音声合成・音声クローン・音声変換ができるTTSツール「Coqui TTS」を試す
GitHubレポジトリ
Coqui TTS
🐸TTSは高度なテキスト音声合成を実現するライブラリです。
🚀+1100言語に対応した事前学習済みモデル。
🛠️新しいモデルのトレーニングや既存モデルのファインチューニングを可能にするツール。
📚データセットの分析とキュレーション用ユーティリティ。🥇TTSのパフォーマンス
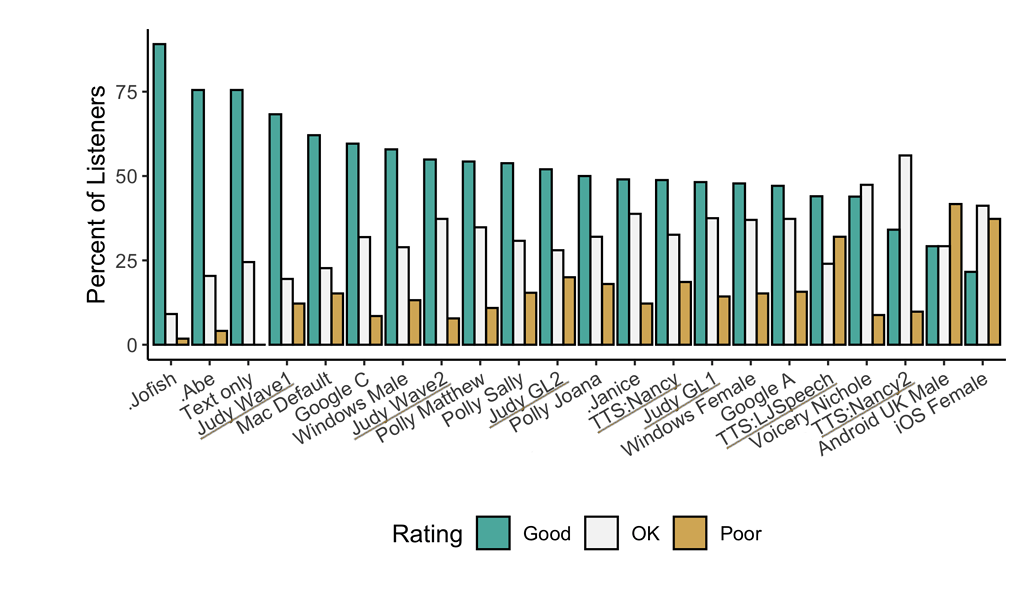
referred from https://github.com/coqui-ai/TTS下線が引かれている「TTS*」や「Judy*」は、🐸TTS内部の非公開モデルで、潜在的な性能を示しています。名前にドット(例:.Jofish .Abe .Janice)が付いたモデルは、実際の人間の声を表しています。
機能
- テキスト音声合成(Text-to-Speech)のための高性能ディープラーニングモデル。
- テキストからスペクトログラムを生成するモデル(Tacotron、Tacotron2、Glow-TTS、SpeedySpeechなど)。
- 効率的に話者埋め込みを計算するスピーカーエンコーダー。
- ボコーダーモデル(MelGAN、Multiband-MelGAN、GAN-TTS、ParallelWaveGAN、WaveGrad、WaveRNNなど)。
- 高速かつ効率的なモデルのトレーニング。
- ターミナルとTensorBoardでの詳細なトレーニングログ。
- マルチスピーカーTTSのサポート。
- 効率的で柔軟、かつ機能が充実した
Trainer API。- リリース済みで即使用可能なモデル。
dataset_analysisモジュール内で、テキスト音声合成(Text2Speech)用データセットを作成・整理するためのツールを提供- モデルの利用・テスト用ユーティリティ。
- モジュール化された(過剰ではない)コードベースで、新しいアイデアの簡単な実装が可能。
モデルの実装
スペクトログラムモデル
- Tacotron: 論文
- Tacotron2: 論文
- Glow-TTS: 論文
- Speedy-Speech: 論文
- Align-TTS: 論文
- FastPitch: 論文
- FastSpeech: 論文
- FastSpeech2: 論文
- SC-GlowTTS: 論文
- Capacitron: 論文
- OverFlow: 論文
- Neural HMM TTS: 論文
- Delightful TTS: 論文
エンドツーモデル
注意(Attention)手法
- Guided Attention: 論文
- Forward Backward Decoding: 論文
- Graves Attention: 論文
- Double Decoder Consistency: ブログ記事
- Dynamic Convolutional Attention: 論文
- Alignment Network: 論文
スピーカーエンコーダー
ボコーダー
- MelGAN: 論文
- MultiBandMelGAN: 論文
- ParallelWaveGAN: 論文
- GAN-TTS discriminators: 論文
- WaveRNN: 公式
- WaveGrad: 論文
- HiFiGAN: 論文
- UnivNet: 論文
音声変換
- FreeVC: 論文
他のモデルの実装に協力いただくことも可能です。
ライセンスはMPL-2.0
ドキュメントはこちら
チュートリアルに従って進める
インストール
インストールは以下の3つの方法がある
- Pythonパッケージ
- ソース
- Docker
Dockerが楽そうなのだけど、一旦Pythonパッケージで。あとでDockerも試してみる。
以下の環境で実施
- Ubuntu-22.04
- RTX4090
- Python-3.11.5
- Coqui TTSはPythonバージョン
>= 3.9, < 3.12の制約があるので注意
- Coqui TTSはPythonバージョン
作業ディレクトリ+Python仮想環境を作成。
mkdir coquitts-test && cd coquitts-test
python -m venv .venv
source .venv/bin/activate
パッケージインストール
pip install TTS
pip freeze | grep -i tts
TTS==0.22.0
TTS(CLI)
Coqui TTSを使ってTTSを行う方法は3つある。
- CLI(
tts) - サーバ(
tts-server) - Python API
まずはCLIで。
利用可能なモデルの一覧を表示。
tts --list_models
Name format: type/language/dataset/model
1: tts_models/multilingual/multi-dataset/xtts_v2
2: tts_models/multilingual/multi-dataset/xtts_v1.1
