「F5-TTS」を試す
論文(alphaXivの概要にリンク)
近年、テキスト音声変換 (TTS) 技術は目覚ましい進歩を遂げ、さまざまな言語やさまざまな話者に対して、ほぼ人間レベルの音声を生成できるモデルが登場しています。このような進歩にもかかわらず、高品質で高速かつ堅牢な TTS システムの構築は依然として困難です。「F5-TTS: Flow Matching で流暢かつ忠実な音声を生成する Fairytaler」という論文では、この分野における既存のいくつかの制限に対処する新しいアプローチを紹介しています。
F5-TTS は、速度や堅牢性を犠牲にすることなく高品質の音声を生成する、非自己回帰 (NAR) TTS システムとしての地位を確立しています。名前の「F5」は、5 つの主要な属性を指します。モデルは、Flow matching を使用して、Fluent (流暢) かつ Faithful (忠実) な音声を Fakes (生成) する Fairytaler (語り手) です。
GitHubレポジトリ
F5-TTS: 流暢かつ忠実な音声を創り出すフェアリーテイラー ― フロー・マッチングによる生成
- F5-TTS:ConvNeXt V2ベースのDiffusion Transformer。高速な学習と推論性能。
- E2 TTS:Flat-UNet Transformer。論文の再現に最も近いモデル。
- Sway Sampling:推論時のフローステップサンプリング戦略。大幅に性能向上。
貢献者の皆様に感謝します!
最新情報
- 2025/03/12:🔥 学習・推論性能が向上したF5-TTS v1ベースモデルを公開。一部デモはこちら。
- 2024/10/08:F5-TTSおよびE2 TTSのベースモデルを🤗 Hugging Face、🤖 Model Scope、🟣 Wisemodelにて公開。
ベンチマーク結果
L20 GPUを用いた単一デコード(26ペアのprompt_audio & target_text、NFE=16):
モデル 同時実行数 平均レイテンシ RTF モード F5-TTS Base (Vocos) 2 253 ms 0.0394 クライアント-サーバ F5-TTS Base (Vocos) 1(バッチサイズ) - 0.0402 オフライン TRT-LLM F5-TTS Base (Vocos) 1(バッチサイズ) - 0.1467 オフライン PyTorch 詳細はこちら。
推論
- 望ましい性能を得るために、詳細ガイドを参照してください。
ライセンス
本コードはMITライセンスで公開されています。事前学習モデルはEmilia(自然環境下データセット)により学習されたため、CC-BY-NCライセンスのもと提供されています。ご了承ください。
公式のモデルのライセンスがCC-BY-NCである点には注意
なお、公式にサポートしている言語は、英語と中国語。日本語はサポートしていないのだが
コミュニティでトレーニングされて公開されているモデルでは複数言語対応しているようで、ここには日本語(ただしcc-by-nc-4.0)もあった。
日本語の解説記事
インストール
インストール方法は以下の3つがある様子
- pipパッケージをインストール
- レポジトリからインストール
- Docker
今回はpipパッケージを使って、Colaboratory T4で試してみる。PyTorch(torch・torchaudio)のインストールが前提で、Colaboratoryでは事前にインストールされているので、一旦これで進める。
!pip freeze | egrep -i "^torch"
torch @ https://download.pytorch.org/whl/cu124/torch-2.6.0%2Bcu124-cp311-cp311-linux_x86_64.whl
torchao==0.10.0
torchaudio @ https://download.pytorch.org/whl/cu124/torchaudio-2.6.0%2Bcu124-cp311-cp311-linux_x86_64.whl
torchdata==0.11.0
torchsummary==1.5.1
torchtune==0.6.1
torchvision @ https://download.pytorch.org/whl/cu124/torchvision-0.21.0%2Bcu124-cp311-cp311-linux_x86_64.whl
pipパッケージでインストールする
!pip install f5-tts
!pip freeze | grep "f5-tts"
f5-tts==1.1.4
推論
推論については以下のガイドが詳しい
事前学習済みモデルのチェックポイントは、🤗 Hugging Face および 🤖 Model Scope からアクセスできます。また、推論スクリプトの実行時に自動的にダウンロードされます。
コミュニティの協力により作成されたその他のチェックポイントは、SHARED.md で確認でき、より多くの言語に対応しています。
現在、1回の生成で30秒まで対応しています。これは、プロンプトと出力オーディオの両方を含む合計の長さです(
