VALL-E X の OSS実装を試す
本家
OSS実装
- Multilingual TTS: Speak in three languages - English, Chinese, and Japanese - with natural and expressive speech synthesis.
- Zero-shot Voice Cloning: Enroll a short 3~10 seconds recording of an unseen speaker, and watch VALL-E X create personalized, high-quality speech that sounds just like them!
- Speech Emotion Control: Experience the power of emotions! VALL-E X can synthesize speech with the same emotion as the acoustic prompt provided, adding an extra layer of expressiveness to your audio.
- Zero-shot Cross-Lingual Speech Synthesis: Take monolingual speakers on a linguistic journey! VALL-E X can produce personalized speech in another language without compromising on fluency or accent. Below is a Japanese speaker talk in Chinese & English. 🇯🇵 🗣
- Accent Control: Get creative with accents! VALL-E X allows you to experiment with different accents, like speaking Chinese with an English accent or vice versa. 🇨🇳 💬
- Acoustic Environment Maintenance: No need for perfectly clean audio prompts! VALL-E X adapts to the acoustic environment of the input, making speech generation feel natural and immersive.
うちのChatGPTちゃんのまとめ
1️⃣ 多言語TTS(テキスト・トゥ・スピーチ)
英語、中国語、日本語の3つの言語で、自然で表現豊かな音声合成ができるよ🗨️🎵2️⃣ ゼロショット音声クローニング
見たことない話者の短い3〜10秒の録音を登録するだけで、その人にそっくりな高品質な音声をVALL-E Xが生成してくれるよ🎤✨3️⃣ 音声感情制御
感情の力を体験しよう!VALL-E Xは、提供された音響プロンプトと同じ感情で音声を合成できるから、オーディオにさらなる表現力が加わるよ😄🎶4️⃣ ゼロショットクロスリンガル音声合成
一言語話者を言語の旅に連れて行こう!VALL-E Xは、流暢さやアクセントを損なわずに、別の言語で個別化された音声を生成できるよ🌏🗨️ 例えば、日本語話者が中国語と英語で話す場合とかね🇯🇵🗣5️⃣ アクセント制御
アクセントで遊ぼう!VALL-E Xは、中国語を英語のアクセントで話すとか、その逆もできるよ🇨🇳💬6️⃣ 音響環境維持
完全にクリーンな音声プロンプトは必要ないよ!VALL-E Xは入力の音響環境に適応するから、音声生成が自然で没入感があるんだよ🎧🌈
上記GitHubの"Features"に生成されたデモ音声がある。あとは以下にも。
HuggingFace Spaceのデモはこちら。