3: tts_models/multilingual/multi-dataset/your_tts
4: tts_models/multilingual/multi-dataset/bark
5: tts_models/bg/cv/vits
6: tts_models/cs/cv/vits
7: tts_models/da/cv/vits
8: tts_models/et/cv/vits
9: tts_models/ga/cv/vits
10: tts_models/en/ek1/tacotron2
11: tts_models/en/ljspeech/tacotron2-DDC
12: tts_models/en/ljspeech/tacotron2-DDC_ph
13: tts_models/en/ljspeech/glow-tts
14: tts_models/en/ljspeech/speedy-speech
15: tts_models/en/ljspeech/tacotron2-DCA
16: tts_models/en/ljspeech/vits
17: tts_models/en/ljspeech/vits--neon
18: tts_models/en/ljspeech/fast_pitch
19: tts_models/en/ljspeech/overflow
20: tts_models/en/ljspeech/neural_hmm
21: tts_models/en/vctk/vits
22: tts_models/en/vctk/fast_pitch
23: tts_models/en/sam/tacotron-DDC
24: tts_models/en/blizzard2013/capacitron-t2-c50
25: tts_models/en/blizzard2013/capacitron-t2-c150_v2
26: tts_models/en/multi-dataset/tortoise-v2
27: tts_models/en/jenny/jenny
28: tts_models/es/mai/tacotron2-DDC
29: tts_models/es/css10/vits
30: tts_models/fr/mai/tacotron2-DDC
31: tts_models/fr/css10/vits
32: tts_models/uk/mai/glow-tts
33: tts_models/uk/mai/vits
34: tts_models/zh-CN/baker/tacotron2-DDC-GST
35: tts_models/nl/mai/tacotron2-DDC
36: tts_models/nl/css10/vits
37: tts_models/de/thorsten/tacotron2-DCA
38: tts_models/de/thorsten/vits
39: tts_models/de/thorsten/tacotron2-DDC
40: tts_models/de/css10/vits-neon
41: tts_models/ja/kokoro/tacotron2-DDC
42: tts_models/tr/common-voice/glow-tts
43: tts_models/it/mai_female/glow-tts
44: tts_models/it/mai_female/vits
45: tts_models/it/mai_male/glow-tts
46: tts_models/it/mai_male/vits
47: tts_models/ewe/openbible/vits
48: tts_models/hau/openbible/vits
49: tts_models/lin/openbible/vits
50: tts_models/tw_akuapem/openbible/vits
51: tts_models/tw_asante/openbible/vits
52: tts_models/yor/openbible/vits
53: tts_models/hu/css10/vits
54: tts_models/el/cv/vits
55: tts_models/fi/css10/vits
56: tts_models/hr/cv/vits
57: tts_models/lt/cv/vits
58: tts_models/lv/cv/vits
59: tts_models/mt/cv/vits
60: tts_models/pl/mai_female/vits
61: tts_models/pt/cv/vits
62: tts_models/ro/cv/vits
63: tts_models/sk/cv/vits
64: tts_models/sl/cv/vits
65: tts_models/sv/cv/vits
66: tts_models/ca/custom/vits
67: tts_models/fa/custom/glow-tts
