PDFを読みやすいフォーマットに変換する「MinerU」を試す
ここで知った。
GitHubレポジトリ
MinerU
プロジェクト紹介
MinerUは、PDFを機械可読形式(例:MarkdownやJSON)に変換するツールで、どのような形式にも簡単に抽出できるようにします。このツールは、InternLMの事前学習プロセス中に誕生しました。私たちは科学文献における記号変換の問題を解決することに重点を置き、大規模モデルの時代における技術開発に貢献することを目指しています。
MinerUは有名な商業製品と比較するとまだ若いツールです。もし何か問題が発生したり、期待通りの結果が得られない場合は、該当するPDFを添付してIssueに報告してください。
主な特徴
- ヘッダー、フッター、脚注、ページ番号などを削除し、文意の一貫性を確保。
- 人間が読める順序でテキストを出力し、単一列、多列、複雑なレイアウトに対応。
- 見出し、段落、リストなど、元の文書の構造を保持。
- 画像、画像の説明、表、表のタイトル、脚注を抽出。
- 文書内の数式を自動認識し、LaTeX形式に変換。
- 文書内の表を自動認識し、HTML形式に変換。
- スキャンされたPDFや文字化けしたPDFを自動検出し、OCR機能を有効化。
- OCRは84言語の検出と認識に対応。
- マルチモーダルやNLP用Markdown、読取順序で整理されたJSON、リッチな中間フォーマットなど、複数の出力形式をサポート。
- レイアウトの可視化やスパンの可視化など、出力品質を効率的に確認できる様々な可視化結果をサポート。
- CPUおよびGPU環境に対応。
- Windows、Linux、Macプラットフォームに対応。
Quick Startに従って進めてみるが、
- オンラインデモ(安定版: OpenDataLab、テスト版: HuggingFace・ModelScope)
- CPU(Windows/Linux/Mac)
- GPU(CUDA・Windows/Linux
の3種類の方法があり、ハードウェア・ソフトウェアの要件が記載されている。
項目 Ubuntu 22.04 LTS Windows 10 / 11 macOS 11以上 オペレーティングシステム Ubuntu 22.04 LTS Windows 10 / 11 macOS 11以上 CPU x86_64(ARM Linuxは未対応) x86_64(ARM Windowsは未対応) x86_64 / arm64 メモリ 16GB以上(推奨: 32GB以上) 16GB以上(推奨: 32GB以上) 16GB以上(推奨: 32GB以上) Pythonバージョン 3.10(Python 3.10仮想環境をcondaで作成してください) 3.10(Python 3.10仮想環境をcondaで作成してください) 3.10(Python 3.10仮想環境をcondaで作成してください) Nvidiaドライバーバージョン 最新版(Proprietary Driver) 最新版 なし CUDA環境 自動インストール [12.1(pytorch)+ 11.8(paddle)] 11.8(手動インストール)+ cuDNN v8.7.0(手動インストール) なし GPUハードウェア対応リスト GPU VRAM 8GB以上(全アクセラレーション機能を有効化可能) GPU VRAM 8GB以上(全アクセラレーション機能を有効化可能) なし 対応GPU 2080~2080Ti / 3060Ti~3090Ti / 4060~4090 2080~2080Ti / 3060Ti~3090Ti / 4060~4090 なし
※Markdownなので表は少し書き換えている。
とりあえず自分はGPU使用で、一番環境依存が少なそうなDockerでやってみようと思う。
- Ubuntu 22.04
- RTX4090(VRAM24GB)
まず、対応しているかを確認
docker run --rm --gpus=all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi
Tue Nov 26 01:20:11 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 38C P8 4W / 450W | 204MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
+-----------------------------------------------------------------------------------------+
問題なさそう。
作業ディレクトリを作成
mkdir miner-u-test && cd miner-u-test
Miner UのDockerfileをダウンロード
wget https://github.com/opendatalab/MinerU/raw/master/Dockerfile
中身はこんな感じ
# Use the official Ubuntu base image
FROM ubuntu:22.04
# Set environment variables to non-interactive to avoid prompts during installation
ENV DEBIAN_FRONTEND=noninteractive
# Update the package list and install necessary packages
RUN apt-get update && \
apt-get install -y \
software-properties-common && \
