軽量な会話モデル「vui」を試す
オープンソースノートブック
本日、会話をレンダリングできる 1 億の音声モデルをオープンソース化します。
これには、音声クローンが可能な 40kh のベース微調整が含まれます。
私たちのモデルは、様々な音声以外の音も発音できます!ぜひお試しください!
公式サイトでデモが聞ける。
あとサービスもやってるのかな?
プロメンバーは、無制限の長さの会話をレンダリングできるようになりました。
GitHubレポジトリ
vui
デバイス上で動作可能な小規模な会話型音声モデル
モデル
- Vui.BASE は 40,000 時間の音声会話で訓練されたベースチェックポイントです
- Vui.ABRAHAM はコンテキスト認識で応答できる単一話者モデルです。
- Vui.COHOST は二人の話者が互いに会話できるチェックポイントです。
音声クローン
ベースモデルを使用すればクローンはかなりうまくできますが、多くの音声を学習しておらず/長期間訓練されていないため完璧ではありません
よくある質問
- 2台の4090で開発されました https://x.com/harrycblum/status/1752698806184063153
- 幻覚: はい、モデルは幻覚を起こしますが、限られたリソースで私ができる最善のものです! :(
- VAD は処理を遅くしますが、無音部分を除去するのに必要です。
モデル
GitHubレポジトリにはライセンスの記載がないが、モデルはMITライセンス。
とりあえずGitHubレポジトリにはipynbがあるので、Colaboratoryで・・・と思ったけど、どうやらPython-3.12以降が必要みたい。ということで、手元のUbuntu-22.04サーバ(RTX4090)で。
レポジトリクローン
git clone https://github.com/fluxions-ai/vui && cd vui
uvを使用してるっぽいので、syncでいけた。Python-3.12.10。
uv sync
デモを起動。
uv run demo.py
初回はモデルがダウンロードされるので少し時間がかかる。READMEでは3つのモデルが記載されているけど、COHOSTがダウンロードされて読み込まれていたので、これがデフォルトみたい。
Available models: ['ABRAHAM', 'BASE', 'COHOST']
Loading model COHOST...
vui-cohost-100m.pt: 100%|█████████████████████████████████████████████████████████████| 198M/198M [00:21<00:00, 9.34MB/s]
fluac-22hz-22khz.pt: 100%|████████████████████████████████████████████████████████████| 307M/307M [00:32<00:00, 9.37MB/s]
tokenizer_config.json: 100%|████████████████████████████████████████████████████████| 2.59k/2.59k [00:00<00:00, 12.4MB/s]
config.json: 100%|██████████████████████████████████████████████████████████████████████| 698/698 [00:00<00:00, 3.63MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████████████| 2.50k/2.50k [00:00<00:00, 12.1MB/s]
Compiling model COHOST...
Warming up model COHOST...
以下のように表示されればOK。Gradioだね。
Models ready for inference!
* Running on local URL: http://0.0.0.0:7860
* Running on public URL: https://XXXXXXXXXX.gradio.live
ブラウザでアクセスするとこんな画面。

