Context Engineering
最近、コンテキスト・エンジニアリングという言葉が、プロンプト・エンジニアリングに代わるより良い選択肢として支持され始めている。 私は気に入っている。 これは定着力がありそうだ。
私はプロンプト エンジニアリングよりも「コンテキスト エンジニアリング」という用語が本当に好きです。
これは、コアとなるスキル、つまり、LLM によってタスクが妥当に解決可能となるようにすべてのコンテキストを提供する技術をより適切に説明しています。
「プロンプトエンジニアリング」よりも「コンテキストエンジニアリング」に +1。
プロンプトは、日常的に LLM に与える短いタスクの説明と関連付けられます。しかし、産業用 LLM アプリケーションでは、コンテキストエンジニアリングは、次のステップに最適な情報をコンテキストウィンドウに正確に記入する、繊細な技術と科学です。科学である理由は、これを適切に行うには、タスクの説明と解説、少数のショット例、RAG、関連する(多模態の可能性のある)データ、ツール、状態と履歴、コンパクト化などが必要です。情報が不足していたり、形式が適切でないと、LLMは最適なパフォーマンスを発揮するための適切なコンテキストを保有できません。過剰または関連性の低い情報を提供すると、LLMのコストが増加し、パフォーマンスが低下する可能性があります。これを適切に実施することは、非常に困難です。そして、LLMの心理や人間の精神に関する直感的な理解が求められるため、これは芸術的な作業です。
コンテキストエンジニアリング自体に加え、LLMアプリは以下を実行する必要があります:
- 問題を適切な制御フローに分解する
- コンテキストウィンドウを適切にパッキングする
- 適切な種類と能力のLLMに呼び出しをディスパッチする
- 生成検証のUIUXフローを処理する
- さらに多くの機能 - ガードレール、セキュリティ、評価、並列処理、プリフェッチング、...
したがって、コンテキストエンジニアリングは、個々のLLM呼び出し(およびそれ以上の機能)を統合して完全なLLMアプリケーションとして調整する、新興の複雑なソフトウェア層の一部に過ぎません。「ChatGPTラッパー」という用語は古く、本当に間違っています。
AI エージェントによるコンテキスト管理(「コンテキストエンジニアリング」)の一般的なパターンについて書きました。
ざっくり要約。o4-miniを使った。
Context Engineering for Agents
コンテキストエンジニアリング
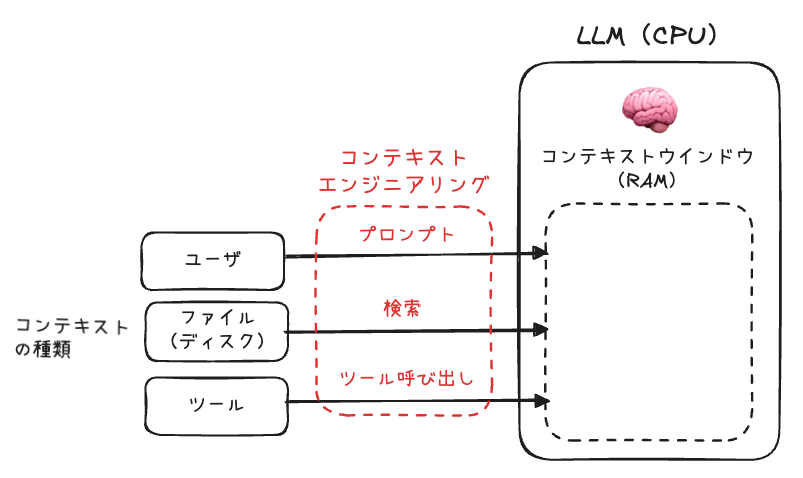
- LLMはCPU、コンテキストウィンドウはRAMのような「作業用メモリ」
- プロンプト・検索・ツール呼び出しなど複数の情報ソースを限られた帯域で処理