add-apt-repository ppa:deadsnakes/ppa && \
apt-get update && \
apt-get install -y \
python3.10 \
python3.10-venv \
python3.10-distutils \
python3-pip \
wget \
git \
libgl1 \
libglib2.0-0 \
&& rm -rf /var/lib/apt/lists/*
# Set Python 3.10 as the default python3
RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 1
# Create a virtual environment for MinerU
RUN python3 -m venv /opt/mineru_venv
# Activate the virtual environment and install necessary Python packages
RUN /bin/bash -c "source /opt/mineru_venv/bin/activate && \
pip3 install --upgrade pip && \
wget https://gitee.com/myhloli/MinerU/raw/master/requirements-docker.txt && \
pip3 install -r requirements-docker.txt --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple && \
pip3 install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/"
# Copy the configuration file template and install magic-pdf latest
RUN /bin/bash -c "wget https://gitee.com/myhloli/MinerU/raw/master/magic-pdf.template.json && \
cp magic-pdf.template.json /root/magic-pdf.json && \
source /opt/mineru_venv/bin/activate && \
pip3 install -U magic-pdf"
# Download models and update the configuration file
RUN /bin/bash -c "pip3 install modelscope && \
wget https://gitee.com/myhloli/MinerU/raw/master/scripts/download_models.py && \
python3 download_models.py && \
sed -i 's|cpu|cuda|g' /root/magic-pdf.json"
# Set the entry point to activate the virtual environment and run the command line tool
ENTRYPOINT ["/bin/bash", "-c", "source /opt/mineru_venv/bin/activate && exec \"$@\"", "--"]
ビルド。結構時間がかかる。
docker build -t mineru:latest .
Dockerコンテナを起動してコンテナに入る。ローカルの作業ディレクトリをマウントしておくと良い。
docker run \
--rm \
-it \
--gpus=all \
-v .:/root/work \
mineru:latest /bin/bash
Miner Uというプロジェクト名だけど、CLIはmagic-pdfという名前になっているみたい。
magic-pdf -v
import tensorrt_llm failed, if do not use tensorrt, ignore this message
import lmdeploy failed, if do not use lmdeploy, ignore this message
magic-pdf, version 0.10.1
ちょっとwarningっぽいものが出ているけど、とりあえずはいいかな。
基本的な使い方を見ていく。以降はコンテナ内の作業。
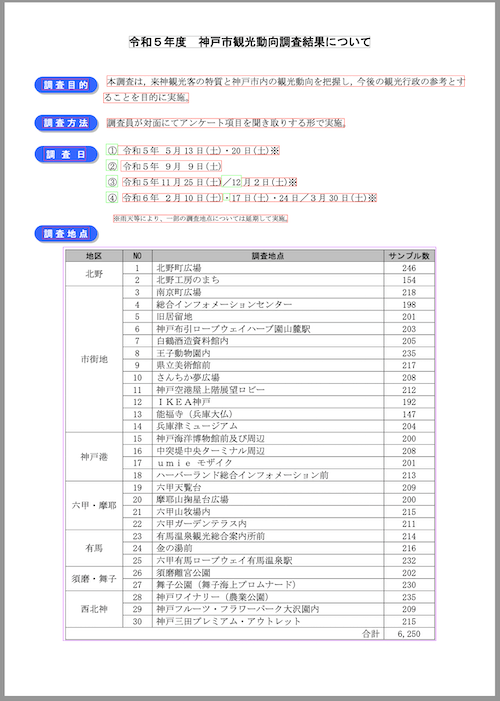
サンプルとして使用するPDFは、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用させていただく。
作業ディレクトリをマウントしたディレクトリに移動
cd ~/work
PDFをダウンロード
wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
PDFを読み込み。-pでPDFを指定して、-oで結果出力するディレクトリを指定する。
magic-pdf -p r5_doukou.pdf -o output -m auto
少し時間が掛かるが以下のように表示されればOK。
2024-11-26 04:08:23.134 | INFO | magic_pdf.pipe.UNIPipe:pipe_mk_markdown:61 - uni_pipe mk mm_markdown finished