fix_durationを指定した場合も同様です)。ただし、infer_cliとinfer_gradioは、長いテキストの場合、自動的にチャンク生成を行います。長い参照音声は、約 12 秒にクリップされます。推論の失敗を避けるため、以下の指示を必ずご確認ください。
- 参照音声は 12 秒未満にし、最後に適切な無音スペース(例:1 秒)を残してください。そうしないと、単語の途中で切り取られ、生成結果が最適にならない可能性があります。
- 大文字(最適な書き方の例:
K.F.C.)は文字単位で発音され、小文字は一般的な単語に使用されます。- 明示的な休止を挿入するには、スペース(空白: "
")または句読点(例: ","、 "." )を追加してください。- 英語の句読点が文の終わりを示す場合、その後にスペース "
" を必ず入れてください。そうしないとチャンクとして認識されません。- 中国語で読み上げたい数字は中国語の文字に変換してください。そうでない場合は英語のままです。
- 生成出力が空白(純粋な沈黙)の場合、FFmpeg のインストールを確認してください。
- 早期段階の微調整済みチェックポイント(数回の更新のみ)を使用している場合は、
use_emaをオフにしてみてください。
主に以下の方法がある
- CLI
- Gradioアプリ
- Python API
あと、以下もある
- TensorRT-LLM(推論を高速で実行するための SDKであるTensorRTを使ってLLMを推論するライブラリ。参考)を使ったデプロイ
- ソケット接続を行うサーバ・クライアントのスクリプトも含まれている
ColaboratoryではCLIとPythonで試してみる。
CLI
パッケージをインストールすると f5-tts_infer-cli が使えるようになる。このコマンドは python src/f5_tts/infer/infer_cli.py を実行しているのと同じらしい。
まずUsage。
!f5-tts_infer-cli --help
2025-05-20 10:13:29.677008: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1747736010.015913 5885 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1747736010.119166 5885 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-05-20 10:13:30.837770: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
usage: python3 infer-cli.py [-h] [-c CONFIG] [-m MODEL] [-mc MODEL_CFG]
[-p CKPT_FILE] [-v VOCAB_FILE] [-r REF_AUDIO]
[-s REF_TEXT] [-t GEN_TEXT] [-f GEN_FILE]
[-o OUTPUT_DIR] [-w OUTPUT_FILE] [--save_chunk]
[--remove_silence] [--load_vocoder_from_local]
[--vocoder_name {vocos,bigvgan}]
[--target_rms TARGET_RMS]
[--cross_fade_duration CROSS_FADE_DURATION]
[--nfe_step NFE_STEP]
[--cfg_strength CFG_STRENGTH]
[--sway_sampling_coef SWAY_SAMPLING_COEF]
[--speed SPEED] [--fix_duration FIX_DURATION]
[--device DEVICE]
Commandline interface for E2/F5 TTS with Advanced Batch Processing.
options:
-h, --help show this help message and exit
-c CONFIG, --config CONFIG
The configuration file, default see
infer/examples/basic/basic.toml
-m MODEL, --model MODEL
The model name: F5TTS_v1_Base | F5TTS_Base |
E2TTS_Base | etc.
-mc MODEL_CFG, --model_cfg MODEL_CFG
The path to F5-TTS model config file .yaml
-p CKPT_FILE, --ckpt_file CKPT_FILE
The path to model checkpoint .pt, leave blank to use
default
-v VOCAB_FILE, --vocab_file VOCAB_FILE
The path to vocab file .txt, leave blank to use
default
-r REF_AUDIO, --ref_audio REF_AUDIO
The reference audio file.
