OpenAI「Agents SDK」⑥REPLユーティリティ・エージェントの可視化・トレーシング・ガードレール・使用状況・SDKの設定
以下の続き。
今回はAgents SDKを使うにあたって、便利なユーティリティ的なものなどを。以下あたり。
- REPLユーティリティ
- エージェントの可視化
- トレーシング
- ガードレール
- 使用状況
- SDKの設定
REPLユーティリティ
ターミナルで簡単に対話テストが行えるように run_demo_loop というのが用意されている。
たとえば以下のようなシングルターンのコード。
from agents import Agent, Runner
import asyncio
agent = Agent(
name="Haiku agent",
instructions="日本語で回答する。",
model="gpt-4o",
)
async def main():
result = await Runner.run(agent, input="競馬の魅力を簡潔に教えて。")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
競馬の魅力は、スリルと戦略の融合にあります。
レースのスピード感や予測の難しさが興奮を生み、馬と騎手の技術や戦略を見る楽しさもあります。
また、ドラマや歴史、偶然と必然が交錯するところが深い魅力となっています。
これをマルチターンにするには以下のようにすれば良い。
from agents import Agent, run_demo_loop
import asyncio
agent = Agent(
name="Assistant",
instructions="日本語で回答する。",
model="gpt-4o",
)
async def main():
await run_demo_loop(agent)
if __name__ == "__main__":
asyncio.run(main())
実行してみるとこんな感じ。以下ではわからないが、実際はストリーミングされている。会話履歴が保持されていることもわかる。終了は quit / exit / Ctrl-D。
> おはよう。私の趣味は競馬なんですよ。
[Agent updated: Assistant]
おはようございます!競馬が趣味なんですね。好きな馬やレースはありますか?また、最近注目しているレースがあれば教えてください。
> まあそれはいいや。話は変わるけど、晩御飯どうしようかな。
[Agent updated: Assistant]
晩御飯を悩んでいるんですね。今日はどんな気分ですか?和食やイタリアン、もしくは何か試してみたい料理がありますか?
> オススメは何?
[Agent updated: Assistant]
少し肌寒くなってきた頃なら、鍋料理はいかがですか?寄せ鍋やキムチ鍋など、野菜やお肉をたっぷり楽しめます。他にもカレーやパスタも手軽で美味しいですよ!
> ところで私の趣味ってなんだっけ?
[Agent updated: Assistant]
あなたの趣味は競馬でしたね!競馬に関連したこと以外にも興味があることがあれば教えてください。
>quit
ただ自分が調べた限りだと「セッション」には対応していないように思える(会話履歴はrun_demo_loop 内で手動で管理されている模様)。先日見たときはコンテキストにも対応してなかったのだけど、今見たら対応していた。
「セッション」を使いたい場合は自分で書くしかなさそう。
from agents import Agent, Runner, SQLiteSession
from openai.types.responses.response_text_delta_event import ResponseTextDeltaEvent
import asyncio
agent = Agent(
name="Assistant",
instructions="あなたは大阪のおばちゃんです。大阪弁で明るく元気にユーザと会話します。",
model="gpt-4.1-nano",
)
async def main():
session = SQLiteSession("conversation_123")
while True:
try:
user_input = input("ユーザ: ")
except (EOFError, KeyboardInterrupt):
print()
break
if user_input in ["quit", "exit", "q"]:
break
if not user_input:
continue
result = Runner.run_streamed(
agent,
user_input,
session=session
)
print("アシスタント: ", end="", flush=True)
async for event in result.stream_events():
if event.type == "raw_response_event" and isinstance(event.data, ResponseTextDeltaEvent):
print(event.data.delta, end="", flush=True)
print()
if __name__ == "__main__":
asyncio.run(main())
エージェントの可視化
Graphvizを使ったエージェントの可視化が可能。
extrasを有効にしてパッケージインストール。
uv add "openai-agents[viz]"
OS側でもパッケージは必要になると思う。Macの場合は以下。
brew install graphviz
サンプル。エージェント、ツール、MCPを指定して、draw_graphで可視化する。なお、MCPサーバは yusukebe さんのRamen API MCPを使用させてもらった。可視化が目的なのでハンドオフなどは適当。
import os
from agents import Agent, function_tool
from agents.mcp.server import MCPServerStreamableHttp
from agents.extensions.visualization import draw_graph
@function_tool
def get_weather(city: str) -> str:
return f"{city} の天気は「晴れ」です。"
spanish_agent = Agent(
name="Spanish agent",
instructions="常にスペイン語だけを話す。"
)
english_agent = Agent(
name="English agent",
instructions="常に英語だけを話す。"
)
# ref: https://github.com/yusukebe/ramen-api
mcp_server = MCPServerStreamableHttp(