68: tts_models/bn/custom/vits-male
69: tts_models/bn/custom/vits-female
70: tts_models/be/common-voice/glow-tts
Name format: type/language/dataset/model
1: vocoder_models/universal/libri-tts/wavegrad
2: vocoder_models/universal/libri-tts/fullband-melgan
3: vocoder_models/en/ek1/wavegrad
4: vocoder_models/en/ljspeech/multiband-melgan
5: vocoder_models/en/ljspeech/hifigan_v2
6: vocoder_models/en/ljspeech/univnet
7: vocoder_models/en/blizzard2013/hifigan_v2
8: vocoder_models/en/vctk/hifigan_v2
9: vocoder_models/en/sam/hifigan_v2
10: vocoder_models/nl/mai/parallel-wavegan
11: vocoder_models/de/thorsten/wavegrad
12: vocoder_models/de/thorsten/fullband-melgan
13: vocoder_models/de/thorsten/hifigan_v1
14: vocoder_models/ja/kokoro/hifigan_v1
15: vocoder_models/uk/mai/multiband-melgan
16: vocoder_models/tr/common-voice/hifigan
17: vocoder_models/be/common-voice/hifigan
Name format: type/language/dataset/model
1: voice_conversion_models/multilingual/vctk/freevc24
色々表示されているが大まかにわけて3つのモデルタイプがある。
- TTSモデル
- ボコーダーモデル
- 音声変換モデル
TTSの通常のプロセスは以下となる。
- テキストを解析
- 単語や音素の単位に分解
- プロソディ(抑揚やイントネーション)を生成
- テキスト解析結果からメルスペクトログラムを生成
- メルスペクトログラムは音声の周波数スペクトル情報
- 音声そのものではなく、音声を表現した「中間表現」
- 中間表現を実際の音声波形(Waveform)に変換
1と2を行うのがTTSモデル(正しくはメルスペクトログラムを生成するスペクトログラムモデル)で、2がボコーダーモデルになる。Coqui TTSはそれぞれ複数のモデルが用意されており、これらを組み合わせて利用することができる。
TTSモデルの中には、1と2をセットで行うエンドツーエンドモデルや、複数スピーカー対応のマルチスピーカーモデルなども含まれる模様。
音声変換モデルというのは、話者変換や感情変換などの音声変換を行うためのモデルっぽい、まだちゃんとわかってないけど。
で、tts --list_modelsで表示されるモデルの出力は以下のルールで出力されているらしい
[モデルタイプ(tts_models/vocoder_models)]/[言語]/[データセット名]/[モデル名]
したがって、日本語で使う場合には以下辺りになるのではないかと思う。
1: tts_models/multilingual/multi-dataset/xtts_v2
2: tts_models/multilingual/multi-dataset/xtts_v1.1
3: tts_models/multilingual/multi-dataset/your_tts
4: tts_models/multilingual/multi-dataset/bark
41: tts_models/ja/kokoro/tacotron2-DDC
1: vocoder_models/universal/libri-tts/wavegrad
2: vocoder_models/universal/libri-tts/fullband-melgan
14: vocoder_models/ja/kokoro/hifigan_v1
もしかしたら他にもあるかもしれないが、一旦これで。
ではTTSさせてみる。TTSモデルだけの指定だとボコーダーはデフォルトになるらしいが、どれだろう・・・
tts --text "おはようございます。今日は良いお天気ですね。" \
--model_name "tts_models/multilingual/multi-dataset/xtts_v2" \
--out_path ./output.wav
む、ライセンスの承諾を求められる。。。
> You must confirm the following:
