ベクトルデータベース「Milvus」を試す
ちょっと評判が良さそうだったので。Go製のベクトルデータベース。
公式サイト
GitHubレポジトリ
Milvusとは?
Milvusは、類似検索やAIアプリケーションの組み込みを強化するために構築されたオープンソースのベクターデータベースです。Milvusは、非構造化データ検索をより利用しやすくし、導入環境に関わらず一貫したユーザー体験を提供します。
Milvus 2.0 は、ストレージと演算が設計上分離されたクラウドネイティブのベクターデータベースです。このリファクタリングされたバージョンのMilvusのすべてのコンポーネントは、弾力性と柔軟性を高めるためにステートレスです。アーキテクチャの詳細については、Milvus Architecture Overviewを参照してください。
Milvusは、2019年10月にオープンソースのApache License 2.0でリリースされました。現在、LF AI & Data Foundationの卒業プロジェクトとなっています。
主な機能
兆単位のベクトルデータセットに対するミリ秒単位の検索
平均レイテンシは、1兆のベクトルデータセットでミリ秒単位で測定されます。
非構造化データの管理を簡素化
- データサイエンスのワークフロー用に設計された豊富なAPI。
- ラップトップ、ローカルクラスタ、クラウドで一貫したユーザーエクスペリエンスを実現
- 事実上、あらゆるアプリケーションにリアルタイム検索と分析を組み込み可能。
信頼性の高い常時稼働のベクターデータベース
Milvusに組み込まれたレプリケーション機能とフェールオーバー/フェールバック機能により、障害が発生した場合でも、データとアプリケーションの業務継続性を維持できます。
高い拡張性と柔軟性
コンポーネントレベルのスケーラビリティにより、必要に応じてスケールアップやスケールダウンが可能です。Milvusは負荷の種類に応じてコンポーネントレベルで自動スケーリングを行うため、リソースのスケジューリングがより効率的になります。
ハイブリッド検索
Milvus 2.4 以降、弊社はマルチベクトルサポートとハイブリッド検索フレームワークを導入しました。これにより、ユーザーは複数のベクトルフィールド(最大10個)を単一のコレクションに取り込むことができます。これらの異なる列のベクトルは、異なる埋め込みモデルから生成されたり、異なる処理方法が施されたりした、データのさまざまな側面を表します。ハイブリッド検索の結果は、相互ランク融合(RRF)や加重スコアリングなどの再ランク付け戦略を使用して統合されます。
この機能は、写真、音声、指紋などのさまざまな属性に基づいてベクトルライブラリ内で最も類似した人物を特定するなど、包括的な検索シナリオにおいて特に有用です。詳細は、ハイブリッド検索をご覧ください。統一されたラムダ構造
Milvusは、データの保存にストリーム処理とバッチ処理を組み合わせ、即時性と効率性のバランスを取ります。統一されたインターフェースにより、ベクトルの類似性検索が容易になります。
コミュニティによるサポート、業界で認められた
1,000社を超える企業ユーザー、GitHubでの27,000を超えるスター評価、活発なオープンソースコミュニティなど、Milvusを使用しているのはあなただけではありません。LF AI & Data Foundationの卒業プロジェクトとして、Milvusは組織的な支援を受けています。
特徴については以前まとめた以下の記事をどうぞ。OSS&スケーラビリティの高さがウリのように思える。
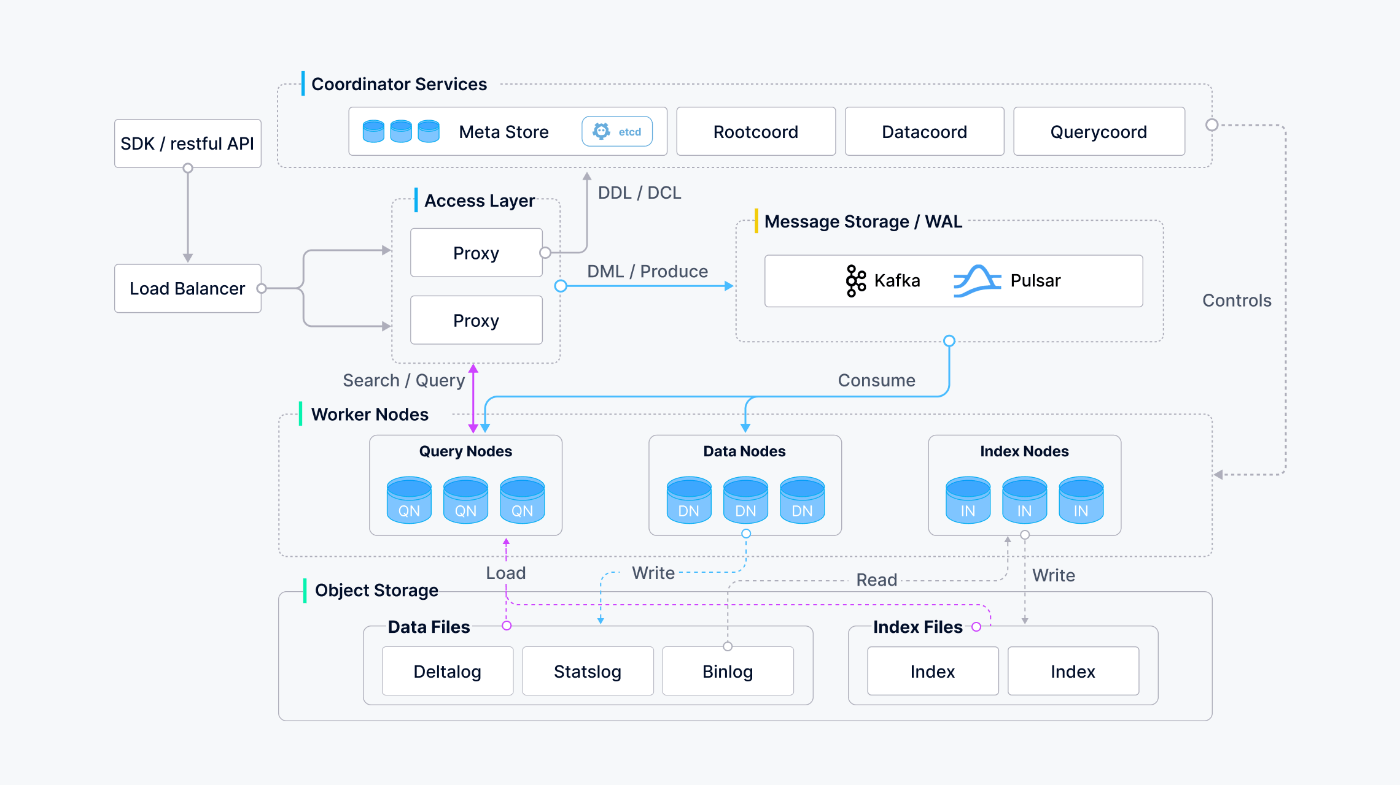
アーキテクチャがゴツい。
Milvus アーキテクチャの概要
Faiss、HNSW、DiskANN、SCANN などの人気のベクトル検索ライブラリを基盤として構築された Milvus は、数百万、数十億、さらには数兆のベクトルを含む高密度のベクトルデータセットにおける類似性検索用に設計されています。 作業を進める前に、埋め込み検索の基本原則について理解しておいてください。
