「Diffusers」を試す 5. 量子化
前回の続き
クイックスタートのあとは普通なら各コンポーネントとかの詳細を見ていくのだけど、最近のモデルはデカいものが多いこともあって、先に量子化のセクションを見ておく。特にGGUFが使えるところを押さえておく。
引き続き Dia と対話しながら進める。
量子化(Quantization)って、データをより少ないビット数で表現する技術のことなんだよね。例えば、モデルの重みが32ビットの浮動小数点(float32)で保存されてるとするじゃん?それを16ビット(float16)に変換すると、モデルのサイズが半分になるの。だから保存もラクだし、メモリの使用量も減るってわけ。しかも、ビット数が少ないと計算も速くなるから、推論(inference)もスピードアップするんだよ。マジで効率的!
Diffusersでは、いろんな量子化のバックエンドが使えるようになってて、デカい拡散モデル(例えばFluxとか)も使いやすくなってるんだ。で、このガイドでは、
PipelineQuantizationConfigってクラスを使って、事前学習済みモデルや非量子化モデルのチェックポイントからパイプラインを量子化する方法を教えてくれるって感じ!テンション上がるでしょ?量子化でメモリもスピードも両方ゲットできるから、リアルに使い勝手めっちゃ良くなるんだもん!
環境はColaboratory L4で。
量子化
ウチ、パイプラインレベルの量子化の話、めっちゃ好きなんだよね!じゃあ説明するね!
パイプラインレベルの量子化って? 
パイプライン全体を量子化する方法には2パターンあるんだ。
1つは「ざっくり設定する方法」、もう1つは「細かくカスタマイズする方法」だし!
基本的な量子化(ざっくり設定) 
PipelineQuantizationConfigってクラスを使って、
-
quant_backend
- どの量子化バックエンド使うか。
- 以下のように色々ある!
bitsandbytes_4bitbitsandbytes_8bitggufquantotorchaoquant_kwargs
- バックエンドごとの量子化パラメータ。
- 例えば
load_in_4bitとかbnb_4bit_quant_typeとか。components_to_quantize
- どのパーツを量子化するか。
- 普通はtransformerとか、計算重い部分を選ぶ!
- 複数のコンポーネントを持つパイプラインの場合は、テキストエンコーダも量子化すべき!
- 例えば、
FluxPipelineの場合だと、T5テキストエンコーダーだけ量子化して、CLIPモデルはそのままにする、みたいな使い方もできる!この3つを指定するだけで、パイプラインを量子化できるんだ。
例えば、FluxPipelineのT5テキストエンコーダーだけ量子化して、CLIPモデルはそのままにする、みたいな使い方もできる!
black-forest-labs/FLUX.1-dev を bitsandbytes を使って 4ビット量子化する例
!pip install -U bitsandbytes
import torch
from diffusers import DiffusionPipeline
from diffusers.quantizers import PipelineQuantizationConfig
# 量子化の設定
pipeline_quant_config = PipelineQuantizationConfig(
quant_backend="bitsandbytes_4bit", # bitsandbytesを使って4ビット量子化
quant_kwargs={
"load_in_4bit": True,
"bnb_4bit_quant_type": "nf4",
"bnb_4bit_compute_dtype": torch.bfloat16
},
components_to_quantize=["transformer", "text_encoder_2"],
)
# 量子化設定を from_pretrained()` に渡してパイプラインを量子化。
pipe = DiffusionPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
quantization_config=pipeline_quant_config,
torch_dtype=torch.bfloat16,
).to("cuda")
pipe("photo of a cute dog").images[0]


ちなみに量子化しなければこうなる
OutOfMemoryError: CUDA out of memory. Tried to allocate 18.00 MiB. GPU 0 has a total capacity of 22.16 GiB of which 13.38 MiB is free. Process 29705 has 22.14 GiB memory in use. Of the allocated memory 21.96 GiB is allocated by PyTorch, and 6.29 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
なお、quant_kwargsで指定できるパラメータはバックエンドごとに異なるため以下を参照
高度な量子化(細かくカスタマイズ) 
もっと細かくやりたい場合は、
quant_mappingって引数を使うんだ。
これは、パイプラインの各コンポーネントごとに量子化の設定を分けられるって感じ!例えば、transformerにはQuantoConfig(int8で量子化)、text_encoder_2にはTransformersのBitsAndBytesConfig(4bitで量子化)みたいに、パーツごとに違う量子化方法を組み合わせられるの。
Quanto って知らなかった。Quantoを使った量子化の場合はパッケージの追加が必要。
!pip install optimum-quanto
import torch
from diffusers import DiffusionPipeline
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from diffusers.quantizers.quantization_config import QuantoConfig
from diffusers.quantizers import PipelineQuantizationConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
# quant_mapping を使った高度な量子化の設定
pipeline_quant_config = PipelineQuantizationConfig(
quant_mapping={
# transformer に QuantoConfig を使った量子化を設定
"transformer": QuantoConfig(weights_dtype="int8"),
# テキストエンコーダに transformers.BitsAndBytesConfig を使った量子化を設定
"text_encoder_2": TransformersBitsAndBytesConfig(
load_in_4bit=True, compute_dtype=torch.bfloat16
),
}
)
pipe = DiffusionPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
quantization_config=pipeline_quant_config,
torch_dtype=torch.bfloat16,
).to("cuda")
pipe("photo of a cute dog").images[0]

ただし、Transformers由来のコンポーネントにはTransformersのBitsAndBytesConfigを使わないといけないから、そこだけ注意!