| > "I have purchased a commercial license from Coqui: licensing@coqui.ai"
| > "Otherwise, I agree to the terms of the non-commercial CPML: https://coqui.ai/cpml" - [y/n]
| | >
なるほど、どうやらモデルに対するライセンスは別で、どうやらこちらは非商用のみに限定されているようである。
一旦とめて他のモデルを選んでみた。
tts --text "おはようございます。今日は良いお天気ですね。" \
--model_name "tts_models/ja/kokoro/tacotron2-DDC" \
--out_path ./output.wav
モデルのダウンロードが始まった。どうやらtts_models/multilingual/multi-dataset/xtts_v2がCoquiのモデルのようである。
> Downloading model to /home/kun432/.local/share/tts/tts_models--ja--kokoro--tacotron2-DDC
88%|██████████████████████████████████████████████████████████████████████████████████████▌ | 508M/575M [00:55<00:06, 9.75MiB/s]
ダウンロードが終わると思いきや、エラー
ValueError: ❗ You need to install JA phonemizer dependencies. Try `pip install TTS[ja]`.
なんと、日本語はextrasの指定が必要な様子。ドキュメントを見てみると
If you are only interested in synthesizing speech with the released 🐸TTS models, installing from PyPI is the easiest option.
うーん、そういう意味か。読み取れなかった。
ってことでインストール。
pip install TTS[ja]
再度先ほどのコマンドを実行。
tts --text "おはようございます。今日は良いお天気ですね。" \
--model_name "tts_models/ja/kokoro/tacotron2-DDC" \
--out_path ./output.wav
今度はいけたみたい。ボコーダーモデルは、TTSモデルにあわせて選択されるのか、言語に合わせて選択されるのか、はわからないが、今回は日本語のモデルが自動で選ばれている様子。
> tts_models/ja/kokoro/tacotron2-DDC is already downloaded.
> vocoder_models/ja/kokoro/hifigan_v1 is already downloaded.
(snip)
> Generator Model: hifigan_generator
> Discriminator Model: hifigan_discriminator
Removing weight norm...
> Text: おはようございます。今日は良いお天気ですね。
> Text splitted to sentences.
['おはようございます。', '今日は良いお天気ですね。']
> Processing time: 0.4904897212982178
> Real-time factor: 0.12170618422112106
> Saving output to ./output.wav
WAVファイルが生成されている。こんな感じ。ちょっとノイジーかな。
上でライセンス承諾を求められたモデルも含めて、他のモデルを使ってみる。
TTSモデルには
- シングルスピーカーモデル(モデルが使用できる音声が1種類)とマルチスピーカーモデル(モデルが使用できる音声が複数種類)
- 特定言語向けモデルとマルチリンガルモデル
という違いがあり、これらによってオプションが異なる様子。
シングルスピーカーモデルは、先程試した tts_models/ja/kokoro/tacotron2-DDC が日本語対応だが、tts_models/multilingual/multi-dataset/xtts_v1.1 もシングルスピーカーに対応している様子、ただしこちらはマルチリンガルモデル。
マルチリンガルモデルの場合は言語インデックスを指定する必要がある。言語インデックスを確認。
tts --model_name "tts_models/multilingual/multi-dataset/xtts_v1.1" --list_language_idxs
> Available language ids: (Set --language_idx flag to one of these values to use the multi-lingual model.
