OpenAI GPT-4 with Visionを試してみる
!pip install -q openai
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
Wikipediaにある「ヒボタンサボテン」の画像を読ませてみる。
from openai import OpenAI
from pprint import pprint
import json
from IPython.display import Image
user_prompt = """
desribe this image in detail. In Japanese.
"""
user_image = ""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/d/d2/Gymnocalicium_mihanowichii_Hibotan.jpg"
}
}
]
}
]
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
)
pprint(json.loads(response.json()), indent=2)
なんか途中で切れてしまっている。max_tokenを超えたってことか。
{ 'choices': [ { 'finish_details': {'type': 'max_tokens'},
'finish_reason': None,
'index': 0,
'message': { 'content': 'この画像は、鉢植えされたサ',
'function_call': None,
'role': 'assistant',
'tool_calls': None}}],
'created': 1699495930,
'id': 'chatcmpl-XXXXXXXXXXXXXXXXXXXX',
'model': 'gpt-4-1106-vision-preview',
'object': 'chat.completion',
'system_fingerprint': None,
'usage': {'completion_tokens': 15, 'prompt_tokens': 784, 'total_tokens': 799}}
max_tokensを指定して再度やってみる
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
max_tokens=1024,
)
切れずに出力された。
{ 'choices': [ { 'finish_details': {'stop': '<|fim_suffix|>', 'type': 'stop'},
'finish_reason': None,
'index': 0,
'message': { 'content': 'この画像は、サボテンの植物を写したものです。下部は緑色で扁平な形状をしており、その上に鮮やかな赤色の球形のサボテンが育っています。赤い部分には、多数の小さな白いトゲがまばらに生えています。サボテンは白い石ころが敷き詰められたテラコッタの鉢植えに入っており、その背景には二つ目の鉢植えとぼんやりと緑色の植物が見えます。光はやわらかく、画像全体には穏やかな雰囲気が漂っています。',
'function_call': None,
'role': 'assistant',
'tool_calls': None}}],
'created': 1699496536,
'id': 'chatcmpl-XXXXXXXXXX',
'model': 'gpt-4-1106-vision-preview',
'object': 'chat.completion',
'system_fingerprint': None,
'usage': { 'completion_tokens': 210,
'prompt_tokens': 784,
'total_tokens': 994}}
ためしに200トークンぐらいに指定してみる
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
max_tokens=200,
)
途中で切れている。
{ 'choices': [ { 'finish_details': {'type': 'max_tokens'},
'finish_reason': None,
'index': 0,
'message': { 'content': 'この画像には、鉢植えのサボテンが写っています。サボテンは、緑色の基部と鮮やかな赤色のトップ部分を持つ、2つの部分から成り立っていることが特徴です。基部は比較的平坦な形状で、多肉植物特有の肉厚な質感があります。一方、上部は丸みを帯びており、サボテン特有の小さな白いトゲが全体に密集して生えています。このサボテンは白色の小石で埋められた茶色い鉢に植えられて',
'function_call': None,
'role': 'assistant',
'tool_calls': None}}],
'created': 1699496627,
'id': 'chatcmpl-XXXXXXXXXX',
'model': 'gpt-4-1106-vision-preview',
'object': 'chat.completion',
'system_fingerprint': None,
'usage': { 'completion_tokens': 200,
'prompt_tokens': 784,
'total_tokens': 984}}
んー、max_tokenをちゃんと指定しないとダメな感じっぽい。max_tokenこれまであまり意識したことないのだけど、これどう計算すればいいんだろうか。
なるほど、デフォルトは非常に小さいと。ただ個人的にはいちいち設定してないのだけど、Azureだからとかあるのかな?もしくはこの情報が古いとか?
