ScrapeGraphAIを試す
🕷️ ScrapeGraphAI:スクレイピングは一度だけ
ScrapeGraphAIは、LLMとダイレクトグラフロジックを使用して、ウェブサイトやローカルドキュメント(XML、HTML、JSONなど)のスクレイピングパイプラインを作成するウェブスクレイピングPythonライブラリである。
抽出したい情報を言うだけで、ライブラリがそれをやってくれる!
以下にcolaboratory用のnotebookが用意されているので、まずはこれをやってみる。
パッケージのインストール。スクレイピング用のパッケージなどもインストールする。
%%capture
!pip install scrapegraphai==0.9.0b7 --upgrade
!apt install chromium-chromedriver
!pip install nest_asyncio
!pip install playwright
!playwright install
notebookでイベントループを使う場合のおまじない
import nest_asyncio
nest_asyncio.apply()
APIキーをセット。OpenAIとGeminiを使うのでそれぞれセットしている。
from google.colab import userdata
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
SmartScraperGraphクラス
SmartScraperGraphクラスは、デフォルトのスクレイピング・パイプラインの1つを表すクラスである。ウェブサイトからhtmlを取得することから、クエリに基づいて関連情報を抽出し、首尾一貫した回答を生成することまで、各ノードが独自の機能を持つ直接的なグラフ実装を使用している。
referred from https://colab.research.google.com/drive/1sEZBonBMGP44CtO6GQTwAlL0BGJXjtfd?usp=sharing
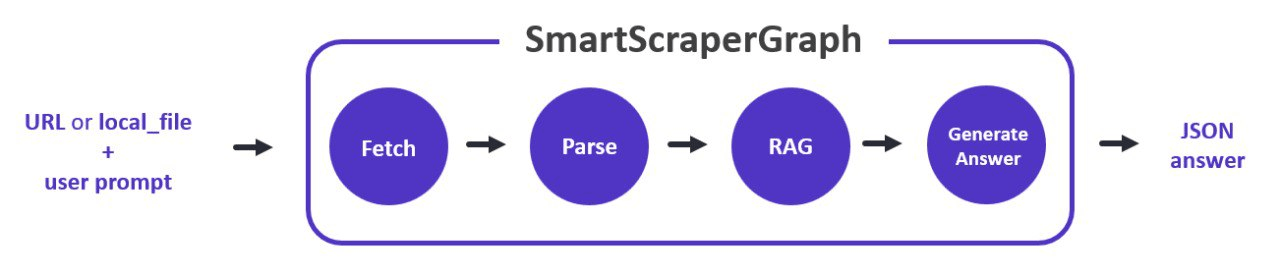
ふむ。とりあえずコード。
from scrapegraphai.graphs import SmartScraperGraph
# 設定
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo-0125",
"temperature":0,
},
}
# SmartScraperGraphクラスにプロンプト、取得先URL(取得済HTMLファイルでも可)、上記の設定を渡して、パイプラインを初期化
smart_scraper_graph = SmartScraperGraph(
prompt="全てのプロジェクトをリストアップして、それぞれ日本語で説明してください。",
source="https://perinim.github.io/projects/",
config=graph_config
)
# パイプラインの実行
result = smart_scraper_graph.run()
結果。ちょっと整形しつつ。
import json
output = json.dumps(result, indent=2, ensure_ascii=False)
print(output)
{
"Projects": [
{
"Title": "Rotary Pendulum RL",
"Description": "RLアルゴリズムを使用して実際の回転振り子を制御するオープンソースプロジェクト"
},
{
"Title": "DQN Implementation from scratch",
"Description": "シンプルおよびダブル振り子をトレーニングするためのDeep Q-Networkアルゴリズムを開発"
},
{
"Title": "Multi Agents HAED",
"Description": "複数のエージェントシステムをシミュレートし、環境マッピングを実行する大学プロジェクト。センサーを装備したエージェントが、読み取りの不確実性を考慮して周囲を探索し記録する"
},
{
"Title": "Wireless ESC for Modular Drones",
"Description": "モジュラードローンアーキテクチャの提案と概念証明。プロジェクトは最高評価を受けた"
}
]
}
今度はGeminiで。
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"api_key": GOOGLE_API_KEY,
"model": "gemini-pro",
},
"verbose":True # verboseを有効化
}
smart_scraper_graph = SmartScraperGraph(
prompt="全てのニュースをリストアップして、日本語で説明してください。カテゴリーごとに分けてください。",
source="https://www.wired.com/category/science/",
config=graph_config
)
result = smart_scraper_graph.run()
設定に"verbose":Trueを追加したことで、実行時の状況が出力されるようになる。なるほど、SmartScraperGraphは内部でスクレイピング・パース・RAG化した上で、最終的にLLMで結果を出力するパイプラインというのがよく分かる。
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|██████████| 1/1 [00:00<00:00, 1113.14it/s]
結果
import json