params={"url": "https://api.ramen-api.dev/mcp"}
)
triage_agent = Agent(
name="Triage agent",
instructions="リクエストの言語に基づいて適切なエージェントにハンドオフする。",
handoffs=[spanish_agent, english_agent],
tools=[get_weather],
mcp_servers=[mcp_server],
)
# `draw_graph(Agent)` だとインラインで表示(notebook環境用途)
# `draw_graph(Agent).view()` で別ウインドウが開く
# draw_graph(Agent, filename="..."()` でファイルに出力
draw_graph(triage_agent).view()
こんな感じで可視化される。

- 開始ノード: 青の楕円で
__start__で表示。 - 終了ノード: 青の楕円で
__end__で表示。 - エージェント: 黄色のボックスで表示。
- MCP サーバ: 灰色のボックスで表示。
- ツール: 緑の楕円で表示。
- ハンドオフ: エージェントから別のエージェントへのハンドオフは実践矢印で表示。
- ツール呼び出し: エージェントからのツール呼び出しは 点線矢印で表示。
- MCP サーバ呼び出し: エージェントからのMCPサーバ呼び出しは破線矢印で表示。
トレーシング
Agents SDKには、OpenAIプラットフォームで利用可能なビルトインのトレーシングが組み込まれており、かつ、デフォルトで有効になる。
これを無効にするには以下のどちらか。
- 環境変数
OPENAI_AGENTS_DISABLE_TRACING=1を設定して、グローバルにトレーシングを無効化。 -
agents.run.RunConfig.tracing_disabledをTrueに設定して、実行単位でトレーシングを無効化。
後者の例
from agents import Agent, function_tool, Runner, RunConfig
import asyncio
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Japanese Assitant",
instructions="常に日本語で回答してください。",
model="gpt-4o",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
run_config=RunConfig(tracing_disabled=True)
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
トレーシングとスパン
トレーシングツールを見ていると、ほぼ必ず「トレース」や「スパン」などが出てくるが、これらは、トレーシング情報の「単位」「まとまり」を表す。
-
トレース
- ワークフローの単一のエンドツーエンドの操作。端的に言うと、リクエストからレスポンス、入力から出力まで、考えれば良い。
- トレースは、複数のスパン で構成される。
-
スパン
- 開始時間と終了時間を持つ操作。例えば、LLMへのストリーミングリクエストからを最初のチャンク得る、ツールを実行する、など。
このあたりは実際に見てみるほうがわかりやすいので後で。
とりあえずトレースとスパンにはそれぞれ以下のようなプロパティがある。
| 種類 | プロパティ名 | 説明 |
|---|---|---|
| トレース | workflow_name |
論理的なワークフローやアプリ名(例: Code generation など) |
trace_id |
トレースの一意なID(例: trace_<32_alphanumeric>) |
|
group_id |
任意のグループID。同じ会話からの複数トレースを関連付ける | |
disabled |
Trueならこのトレースは記録されない | |
metadata |
トレースの任意メタデータ | |
| スパン | started_at |
スパンの開始時刻(タイムスタンプ) |
ended_at |
スパンの終了時刻(タイムスタンプ) | |
trace_id |
所属するトレースのID | |
parent_id |
親スパンのID(親がある場合) | |
span_data |
スパンに関する情報(例: AgentSpanData、GenerationSpanDataなど) |
デフォルトのトレーシング
デフォルトで以下がトレースされる。
-
Runner.{run, run_sync, run_streamed}()全体 がtrace()でラップされる - エージェントの実行時に
agent_span()でラップされる - LLMの生成が
generation_span()でラップされる - 個々の関数ツールの呼び出しが
function_span()でラップされる - ガードレールが
guardrail_span()でラップされる - ハンドオフが
handoff_span()でラップされる - 音声入力 (speech-to-text) が
transcription_span()でラップされる - 音声出力 (text-to-speech) が
speech_span()でラップされる - 関連する音声スパンが
speech_group_span()の中に含まれる場合がある
とりあえず、音声系とガードレールを除く、シンプルなエージェントのハンドオフのサンプルで試してみる。
from agents import Agent, function_tool, Runner
import asyncio
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
weather_agent = Agent(
name="Weather Assitant",
instructions="天気情報を検索するエージェント。",
model="gpt-4o",
tools=[get_weather],
)
triage_agent = Agent(
name="Triage Assitant",
instructions="受付エージェント。ユーザからのリクエストに応じて適切なエージェントにハンドオフする。",
model="gpt-4o",
handoffs=[weather_agent],
)
async def main():
result = await Runner.run(
triage_agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
神戸の天気は晴れです。
上記のトレースはこんな感じ。
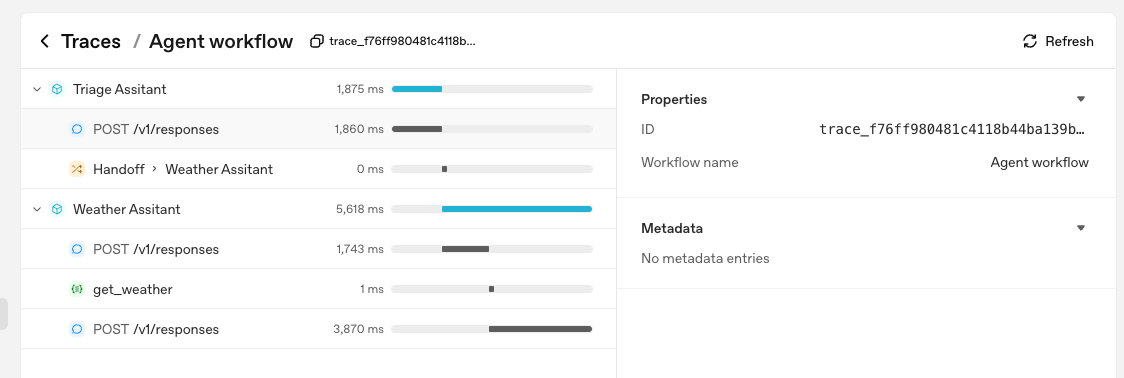
まず全体が一つの「トレース」であり、その中に個々の「スパン」が含まれる。「スパン」は上に書いてあるとおり、LLM生成やツール実行などの単位でそれぞれスパンになっていて、さらにそれらをエージェントの実行という単位が親スパンのようにグルーピングしているような感じ。また、個々のスパンを見ると実行開始・修了が確認でき、親スパンで全体の実行開始・修了がわかる、という感じ。