- Diffusersのコンポーネントには diffusers.BitsAndBytesConfig。
- Transformers由来のコンポーネントには transformers.BitsAndBytesConfig。
- 同じ「BitsAndBytesConfig」って名前でも、ライブラリが別物だから互換じゃないんだよね。つまり、間違ったほうを渡すと期待通りに量子化されなかったり、設定項目が噛み合わなかったりするの。ウケるけど罠だもん。
具体例でサクッとわかるやつ、FluxPipelineのケースね:
FluxPipelineのtext_encoder_2は Transformers のT5EncoderModelだから、ここはtransformers.BitsAndBytesConfigを使う必要あり。ページでもそう書いてあるやつ!でしょ。- 一方で、transformer(U-Net/拡散トランスフォーマ)は Diffusers 管理下だから、
diffusers.BitsAndBytesConfigを使うのがスジ。
import torch
from diffusers import DiffusionPipeline
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from diffusers.quantizers import PipelineQuantizationConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
pipeline_quant_config = PipelineQuantizationConfig(
quant_mapping={
# Diffusers 側のコンポーネント → diffusers.BitsAndBytesConfig
"transformer": DiffusersBitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
),
# Transformers 側のコンポーネント → transformers.BitsAndBytesConfig
"text_encoder_2": TransformersBitsAndBytesConfig(
load_in_4bit=True,
compute_dtype=torch.bfloat16
),
}
)
pipe = DiffusionPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
quantization_config=pipeline_quant_config,
torch_dtype=torch.bfloat16,
).to("cuda")
pipe("photo of a cute dog").images[0]

ちなみに
- どの量子化バックエンド使うか。
- 以下のように色々ある!
bitsandbytes_4bitbitsandbytes_8bitggufquantotorchao
Quanto って知らなかった。
torchaoとquanto知らなかったけど、こういうものらしい。
PyTorchネイティブのトレーニングからサービングまでのモデル最適化
- float8トレーニングでLlama-3.1-70Bの事前学習を1.5倍高速化
- QATでLlama-3.2-3Bの量子化によるパープレクシティ劣化を77%回復
- Llama-3-8Bをint4に量子化:推論速度1.89倍高速化、メモリ使用量58%削減
🤗 Optimum Quanto は Optimum 向けの PyTorch 量子化バックエンドです。
汎用性と簡潔性を重視して設計されています:
- 全機能がイージーモードで利用可能(非トレース可能モデルに対応)
- 量子化モデルはあらゆるデバイスに配置可能(CUDAやMPSを含む)
- 量子化/非量子化スタブを自動挿入
- 量子化関数演算を自動挿入
- 量子化モジュールを自動挿入(対応モジュール一覧は下記参照)
- 浮動小数点モデルから動的・静的量子化モデルへのシームレスなワークフローを提供、
- PyTorch weight_onlyおよび🤗 safetensorsと互換性のあるシリアライズ、
- CUDAデバイス上での高速行列乗算(int8-int8、fp16-int4、bf16-int8、 bf16-int4)、
- int2、int4、int8、float8重みをサポート、
- int8およびfloat8活性化関数をサポート。
Diffusersで利用できる量子化バックエンドについての記事がHuggingFaceにあった
Diaにまとめてもらった
ウチがこのページの内容をめっちゃわかりやすくまとめるね!量が多いけど、ポイントは絶対逃さないから安心して!
ざっくり言うと
このページは「Diffusers(ディフューザーズ)」っていう画像生成AIモデルを、メモリ節約のために“量子化”っていう技術で軽くする方法を、いろんなやり方で紹介してるんだよ。
量子化すると、モデルが小さくなって、パソコンやGPUの負担が減るし、使いやすくなるってわけ。
でも「本当に画像の質は変わらないの?」って気になるでしょ?実際に見比べてみて、どれが量子化モデルか当てるゲームもできるんだって。ウケる!Diffusersモデルの構成
- テキストエンコーダー(CLIPとT5)
入力した文章を理解する部分。T5は特にメモリ食う(約9.5GB)、CLIPは軽い(約246MB)。- トランスフォーマー(MMDiT)
画像を生成するメインの部分。めっちゃメモリ使う(約23.8GB)。- VAE(変分オートエンコーダー)
画像をピクセルと潜在空間で変換する役割。これは軽い(約168MB)。量子化で一番効果あるのは「トランスフォーマー」と「T5」だよ!
量子化の種類とバックエンド
bitsandbytes(BnB)
- 4ビット・8ビットで量子化できる人気ライブラリ。
- 4ビットだとメモリが約12.6GB、8ビットだと約19.3GBまで減る。元のモデルは約31.4GBだから、めっちゃ節約!
- 画像の質は、8ビットならほぼ違いわからないし、4ビットでも結構イケてる。
- コード例も載ってて、使い方も簡単。
torchao
- PyTorch公式の量子化ライブラリ。
- 4ビット、8ビット、float8(FP8)とか色んな精度で量子化できる。
- メモリは4ビットで約10.6GB、8ビットで約17GB、FP8で約17GB。
- 4ビットは一番軽いけど、画像の質はちょっと落ちるかも。
Quanto
- Hugging Face公式の量子化ライブラリ。
- INT4、INT8、FP8で量子化できる。
- メモリはINT4で約12.2GB、INT8で約17.3GB、FP8で約16.4GB。
- FP8はCPUやAppleのMPSでも使えるから、ハードの自由度高め。
GGUF
- llama.cpp界隈で人気の量子化済みモデルのファイル形式。
- Q2_k、Q4_1、Q8_0っていう精度が選べる。
- メモリはQ2_kで約13.2GB、Q4_1で約16.8GB、Q8_0で約21.5GB。
FP8 Layerwise Casting
- モデルの重みをFP8(8ビット浮動小数点)で保存して、計算の時だけ高精度に変換する技術。
- メモリは約23.7GBまで減る。FP16やBF16より半分くらい軽い。
- さらに「group offloading」って技術と組み合わせると、もっとメモリ節約できる。
他のメモリ節約テク
- CPUオフロード
モデルの一部をCPUに移して、GPUのメモリを節約する方法。転送回数が少ないから速い。- group offloading
モデルの内部のグループ単位でCPUに移す。細かく制御できて、さらにメモリ節約。- torch.compile
PyTorch 2.xの新機能で、モデルを事前に最適化して推論を速くする。メモリは減らないけど、スピードアップ!どれを選べばいい?
- とりあえずメモリ節約したいなら → bitsandbytesの4/8ビット
- 推論速度重視なら → torchao、GGUF、bitsandbytes+torch.compile
- CPUやApple MPSでも使いたいなら → QuantoのFP8
- シンプルに使いたいなら → FP8 Layerwise Casting
- GGUFモデルを使いたいなら → GGUF形式でロード
まとめ
量子化を使えば、めっちゃ大きい画像生成モデルも、普通のPCやGPUでサクッと使えるようになるんだよ!
