Playwrightを試してみる(Python)
🎭 Playwright
PlaywrightはWebテストと自動化のためのフレームワークです。これを使うことで、単一のAPIを通じてChromium、Firefox、WebKitのテストが可能です。Playwrightは、常に最新で、機能豊富で、信頼性が高く、速いクロスブラウザのWeb自動化を実現するために開発されました。
すべてのブラウザで、すべてのプラットフォームにおいてヘッドレス実行がサポートされています。詳細についてはシステム要件をご確認ください。
Python、.NET、またはJava用のPlaywrightをお探しですか?
機能
堅牢・不安定なテストなし
自動待機:Playwrightは、アクションを実行する前に要素が操作可能になるのを待ちます。また、豊富な内省イベントセットを持っています。これらの組み合わせにより、不安定なテストの主な原因である人工的なタイムアウトが不要になります。
Web最適化のアサーション:Playwrightのアサーションは動的なWeb向けに特別に作られています。必要な条件が満たされるまでチェックは自動的に再試行されます。
トレーシング:テスト再試行戦略を設定し、実行トレース、ビデオ、スクリーンショットをキャプチャして不安定さを排除します。
トレードオフなし・制限なし
ブラウザは異なるオリジンのWebコンテンツを異なるプロセスで実行します。Playwrightは現代のブラウザのアーキテクチャに沿っており、プロセス外でテストを実行します。これにより、通常のプロセス内テストランナーの制限がありません。
全てを複数に:複数のタブ、複数のオリジン、複数のユーザーにまたがるテストシナリオを作成します。異なるユーザー向けに異なるコンテキストのシナリオを作成し、それをサーバーに対して実行します。これらを全て一つのテストで行います。
信頼できるイベント:要素をホバーし、動的なコントロールとやり取りし、信頼できるイベントを生成します。Playwrightは実際のユーザーと区別がつかない実際のブラウザの入力パイプラインを使用します。
フレームのテスト、Shadow DOMを突破:PlaywrightのセレクタはShadow DOMを突破し、フレームへの移動をシームレスにします。
完全な隔離 • 高速実行
ブラウザコンテキスト:Playwrightは各テストに対してブラウザコンテキストを作成します。ブラウザコンテキストは新しいブラウザプロファイルと同等です。これにより、オーバーヘッドゼロで完全なテスト隔離が実現します。新しいブラウザコンテキストを作成するのは数ミリ秒しかかかりません。
ログインは一度だけ:コンテキストの認証状態を保存し、すべてのテストで再利用します。これにより、各テストでの繰り返しのログイン操作を回避しつつ、独立したテストの完全な隔離を実現します。
強力なツール
Codegen:アクションを記録してテストを生成します。任意の言語に保存します。
Playwrightインスペクタ:ページを検査し、セレクタを生成し、テスト実行をステップスルーし、クリックポイントを確認し、実行ログを探索します。
トレースビューア:テスト失敗の調査に必要なすべての情報をキャプチャします。Playwrightトレースには、テスト実行のスクリーンキャスト、ライブDOMスナップショット、アクションエクスプローラー、テストソースなどが含まれます。
スクレイピングにはもっぱらSeleniumを使っている(いまだ使いこなせてる気が全くしない)のだけど、ちょっと違うものも触っておこうということで。
Python版のドキュメントを見ると、2つのGetting Startedがある
e2eテストツールとしてのGetting Started
ライブラリとしてのGetting Started
純粋にスクレイピングで使うならば後者になると思うので、こちらに従ってやっていく。
Playwrightのインストール
!pip install playwright
次にブラウザなどをインストールする。特に指定しなければ、Chromium、Firefox、Webkitがインストールされる。あと、--with-depsをつけておくと、Playwrightが依存するOSパッケージも合わせてインストールしてくれる。
!playwright install --with-deps
で、JupyterやColaboratoryの場合はイベントループで動いているので、以下が必要になる。
import nest_asyncio
