超軽量なOCR向けVLM「LightOnOCR-1B」を試す
最近またOCR用途のVLMは色々でてるね。ここで知った。
最近、OCRのリリースをたくさん見かけたかもしれません...
ここではもう一つ、🦉 LightOnOCR-1B を紹介します
完全にエンドツーエンドで微分可能なVLMモデルで、最新のリリースすべてと競合しながら、はるかに高速です🚀
2/10
ブログ:
https://huggingface.co/blog/lightonai/lightonocr
ほとんどのOCRシステムは複雑な多段階のパイプラインに依存しています
🦉 LightOnOCR-1Bは、それらを単一の完全に微分可能なモデルに置き換えます。
テーブル、フォーム、方程式などの構造化されたレイアウトを、脆弱な前処理ステップなしで直接処理します
3/10
品質(Olmo-Bench)
• DeepSeekOCRを上回る
• dots.ocr(約3倍大きい)に匹敵
• Qwen3-VL-2B-Instructに対して+16ポイント
• ベンチマーク特化の微調整なし
LightOnOCR-1Bは、その重量クラスで最先端のパフォーマンスを達成しています。
4/10
効率
シングル H100 GPU (80 GB):
• 5.71 ページ / 秒 ≈ 493,000 ページ / 日
• dots.ocr より 6.49 倍速い
• PaddleOCR-VL-0.9B より 2.67 倍速い
• DeepSeekOCR より 1.73 倍速い
• 1,000 ページあたり $0.01 未満
高品質かつコスト効率の高いコンパクトなモデル。
5/10
トレーニング
Qwen2-VL-72B-Instructから、1760万ページと455億トークンの厳選されたコーパスを使用して蒸留。
すべてPDFからネイティブ解像度でレンダリングされ、Markdownに正規化 — 軽量でトークン効率が高く、意味的に一貫性がある。
データセットは公開される予定。
6/10
アブレーションと発見
• 単一ステージ > 2ステージ(+1.4平均)
• 大きな教師(72B対7B)→ +11.8ポイント