- 「コンテキストエンジニアリング」とは必要情報をコンテキストウィンドウに詰め込む技術
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432コンテキストエンジニアリングの台頭
- 焦点領域
- 指示(プロンプト/メモリ/few-shot例)
- 知識(RAGやメモリで世界知識を拡張)
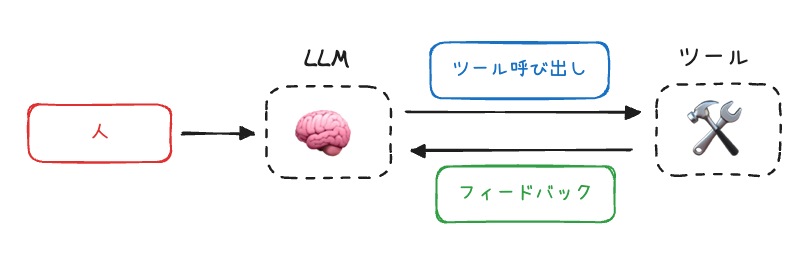
- ツールフィードバック(環境からの情報流入)
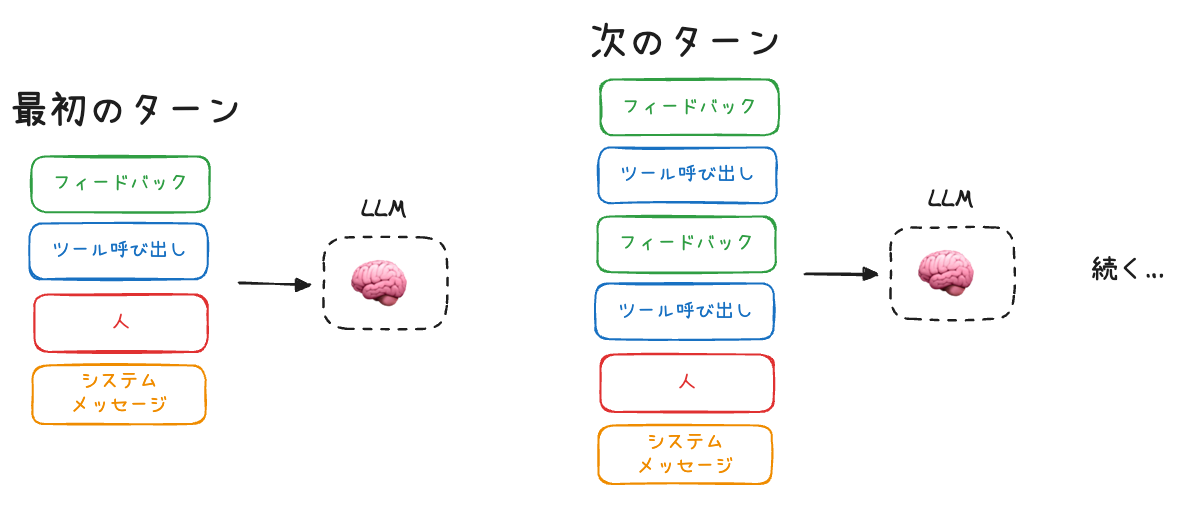
- エージェントはLLMとツール呼び出しを組み合わせ、長期タスクで文脈管理が必須
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432エージェントのためのコンテキストエンジニアリング
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432
- ツール呼び出しフィードバックが50万トークン超・数ドルのコストに膨張
- 長い文脈は性能劣化を招き、「コンテキスト劣化症候群」を引き起こす
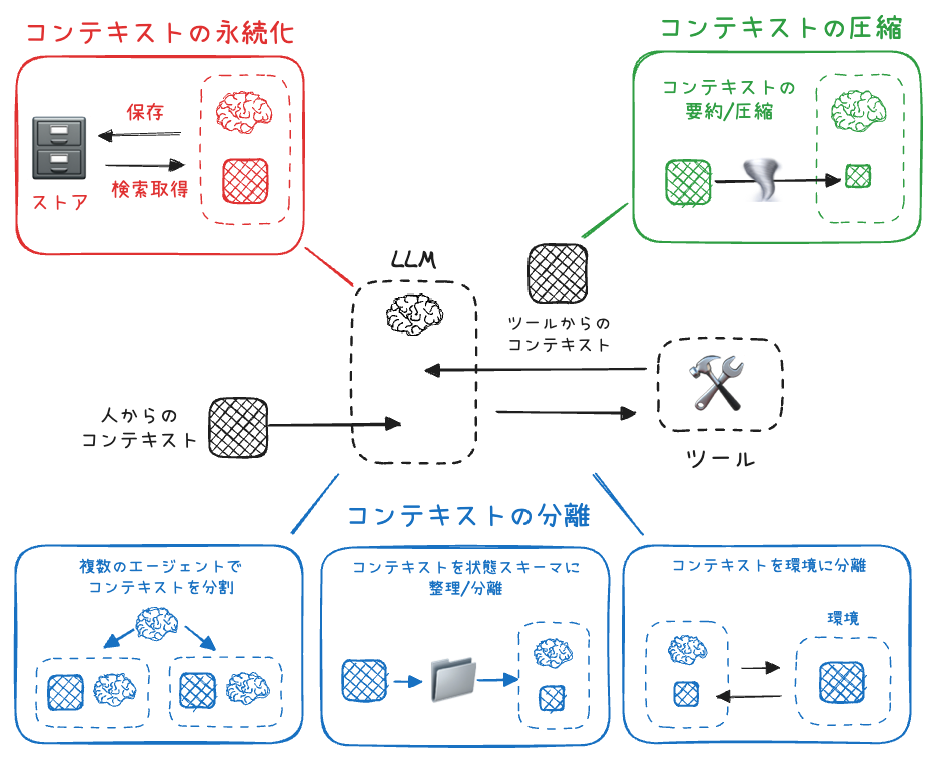
- 解決策を「圧縮」「永続化」「分離」の3カテゴリに分類
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432コンテキストの圧縮
- コンテキスト要約
- Claude Codeの「オートコンパクト」(95%超で要約)
- 再帰的・階層的要約でエージェント軌跡やツール出力を縮小
- 要約モデル(Devin)で特定イベントを保持しつつトークン削減
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432コンテキストの永続化
格納
- ファイル(CLAUDE.md, ルールファイル, メモリファイル群)
- 埋め込みドキュメント(Letta, Mem0, LangGraph, Mem)
- 知識グラフ(Zep, Neo4J)
保存
- Reflexionによる自己反省メモリ
- Generative Agentsの要約メモリ
- ChatGPT, Cursor, Windsurfの自動メモリ生成機能
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432取得
- 全メモリ読み込みまたは埋め込み/グラフ検索
- 類似度・最新性・重要度スコアリング(Generative Agents)
- 取得失敗事例(Simon WillisonによるGPT-4oのロケーション誤注入)
コンテキストの分離
コンテキストスキーマ
- Pydanticモデル等で
