Neo4jを試す
GraphRAGをきちんと理解したい。
ナレッジグラフのインテグレーションもLlamaIndexで一応触っている。
が、そもそもナレッジグラフ単体できちんと触っていないし、雰囲気でやっている感がある。
そこで、改めて手を動かしながら理解するために、Neo4jのGetting Startedをやってみることにする。
Neo4jのGetting Starated
グラフデータベースとは?
Neo4jグラフデータベースは、テーブルやドキュメントの代わりにノードとリレーションシップを格納します。データはホワイトボードにアイデアをスケッチするように格納されます。データはあらかじめ定義されたモデルに制限されることなく格納されるため、非常に柔軟な思考と利用が可能になります。
グラフの基本についてさらに詳しく知りたい場合は、「グラフデータベースの概念」を参照してください。
ふむ、より基礎的な「グラフデータベースの概念」をまず見てみる。
グラフデータベースの概念
はじめに
- Neo4jはプロパティグラフデータベースモデルを使用している。
- グラフデータ構造は、リレーションシップによって接続できるノード(個別のオブジェクト)で構成される
- Neo4jプロパティグラフデータベースモデルは、以下の要素で構成される
- ノードは、ドメインのエンティティ(個別のオブジェクト)を記述する。
- ノードには、どのような種類のノードであるかを定義(分類)するためのラベルをゼロ個以上持つことができる。
- リレーションシップは、ソースノードとターゲットノード間の接続を記述する。
- リレーションシップには常に方向性(一方向)がある。
- リレーションシップには、そのリレーションシップの種類を定義(分類)するための型(1種類)が必要。
- ノードとリレーションシップには、それらをさらに詳しく説明するプロパティ(キーと値のペア)を設定できる。
- ノードとリレーションシップの別名は以下
- ノード: 頂点、点、ポイント
- リレーションシップ: 関係、関係性、エッジ、辺、リンク、線
グラフの例
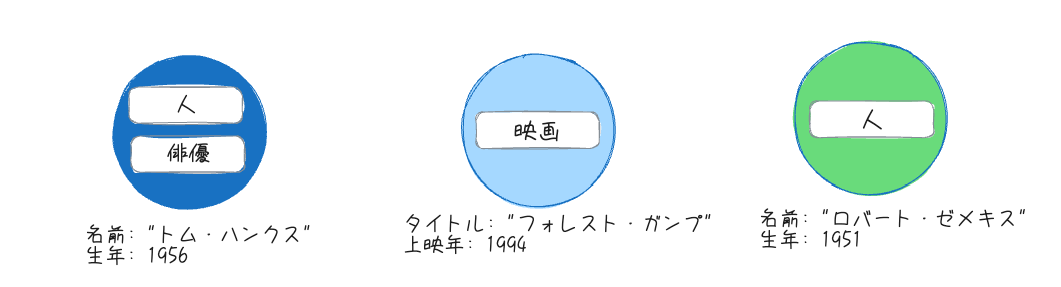
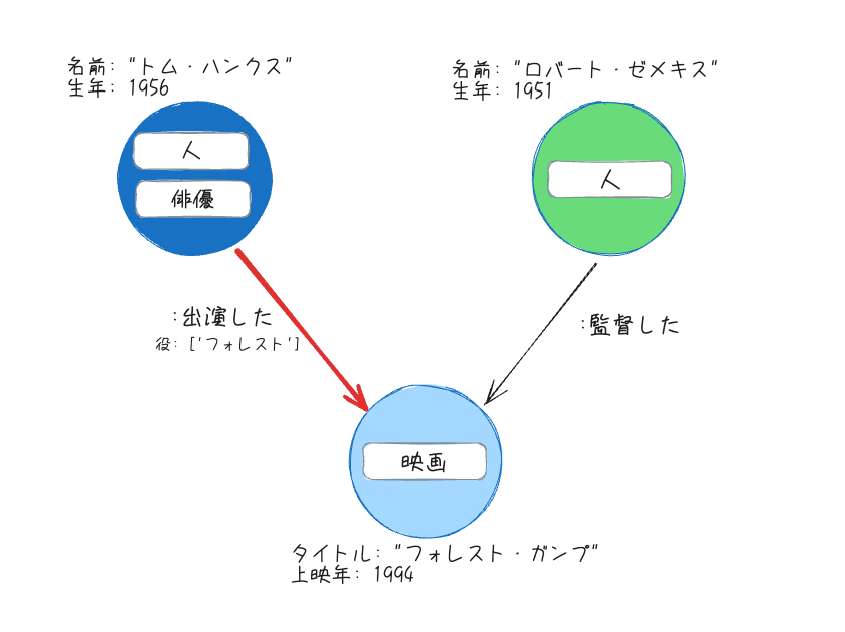
以下のようなグラフを例にする。
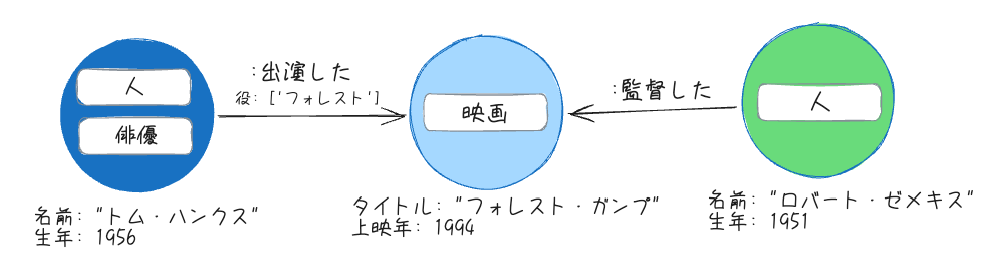
Cypherというクエリ言語を使って上記を作成するとこうなる。日本語もいけるっぽい?
CREATE (:人:俳優 {名前: 'トム・ハンクス', 生年: 1956})-[:出演した {役: ['フォレスト']}]->(:映画 {タイトル: 'フォレスト・ガンプ', 上映年: 1994})<-[:監督した]-(:人 {名前: 'ロバート・ゼメキス', 生年: 1951})

ノード