画像のトークン数の計算は記載があった
コスト計算
画像入力はテキスト入力と同様に、トークンで課金されます。画像のトークンコストは、サイズと各image_urlブロックの
detailオプションの2つの要素によって決まります。detail:lowの画像はすべて85トークンずつかかります。detail:highの画像は、まず縦横比を維持したまま2048×2048の正方形に収まるように拡大縮小されます。次に、画像の最も短い辺の長さが768pxになるように拡大縮小されます。最後に、画像が何個の512pxの正方形で構成されているかを数える。これらの正方形はそれぞれ170トークンかかる。さらに85トークンが常に最終合計に加えられる。上記を示すいくつかの例を挙げよう。
- 1,024×1,024の正方形画像の詳細:高モードでは765トークンを消費します。
- 1024は2048より小さいので、初期サイズは変更しない。
- 最短辺は1024なので、画像を768 x 768に縮小する。
- 画像を表現するには512pxの正方形のタイルが4つ必要なので、最終的なトークン・コストは
170 * 4 + 85 = 765となる。- 2048 x 4096の画像の詳細:高モードでは1105トークンを要する。
- 2048の正方形に収まるように、画像を1024 x 2048に縮小します。
- 最短辺は1024なので、さらに768 x 1536に縮小する。
- 512pxのタイルが6枚必要なので、最終的なトークン・コストは
170 * 6 + 85 = 1105となる。- 4096 x 8192の詳細画像:最も低いコストは85トークン
- 入力サイズに関係なく、低詳細画像は固定コストです。
わかりにくいのでChatGPTに関数を作ってもらった。合っているかはちゃんと確認してない。
from PIL import Image
import requests
from io import BytesIO
def get_image_size(image_url):
"""
与えられた画像URLから画像のサイズを取得します。
パラメータ:
- image_url: 画像のURL。
戻り値:
- 画像の寸法を表すタプル (width, height)。
"""
try:
response = requests.get(image_url, headers=headers)
response.raise_for_status()
image = Image.open(BytesIO(response.content))
return image.size
except requests.exceptions.HTTPError as e:
print(f"HTTPエラーが発生しました: {e}")
return None
except Exception as e:
print(f"その他のエラーが発生しました: {e}")
return None
def calculate_image_token_cost(image_width, image_height, detail_mode):
"""
与えられた画像の幅、高さ、および詳細モードに基づいてトークンコストを計算します。
パラメータ:
- image_width: 画像の幅(ピクセル単位)。
- image_height: 画像の高さ(ピクセル単位)。
- detail_mode: 'high'または'low'の文字列で、詳細モードを示します。
戻り値:
- 画像のトークンコスト。
"""
# 低詳細モードでは、コストは85トークンで固定です
if detail_mode == 'low':
return 85
# 高詳細モードでは、画像のサイズに基づいてコストを計算します
if detail_mode == 'high':
# 必要に応じて画像を2048x2048の正方形に収まるようにスケールします
max_dimension = max(image_width, image_height)
if max_dimension > 2048:
scale_factor = 2048.0 / max_dimension
image_width = int(image_width * scale_factor)
image_height = int(image_height * scale_factor)
# 画像を最短辺が768ピクセルになるようにスケールします
min_dimension = min(image_width, image_height)
scale_factor = 768.0 / min_dimension
image_width = int(image_width * scale_factor)
image_height = int(image_height * scale_factor)
# 画像を表現するために必要な512ピクセルのタイルの数を計算します
tiles_width = -(-image_width // 512) # 切り上げ除算
tiles_height = -(-image_height // 512) # 切り上げ除算
num_tiles = tiles_width * tiles_height
# 最終的なトークンコストを計算します
token_cost = 170 * num_tiles + 85
return token_cost
def calculate_token_cost_from_path_or_url(image_path_or_url, detail_mode):
"""
与えられた画像のパスまたはURLと詳細モードに基づいてトークンコストを計算します。
パラメータ:
- image_path_or_url: 画像のパスまたはURL。
- detail_mode: 'high'または'low'の文字列で、詳細モードを示します。
戻り値:
- サイズを決定できる場合は画像のトークンコスト、それ以外の場合はNone。
"""
# 最初に画像のサイズを取得します
size = get_image_size(image_path_or_url)
if size is None:
return None
image_width, image_height = size
# 提供された幅と高さを使用してトークンコストを計算します
token_cost = calculate_image_token_cost(image_width, image_height, detail_mode)
# 計算されたトークンコストを返します
return token_cost
# wikipediaの場合はUser-Agentを指定してアクセスする必要がある cf: https://meta.wikimedia.org/wiki/User-Agent_policy/ja
contact_info = "kun432.8d1w@gmail.com"
requests_version = requests.__version__
user_agent = f"gpt-4v-test/1.0 ({contact_info}) Python-requests/{requests_version}"
headers = {
'User-Agent': user_agent
}
上記のサボテン画像は583x768ピクセル。
lowの場合。
calculate_token_cost_from_path_or_url("https://upload.wikimedia.org/wikipedia/commons/d/d2/Gymnocalicium_mihanowichii_Hibotan.jpg", "low")
85
hightの場合。
calculate_token_cost_from_path_or_url("https://upload.wikimedia.org/wikipedia/commons/d/d2/Gymnocalicium_mihanowichii_Hibotan.jpg", "high")
765
テキストプロンプトのトークンは以下で計算できる。
!pip install tiktoken
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4-vision-preview")
encoding.name
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
print(encoding.name)
print(num_tokens_from_string(user_prompt, encoding.name))
cl100k_base
12
765+12=777なので微妙に足りないけどおおよそは合ってる感じ。GPT-4は128Kだけどpreview時点ではtierによって上限が異なるらしい。自分の場合はtier3なので40000トークン/分,、tier4なら150000トークンで128K使えることになるらしい。
あと知らなかったけど、RPD(1日あたりのリクエスト数)というのもあるんだね・・・
あとでやるけど、動画(でフレーム分割)とかじゃない限りは基本的にはある程度大きくしておいても問題なさそうな気はする。
ということで動画もやってみる。
動画といってもmp4なんかをそのまま渡せるわけではなくて、フレームに分解して、複数の画像として渡してやるようなイメージになる。
以下の動画を使わせていただく。
流れはここを参考に。
まず動画をフレームに分割する。
from IPython.display import display, Image, Audio
import cv2 # We're using OpenCV to read video
import base64
import time
import openai
import os
import requests
video = cv2.VideoCapture("horse_racing_-_7969 (360p).mp4")
base64Frames = []
while video.isOpened():
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.")