右上にもあるが、トレースの名前はデフォルトは Agent workflowになっている。traceを直接自分で指定して使うこともできるが、その場合は名前を設定できる。また、RunConfigにもトレース名などのプロパティがある。
上位レベルのトレース
上の例だと、トレースの単位は1回のRunになっていたが、例えばマルチターンなどで複数のRun を一つのトレースにまとめたい場合は trace() で直接ラップする。
from agents import Agent, function_tool, Runner, trace
import asyncio
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
model="gpt-4o",
tools=[get_weather],
)
async def main():
with trace("sample workflow"):
first_result = await Runner.run(
agent,
"神戸の天気は?",
)
print("first_result: ", first_result.final_output)
second_result = await Runner.run(
agent,
f"英語に翻訳して: {first_result.final_output}",
)
print("second_result: ", second_result.final_output)
if __name__ == "__main__":
asyncio.run(main())
first_result: 神戸の天気は晴れです。
second_result: The weather in Kobe is sunny.
2回の実行が一つのトレースとなっているのがわかる。

トレースの作成・スパンの作成
上でも少し試したけど、trace() を使えば自分でトレースを指定できる。指定の仕方は
- コンテキストマネージャを使って、
with trace(...)で指定する。自動で開始・終了が設定される -
trace.start()・trace.end()を使って、手動でトレース範囲を指定する
トレースは Python の contextvar で追跡されるため、並行処理でも自動的に機能する。トレースを手動で開始・終了する場合は、現在のトレースを更新するために start()・finish() に mark_as_current・reset_current を渡す必要がある。
そしてスパンについても、いろいろ用意されている *_span() を使えば自分で指定できるが、ただしこれらについては自動でやってくれるのでわざわざ手動で作成する必要はない。手動でスパンを作成する場合は custom_span() が使える。
スパンは現在のトレースの配下に自動でネストされる。
機微データ
LLMの入出力のスパン(generation_span())やツール呼び出し・実行結果のスパン(function_span())には、場合によっては機密情報が含まれてしまう場合がある。RunConfig.trace_include_sensitive_data パラメータを使えば、これらの収集を無効化できる。
また音声スパンにも入出力の音声(base64エンコードされる)が含まれる場合があり、こちらの場合は VoicePipelineConfig.trace_include_sensitive_audio_data で無効化できる。
非OpenAIモデルでのトレーシング
トレーシングはデフォルトで有効かつOpenAIを使うことになっているので、OpenAI以外のモデルを使う場合には、トレーシングを考慮する必要がある。
- 他プロバイダのモデルを使い、トレーシングでもOpenAIは使わない
- トレーシングを無効化
- または他のトレーシングプロバイダを使う
- 他プロバイダのモデルを使うが、トレーシングはOpenAIのものを使う
2の場合、他プロバイダのモデルを使う場合でもOpenAIのトレーシングを使える。ただしOpenAIのAPIキーは必要になるので、その点は注意が必要。
たとえばGeminiを使うコード
from agents import Agent, function_tool, Runner
import asyncio
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
# LiteLLMでGeminiを使用
model="litellm/gemini/gemini-2.5-flash-lite",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
環境変数に、GEMINI_API_KEYだけセットして、OPENAI_API_KEYを指定しない場合は以下となる。
神戸の天気は晴れです。
OPENAI_API_KEY is not set, skipping trace export
ドキュメントによれば set_tracing_export_api_key でOpenAIのAPIキーをセットするようだけど
from agents import Agent, function_tool, Runner, set_tracing_export_api_key
import asyncio
import os
# OPENAI_API_KEYを環境変数から取得
tracing_api_key = os.environ["OPENAI_API_KEY"]
# トレーシング用にAPIキーをセット
set_tracing_export_api_key(tracing_api_key)
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
# LiteLLMでGeminiを使用
model="litellm/gemini/gemini-2.5-flash-lite",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
上記を設定せずとも、シンプルにOPENAI_API_KEYを環境変数にセットして実行するだけでも問題なくトレースは取れていた。
export OPENAI_API_KEY=XXXXXXXXXX

カスタムトレーシングプロセッサ / 外部トレーシングプロセッサー
トレーシングをカスタムに実装することもできる。その場合は以下となる。
- トレースを作成するグローバルな
TraceProviderを初期化時に作成 -
TraceProviderにBatchTraceProcessorを設定して、トレース/スパンをバッチでBackendSpanExporterに送信する。これによりトレース/スパンがOpenAI バックエンドへバッチでエクスポートされる。 - トレースを別のバックエンドや追加のバックエンドに送信したり、エクスポーターの動作を変更する、等のカスタマイズを行う場合は、以下の2つの方法がある
