Open8
spaCyに入門する
このあたりを参考に進める
実践Data Scienceシリーズ Pythonではじめるテキストアナリティクス入門
基本的にnpaka先生の記事の後追い写経するだけなので見るべきところはないと思う。
colaboratoryでやる。デフォルトでインストールされている模様。
!pip freeze | grep -i spacy
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl#sha256=86cc141f63942d4b2c5fcee06630fd6f904788d2f0ab005cce45aadb8fb73889
spacy==3.7.4
spacy-legacy==3.0.12
spacy-loggers==1.0.5
spaCyとは何か?
- Pythonで利用できる無料かつオープンソースの高度な自然言語処理(NLP)ライブラリ。
- 大量のテキストを処理し、解析するために設計されており、テキストの内容や文脈上の意味を理解するのに役立つ。
- 実用向けに特化しており、情報抽出、自然言語理解システムの構築、ディープラーニング用のテキスト前処理に使用される。
spaCyではないもの
- プラットフォームや「API」ではない。サービスとしてのソフトウェアやウェブアプリケーションを提供しないオープンソースのライブラリである。
- 即戦力のチャットボットエンジンではない。会話型アプリケーションに使用できるが、チャットボット専用に設計されているわけではない。
- 研究ソフトウェアではない。最新の研究に基づいて構築されているが、実用的な目的で設計されており、選択肢を限定することで性能と開発者体験を向上させる。
- 企業ではない。オープンソースのライブラリであり、Explosion社がspaCyを含むソフトウェアを公開してる。
spaCyの機能
| 英語の名称 | 日本語の名称 | 説明 |
|---|---|---|
| Tokenization | トークン化 | テキストを単語や句読点などに分割する。 |
| Part-of-speech (POS) Tagging | 品詞タグ付け | トークンに動詞や名詞などの品詞を割り当てる。 |
| Dependency Parsing | 係り受け解析 | トークン間の構文依存関係を示すラベルを割り当てる。 |
| Lemmatization | 規範化(レンマ化) | 単語の基底形を割り当てる。例えば、「was」のレンマは「be」、「rats」のレンマは「rat」。 |
| Sentence Boundary Detection (SBD) | 文境界検出 | 個々の文を見つけて分割する。 |
| Named Entity Recognition (NER) | 固有表現認識 | 人物、企業、場所などの固有名詞にラベルを付ける。 |
| Entity Linking (EL) | エンティティリンク | テキストのエンティティを知識ベース内の一意の識別子に曖昧さ解消する。 |
| Similarity | 類似性 | 単語、テキストスパン、文書を比較し、互いにどれだけ似ているかを評価する。 |
| Text Classification | テキスト分類 | 文書全体または文書の一部にカテゴリーやラベルを割り当てる。 |
| Rule-based Matching | ルールベースマッチング | テキストや言語的アノテーションに基づいてトークンの並びを検出する。正規表現に類似。 |
| Training | トレーニング | 統計モデルの予測を更新し改善する。 |
| Serialization | シリアライゼーション | オブジェクトをファイルやバイト文字列に保存する。 |
統計モデル
- spaCyの機能の中には独立して動作するものもあれば、訓練済みパイプラインが必要なものもある。
- 訓練済みパイプラインは、品詞や依存関係などの言語的アノテーションを予測するために使用される。
- spaCyは多言語の訓練済みパイプラインを複数提供しており、それぞれサイズや速度、メモリ使用量、精度が異なる。
- パイプラインには通常、以下の様なものが含まれる:
- 文脈内でのアノテーションを予測するための品詞タグ付け、依存関係解析、固有表現認識に対するバイナリ重み。
- 語彙における語彙エントリ、すなわち単語とその文脈に依存しない属性(形状や綴りなど)。
- 規範化ルールやルックアップテーブルなどのデータファイル。
- 単語間の類似度を判断するための多次元意味表現であるワードベクトル。
- パイプラインを読み込む際にspaCyを正しい状態に設定するための言語や処理パイプライン設定、モデル実装などの設定オプション。
言語的アノテーション
- spaCyはテキストの文法構造を理解するための、さまざまな言語的アノテーションを提供する。例えば、品詞のような単語の種類や、単語間の関係など。
- 訓練済みパイプラインをインストールした後、
spacy.loadを通じてロードすることにより、テキスト処理に必要なすべてのコンポーネントとデータを含むLanguageオブジェクトが返される。 -
nlpオブジェクトをテキストの文字列に適用すると、処理されたDocが返される。例えば以下のコードでは、単語、品詞、構文依存関係を出力する:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_)