-s REF_TEXT, --ref_text REF_TEXT
The transcript/subtitle for the reference audio
-t GEN_TEXT, --gen_text GEN_TEXT
The text to make model synthesize a speech
-f GEN_FILE, --gen_file GEN_FILE
The file with text to generate, will ignore --gen_text
-o OUTPUT_DIR, --output_dir OUTPUT_DIR
The path to output folder
-w OUTPUT_FILE, --output_file OUTPUT_FILE
The name of output file
--save_chunk To save each audio chunks during inference
--remove_silence To remove long silence found in ouput
--load_vocoder_from_local
To load vocoder from local dir, default to
../checkpoints/vocos-mel-24khz
--vocoder_name {vocos,bigvgan}
Used vocoder name: vocos | bigvgan, default vocos
--target_rms TARGET_RMS
Target output speech loudness normalization value,
default 0.1
--cross_fade_duration CROSS_FADE_DURATION
Duration of cross-fade between audio segments in
seconds, default 0.15
--nfe_step NFE_STEP The number of function evaluation (denoising steps),
default 32
--cfg_strength CFG_STRENGTH
Classifier-free guidance strength, default 2.0
--sway_sampling_coef SWAY_SAMPLING_COEF
Sway Sampling coefficient, default -1.0
--speed SPEED The speed of the generated audio, default 1.0
--fix_duration FIX_DURATION
Fix the total duration (ref and gen audios) in
seconds, default None
--device DEVICE Specify the device to run on
Specify options above to override one or more settings from config.
音声ファイルをリファレンスに使って音声を生成の例。f5-ttsパッケージにはサンプルの音声が用意されている。レポジトリだと以下で確認できる。
パッケージインストールすると以下に置いてあったのでこれを使う。
!ls -lt /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/basic/
total 576
-rw-r--r-- 1 root root 324558 May 20 09:57 basic_ref_zh.wav
-rw-r--r-- 1 root root 256018 May 20 09:57 basic_ref_en.wav
-rw-r--r-- 1 root root 558 May 20 09:57 basic.toml
パス指定が面倒なので exampels ディレクトリごとカレントに一旦コピー
cp -pr /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples .
examplesディレクトリの中は以下となっている。
examples
├── basic
│ ├── basic_ref_en.wav
│ ├── basic_ref_zh.wav
│ └── basic.toml
├── multi
│ ├── country.flac
│ ├── main.flac
│ ├── story.toml
│ ├── story.txt
│ └── town.flac
└── vocab.txt
リファレンス音声を確認しておく。
from IPython.display import Audio
Audio("examples/basic/basic_ref_en.wav")
英語の男性の声で、
Some call me nature, others call me mother nature.
と発話している音声となっている。
これを使って発話する。リファレンスの音声とそのテキストを指定しているが、テキストについては""とすることで、ASRモデルが自動で文字起こししてくれるらしい。なお、初回はモデルがダウンロードされるので少し時間がかかる。
!f5-tts_infer-cli \
--model F5TTS_v1_Base \
--ref_audio "examples/basic/basic_ref_en.wav" \
--ref_text "Some call me nature, others call me mother nature." \
--gen_text "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races."
pytorch_model.bin: 100% 54.4M/54.4M [00:00<00:00, 193MB/s]
model_1250000.safetensors: 100% 1.35G/1.35G [00:05<00:00, 244MB/s]
Using F5TTS_v1_Base...
vocab : /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/vocab.txt
token : custom
model : /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Voice: main
ref_audio examples/basic/basic_ref_en.wav
Converting audio...
Using custom reference text...
ref_text Some call me nature, others call me mother nature.
ref_audio_ /tmp/tmpuuyjdsk_.wav
No voice tag found, using main.
Voice: main
gen_text 0 Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races.
Generating audio in 1 batches...