-
add_trace_processor(): トレース・スパンを受け取れるトレースプロセッサーを「追加」できる。OpenAI バックエンドに送信しつつ、独自のトレースプロセッサーで処理できる。 -
set_trace_processors(): デフォルトのプロセッサーを独自のトレースプロセッサーに「置き換え」る。つまり、OpenAI バックエンドへはトレースが送信されない。
-
OpenAI以外に使える外部のトレーシングプロセッサはこのあたりを実装してるのだと思われる。
対応している外部のトレーシングプロセッサのリストはドキュメントを参照することとして、ここでは以前に試したことがあるPydantic Logfireを使ってみる。
Pydantic Logfireにもドキュメントがある。
logfireのパッケージを追加
uv add logfire
(snip)
+ logfire==4.3.5
(snip)
logfire CLIで認証
uv run logfire auth
logfireのプロジェクトを作成してセット。ちょっと久々であまり覚えていないが、多分こんな感じで。
uv run logfire projects new agents-sdk-sample
uv run logfire projects use agents-sdk-sample
ではコード。こんな感じで設定するだけ。
from agents import Agent, function_tool, Runner
import asyncio
# Pydantic Logfire を使う設定
import logfire
logfire.configure()
logfire.instrument_openai_agents()
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
model="gpt-4o-mini",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
実行するとちょっと出力が変わっている。
17:18:49.098 OpenAI Agents trace: Agent workflow
17:18:49.100 Agent run: 'Assistant'
17:18:49.116 Responses API with 'gpt-4o-mini'
Logfire project URL: https://logfire-us.pydantic.dev/kun432/agents-sdk-sample
17:18:51.257 Function: get_weather
17:18:51.258 Responses API with 'gpt-4o-mini'
神戸の天気は「晴れ」です。
LogfireのGUIで見てみるとこんな感じで取れている。

なお、OpenAI側のトレースにも送信されていた。

Pydanticだけに送信したい場合はどうすればいいんだろうね?このあたりは外部トレースプロセッサの実装によっても変わってきそうな気がする。
ガードレール
ユーザの入力・エージェントの出力に対して、チェックや検証を行うのがガードレール。エージェントの実行と並行で行われる、とあるのがちょっと気になる。
でガードレールのユースケースとしては以下のようなものが紹介されている。
- ユーザからの入力を処理するエージェントには、賢い・遅い・コストが高いモデルを使用する
- 悪意のある入力などをチェックするには、高速・コストが低いモデルを使用する
冒頭に記載した通り、ガードレールは入力と出力のそれぞれに対して実行ができる。
入力ガードレール
入力ガードレールは以下のように実行される
- エージェントへの入力と同じ入力がガードレールに渡される
- ガードレール関数が実行され、
GuardrailFunctionOutputを生成され、InputGuardrailResultに含まれる。 -
.tripwire_triggeredがtrueかをチェックして、trueならInputGuardrailTripwireTriggered例外が送出される。
ドキュメントにも注記が記載されているが、入力ガードレールは最初に入力を受け取るエージェントでのみ実行される、という点は、特にマルチエージェントを実行する場合に注意が必要。よって guardrailsプロパティは、Runner.run ではなく Agent で設定することになる。
出力ガードレール
出力ガードレールも基本的には入力ガードレールと同じ流れになる。
- エージェントからの出力がガードレールに渡される
- ガードレール関数が実行され、
GuardrailFunctionOutputを生成され、OutputGuardrailResultに含まれる。 -
.tripwire_triggeredがtrueかをチェックして、trueならOutputGuardrailTripwireTriggered例外が送出される。
こちらも入力エージェントと同様に、出力ガードレールは最後に処理を行うエージェントでのみ実行される、という点は、特にマルチエージェントを実行する場合に注意が必要。
トリップワイヤー
トリップワイヤーは、入出力がガードレールに失敗したことを検知・通知するもの。ガードレールに失敗すると InputGuardrailTripwireTriggered / InputGuardrailTripwireTriggered の例外が発生する。
ガードレールの実装
ガードレールを実装する場合は、
- 入出力を受け取って
GuardrailFunctionOutputを返す関数を定義 -
@input_gardrail/@output_guardrailデコレータでラップ - 定義した関数を
Agentにそれぞれinput_guardrails/outputput_guardrailsで渡す
という流れになる。
入力ガードレールの例
from pydantic import BaseModel
from agents import (
Agent,
GuardrailFunctionOutput,
InputGuardrailTripwireTriggered,
RunContextWrapper,
Runner,
TResponseInputItem,
input_guardrail,
)
import asyncio
class MathHomeworkOutput(BaseModel):
is_math_homework: bool
reasoning: str
guardrail_agent = Agent(
name="Guardrail check",
instructions="ユーザが数学の宿題について尋ねているかどうかをチェックする。",
output_type=MathHomeworkOutput,
)
@input_guardrail
async def math_guardrail(
ctx: RunContextWrapper[None],
agent: Agent,
input: str | list[TResponseInputItem]