Apple PROPN nsubj
is AUX aux
looking VERB ROOT
at ADP prep
buying VERB pcomp
U.K. PROPN dobj
startup NOUN dep
for ADP prep
$ SYM quantmod
1 NUM compound
billion NUM pobj
- 処理された
Docでも、元のテキストの全情報(空白文字を含む)を保持しており、トークンのオリジナル文字列へのオフセットを取得したり、トークンとそれに続く空白を結合して元のテキストを再構築することが可能。つまり、spaCyでテキストを処理しても情報は失われない。
日本語用の訓練済みパイプラインは以下。
今回はja_core_news_smで。
!python -m spacy download ja_core_news_sm
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
for token in doc:
print(token.text, token.pos_, token.dep_)
アップル PROPN nmod
、 PUNCT punct
英国 PROPN nmod
の ADP case
新興 NOUN compound
企業 NOUN obj
を ADP case
10億 NUM nummod
ドル NOUN obl
で ADP case
買収 NOUN ROOT
か PART mark
。 PUNCT punct
トークン化
- spaCyはテキスト処理時に最初にトークン化を行い、テキストを単語や句読点などに分割する。これは言語ごとの特定のルールを適用して行われる。例えば、文末の句読点は分離されるが、「U.K.」は一つのトークンとして保持される。
- 各
Docは個別のトークンで構成され、以下のようにしてトークンを繰り返し処理することができる:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for i, token in enumerate(doc):
print(i, ":", token.text)
0 : Apple
1 : is
2 : looking
3 : at
4 : buying
5 : U.K.
6 : startup
7 : for
8 : $
9 : 1
10 : billion
- トークン化はまず空白文字で生テキストを分割することから始まり、その後トークナイザーがテキストを左から右へ処理する。各部分文字列に対して二つのチェックが行われる:
- 部分文字列がトークナイザーの例外ルールに一致するか? 例えば「don't」は空白を含まないが、「do」と「n't」に分割されるべきであり、「U.K.」は常に一つのトークンのままであるべき。
- 接頭辞、接尾辞、または中間接辞が分離できるか? 例えば、カンマ、ピリオド、ハイフン、引用符などが分離の対象となる。
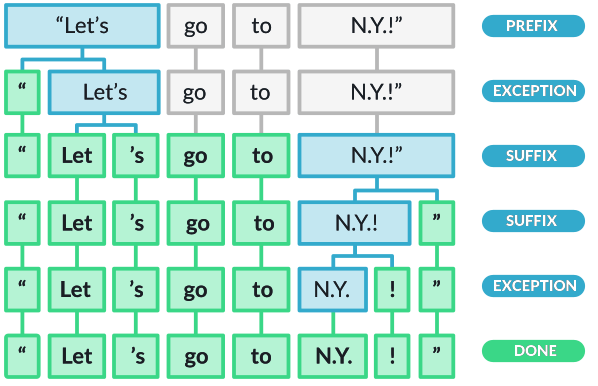
refer from: https://spacy.io/usage/spacy-101
- ルールが一致する場合、トークナイザーはルールを適用してループを続け、新しく分割された部分文字列から処理を再開する。これにより、spaCyは略語や複数の句読点が組み合わさった複雑なネストされたトークンも分割できる。
- 句読点のルールは一般的に広範囲に適用されるが、トークナイザーの例外は各言語の具体的な特性に大きく依存する。そのため、使用可能な各言語には、ハードコーディングされたデータや例外ルールを読み込む独自のサブクラスがある。例えば、
EnglishやGermanなどがこれに該当する。
日本語の場合。なお、日本語の場合はトークナイザーはSudachiが使用されているらしい。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
for i, token in enumerate(doc):
print(i, ":", token.text)
0 : アップル
1 : 、
2 : 英国
3 : の
4 : 新興
5 : 企業
6 : を
7 : 10億
8 : ドル
9 : で
10 : 買収
11 : か
12 : 。
品詞タグと依存関係
-
トークン化の後、spaCyは与えられた
Docを解析し、タグ付けすることができる。これには訓練されたパイプラインとその統計モデルが使用され、文脈において最も適切なタグやラベルを予測する。 -
訓練されたコンポーネントには、言語全体にわたって一般化できる予測を行うために十分な例を示すことで生成されるバイナリデータが含まれている。例えば、英語で「the」の後に来る単語はほとんどの場合名詞である。
-
言語的アノテーションは
Token属性として利用可能である。多くのNLPライブラリと同様に、spaCyはメモリ使用を削減し効率を向上させるために、すべての文字列をハッシュ値にエンコードする。そのため、属性の可読な文字列表現を取得するには、属性名にアンダースコア_を追加する必要がある:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Apple Apple PROPN NNP nsubj Xxxxx True False
