Pythonで画像からテキスト抽出(OCR)いろいろ
スクレイピングでHTMLを舐めるのが辛いので、OCRしてしまえばいいのではないか、と思いついた。
ということで、画像からテキストを抽出するためのライブラリをいくつか試してみる。
- Tesseract(pytesseract)
- easyOCR
- PaddleOCR
- Surya OCR
- ocrmac
PDFからの抽出は以下の参考に。
画像は自分の記事をスクレイピングして画面キャプチャしたものを使う
Tesseract(pytesseract)
%%bash
apt update
apt install -y tesseract-ocr
pip install pytesseract
日本語で使う場合には訓練データが別途必要になる。訓練データは、3種類、標準・fast・bestがあってて、Ubuntu・Debianでは別パッケージになっている模様(tesseract-ocr-jpn)。ただこれにはfastしか含まれていないっぽい?ので、今回は公式のGithubレポジトリから全部を持ってきた。
%%bash
mkdir -p tessdata tessdata_fast tessdata_best
wget https://github.com/tesseract-ocr/tessdata/raw/main/jpn.traineddata -P tessdata
wget https://github.com/tesseract-ocr/tessdata/raw/main/jpn_vert.traineddata -P tessdata
wget https://github.com/tesseract-ocr/tessdata_fast/raw/main/jpn.traineddata -P tessdata_fast
wget https://github.com/tesseract-ocr/tessdata_fast/raw/main/jpn_vert.traineddata -P tessdata_fast
wget https://github.com/tesseract-ocr/tessdata_best/raw/main/jpn.traineddata -P tessdata_best
wget https://github.com/tesseract-ocr/tessdata_best/raw/main/jpn_vert.traineddata -P tessdata_best
環境変数TESSDATA_PREFIXで読み込む訓練データのディレクトリを変えれば、それぞれを試すことができる。
ということで比較。レイアウト検出などもあるので、ページ冒頭部分と記事本文冒頭部分の2箇所の結果を記載する。
標準
import os
from PIL import Image
import pytesseract
os.environ["TESSDATA_PREFIX"] = "tessdata"
print(pytesseract.image_to_string(Image.open('capture.png'), lang='jpn'))
ページ冒頭

記事本文冒頭

fast
os.environ["TESSDATA_PREFIX"] = "tessdata_fast"
print(pytesseract.image_to_string(Image.open('capture.png'), lang='jpn'))
ページ冒頭

記事本文冒頭

best
os.environ["TESSDATA_PREFIX"] = "tessdata_best"
print(pytesseract.image_to_string(Image.open('capture.png'), lang='jpn'))
ページ冒頭

記事本文冒頭

3つの中だとFastが一番良いという結果に。
easyOCR
!pip install easyocr
import easyocr
reader = easyocr.Reader(['ja','en'], gpu=True)
results = reader.readtext('capture.png')
for r in results:
print(r)

なぜか全然ダメな感じに。
記事本文冒頭部分だけをクリップしてリトライしてみた。
results = reader.readtext('capture2.png')
for r in results:
print(r)

こちらは問題なし。
レイアウトとかにも強そうな感はあるので、入力データがでかすぎるとダメとかなのかな?
PaddleOCR
カーネルの再起動が必要になる。
!pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install "paddleocr>=2.0.1"
from paddleocr import PaddleOCR,draw_ocr
ocr = PaddleOCR(use_angle_cls=True, lang='japan')
result = ocr.ocr("capture.png", cls=True)
print(result)
ただresultが[None]になってしまうのよなぁ。。。
easyOCRと同じように一部だけだとうまくいく。
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='japan')
result = ocr.ocr("capture2.png", cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)

