Twelve Labsを試す
たまたま見つけた。
気になったのはこれ
マルチモーダル対応のEmbeddingモデルらしく、以下の検索が可能
- Text-to-Video
- Image-to-Video
- Text-to-Audio
- Audio-to-Video
公式サイト
Feloで調べてみた
Twelve Labsについて
会社概要
Twelve Labsは、2021年に設立されたAI企業で、主に動画理解技術に特化しています。彼らの製品は、動画の検索や分析を行うためのプロプライエタリなAIを提供しており、特に動画コンテンツの推薦やターゲット広告に利用されています。Twelve Labsは、動画のアクション、オブジェクト、音声、テキストなどの情報を抽出し、ユーザーが必要なコンテンツを迅速に見つけられるようにすることを目指しています[1][2][3]。
技術と機能
Twelve Labsのプラットフォームは、マルチモーダルAIを活用しており、動画の内容を人間のように理解する能力を持っています。これにより、ユーザーは自然言語を用いて動画を検索でき、メタデータタグだけでなく、文脈や意味に基づいた検索結果を得ることが可能です。最近、Mimirというクラウドネイティブなアセット管理会社との統合により、動画のセマンティック検索機能が強化され、ユーザーはより直感的にコンテンツを探し出すことができるようになりました[2:1][4][5]。
市場と顧客
Twelve Labsの顧客は多岐にわたり、動画制作会社、放送局、デジタルエージェンシー、教育機関などが含まれます。彼らの技術は、特に大量の動画データを扱う企業にとって、コンテンツの発見や利用を大幅に向上させるものです[1:1][2:2][6]。
今後の展望
Twelve Labsは、動画理解の分野でのリーダーシップを確立し、さらなる技術革新を目指しています。彼らは、動画データが世界のデータの80%を占める中で、動画理解技術の重要性が増すと考えており、今後もマルチモーダルAIの発展に寄与していく意向を示しています[6:1][7][8]。
Embed APIの公式ブログ記事
このEmbeddingモデルも含めて少し色々調べてみたところ、以下にTwelve Labsのプラットフォームの概要がある。