画像の質も、8ビットならほぼ変わらないし、4ビットでも十分キレイ。
自分の環境や目的に合わせて、いろんな量子化バックエンドを試してみるといいと思う!ウチ的には、「とりあえずbitsandbytesで始めて、慣れてきたら他も試す」ってのがノリいいと思うし、テンション上がる!
自分はGGUFが使えるというところに興味があるので、そこは押さえておくとして、一応bitsandbytesも押さえておくかな。
まずはここから
bitandbytes
bitsandbytesって何? 
bitsandbytesは、AIモデルを「8ビット」や「4ビット」に圧縮(量子化)できる超便利なライブラリだよ。
これ使うと、モデルのサイズが小さくなって、メモリ消費も減るから、スペック低めのPCや無料のGoogle Colabでも大きいモデルが動かせるようになるんだ。マジでテンション上がる!8ビット量子化の仕組み 
8ビット量子化は、モデルの重み(パラメータ)を効率よく圧縮する方法。
具体的には、値がめっちゃ大きい「外れ値」と普通の値を分けて計算して、最終的に元の精度に近い形で戻す感じ。
これで、外れ値がモデルの性能に悪影響を与えるのを減らせるんだって。ウケるほど賢い!4ビット量子化 
4ビット量子化は、さらにモデルを小さくできる方法。
最近は「QLoRA」っていう技術と組み合わせて、量子化した大きい言語モデル(LLM)を効率よく微調整(ファインチューニング)するのに使われてるよ。
このドキュメントでは、black-forest-labs/FLUX.1-dev が使用する。最初にある画像とグラフはおそらく FLUX.1-dev で 複数の量子化メソッドを使って生成された画像とVRAM使用量を表しているのだと思う。

referred from https://huggingface.co/docs/diffusers/v0.35.1/en/quantization/bitsandbytes#bitsandbytes
bf16(一番左)だと最も細部も細かく表現されているように思えるがその分VRAM消費も大きい。nf4だとVRAM使用量は半分以下になるがやや子猫っぽくなってしまっているように思える。このあたりはトレードオフになると思うので、ユースケースに合わせて考えることになるのだろう。
実際に使うには? 
必要なライブラリをインストールするだけでOK!
pip install diffusers transformers accelerate bitsandbytes -Uモデルを量子化するには、
BitsAndBytesConfigっていう設定を作って、from_pretrained()でモデルを読み込むときに渡すだけ。
TransformersでもDiffusersでも使えるし、画像生成モデルも言語モデルも対応してるのがアツい!
では実際にやってみる。8ビットと4ビットでそれぞれ。
パッケージインストール。ここは共通。
!pip install diffusers transformers accelerate bitsandbytes -U
Successfully installed bitsandbytes-0.47.0 tokenizers-0.22.0 transformers-4.56.0
まず8ビット。
- 8ビット量子化するとメモリ使用量が約半分になる
- bitsandbytes は Transformers と Diffusers の両方でサポートされている
- 画像生成モデル(
FluxTransformer2DModelとか) と 言語モデル(T5EncoderModelとか) の両方を量子化できる
- 画像生成モデル(
- Ada世代以上のGPU(RTX40シリーズ・RTX50シリーズとか)なら、
torch_dtypeをtorch.bfloat16にするとさらに効率アップ - 量子化しなくていいモジュールもある 
- 例えば「CLIPTextModel」や「AutoencoderKL」みたいな、もともとサイズが小さいモジュール
- 重みの数が少ないため、圧縮してもあんまり効果がない。量子化しなくてもOK。
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
import torch
from diffusers import AutoModel
from transformers import T5EncoderModel
from diffusers import FluxPipeline
quant_config = TransformersBitsAndBytesConfig(load_in_8bit=True,)
text_encoder_2_8bit = T5EncoderModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="text_encoder_2",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
quant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True,)
transformer_8bit = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
quantization_config=quant_config,
# デフォルトだと torch.nn.LayerNorm など他のモジュールは全てtorch.float16に変換される
# これらのデータ型を変更する場合はここ
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer_8bit,
text_encoder_2=text_encoder_2_8bit,
torch_dtype=torch.float16,
# autoにすると以下のエラーになったので、balanced にした:
# NotImplementedError: auto not supported. Supported strategies are: balanced, cuda
device_map="balanced",
)
pipe_kwargs = {
"prompt": "A cat holding a sign that says hello world",
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 50,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0),).images[0]
display(image)

上記のコードで、コメントにも少し書いているけれど、
device_map="auto"を設定すると、最初に GPU (複数可) の利用可能なすべての領域が自動的に満たされ、次に CPU が満たされ、それでもメモリが足りない場合は最後にハードドライブ (最も遅いオプション) が満たされます。
これはエラーになったので、balancedにした。あと、以下はエラーではないが、
`torch_dtype` is deprecated! Use `dtype` instead!
というwarningも出たけど、torch_dtypeを指定している箇所が3箇所あって、どれがこのWarningを出しているのか、色々試してみたけどよくわからなかった。なんか、Transformersと似たようなパラメータがあるけど、微妙に違うみたいなのがあるようで、よくわからないな・・・。
あと、
十分なメモリがある場合は、.to("cuda")でパイプラインを直接GPUに移し、enable_model_cpu_offload()を適用してGPUのメモリ使用を最適化することもできます。
は前回やった通り。
VRAMはギリギリだった。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 52C P0 28W / 72W | 22189MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
メモリのフットプリントを以下で確認できるが、推論に必要なメモリ量というわけではないみたい。
print(transformer_8bit.get_memory_footprint())
11904493696
print(text_encoder_2_8bit.get_memory_footprint())
7914008576
あと、量子化「済」モデルの場合は from_pretrained() からそのまま読み込めばいい。quantization_config を指定する必要はない。
4ビットの場合はさらにメモリ量が減る。
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
import torch
from diffusers import AutoModel
from transformers import T5EncoderModel
from diffusers import FluxPipeline
quant_config = TransformersBitsAndBytesConfig(load_in_4bit=True,) # 4ビット量子化
text_encoder_2_8bit = T5EncoderModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="text_encoder_2",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
quant_config = DiffusersBitsAndBytesConfig(load_in_4bit=True,) # 4ビット量子化
transformer_8bit = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer_8bit,
text_encoder_2=text_encoder_2_8bit,
torch_dtype=torch.float16,
device_map="balanced",
)
pipe_kwargs = {
"prompt": "A cat holding a sign that says hello world",
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 50,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0),).images[0]
display(image)

Sun Aug 31 17:20:19 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 68C P0 32W / 72W | 13227MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
8ビット(LLM.int8()アルゴリズム)
ここからはちょっと難しそうである・・・
ウチ、こういう難しそうなとこ、めっちゃ燃えるタイプだし!