• 語彙の剪定(→ 32k)は精度を維持し、速度を向上
• ファインチューニング(OlmOCR-mixで1エポックで+9ポイント)
7/10
語彙の削減
Qwen3の語彙を151k→32k/16kトークンに削減:
• 英語/フランス語の精度を維持
• 解読速度が約12%向上
• 非ラテン文字での損失は予想通り
ドメイン特化型トークン化がOCR効率を改善する方法を示す。
8/10
アーキテクチャ
ネイティブ解像度のViT(Pixtralベース)が、コンパクトなマルチモーダル投影層を介してQwen3言語モデルに接続される。
文書は200 DPI(最大1540 px)でレンダリングされる。
推論解像度が高いほど → 密なテキストや数式ページで+6ポイント向上。
9/10
ファインチューニングと適応性
エンドツーエンドのトレーニング可能性により、専門化が簡単になります。
OlmOCR-mix(ドキュメントサブセット)において:
• 1エポック後に全体で+9ポイント
• ヘッダーとフッターで+51ポイント
MonkeyOCR-3Bを上回り、最小限の努力でMinerU 2.5のパフォーマンスに近づきます。
10/10
概要
🦉 LightOnOCR-1B
• 10億のパラメータ | エンドツーエンド | 高速 | オープンデータ
• 最先端の品質/コストバランス
• vLLMで簡単に提供可能
利用可能なモデル:
https://huggingface.co/lightonai/LightOnOCR-1B-1025
https://huggingface.co/lightonai/LightOnOCR-0.9B-32k-1025
試せるデモがある
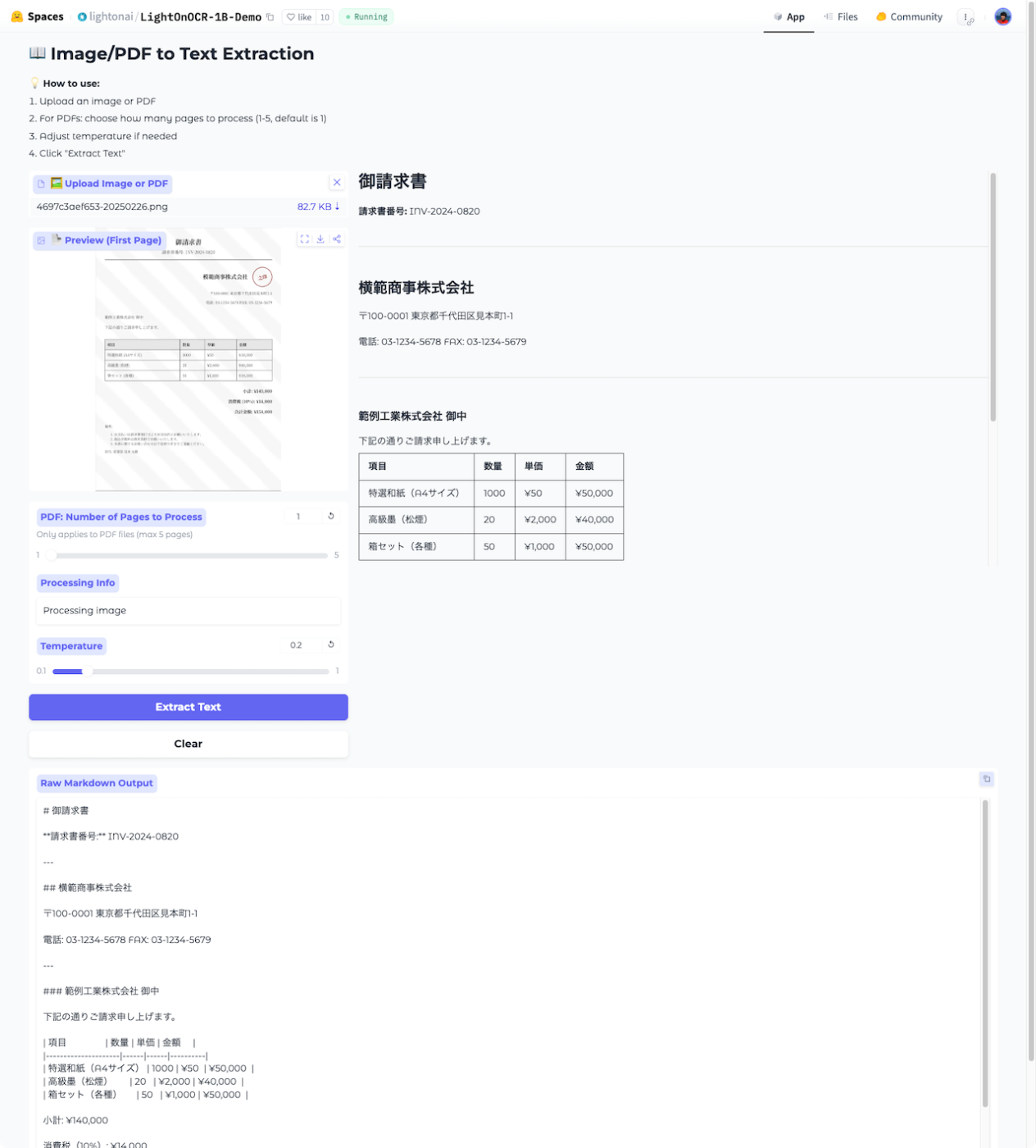
昔作ったダミーの請求書画像を使ってみたけど、日本語は普通に読み取れる模様。
ダミーの請求書の画像

デモの実行結果。1Bと軽量なこともあってか、一瞬で終わる。
HuggingFaceのブログ
Dia によるまとめ。
LightOnOCR-1Bは、速くて安いのに高精度なOCR向け小型VLMだよ。
これは何?どうスゴいの?
