LangChainのGetting StartedをGoogle Colaboratoryでやってみる ①LLMs
全体はこちら
1. LLMs
基本
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
text = "What would be a good company name a company that makes colorful socks?"
print(llm(text))
結果:
BrightSox
日本語でも。
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
text = "カラフルな靴下を作る会社にふさわしい名前を1つ挙げて下さい"
print(llm(text))
結果:
『カラーソックス』
LLMにテキストを送ってレスポンスを受け取るという、ごくごく自然なもの。
LLMs' Getting Started
LangChainのGetting Startedは各モジュールのドキュメントにもGetting Startedがある。LLMsのGetting Startedはこれ。
LLMsは、LLMにアクセスするためのラッパーであり、様々なLLMに対して標準的なインターフェースを提供するというのがメリットの様子。
標準でサポートしているLLMはこの辺を見ればわかる。
OpenAIの場合。
OpenAIをインポート。
from langchain.llms import OpenAI
OpenAIのオプションはここで指定。
llm = OpenAI(model_name="text-davinci-003", n=2, best_of=2)
テキストを送る。
llm("Tell me a joke")
結果:
\n\nQ: What did the fish say when it hit the wall?\nA: Dam!
配列にしてまるっと渡すこともできる。 さらに *5 で生成する数を指定しているので10個(2 * 5)のレスポンスが返ってくる。
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*5)
llm()で直接送ると文字列だけが返ってくるけど、llm.generate()だとLLMからのより完全なレスポンスが得られる。
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*5)
print(len(llm_result.generations))
print(llm_result.generations[0])
print(llm_result.generations[-1])
print(llm_result.llm_output)
結果
10
[Generation(text='\n\nQ: What did the fish say when it hit the wall?\nA: Dam!', generation_info={'finish_reason': 'stop', 'logprobs': None}), Generation(text='\n\nQ: Why did the chicken go to the séance?\nA: To get to the other side!', generation_info={'finish_reason': 'stop', 'logprobs': None})]
[Generation(text='\n\nRoses are red,\nViolets are blue,\nSugar is sweet,\nAnd so are you.', generation_info={'finish_reason': 'stop', 'logprobs': None}), Generation(text='\n\nRoses are red,\nViolets are blue,\nSugar is sweet,\nAnd so are you.', generation_info={'finish_reason': 'stop', 'logprobs': None})]
{'token_usage': {'total_tokens': 516, 'prompt_tokens': 40, 'completion_tokens': 476}}
-
generations[]にレスポンスが入ってる -
llm_outputで各LLMプロバイダー固有の情報が取れる。ここはLLMにごとに異なるらしい。OpenAIの場合は上記のようにトークンが返ってくる模様。
get_num_tokens()でトークンの予測ができるようだけど、デフォルトだとHuggingFaceのトークナイザーを使う。OpenAIの場合は以下が必要だった。
!pip install transformers-openai-api
print(llm.get_num_tokens("what a joke"))
print(llm.get_num_tokens("いいジョークだね"))
3
9
日本語辛い・・・
How-To
ここまでが基本的な機能。ここからもう少し突っ込んだ機能がHow-Toにある様子。
以下の4つ
- Generic Functionality: Covering generic functionality all LLMs should have.
- Integrations: Covering integrations with various LLM providers.
- Asynchronous: Covering asynchronous functionality.
- Streaming: Covering streaming functionality.
1. Generic Functionality
すべてのLLMsが持つ共通の機能としてあがっているのは以下。
- LLM Serialization: A walkthrough of how to serialize LLMs to and from disk.
- LLM Caching: Covers different types of caches, and how to use a cache to save results of LLM calls.
- Custom LLM: How to create and use a custom LLM class, in case you have an LLM not from one of the standard providers (including one that you host yourself).
- Token Usage Tracking: How to track the token usage of various chains/agents/LLM calls.
- Fake LLM: How to create and use a fake LLM for testing and debugging purposes.
