUでも可能です。
Parslはデータを処理します
Parslは、ファイルを伴うワークフローを第一級のサポートで提供します。データは、たとえ異なるファイルシステム上に存在する場合でも、自動的にワーカー間で移動されます。
Parslは高速です
Parslはスピードを重視して構築されています。ワークフローは、数万の並列タスクを管理し、1秒あたり数千のタスクを処理できます。
Parslはコミュニティです
Parslは、大規模で経験豊富なコミュニティの一部です。
Parslプロジェクトは、持続可能な研究用ソフトウェアの開発を目的とした全米科学財団のプロジェクトの一環として、ワークフローに数十年の経験を持つ研究者たちによって立ち上げられました。
Parslチームは、GitHub、Slackでの会話、隔週の開発者会議、ワークフローコミュニティイニシアチブとの連携を通じて、コミュニティの指導を受けています。
Parslについて書かれた日本語の記事
Quickstart
Quickstartに従って進める
インストール
ローカルのMacで。
作業ディレクトリ作成
mkdir parsl-work && cd parsl-work
Python仮想環境作成。最近はuvをよく使う。
uv venv -p 3.12.8
パッケージインストール
uv pip install parsl
(snip)
+ parsl==2025.2.10
(snip)
Parslの主要な概念
最初に少し概念的な説明がある。
referred from https://parsl.readthedocs.io/en/stable/quickstart.html#getting-startedParslプログラムは、リモートコンピュータに分散された ワーカー 上で実行するタスクを送信します。これらのタスクの指示は、Python関数を使用してユーザーが定義する 「アプリ」 内に含まれています。各リモートコンピュータ(例えば、スーパーコンピュータ上のノード)には、ワーカーを管理する単一の 「エグゼキューター」 があります。Parslが利用可能なリモートリソースは 、「プロバイダー」 によって取得され、 「ランチャー」 によってシステム上にエグゼキューターが配置されます。タスクの実行は、ローカルシステム上で実行される 「データフローカーネル」 によって仲介されます。

うん、さっぱりピンとこない。とりあえず、コードは「アプリ」になって、それをタスクとして投げたら、複数のサーバ内で「ワーカー」が実行する、という感じに見える。
このあと、
- アプリケーションタイプ
- エグゼキュータ
- 実行プロバイダ
- ランチャー
- データフローカーネル
という感じで 各コンポーネントの説明があるのだけど、今読んでも頭に入らないと思うので、このまま進めていく。
ドキュメントやチュートリアルをしばし眺めていたのだが、コンポーネントも色々あるとそこそこ複雑性も増すし、全体の仕組みとしても大きくなるので、文章での説明じゃなくて図でまとめられているものが欲しい。
でアプローチを変えてググッてみたら、以下の記事を見つけて、その画像がわかりやすかった。
というかParslは論文になっているのね。で、画像は論文の中で書かれているものだった
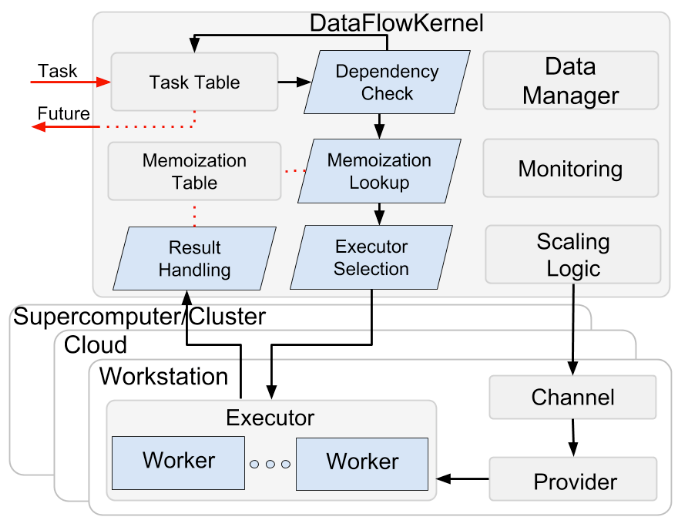
referred from: Babuji, Y., Woodard, A., Li, Z., Katz, D. S., Clifford, B., Kumar, R., Lacinski, L., Chard, R., Wozniak, J. M., Foster, I., Wilde, M., & Chard, K. (2019). Parsl: Pervasive Parallel Programming in Python. In HPDC ’19: Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing (pp. 25–36). https://doi.org/10.1145/3307681.3325400
とりあえず全体と各コンポーネントの動きが見えたので、この後も進めれそう。