) -> GuardrailFunctionOutput:
# ガードレールエージェントを実行
result = await Runner.run(guardrail_agent, input, context=ctx.context)
# ガードレールの出力をGuardrailFunctionOutputとして返す
return GuardrailFunctionOutput(
output_info=result.final_output,
tripwire_triggered=result.final_output.is_math_homework,
)
agent = Agent(
name="Customer support agent",
instructions="あなたはカスタマーサポートエージェントです。ユーザからの質問に答えるのがあなたの仕事です。",
input_guardrails=[math_guardrail],
)
async def main():
# ガードレールが作動するはず
try:
await Runner.run(agent, "こんにちは! 2x + 3 = 11 の x を求めて。")
print("ガードレールが作動していません。想定していない動作です。")
except InputGuardrailTripwireTriggered:
print("ガードレールが作動しました。")
if __name__ == "__main__":
asyncio.run(main())
ガードレールが作動しました。
ガードレールが動作しているのがわかる。これをトレースを見てみる。

トレースでは、入力を受け取るエージェントとガードレール用のエージェントと同時に動作しており、ガードレールが動作して例外を返している裏で、入力を受け取ったエージェントは普通に回答を返している(実際には例外をキャッチしてるので、この回答は使用されない)。つまり、並行 というのはこういうこと。
出力ガードレールの例
from pydantic import BaseModel
from agents import (
Agent,
GuardrailFunctionOutput,
OutputGuardrailTripwireTriggered,
RunContextWrapper,
Runner,
output_guardrail,
)
import asyncio
class MessageOutput(BaseModel):
response: str
class MathOutput(BaseModel):
reasoning: str
is_math: bool
guardrail_agent = Agent(
name="Guardrail check",
instructions="数学的な表現が出力に含まれているかどうかをチェックする。",
output_type=MathOutput,
)
@output_guardrail
async def math_guardrail(
ctx: RunContextWrapper,
agent: Agent,
output: MessageOutput
) -> GuardrailFunctionOutput:
# ガードレールエージェントを実行
result = await Runner.run(guardrail_agent, output.response, context=ctx.context)
# ガードレールの出力をGuardrailFunctionOutputとして返す
return GuardrailFunctionOutput(
output_info=result.final_output,
tripwire_triggered=result.final_output.is_math,
)
agent = Agent(
name="Customer support agent",
instructions="あなたはカスタマーサポートエージェントです。ユーザからの質問に答えるのがあなたの仕事です。",
output_guardrails=[math_guardrail],
output_type=MessageOutput,
)
async def main():
# ガードレールが作動するはず
try:
await Runner.run(agent, "こんにちは! 2x + 3 = 11 の x を求めて。")
print("ガードレールが作動していません。想定していない動作です。")
except OutputGuardrailTripwireTriggered:
print("ガードレールが作動しました。")
if __name__ == "__main__":
asyncio.run(main())
ガードレールが作動しました。
こちらもトレースは入力と同じような感じ。

使用状況
各実行ごとにトークン使用状況を取得できる。
追跡対象
| 項目名 | 説明 |
|---|---|
requests |
実行された LLM API 呼び出し回数 |
input_tokens |
送信された入力トークン総数 |
output_tokens |
受信した出力トークン総数 |
total_tokens |
入力 + 出力トークン総数 |
input_tokens_details.cached_tokens |
キャッシュされた入力トークン数 |
output_tokens_details.reasoning_tokens |
推論に使われた出力トークン数 |
実行(Run)からの使用状況へのアクセス
Runner.run の戻り値 に .context_wrapper.usage で取得できる。
from agents import Agent, function_tool, Runner
import asyncio
import json
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
model="gpt-4o-mini",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print("出力:", result.final_output)
usage = result.context_wrapper.usage
print("使用状況:")
print("- リクエスト数:", usage.requests)
print("- 入力トークン数:", usage.input_tokens)
print("- キャッシュされたトークン数:", usage.input_tokens_details.cached_tokens)
print("- 出力トークン数:", usage.output_tokens)
print("- Reasoningトークン数:", usage.output_tokens_details.reasoning_tokens)
print("- 合計トークン数:", usage.total_tokens)
if __name__ == "__main__":