output = json.dumps(result, indent=2, ensure_ascii=False)
print(output)
{
"ニュース": [
{
"カテゴリー": "バイオテクノロジー",
"見出し": "イーロン・マスクのニューラリンク、脳インプラントに挫折。設計が原因か",
"説明": "ニューラリンクは、最初の人間用脳コンピュータインターフェースインプラントで機械的な問題が発生しました。その斬新な設計により、故障しやすくなっている可能性があります。"
},
{
"カテゴリー": "バイオテクノロジー",
"見出し": "米国、合成DNAの取り締まりを強化",
"説明": "合成DNAはパンデミックを引き起こす可能性があります。バイデン大統領の動きは、郵送遺伝物質の安全性とセキュリティに関する新しい基準を作成することを目的としています。"
},
{
"カテゴリー": "バイオテクノロジー",
"見出し": "中国、脳コンピュータインターフェースに関する物議を醸す計画",
"説明": "中国の脳コンピュータインターフェース技術は米国に追いつきつつあります。しかし、それは認知能力の向上という非常に異なるユースケースを想定しています。"
},
{
"カテゴリー": "バイオテクノロジー",
"見出し": "医師が画期的な手術で心臓ポンプとブタの腎臓移植を組み合わせる",
"説明": "この種の最初の手術で、54歳のニュージャージー州の女性は、心臓ポンプを装着した後、遺伝子組み換えされたブタの腎臓と胸腺を受け取りました。"
},
{
"カテゴリー": "ロボット工学",
"見出し": "アトラスロボットは死んだ。アトラスロボット万歳",
"説明": "古いモデルが電源を切ることさえできないうちに、ボストン・ダイナミクスは、私たち人間には決してできない方法で動くことができる、より強力な新しいアトラスロボットを解き放ちました。"
},
{
"カテゴリー": "ロボット工学",
"見出し": "次世代の医師と彼らの外科用ロボットに会う",
"説明": "心配しないでください、あなたの次の外科医は間違いなく人間になります。しかし、医学生がメスを使用する訓練を受けているのと同じように、手術を容易にするために設計されたロボットを使用する訓練も受けています。"
},
{
"カテゴリー": "ロボット工学",
"見出し": "AIは人間が想像もできない非常に効果的な抗体を構築しています",
"説明": "ロボット、コンピューター、アルゴリズムは、膨大な量のデータを処理し、これまで想像もできなかった分子を構築することで、人間にはできない方法で潜在的な新しい治療法を探しています。"
},
{
"カテゴリー": "ロボット工学",
"見出し": "この人工筋肉は独自に物を動かす",
"説明": "キュウリ植物に触発されたアクチュエーターにより、ロボットは環境に応じてより自然に動くようになったり、居住不能な場所のデバイスに使用されたりします。"
},
{
"カテゴリー": "心理学と神経科学",
"見出し": "科学者たちはあなたの「小さな脳」の秘密を解き明かしています",
"説明": "小脳は運動の調整以上の役割を果たします。新しい技術により、それが実際には脳内の感覚的および感情的処理の中心であることが明らかになりました。"
},
{
"カテゴリー": "心理学と神経科学",
"見出し": "ニューラリンクの手術用ロボットの背後にいるデザイナーに会う",
"説明": "アフシン・メヒンは、最も未来的な神経技術デバイスのいくつかを設計するのに貢献してきました。"
},
{
"カテゴリー": "心理学と神経科学",
"見出し": "あなたは騒音に敏感ですか?見分ける方法",
"説明": "騒音を「大きい」と感じる基準は人によって異なりますが、音量を少し下げるために私たち全員ができることがいくつかあります。"
},
{
"カテゴリー": "心理学と神経科学",
"見出し": "ホワイトノイズマシンで声が聞こえる理由",
"説明": "ホワイトノイズマシンを動かして寝ようとしたときに音楽、声、または他の音が聞こえたことがあるなら、あなたは気が狂っているわけではありません。これが起こっていることです。"
},
{
"カテゴリー": "最新",
"見出し": "アラバマ州で培養肉を販売すると刑務所に行く可能性",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "英国の気候政策の不都合な真実",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "アメリカ人の3人に1人が危険な大気汚染地域に住んでいる",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "植物ベースの肉が急増。バストがやってくる",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "緑の屋根は素晴らしい。青緑の屋根はさらに優れています",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "環境被害は今後25年間で収入の5分の1を費やす可能性",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "ついにニューラリンクの脳インプラント試験が行われている場所が判明",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "炭素農家の台頭",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "ドバイの洪水は雲の種まきが原因ではない",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "米国のインフラは壊れています。