LightOnOCR-1BはPDFやスキャン画像みたいな文字ぎっしりのドキュメントを、画像→テキスト(しかも構造付き)に変換するための1Bパラメータ級のビジョン言語モデルだよ。特徴は「小さくて軽いのに、マジで精度高い」「推論めっちゃ速い」「エンドツーエンドで学習&微調整が簡単」ってとこだし。
- 速さ: H100 1枚で約5.71ページ/秒、ざっくり49万ページ/日処理できるってヤバくない?コストも1000ページ当たり約1円未満って書いてあって、リアルに運用向きだもん。
- 品質: 有名ベンチの Olmo-Bench で、同サイズ帯の最先端レベル。DeepSeekOCR より強くて、よりデカい一般用途VLMとも互角か上、ってノリ。
- 単体モデル: 最近ありがちな「検出→切り出し→認識→整形」みたいな複雑パイプラインじゃなくて、1回のモデル呼び出しで完結するから、壊れにくく微調整もしやすいでしょ。
なんで速くて安いの?
- 単発呼び出し: ページごとに1回推論。パイプライン勢がやりがちな切り取り・再試行なし。だからオーバーヘッドが少ないのが効く。
- 言語側をスリム化: Qwen3系の言語バックボーンを使いつつ、用途に合わせて 語彙(トークン)を削るバリアント(32k/16k) も用意。英語・フランス語中心なら小さい語彙で十分で、推論がさらに速くなるだし。
- 視覚側の最適化: 画像エンコーダはネイティブ解像度対応(NaViTスタイル)。トークン数を抑えるためにビジョントークンを1/4にダウンサンプルして言語モデルへ。これで計算量がだいぶ軽いのよ。
学習のキモ:大規模PDF+蒸留
教師役の超大型VLM(Qwen2‑VL‑72B)に大量のドキュメントをMarkdown+LaTeXで書き起こしてもらって、そこで出たテキストを正規化(ループ/重複/余計な装飾の除去、幻覚フィルタ)したうえで、17.6Mページ / 45.5Bトークンの超でかい合成データで小型モデルに蒸留してるのがパンチライン。
面白いのが、教師がデカいほど下流の精度が伸びるって検証もあって、7B教師より72B教師の方が全カテゴリでガッツリ良くなるって。やっぱ教師の質、効くよね。ベンチ結果の見方
- Olmo-Bench: 構造化ドキュメントでの精度を自動テストで評価するやつ。LightOnOCR-1Bは同クラス最強クラスで、パイプライン勢に匹敵しつつ推論はずっと速い。
- OmniDocBench: HTML中心&編集距離(文字の差分)依存でフォーマット差に敏感。LightOnOCRはMarkdownテーブルで出すから、単純な正規表現でHTMLに変換するとスコアがやや不利になりがち。試しにテーブルを最初からHTMLで学習した派生を作ったら、英語全体スコアがグッと改善。つまり「メトリクスがフォーマットにめっちゃ敏感」って話だし。
語彙(トークン)を削るとどうなる?
- 英語/フランス語みたいなラテン系中心なら、32k語彙が最適バランスっぽい。精度ほぼ維持で最速になりやすい感じ。
- 16kはさらに小さいけど、文字種のカバーが減るぶん1ページあたりのトークン数が増えて速度メリットが相殺されがちだし。
- 非ラテン文字(日本語/中国語/アラビア語など) は、削りすぎるとバイトレベル分解に落ちてトークン数が激増してしんどい。つまり、多言語運用したいなら 元の大語彙(151k) が安心。
解像度とか拡張の小ネタ
- 推論時の解像度を上げる(1024→1540px)と、特に小さい文字や旧スキャンで精度がゴリっと上がる。表はちょい下がるケースもあるけど、総合的には上げたほうが強いってデータ。
- 軽めの画像拡張(回転/スケール/格子歪み/微妙な膨張・収縮) は平均では効果ほぼゼロ。ただ、ノイズ強め系でちょい効くから最終モデルには入れてる、ってスタンスだね。
微調整のしやすさ(ここ大事)
エンドツーエンドだから、特定のドメイン(領収書、帳票、学術PDF、電子帳票レイアウトとか)に1エポックの微調整でもスコアがグッと伸びる実例あり。パイプラインだと各コンポーネントごとにラベル付けや手直しが要るけど、単体モデルならデータ用意して回すだけで順当に伸びるの、現場的に超ありがたいでしょ。
どう使うイメージ?