2024-11-26 04:08:23.165 | INFO | magic_pdf.pipe.UNIPipe:pipe_mk_uni_format:56 - uni_pipe mk content list finished
2024-11-26 04:08:23.166 | INFO | magic_pdf.tools.common:do_parse:183 - local output dir is output/r5_doukou/auto
こんな感じで出力される。
apt update && apt install -y tree
tree output
output/
`-- r5_doukou
`-- auto
|-- images
| |-- 0127921889fc2dd2ce860b469df0254bd7e7c3fac82403b6a58bb2cdd760eedf.jpg
| |-- 12c4019bdc5b55fdcf620409c7cc4b492ee7075c8324d4d237c407b1cc604a4f.jpg
| |-- 18458820931e6c3a8289ba128c523d81f7b73c1425592518c7be4fd9dc9ebf26.jpg
| |-- 19b6e6d1b52535d3f4d069b642723702932e346dc72f6aa57603b304103a7c33.jpg
| |-- 1b91b6f5acaa5fd4ac3ff7d2359032f40f692c30c82f19567dad46ee0ab19f43.jpg
| |-- 29ed2763bfac5c0a72f3e6b1289230a69b4daa61cd1d24d17c1474c06d13007e.jpg
| |-- 34fb4bbca00c04c1fa9b7ed8176a807ecfe93eaf0b51ce986e0c229123f83a05.jpg
| |-- 4742fd5f51ce3ba83bbe21e050737aacdb5ead7a6783ebfb06acdff6d49cddff.jpg
| |-- 4d97a88634547268695a74da2aeee9ad908dbb9f660c0a662b91a813be4b5384.jpg
| |-- 507472230480fb8c07f1eb876f5a2dffaf53e7014991bdb2273938132e15a858.jpg
| |-- 591dc1930c9b62816d47e974ce8bbebe4a74771bd154e84e432dc3c1ec179bbe.jpg
| |-- 5d309ff27c7f03660088f3b8d1ae0d0fde837797b3aef969fc24a0e054c2dbea.jpg
| |-- 6012700f539ecd70b360d25b81eb88a4bc2cdfa1022b10dcf16b4a2da5e8b999.jpg
| |-- 633d581f0bc247548f90d8f57de8d2dd456f5dd0febcef0f7ab3f68df48a5f33.jpg
| |-- 66864b88a8b50d5344c48a3711f41ca6f91070f0062e1261dbff12fc20b9ad31.jpg
| |-- 6721237b61ece8da68ef743d3e2367be0d8d3510811f505aedf55bcce049e73a.jpg
| |-- 6baf6bb976928989e5072c0a94c59d65c581c6cd51dc671d85db50d54f93f57a.jpg
| |-- 6e021cd82eabe145c0f3046fb00281c9977315ec872235eb264e3b19855ed355.jpg
| |-- 736639ac2ef07d392c83ea9f7f3cd8cf71a05bdfeb89a25dd6d213234873098c.jpg
| |-- 742d76bb6a3f519fdeba82f96d0244f03c122cabacc467866ebfb1548d81f685.jpg
| |-- 7f78a13c3ec79a4734e4c6b61e862e55c982e5cc43b99f1a3256f4e045dc1497.jpg
| |-- 832bc34aef102a5fb9e2d90f3b936f2d2e1a9f5b68391f7f98bdbc70c73d2443.jpg
| |-- 8653f94ea3d535085e0cd636170dbae8bdb22176615c5bc70970dc4bdd302b73.jpg
| |-- 8b5727d8d44d9fcf1a9eefe1df8ecfd8db016e97ebafa6417860f85325ca941a.jpg
| |-- 8ca8827c3af34711255d4303b4491bdc87c76c54d7b7193bb2f95d278dc56fcb.jpg
| |-- 91c7ab51f02a51914bfedf80ae2bf3dfeab98d43906d187e56fde54c9e3f42fa.jpg
| |-- 91d57f74a06d5e650845f5a1483ef68c07ecb68321c39a20c6dafc661c7f5d3f.jpg
| |-- a7616445e76e51eb3ab53eb326d3818849275fd24d8bc1824aeccd1ec3c75885.jpg
| |-- a840fb9ea7bc8342af16f0059511a765f4ed2baf23d4a7113fcc067fcba92487.jpg