修正するための8億3000万ドルの計画",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "彼らは秘密裏に自分自身で実験しました。彼らが発見したことは戦争に勝つのに役立ちました",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "気候変動を加速させているパラドックス",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "風車を修理するために大学ではなくガッツが必要",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "脳インプラントの次のフロンティアは人工視覚",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "宇宙軍が軌道上で軍事演習を計画",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "トロントは暴風雨と洪水を管理したいと考えています。雨税で",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "イーロン・マスクの最新の火星ピッチには可能性がある",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "欧州、気候変動対策の不十分さは人権侵害であると裁定",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "最高の皆既日食の写真",
"説明": null
},
{
"カテゴリー": "最新",
"見出し": "皆既日食をオンラインで視聴",
"説明": null
},
{
"カテゴリー": "健康",
"見出し": "脳を食べる虫と水銀中毒にならない方法",
"説明": "無所属の大統領候補ロバート・F・ケネディ・ジュニアは、脳寄生虫と水銀中毒の両方を同時に患っていました。それぞれの状態はどれほどまれですか?"
},
{
"カテゴリー": "健康",
"見出し": "制御不能な腸内真菌があなたのコロナを悪化させる可能性",
"説明": "感染症はあなたのマイクロバイオームを混乱させる可能性があり、特定の腸内真菌が暴走すると、免疫システムが過剰に活性化される可能性があります。"
},
{
"カテゴリー": "健康",
"見出し": "鳥インフルエンザが驚くべき新しい方法で広がっています",
"説明": "H5N1は米国全土の牛に感染"
}
]
}
SearchGraphクラス
このグラフは、ユーザープロンプトをインターネット検索クエリに変換し、関連するURLを取得し、スクレイピング処理を開始する。SmartScraperGraphに似ているが、SearchInternetNodeノードが追加されている。
referred from https://colab.research.google.com/drive/1sEZBonBMGP44CtO6GQTwAlL0BGJXjtfd?usp=sharing
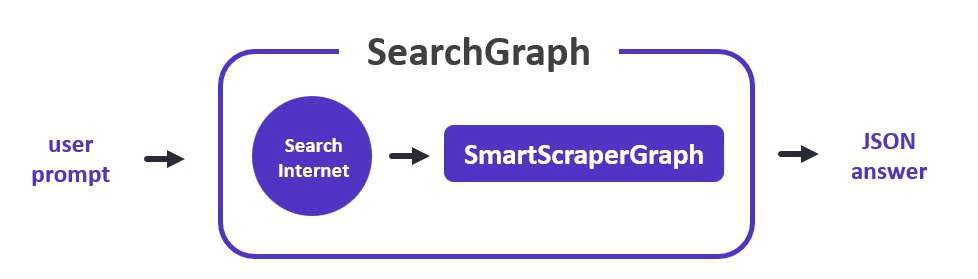
なるほど、URLの代わりに検索エンジンを使うステップが前段に追加されると。
from scrapegraphai.graphs import SearchGraph
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo-0125",
"temperature": 0,
},
"verbose":True
}
search_graph = SearchGraph(
prompt="ヨーロッパの国名をリストアップしてください。日本語で。",
config=graph_config
)
result = search_graph.run()
クエリが生成されている。どうやら検索結果を複数見ているような気がする。ちょっとスクレイピングでエラーっぽいものがでているようだけど。
--- Executing SearchInternet Node ---
Search Query: ヨーロッパの国名 一覧 日本語
--- Executing GraphIterator Node ---
Processing Graph Instances: 0%| | 0/3 [00:00<?, ?it/s]--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|██████████| 1/1 [00:00<00:00, 2272.10it/s]
Processing Graph Instances: 33%|███▎ | 1/3 [00:08<00:16, 8.12s/it]--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|██████████| 1/1 [00:00<00:00, 1895.30it/s]
Processing Graph Instances: 67%|██████▋ | 2/3 [00:11<00:05, 5.05s/it]--- Executing Fetch Node ---
/usr/local/lib/python3.10/dist-packages/scrapegraphai/utils/remover.py:26: MarkupResemblesLocatorWarning: The input looks more like a filename than markup. You may want to open this file and pass the filehandle into Beautiful Soup.