- 大量のPDF→Markdown抽出をして、RAGやクエリ回答に回すフロー。Markdownは軽くて構造保持にちょうどよく、下流処理もしやすいんだよね。
- 表や数式もMarkdown/LaTeXで整うから、技術資料や研究PDFの取り込みに向いてるだし。
- 日本語をガチで使うなら、語彙削り版よりフル語彙版が安心。欧州言語メインなら32kがスピード&精度の最強折衷ってノリ。
デプロイの雰囲気
vLLM でサクッとサーブできるように設計されてる。1ページ1コールでスループット上げやすいし、クラッシュしたらワーカー数を落として安定運用、みたいな評価手順も公開どおり。モデルはここから拾えるよ→ LightOnOCR-1B-1025 (https://huggingface.co/lightonai/LightOnOCR-1B-1025)。
まとめ(ウケるくらい現実的)
- 小型なのにSOTA級の精度、しかも爆速&低コスト。
- Markdown出力で下流処理しやすく、エンドツーエンドで微調整が簡単。
- 英仏中心なら語彙削りでさらに速く、多言語ならフル語彙で安定。
- メトリクスはフォーマットに敏感だから、用途に合わせた出力形式(表をHTMLにする等)で体感品質を引き上げるのがコツだし。
ウチ的には、運用目線で「速い・安い・壊れない・微調整効く」はテンション上がるやつ。実務でPDF山ほどさばくなら、試す価値マジで高いと思うんだよね😉
モデルは3つ
上にも書いてあったけど、日本語だと LightOnOCR-1B-1025、英語・フランス語なら LightOnOCR-0.9B-32k-1025 がよいみたい。
LightOnOCR-1B-1025のモデルカードから抜粋。翻訳はPLaMo翻訳を使用。
LightOnOCR-1B-1025
モデルの完全なBF16バージョンです。さらなるファインチューニングや研究用途には、このバリエーションの使用を推奨します。
LightOnOCR-1B は、光学文字認識(OCR)および文書理解のためのコンパクトでエンドツーエンドの視覚-言語モデルです。本モデルはそのパラメータ規模クラスにおいて最先端の精度を達成しつつ、より大規模な汎用VLMと比較して処理速度が数倍速く、コストも大幅に低減されています。
主な特徴
- ⚡ 処理速度: dots.ocr の 5 倍、PaddleOCR-VL-0.9B の 2 倍、DeepSeekOCR の 1.73 倍の速度
- 💸 効率性: H100 GPU 1台あたり5.71ページ/秒の処理速度を実現(1日あたり約493,000ページ)。1,000ページあたり0.01ドル未満の低コスト運用が可能です。
- 🧠 エンドツーエンド設計: 完全に微分可能で、外部OCRパイプラインが不要
- 🧾 多機能性: 表、領収書、フォーム、複数列レイアウト、数式表記など多様な文書形式に対応
- 🌍 コンパクトなバリエーション: ヨーロッパ言語向けの32k語彙版と16k語彙版を用意
モデル概要
LightOnOCR は、高性能なVision Transformerエンコーダと、高品質なオープンソースVLMから蒸留された軽量なテキストデコーダを組み合わせたモデルです。 文書解析タスクに特化して最適化されており、高解像度ページからレイアウト情報を保持した正確なテキスト抽出を実現します。
ベンチマーク
モデル ArXiv 古いスキャン画像 数式処理 表形式データ 複数列対応 小さなテキスト ベースモデル 総合性能 LightOnOCR-1B-1025(語彙数:151,000) 81.4 71.6 76.4 35.2 80.0 88.7 99.5 76.1 LightOnOCR-1B-32k(語彙数:32,000) 80.6 66.2 73.5 33.5 71.2 87.6 99.5 73.1 LightOnOCR-1B-16k(語彙数:16,000) 82.3 72.9 75.3 33.5 78.6 85.1 99.8 75.4
レンダリングと前処理のポイント
- PDFファイルをPNG形式またはJPEG形式に変換し、最長辺のサイズを1280~1300ピクセルに設定してください。
- テキストの幾何学的形状を保持するため、アスペクト比を維持してください
- LightOnOCRは中程度の傾きには強い耐性を持ちますが、強い回転補正はオプション機能です
- 1ページにつき1枚の画像を使用してください。vLLMによるバッチ処理にも対応しています
すべてのベンチマーク評価は、vLLMを使用してOlmo-Bench上で実施しました。バリエーション