nest_asyncio.apply()
さらに、Playwrightは同期・非同期APIの両方に対応しているが、上記の理由で非同期APIを使うことになる。
では最初のコード。非同期APIを使用するので、async/awaitを使う。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# ブラウザを起動
browser = await p.chromium.launch()
# 新しいページを開く
page = await browser.new_page()
# URLに移動
await page.goto("http://playwright.dev")
# ページタイトルを取得して表示
print(await page.title())
# ブラウザを閉じる
await browser.close()
asyncio.run(main())
Fast and reliable end-to-end testing for modern web apps | Playwright
JupyterやColaboratoryでは動かないけど、同期APIで実行する場合はこう。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("http://playwright.dev")
print(page.title())
browser.close()
とりあえず、手元でスクレイピングしてるやつを軽く書き換えてみた感想。
- かなりスッキリ書ける
- 読み込みを待つためにsleep入れたりが不要なのは良い(入れることもできる)
- セットアップが楽
あたりかな。
以下の記事で、Seleniumを使ってキャプチャしているけど、画面サイズ指定とかも含めて、きちんと全部をキャプチャするのは結構手間だったけど、
Playwrightだと何もせずともfull_page=Trueを指定するだけできれいに全体が撮れていた。
await page.screenshot(path="./example.png", full_page=True)
まあ自分がSeleniumを使いこなせてないだけとも思うけども、自分の用途的(キャプチャ以外にも競馬データのスクレイピングとか)には乗り換えてもいいかなぁという気がするぐらいには好印象ではある。
もうちょっと色々試してみる(予定)
自動待機:Playwrightは、アクションを実行する前に要素が操作可能になるのを待ちます。また、豊富な内省イベントセットを持っています。これらの組み合わせにより、不安定なテストの主な原因である人工的なタイムアウトが不要になります。
あたりはドキュメントだとここ
以下も参考になる。
・・・のだけど、wait_for_selectorは既にdeprecatedで、locator.wait_for()が推奨されている。
JRAの各競馬場ごとの馬場状態を取得するサンプル。
以下のようなことをやっている。
- 複数の競馬場で同時開催されるため、タブで切り替えて情報を取得
- 芝クッション値、芝・ダート含水率などの数値をパースする
- 非表示部分などをクリックで表示させて全画面キャプチャする。
import asyncio
import json
from playwright.async_api import async_playwright
import tracemalloc
tracemalloc.start()
base_url = "https://www.jra.go.jp/keiba/baba"
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
# JRAの馬場情報のトップページにアクセス
await page.goto(f"{base_url}/index.html")
await page.wait_for_load_state("networkidle")
# タブから開催中の各競馬場を取得
baba_links = await page.locator('div.kaisai_tab div.nav.tab a').element_handles()
baba_link_info = {}
for link in baba_links:
link_text = await link.inner_text()
link_href = await link.get_attribute('href')