「ノード」は、ドメインのエンティティ(個別のオブジェクト)を表すために使用される。最も単純なグラフは、関係のない単一のノードとなる。
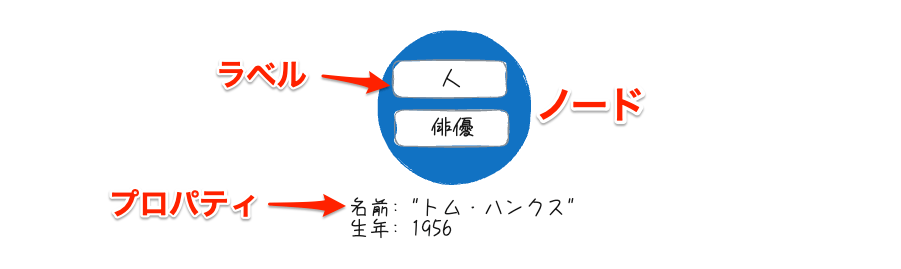
ノードは「ラベル」と「プロパティ」を持つことができる。ラベルとプロパティについては後述。上記の例の場合は以下となる。
- ラベル
人俳優
- プロパティ
-
名前:トム・ハンクス -
生年:1956
-
ノードを作成するCypherは以下。
CREATE (:人:俳優 {名前: 'トム・ハンクス', 生年: 1956})
ノードのラベル
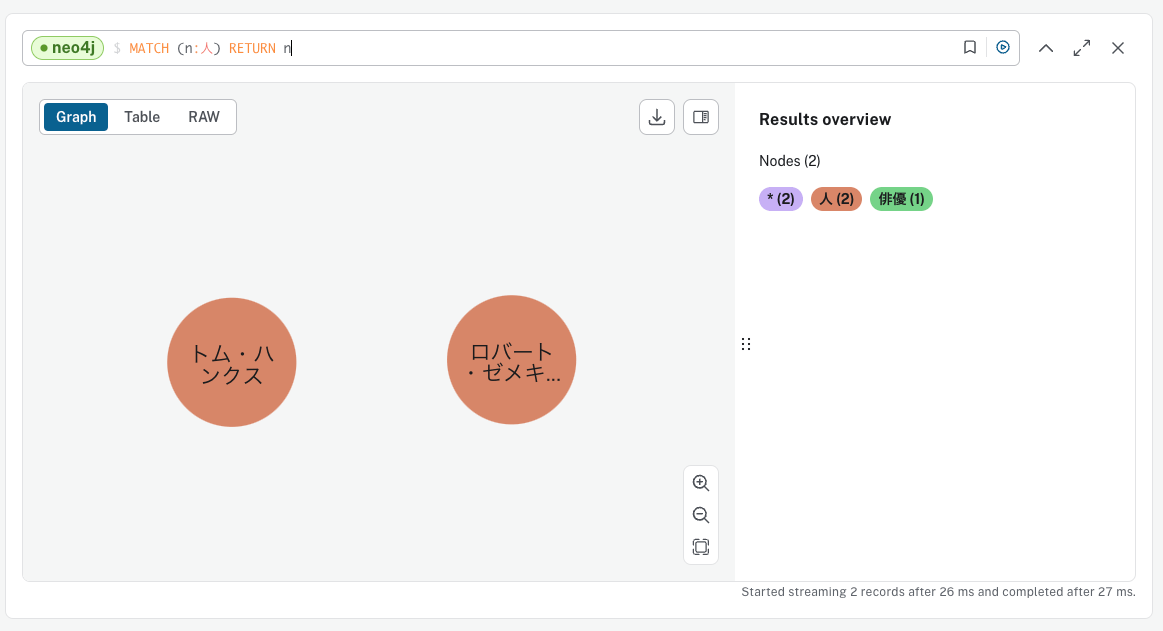
ノードの「ラベル」は、そのノードがどのような種類のノードであるかを定義し、分類・グループ化するためのもの。ラベルにより分類・グループ化することでドメインが形成され、指定したラベルを持つノードを絞り込んで操作をおこなったりできる。
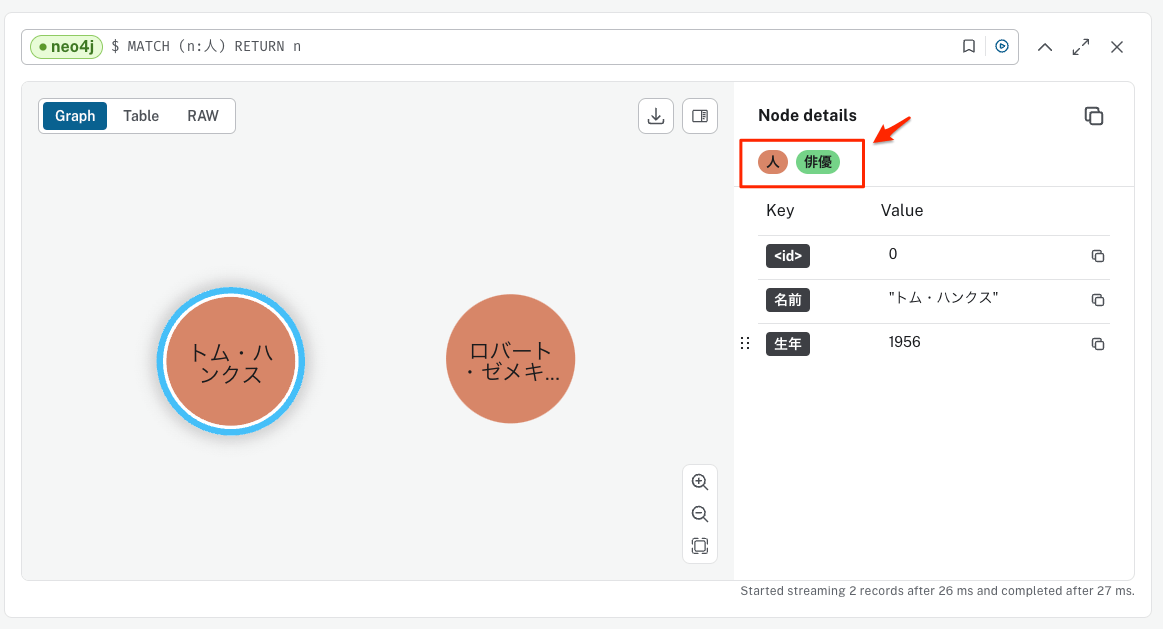
MATCH (n:人) RETURN n
ラベルは実行時に追加や削除ができるため、一時的な状態をマークするという使い方にも使用できる。
- 一時停止中の銀行口座に「一時停止中」ラベルを付与
- 現在旬の野菜に「季節限定」ラベルを付与。
ラベルはゼロ個以上付与できる。
リレーションシップ
「リレーションシップ」は、ノードの間の接続がどのように関連しているかを示す。