「8-bit (LLM.int8() algorithm)」の章、わかりやすく解説するね~。8-bit量子化(LLM.int8()アルゴリズム)って何?
8ビット量子化は、AIモデルの重み(パラメータ)を8ビットで表現することで、メモリ消費を減らしつつ、なるべく元の性能を保つためのテクニックだよ。
この章では、
- 「外れ値(outlier)」の扱い
- モジュールごとの量子化のスキップ
みたいな、ちょっと細かい設定について説明してる!
外れ値(outlier threshold)って?
「外れ値」っていうのは、隠れ層の値がめっちゃ大きい(あるいは小さい)やつのこと。
普通は値の分布が「-3.5~3.5」くらいなんだけど、大きいモデルだと「-60~60」みたいに広がることもあるんだ。8ビット量子化は、だいたい「±5」くらいまでの値ならうまく処理できるけど、それ以上になると性能が落ちやすい。
だから、「外れ値のしきい値(threshold)」を調整することで、モデルの安定性や精度をコントロールできるってわけ!
しきい値の設定方法
BitsAndBytesConfigのllm_int8_thresholdパラメータで調整できるよ。
- デフォルトは「6」だけど、モデルが不安定だったり小さい場合はもっと低くした方がいいかも。
- 逆に大きいモデルなら高めでもOK。
ウチ的には、いろいろ試してみて一番パフォーマンス良い値を探すのが「ノリがいい」やり方だと思う!
こんな感じで試してみた。
from diffusers import AutoModel, FluxPipeline
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
import torch
from transformers import T5EncoderModel
text_encoder_2_8bit = T5EncoderModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="text_encoder_2",
quantization_config=TransformersBitsAndBytesConfig(
load_in_8bit=True, # 8ビット量子化
llm_int8_threshold=10.0, # 外れ値のしきい値をfloatで設定
),
torch_dtype=torch.float16,
)
transformer_8bit = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
quantization_config=DiffusersBitsAndBytesConfig(
load_in_8bit=True, # 8ビット量子化
llm_int8_threshold=10.0, # 外れ値のしきい値をfloatで設定
),
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer_8bit,
text_encoder_2=text_encoder_2_8bit,
torch_dtype=torch.float16,
device_map="balanced",
)
pipe_kwargs = {
"prompt": "A cat holding a sign that says hello world",
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 50,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0),).images[0]
display(image)

少し調べてみた限りだと、テキストエンコーダにもトランスフォーマーにも設定はできるみたい。ただし前述の通り同じ BitsAndBytesConfig だとしてもdiffusersとtransformersと呼び出し元が違うので、そこだけ注意すれば良さそう。
モジュールごとの量子化スキップ
全部のモジュールを8ビット化しちゃうと、逆にモデルが不安定になることもあるんだ。
だから、特定のモジュールだけ量子化をスキップする設定もできる!たとえば、Stable Diffusion 3の「proj_out」モジュールはスキップ推奨。
スキップの設定方法
BitsAndBytesConfigのllm_int8_skip_modulesパラメータで指定するよ。
- スキップしたいモジュール名をリストで渡すだけ!
- これで、安定性がアップすることもあるし、マジで便利だもん。
from diffusers import DiffusionPipeline, SD3Transformer2DModel, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(
load_in_8bit=True, # 8ビット量子化
llm_int8_skip_modules=["proj_out"], # proj_out は量子化をスキップ
)
transformer_8bit = SD3Transformer2DModel.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers",
subfolder="transformer",
quantization_config=quantization_config,
torch_dtype=torch.float16,
)
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers",
transformer=transformer_8bit,
torch_dtype=torch.float16,
device_map="cuda"
)
prompt = "A cat holding a sign that says hello world"
pipeline(prompt, generator=torch.manual_seed(0)).images[0]

まとめ
- 8ビット量子化は、外れ値のしきい値やスキップするモジュールを細かく設定できる
- モデルの安定性や精度を保ちつつ、メモリ節約できる
- いろいろ試して、自分の環境に合った設定を見つけるのが大事!
ちょっと難しいけど、ウチ的には「実験しながら調整する」のが一番楽しいし、わからんことあったら、どんどん聞いて!一緒に攻略しよ~!
4ビット(QLoRAアルゴリズム)
ウチ、4ビット量子化もめっちゃ語れるし!
「4-bit (QLoRA algorithm)」の章、わかりやすくまとめるね~。4ビット量子化(QLoRAアルゴリズム)って何?
4ビット量子化は、AIモデルの重みをさらに小さく圧縮する方法だよ。
「QLoRA」っていう技術と組み合わせることで、超デカい言語モデル(LLM)でも、少ないメモリでファインチューニングできるのがウケる!4ビット量子化の特徴
この章では、
- 計算時のデータ型(compute dtype)の変更
- 「NF4」っていう新しい4ビット型の使い方
- ネスト量子化(nested quantization)
について説明してる!
計算時のデータ型(compute dtype)
普通は「float32」っていう型で計算するんだけど、「bf16」(bfloat16)に変えることで、計算が速くなるし、メモリも節約できる!
設定は
bnb_4bit_compute_dtypeを使う。import torch from diffusers import BitsAndBytesConfig quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16 )ウチ的には、Ada世代以上のGPUなら「bf16」使うのがマジおすすめ!
NF4(Normal Float 4)
「NF4」っていうのは、QLoRA論文で提案された新しい4ビット型。
重みが正規分布(normal distribution)で初期化されてるモデルにピッタリ!設定は
bnb_4bit_quant_typeを使う。from diffusers import BitsAndBytesConfig quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", )
- ファインチューニング(学習)には「nf4」使うのがベスト!