baba_link_info[link_text] = {"url": f"{base_url}/{link_href}"}
for place, info in baba_link_info.items():
# 各競馬場ごとに処理
await page.goto(f"{info['url']}")
await page.wait_for_load_state("networkidle")
#-----
# 芝クッション値
#-----
# 日付リストを取得
turf_cushon_date_locator = page.locator('select#cushion_list')
await turf_cushon_date_locator.wait_for(state='visible')
turf_cushon_date_options = await turf_cushon_date_locator.locator('option').all_text_contents()
# 表示されている日付のクッション値取得
turf_cushon_date_value_locator = page.locator('div#cushion_num p strong')
await turf_cushon_date_value_locator.wait_for(state='visible')
cushon_value = await turf_cushon_date_value_locator.inner_text()
baba_link_info[place].update(
{
"turf_cushon": {
"date": turf_cushon_date_options[0],
"cushon_value": cushon_value
}
}
)
#-----
# 含水率
#-----
# 日付リストを取得
moist_date_locator = page.locator('select#moist_list')
await page.wait_for_selector('select#moist_list', state='visible')
moist_date_options = await moist_date_locator.locator('option').all_text_contents()
# 表示されている日付の含水率取得
moist_date_value_locator_turf_gm = page.locator('#turf_line td.gm')
moist_date_value_locator_turf_c4 = page.locator('#turf_line td.c4')
moist_date_value_locator_dirt_gm = page.locator('#dirt_line td.gm')
moist_date_value_locator_dirt_c4 = page.locator('#dirt_line td.c4')
await moist_date_value_locator_turf_gm.wait_for(state='visible')
await moist_date_value_locator_turf_c4.wait_for(state='visible')
await moist_date_value_locator_dirt_gm.wait_for(state='visible')
await moist_date_value_locator_dirt_c4.wait_for(state='visible')
moist_value_turf_gm = await moist_date_value_locator_turf_gm.inner_text()
moist_value_turf_c4 = await moist_date_value_locator_turf_c4.inner_text()
moist_value_dirt_gm = await moist_date_value_locator_dirt_gm.inner_text()
moist_value_dirt_c4 = await moist_date_value_locator_dirt_c4.inner_text()
baba_link_info[place].update(
{
"turf_moist_c4": {
"date": moist_date_options[0],
"moist_value": moist_value_turf_c4