リレーションシップは、1方向の方向性、つまりリレーションシップの起点となるソースノードと、終点となるターゲットノード(デスティネーションノードとも言う)を接続する。
リレーションシップには、そのリレーションシップの関係性を定義・分類する「タイプ」が必ず1️つ必要になり、さらに「プロパティ」を持つことができる。上記の例の場合は以下となる。
- リレーションシップタイプ
出演した
- プロパティ
-
役:['フォレスト'] -
評価:5
-
リレーションシップを作成するCypherは以下。
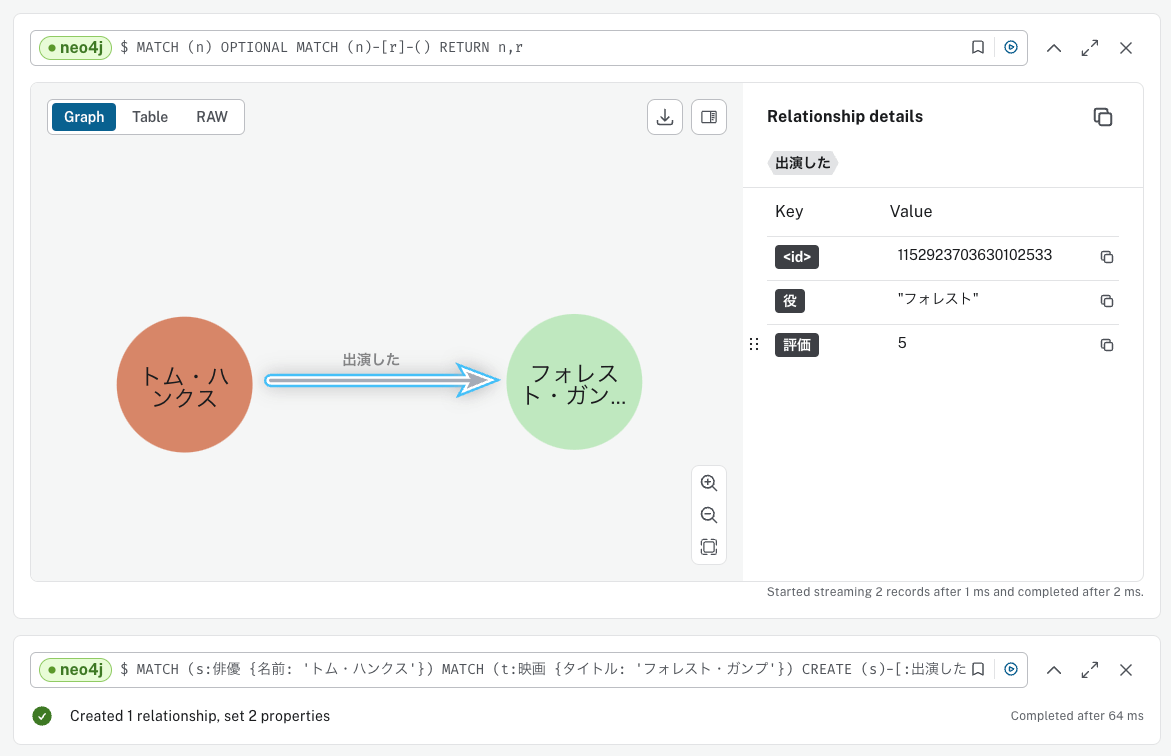
CREATE ()-[:出演した {役: ['フォレスト'], 評価: 5}]->()
ただし実際にはソースノードとターゲットノードの指定が必要になる。ノードだけが存在する状態があったとして、

以下を実行する
MATCH (s:俳優 {名前: 'トム・ハンクス'})
MATCH (t:映画 {タイトル: 'フォレスト・ガンプ'})
CREATE (s)-[:出演した {役: 'フォレスト', 評価: 5}]->(t);
リレーションシップは常に方向性を持つが、必要なければその方向性を無視でき、データモデル上必要なければ逆方向に重複したリレーションをもたせる必要はない。ここはちょっと意味がわからないのだけども、多分こういうことかな?