refered from https://docs.twelvelabs.io/docs/platform-overview
サービスとして提供されているAPIは、今回のEmbed APIを除くと以下の3つ
- Generate: 動画から要約などのテキスト生成
- Classify: 動画を分類
- Search: 動画を自然言語で検索
これらを利用するには、動画をTwelve Labsプラットフォーム上にアップロードしインデックスを作成する必要がある。
で、これらの基盤となっているのがTwelve LabsのマルチモーダルEmbeddingモデルであり、今回新たにそのモデルを使ってembeddingsを生成できるのがEmbed APIということらしい。
EmbeddingモデルについてはEmbed APIのブログ記事内に記載されている。
| モデル名 | モダリティ | 次元数 | 類似性メトリクス |
|---|---|---|---|
| Marengo-retrieval-2.6 | 動画 / 音声 / 画像 / テキスト (すべて同じ潜在空間) |
1024 | コサイン類似度 |
Embed APIに関するドキュメントは以下
で、各モダリティごとにドキュメントが分かれている
動画
テキスト
音声
画像
これらをざっと見てみた感じ、動画以外はEmbed APIに投げるだけだが、動画の場合はTwelve Labsのプラットフォーム上での作業が必要になる。
- Twelve Labsにインデックスを作成
- 動画をインデックスにアップロード
- embeddings生成タスクが実行
- タスク完了後にembeddingsを取得
また、各モダリティごとの仕様は以下となっている模様。
動画
- 1動画に対して1 embeddingsではなく、2〜10秒ごとに分割され、それぞれのembeddingsが生成される
- 動画の解像度は: 480x360 / 360x480 〜 4K (3840x2160)
- 動画・音声のフォーマットはffmpegで対応しているフォーマット
- 動作ファイルの長さは、4秒〜最大2時間
- 動画ファイルサイズは2GB以下
テキスト
- 最大入力トークンは77トークン
音声
- 音声の再生時間は10秒以下
- 音声フォーマットはWAV / MP3 / FLAC
画像
- 画像ファイルの最大サイズは5MB
- 画像のフォーマットは JPEG / PNG
- 画像の解像度は378 x 378 px以上
これらを見る限り、あくまでも動画がメインであって、テキスト・音声・画像は検索時のクエリとして使う、というユースケースに思える。逆に言うと、会議動画・会議音声・議事録のテキスト・議事録の画像みたいなものを全部ベクトル化して1つのベクトルDBに保存しておいて検索、みたいなのは難しそうに思う。
とはいえ、すべてが同じベクトル空間の中にあるっていうのはちょっと興味深い。
データセット用意してやってみようと思ったのだけど、マルチモーダルなデータセットでライセンス等に問題がなさそうなものが見当たらない。動画とかになるとYouTubeが多くて、自分の動画ならまだしも人様のとなると・・・
ということで、少しPlaygroundを試してみる。アカウント作成してログインすると、こんな感じの画面になる。
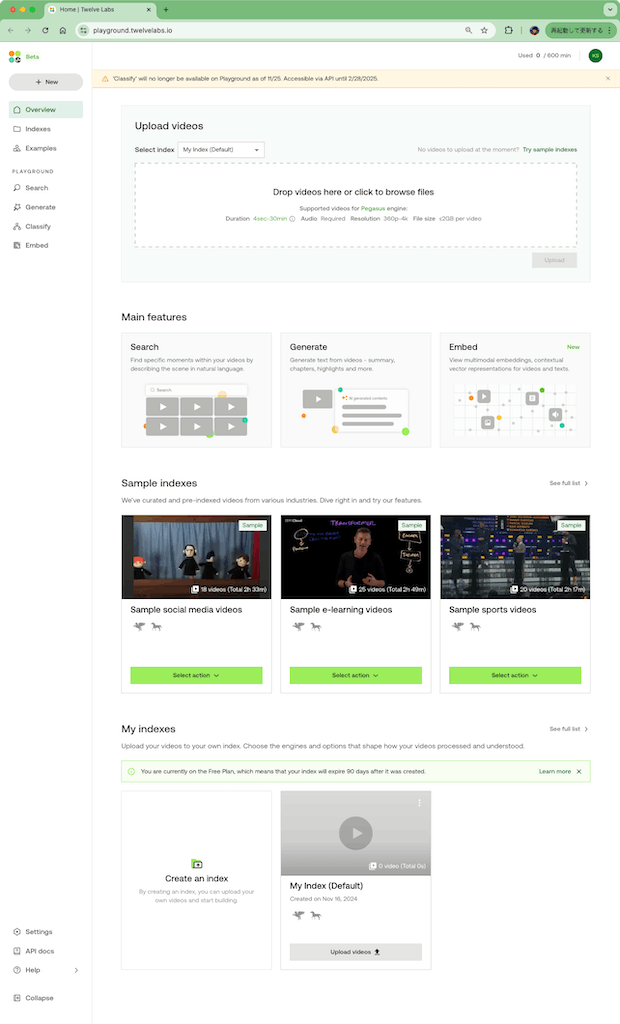
サービスとしては上の方で書いた通り「Search」「Generate」「Embed」がメインになっていて、それぞれのPlaygroundが用意されている。