soup = BeautifulSoup(html_content, 'html.parser')
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|██████████| 1/1 [00:00<00:00, 2296.99it/s]
Processing Graph Instances: 100%|██████████| 3/3 [00:43<00:00, 14.37s/it]
--- Executing MergeAnswers Node ---
結果
import json
output = json.dumps(result, indent=2, ensure_ascii=False)
print(output)
{
"ヨーロッパの国名": [
"アイスランド",
"アイルランド",
"アルバニア",
"アンドラ",
"イギリス",
"イタリア",
"ウェールズ",
"ウクライナ",
"エストニア",
"オーストリア",
"オランダ",
"キプロス",
"ギリシャ",
"クロアチア",
"コソボ",
"サンマリノ",
"ジャーマニー",
"スイス",
"スウェーデン",
"スペイン",
"スロヴァキア",
"スロベニア",
"セルビア",
"チェコ",
"デンマーク",
"ドイツ",
"ノルウェー",
"ハンガリー",
"フィンランド",
"フランス",
"ブルガリア",
"ベラルーシ",
"ベルギー",
"ポーランド",
"ボスニア・ヘルツェゴビナ",
"ポルトガル",
"マケドニア",
"マルタ",
"モナコ",
"モルドヴァ",
"モンテネグロ",
"ラトビア",
"リトアニア",
"リヒテンシュタイン",
"ルーマニア",
"ルクセンブルク",
"ロシア",
"プロイセン"
]
}
SpeechGraph
SpeechGraphは、音声ファイルと共に回答を生成するデフォルトのスクレイピング・パイプラインの一つを表すクラスである。SmartScraperGraph に似ているが、TextToSpeechNode ノードが追加されている。
referred from https://colab.research.google.com/drive/1sEZBonBMGP44CtO6GQTwAlL0BGJXjtfd?usp=sharing
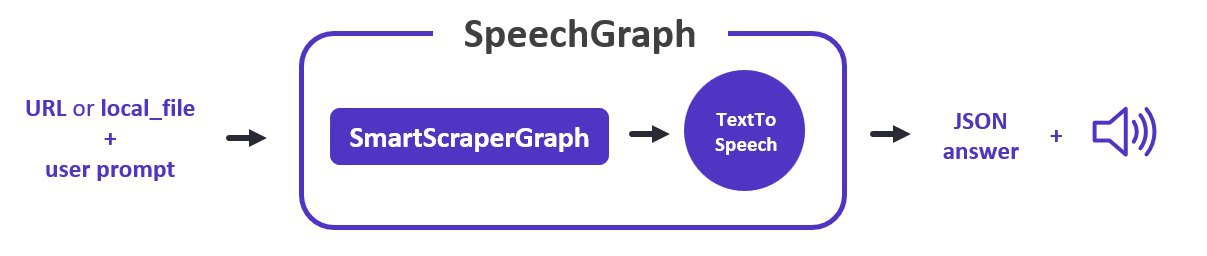
今度はパイプラインの最後にTTSを追加する。
from scrapegraphai.graphs import SpeechGraph
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo",
},
"tts_model": {
"api_key": OPENAI_API_KEY,
"model": "tts-1",
"voice": "alloy"
},
"output_path": "website_summary.mp3",
}
speech_graph = SpeechGraph(
prompt="ウェブサイトの日本語での要約を作成してください。",
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = speech_graph.run()
まずJSONでの結果
import json
output = json.dumps(result, indent=2, ensure_ascii=False)
print(output)
{
"要約": {
"プロジェクト": [
{
"タイトル": "Rotary Pendulum RL",
"説明": "RLアルゴリズムを使用して実際の回転振り子を制御するオープンソースプロジェクト"
},
{
"タイトル": "DQN Implementation from scratch",
"説明": "Deep Q-Networkアルゴリズムを使用して単純および二重振り子をトレーニングするプロジェクト"
},
{
"タイトル": "Multi Agents HAED",
"説明": "複数のエージェントが環境マッピングを実行するためにシミュレートされる大学のプロジェクト。センサーを装備したエージェントは、自分の周囲を探索し記録し、読み取り値の不確実性を考慮する。"
},
{
"タイトル": "Wireless ESC for Modular Drones",
"説明": "モジュラードローンアーキテクチャの提案と概念証明。プロジェクトは最高の成績を受け取りました。"
}
]
}
}
あわせてTTSの音声ファイルも出力される
from IPython.display import Audio
wn = Audio("website_summary.mp3", autoplay=True)
display(wn)
生成された音声はこんな感じ
カスタムグラフ
パイプラインはビルトインのノードから構成される。このノードを組み合わせることで、カスタムなパイプラインを作成することができる。
ビルトインのノードはnodes_metadataから参照できる。
from scrapegraphai.helpers import nodes_metadata