100% 1/1 [00:08<00:00, 8.17s/it]
tests/infer_cli_basic.wav
生成された音声を聞いてみる。
Audio("tests/infer_cli_basic.wav")
実際に生成されたものはこちら。
ボコーダーを差し替えることができる。デフォルトはどうやらVocosというものが使用されているようだが、これをBigVGANに変更できるのだが・・・
!f5-tts_infer-cli \
--model F5TTS_Base \
--vocoder_name bigvgan \
--load_vocoder_from_local
UnboundLocalError: cannot access local variable 'bigvgan' where it is not associated with a value
エラーになる。これはpipパッケージではなく、レポジトリからインストールしないと使えない。READMEにも書いてあった。
2. ローカル編集可能モード(学習・微調整も行う場合)
git clone https://github.com/SWivid/F5-TTS.git cd F5-TTS # git submodule update --init --recursive # (必要な場合のみ、bigvgan用) pip install -e .
あと、BigVGANを使う場合、ベースモデルはv1(F5TTS_v1_Base)ではなくv0(F5TTS_Base)である必要があるらしい。
チェックポイントを直接指定して推論。ダウンロードされたモデルがキャッシュされているパスを指定してみた。
!f5-tts_infer-cli --ckpt_file /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Using F5TTS_v1_Base...
vocab : /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/vocab.txt
token : custom
model : /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Voice: main
ref_audio /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/basic/basic_ref_en.wav
Converting audio...
Using custom reference text...
ref_text Some call me nature, others call me mother nature.
ref_audio_ /tmp/tmptj96xbkf.wav
No voice tag found, using main.
Voice: main
gen_text 0 I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring.
Generating audio in 1 batches...
100% 1/1 [00:07<00:00, 7.55s/it]
tests/infer_cli_basic.wav
テキストなどを何も指定していないのに生成された。とりあえず結果を聞いてみる
Audio("tests/infer_cli_basic.wav")
I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring.
F5-TTSには設定から音声を発話する機能がある。パッケージに付属しているサンプル音声がインストールされた箇所にTOMLファイルがあった。
パッケージインストールすると以下に置いてあったのでこれを使う。
!ls -lt /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/basic/出力total 576 -rw-r--r-- 1 root root 324558 May 20 09:57 basic_ref_zh.wav -rw-r--r-- 1 root root 256018 May 20 09:57 basic_ref_en.wav -rw-r--r-- 1 root root 558 May 20 09:57 basic.toml
この中身を見てみる。なお、コメントは日本語に翻訳している。
!cat /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/basic/basic.toml
# F5TTS_v1_Base または E2TTS_Base を選択
model = "F5TTS_v1_Base"
ref_audio = "infer/examples/basic/basic_ref_en.wav"
# 空("")で指定すると、リファレンス音声を自動で文字起こしする
ref_text = "Some call me nature, others call me mother nature."
gen_text = "I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring."
# 生成するテキストをファイルで指定する。その場合、上で指定したテキストは無視される
gen_file = ""
remove_silence = false
output_dir = "tests"
output_file = "infer_cli_basic.wav"
オプションで指定しない限り、どうやら上記の(パッケージがインストールされたパスの)設定ファイルをデフォルトとして生成するらしい。
これを自分で指定することもできる。先ほどカレントにコピーしたexamplesディレクトリ内のTOMLファイルを編集する。ここでは生成するテキスト、出力ディレクトリ、出力ファイル名を変更した。
model = "F5TTS_v1_Base"
ref_audio = "infer/examples/basic/basic_ref_en.wav"
ref_text = "Some call me nature, others call me mother nature."
gen_text = "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races."
gen_file = ""
remove_silence = false
output_dir = "output"
output_file = "keiba.wav"
CLIで-cでTOMLファイルを参照する。
f5-tts_infer-cli -c examples/basic/basic.toml
2025-05-20 12:04:22.443084: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1747742662.476251 33955 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1747742662.486429 33955 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-05-20 12:04:22.520085: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Download Vocos from huggingface charactr/vocos-mel-24khz
Using F5TTS_v1_Base...
vocab : /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/vocab.txt
token : custom
model : /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Voice: main
ref_audio /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/basic/basic_ref_en.wav
Converting audio...