Classifyは、上部にも表示されているけど、どうやらはディスコンっぽい雰囲気がある。

で、動画を自分のインデックスにアップロードして、という流れっぽいのだけど、サンプルのインデックスが用意されている様子。どういうサンプルがあるのか見てみる。

ソーシャルメディア、Eラーニング、スポーツ、広告、それらのミックスという感じで用意されている。ミックスのものを見てみる。

いろいろな動画が入っているのがわかる。


右上の"Select Action"から、それぞれのPlaygroundが試せる模様
Search
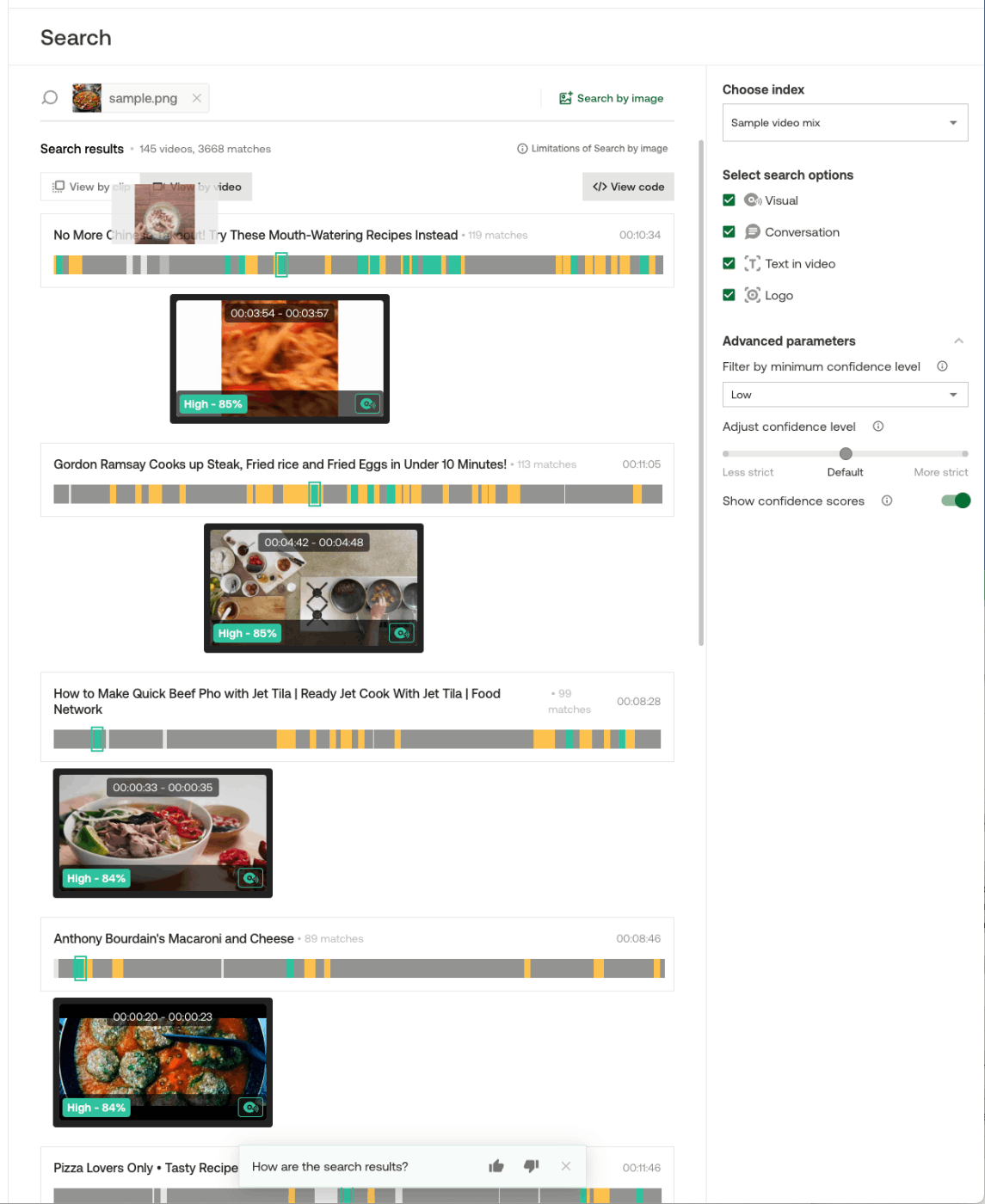
Searchは動画の検索。

検索キーワードの入力欄を選択するとサジェストが表示される。ここを見る限りは、自然言語で入力できる模様。また、右に表示されているように、画像でのクエリもできる様子。

右側で、検索するインデックスの指定や、検索時のオプション・パラメータなどを指定できる様子。

検索時のオプションは以下に説明がある
検索オプションは、動画理解エンジンが検索を実行する際に使用する情報源を指定します。次の値がサポートされています:
visual: アクション、オブジェクト、サウンド、イベントなど、見聞きできる動画コンテンツを分析します。次の例は、有効な検索語です:
- 「城の近くを飛ぶ鳥」
- 「水面を照らす太陽」
- 「道路を走る鶏」
- 「子供の手を握る警官」
- 「スタジアムで歓声を上げる群衆」。
conversation: 動画内の人間の会話を分析します。text_in_video: 動画内のテキストを検出し、抽出します(OCR)。logo: 動画内のブランドロゴを識別します。
なるほど、動画のデータは複数のモダリティでインデックス化されていて、検索時に選択できるような感じみたい。
その他、検索結果のスコアで信頼度みたいなもの指定してフィルタができる様子。。
こんな感じで検索してみた。

なるほど、動画のセグメントを検索結果として返してくれるみたい。あと、日本語でも問題なさそう。
もう一つ。DALL・Eで画像を生成して検索してみる。
A frying pan containing cooked food, showing a variety of colorful vegetables and meat sizzling in the pan. The food appears delicious, with some steam rising and a glossy texture from the sauce. The scene is well-lit, giving the food a fresh and appetizing look.