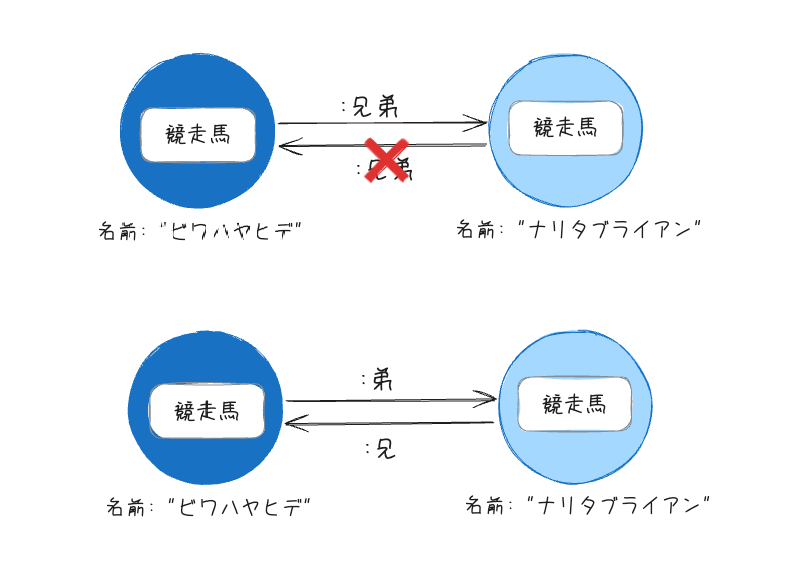
上の例では、ざっくり「兄弟」ということだけなのでどちらのノードから見ても同じであり方向性を無視できる≒1つのリレーションで良いが、下の例では、明確に「兄」「弟」という区別が重要なのであれば、それぞれのリレーションを必要とする、ということなんだろうと思う。
あと、ノードのリレーションシップは自分自身に向かうことも可能。

リレーションシップタイプ
リレーションシップは必ず1つのリレーションシップタイプが必要になる。以下の例だと、ソースノードトム・ハンクスからターゲットノードフォレスト・ガンプに、出演したというタイプを持つリレーションシップ、ということになる。
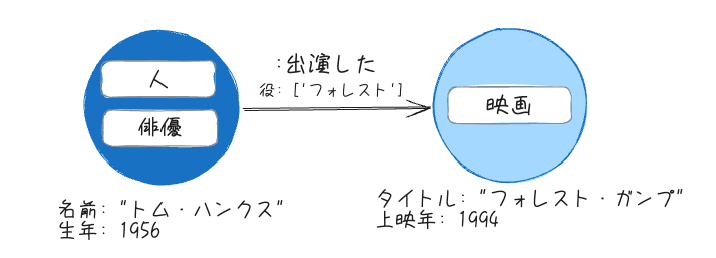
ソースノードから見れば外向きのリレーション、ターゲットノードから見れば内向きのリレーション、ということも言える。
プロパティ
プロパティは、キーと値のペアで、ノードやリレーションに対してデータを付与するのに使用される。
-
number、string、booleanが値として使える - リストも可能、ただし同一の型に限る
トラバーサルとパス
トラバーサルは、質問に対する答えを見つけるためにグラフに問い合わせる方法のこと。グラフにおけるトラバーサルは、ルールに従って、リレーションをたどりながらノードを探索することになり、ほとんどの場合はグラフのサブセットのみが探索されることになる。
例: 「トム・ハンクスが出演した映画は?」
-
トム・ハンクスノードから探索スタート。 -
トム・ハンクスノードに接続されているリレーションから、出演したリレーションをたどる。 -
映画ラベルが付与されているフォレスト・ガンプノードにたどりつく。
この時のトラバーサル結果の長さは1になるが、単一ノードしかない≒リレーションシップが存在しない場合はパスの長さは0となり、これが最短となる。

1つのリレーションシップが含まれていれば、パスの長さは1となるが、リレーションが自分自身を指す場合もこれに該当する。
スキーマ
Neo4jにおけるスキーマは、インデックスと制約のことを指す。ただしこれはオプション。
- インデックスと制約を作成する必要はなく、スキーマを前もって定義しなくても、ノード、リレーションシップ、プロパティなどのデータを作成できる。
- パフォーマンスやモデリング上の利点を得るために必要な場合は、インデックスや制約を使えば良い。
インデックス
インデックスは、パフォーマンスの向上が必要な場合に使用する。
参考
制約
制約は、データをドメインの規則に従っていることを確認するために使用する。
参考
命名規則
推奨されているのは以下。
| 項目 | 推奨 | 例 |
|---|---|---|
| ノードラベル | upper camel case | :VehicleOwner |
| リレーションシップタイプ | screaming snake case | :OWNS_VEHICLE |
| プロパティ | lower camel case | firstName |