Using custom reference text...
ref_text Some call me nature, others call me mother nature.
ref_audio_ /tmp/tmp44ljn_wb.wav
No voice tag found, using main.
Voice: main
gen_text 0 Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races.
Generating audio in 1 batches...
100% 1/1 [00:06<00:00, 6.29s/it]
output/keiba.wav
Audio("output/keiba.wav")
設定ファイルのとおりに生成されていることが確認できる。
設定ファイルのより複雑な例として、複数のスタイルを設定して生成する例がある。examples/multiディレクトリの下。
model = "F5TTS_v1_Base"
ref_audio = "infer/examples/multi/main.flac"
ref_text = ""
gen_text = ""
gen_file = "infer/examples/multi/story.txt"
remove_silence = true
output_dir = "tests"
output_file = "infer_cli_story.wav"
[voices.town]
ref_audio = "infer/examples/multi/town.flac"
ref_text = ""
[voices.country]
ref_audio = "infer/examples/multi/country.flac"
ref_text = ""
A Town Mouse and a Country Mouse were acquaintances, and the Country Mouse one day invited his friend to come and see him at his home in the fields. The Town Mouse came, and they sat down to a dinner of barleycorns and roots, the latter of which had a distinctly earthy flavour. The fare was not much to the taste of the guest, and presently he broke out with [town] “My poor dear friend, you live here no better than the ants. Now, you should just see how I fare! My larder is a regular horn of plenty. You must come and stay with me, and I promise you you shall live on the fat of the land.” [main] So when he returned to town he took the Country Mouse with him, and showed him into a larder containing flour and oatmeal and figs and honey and dates. The Country Mouse had never seen anything like it, and sat down to enjoy the luxuries his friend provided: but before they had well begun, the door of the larder opened and someone came in. The two Mice scampered off and hid themselves in a narrow and exceedingly uncomfortable hole. Presently, when all was quiet, they ventured out again; but someone else came in, and off they scuttled again. This was too much for the visitor. [country] “Goodbye,” [main] said he, [country] “I’m off. You live in the lap of luxury, I can see, but you are surrounded by dangers; whereas at home I can enjoy my simple dinner of roots and corn in peace.”
A Town Mouse and a Country Mouse were acquaintances, and the Country Mouse one day invited his friend to come and see him at his home in the fields. The Town Mouse came, and they sat down to a dinner of barleycorns and roots, the latter of which had a distinctly earthy flavour. The fare was not much to the taste of the guest, and presently he broke out with [town] “My poor dear friend, you live here no better than the ants. Now, you should just see how I fare! My larder is a regular horn of plenty. You must come and stay with me, and I promise you you shall live on the fat of the land.” [main] So when he returned to town he took the Country Mouse with him, and showed him into a larder containing flour and oatmeal and figs and honey and dates. The Country Mouse had never seen anything like it, and sat down to enjoy the luxuries his friend provided: but before they had well begun, the door of the larder opened and someone came in. The two Mice scampered off and hid themselves in a narrow and exceedingly uncomfortable hole. Presently, when all was quiet, they ventured out again; but someone else came in, and off they scuttled again. This was too much for the visitor. [country] “Goodbye,” [main] said he, [country] “I’m off. You live in the lap of luxury, I can see, but you are surrounded by dangers; whereas at home I can enjoy my simple dinner of roots and corn in peace.”
なるほど、細かく分けることができて、かつ、テーブルを使うと、リファレンス音声を切り替えるタグみたいな感じにできるのね。
実行
!f5-tts_infer-cli -c examples/multi/story.toml
Using F5TTS_v1_Base...
vocab : /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/vocab.txt
token : custom
model : /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Voice: town
ref_audio /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/multi/town.flac
Converting audio...