messagesとsectionsを分割し、重い部分は選択的に取得マルチエージェント
- OpenAI Swarmで関心分離、サブエージェントが独立したコンテキストを保持
- Anthropicの実験で90.2%性能向上(ただしトークン15×, 調整と連携が課題)
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432環境隔離
- HuggingFace CodeAgentがサンドボックス実行でオブジェクトを保存・隔離
- 画像・音声などを変数で管理し、LLMコンテキストを軽量化
referred from https://rlancemartin.github.io/2025/06/23/context_engineering/ and translated into Japanese by kun432レッスン
- まずは計測: トークン使用量を常時計測し、過剰消費を検出
- エージェント状態を考える: 状態スキーマで必要情報を厳選
- ツール境界で圧縮: トークン重いツール出力を小規模LLMで要約
- シンプルなメモリから開始: ファイルベースで狭い範囲の好みを保存・更新
- 並列可能なタスクにはマルチエージェントを検討: 緊密連携不要で平易に並列化可能な場面で活用

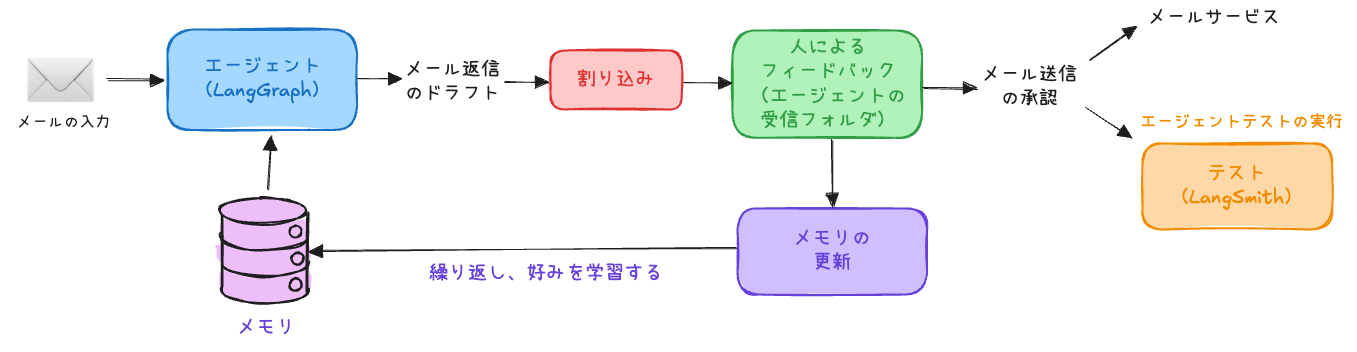

AI の分野で最も注目されている議論は「コンテキストエンジニアリング」です。しかし、それは一体何なのでしょうか?本当に必要なのでしょうか?コンテキストエンジニアリングは、より良いプロンプトを作成することではありません。適切なタイミングで適切な情報を提供する動的なシステムを構築することです。
AI アシスタントに会議のスケジュールを依頼した場合を考えてみましょう。
→ 貧弱なコンテキスト:リクエストのみを認識します。結果はロボットのような役に立たない返信になります。
→ 豊富なコンテキスト:リクエストに加え、あなたのカレンダー、過去のメール、利用可能なツール(send_inviteなど)を認識します。結果は、問題を積極的に解決する「魔法のような」アシスタントになります。AIエージェントの未来は、完璧なプロンプトではありません。完璧なコンテキストです。
以下、Diaによる要約
AI時代の新しい重要スキルは「プロンプト」ではなく「コンテキスト・エンジニアリング」
コンテキスト・エンジニアリングとは
- AI分野で注目されている新しい概念
-「プロンプト」だけでなく、AIがタスクを解決するために必要な全ての情報(コンテキスト)を設計・提供する技術- 成功するAIエージェントは、モデルの賢さよりも、与えるコンテキストの質が重要
コンテキストとは何か
referred from https://www.philschmid.de/context-engineering and translated into Japanese by kun432