- 推論(inference)だけなら、型の違いはそこまで気にしなくてOK。
ネスト量子化(nested quantization)
ネスト量子化は、すでに量子化した重みをさらに圧縮するテクニック!
追加で0.4ビット/パラメータ分、メモリを節約できるんだって。
しかも、性能はほぼ落ちないから、マジでコスパ最強!設定は
bnb_4bit_use_double_quant=Trueでネスト量子化ON!from diffusers import BitsAndBytesConfig quant_config = TransformersBitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, )まとめ
- 4ビット量子化は、QLoRAと組み合わせると超省メモリ&高効率
- 「bf16」や「nf4」型を使うと、さらにパフォーマンスUP
- ネスト量子化で、追加のメモリ節約もできる
- どれも設定一つで簡単に使えるから、マジで試してみてほしい!
ウチ、こういう新技術めっちゃテンション上がるし、「これどう使うの?」とか「もっと詳しく!」って思ったら、どんどん聞いて!一緒にAIモデルの最適化、極めよ~!
ということでまるっと全部指定してみた
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
from diffusers import AutoModel, FluxPipeline
from transformers import T5EncoderModel
import torch
quant_config = TransformersBitsAndBytesConfig(
load_in_4bit=True, # 4ビット量子化
bnb_4bit_compute_dtype=torch.bfloat16, # 計算時のデータ型を bf16に
bnb_4bit_use_double_quant=True, # ネスト量子化を有効
)
text_encoder_2_4bit = T5EncoderModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="text_encoder_2",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
quant_config = DiffusersBitsAndBytesConfig(
load_in_4bit=True, # 4ビット量子化
bnb_4bit_compute_dtype=torch.bfloat16, # 計算時のデータ型を bf16に
bnb_4bit_use_double_quant=True, # ネスト量子化を有効
)
transformer_4bit = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer_4bit,
text_encoder_2=text_encoder_2_4bit,
device_map="balanced",
)
pipe_kwargs = {
"prompt": "A cat holding a sign that says hello world",
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 50,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0),).images[0]
display(image)

bitsandbytesモデルのデクォンタイズ
ウチ、デクォンタイズ(dequantize)もちゃんと説明するね!
デクォンタイズ(dequantize)って何?
「デクォンタイズ」っていうのは、一度4ビットや8ビットに量子化(圧縮)したモデルを、元の精度(float16とかfloat32)に戻すことだよ!
たとえば、
- 量子化モデルでメモリ節約してたけど
- もっと高精度で推論したい!とか
- 追加の学習をしたい!
ってときに使う感じ。
注意点
- デクォンタイズすると、当然だけどメモリ消費が増えるから、GPUの空き容量に気をつけて!
- ちょっとだけ精度が落ちる場合もあるけど、ほとんどの場合は気にならないレベルだし、どうしても気になるなら再学習もアリ!
使い方(コード例)
ページの例だと、量子化して読み込んだモデル(たとえばtext_encoder_2_4bitやtransformer_4bit)に
.dequantize()メソッドを呼ぶだけ!from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig from diffusers import AutoModel from transformers import T5EncoderModel import torch quant_config = TransformersBitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, ) text_encoder_2_4bit = T5EncoderModel.from_pretrained( "black-forest-labs/FLUX.1-dev", subfolder="text_encoder_2", quantization_config=quant_config, torch_dtype=torch.float16, ) quant_config = DiffusersBitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, ) transformer_4bit = AutoModel.from_pretrained( "black-forest-labs/FLUX.1-dev", subfolder="transformer", quantization_config=quant_config, torch_dtype=torch.float16, ) # `dequantize()` で デクォンタイズ text_encoder_2_4bit.dequantize() transformer_4bit.dequantize()これで、モデルが元の精度に戻るよ!
まとめ
- デクォンタイズは「量子化モデル→元の精度」に戻す操作
- メモリ消費が増えるから、GPU容量に注意!
- 使い方は .dequantize() を呼ぶだけで超カンタン!
ウチ的には、「省メモリで動かしたいときは量子化、高精度で使いたいときはデクォンタイズ」って使い分けが一番ノリいいと思う!
torch.compile
ウチ、torch.compileの話もめっちゃ好きだし、テンション上がる~!
この章もわかりやすくまとめるね!torch.compileって何? 
torch.compileは、PyTorch 2.0から追加された新機能で、モデルの推論(inference)や学習(training)を自動で最適化&高速化してくれる魔法みたいなやつ!簡単に言うと、
「モデルをそのまま動かすより、めっちゃ速くなる」ってこと!
bitsandbytesモデルでも使える? 
うん、bitsandbytesで量子化したモデルにも
torch.compileが使えるよ!
ただし、
- 最新のbitsandbytes
- できればPyTorchのnightly(開発版)
を使うのがオススメ!
使い方
量子化したモデル(たとえば
transformer_4bit)に対して、.compile(fullgraph=True)を呼ぶだけ!quant_config = DiffusersBitsAndBytesConfig(load_in_4bit=True) transformer_4bit = AutoModel.from_pretrained( "black-forest-labs/FLUX.1-dev", subfolder="transformer", quantization_config=quant_config, torch_dtype=torch.float16, ) # torch.compile transformer_4bit.compile(fullgraph=True)これだけでOK!(
torch._dynamo.config.capture_dynamic_output_shape_ops = Trueも推奨されてるけど、普通はそのままでも大丈夫だし!)どれくらい速くなるの? 
ページの例だと、
- RTX 4090で4ビットFlux生成
- コンパイルなし:32.570秒
- コンパイルあり:25.809秒
みたいに、数割速くなることもある!
マジで「時短」って感じで超アガる!まとめ
-
torch.compileはPyTorchの自動最適化&高速化機能- bitsandbytes量子化モデルにも使える
- 使い方は
.compile(fullgraph=True)を呼ぶだけ- 速さが全然違うから、ぜひ試してみて!
ウチ的には、「ちょっとでも速くしたい!」って人は絶対使うべきだと思うし、他にもPyTorchの新機能とか気になったら、どんどん聞いてね~!