No reference text provided, transcribing reference audio...
config.json: 100% 1.26k/1.26k [00:00<00:00, 7.19MB/s]
model.safetensors: 100% 1.62G/1.62G [00:08<00:00, 180MB/s]
generation_config.json: 100% 3.77k/3.77k [00:00<00:00, 27.7MB/s]
tokenizer_config.json: 100% 283k/283k [00:00<00:00, 4.34MB/s]
vocab.json: 100% 1.04M/1.04M [00:00<00:00, 8.19MB/s]
tokenizer.json: 100% 2.71M/2.71M [00:00<00:00, 10.9MB/s]
merges.txt: 100% 494k/494k [00:00<00:00, 2.72MB/s]
normalizer.json: 100% 52.7k/52.7k [00:00<00:00, 185MB/s]
added_tokens.json: 100% 34.6k/34.6k [00:00<00:00, 172MB/s]
special_tokens_map.json: 100% 2.19k/2.19k [00:00<00:00, 23.1MB/s]
preprocessor_config.json: 100% 340/340 [00:00<00:00, 2.90MB/s]
Device set to use cuda
/usr/local/lib/python3.11/dist-packages/transformers/models/whisper/generation_whisper.py:573: FutureWarning: The input name `inputs` is deprecated. Please make sure to use `input_features` instead.
warnings.warn(
You have passed task=transcribe, but also have set `forced_decoder_ids` to [[1, None], [2, 50360]] which creates a conflict. `forced_decoder_ids` will be ignored in favor of task=transcribe.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
ref_text The difference in the rainbow depends considerably upon the size of the drops and the width of the coloured band increases as the size of the drops increases.
ref_audio_ /tmp/tmppgqj22xe.wav
Voice: country
ref_audio /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/multi/country.flac
Converting audio...
No reference text provided, transcribing reference audio...
/usr/local/lib/python3.11/dist-packages/transformers/models/whisper/generation_whisper.py:573: FutureWarning: The input name `inputs` is deprecated. Please make sure to use `input_features` instead.
warnings.warn(
ref_text six spoons of fresh snow peas, five thick slabs of blue cheese, and maybe a snack for her brother Bob.
ref_audio_ /tmp/tmpgrra5hme.wav
Voice: main
ref_audio /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/multi/main.flac
Converting audio...
No reference text provided, transcribing reference audio...
/usr/local/lib/python3.11/dist-packages/transformers/models/whisper/generation_whisper.py:573: FutureWarning: The input name `inputs` is deprecated. Please make sure to use `input_features` instead.
warnings.warn(
ref_text Six spoons of fresh snow peas, five thick slabs of blue cheese and maybe a snack for her brother Bob.
ref_audio_ /tmp/tmp2df0ekl4.wav
No voice tag found, using main.
Voice: main
gen_text 0 A Town Mouse and a Country Mouse were acquaintances, and the Country Mouse one day invited his friend to come and see him at his home in the fields. The Town Mouse came, and they sat down to a dinner of barleycorns and roots, the latter of which had a distinctly earthy flavour. The fare was not much to the taste of the guest,
gen_text 1 and presently he broke out with
Generating audio in 2 batches...
100% 2/2 [00:09<00:00, 4.70s/it]
Voice: town
gen_text 0 “My poor dear friend, you live here no better than the ants. Now, you should just see how I fare! My larder is a regular horn of plenty. You must come and stay with me, and I promise you you shall live on the fat of the land.”
Generating audio in 1 batches...
100% 1/1 [00:05<00:00, 5.54s/it]
Voice: main
gen_text 0 So when he returned to town he took the Country Mouse with him, and showed him into a larder containing flour and oatmeal and figs and honey and dates. The Country Mouse had never seen anything like it, and sat down to enjoy the luxuries his friend provided: but before they had well begun,
gen_text 1 the door of the larder opened and someone came in. The two Mice scampered off and hid themselves in a narrow and exceedingly uncomfortable hole. Presently, when all was quiet, they ventured out again; but someone else came in, and off they scuttled again. This was too much for the visitor.