正確なルールについては以下
最初のほうにも記載したけども、今回ほぼほぼ全て日本語で指定してて、一応動作もしているみたいではあるが、これが正しいのかはわからない。
余談: ナレッジグラフのモデリング手法
冒頭で、
Neo4jはプロパティグラフデータベースモデルを使用している。
と記載したが、自分の理解では、
- 情報のモデリング手法は多数ある
- ナレッジグラフの場合は、主に「RDF」と「プロパティグラフ」が多いらしい。
- Neo4jは「プロパティグラフ」を採用している
と理解している、
Neo4jとは関係ないけども、一応、他のモデリング手法についても、ChatGPTやClaudeに聞いた内容をまとめておく。
- タキソノミー
- ERモデル
- オントロジー
- RDF
- プロパティグラフ
- オブジェクトプロパティグラフ
- トピックマップ
- フォークソノミー
1. タキソノミー
最もシンプルで基本的な階層構造を持ち、多くの他の手法の基礎となる概念
- 概念や実体を階層的に分類・整理する
- 上位概念と下位概念の関係を明確に示す
- シンプルで理解しやすい構造
- 情報の体系的な整理に適している
- 例: 生物学の分類体系、図書館の書籍分類
2. ERモデル
データベース設計の基本として広く使用されており、タキソノミーよりも複雑だが、まだ比較的シンプル
- エンティティ(実体)、属性、関係を図式化する
- データベース設計でよく使用される
- エンティティ間の関係性を明確に表現できる
- 属性の詳細を記述できる
- システム分析や設計に適している
3. オントロジー
タキソノミーの概念を拡張し、より複雑な関係を表現、セマンティックWebの基礎となる概念
- 概念間の複雑な関係を定義する
- 階層構造と横断的な関係を同時に表現できる
- 推論が可能
- セマンティックWebや知識ベースシステムに適している
- ドメイン固有の知識を形式化できる
4. RDF
オントロジーの実装方法の一つで、Webリソースの記述に特化
- 主語-述語-目的語の三つ組(トリプル)でデータを表現する
- URIを使用してリソースを一意に識別する
- Webリソースの記述に適している
- 異なるデータセット間のリンクを容易にする
- Linked Open Data (LOD) プロジェクトで広く採用されている
5. プロパティグラフ
RDFよりも柔軟な関係表現が可能で、現代のグラフデータベースで広く使用されている
- ノードとエッジにプロパティ(属性)を持たせることができる
- 関係にも属性を付与できる
- グラフデータベース(例:Neo4j)でよく使用される
- 複雑なネットワーク構造を表現するのに適している
- クエリの柔軟性が高い
6. オブジェクトプロパティグラフ
プロパティグラフの拡張版で、オブジェクト指向の概念を取り入れたより複雑なモデル
- オブジェクト指向の概念をグラフ構造に組み込んでいる
- クラス、属性、関係を明確に定義できる
- 継承や多重度など、より複雑な概念も表現可能
- プロパティグラフモデルの拡張版