- システムプロンプト/指示: AIの振る舞いを決める初期設定やルール、例示など
- ユーザープロンプト: ユーザーからの具体的な質問や依頼
- 短期記憶(会話履歴): 直近のやりとりや会話の流れ
- 長期記憶: 過去の会話やユーザーの好み、プロジェクトの要約など
- 外部情報(RAG): ドキュメントやデータベース、APIから取得した最新情報
- 利用可能なツール: AIが使える機能やツールの定義
- 出力フォーマット: AIの返答形式(例:JSON形式など)
なぜ重要なのか: 「安っぽいデモ」から「魔法のようなプロダクト」へ
- エージェントの成否は、コードやモデルの性能よりも「どんなコンテキストを与えるか」で決まる
- 例: 会議のスケジュール調整
- 安っぽいデモ(Cheap Demo)
- AIは、ユーザーからの「明日ちょっと打ち合わせできる?」というメールだけを見て返答する
- 返答例: 「ご連絡ありがとうございます。明日で大丈夫です。ご希望の時間はありますか?」
- 形式的、相手の状況・自分の予定・関係性など考慮しない、テンプレートのような機械的なやりとり
- 魔法のようなプロダクト(Magical Product)
- AIは、以下のような追加情報も参照する
- 自分のカレンダー(明日は予定が詰まっている)
- 過去のメール履歴(相手とはカジュアルなやりとりが多い)
- 連絡先リスト(相手は重要なパートナー)
- 「招待を送る」などのツールも利用可能
- 返答例: 「ジム、明日は一日中予定が詰まってるんだ。木曜の午前なら空いてるけどどう?今、招待送ったから確認してみて!」
- 人間のように、状況や相手との関係性を踏まえた自然なコミュニケーション
- 必要な情報やツールを組み合わせて、相手にとっても自分にとっても最適な提案ができる
-「魔法のような」AI体験は、適切なタスクに適切なコンテキストを提供することで生まれるプロンプトからコンテキスト・エンジニアリングへ
- システムとしての設計: 単なるテンプレートではなく、LLMに渡す前に必要な情報を集めて構成するシステム
- 動的な生成: リクエストごとに必要な情報やツールを選び、最適な形で提供
- 情報とツールの最適化: 必要な時に必要なものだけを渡す
- フォーマットの工夫: 分かりやすい要約や明確なツール定義が重要
結論
- 強力で信頼できるAIエージェントを作るには、魔法のプロンプトや最新モデルよりも「コンテキストの設計」が鍵
- ビジネスの目的や必要な出力を理解し、LLMがタスクを達成できるように情報とツールを整理・構造化することが求められる

https://simonwillison.net/2025/Jun/29/how-to-fix-your-context/ で紹介されていた。