Milvusは、データシャーディング、ストリーミングデータ取り込み、動的スキーマ、ベクトルおよびスカラーデータの検索結合、マルチベクトルおよびハイブリッド検索、疎ベクトル、その他多くの高度な機能もサポートしています。このプラットフォームは、オンデマンドでパフォーマンスを提供し、あらゆる組み込み検索シナリオに合わせて最適化できます。最適な可用性と柔軟性を実現するために、Kubernetesを使用してMilvusを展開することをお勧めします。
Milvusは、ストレージとコンピューティングの分離と、コンピューティングノードの水平スケーラビリティを特徴とする共有ストレージアーキテクチャを採用しています。データプレーンとコントロールプレーンの分離の原則に従い、Milvusはアクセスレイヤー、コーディネーターサービス、ワーカーノード、ストレージの4つのレイヤーで構成されています。これらのレイヤーは、スケーリングや災害復旧に関しては相互に独立しています。
refered from https://milvus.io/docs/architecture_overview.md
K8S推奨か。機能もかなり豊富っぽい。
利用/インストール方法は以下が参考になる
- マネージドサービス「Zilliz Cloud」を使う
- Zilliz(Milvusの商用の親会社)が提供するクラウドサービス
- 「Milvus Lite」を使う
- 「Milvus Standalone」の軽量版
- プロトタイプやエッジ利用用途
- Pythonパッケージでインストール可能
- 「Milvus Standalone」
- 単一サーバ向け
- 小規模または初期の商用プロダクト用途
- DockerまたはDocker Composeを使う
- 「Milvus Distributed」
- 分散環境向け
- 商用・高スケール用途
- Kuberenetesを使う
ラインナップの比較はここ
| 機能 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| SDK/クライアントライブラリ | Python gRPC |
Python Go Java Node.js C# RESTful |
Python Java Go Node.js C# RESTful |
| データタイプ | 密ベクトル 疎ベクトル バイナリベクトル ブール値 整数 浮動小数点 可変長文字列 配列 JSON |
密ベクトル 疎ベクトル バイナリベクトル ブール値 整数 浮動小数点 可変長文字列 配列 JSON |
密ベクトル 疎ベクトル バイナリベクトル ブール値 整数 浮動小数点 可変長文字列 配列 JSON |
| 検索機能 | ベクトル検索(ANN検索) メタデータフィルタリング 範囲検索 スカラークエリ 主キーによるエンティティの取得 ハイブリッド検索 |
ベクトル検索(ANN検索) メタデータフィルタリング 範囲検索 スカラークエリ 主キーによるエンティティの取得 ハイブリッド検索 |
ベクトル検索(ANN検索) メタデータフィルタリング 範囲検索 スカラークエリ 主キーによるエンティティの取得 ハイブリッド検索 |
| CRUD 操作 | ✔️ | ✔️ | ✔️ |
| 高度なデータ管理 | N/A | アクセス制御 パーティショニング パーティションキー |
アクセス制御 パーティショニング パーティションキー 物理リソースのグループ化 |
| 整合性レベル | 強い整合性 | 強い整合性 有界整合性制約 セッション整合性 結果整合性 |
強い整合性 有界整合性制約 セッション整合性 結果整合性 |
基本的なデータの扱いや検索というところでは違いはなさそうで、SDK、運用・管理ってところで違いがある感じ。
とりあえずMilvus Liteで進めてみる。
インストール(Milvus Lite)
Milvus Liteということで、Python+Colaboratotyで。
パッケージインストール。Milvus Liteのパッケージは milvus-liteで、Python SDKのパッケージが pymilvusなのだけど、pymilvusを-Uでインストールすれば最新版が入るということで、pymilvusがオススメらしい。あと、後ほどベクトルデータを用意するのに、OpenAIのパッケージもインストールしておく。
!pip install -U pymilvus
!pip install openai