['en', 'es', 'fr', 'de', 'it', 'pt', 'pl', 'tr', 'ru', 'nl', 'cs', 'ar', 'zh-cn', 'ja']
言語インデックスを指定して実行。
tts --text "おはようございます。今日は良いお天気ですね。" \
--model_name "tts_models/multilingual/multi-dataset/xtts_v1.1" \
--language_idx "ja" \
--out_path ./output2.wav
が、エラー・・・ちょっと良くわからない
TypeError: expected str, bytes or os.PathLike object, not NoneType
マルチスピーカーモデルの場合はスピーカーインデックスを指定する必要がある。
tts --model_name "tts_models/multilingual/multi-dataset/xtts_v2" --list_speaker_idxs
> Available speaker ids: (Set --speaker_idx flag to one of these values to use the multi-speaker model.
dict_keys(['Claribel Dervla', 'Daisy Studious', 'Gracie Wise', 'Tammie Ema', 'Alison Dietlinde', 'Ana Florence', 'Annmarie Nele', 'Asya Anara', 'Brenda Stern', 'Gitta Nikolina', 'Henriette Usha', 'Sofia Hellen', 'Tammy Grit', 'Tanja Adelina', 'Vjollca Johnnie', 'Andrew Chipper', 'Badr Odhiambo', 'Dionisio Schuyler', 'Royston Min', 'Viktor Eka', 'Abrahan Mack', 'Adde Michal', 'Baldur Sanjin', 'Craig Gutsy', 'Damien Black', 'Gilberto Mathias', 'Ilkin Urbano', 'Kazuhiko Atallah', 'Ludvig Milivoj', 'Suad Qasim', 'Torcull Diarmuid', 'Viktor Menelaos', 'Zacharie Aimilios', 'Nova Hogarth', 'Maja Ruoho', 'Uta Obando', 'Lidiya Szekeres', 'Chandra MacFarland', 'Szofi Granger', 'Camilla Holmström', 'Lilya Stainthorpe', 'Zofija Kendrick', 'Narelle Moon', 'Barbora MacLean', 'Alexandra Hisakawa', 'Alma María', 'Rosemary Okafor', 'Ige Behringer', 'Filip Traverse', 'Damjan Chapman', 'Wulf Carlevaro', 'Aaron Dreschner', 'Kumar Dahl', 'Eugenio Mataracı', 'Ferran Simen', 'Xavier Hayasaka', 'Luis Moray', 'Marcos Rudaski'])
スピーカーインデックスを指定して実行。今回は適当に"Claribel Dervla"を選択。なお、言語インデックスも指定する必要がある。
tts --text "おはようございます。今日は良いお天気ですね。" \
--model_name "tts_models/multilingual/multi-dataset/xtts_v2" \
--out_path ./output2.wav \
--speaker_idx "Claribel Dervla" \
--language_idx "ja"
できたっぽい。
['おはようございます。', '今日は良いお天気ですね。']
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
> Processing time: 3.599776029586792
> Real-time factor: 0.8609755884717628
> Saving output to ./output2.wav
生成された音声はこんな感じ。日本語専用のものよりもいい感じに思える。
CLIのusageは以下。
tts --help
usage: tts [-h] [--list_models [LIST_MODELS]] [--model_info_by_idx MODEL_INFO_BY_IDX] [--model_info_by_name MODEL_INFO_BY_NAME]
[--text TEXT] [--model_name MODEL_NAME] [--vocoder_name VOCODER_NAME] [--config_path CONFIG_PATH] [--model_path MODEL_PATH]
[--out_path OUT_PATH] [--use_cuda USE_CUDA] [--device DEVICE] [--vocoder_path VOCODER_PATH]
[--vocoder_config_path VOCODER_CONFIG_PATH] [--encoder_path ENCODER_PATH] [--encoder_config_path ENCODER_CONFIG_PATH]
[--pipe_out [PIPE_OUT]] [--speakers_file_path SPEAKERS_FILE_PATH] [--language_ids_file_path LANGUAGE_IDS_FILE_PATH]
[--speaker_idx SPEAKER_IDX] [--language_idx LANGUAGE_IDX] [--speaker_wav SPEAKER_WAV [SPEAKER_WAV ...]]