バリエーション 説明 LightOnOCR-1B-1025 完全多言語対応モデル(デフォルト設定) LightOnOCR-1B-32k ヨーロッパ言語向けに最適化された、語彙を削減した最速バージョン(32,000トークン) LightOnOCR-1B-16k 語彙サイズが最も小さい、最もコンパクトなバリエーション ファインチューニング
トレーニングおよび推論用のTransformers統合機能は近日中に公開予定です。
LightOnOCRは完全に微分可能であり、以下の機能をサポートしています:
- LoRAによるファインチューニング
- ドメイン適応(領収書、学術論文、各種フォームなど)
- タスク特化型コーパスを用いた多言語ファインチューニング
データセットの公開に合わせて、ファインチューニングの設定例も提供予定です。
データセット
多様な大規模PDFコーパスで学習済み:
- 学術論文、書籍、領収書、請求書、表、フォーム、手書きテキストなど
- 複数言語対応(ラテン文字使用言語が中心)
- 実際の文書スキャンデータと合成データ
本データセットはオープンライセンスの下で公開されます。
ライセンス
Apache License 2.0
LightOnOCR-1B-1025 のモデルカードによると、どうやらvLLMでサーバを立てるようなので、今回はローカルのUbuntu-22.04サーバ(RTX4090)で。
uvで。
mkdir lightonocr-work && cd $_
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly \
--prerelease=allow
のだが怒られる・・・
× Failed to resolve dependencies for `vllm` (v0.11.1rc3.dev57+g6454afec9.cu129)
╰─▶ Package `triton-kernels` was included as a URL dependency. URL dependencies must be
expressed as direct requirements or constraints. Consider adding `triton-kernels @
git+https://github.com/triton-lang/triton.git@v3.5.0#subdirectory=python/triton_kernels` to your dependencies or
constraints file.
どうやらvLLMのnightly版がtriton-kernelsをgit参照していて、uv pipはこれを許可しないみたい。明示的に追加してやれば良さそう。
uv pip install -U vllm \
"triton-kernels @ git+https://github.com/triton-lang/triton.git@v3.5.0#subdirectory=python/triton_kernels" \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly \
--prerelease=allow
いけたみたい。
(snip)
+ pillow==12.0.0
(snip)
+ requests==2.32.5
(snip)
+ triton-kernels==1.0.0 (from git+https://github.com/triton-lang/triton.git@c3c476f357f1e9768ea4e45aa5c17528449ab9ef#subdirectory=python/triton_kernels)
(snip)
+ vllm==0.11.1rc3.dev57+g6454afec9.cu129
(snip)
続きも。
uv pip install pypdfium2 pillow requests
+ pypdfium2==4.30.0
サーバを起動してモデルをロード
vllm serve lightonai/LightOnOCR-1B-1025 \
--limit-mm-per-prompt '{"image": 1}' \
--async-scheduling
(snip)
(APIServer pid=263283) INFO: Started server process [263283]
(APIServer pid=263283) INFO: Waiting for application startup.
(APIServer pid=263283) INFO: Application startup complete.