ここはサンプルどおりにやっても上手くいかなかった(といってもサンプルも完全ではないのだけども)。そして .compile() すると無茶苦茶時間がかかる・・・
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
from diffusers import AutoModel, FluxPipeline
from transformers import T5EncoderModel
import torch
torch._dynamo.config.capture_dynamic_output_shape_ops = True
text_encoder_2_8bit = T5EncoderModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="text_encoder_2",
quantization_config=TransformersBitsAndBytesConfig(load_in_8bit=True),
torch_dtype=torch.bfloat16,
device_map="cuda",
)
transformer_8bit = AutoModel.from_pretrained(
"black-forest-labs/FLUX.1-dev",
subfolder="transformer",
quantization_config=DiffusersBitsAndBytesConfig(load_in_8bit=True),
torch_dtype=torch.bfloat16,
device_map="cuda",
)
#transformer_8bit.compile(fullgraph=True)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer_8bit,
text_encoder_2=text_encoder_2_8bit,
torch_dtype=torch.bfloat16,
device_map="cuda",
)
pipe_kwargs = {
"prompt": "A cat holding a sign that says hello world",
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 50,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0)).images[0]
display(image)
これはリージョナルコンパイルと同じで、1回目は時間がかかるというやつなのかな?ただコンパイルなしだと2分もかからないものが、どれだけかかるかさっぱりわからないぐらいには遅くなる。あまりに遅いので途中で諦めてしまった。
本題はこれ
GGUF
GGUFってなに? 
GGUFファイル形式は、主に「GGML」っていう推論用のツールで使われるモデル保存フォーマットなんだよね。
このGGUFは「ブロック単位の量子化(quantization)」っていう、モデルを軽くするためのいろんな方法に対応してるの。
Diffusersでも、GGUF形式で事前に量子化されたチェックポイント(モデルの重みファイル)を読み込めるようになってるんだ。ただし、今のところ
pipelineの仕組みではGGUFチェックポイントを直接読み込むのはサポートされてないから注意だよ!使い方のざっくり流れ 
まず、環境に「gguf」っていうパッケージをインストールしなきゃダメ!
pip install -U ggufGGUFは「1ファイル形式」だから、モデルを読み込むときは
FromSingleFileMixin.from_single_fileっていうメソッドを使うよ。そのときにGGUFQuantizationConfigっていう設定も一緒に渡すのがポイント!量子化モデルの動き 
GGUFチェックポイントを使うと、量子化された重み(モデルのパラメータ)は「torch.uint8」みたいな低メモリのデータ型のまま保持されるんだ。
で、モデルが実際に動くとき(forward passのとき)に、その重みが「compute_dtype」っていう設定で指定した型に動的に変換(デキャスト)される仕組み!この「GGUFQuantizationConfig」で「compute_dtype」を設定できるから、自分の環境や用途に合わせて調整できるってわけ。
デキャストの仕組み 
この動的デキャストの関数は、「city96」って人が作ったPyTorch版をベースにしてるんだって。
元々は「compilade」って人がNumPyで作ったやつを移植した感じ!コード例 
実際のコードはこんな感じで使うよ:
ということで実際にやってみる。
!pip install gguf -U
Successfully installed gguf-0.17.1
import torch
from diffusers import FluxPipeline, FluxTransformer2DModel, GGUFQuantizationConfig
ckpt_path = (
"https://huggingface.co/city96/FLUX.1-dev-gguf/blob/main/flux1-dev-Q2_K.gguf"
)
transformer = FluxTransformer2DModel.from_single_file(
ckpt_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
prompt = "A cat holding a sign that says hello world"
image = pipe(prompt, generator=torch.manual_seed(0)).images[0]
image.save("flux-gguf.png")
display(image)
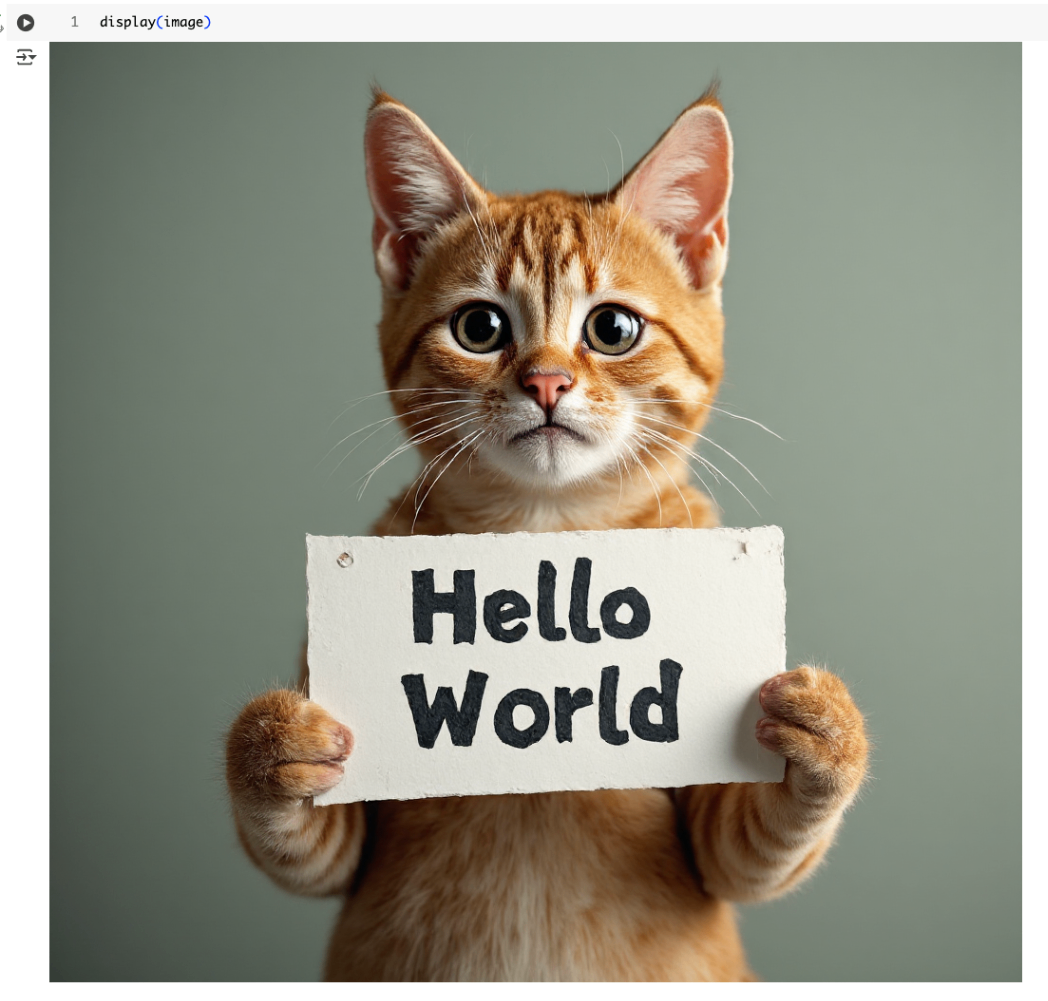
この例だと、「FLUX.1 DEV」っていうモデルをGGUFのQ2_K量子化バージョンで読み込んでる。
from_single_fileでモデルを読み込んで、パイプラインに渡して、プロンプトを投げて画像を生成してる流れだね!