!pip freeze | egrep -i "milvus|openai"
milvus-lite==2.4.10
openai==1.47.1
pymilvus==2.4.6
クライアントを初期化する。この時、Milvus Liteではデータベースをローカルファイルで指定する。
from pymilvus import MilvusClient
milvus_client = MilvusClient("./milvus_demo.db")
DEBUG:pymilvus.milvus_client.milvus_client:Created new connection using: a0c04fbf5dc9448d9824a2db5cc03c33
プロセスがあがっている。
$ ps auxw | grep -i milvus
root 600 0.1 0.2 194172 31876 ? Sl 18:16 0:00 /usr/local/lib/python3.10/dist-packages/milvus_lite/lib/milvus /content/milvus_demo.db unix:/tmp/tmp2fz3z7tc_milvus_demo.db.sock ERROR /content/.milvus_demo.db.lock
root 716 0.0 0.0 6484 2280 pts/2 S+ 18:16 0:00 grep --color=auto -i milvus
そしてデータベースが作成されている。SQLite3の様子。
$ file milvus_demo.db
milvus_demo.db: SQLite 3.x database, last written using SQLite version 3045000, file counter 1, database pages 2, cookie 0x1, schema 4, UTF-8, version-valid-for 1
次にコレクションを作成する。1536次元で作成する。
milvus_client.create_collection(
collection_name="demo_collection",
dimension=1536,
)
DEBUG:pymilvus.milvus_client.milvus_client:Successfully created collection: demo_collection
DEBUG:pymilvus.milvus_client.milvus_client:Successfully created an index on collection: demo_collection
ドキュメントとベクトルデータを用意する。
import os
from openai import OpenAI
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
oepnai_client = OpenAI()
docs = [
"人工知能は、1956年に学問分野として確立されました。",
"アラン・チューリングは、AIの研究を本格的に行った最初の人物です。",
"ロンドン近郊の町、メイダ・ヴェールで生まれたチューリングは、イングランド南部で育ちました。",
]
response = oepnai_client.embeddings.create(
input=docs,
model = "text-embedding-3-small"
)
vectors = [data.embedding for data in response.data]
data = [ {"id": idx, "vector": vector, "text": docs[idx], "subject": "history"} for idx, vector in enumerate(vectors)]
コレクションにデータを追加する。
res = milvus_client.insert(
collection_name="demo_collection",
data=data
)
では検索してみる。
import json
query = "人工知能は学問として確立したのはいつですか?"