- 複雑なドメインモデルの表現に適している
7. トピックマップ
オントロジーやRDFと類似しているが、より主題指向、情報の文脈や関連性に重点を置く
- 主題(トピック)を中心とした知識表現
- トピック間の関係性を多様な方法で表現できる
- 情報リソースをトピックに関連付けることができる
- 複雑な知識構造を直感的に表現できる
- 情報の文脈や関連性を重視する
8. フォークソノミー
最も新しく、ユーザー主導の分類方法。他の手法とは異なり、ボトムアップアプローチを採用
- ユーザーが自由にタグ付けを行う協調的な分類方法
- ボトムアップ型のアプローチ
- 柔軟性が高く、新しい概念や関係性を容易に追加できる
- ユーザー参加型のコンテンツ分類に適している
- 例: ソーシャルブックマーキング、SNSのハッシュタグ
グラフデータベースとは?(再び)
ということでGet Startedに戻る。
プロパティグラフモデル
ここは「グラフデータベースの概念」でやったことのおさらいっぽいけど、
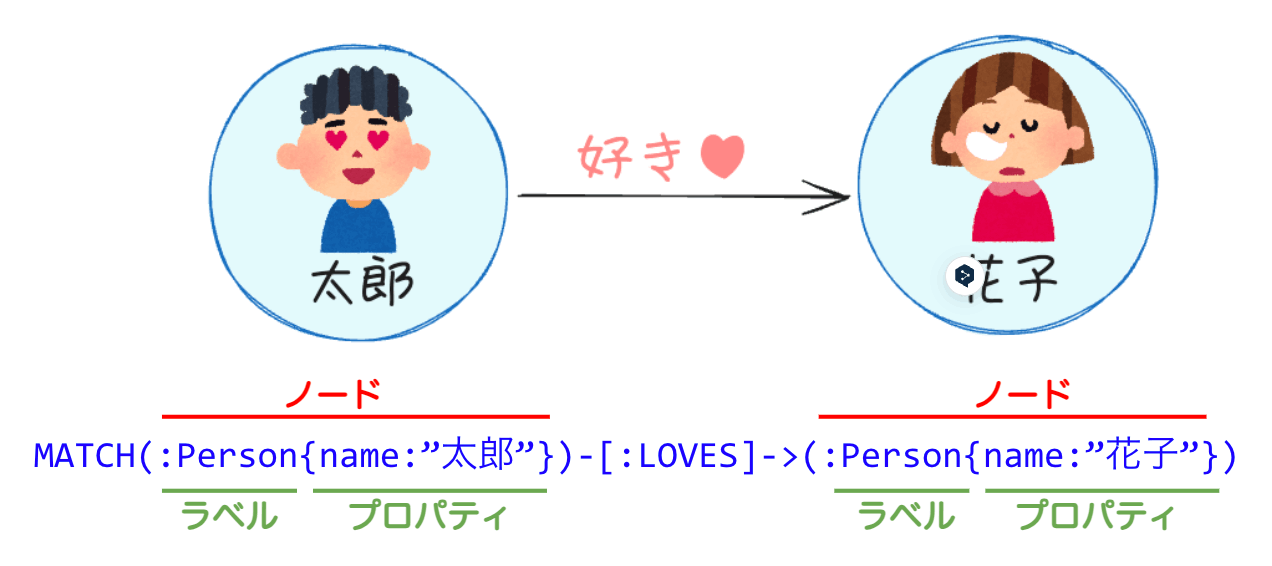
https://neo4j.com/docs/getting-started/get-started-with-neo4j/graph-database/ の図を日本語翻訳して少し書き換えたもの*
この図にある文例を見ると
- ノードは
()で括る - リレーションは
[]で括って、()-[]->()で表現する - ノードラベルとリレーションシップタイプは
:で始める - ノードとリレーションシップのプロパティは、
{key:"value"}で指定する
という感じっぽい。
Neo4jとは?
- Java/Scala製のネイティブグラフデータベース
- ACIDトランザクション、クラスタ、ランタイムフェイルオーバーに対応
- インデックスフリー隣接(IFA)
- データベース トランザクションがコミットされると、リレーションシップへの参照が、リレーションシップの開始と終了の両方のノードに格納される。
- 各ノードは、そのノードに接続されているすべての入出力リレーションシップを認識している
- 基盤となるグラフ エンジンは、単にメモリ内でポインタを追いかけるだけ。
- メリット
- インデックス参照が少ない
- テーブルスキャンがない
- データ重複が削減
- 提供形態
- マネージドクラウドサービス: AuraDB
- コミュニティ版
- セルフホストが可能
- GitHubレポジトリ: https://github.com/neo4j/neo4j
- エンタープライズ版
- セルフホストが可能
- コミュニティ版のすべての機能+以下のような企業向け機能が追加
- バックアップ
- クラスタリング
- フェイルオーバーなど
- グラフ用クエリ言語Cypherに対応
- 効率的なグラフ表現で一定のトラバーサル時間に抑えつつ、中程度のハードウェアで数十億ノードへスケールアップ可能
- Java/JavaScript/.NET/Pythonなどでアクセス可能
なぜグラフデータベースなのか?