数秒程度の生成でも1分ぐらいかかるのと、あとちょいちょいエラーになる。どうもデモに割り当てられているインスタンスがCPUベースのものらしい。GPUなら数秒で生成されるとのこと。
ということで、Colabの手順を見てみる。
内容はこんな感じ。
# This takes about 4 minutes until the UI pop up
!git lfs install
!git clone https://huggingface.co/spaces/Plachta/VALL-E-X
%cd VALL-E-X
!pip install --no-build-isolation -r requirements.txt
!pip install gradio
%run app.py
確かColabで無料ユーザの場合はWeb UIが禁止になってたはず。
有料は大丈夫っぽいのだけど、一応手元で。Core i9-13900F / RTX4090 / rye / python-3.11.3でやってみた。
$ rye init wall-e-x-sample
$ cd wall-e-x-sample
$ git lfs install
$ ls src # src配下のディレクトリ名を確認
$ rm -rf src
$ git submodule add https://huggingface.co/spaces/Plachta/VALL-E-X src/wall_e_x_sample # 確認したディレクトリ名に合わせる
$ cat src/wall_e_x_sample/requirements.txt | xargs rye add
$ rye add gradio
$ rye sync
なのだけどrye syncするとpyopenjtalkのビルドで色々躓く。
- clangが見つからない
- cmakeが見つからない
-
#include <fstream>でfstreamが見つからない
結論から言うと以下のパッケージを先に入れておく必要があった。
$ sudo apt-get install clang cmake install g++-12
gccやmakeやその他一般的なライブラリ等は元々入れてあって、cmakeとか過去に困ったことがないのだけどもなー。pyenv/pyenv-virtualenvでも試してみた感じだとg++-12とかなくてもエラー起きないし。
多分だけど、元のnotebookではpip install --no-build-isolation ...となっているのをryeで実現する方法が分からなくて雑にaddしたのが良くなかったのではないかという気がしてる。
--no-build-isolationについてはこの辺。
rye syncできたらapp.pyを実行する。初回はモデルのダウンロードが行われるので多少時間がかかる。
$ cd src/wall_e_x_sample
$ rye run python app.py
なお、うちの環境はLAN内のサーバなので以下だけ修正してある。
app.launch(server_name="192.168.X.X")
あとLAN内のサイトに対してブラウザでマイクを有効にするには以下あたりも設定が必要。
ダウンロードが終わるとgradioのUIが立ち上がる。
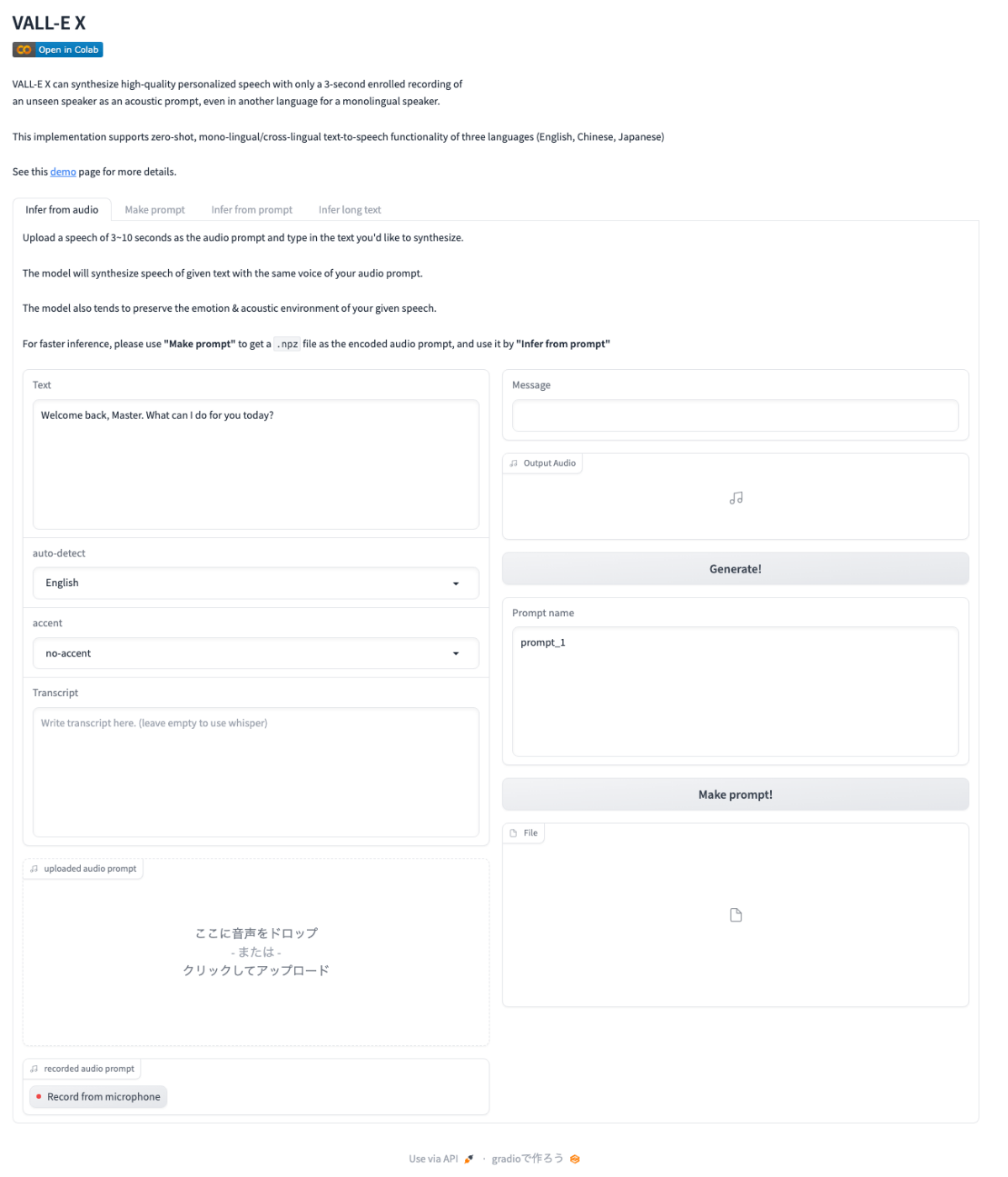
タブからは4つのメニューがあることがわかる。
- Infer from audio
- Make prompt
- Infer from prompt
- Infer long text
でVALL-E-Xにおける「プロンプト」というのは、LLMやStable Diffusionのような「テキストプロンプト」ではなく、入力として使う音声データ、つまり「音響プロンプト」のことを指す。これを踏まえると各メニューの機能は
-
- Make prompt
- 音声をその場で録音するか、音声データファイルをアップロード。