},
"turf_moist_gm": {
"date": moist_date_options[0],
"moist_value": moist_value_turf_gm
},
"dirt_moist_c4": {
"date": moist_date_options[0],
"moist_value": moist_value_dirt_c4
},
"dirt_moist_c4": {
"date": moist_date_options[0],
"moist_value": moist_value_dirt_gm
}
}
)
#-----
# 週刊情報
#-----
# 情報が折りたたまれているので、「全て表示する」をクリックして開いてからキャプチャする
button_count = await page.locator('text="全て表示する"').count()
if button_count:
await page.get_by_text("全て表示する").click()
# ヘッダーがLazyloadされるので、一旦一番上まで戻ってからキャプチャする
await page.keyboard.press('Home')
await page.screenshot(path=f"{place}.png", full_page=True)
# ブラウザを閉じる
await browser.close()
# 全結果を出力
print(json.dumps(baba_link_info, ensure_ascii=False, indent=2))
asyncio.run(main())
結果
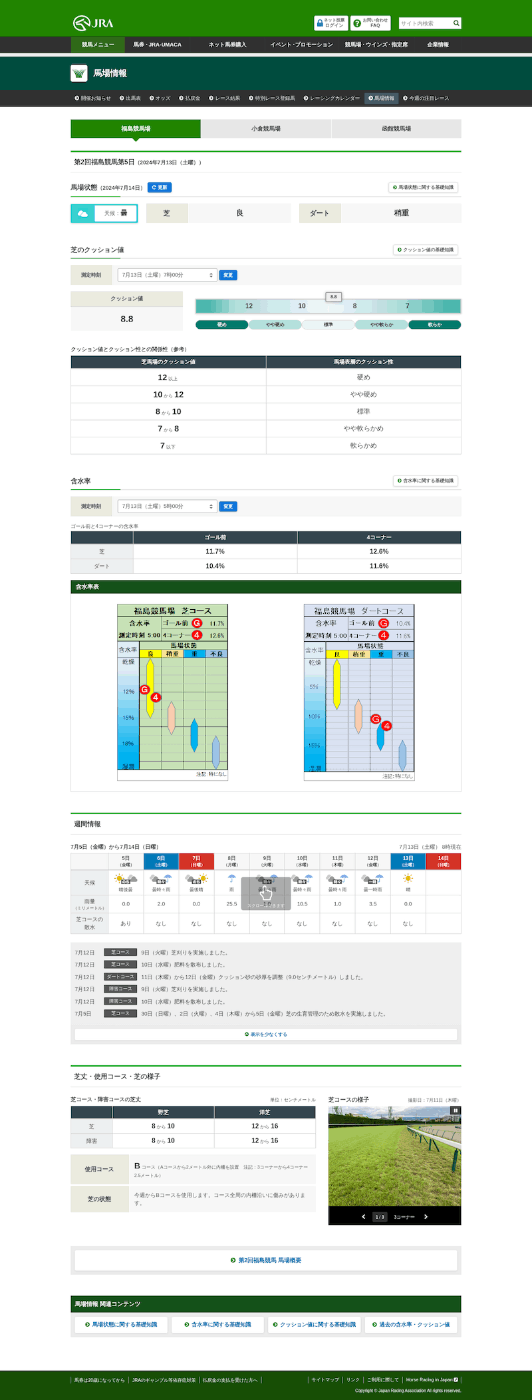
===== 福島競馬場 =====
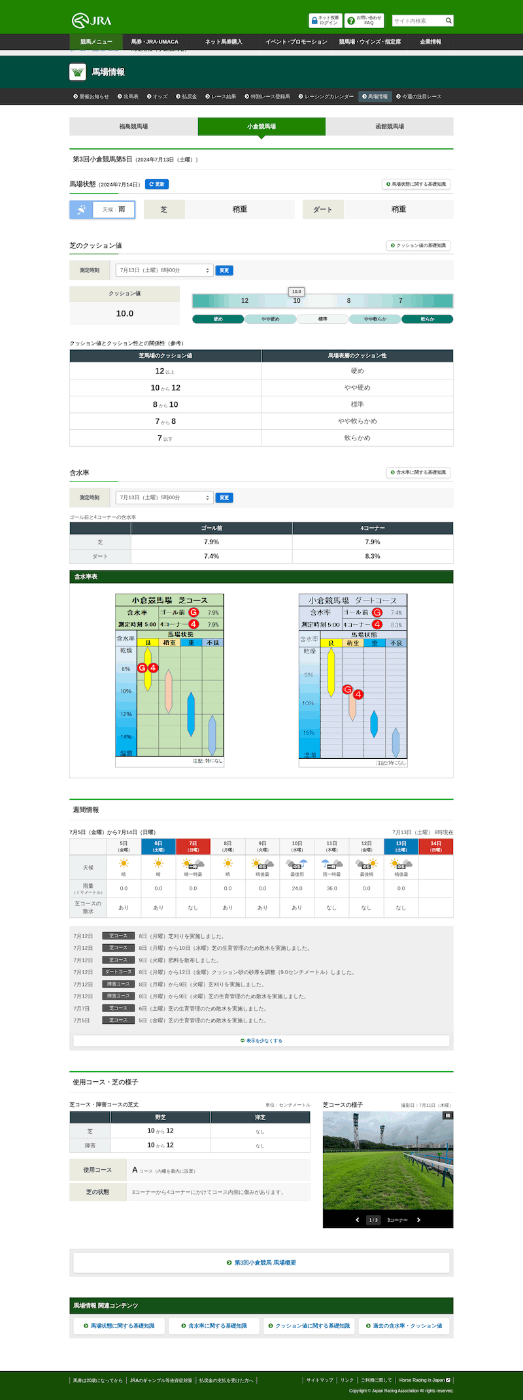
===== 小倉競馬場 =====
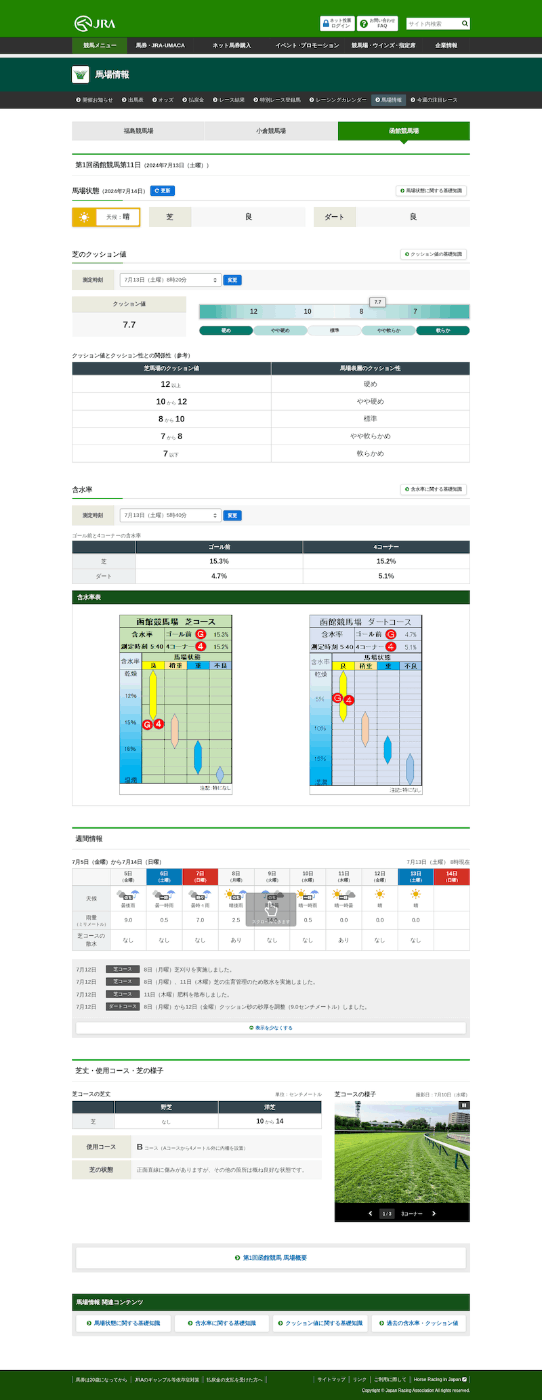
===== 函館競馬場 =====
{
"福島競馬場": {
"url": "https://www.jra.go.jp/keiba/baba/index.html",
"turf_cushon": {
"date": "7月13日(土曜)7時00分",
"cushon_value": "8.8"
},
"turf_moist_c4": {
"date": "7月13日(土曜)5時00分",
"moist_value": "12.6%"
},
"turf_moist_gm": {
"date": "7月13日(土曜)5時00分",
"moist_value": "11.7%"
},
"dirt_moist_c4": {
"date": "7月13日(土曜)5時00分",
"moist_value": "10.4%"
}
},
"小倉競馬場": {
"url": "https://www.jra.go.jp/keiba/baba/index2.html",
"turf_cushon": {
"date": "7月13日(土曜)8時00分",
"cushon_value": "10.0"
},
"turf_moist_c4": {
"date": "7月13日(土曜)5時00分",
"moist_value": "7.9%"
},
"turf_moist_gm": {
"date": "7月13日(土曜)5時00分",
"moist_value": "7.9%"
},
"dirt_moist_c4": {
"date": "7月13日(土曜)5時00分",
"moist_value": "7.4%"
}
},
"函館競馬場": {
"url": "https://www.jra.go.jp/keiba/baba/index3.html",
"turf_cushon": {
"date": "7月13日(土曜)8時20分",
"cushon_value": "7.7"
},
"turf_moist_c4": {
"date": "7月13日(土曜)5時40分",
"moist_value": "15.2%"
},
"turf_moist_gm": {
"date": "7月13日(土曜)5時40分",
"moist_value": "15.3%"
},
"dirt_moist_c4": {
"date": "7月13日(土曜)5時40分",
"moist_value": "4.7%"
}
}
}
キャプチャは以下の通り