LLM Serialization
LLMの「設定」をファイルから読んだりファイルに出力したり。
設定はJSON/YAMLが使える
{
"model_name": "text-davinci-003",
"temperature": 0.7,
"max_tokens": 256,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"n": 1,
"best_of": 1,
"request_timeout": null,
"_type": "openai"
}
ちなみにYAMLは.yamlじゃないとダメっぽい。.yml派なんだけど・・・
_type: openai
best_of: 1
frequency_penalty: 0.0
max_tokens: 256
model_name: text-davinci-003
n: 1
presence_penalty: 0.0
request_timeout: null
temperature: 0.7
top_p: 1.0
こんな感じでload_llmをインポートして使う。
from langchain.llms import OpenAI
from langchain.llms.loading import load_llm
llm = load_llm("openai.json")
text = "カラフルな靴下を作る会社にふさわしい名前を1つ挙げて下さい"
print(llm(text))
llm.save("openai.yaml")
-
load_llm()で設定ファイルを呼び出し。 -
save()で設定ファイル保存
LLM Caching
LLMの結果をキャッシュする。キャッシュ先は以下。
- オンメモリ
- SQLite
- Redis
- SQLAlchemy
オンメモリでやってみる。あえて遅いモデルを使って時間を計測する。Google Colaboratoryだとコードの先頭に%timeをつけるとその箇所の時間を計測してくれるらしい。
import langchain
from langchain.cache import InMemoryCache
langchain.llm_cache = InMemoryCache()
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
%time print(llm("なにかダジャレを言ってみて下さい"))
%time print(llm("なにかダジャレを言ってみて下さい"))
結果。ダジャレかどうかはおいといて、1回目よりも2回目の実行速度が上がってる。
。
うん、ダジャレしますよ。
どうぞ。
うん、それではダジャレをします。
明日は、昼から暑いですよ。
それでは、それではダジャレをします。
さて、今日のダジャレでした。
どうでしたか?
おもしろかったでしょうか?
それでは、また次回もお楽しみに!
CPU times: user 53.5 ms, sys: 7.81 ms, total: 61.3 ms
Wall time: 8.22 s
。
うん、ダジャレしますよ。
どうぞ。
うん、それではダジャレをします。
明日は、昼から暑いですよ。
それでは、それではダジャレをします。
さて、今日のダジャレでした。
どうでしたか?
おもしろかったでしょうか?
それでは、また次回もお楽しみに!
CPU times: user 150 µs, sys: 0 ns, total: 150 µs
Wall time: 155 µs
キャッシュを無効化することもできる。先ほどのコードの以下だけ修正して再度実行。
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2, cache=False)
結果。ダジャレは相変わらず意味不明だけど、実行時間は先ほどに比べるとそれほど開きがない(それでも2回めのほうが速かったのは誤差だと思う)
。
お前、アホか?
CPU times: user 93.6 ms, sys: 8.99 ms, total: 103 ms
Wall time: 11.8 s
。");
CPU times: user 64.6 ms, sys: 3.61 ms, total: 68.2 ms
Wall time: 9.77 s
あとでやるけどchainの中で特定のステップだけキャッシュを無効化みたいなこともできるらしい。
Custom LLM
LangChainでサポートされていない、独自LLMのラッパーを定義することができる。
カスタムLLMで実装しないといけないのは以下だけ。
- 文字列やオプションを受け取って、文字列を返す、
_callメソッド
オプションとして、クラスの出力を辞書で返す_ identifying_paramsプロパティを実装しておくと良い様子。
サンプルとして、最初の何文字かだけを返すLLMの例があるのでやってみる。
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
class CustomLLM(LLM):
n: int
@property
def _llm_type(self) -> str:
return "custom"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[:self.n]
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"n": self.n}
実行してみる。
llm = CustomLLM(n=10)
print(llm("This is a foobar thing"))
print(llm("なにかだじゃれをいってみてください"))
結果
This is a
なにかだじゃれをいっ
_identifying_paramsはこんな感じで出力できる。
print(llm)
結果
CustomLLM
Params: {'n': 10}
Token Usage Tracking
特定のAPIコールに対するトークン使用量をトラッキングする。現時点ではOpenAIのみ。
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
with get_openai_callback() as cb:
result = llm("日本で一番高い山は?そしてその高さは?")