ではPDFを推論してみる。サンプルとして、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用する。
PDFをダウンロード
wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
ではこれらのうち、1ページ目と4ページ目をピックアップして試してみる。まず1ページ目。

サンプルコード。
import base64
import requests
import pypdfium2 as pdfium
import io
ENDPOINT = "http://localhost:8000/v1/chat/completions"
MODEL = "lightonai/LightOnOCR-1B-1025"
# PDFファイルのパス
pdf_path = "r5_doukou.pdf"
# PDFを開いて1ページ目を画像に変換
pdf = pdfium.PdfDocument(pdf_path)
page = pdf[0]
# 300 DPI でレンダリング(スケール係数 = 300/72 ≈ 4.17)
pil_image = page.render(scale=4.17).to_pil()
# base64に変換
buffer = io.BytesIO()
pil_image.save(buffer, format="PNG")
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
# リクエスト
payload = {
"model": MODEL,
"messages": [{
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_base64}"}
}]
}],
"max_tokens": 6500,
"temperature": 0.2,
"top_p": 0.9,
}
response = requests.post(ENDPOINT, json=payload)
text = response.json()['choices'][0]['message']['content']
print(text)
実行
time uv run pdf_inference_sample.py
結果
# 令和5年度 神戸市観光動向調査結果について
## 調査目的
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。
## 調査方法
調査員が対面にてアンケート項目を聞き取りする形で実施。
## 調査日
1. 令和5年5月13日(土)・20日(土)
2. 令和5年9月9日(土)
3. 令和5年11月25日(土)/12月2日(土)
4. 令和6年2月10日(土)・17日(土)・24日/3月30日(土)
※雨天等により、一部の調査地点については延期して実施。
## 調査地点
| 地区 | NO | 調査地点 | サンプル数 |
|------------|----|--------------------------------------------------------------------------|------------|
| 北野 | 1 | 北野町広場 | 246 |
| | 2 | 北野工房のまち | 154 |
| | 3 | 南京町広場 | 218 |
| | 4 | 総合インフォメーションセンター | 198 |
| | 5 | 旧居留地 | 201 |
| | 6 | 神戸布引ロープウェイハーブ園山麓駅 | 203 |
| | 7 | 白鶴酒造資料館内 | 205 |
| | 8 | 玉子動物園内 | 235 |
| | 9 | 県立美術館前 | 217 |
| | 10 | さんちか夢広場 | 208 |
| | 11 | 神戸空港屋上階展望ロビー | 212 |
| | 12 | I K E A神戸 | 192 |
| | 13 | 能福寺(兵庫大仏) | 147 |
| | 14 | 兵庫津ミュージアム | 204 |
| 神戸港 | 15 | 神戸海洋博物館前及び周辺 | 200 |
| | 16 | 中突堀中央ターミナル周辺 | 208 |
| | 17 | u m i eモザイク | 201 |
| | 18 | ハーバーランド総合インフォメーション前 | 213 |
| 六甲・摩耶 | 19 | 六甲天駒台 | 209 |
| | 20 | 摩耶山樹皇台広場 | 200 |
| | 21 | 六甲山牧場内 | 215 |
| | 22 | 六甲ガーデンテラス内 | 211 |
| 有馬 | 23 | 有馬温泉観光総合案内所前 | 214 |
| | 24 | 金の湯前 | 216 |
| | 25 | 六甲有馬ロープウェイ有馬温泉駅 | 232 |
| 須磨・舞子 | 26 | 須磨避宮公園 | 202 |
| | 27 | ドゥ子公園(舞子海上プロムナード) | 230 |
| 西北神 | 28 | 神戸ワイナリー(農業公園) | 235 |
| | 29 | 神戸フルーツ・フラワーバーク大沢園内 | 209 |