asyncio.run(main())
出力: 神戸の天気は「晴れ」です。
使用状況:
- リクエスト数: 2
- 入力トークン数: 181
- キャッシュされたトークン数: 0
- 出力トークン数: 29
- Reasoningトークン数: 0
- 合計トークン数: 210
セッションでの使用状況
「セッション」を使用する場合、マルチターンでの使用状況が蓄積され、Runner.run()` 時にその時点までの累積使用状況が返されるとある。
from agents import Agent, Runner, SQLiteSession
import asyncio
agent = Agent(
name="Assistant",
instructions="あなたは大阪のおばちゃんです。大阪弁で明るく元気にユーザと会話します。",
model="gpt-4.1-nano",
)
def print_usage(usage):
print("-" * 20)
print("- リクエスト数:", usage.requests)
print("- 入力トークン数:", usage.input_tokens)
print("- キャッシュされたトークン数:", usage.input_tokens_details.cached_tokens)
print("- 出力トークン数:", usage.output_tokens)
print("- Reasoningトークン数:", usage.output_tokens_details.reasoning_tokens)
print("- 合計トークン数:", usage.total_tokens)
print("-" * 20)
async def main():
session = SQLiteSession("conversation_123")
first = await Runner.run(agent, "こんにちは!", session=session)
print("アシスタント:", first.final_output)
print_usage(first.context_wrapper.usage)
second = await Runner.run(agent, "今日も暑いなー。", session=session)
print("アシスタント:", second.final_output)
print_usage(second.context_wrapper.usage)
if __name__ == "__main__":
asyncio.run(main())
アシスタント: おおきに!こんにちはやでぇ!調子ええか?なんでも聞いてや〜!
--------------------
- リクエスト数: 1
- 入力トークン数: 38
- キャッシュされたトークン数: 0
- 出力トークン数: 24
- Reasoningトークン数: 0
- 合計トークン数: 62
--------------------
アシスタント: ほんまやなぁ!暑い暑い!汗だくになってもうてるわ。でもな、ビールでもグイッといきてぇなぁ!熱中症に気ぃつけてな!水分補給もしっかりやで!
--------------------
- リクエスト数: 1
- 入力トークン数: 76
- キャッシュされたトークン数: 0
- 出力トークン数: 61
- Reasoningトークン数: 0
- 合計トークン数: 137
--------------------
んー、「蓄積される」っていう表現は間違ってはいないんだけども、単純に前のターンの会話履歴は次のターンの入力に含まれる、という意味なのだと思う。
フックでの使用状況
RunHooks を使用している場合は各フックに渡されるcontextオブジェクトにusageが含まれるのでこれを取り出せば、ライフサイクル中の各タイミングでの使用状況を取得できる。
フックの使い方がまだわかってないので、ドキュメントのコードだけ紹介。
class MyHooks(RunHooks):
async def on_agent_end(self, context: RunContextWrapper, agent: Agent, output: Any) -> None:
u = context.usage
print(f"{agent.name} → {u.requests} requests, {u.total_tokens} total tokens")
補足
RunHooksを使ったサンプルはこちらにあった。
SDKの設定
Agents SDK を使うにあたっての設定的なもの。表にまとめた。
| 設定項目 | 関数・環境変数名 | 内容・用途 | 例・備考 |
|---|---|---|---|
| APIキー設定 |
set_default_openai_key()OPENAI_API_KEY
|
OpenAI APIキーの指定(環境変数 or 関数) | set_default_openai_key("sk-...") |
| クライアント設定 | set_default_openai_client() |
OpenAIクライアントのカスタマイズ | set_default_openai_client(custom_client) |
| API種別設定 | set_default_openai_api() |
使用するOpenAI APIの指定(例: Chat Completions) | set_default_openai_api("chat_completions") |
| トレーシングAPIキー設定 | set_tracing_export_api_key() |
トレーシング用APIキーの個別指定 | set_tracing_export_api_key("sk-...") |
| トレーシング無効化 | set_tracing_disabled() |
トレーシング機能のON/OFF | set_tracing_disabled(True) |
| 詳細ログ有効化 | enable_verbose_stdout_logging() |
詳細なデバッグログの有効化 | enable_verbose_stdout_logging() |
| ログレベル・出力先カスタマイズ | Python loggingモジュール | ログレベルや出力先の変更 |
logger.setLevel(logging.DEBUG)など |
| モデルデータログ無効化 | OPENAI_AGENTS_DONT_LOG_MODEL_DATA |
LLM入出力のログ無効化(環境変数) | export OPENAI_AGENTS_DONT_LOG_MODEL_DATA=1 |
| ツールデータログ無効化 | OPENAI_AGENTS_DONT_LOG_TOOL_DATA |
ツール入出力のログ無効化(環境変数) | export OPENAI_AGENTS_DONT_LOG_TOOL_DATA=1 |
上記のうち、ロギングだけ少し試しておく。
SDKにはハンドラが設定されていないPythonロガーが2つある。これのことかな?