結果
近しいものが拾えているように見える。
内部的にはEmbeddingモデルでembeddingsを生成して検索しているのだろうと思ったのだけど、どうやらモデルは複数あってAPIによって違いがある様子。Twelve Labsではこのモデルを「動画理解エンジン」という言い方をしているっぽい。
- Marengo
- Embeddingエンジン
- 検索や分類などのタスクを実行することに長けており、より高度なビデオ理解を可能にする。
- さらに2種類のエンジンがある
- Marengo2.6
- "Search" / "Classify"で使用される
- Marengo-retrieval-2.6
- "Embed"で使用される
- Marengo2.6
- Pegasus
- Generativeエンジン
- 動画を元にテキストを生成する。
- 現在のエンジンはPegasus1.1
- "Generate"で使用される
マルチモーダルなデータセットを使って実際にEmbed APIを試したかったのだけど、いい感じのデータセットが見当たらなかったので、Playgroundでできることを見ていく。
Generate
上にある通り、動画の内容を元にテキストでQAしたりする。

同じサンプルのインデックスの中から以下の動画を選択した。

プロンプトはテンプレート的なものを使ったり

スクラッチで書けたりする。

スクラッチで試してみる。
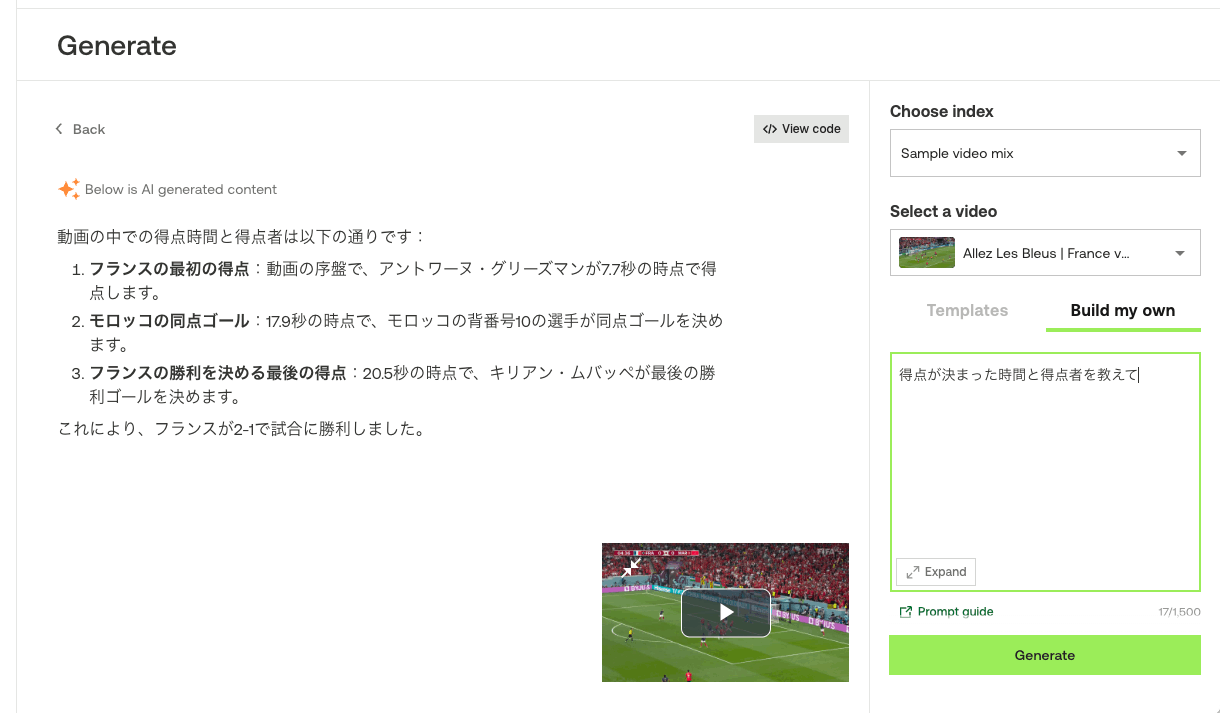

とりあえず日本語は普通に使える。中身については、WC2022のフランス対モロッコというところは理解してるみたいだけど、細かいところはハルシネーションしてる感じかな。
Embed
動画のインデックスに対して、テキストでEmbed検索ができ、可視化される。
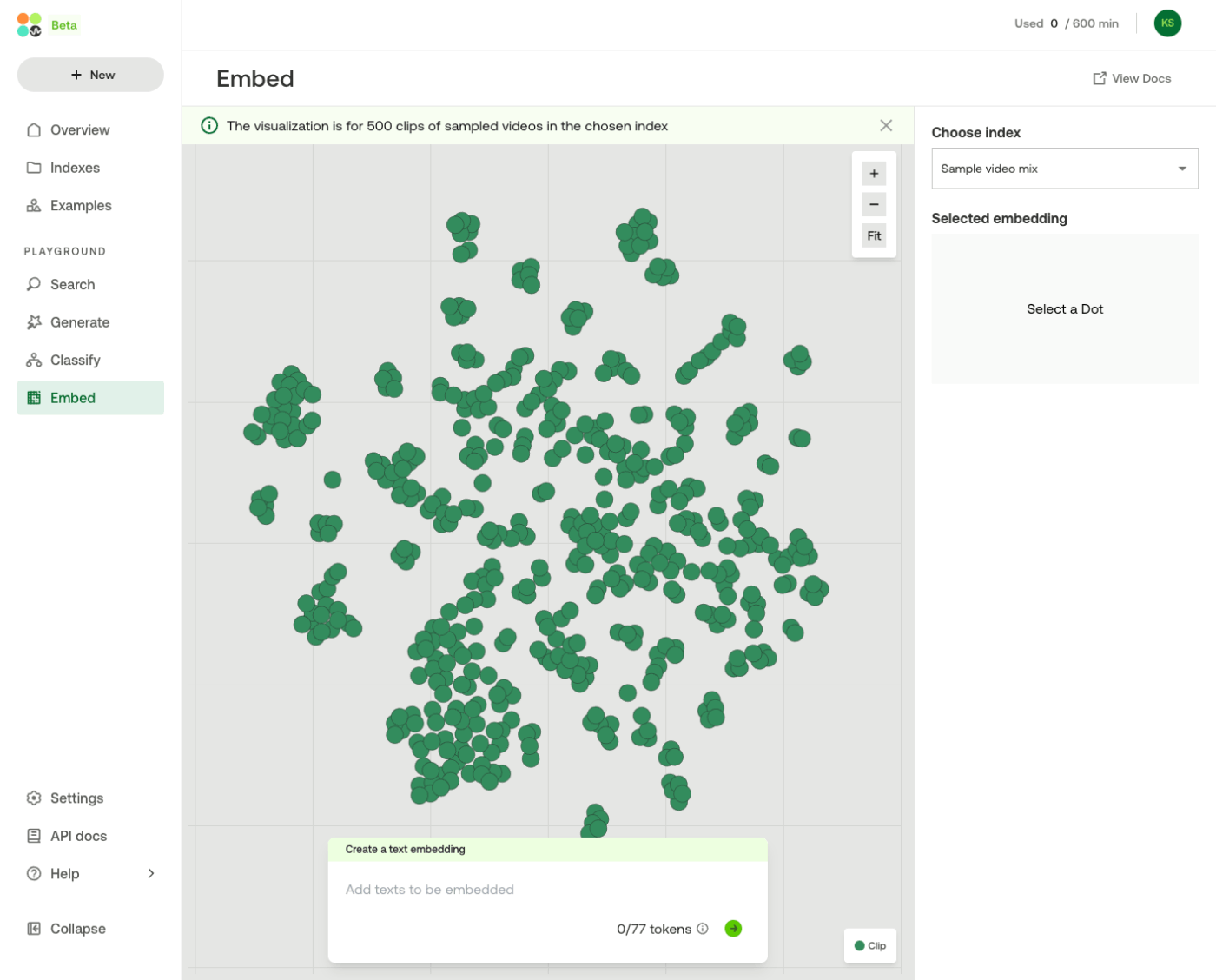
以下のクエリを投げてみる。
ジダンが他の選手に頭突きをした
少し重なって見にくいのだが、テキストのEmbeddingが同じ空間内に配置される。