nodes_metadata.keys()
dict_keys([
'SearchInternetNode',
'FetchNode',
'GetProbableTagsNode',
'ParseNode',
'RAGNode',
'GenerateAnswerNode',
'ConditionalNode',
'ImageToTextNode',
'TextToSpeechNode'
])
キーを指定すると、各ノードの詳細がわかる
nodes_metadata['ImageToTextNode']
{'description': "Refactors the user's query into a search\n query and fetches the search result URLs.",
'type': 'node',
'args': {'user_input': "User's query or question."},
'returns': "Updated state with the URL of the search result under 'url' key."}
各ノードについてはドキュメントにもある
カスタムなグラフを作成して使うには以下の流れになる
- 使用するノードを選択
- BaseGraphクラスでグラフを定義
- ノードのリストを定義
- ノード間のエッジをタプルで定義
- エントリーポイントとなるノードを定義
- executeメソッドで実行
notebookのコードに一部不備があったので修正している。
from scrapegraphai.models import OpenAI
from scrapegraphai.graphs import BaseGraph
from scrapegraphai.nodes import FetchNode, ParseNode, RAGNode, GenerateAnswerNode
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo-0125",
"temperature": 0,
"streaming": True
},
}
llm_model = OpenAI(graph_config["llm"])
# グラフで使用するノードを定義
fetch_node = FetchNode(
input="url | local_dir",
output=["doc"],
)
parse_node = ParseNode(
input="doc",
output=["parsed_doc"],
node_config={"chunk_size": 4096}
)
rag_node = RAGNode(
input="user_prompt & (parsed_doc | doc)",
output=["relevant_chunks"],
node_config={"llm_model": llm_model},
)
generate_answer_node = GenerateAnswerNode(
input="user_prompt & (relevant_chunks | parsed_doc | doc)",
output=["answer"],
node_config={"llm_model": llm_model},
)
# ノードとエッジを定義してグラフを作成
graph = BaseGraph(
nodes=[
fetch_node,
parse_node,
rag_node,
generate_answer_node,
],
edges=[
(fetch_node, parse_node),
(parse_node, rag_node),
(rag_node, generate_answer_node)
],
entry_point=fetch_node
)
実行。
# グラフを実行
result = graph.execute({
"user_prompt": "List me the projects with their description",
"url": "https://perinim.github.io/projects/"
})
result = result.get("answer", "回答なし")
なんだけど・・・どうやら内部的にLangChainを使っているらしく、多分LangChainのパッケージが変わったかなんかでうまく行かなくなってるんじゃないかなぁ。わからないけど。
3 frames
/usr/local/lib/python3.10/dist-packages/langchain_community/vectorstores/faiss.py in from_texts(cls, texts, embedding, metadatas, ids, **kwargs)
928 faiss = FAISS.from_texts(texts, embeddings)
929 """
--> 930 embeddings = embedding.embed_documents(texts)