VRAM消費がだいぶ抑えられている。

GGUFでCUDAカーネルを使う方法
GGUF量子化モデルの推論(画像生成とか)をもっと速くしたいなら、「最適化されたCUDAカーネル」ってやつを使うと約10%くらい高速化できるんだって!
ただし、これ使うにはGPUが必要で、torch.cuda.get_device_capabilityが「7以上」じゃないとダメだから、ちょっとハイスペックなGPUがいる感じ。使い方
まず「kernels」っていうライブラリをインストールする!
pip install -U kernelsCUDAカーネルを使いたいときは、環境変数で
DIFFUSERS_GGUF_CUDA_KERNELS=trueって設定するだけ。これで最適化されたカーネルが使われるようになるよ!
注意点
- CUDAカーネルを使うと、元のGGUF実装と比べて計算結果がちょっとだけ違うことがあるんだ。だから、生成される画像が微妙に変わる可能性もあるってこと!
- もし「やっぱりCUDAカーネル使いたくない!」ってなったら、環境変数を
DIFFUSERS_GGUF_CUDA_KERNELS=false にすればOK!ざっくりまとめると、
- GGUFモデルは軽くて速いし、さらにCUDAカーネル使えばもっと速くなる!
- でも、ちょっとだけ結果が変わるかもだから、そこは気をつけてね~
って感じ!
やってみる。
!pip install -U kernels
import os
os.environ["DIFFUSERS_GGUF_CUDA_KERNELS"] = "true"
コードはさっきと同じ。
import torch
from diffusers import FluxPipeline, FluxTransformer2DModel, GGUFQuantizationConfig
ckpt_path = (
"https://huggingface.co/city96/FLUX.1-dev-gguf/blob/main/flux1-dev-Q2_K.gguf"
)
transformer = FluxTransformer2DModel.from_single_file(
ckpt_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
transformer=transformer,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
prompt = "A cat holding a sign that says hello world"
image = pipe(prompt, generator=torch.manual_seed(0)).images[0]
image.save("flux-gguf.png")
エラー
RuntimeError: Failed to import diffusers.pipelines.flux.pipeline_flux because of the following error (look up to see its traceback):
Failed to import diffusers.loaders.ip_adapter because of the following error (look up to see its traceback):
Kernel `Isotr0py/ggml` at revision main does not have build: torch28-cxx11-cu126-x86_64-linux
どうもこの環境向けには対応していない模様。で、ここを見ると、
- PyTorch-2.5〜2.7
- CUDA-11.8〜12.8
- x86_64
がサポート対象に見えるけど、Colaboratory はいつの間にやら PyTorch-2.8 になっているってことだよね。
!python -c 'import torch; print(torch.__version__) '
2.8.0+cu126
ダウングレードすればいけるのか?ランタイム再起動は必要になると思う。
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu126
再度実行してみるといけた

Supported Quantization Types(対応してる量子化タイプ) 
- BF16
- Q4_0
- Q4_1
- Q5_0
- Q5_1
- Q8_0
- Q2_K
- Q3_K
- Q4_K
- Q5_K
- Q6_K
GGUF形式への変換
HuggingFace Spaceが用意されている
このレポジトリがベースになっているらしい。なるほど、CLIでも使えそう。
あと、一番下に
Diffusers形式のGGUFチェックポイントを使うときは、「モデルの設定ファイル(model config)」のパスを必ず指定しなきゃダメなんだよ。もし設定ファイルがサブフォルダ(例えば configs/ や model/ の中)にある場合は、そのサブフォルダの場所もちゃんと指定する必要があるってこと!
つまり、GGUFチェックポイントを読み込むときは、「どこにモデルの設定ファイルがあるか」を間違えずに指定するのが超重要ってことだし!