[--gst_style GST_STYLE] [--capacitron_style_wav CAPACITRON_STYLE_WAV] [--capacitron_style_text CAPACITRON_STYLE_TEXT]
[--list_speaker_idxs [LIST_SPEAKER_IDXS]] [--list_language_idxs [LIST_LANGUAGE_IDXS]] [--save_spectogram SAVE_SPECTOGRAM]
[--reference_wav REFERENCE_WAV] [--reference_speaker_idx REFERENCE_SPEAKER_IDX] [--progress_bar PROGRESS_BAR]
[--source_wav SOURCE_WAV] [--target_wav TARGET_WAV] [--voice_dir VOICE_DIR]
Synthesize speech on command line.
You can either use your trained model or choose a model from the provided list.
If you don't specify any models, then it uses LJSpeech based English model.
#### Single Speaker Models
- List provided models:
```
$ tts --list_models
```
- Get model info (for both tts_models and vocoder_models):
- Query by type/name:
The model_info_by_name uses the name as it from the --list_models.
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"
For example:
$ tts --model_info_by_name tts_models/tr/common-voice/glow-tts
$ tts --model_info_by_name vocoder_models/en/ljspeech/hifigan_v2
- Query by type/idx:
The model_query_idx uses the corresponding idx from --list_models.
$ tts --model_info_by_idx "<model_type>/<model_query_idx>"
For example:
$ tts --model_info_by_idx tts_models/3
- Query info for model info by full name:
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"
- Run TTS with default models:
```
$ tts --text "Text for TTS" --out_path output/path/speech.wav
```
- Run TTS and pipe out the generated TTS wav file data:
```
$ tts --text "Text for TTS" --pipe_out --out_path output/path/speech.wav | aplay
```
- Run a TTS model with its default vocoder model:
```
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wav
```
For example:
```
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --out_path output/path/speech.wav
```
- Run with specific TTS and vocoder models from the list:
```
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --vocoder_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wav
```
For example:
```
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --vocoder_name "vocoder_models/en/ljspeech/univnet" --out_path output/path/speech.wav
```
- Run your own TTS model (Using Griffin-Lim Vocoder):
```
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav
```
- Run your own TTS and Vocoder models:
```
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav
--vocoder_path path/to/vocoder.pth --vocoder_config_path path/to/vocoder_config.json
```
#### Multi-speaker Models
- List the available speakers and choose a <speaker_id> among them:
```
$ tts --model_name "<language>/<dataset>/<model_name>" --list_speaker_idxs
```
- Run the multi-speaker TTS model with the target speaker ID:
```
$ tts --text "Text for TTS." --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --speaker_idx <speaker_id>
```
- Run your own multi-speaker TTS model:
```
$ tts --text "Text for TTS" --out_path output/path/speech.wav --model_path path/to/model.pth --config_path path/to/config.json --speakers_file_path path/to/speaker.json --speaker_idx <speaker_id>
```
### Voice Conversion Models
```
$ tts --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --source_wav <path/to/speaker/wav> --target_wav <path/to/reference/wav>
```
options:
-h, --help show this help message and exit
--list_models [LIST_MODELS]
list available pre-trained TTS and vocoder models.
--model_info_by_idx MODEL_INFO_BY_IDX
model info using query format: <model_type>/<model_query_idx>
--model_info_by_name MODEL_INFO_BY_NAME
model info using query format: <model_type>/<language>/<dataset>/<model_name>
--text TEXT Text to generate speech.
--model_name MODEL_NAME
Name of one of the pre-trained TTS models in format <language>/<dataset>/<model_name>
--vocoder_name VOCODER_NAME
Name of one of the pre-trained vocoder models in format <language>/<dataset>/<model_name>
--config_path CONFIG_PATH
Path to model config file.