931 return cls.__from(
932 texts,
AttributeError: 'OpenAI' object has no attribute 'embed_documents'
でも雰囲気はわかる。
でグラフはGraphBuilderでGraphVizを使った可視化ができる。
from scrapegraphai.builders import GraphBuilder
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "gpt-3.5-turbo",
},
}
graph_builder = GraphBuilder(
user_prompt="Extract the news and generate a text summary with a voiceover.",
config=graph_config
)
graph_json = graph_builder.build_graph()
graphviz_graph = graph_builder.convert_json_to_graphviz(graph_json)
graphviz_graph.render('ScrapeGraphAI_generated_graph', view=True)
JSON出力
graph_json
{'input': 'Extract the news and generate a text summary with a voiceover.',
'text': [{'nodes': [{'node_name': 'SearchInternetNode', 'node_type': 'node'},
{'node_name': 'FetchNode', 'node_type': 'node'},
{'node_name': 'GetProbableTagsNode', 'node_type': 'node'},
{'node_name': 'ParseNode', 'node_type': 'node'},
{'node_name': 'RAGNode', 'node_type': 'node'},
{'node_name': 'GenerateAnswerNode', 'node_type': 'node'},
{'node_name': 'ConditionalNode', 'node_type': 'conditional_node'},
{'node_name': 'ImageToTextNode', 'node_type': 'node'},
{'node_name': 'TextToSpeechNode', 'node_type': 'node'}],
'edges': [{'from': 'SearchInternetNode', 'to': ['FetchNode']},
{'from': 'FetchNode', 'to': ['GetProbableTagsNode']},
{'from': 'GetProbableTagsNode', 'to': ['ParseNode']},
{'from': 'ParseNode', 'to': ['RAGNode']},
{'from': 'RAGNode', 'to': ['GenerateAnswerNode', 'ConditionalNode']},
{'from': 'ConditionalNode',
'to': ['ImageToTextNode', 'TextToSpeechNode']}],
'entry_point': 'SearchInternetNode'}]}
GraphViz出力
graphviz_graph
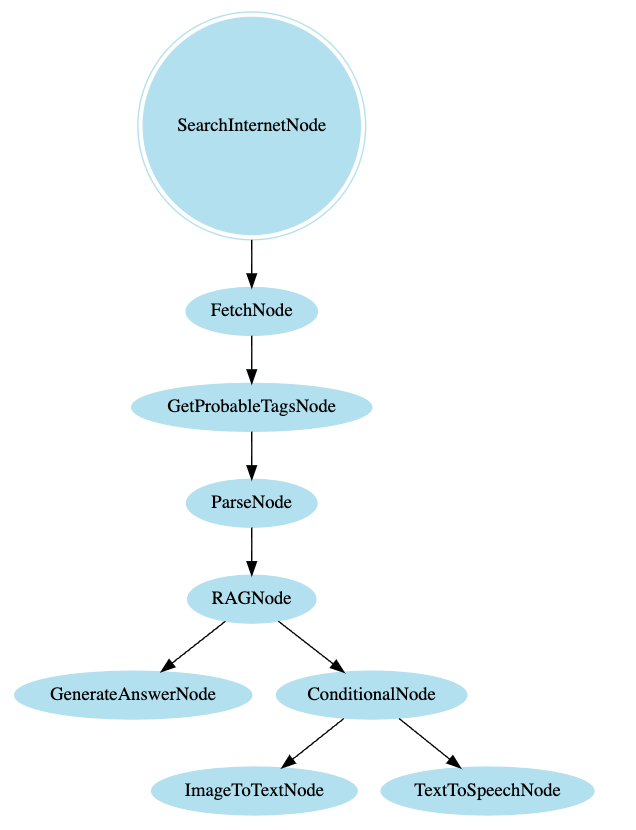
まとめ
- まだこなれてないところがあるのと、多分何かしらLangChainの変更の影響がでてしまってるような感があるけども、普通の使い方ならかなりシンプルに書けるし、カスタムでパイプライン作る場合でも、とてもわかりやすく感じた。
- RAGっぽいことをやって入るんだけども、RAGフレームワークというよりは、エージェントのツールっぽさがあるように感じる。これだけでRAG作るというよりは、RAGとかエージェントから呼び出す、ってのがなんとなく良さそうな気がした。
- LCELとかLangGraphとか使ったことあれば、多分すぐにカスタムなパイプライン書けそう。
- ただ日本語の場合にどうすればいいのか、というのはやっぱりある
- プロンプトを日本語にしてみたけど、JSONのキーまで日本語になってたり。
- コード少し見た感じだと、内部でプロンプト持ってて、インスタンス初期化時に書き換えれるような、雰囲気はある。
かなりミニマムにフローエンジニアリングできる感じで、個人的にはちょっと今後に期待。
公式ドキュメント
ワークフロー的に定義できるLLMフレームワークが主流になっていく感があるなぁ。
RAGとかエージェントから呼び出す、ってのがなんとなく良さそうな気がした。
やはりRAGっていうよりはツールなのよね、LLMが主なのではなくて、スクレイピングを簡単にやるためにLLMを味付けとして使うってところかな