Generating audio in 2 batches...
100% 2/2 [00:11<00:00, 5.59s/it]
Voice: country
gen_text 0 “Goodbye,”
Generating audio in 1 batches...
100% 1/1 [00:02<00:00, 2.65s/it]
Voice: main
gen_text 0 said he,
Generating audio in 1 batches...
100% 1/1 [00:01<00:00, 1.97s/it]
Voice: country
gen_text 0 “I’m off. You live in the lap of luxury, I can see, but you are surrounded by dangers; whereas at home I can enjoy my simple dinner of roots and corn in peace.”
Generating audio in 1 batches...
100% 1/1 [00:04<00:00, 4.82s/it]
tests/infer_cli_story.wav
結果
Audio("tests/infer_cli_story.wav")
Pythonで。なんだろう、この画像パスを指定するオプションは?とりあえず実行。
from importlib.resources import files
from f5_tts.api import F5TTS
f5tts = F5TTS()
wav, sr, spec = f5tts.infer(
ref_file="examples/basic/basic_ref_en.wav",
ref_text="some call me nature, others call me mother nature.",
gen_text="""I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences.""",
file_wave="output/api_out.wav",
file_spec="output/api_out.png",
seed=None,
)
display(Audio(data=wav, rate=sr))
display(HTML(f'<img src="{url}" width="600" style="border-radius:8px;">')
)
エラー。
ModuleNotFoundError: No module named 'numpy.rec'
numpyの問題かなと思ったけど、多分matplotlibの方。
!pip freeze | egrep -i "numpy|matplotlib"
matplotlib==3.10.0
matplotlib-inline==0.1.7
matplotlib-venn==1.1.2
numpy==1.26.4
numpy2に対応する前のmatplotlibのバージョンに戻す。自分が調べた限りは3.7.5。
!pip install "matplotlib==3.7.5"
ランタイムの再起動が必要になる。再起動後に上のPythonコードを再度実行すると動作すると思う。
Download Vocos from huggingface charactr/vocos-mel-24khz
vocab : /usr/local/lib/python3.11/dist-packages/f5_tts/infer/examples/vocab.txt
token : custom
model : /root/.cache/huggingface/hub/models--SWivid--F5-TTS/snapshots/84e5a410d9cead4de2f847e7c9369a6440bdfaca/F5TTS_v1_Base/model_1250000.safetensors
Converting audio...
Using custom reference text...
ref_text some call me nature, others call me mother nature.