is be AUX VBZ aux xx True True
looking look VERB VBG ROOT xxxx True False
at at ADP IN prep xx True True
buying buy VERB VBG pcomp xxxx True False
U.K. U.K. PROPN NNP dobj X.X. False False
startup startup NOUN NN dep xxxx True False
for for ADP IN prep xxx True True
$ $ SYM $ quantmod $ False False
1 1 NUM CD compound d False False
billion billion NUM CD pobj xxxx True False
| TEXT | LEMMA | POS | TAG | DEP | SHAPE | ALPHA | STOP |
|---|---|---|---|---|---|---|---|
| Apple | apple | PROPN | NNP | nsubj | Xxxxx | True | False |
| is | be | AUX | VBZ | aux | xx | True | True |
| looking | look | VERB | VBG | ROOT | xxxx | True | False |
| at | at | ADP | IN | prep | xx | True | True |
| buying | buy | VERB | VBG | pcomp | xxxx | True | False |
| U.K. | u.k. | PROPN | NNP | compound | X.X. | False | False |
| startup | startup | NOUN | NN | dobj | xxxx | True | False |
| for | for | ADP | IN | prep | xxx | True | True |
| $ | $ | SYM | $ | quantmod | $ | False | False |
| 1 | 1 | NUM | CD | compound | d | False | False |
| billion | billion | NUM | CD | pobj | xxxx | True | False |
- spaCyの組み込みビジュアライザーであるdisplaCyを使用すると、例文とその依存関係を視覚的に表示できる。
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
displacy.serve(doc, style="dep")

日本語の場合。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
for token in doc:
print([str(t) for t in [token.text, token.lemma_, token.pos_, token.tag_, token.dep_, token.shape_, token.is_alpha, token.is_stop]])
['アップル', 'アップル', 'PROPN', '名詞-普通名詞-一般', 'nmod', 'xxxx', 'True', 'False']
['、', '、', 'PUNCT', '補助記号-読点', 'punct', '、', 'False', 'False']
['英国', '英国', 'PROPN', '名詞-固有名詞-地名-国', 'nmod', 'xx', 'True', 'False']
['の', 'の', 'ADP', '助詞-格助詞', 'case', 'x', 'True', 'True']
['新興', '新興', 'NOUN', '名詞-普通名詞-一般', 'compound', 'xx', 'True', 'False']
['企業', '企業', 'NOUN', '名詞-普通名詞-一般', 'obj', 'xx', 'True', 'False']
['を', 'を', 'ADP', '助詞-格助詞', 'case', 'x', 'True', 'True']
['10億', '10億', 'NUM', '名詞-数詞', 'nummod', 'ddx', 'False', 'False']
['ドル', 'ドル', 'NOUN', '名詞-普通名詞-助数詞可能', 'obl', 'xx', 'True', 'False']
['で', 'で', 'ADP', '助詞-格助詞', 'case', 'x', 'True', 'True']
['買収', '買収', 'NOUN', '名詞-普通名詞-サ変可能', 'ROOT', 'xx', 'True', 'False']
['か', 'か', 'PART', '助詞-終助詞', 'mark', 'x', 'True', 'True']
['。', '。', 'PUNCT', '補助記号-句点', 'punct', '。', 'False', 'False']
| TEXT | LEMMA | POS | TAG | DEP | SHAPE | ALPHA | STOP |