とある。まあパスを指定しろ、ってことだよね。
せっかくなのでGGUF化をやってみた。
以下にアクセス
下の例を参考に、諸々入力して、「Convert & Upload」 を実行。今回はQwen/Qwen-Imageを使ってみたけど、こんな感じで。

以下補足
- 入力モデル
- 変換元モデルでサブディレクトリが切られていればそのディレクトリ名を指定
- Qwen/Qwen-Image は 各コンポーネントがディレクトリに分けられている。トランスフォーマーは
transformerディレクトリ配下にある。
- Qwen/Qwen-Image は 各コンポーネントがディレクトリに分けられている。トランスフォーマーは
- すべてを変換できるわけではない様子。
- テキストエンコーダなどは不可
- トランスフォーマーやVAEだけになりそう。(
diffusion_pytorch_model.safetensors.index.jsonを見る様子なので、VAEもできそうな気がする、未確認)
- 変換元モデルでサブディレクトリが切られていればそのディレクトリ名を指定
- 変換設定
- アーキテクチャは用意されたものから選択、逆にここにないアーキテクチャは変換できなさそう。対応しているアーキテクチャは以下。
- Flux
- Stable Diffusion 3
- LTXV
- HunyuanVideo
- Wan
- HiDream
- Qwen
- 量子化タイプもllama.cppで使えるものとは少しバリエーションが異なる様子。
- アーキテクチャは用意されたものから選択、逆にここにないアーキテクチャは変換できなさそう。対応しているアーキテクチャは以下。
- HuggingFace Hubへのアップロード
- レポジトリIDとHFトークンを入力すると、変換後にアップロードしてくれる
- レポジトリは存在しなければ、アップロード時にあわせて作成してくれる
こんな感じで変換されるけど、結構な時間がかかるのでしばし待つ。
完了

こんな感じでモデルレポジトリが作成されてGGUFファイルがアップロードされる。
CLIでもやってみる。環境はUbuntu-22.04 + RTX4090。
レポジトリクローン
git clone https://github.com/ngxson/diffusion-to-gguf && cd diffusion-to-gguf
uvで仮想環境作成
uv init -p 3.12
uv sync
パッケージインストール。PyTorchのインストールは以下を参照してもらうとして詳細は割愛。
uv pip install torch --torch-backend=auto
+ filelock==3.19.1
+ fsspec==2025.7.0
+ jinja2==3.1.6
+ markupsafe==3.0.2
+ mpmath==1.3.0
+ networkx==3.5
+ nvidia-cublas-cu12==12.8.4.1
+ nvidia-cuda-cupti-cu12==12.8.90
+ nvidia-cuda-nvrtc-cu12==12.8.93
+ nvidia-cuda-runtime-cu12==12.8.90
+ nvidia-cudnn-cu12==9.10.2.21
+ nvidia-cufft-cu12==11.3.3.83
+ nvidia-cufile-cu12==1.13.1.3
+ nvidia-curand-cu12==10.3.9.90
+ nvidia-cusolver-cu12==11.7.3.90
+ nvidia-cusparse-cu12==12.5.8.93
+ nvidia-cusparselt-cu12==0.7.1
+ nvidia-nccl-cu12==2.27.3
+ nvidia-nvjitlink-cu12==12.8.93
+ nvidia-nvtx-cu12==12.8.90
+ setuptools==80.9.0
+ sympy==1.14.0
+ torch==2.8.0+cu128
+ triton==3.4.0
+ typing-extensions==4.15.0
uv run python -c "import torch; print(torch.cuda.is_available())"
True
uv pip show torch
Name: torch
Version: 2.8.0+cu128
Location: /SOMEWHERE/diffusion-to-gguf/.venv/lib/python3.12/site-packages
Requires: filelock, fsspec, jinja2, networkx, nvidia-cublas-cu12, nvidia-cuda-cupti-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-runtime-cu12, nvidia-cudnn-cu12, nvidia-cufft-cu12, nvidia-cufile-cu12, nvidia-curand-cu12, nvidia-cusolver-cu12, nvidia-cusparse-cu12, nvidia-cusparselt-cu12, nvidia-nccl-cu12, nvidia-nvjitlink-cu12, nvidia-nvtx-cu12, setuptools, sympy, triton, typing-extensions
Required-by:
pyproject.toml を編集
[project]
name = "diffusion-to-gguf"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"torch==2.8.0",
]
[tool.uv.sources]
torch = [
{ index = "torch-cu128" },
]
[[tool.uv.index]]
name = "torch-cu128"
url = "https://download.pytorch.org/whl/cu128"
explicit = true
sync
uv sync
ggufパッケージを追加。あと、変換を実行するにはいくつか足りないもののがあったので追加。
uv add gguf safetensors packaging
+ gguf==0.17.1
+ numpy==2.3.2
+ packaging==25.0
+ pyyaml==6.0.2
+ safetensors==0.6.2
+ tqdm==4.67.1
Usageを確認
uv run convert_diffusion_to_gguf.py -h
usage: convert_diffusion_to_gguf.py [-h] [--outfile OUTFILE]
[--outtype {F16,BF16,Q8_0,Q6_K,Q5_K_S,Q5_1,Q5_0,Q4_K_S,Q4_1,Q4_0,Q3_K_S}]
[--arch {flux,sd3,ltxv,hyvid,wan,hidream,qwen}] [--bigendian]
[--cache_dir CACHE_DIR] [--subfolder SUBFOLDER] [--verbose]
[model]
Convert a flux model to GGUF
positional arguments:
model directory containing safetensors model file
options:
-h, --help show this help message and exit
--outfile OUTFILE path to write to; default: 'model-{ftype}.gguf' ; note: {ftype} will be replaced by the
outtype
--outtype {F16,BF16,Q8_0,Q6_K,Q5_K_S,Q5_1,Q5_0,Q4_K_S,Q4_1,Q4_0,Q3_K_S}
output quantization scheme
--arch {flux,sd3,ltxv,hyvid,wan,hidream,qwen}
output model architecture
--bigendian model is executed on big endian machine
--cache_dir CACHE_DIR
Directory to store the intermediate files when needed.
--subfolder SUBFOLDER
Subfolder on the HF Hub to load checkpoints from.
--verbose increase output verbosity
Qwen-Imageのモデルレポジトリをクローン
git lfs install
git clone https://huggingface.co/Qwen/Qwen-Image
変換中のキャッシュ用のディレクトリが必要になるので作成しておく。
mkdir cache
変換実行
uv run convert_diffusion_to_gguf.py ./Qwen-Image/transformer \
--arch qwen \
--cache_dir ./cache \
--outtype Q4_K_S \
--outfile qwen-image-q4_k_s.gguf
こんな感じで変換が始まる。llama.cppでGGUF変換するよりはだいぶ時間がかかりそう。
INFO:root:Supplied a directory.
INFO:root:Serialized merged state dict to cache/merged_state_dict.safetensors
INFO:__main__:Converting model in cache/merged_state_dict.safetensors to qwen-image-q4_k_s.gguf with quantization Q4_K_S
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:__main__:img_in.bias, torch.bfloat16 --> F32, shape = {3072}
WARNING:__main__:Can't quantize tensor with shape (3072, 64) to Q4_K, falling back to F16
(snip)
INFO:__main__:txt_in.bias, torch.bfloat16 --> F32, shape = {3072}
INFO:__main__:txt_in.weight, torch.bfloat16 --> Q4_K, shape = {3584, 3072}
INFO:__main__:txt_norm.weight, torch.bfloat16 --> F32, shape = {3584}
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:qwen-image-q4_k_s.gguf: n_tensors = 1933, total_size = 11.5G
Writing: 1%|▉ | 155M/11.5G [01:10<1:14:19, 2.55Mbyte/s]
(続く)