| |-- ae68d9c4014183333ca968cd8c9b29e482d5e209e4e8984b16b44c573939a041.jpg
| |-- b53f94f1c44addd148440576d8fdd459b5edbc9085f9f14edc32b049e3bcceb7.jpg
| |-- b912c1778fbbe0a3af869c7437efd235b1e8f871371eb729a8cc1223bf71fdb5.jpg
| |-- c08541a1bd69caec3ef17746e4f5e9ca0ca2143c4d43cdcafef5f1a8043a3c02.jpg
| |-- dd04421ee0b96a13880fcdf19e5b23ba1bfdbb23b1d42f2fa74eeebb5d2b1263.jpg
| |-- e132f4f314f32f18731bee042b2b37024b8d68526bb6dd51f4ed79a4a8494d87.jpg
| |-- eb7352928e52baf5842af8854c80e1bcde91ef9b853acc1c92d2959aeb9f1376.jpg
| |-- ee35fb24c032d6a40d240ac77a73eee88189c6165c8949bb8b284343d83b7346.jpg
| |-- f2937d54ae44a85a13c3902b5f3eb55f0ab6f0023b978a45a8218a0a83bfa636.jpg
| |-- f351a0e0032b14a9cc61a1a5d7e1ac845cab3b53a7b71eed015f42926c79ffa2.jpg
| `-- fab83a9b31c7d118ca4c3b9ff70f18eac49c99ca6444e30ac63546db06f6da5d.jpg
|-- r5_doukou.md
|-- r5_doukou_content_list.json
|-- r5_doukou_layout.pdf
|-- r5_doukou_middle.json
|-- r5_doukou_model.json
|-- r5_doukou_origin.pdf
`-- r5_doukou_spans.pdf
3 directories, 47 files
出力されるファイルの説明は以下にあるが、
ざっくりだとこんな感じ。
-
◯◯◯.md: Markdownファイル -
◯◯◯_layout.pdf: レイアウト図(レイアウトの読み込み順を含む) -
◯◯◯_middle.json: MinerUの中間処理結果 -
◯◯◯_model.json: モデル推論結果 -
◯◯◯_origin.pdf: 元のPDFファイル -
◯◯◯_spans.pdf: 最小粒度bbox位置情報図 -
◯◯◯_content_list.json: 読み上げ順に並べたリッチテキストJSON -
images/: 画像保存用ディレクトリ
順番に見ていく。抜粋で。
◯◯◯.md: Markdownファイル
1ページ目
# 調査目的
本調査は,来神観光客の特質と神戸市内の観光動向を把握し,今後の観光行政の参考とすることを目的に実施。
調 査 方 法
調査員が対面にてアンケート項目を聞き取りする形で実施。
調査日
$\textcircled{1}$ 令和5年 5月13 日(土)・20 日(土)※
$\textcircled{2}$ 令和5年 9月 9日(土)
$\textcircled{3}$ 令和5年11 月25 日(土) $\angle12$ 月2日(土)※
$\circledast$ 令和6年 2月10 日(土) $\cdot$ 17 日(土)・24 日/3月30 日(土)※
※雨天等により、一部の調査地点については延期して実施。
# 調査地点

4ページ目
# 分析の詳細
性別構成としては、全市では「男性」が $43.\,5\%$ 、「女性」 $\%56.\,5\%$ となっている。
$\bullet$ 地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
# 【図表1性別構成】


(2)年齢構成
年齢構成としては、全市では「60歳以上」 $)\mathrm{{\ddot{\Omega}}24.\ 3\%}$ で最も高 $\bigstar$ 、次いで「50歳代」 $(19.\,8\%)$ )、「40歳代」 $\left\langle18.\ 0\%\right.$ )、「20歳代」( $16.\,9\%$ )、「30歳代」( $16.\,2\%$ ) $\mathcal{O}$ 順とな $\supset$ ており、40歳代以上が6割を超える。
地区別にみると、『須磨・舞子』では「60歳以上」( $35.\,9\%$ )が他 $\mathcal{O})$ 地区と比較して高くなっている。
【図表2年齢構成】


◯◯◯_layout.pdf: レイアウト図(レイアウトの読み込み順を含む)
1ページ

4ページ

◯◯◯_middle.json: MinerUの中間処理結果
{
"pdf_info": [
{
"preproc_blocks": [
{
"type": "title",
"bbox": [
44,
92,
102,
108
],
"lines": [
{
"bbox": [
45,
93,
101,
106
],
"spans": [
{
"bbox": [
45,
93,
101,
106
],
"score": 1.0,
"content": "調査目的",
"type": "text"
}
],
"index": 0
}
],
"index": 0
},
{
"type": "text",
"bbox": [
122,
88,
558,
122
],