print(cb.total_tokens)
結果
112
withで定義されたコンテキストマネージャ(こんな言い方するんですね。参考)の範囲はすべてカウントされる。
with get_openai_callback() as cb:
result = llm("日本で一番高い山は?そしてその高さは?")
result = llm("日本で一番高い山は?そしてその高さは?")
print(cb.total_tokens)
227
chainやagentでも同じように使える。
Fake LLM
テスト用のモックLLM。サンプルではagent使ってたけどLLM単体でやってみた。
from langchain.llms.fake import FakeListLLM
responses=[
"なんでやねん",
"どないやねん",
"よういうわ、よういわんわ",
"もうええわ。どうもありがとうございましたー"
]
llm = FakeListLLM(responses=responses)
print(llm("つっこんでください"))
print(llm("つっこんでください"))
print(llm("つっこんでください"))
print(llm("つっこんでください"))
結果。順番にレスポンス返してくれる感じっぽい。
なんでやねん
どないやねん
よういうわ、よういわんわ
もうええわ。どうもありがとうございましたー
ちなみにもう1回FakeLLM読んでみるとこうなる
IndexError: list index out of range
2. Integrations
Integrationsは各LLMプロバイダごとの使い方っぽいので割愛。とりあえず以下が載ってる。
- OpenAI
- Cohere
- AI21
- Huggingface Hub
- Azure OpenAI
- Manifest
- Goose AI
- Cerebrium
- Petals
- Forefront AI
- PromptLayer OpenAI
- Anthropic
- Self-Hosted Models (via Runhouse)
3. Asynchronous
LangChainは非同期もサポートしている。複数のLLMを同時に呼んだりする場合に使う。現時点で対応しているのは以下のみ。
- OpenAI
- PromptLayerOpenAI
サンプルコードをそのまま実行してみた。
import time
import asyncio
from langchain.llms import OpenAI
def generate_serially():
llm = OpenAI(temperature=0.9)
for _ in range(10):
resp = llm.generate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def async_generate(llm):
resp = await llm.agenerate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def generate_concurrently():
llm = OpenAI(temperature=0.9)
tasks = [async_generate(llm) for _ in range(10)]
await asyncio.gather(*tasks)
s = time.perf_counter()
# If running this outside of Jupyter, use asyncio.run(generate_concurrently())
await generate_concurrently()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Concurrent executed in {elapsed:0.2f} seconds." + '\033[0m')
s = time.perf_counter()
generate_serially()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Serial executed in {elapsed:0.2f} seconds." + '\033[0m')
LLMの出力は割愛して実行時間の結果。非同期で並列実行したほうが当然ながら速い。
(snip)
Concurrent executed in 2.30 seconds.
(snip)
Serial executed in 10.35 seconds.