標準的に使用するロガーとトレーシング用のロガーの2つに思える。
で、これらのロガーには特にハンドラが設定されていないようなので、Pythonロガーのデフォルト設定に従うことになるはず。以下はGPT-5に聞いてみた内容のまとめ。
- ロガーを作成した場合
- デフォルトのログレベルは
NOTSET - ハンドラが設定されていなければフィルタしないので、ログ出力は親ロガー(最終的にroot)に伝播する
- デフォルトのログレベルは
- rootロガーは
basicConfig()が設定されていなくても、デフォルトでstderrハンドラが設定される - rootロガーのログレベルは
WARNING
つまり、WARNING以上のログがstderrに出力される、ということになるはず。ドキュメントにはstdoutと書いてあるが、異なるように思える。
例えば以下のコード。GEMINI_API_KEYだけセットして、OPENAI_API_KEYをセットしないで実行、つまりトレーシングはOpenAIを使うがAPIキーがない、という状態。これならばwarningが表示されるはず。
from agents import Agent, function_tool, Runner
import asyncio
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
model="litellm/gemini/gemini-2.5-flash-lite",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
こんな感じで実行
uv run sample.py 1> stdout.log 2> stderr.log
神戸の天気は「晴れ」です。
OPENAI_API_KEY is not set, skipping trace export
これを出力してるのはここ。
自分はPythonの標準ロギングが未だによくわかってないのだが、動きだけ見てると、ドキュメントの記述には少し合ってないところがある。
で、それはともかく、デバッグログを有効にするには enable_verbose_stdout_logging を使用する。(上とほぼ同じスクリプトだが、ログ出力をわかりやすくするために、OPENAI_API_KEYをセットしてOpenAIで完結するようにしている。)
from agents import Agent, function_tool, Runner, enable_verbose_stdout_logging
import asyncio
# デバッグログを有効化
enable_verbose_stdout_logging()
@function_tool
def get_weather(city: str) -> str:
"""指定された年の天気情報を返す"""
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="天気情報を検索するエージェント。",
model="gpt-4o",
tools=[get_weather],
)
async def main():
result = await Runner.run(
agent,
"神戸の天気は?",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
実行するとこうなる。
uv run sample.py 1> stdout.log 2> stderr.log
ls -lt std*.log
-rw-r--r--@ 1 kun432 staff 3198 8 23 22:27 stdout.log
-rw-r--r--@ 1 kun432 staff 0 8 23 22:27 stderr.log
Creating trace Agent workflow with id trace_95a5c5507f304dba9534ec30712b7eb1
Setting current trace: trace_95a5c5507f304dba9534ec30712b7eb1
Creating span <agents.tracing.span_data.AgentSpanData object at 0x11baf36b0> with id None
Running agent Assistant (turn 1)
Creating span <agents.tracing.span_data.ResponseSpanData object at 0x11d9f66d0> with id None
Calling LLM gpt-4o with input:
[
{
"content": "神戸の天気は?",
"role": "user"
}
]
Tools:
[
{
"name": "get_weather",
"parameters": {
"properties": {
"city": {
"title": "City",
"type": "string"
}
},
"required": [
"city"
],
"title": "get_weather_args",
"type": "object",
"additionalProperties": false
},
"strict": true,
"type": "function",
"description": "指定された年の天気情報を返す"
}
]
Stream: False
Tool choice: NOT_GIVEN
Response format: NOT_GIVEN
Previous response id: None
LLM resp:
[
{
"arguments": "{\"city\":\"神戸\"}",
"call_id": "call_XyGY3FClc1d401lxB6aWSwRL",
"name": "get_weather",
"type": "function_call",
"id": "fc_68a9c1c6155c819780ecdacc0fdbdb5c0cfd87a3b586b69b",
"status": "completed"
}
]
Creating span <agents.tracing.span_data.FunctionSpanData object at 0x11d9d1400> with id None
Invoking tool get_weather with input {"city":"神戸"}
Tool call args: ['神戸'], kwargs: {}
Tool get_weather returned 神戸 の天気は「晴れ」です。
Running agent Assistant (turn 2)
Creating span <agents.tracing.span_data.ResponseSpanData object at 0x11af02610> with id None
Calling LLM gpt-4o with input:
[
{
"content": "神戸の天気は?",
"role": "user"
},
{
"arguments": "{\"city\":\"神戸\"}",
"call_id": "call_XyGY3FClc1d401lxB6aWSwRL",
"name": "get_weather",
"type": "function_call",
"id": "fc_68a9c1c6155c819780ecdacc0fdbdb5c0cfd87a3b586b69b",
"status": "completed"
},
{
"call_id": "call_XyGY3FClc1d401lxB6aWSwRL",