--model_path MODEL_PATH
Path to model file.
--out_path OUT_PATH Output wav file path.
--use_cuda USE_CUDA Run model on CUDA.
--device DEVICE Device to run model on.
--vocoder_path VOCODER_PATH
Path to vocoder model file. If it is not defined, model uses GL as vocoder. Please make sure that you installed vocoder library before (WaveRNN).
--vocoder_config_path VOCODER_CONFIG_PATH
Path to vocoder model config file.
--encoder_path ENCODER_PATH
Path to speaker encoder model file.
--encoder_config_path ENCODER_CONFIG_PATH
Path to speaker encoder config file.
--pipe_out [PIPE_OUT]
stdout the generated TTS wav file for shell pipe.
--speakers_file_path SPEAKERS_FILE_PATH
JSON file for multi-speaker model.
--language_ids_file_path LANGUAGE_IDS_FILE_PATH
JSON file for multi-lingual model.
--speaker_idx SPEAKER_IDX
Target speaker ID for a multi-speaker TTS model.
--language_idx LANGUAGE_IDX
Target language ID for a multi-lingual TTS model.
--speaker_wav SPEAKER_WAV [SPEAKER_WAV ...]
wav file(s) to condition a multi-speaker TTS model with a Speaker Encoder. You can give multiple file paths. The d_vectors is computed as their average.
--gst_style GST_STYLE
Wav path file for GST style reference.
--capacitron_style_wav CAPACITRON_STYLE_WAV
Wav path file for Capacitron prosody reference.
--capacitron_style_text CAPACITRON_STYLE_TEXT
Transcription of the reference.
--list_speaker_idxs [LIST_SPEAKER_IDXS]
List available speaker ids for the defined multi-speaker model.
--list_language_idxs [LIST_LANGUAGE_IDXS]
List available language ids for the defined multi-lingual model.
--save_spectogram SAVE_SPECTOGRAM
If true save raw spectogram for further (vocoder) processing in out_path.
--reference_wav REFERENCE_WAV
Reference wav file to convert in the voice of the speaker_idx or speaker_wav
--reference_speaker_idx REFERENCE_SPEAKER_IDX
speaker ID of the reference_wav speaker (If not provided the embedding will be computed using the Speaker Encoder).
--progress_bar PROGRESS_BAR
If true shows a progress bar for the model download. Defaults to True
--source_wav SOURCE_WAV
Original audio file to convert in the voice of the target_wav
--target_wav TARGET_WAV
Target audio file to convert in the voice of the source_wav
--voice_dir VOICE_DIR
Voice dir for tortoise model
TTS(サーバ)
GUIで生成できるWebサーバも用意されている。一応デモとあるので、シンプルに試すだけのものだと思う。
基本的にはCLIと同じようにモデルなどを指定して起動すれば良いみたい。
tts-server --model_name "tts_models/ja/kokoro/tacotron2-DDC"
WebサーバはFlaskで書かれているみたい。
Removing weight norm...
* Serving Flask app 'TTS.server.server'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (::)
* Running on http://[::1]:5002
* Running on http://[XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX]:5002
Press CTRL+C to quit
5002番ポートにアクセスするとシンプルなフォームが表示されるので、テキストを入力して、TTSさせるだけ。

Python TTS API
Pythonからも使える。
日本語・シングルスピーカーモデルの場合。
import torch
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
tts = TTS(model_name="tts_models/ja/kokoro/tacotron2-DDC").to(device)
# WAVオブジェクトを生成する場合
#wav = tts.tts(text="こんにちは!今日はいいお天気ですね!")
# WAVファイルに出力する場合
tts.tts_to_file(text="こんにちは!今日はいいお天気ですね!", file_path="output_python.wav")
python sample.py
(snip)
['こんにちは!', '今日はいいお天気ですね!']