Diaによる要約。
コンテキストをどう修正するか?
はじめに
- 長いコンテキストが失敗する主な例
- 誤情報の繰り返し(コンテキスト・ポイズニング)
- 文脈の過集中(コンテキスト・ディストラクション)
- 不要情報による混乱(コンテキスト・コンフュージョン)
- 矛盾情報の混在(コンテキスト・クラッシュ)
- 情報管理が重要であり、「ゴミを入れればゴミが出る」という原則が当てはまる。
- コンテキスト管理の戦術
- RAG(リトリーバル強化生成): 必要な情報だけを選んでLLMに追加し、より良い応答を引き出す手法。
- ツール・ロードアウト: 必要なツール定義だけを選択してコンテキストに加えること。
- コンテキスト隔離: 各コンテキストを専用のスレッドで分離し、それぞれを1つ以上のLLMで個別に使うこと。
- コンテキスト剪定: 不要または関係のない情報をコンテキストから削除すること。
- コンテキスト要約: 蓄積したコンテキストを要約し、簡潔な形にまとめること。
- コンテキスト・オフローディング: 情報をLLMのコンテキスト外に保存し、必要に応じて参照できるようにすること
RAG(Retrieval Augmented Generation)
- 必要な情報だけを選んでLLMに与える手法。
- コンテキストウィンドウが大きくなっても、無関係な情報を詰め込むと応答の質が下がるため、RAGの重要性は変わらない。
ツール・ロードアウト
- 必要なツール定義だけを選択してコンテキストに加える手法。
- ツール数が多いと混乱が生じやすく、RAGを使って30個未満に絞ると精度が大幅に向上する。
- 小型モデルではさらに少ないツール数が望ましい。
- ツール選択の自動化や省電力・高速化のメリットもある。
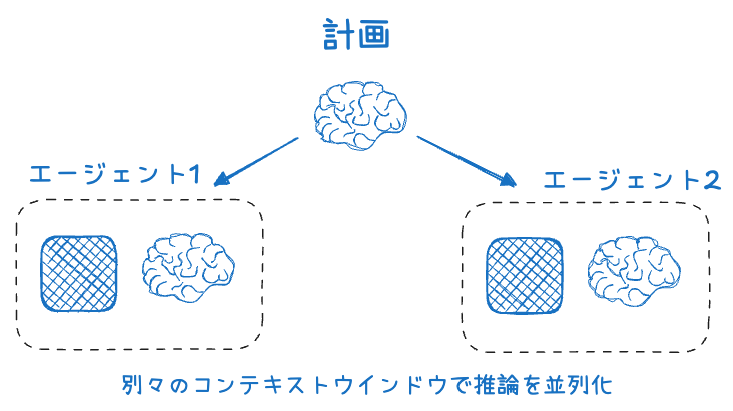
コンテキスト隔離
- タスクごとに独立したスレッドやエージェントでコンテキストを分離する手法。
- 複数のサブエージェントが並行して異なる観点を調査し、最終的にまとめることで高品質な結果が得られる。
- 並列化が可能な場合に有効。
コンテキスト剪定
- 不要な情報をコンテキストから削除する手法。
- LLMや専用ツール(例:Provence)を使って、関連性の低い部分を自動的に削除できる。
- コンテキストを構造化しておくと、剪定や要約がしやすくなる。
コンテキスト要約
- 蓄積したコンテキストを短く要約する手法。
- コンテキストが長くなりすぎるとモデルが過去の履歴に引きずられやすくなるため、要約が有効。
- どの情報を残すかの設計が重要。
コンテキスト・オフローディング
- LLMのコンテキスト外に情報を保存し、必要に応じて参照する手法(例:スクラッチパッド)。
- 長いツールチェーンや複雑な意思決定、厳格なルール遵守が必要な場面で効果的。