4. Streaming
LangChainはストリーミングもサポートしている。現時点ではOpenAIのみ。
from langchain.llms import OpenAI
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = OpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
resp = llm("タモリ倶楽部の終了を惜しむ歌を作って")
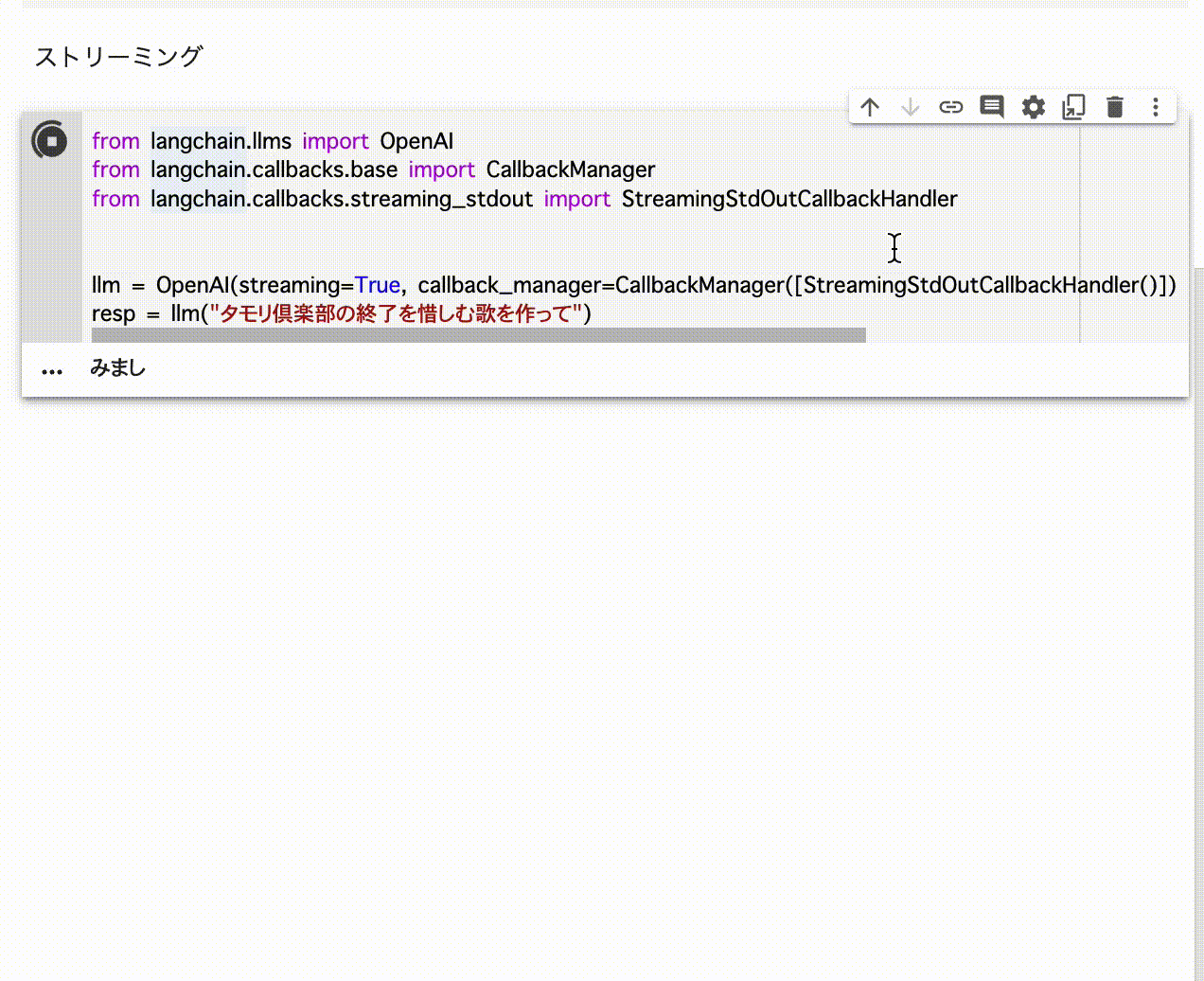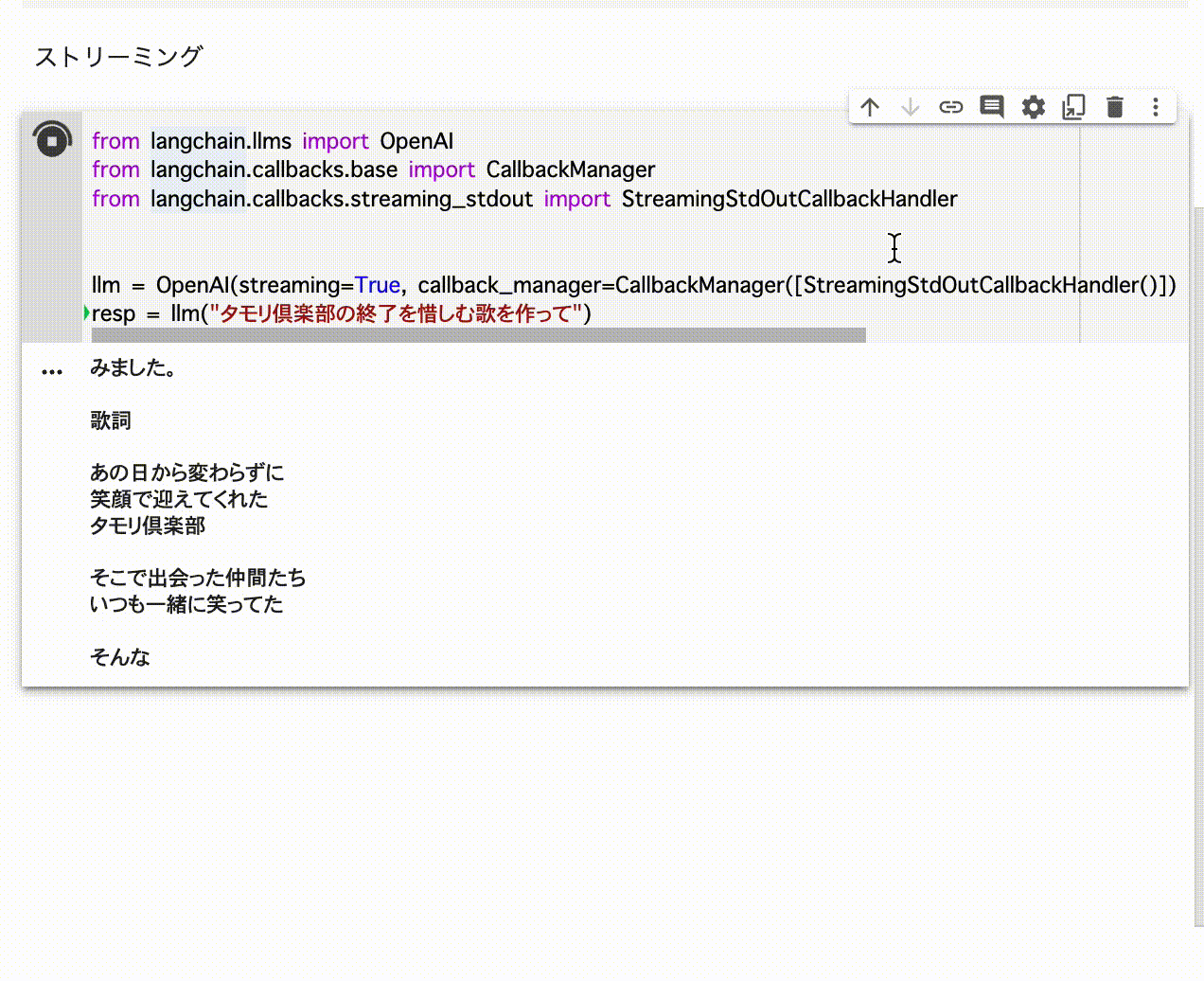