白黒写真をカラー化するモデル「DDColor」を試す
まとめてもらった
DDColor: 写真リアルでセマンティックに認識可能な画像のカラー化に向けてのデュアルデコーダを用いたアプローチ
ひとことでまとめるとどんなものですか?
DDColorは、写真のリアルさと意味的な正確さを実現するための新しい画像カラー化手法です。この手法は、デュアルデコーダ構造を採用しており、一方のデコーダでピクセルの空間解像度を復元し、もう一方で色のクエリを精緻化します。
先行研究と比較してどの点がすごいのですか?
DDColorは、既存の手法と比較して、複雑なシーンにおいてより自然で鮮やかな色彩を生成する能力があります。また、手作業による事前設計を必要としないセマンティックに意識した色クエリの学習を実現し、色の滲み効果を大幅に軽減します。
技術や手法の重要な点はどこにありますか?
この手法の核となるのは、ピクセルデコーダと色デコーダの二つのデコーダです。ピクセルデコーダは画像の空間解像度を復元し、色デコーダはビジュアル特徴から色クエリを学習し、クロスアテンションによって色と多層セマンティック表現の間の相関を確立します。
技術や手法はどのように有効だと判断されましたか?
広範な実験により、DDColorは定量的および定性的に既存の最先端技術を超える性能を発揮することが示されました。特に、ImageNet、COCO-Stuff、ADE20Kの各データセットでの色彩の豊かさとセマンティックな一貫性の点で優れた結果を得ています。
何か議論や批判すべき点はありますか?
透明または半透明のオブジェクトを扱う際には、まだ視覚的なアーティファクトが生じる場合があり、この問題に対処するためには追加のセマンティックな監督が必要かもしれません。また、色の生成に関するユーザーのコントロールや指示を組み込むことは今後の課題です。
次に読むべき論文・文献は?
- Zhang, Richard, Phillip Isola, and Alexei A. Efros. "Colorful Image Colorization." In European conference on computer vision, pp. 649-666. Springer, 2016.
- He, Kaiming, et al. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929, 2020.
Colaboratoryで。ランタイムは"T4 GPU"。
!git clone https://github.com/piddnad/DDColor
%cd DDColor
依存パッケージのインストール。ランタイムの再起動が求められるので再起動。
!pip install -r requirements.txt
!python setup.py develop
余談だけど、再起動すると、移動していたパスが元に戻るので、再度移動する必要がある
!pwd # => /content
%cd DDColor
推論には3つの方法がある。ここではHuggingFaceのモデルを使う方法でやってみる。モデルは以下にある。
各モデルの説明
レポジトリ内のaseets/test_imagesにサンプルの画像が入っているのでこれを使う。もともとはこんな感じ。
import os
import base64
from IPython.display import display, HTML
def image2base64(filepath):
with open(filepath, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def display_images(directory_path, max_height=100):
supported_image_formats = ['.jpg', '.jpeg', '.png', '.gif', '.bmp']
images_html = []
for filename in os.listdir(directory_path):
if any(filename.lower().endswith(ext) for ext in supported_image_formats):
filepath = os.path.join(directory_path, filename)
encoded_image = image2base64(filepath)
images_html.append(f'<img src="data:image/png;base64,{encoded_image}" style="max-height: {max_height}px; margin: 5px;" />')
html = '<div style="display: flex; flex-wrap: wrap; justify-content: space-around;">' + ''.join(images_html) + '</div>'
display(HTML(html))
display_images("./assets/test_images", max_height=200)

スクリプトが用意されているのでこれを使ってみる。 --model_nameにモデルを指定する。
!python inference/colorization_pipeline_hf.py --model_name ddcolor_modelscope --input ./assets/test_images
config.json: 100% 258/258 [00:00<00:00, 1.17MB/s]
pytorch_model.bin: 100% 912M/912M [00:15<00:00, 58.6MB/s]
Output path: results
100% 13/13 [00:04<00:00, 2.91it/s]
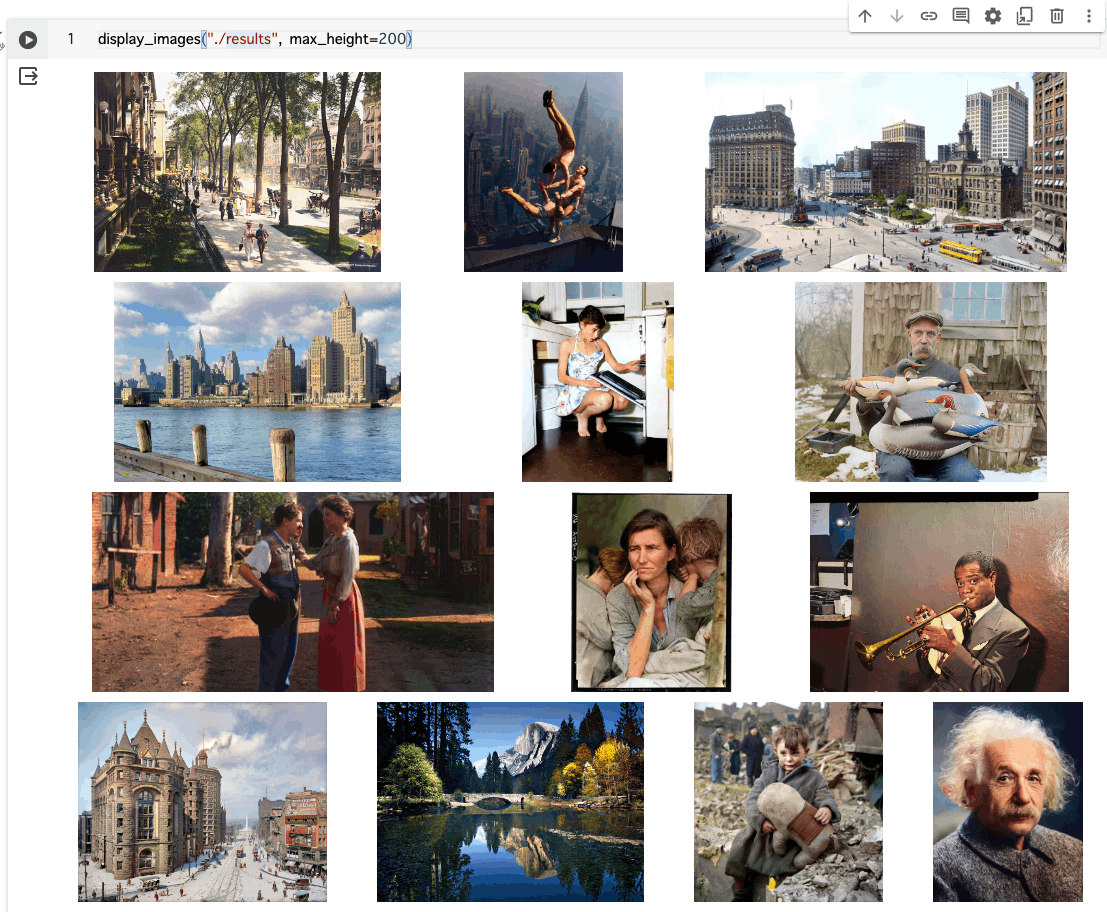
resultsディレクトリに出力されるので見てみる。
display_images("./results", max_height=200)