response = oepnai_client.embeddings.create(
input=[query],
model = "text-embedding-3-small"
)
res = milvus_client.search(
collection_name="demo_collection",
data=[response.data[0].embedding],
filter="subject == 'history'",
limit=2,
output_fields=["text", "subject"],
)
print(json.dumps(res, indent=4, ensure_ascii=False))
以下のように検索できている様子。
[
[
{
"id": 0,
"distance": 0.836178719997406,
"entity": {
"text": "人工知能は、1956年に学問分野として確立されました。",
"subject": "history"
}
},
{
"id": 1,
"distance": 0.3081776797771454,
"entity": {
"text": "アラン・チューリングは、AIの研究を本格的に行った最初の人物です。",
"subject": "history"
}
}
]
]
filterでフィルタを掛けることができる。ドキュメントのコードを見ると以下とあるのだが、
This will exclude any text in "history" subject despite close to the query vector.
逆じゃないかなぁ???今回の条件だと"subject"が"history"なものだけを抽出するんだよね・・・?こうしてやると、何もでないし。
res = milvus_client.search(
collection_name="demo_collection",
data=[response.data[0].embedding],
filter="subject != 'history'",
limit=2,
output_fields=["text", "subject"],
)
print(json.dumps(res, indent=4, ensure_ascii=False))
[
[]
]
検索はsearchで、単にエンティティでマッチさせる場合にはqueryを使う。
res = milvus_client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)
print(json.dumps(res, indent=4, ensure_ascii=False))
なるほど、distanceが出力されていない。
[
{
"id": 0,
"text": "人工知能は、1956年に学問分野として確立されました。",
"subject": "history"
},
{
"id": 1,
"text": "アラン・チューリングは、AIの研究を本格的に行った最初の人物です。",
"subject": "history"
},
{
"id": 2,
"text": "ロンドン近郊の町、メイダ・ヴェールで生まれたチューリングは、イングランド南部で育ちました。",
"subject": "history"
}
]
データの削除
res = milvus_client.delete(
collection_name="demo_collection",
filter="id == 2",
)
print(json.dumps(res, indent=4, ensure_ascii=False))
[
2
]
res = milvus_client.query(
collection_name="demo_collection",
output_fields=["text", "subject"],
limit=5,
)
print(json.dumps(res, indent=4, ensure_ascii=False))
[
{
"id": 0,
"text": "人工知能は、1956年に学問分野として確立されました。",
"subject": "history"
},
{
"id": 1,
"text": "アラン・チューリングは、AIの研究を本格的に行った最初の人物です。",
"subject": "history"
}
]
その他、このドキュメントにはMilvus Liteと他のデプロイ方法でのAPIの違いが記載されているが、上の方で書いた通り、運用まわりの違いはあるけども、基本的なデータの扱いや検索という点では違いはなさそう。Mivlus Liteの場合は使用できるインデックスがFLATのみ、というぐらい。
以下にチュートリアルがまとめてあるようなので、気になるものを試していこうと思う。