gen_text 0 I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring.
gen_text 1 Respect me and I'll nurture you; ignore me and you shall face the consequences.
Generating audio in 2 batches...
100%|██████████| 2/2 [00:10<00:00, 5.33s/it]

なるほどね、スペクトログラムか。
コミュニティで作成された日本語モデルを試してみる
from huggingface_hub import snapshot_download
snapshot_download('Jmica/F5TTS', local_dir='f5tts_ja')
リファレンス音声は自分の声を録音したものを用意した。
!f5-tts_infer-cli \
--ckpt_file ./f5tts_ja/JA_21999120/model_21999120.pt \
--vocab_file ./f5tts_ja/JA_21999120/vocab_japanese.txt \
--ref_audio "my_voice.wav" \
--ref_text "おはようございます。今日はとても良いお天気ですね。こんな日は競馬場に行きたくなりますね。" \
--gen_text "こんにちは。" \
--output_dir "./output" \
--output_file "sample_ja.wav"
Audio("output/sample_ja.wav")
生成されたものは何を言っているのか全然聞き取れない感じ・・・英語のリファレンス音声しても似たような感じだった。この辺り見ると、ひらがな・カタカナにしないといけないってのはあるにしても、一応それっぽい生成はできてるようなのだけど・・・
上の続き
Gradioだといけた

ここに Shared Modelのページにある設定をそのままコピペすれば良い。

あと、上であったとおり、発話したいテキストはひらがな・カタカナにしておく必要がある。リファレンス音声のテキストもたぶん同じにしたほうが良さそう。
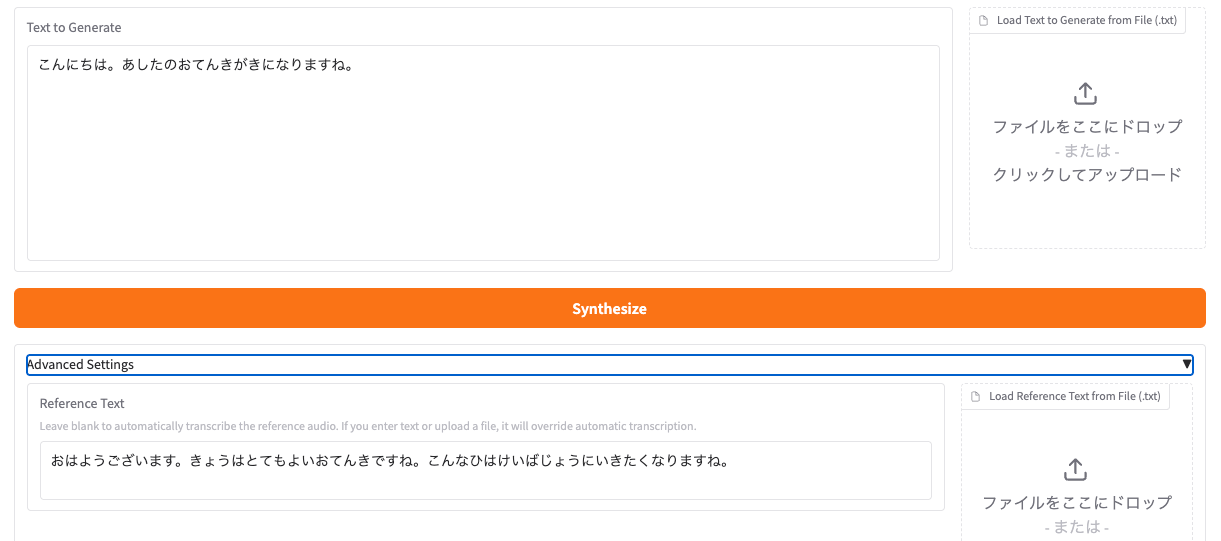
まあ発話やイントネーションは少し微妙ではあるのだけど、とりあえず日本語使えるところまでは来れたのでOKとする。
ただこれCLIだとどうやって渡せばいいのかな?CLIだと以下の引数があるけど、ファイルのフォーマットがわからない・・・
-mc MODEL_CFG, --model_cfg MODEL_CFG
The path to F5-TTS model config file .yaml
ライセンス
本コードはMITライセンスで公開されています。事前学習モデルはEmilia(自然環境下データセット)により学習されたため、CC-BY-NCライセンスのもと提供されています。ご了承ください。
公式のモデルのライセンスがCC-BY-NCである点には注意
ここがネックになるというところで、ライセンス場問題のない事前学習モデルを公開されている方がいる。
元の F5-TTS モデルとの主な違いは、モデルのライセンスです。トレーニングデータのため、F5-TTS モデルは非営利ライセンス (CC BY-NC) でライセンスされています。このモデルは、寛容なライセンスで提供されているデータを使用してトレーニングされており、Apache 2.0 ライセンスで提供されているため、商用および個人目的の両方で使用できます。
まとめ
今となっては半年以上前のもので、日本語も微妙ではあるのだが、なんていうか、思いの外しっかり作ってあるというか、整理されてるなーと個人的には感じた。
この手のプロジェクト、ライブラリの依存関係とかが複雑で環境構築が大変、ドキュメント見てもよくわからない、ってのは結構多いと思っていて、なんというかそのあたりが少しスッキリ整理されている印象を受けたのだよな。コミュニティベースのモデル、みたいなエコシステムっぽいものもあるし。
今後のプロジェクトの継続性みたいなものを考えるとこういうのは結構大事な気がしている。