|---|---|---|---|---|---|---|---|
| アップル | アップル | PROPN | 名詞-普通名詞-一般 | nmod | xxxx | True | False |
| 、 | 、 | PUNCT | 補助記号-読点 | punct | 、 | False | False |
| 英国 | 英国 | PROPN | 名詞-固有名詞-地名-国 | nmod | xx | True | False |
| の | の | ADP | 助詞-格助詞 | case | x | True | True |
| 新興 | 新興 | NOUN | 名詞-普通名詞-一般 | compound | xx | True | False |
| 企業 | 企業 | NOUN | 名詞-普通名詞-一般 | obj | xx | True | False |
| を | を | ADP | 助詞-格助詞 | case | x | True | True |
| 10億 | 10億 | NUM | 名詞-数詞 | nummod | ddx | False | False |
| ドル | ドル | NOUN | 名詞-普通名詞-助数詞可能 | obl | xx | True | False |
| で | で | ADP | 助詞-格助詞 | case | x | True | True |
| 買収 | 買収 | NOUN | 名詞-普通名詞-サ変可能 | ROOT | xx | True | False |
| か | か | PART | 助詞-終助詞 | mark | x | True | True |
| 。 | 。 | PUNCT | 補助記号-句点 | punct | 。 | False | False |
各項目の意味は以下。
- TET: 元の単語テキスト。
- LEMMA: 単語の基本形。
- POS: 単純なUPOS品詞タグ。
- TAG: 詳細な品詞タグ。
- DEP: 構文依存、つまりトークン間の関係。
- SHAPE: 単語の形 - 大文字、句読点、数字。
- is alpha: トークンはアルファ文字か。
- is stop: トークンはストップリストの一部か、つまり、つまり、その言語で最も一般的な単語か。
係り受けの可視化
import spacy
from spacy import displacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
displacy.serve(doc, style="dep")

固有表現
- 固有表現は「実世界のオブジェクト」であり、人物、国、製品、書籍のタイトルなどが該当する。spaCyは文書内のさまざまな種類の固有表現を認識することができ、モデルに予測を求めることでこれを実現する。モデルは統計的であり、訓練された例に強く依存するため、常に完璧に機能するわけではなく、使用ケースに応じて後で調整が必要になることがある。
- 固有表現は
Docのentsプロパティとして利用可能である:
Apple 0 5 ORG
U.K. 27 31 GPE
$1 billion 44 54 MONEY
| TEXT | START | END | LABEL | DESCRIPTION |
|---|---|---|---|---|
| Apple | 0 | 5 | ORG |
企業、機関、組織 |
| U.K. | 27 | 31 | GPE |
地政学的実体、すなわち国、都市、州 |
| $1 billion | 44 | 54 | MONEY |
通貨単位を含む金銭的価値 |
- spaCyの組み込みビジュアライザーであるdisplaCyを使用すると、例文とその固有表現を視覚的に表示できる。
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
displacy.serve(doc, style="ent")

日本語の場合。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
アップル 0 4 ORG
英国 5 7 GPE
10億ドル 13 18 MONEY
| TEXT | START | END | LABEL | DESCRIPTION |
|---|---|---|---|---|
| アップル | 0 | 4 | ORG |
企業、機関、組織 |
| 英国 | 5 | 7 | GPE |
地政学的実体、すなわち国、都市、州 |
| 10億ドル | 13 | 18 | MONEY |
通貨単位を含む金銭的価値 |
import spacy
from spacy import displacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル、英国の新興企業を10億ドルで買収か。")
displacy.serve(doc, style="ent")

単語ベクトルと類似性
- 類似性は、単語の多次元的な意味表現である単語ベクトルまたは「単語埋め込み」を比較することによって決定される。単語ベクトルはword2vecのようなアルゴリズムを使用して生成され、通常以下のような形式をしている:
array([2.02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
...