- 情報管理の工夫がエージェント設計の鍵となる。
まとめ
- コンテキストは無料ではなく、すべての情報がモデルの挙動に影響する。
- 大きなコンテキストウィンドウがあっても、情報管理を怠らず、必要な情報だけを厳選することが重要。
「エージェントを優れたものにする要素はすべてコンテキストエンジニアリングです」
@dexhorthy 氏の講演を @aiDotEngineer で公開できることを嬉しく思います。コンテキストエンジニアリングという用語を考案した同氏は、今日の AI エンジニアリングにおける最も重要な問題の一部を捉えた人物です。
コンテキストエンジニアリングについて詳しく知りたい方は、こちらからご覧ください。
🆕 12-factor Agents: 信頼性の高い LLM アプリケーションのパターン
エージェントの信頼性に関するトラックの次の注目講演は、コンテキストエンジニアリングという用語を考案した、ファンに人気の @dexhorthy 氏によるマニフェストです。
LLMが指数関数的に進化しても、LLMを活用したソフトウェアを信頼性が高く、スケーラブルで、メンテナンスしやすいものにするためのコアエンジニアリング技術は存在し続けます。
ファクター1: 自然言語からツール呼び出しへ
ファクター2: プロンプトを管理する
ファクター3: コンテキストウィンドウを管理する
ファクター4: ツールは構造化された出力に過ぎない
ファクター5: 実行状態とビジネス状態を統一する
ファクター6: シンプルなAPIで起動/一時停止/再開
ファクター7: ツール呼び出しで人間と連絡を取る
ファクター8: 制御フローを所有する
ファクター9: エラーをコンテキストウィンドウにコンパクトにまとめる
ファクター10: 小型で焦点を絞ったエージェント
ファクター11: どこからでもトリガーし、ユーザーがいる場所で対応する
ファクター12: エージェントをステートレスなリデューサーにする
以下にまとまっていた
AI用語に混乱している人のために説明しておくと、これらはすべては単なる「検索」である。
RAG -> 埋め込み表現間のセマンティック検索
状態・履歴 -> タスク終了後に消えるキャッシュされた検索
メモリ -> ユーザーの「ポリシー」または「ルール」を検索(通常はキーワードと結合に基づく)
プロンプト -> LLMモデルの確率空間における潜在的な検索
構造化出力 -> 検索の補完(与えられた検索クエリから出力を自動補完するもの)そして残りは通常のソフトウェアエンジニアリングです
ちょっと「コンテキストエンジニアリング」がバズワードっぽくなってきている感は確かにあるので、それに対するアンチテーゼかな。
「単なる」と言うのはどうかなぁ、それぞれの「検索」の定義・手法は違うような気もするし。ただ「検索」で言い換えれるといえばそれはそう。