"output": "神戸 の天気は「晴れ」です。",
"type": "function_call_output"
}
]
Tools:
[
{
"name": "get_weather",
"parameters": {
"properties": {
"city": {
"title": "City",
"type": "string"
}
},
"required": [
"city"
],
"title": "get_weather_args",
"type": "object",
"additionalProperties": false
},
"strict": true,
"type": "function",
"description": "指定された年の天気情報を返す"
}
]
Stream: False
Tool choice: NOT_GIVEN
Response format: NOT_GIVEN
Previous response id: None
LLM resp:
[
{
"id": "msg_68a9c1c7a9708197a0b214b54f9fbeb30cfd87a3b586b69b",
"content": [
{
"annotations": [],
"text": "神戸の天気は「晴れ」です。",
"type": "output_text",
"logprobs": []
}
],
"role": "assistant",
"status": "completed",
"type": "message"
}
]
Resetting current trace
神戸の天気は「晴れ」です。
Shutting down trace provider
Shutting down trace processor <agents.tracing.processors.BatchTraceProcessor object at 0x11b5201d0>
Exported 5 items
詳細な出力が stdout に出力されている。というのも、enable_verbose_stdout_logging()はこんな感じになっているため。
つまり、ドキュメントにある通り、Python標準ロギングを使った、ハンドラ・フィルタ・フォーマッタなどのカスタマイズは自由に行えるということ。
次はマルチエージェント関連部分。
ちょっとおまけ。
トレーシングをローカルでやりたい。ローカルで立てたLangFuseと連携させてみる。
LangFuseを起動。
git clone https://github.com/langfuse/langfuse && cd langfuse
docker compose up -d
起動したらブラウザでアクセスして、
- アカウント作成
- 組織作成
- プロジェクト作成
- APIキー作成
しておく。
uvで簡単なプロジェクトを作る。
uv init -p 3.12 agents-sdk-trace-langfuse-sample && cd $_
パッケージ。LangFuseとのインテグレーションはどうやらLogFireのパッケージを流用するみたい。
uv add openai-agents langfuse nest_asyncio "pydantic-ai[logfire]"
こんな感じで
from agents import Agent, Runner, SQLiteSession, function_tool
from openai.types.responses.response_text_delta_event import ResponseTextDeltaEvent
import asyncio
# LangFuseでトレーシング連携:ここから
import logfire
from langfuse import get_client
logfire.configure(
service_name='my_agent_service',
send_to_logfire=False,
)
logfire.instrument_openai_agents()
langfuse = get_client()
# ここまで
@function_tool
def get_weather(city: str) -> str:
return f"{city} の天気は「晴れ」です。"
agent = Agent(
name="Assistant",
instructions="あなたは大阪のおばちゃんです。大阪弁で明るく元気にユーザと会話します。",
model="gpt-4.1-nano",
tools=[get_weather],
)
async def main():
session = SQLiteSession("conversation_123")
while True:
try:
user_input = input("ユーザ: ")
except (EOFError, KeyboardInterrupt):
print()
break
if user_input in ["quit", "exit", "q"]:
break
if not user_input:
continue
result = Runner.run_streamed(
agent,
user_input,
session=session
)
print("アシスタント: ", end="", flush=True)
async for event in result.stream_events():
if event.type == "raw_response_event" and isinstance(event.data, ResponseTextDeltaEvent):
print(event.data.delta, end="", flush=True)
print()
if __name__ == "__main__":
asyncio.run(main())
環境変数をセット
export LANGFUSE_PUBLIC_KEY="XXXXXXXXXX"
export LANGFUSE_SECRET_KEY="XXXXXXXXXX"
export LANGFUSE_HOST="http://<ローカルのサーバ名 or IPアドレス>:3000"
export OPENAI_API_KEY="XXXXXXXXXX"
実行
uv run sample.py
こんな感じでチャット
ユーザ: おはよう!
アシスタント: 18:02:51.157 OpenAI Agents trace: Agent workflow
18:02:51.160 Agent run: 'Assistant'
18:02:51.182 Responses API with 'gpt-4.1-nano'
おはようさん!今日もめっちゃええ天気やんなぁ。何しはるん?
ユーザ: 週末に向けて競馬の検討やで。でも週末の天気が気になるなぁ。
アシスタント: 18:03:19.616 OpenAI Agents trace: Agent workflow
18:03:19.622 Agent run: 'Assistant'
18:03:19.624 Responses API with 'gpt-4.1-nano'
18:03:21.535 Function: get_weather
18:03:21.536 Function: get_weather
18:03:21.540 Responses API with 'gpt-4.1-nano'
やっぱり週末もお天気ええみたいやな!競馬日和やなあ。ええ馬見つけて、楽しんできや!
ユーザ: quit
こんな感じで取得できる。