"lines": [
{
"bbox": [
124,
89,
558,
102
],
"spans": [
{
"bbox": [
124,
89,
558,
102
],
"score": 1.0,
"content": "本調査は,来神観光客の特質と神戸市内の観光動向を把握し,今後の観光行政の参考とす",
"type": "text"
}
],
"index": 1
},
(snip)
◯◯◯_model.json: モデル推論結果
[
{
"layout_dets": [
{
"category_id": 1,
"poly": [
340.11480712890625,
246.88717651367188,
1552.6397705078125,
246.88717651367188,
1552.6397705078125,
338.9091491699219,
340.11480712890625,
338.9091491699219
],
"score": 0.9999951124191284
},
{
"category_id": 1,
"poly": [
339.8384094238281,
385.0721740722656,
1153.7464599609375,
385.0721740722656,
1153.7464599609375,
427.5785217285156,
339.8384094238281,
427.5785217285156
],
"score": 0.9999939203262329
},
{
"category_id": 1,
"poly": [
341.49017333984375,
481.0704040527344,
1260.278076171875,
481.0704040527344,
1260.278076171875,
680.07763671875,
341.49017333984375,
680.07763671875
],
"score": 0.9999827146530151
},
(snip)
◯◯◯_origin.pdf: 元のPDFファイル
元ファイルと同じなので割愛
◯◯◯_spans.pdf: 最小粒度bbox位置情報図
1ページ
4ページ

◯◯◯_content_list.json: 読み上げ順に並べたリッチテキストJSON
[
{
"type": "text",
"text": "調査目的",
"text_level": 1,
"page_idx": 0
},
{
"type": "text",
"text": "本調査は,来神観光客の特質と神戸市内の観光動向を把握し,今後の観光行政の参考とすることを目的に実施。",
"page_idx": 0
},
{
"type": "text",
"text": "調 査 方 法",
"page_idx": 0
},
{
"type": "text",
"text": "調査員が対面にてアンケート項目を聞き取りする形で実施。",
"page_idx": 0
},
(snip)
images/: 画像保存用ディレクトリ

ざっと見た感じはこうかな。
- あくまでもテキストとして抽出するようで、表や図などはすべて画像となっていた。
- ただし
-mで抽出方法が選択できる。txt/ocr/autoから選択可能で、autoだと自動でtxtかocrを判定する。 - なお、内部的にはPaddleOCRが使用されている様子。
- ただし
- Markdownとしては、
- 画像は、画像フォルダへのリンクとして埋め込まれる
- 箇条書きや数字の部分で、KaTexっぽい記述になっている
レイアウトや表の検出には以下のモデルを使用しているっぽい。
処理中のVRAMはこんな感じだった。
Tue Nov 26 13:52:51 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 48C P0 154W / 450W | 6377MiB / 24564MiB | 39% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1377 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1454 G /usr/bin/gnome-shell 15MiB |
| 0 N/A N/A 3554741 C /opt/mineru_venv/bin/python3 6170MiB |
+-----------------------------------------------------------------------------------------+
OCRの使われ方がよくわからなかったので、明示的にやってみた。--langでOCRに渡す言語を指定する。
magic-pdf -p r5_doukou.pdf -o output -m ocr --lang japan
ログを見る限り別のモデル(PaddlrOCRのマルチリンガルモデルっぽい)がダウンロードされたので、-m autoでやったときとは処理の仕方は変わったはずだけど、結果だけ見るとあまり変わらなかった。
まとめ
個人的な所感。
Markdownとしては画像リンクも含めて完結はしているのだけど、グラフはともかく、表あたりは頑張って読み込んでほしいなというところ。過去に試した他のソリューションに比べると、その点についてはちょっと物足りないかなというところはある。
ただ、テキストのパース(Markdown)とそれ以外(画像)みたいに分離だけやっといて、あとは何かしらのパイプラインに流すみたいに使うなら、お手軽感はあるかな。CLIも簡単だし、PythonのSDKもあるし。