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e+00, -4.71559986e-02, 5.31750023e-01], dtype=float32)
- 組み込みの単語ベクトルを持つパイプラインパッケージは、これを
Token.vector属性として提供する。Doc.vectorおよびSpan.vectorは、それらのトークンベクトルの平均としてデフォルト設定される。 - トークンにベクトルが割り当てられているかを確認し、L2ノルムを取得することができる。これはベクトルの正規化に使用される。
import spacy
nlp = spacy.load("en_core_web_md")
tokens = nlp("dog cat banana afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
dog True 75.254234 False
cat True 63.188496 False
banana True 31.620354 False
afskfsd False 0.0 True
- 英語でよく使われる単語「dog」、「cat」、「banana」はパイプラインの語彙に含まれ、それぞれベクトルを持っている。一方、一般的ではない「afskfsd」のような単語は語彙外であり、そのベクトル表現は300次元のゼロで構成されており、事実上存在しないと見なされる。
- アプリケーションが大規模なボキャブラリとより多くのベクトルから恩恵を受ける場合、より大きなパイプラインパッケージを使用するか、例えば
en_core_web_lgのような完全なベクトルパッケージを読み込むことを検討するべきである。このパッケージには685,000個のユニークなベクトルが含まれている。 - spaCyは2つのオブジェクトを比較し、どれだけ類似しているかの予測を行うことができる。類似性の予測は、推薦システムを構築したり、重複を検出したりするのに役立つ。例えば、ユーザーが現在見ている内容に類似したコンテンツを提案したり、サポートチケットが既存のものと非常に類似している場合に重複としてラベル付けすることができる。
- 各
Doc、Span、Token、Lexemeには.similarityメソッドがあり、他のオブジェクトと比較して類似性を判定することができる。もちろん、類似性は常に主観的であり、2つの単語、スパン、文書が類似しているかどうかは観察の仕方に依存する。spaCyの類似性実装は通常、かなり汎用的な類似性の定義を前提としている。
import spacy
nlp = spacy.load("en_core_web_md") # 必ず大きめのパッケージを使用すること!
doc1 = nlp("I like salty fries and hamburgers.")
doc2 = nlp("Fast food tastes very good.")
# 2つの文書の類似性
print(doc1, "<->", doc2, doc1.similarity(doc2))
# トークンとスパンの類似性
french_fries = doc1[2:4]
burgers = doc1[5]
print(french_fries, "<->", burgers, french_fries.similarity(burgers))
I like salty fries and hamburgers. <-> Fast food tastes very good. 0.691649353055761
salty fries <-> hamburgers 0.6938489675521851
類似性結果から何を期待するか
- 類似性スコアは有用だが、その情報の限界を理解することが重要である。単語間の関係は多様であり、異なるデータで訓練されたベクトルは目的に合わない結果を生じる可能性がある。
- 類似性には客観的な定義がなく、その有効性は使用するアプリケーションによって異なる。例えば、食べ物に関する好みが類似しているかどうかは、分析の文脈に依存する。
-
DocやSpanの類似性はトークンベクトルの平均に基づいており、これはフレーズ全体の意味を完全に代表するものではない。 - ベクトルの平均化は単語の順序に対して不敏感であり、同じ意味を異なる言葉で表現する文書間の類似性は低くなることがある。
日本語の場合。
!python -m spacy download ja_core_news_md
import spacy
nlp = spacy.load("ja_core_news_md")
tokens = nlp("犬 猫 バナナ orz")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
犬 True 3.4318957 False
猫 True 3.1371322 False
バナナ True 3.6754096 False
orz False 0.0 True
import spacy
nlp = spacy.load("ja_core_news_md")
doc1 = nlp("フライドポテトとハンバーガーが好きだ。")
doc2 = nlp("ファーストフードはとても美味しい。")
#2つの文書の類似性
print(doc1, "<->", doc2, doc1.similarity(doc2))
# トークンとスパンの類似性
french_fries = doc1[0:2]
burgers = doc1[3]
print(french_fries, "<->", burgers, french_fries.similarity(burgers))
フライドポテトとハンバーガーが好きだ。 <-> ファーストフードはとても美味しい。 0.7933248096530182
フライドポテト <-> ハンバーガー 0.7075340151786804