周辺のプロットに紐づいている動画を見てみると、こんな感じ。
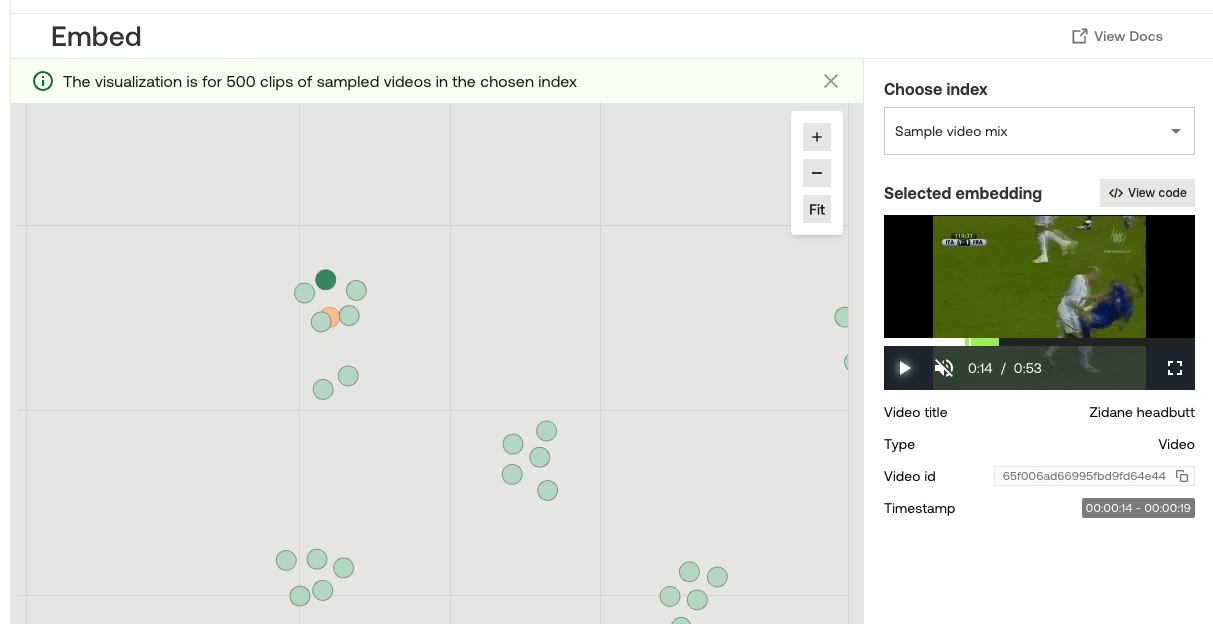

距離が離れるにつれて、コンテキストが変わっていってる感じもわかる。


まとめ
上にも書いたけども、
これらを見る限り、あくまでも動画がメインであって、テキスト・音声・画像は検索時のクエリとして使う、というユースケースに思える。逆に言うと、会議動画・会議音声・議事録のテキスト・議事録の画像みたいなものを全部ベクトル化して1つのベクトルDBに保存しておいて検索、みたいなのは難しそうに思う。
とはいえ、すべてが同じベクトル空間の中にあるっていうのはちょっと興味深い。
というところで、何でもかんでもembeddings化してベクトルDBに入れて検索、というふうにやるには動画以外のモダリティのコンテキストサイズが足りないところはあって、あくまでも動画がメイン、というところはある。
各モダリティごとに情報量の差があるので、マルチモーダルで同じベクトル空間を共有するってのはなかなか難しいのだと思うけど、Twelve LabsのEmbeddingモデルは、制約はありつつもそれを実現できているのではないかと感じる。
音声とテキストのコンテキストサイズが大きくなれば、それこそいろんなデータをベクトル化して検索ってのができるようになるんじゃないかなぁ、ハードルは高そうだけど今後に期待したいところ。