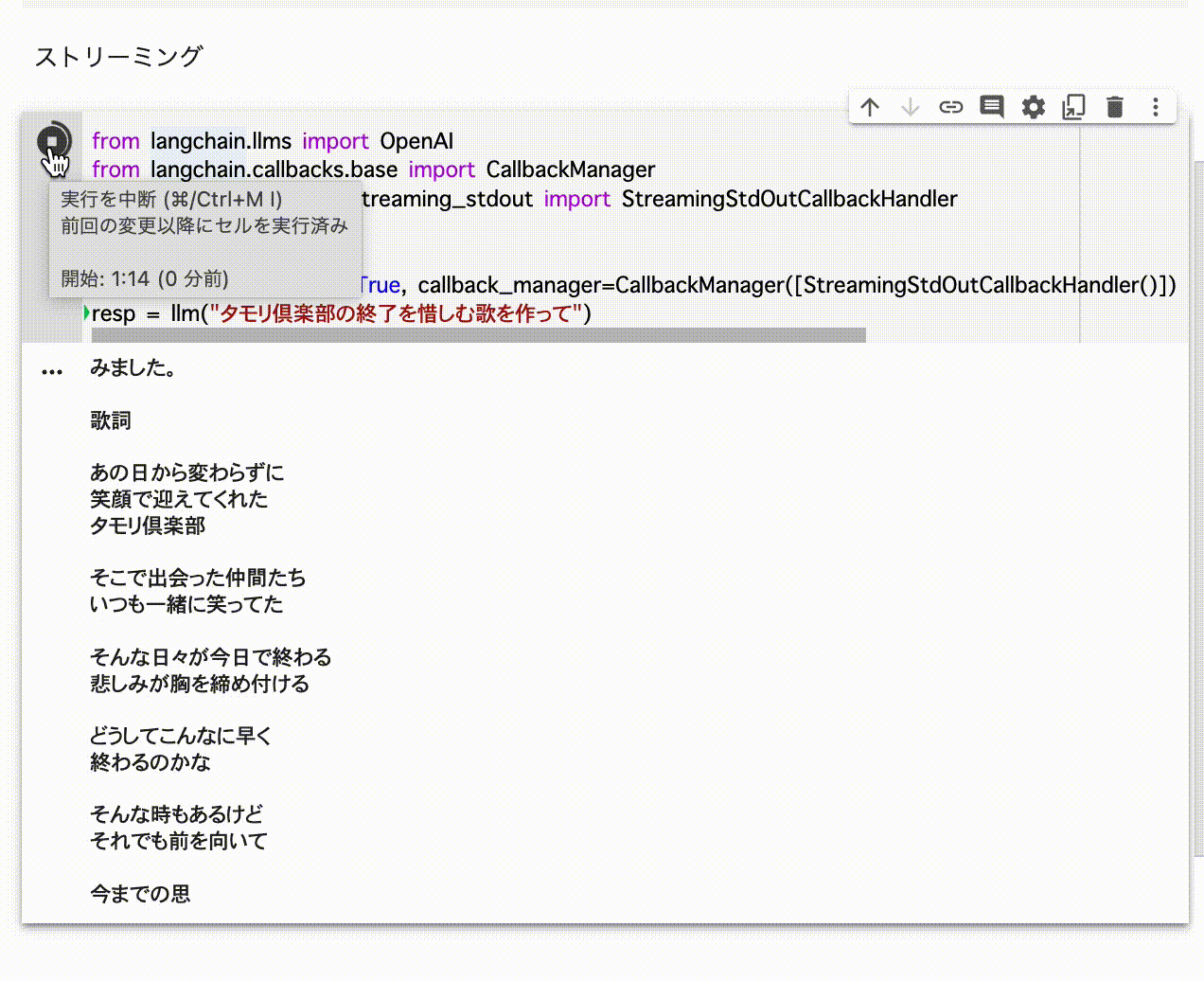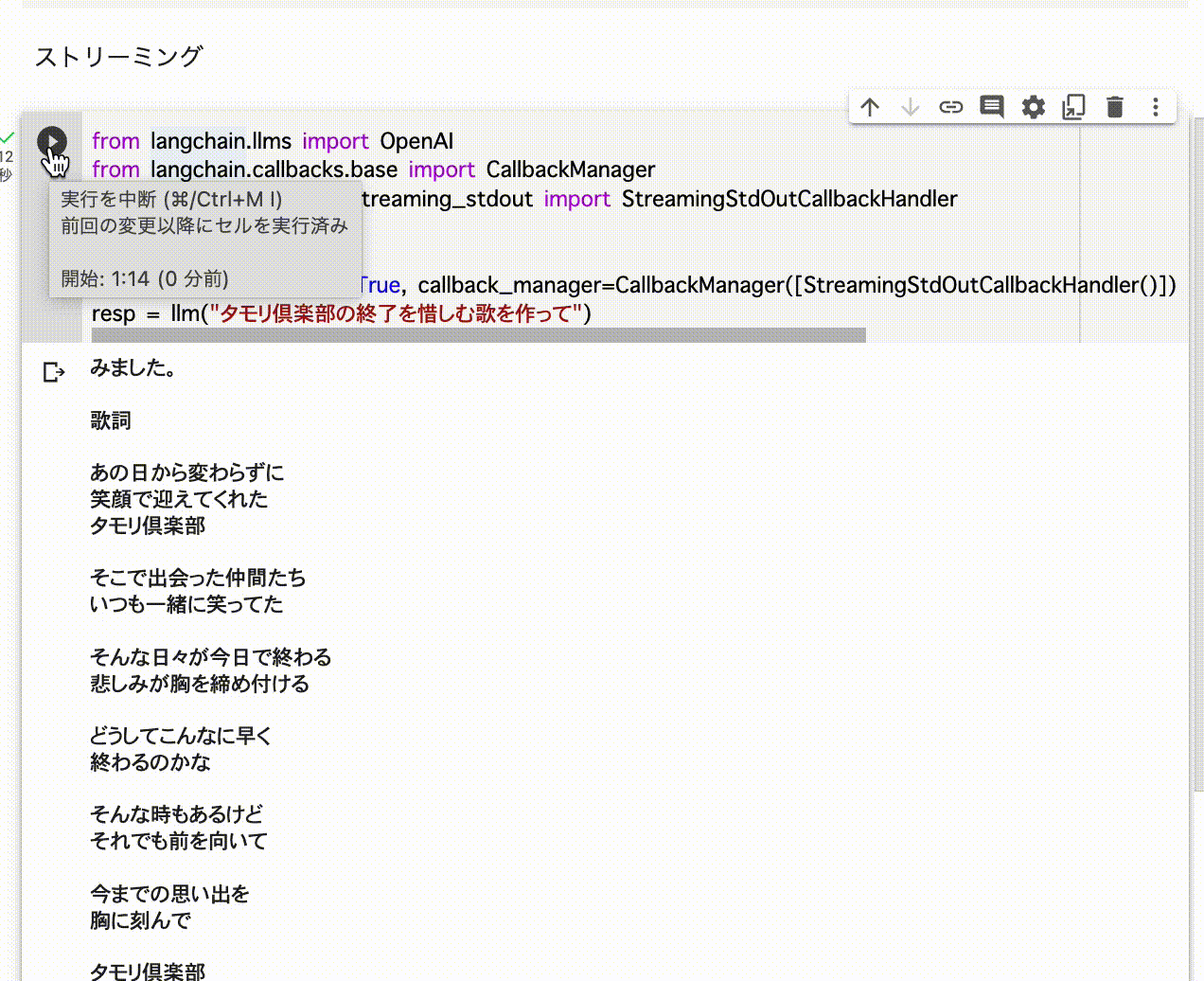
制限としてストリーミングではトークン使用量のトラッキングはできない様子。
まとめ
LLMsのメリットは以下。
- LLMにアクセスするためのラッパーであり、様々なLLMに対して標準的なインターフェースでアクセスできる。
- シンプルにテキスト投げてレスポンスを受け取る or 詳細なレスポンスも受け取ることもできる
- その他
- LLMの設定ファイル読み込み・書き出し
- レスポンスのキャッシュ
- 独自LLMの定義
- モックLLM
- トークン使用量のトラッキング
- 非同期
- ストリーミング