- 音声データの発話内容をテキストで入力。ただしこれはオプションで、入力しなければWhisperでSTTされる。
- 音響プロンプトファイルをとして出力。
-
- Infer from prompt
- 2の音響プロンプトファイルを使って、TTSを行う
-
- Infer from audio
- 上記の2と3を1画面で行うもの
と考えれば良い。
で、1と3には制限があり、発話内容のテキストは150文字(日本語の場合でも同様)までとなっている。この制限を外す感じで、
-
- Infer long text
- 発話内容のテキストは1000文字(日本語の場合でも同様)まで
という感じになってるっぽい。
あと音響プロンプトも15秒までとなっていて、このあたりの制限はapp.pyの中で明示的に書かれているので。vall-e-x的な制限ではなさそうだけど、変更してどうなるかまでは試してない。
一応pyenv/pyenv-virtualenvだとこんな感じでサクッと入るのではなかろうか。
$ pyenv virtualenv 3.10.11 vall-e-x-sample
$ mkdir vall-e-x-sample && cd vall-e-x-sample
$ pyenv local vall-e-x-sample
$ git lfs install
$ git clone https://huggingface.co/spaces/Plachta/VALL-E-X
$ cd VALL-E-X
$ pip install numpy cython wheel
$ pip install --no-build-isolation -r requirements.txt
$ pip install gradio
$ run app.py
nvidia-smiでみるとGPUは7GBぐらいで収まりそう。
所感
この手のやつはあくまでも個人的な感想にしかならないと思うのでその前提で。
- 自分の音声を使ってやってみたけど、単純な日本語→日本語は普通に大きな違和感はなし。
- イントネーションとか多少はあるけども、それはSTT全般に言える話
- AlexaやGoogleなどに比べると流暢な気はするけど、Voicepeakには負けてると思う。
- ただ、英語や中国語などの別言語を生成、かつアクセントを指定、にすると、テキスト通りに生成されなかったり、違和感がある結果になる事が結構あった。
- 音響プロンプトの品質?にもよるのかもしれない。
- VALL-E-Xには音響環境に依存しないとあるのでそこが問題ないとなれば、音響プロンプトの発話内容(こういう音響プロンプトを用意しておけばうまく生成されやすい、みたいな)とかあるのかも。
- あとは声質とかもありそう
デモの音声は結構いい感じに思えたので勝手に期待高くしてた分、まあこんなものかー、というところ。個人的には以前に試したberk-with-voice-cloneと基本的にできることは同じで、あっちのほうが衝撃度合いは高かったかなー。文字通りのプロンプトで語調を制御したりってのもできたし。
ElevenLabsあたりが出してる音声クローンの方がもっとすごそうなんだけど、とはいえあちらも実際に試したことはないし。単にデモがすごいだけっていう可能性はある。
自分的にはそこまでには思えず、とはいえ評価する声も多そう、というところで、実際に試してみて判断することをオススメ。
ちなみに、bark-with-voice-cloneについては、
- どうもレポジトリの更新は止まってそう
- 自分が以前に書いたnotebookも"not working"というツッコミだけ入ってた(それだけでわかるかボケ、と思って調べずに無視した)
という感じなので、あくまでも参考ということで。
なんとなくだけど、カスタム音声でのTTSって、よほど声に価値があるケースを除いて、あんまり需要ないのかなーという気がしてる。いいユースケースが見つかってないだけかもしれないけど。
大事なことを忘れていた。MITライセンスだね。
なるほど。その観点はなかった。