Surya OCR
カーネル再起動が必要になるので注意。
!pip install surya-ocr
from PIL import Image
from surya.ocr import run_ocr
from surya.model.detection import segformer
from surya.model.recognition.model import load_model
from surya.model.recognition.processor import load_processor
image = Image.open("capture.png")
langs = ["ja","en"]
det_processor, det_model = segformer.load_processor(), segformer.load_model()
rec_model, rec_processor = load_model(), load_processor()
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
うーん、CUDA out of memory...
一部だけの画像でやり直す。
image = Image.open("capture.png")
langs = ["ja","en"]
det_processor, det_model = segformer.load_processor(), segformer.load_model()
rec_model, rec_processor = load_model(), load_processor()
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
for tl in predictions[0].text_lines:
print(tl.polygon, tl.text, tl.confidence)
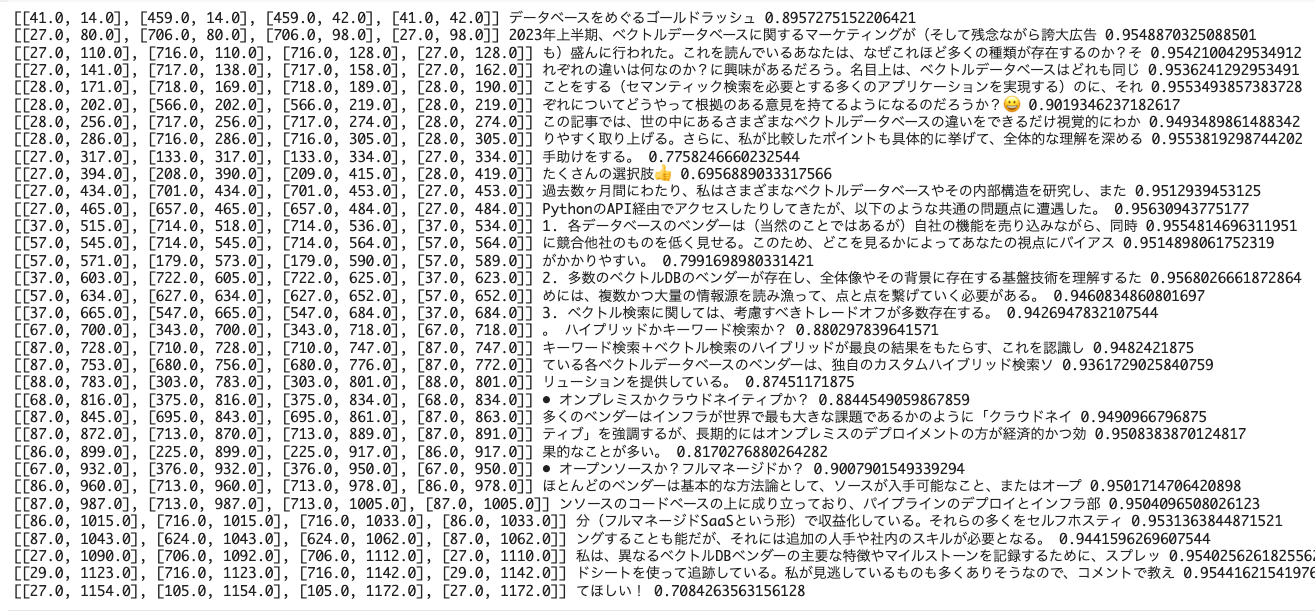
ocrmac
MacのVenturaあたりからプレビュー.appで自動でOCRされるようになったやつをPython経由で使える。
!pip install ocrmac
でこれもでかすぎるとダメ。何も返さない。 よって一部抜粋で。
from ocrmac import ocrmac
annotations = ocrmac.OCR('capture2.png', language_preference=['ja-JP']).recognize()
for a in annotations:
print(a)

ちょっとサンプルとして使う画像のチョイスが悪かったかもしんない。
画像は自分の記事をスクレイピングして画面キャプチャしたものを使う
今回の画像のフォーマット
- 1185 x 19047px
- 4.3MB
って感じで、推測だけど、ファイルサイズってよりは画像のサイズ(縦横比とかそっち)がよくなくて、Tesseract以外はうまくいかなかったんじゃなかろうかと。もうちょっと考えたほうが良かったかも。
とりあえずいったんまとめ
- そんな中でもTesseractは普通に全部読み取っていたのはすごい。
- なお、Tesseractだとfastが最も良い、というか、使いやすい感。
- 全体的にはどれ選んでもそれなりに満足できる感じの認識じゃないかなぁと思う。あまり大きな差は感じなかった。
- Surya OCRは唯一絵文字を認識していたってのは特徴かもしれない。
最初に書いた通り、目的はWebサイトのスクレイピングで、Seleniumとかでもできなくはないけどいろいろ辛みもあって、OCRとかマルチモーダルLLMでできると楽かなぁと思っている。