> Processing time: 0.17624568939208984
> Real-time factor: 0.03871351461483485
WAVファイルが生成される。CLIで試したものとほぼ同じ(多少は異なる様子)なので内容は割愛。
マルチリンガル・マルチスピーカーモデルの場合
import torch
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
tts = TTS(model_name="tts_models/multilingual/multi-dataset/xtts_v2").to(device)
# WAVオブジェクトを生成する場合
#wav = tts.tts(
# text="こんにちは!今日はいいお天気ですね!",
# language="ja",
# speaker="Claribel Dervla",
#)
# WAVファイルに出力する場合
tts.tts_to_file(
text="こんにちは!今日はいいお天気ですね!",
language="ja",
speaker="Claribel Dervla",
file_path="output_python2.wav",
)
また、CLIのときは試してなかったけど、TTSモデルの中には音声クローンに対応しているモデルもある。音声クローンを使う場合はベースとなる音声をspeaker_wavで指定する。
import torch
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
tts = TTS(model_name="tts_models/multilingual/multi-dataset/xtts_v2").to(device)
tts.tts_to_file(
text="こんにちは!今日はいいお天気ですね!",
language="ja",
speaker_wav="my_voice.wav",
file_path="output_clone.wav",
)
ベースの音声
ベースの音声を使って生成した音声
言語を変えてみる。
import torch
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
tts = TTS(model_name="tts_models/multilingual/multi-dataset/xtts_v2").to(device)
tts.tts_to_file(
text="This is voice cloning",
language="en",
speaker_wav="my_voice.wav",
file_path="output_clone_en.wav",
)
tts.tts_to_file(
text="C'est le clonage de la voix.",
language="fr",
speaker_wav="my_voice.wav",
file_path="output_clone_fr.wav",
)
tts.tts_to_file(
text="Isso é clonagem de voz.",
language="pt",
speaker_wav="my_voice.wav",
file_path="output_clone_pt.wav",
)
それぞれこんな感じ
あと、これもCLIでは試してないけど、音声変換モデルを使うと、ベースとなる音声データの音声を使って、別の音声データの音声を変換する、ということもできるみたい。適当な例が思いつかなかったので、実行していないけどこんな感じっぽい。
import torch
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
tts = TTS(model_name="voice_conversion_models/multilingual/vctk/freevc24").to(device)
tts.voice_conversion_to_file(
source_wav="my_voice.wav",
target_wav="somebody_voice.wav",
file_path="me_talk_like_somebody.wav",
)
音声クローンと音声変換モデルはCLIでもおそらくできると思う。
Docker
CLIおよびサーバが含まれているDockerイメージが用意されている。今回自分はPythonパッケージインストールしたのだけど、一部のモデルは動作しなかった。それが環境なのか不具合なのかはわかってないけど、もし環境なのであればDockerイメージを使うことで解決する、かもしれない。
今回は割愛。
モデルのトレーニング
モデルのトレーニングについては以下。マルチスピーカーモデルやファインチューニング、データセットなどについても記載されているので、興味があれば。
まとめ
以前試したwhisper-ctranslate2を改めて見直していて、
whisper-ctranslate2のレポジトリを見ていたところ、作者の方が新しく「open-dubbing」というプロジェクトを起ち上げられていた。
open-dubbingは、機械学習モデルを使用して、異なる言語への音声対話の自動翻訳と同期を行うAIダビングシステムです!🎉
でその中でTTSとして紹介されていたので、気になって少し試してみた次第。
自分の少ない過去のTTS経験と照らし合わせてみた限りだと、特に目新しさはないかな。精度も今回はそこまで試してないのでわからない。ただ、音声クローンや音声変換なんかは以前「bark-with-voice-clone」を試したときと比べてかなりシンプルに実現できてしまっていて、TTSもどんどんお手軽かつ精度高くなっているのだなぁという印象。
ただ、対応しているモデルはいろいろあるのだけど、ライセンスや機能など個別に確認する必要があるのと、あと、Coqui AIのトップページを見ると・・・

うーん・・・最近は更新されていないようだし、今後ももうメンテされないかもしれない。
どうやらこちらでfork版がメンテされている模様。パッケージ名はcoqui-ttsに変わっている。
インストール時のextraについても明記があって、使うならこちらのほうが良さそう。