| | 30 | 神戸三田プレミアム・アウトレット | 215 |
合計 | 6,250
表組は一番下で失敗してるけど他はOK。ただ、いくつかうまく文字を読み取れてない箇所があるね。
ちなみにvLLMを起動した直後のKVキャッシュがない状態だと速度はこんな感じ。
real 0m8.541s
user 0m4.469s
sys 0m0.059s
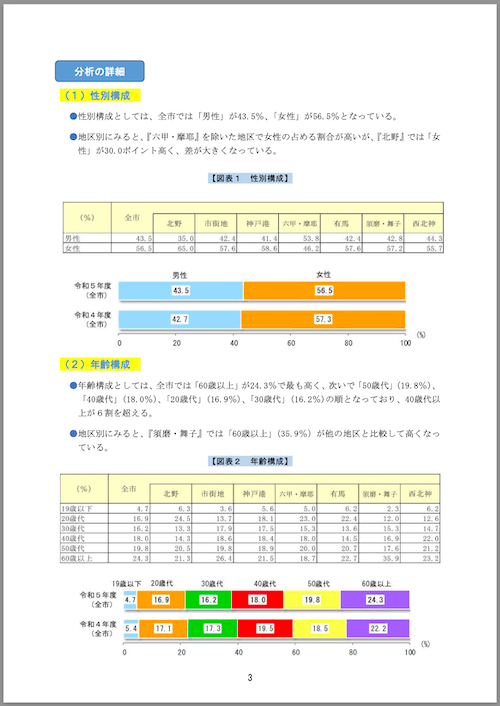
次に4ページ目。こちらはグラフが画像として埋め込まれている。
スクリプトを以下のように修正して実行。
(snip)
pdf = pdfium.PdfDocument(pdf_path)
page = pdf[3] # 変更
(snip)
結果
# 分析の詳細
## (1)性別構成
- 性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
- 地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
### 【図表 1 性別構成】
| (%) | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 須磨・舞子 | 西北神 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 男性 | 43.5 | 35.0 | 42.4 | 41.4 | 53.8 | 42.4 | 42.8 | 44.3 |
| 女性 | 56.5 | 65.0 | 57.6 | 58.6 | 46.2 | 57.6 | 57.2 | 55.7 |

## (2)年齢構成
- 年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代」(16.2%)の順となっており、40歳代以上が6割を超えている。
- 地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっている。
### 【図表 2 年齢構成】
| (%) | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 須磨・舞子 | 西北神 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 19歳以下 | 4.7 | 6.3 | 3.6 | 5.6 | 5.0 | 6.2 | 2.3 | 6.2 |
| 20歳代 | 16.9 | 24.5 | 13.7 | 18.1 | 23.0 | 22.4 | 12.0 | 12.6 |
| 30歳代 | 16.2 | 13.3 | 17.9 | 17.5 | 15.3 | 13.6 | 15.3 | 14.7 |
| 40歳代 | 18.0 | 14.3 | 18.6 | 18.4 | 18.0 | 14.5 | 16.9 | 22.0 |
| 50歳代 | 19.8 | 20.5 | 19.8 | 18.9 | 20.0 | 20.7 | 17.6 | 21.2 |
| 60歳以上 | 24.3 | 21.3 | 26.4 | 21.5 | 18.7 | 22.7 | 35.9 | 23.2 |

こちらは表はそれっぽく読めてるのだけど、グラフの部分は画像リンクになっている。果たしてこの画像は取得できるんだろうか???レスポンスの中身を見てみたけど、画像については見当たらなかった。
あとちょっと気になったのはたまにvLLMがクラッシュする。
terminate called after throwing an instance of 'c10::AcceleratorError'
what(): CUDA error: device-side assert triggered
Search for `cudaErrorAssert' in https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html for more information.
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
んー、ちょっとわからん。vLLMがnightlyだからなのか、モデルになにか問題があるのか、なおま環なのか・・・
まとめ
サイズも軽量で確かに高速。精度もまあまあ。サイズ感からすれば高いと思う。ただし
- 多少文字の認識ミスがあった。
- 表も惜しい、セル結合された箇所をうまく取れてなkった。
- たまにクラッシュする
- 文書内の画像はどうすれば???
あたり、精度もそうだけど、いろいろこなれてない感があるかなぁ・・・
個人的には表をMarkdownで出力してくれるのはHTMLよりも好み。まあMarkdownだと複雑な表の表現に限界はありそうなのだけどね・・・あとサイズが小さくて速いってのはそれだけでメリットあると自分は思っているので、期待したいなぁ。
とりあえずvLLMでちゃんと動く(クラッシュしない)ようになってほしいところ。あとどうやらtransformersでもマージされそうなのでうごかしやすくなりそう。
Llama.cppで対応されていた。