- グラフデータベースは現代の複雑な接続世界に適したデータ管理システム
- データ要素(ノード)と関係性を柔軟に格納し、高速処理を実現
- 従来のリレーショナルDBと異なり、JOINや参照操作が不要
- 1コアあたり毎秒数百万の接続を処理可能
- 多対多関係を持つ異種データの課題に対応:
- 深い階層の探索
- 遠隔アイテム間の隠れた接続発見
- アイテム間の相互関係把握
- 社会、決済、道路ネットワークなど、現実世界の相互接続したグラフ構造に関する質問に適している
Neo4jのユースケース
- リアルタイムトランザクションアプリケーション(収益の創出と保護)
- レコメンデーション
- 不正検出
- 動的価格設定
- IoTアプリケーション
- メタデータと高度な分析(実用的な洞察の生成)
- 顧客エンゲージメント
- データレイク統合
- リスク軽減
- AI用ナレッジグラフ
- 内部ビジネスプロセス(効率性の向上とコスト削減)
- ネットワーク管理
- サプライチェーン効率
- IDとアクセス管理
んー、少しドキュメント見てみたけど、この流れで行くと読み物が続きそうな感じ・・・コレジャナイ感がある。
手を動かしながら学びたいのだけど、そういうのはどこにあるのだろうか?
これかな?
Beginnerだと以下
- Neo4j Fundamentals
- Cypher Fundamentals
- Graph Data Modeling Fundamentals
- Importing Data Fundamentals
書いてある時間だとここまでで6時間
LLM向けとかIntermediateならば以下
- Neo4j & LLM Fundamentals
- Introduction to Vector Indexes and Unstructured Data
- Build a Neo4j-backed Chatbot using Python/TypeScript
- Building Neo4j Applications with Python/TypeScript
こっちは8〜12時間か
以下は面白そうなんだけど、Coming Soonらしい
- Constructing a Knowledge Graph with LLMs
あとはsandboxも学習には良い
とりあえず以下をやった。
- Neo4j Fundamentals
- Cypher Fundamentals
- Graph Data Modeling Fundamentals
グラフデータベースとかプロパティグラフの基本的な雰囲気を掴むだけならば、最初の2つだけで良いかなとも思う。
Graph Data Modeling Fundamentalsは、最初の2つと多少重複するところがあった気はするが、グラフ設計という点で流行っておいたほうがいいのかなという感じ。
残りはどうしようかなぁというところ。
- Importing Data Fundamentals
- Neo4j & LLM Fundamentals
- Introduction to Vector Indexes and Unstructured Data
- Build a Neo4j-backed Chatbot using Python/TypeScript
- Building Neo4j Applications with Python/TypeScript
Importing Data Fundamentalsはいろいろなデータインポートのやり方みたいな感じだったので途中でやめた、必要になったら調べるだろうという気もしてるし。
LLM周りどうしようかなぁ、結構ボリューム的に重ためなのだよな。ただ、ベクトルインデックスのところは気になるので、とりあえずIntroduction to Vector Indexes and Unstructured Dataをやってみる。
以下も終わらせた。
- Neo4j & LLM Fundamentals
- Introduction to Vector Indexes and Unstructured Data
"Neo4j & LLM Fundamentals"は、LangChainメインで使う人ならやっておいても良さそう。自分はLlamaIndex推しなので粛々と写経しただけ。
Introduction to Vector Indexes and Unstructured Dataは、Neo4jでやっておいて損はない感じ。
なお、終了したコースは以下のようにAchivementとして公開できる。

Neo4j Certified ProfessionalをパスするとTシャツがもらえるらしい
GraphAcademyの内容は実はGitHubで公開されている。ただライセンスが指定されていないので何処まで内容を書いていいものかがわからない。(なのでこのスクラップでもGraphAcademyでやった内容については書いてない)