この時点でのVRAM消費は5GB程度。
Fri Jun 6 10:07:40 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 52C P8 16W / 450W | 4914MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
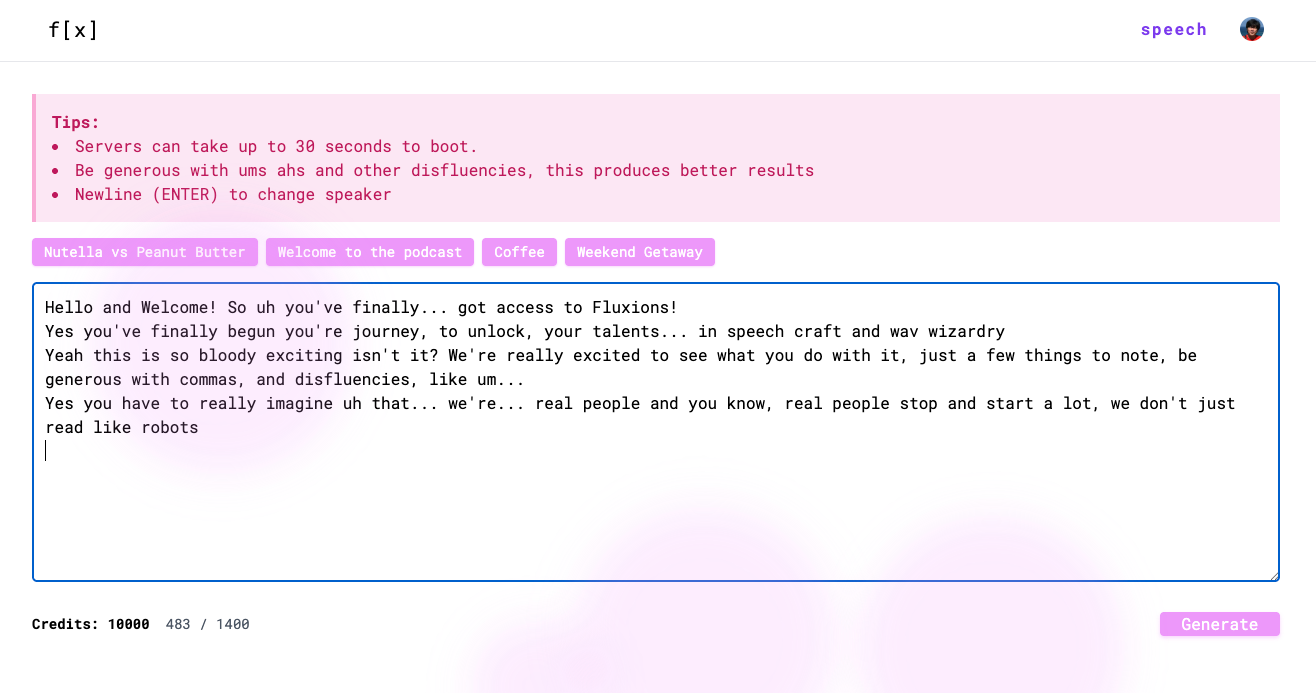
とりあえずデフォルトですでに生成されたものが入っている。こういうテキスト。
Welcome to Fluxions, the podcast where... we uh explore how technology is shaping the world around us. I'm your host, Alex.
[breath] And I'm Jamie um [laugh] today, we're diving into a [hesitate] topic that's transforming customer service uh voice technology for agents.
That's right. We're [hesitate] talking about the AI-driven tools that are making those long, frustrating customer service calls a little more bearable, for both the customer and the agents.
(日本語訳)
A: Fluxionsへようこそ。このポッドキャストでは、テクノロジーが私たちの周りの世界をどう変えているかを探ります。ホストのアレックスです。
B: [息継ぎ] そして私はジェイミーです。えっと [笑い] 今日は、[躊躇い] カスタマーサービスを変革しているトピック、つまりエージェント向けの音声技術について、深く掘り下げていきます。
C: その通りです。私たちは・・・ [躊躇い] 顧客とエージェントの両方にとって、長くてストレスの多いカスタマーサービス通話 を少しだけ耐えられるようにするAI駆動型ツールについて話していきます。
発話者は1行ごとに交互になるような感じ。あと [breath] / [laugh] / [hesitate] などの非言語タグも使えるみたい。
すでに生成された音声はこんな感じ。
再度生成してみる。

生成にはだいたい.3.7秒程度かかっていた。

生成されたもの。
VRAM消費は少し増えていた。
Fri Jun 6 10:19:15 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 53C P8 17W / 450W | 5680MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
COHOSTは2人の話者による対話を生成するが、BASEとABRAHAMは単一話者になる。BASEがベースモデルで、ABRAHAMがコンテキストに合わせて発話するようにファインチューニングしたモデル、ということなのだろうと思う。
上と同じ文章を生成させてみた。
対話ベースの台本が一人の話者で発話されているのがわかる。
当然ながら 日本語には非対応
音声クローンとあるが、ゼロショットではなく、音声データでモデルを学習させる感じかな。ただし、トレーニング用のコードは公開されていなさそう。
一応、サービスの方にもアカウント作ってみたが、Gradioでできることがそのまま、って感じに見える。料金等も全く記載されていないけど、最初から10000クレジットあるのは無料ってことでいいのかな?とりあえずまだまだこれから、って感じに見える。
40000時間のデータとRTX4090x2でトレーニングされてるらしいけど、どれぐらいの学習時間かかっているんだろう。