586フレームになった。
586 frames read.
今回の動画は640x360なのでざっと計算してみる
for i in ["low", "high"]:
print("esimated tokens for detail:{i} ", calculate_image_token_cost(640, 360, i) * len(base64Frames))
esimated tokens for detail:{i} 49810
esimated tokens for detail:{i} 647530
上で書いた通りtier3だと128Kトークンをフルには使えないので、今回はdetail:lowでかつスライスしてフレーム数を半分ぐらいに減らしてやってみる。gpt-4-vison-previewは 入力は$0.01 / 1K tokensなので大体1回40円ぐらい?たっか・・・
とりあえずこの動画の前半部分は不要なので、前半半分を切る感じにするつもり。プレビュー。
display_handle = display(None, display_id=True)
for img in base64Frames[300:]:
display_handle.update(Image(data=base64.b64decode(img.encode("utf-8"))))
time.sleep(0.01)
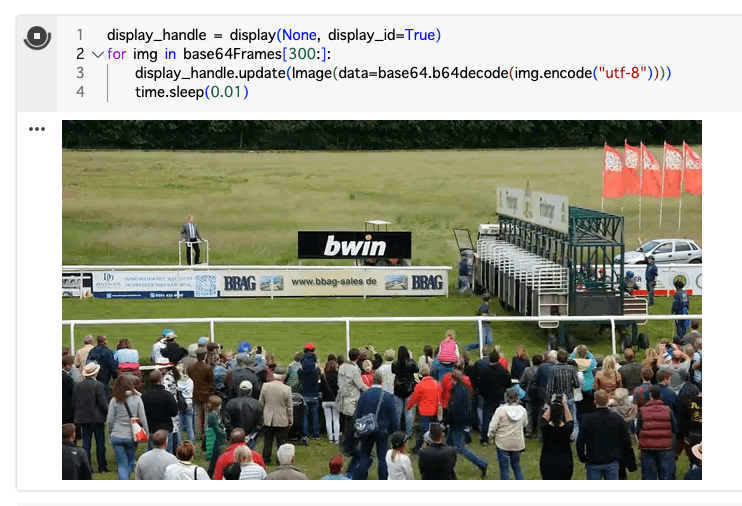
でペイロードを作成していくけども、上の参考URL、多分pythonのOpenAIクライアントのバージョンが古いので、現在のドキュメントの指定とは違っている。書き方を変える必要がある。
まずちょっとお試しでフレーム数をかなり減らしてペイロードを作ってみる。
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "These are frames from a video that I want to upload. Generate a compelling description in Japanese that I can upload along with the video.",
},
*map(lambda x: {"type": "image_url", "image_url": { "url": f"data:image/jpeg;base64,{x}", "detail": "low" }}, base64Frames[300::50]),
],
},
]
pprint(PROMPT_MESSAGES, indent=2)
いけてそう
では約300フレームのペイロードを作ってAPIに投げてみる。
%%time
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "These are frames from a video that I want to upload. Generate a compelling description in Japanese that I can upload along with the video.",
},
*map(lambda x: {"type": "image_url", "image_url": { "url": f"data:image/jpeg;base64,{x}", "detail": "low" }}, base64Frames[300:]),
],
},
]
params = {
"model": "gpt-4-vision-preview",
"messages": PROMPT_MESSAGES,
"max_tokens": 1000,
}
response = client.chat.completions.create(**params)
pprint(json.loads(response.json()), indent=2)
結果。なんか余計な説明もついてきてる。プロンプトは調整する必要がありそう。
{ 'choices': [ { 'finish_details': {'stop': '<|fim_suffix|>', 'type': 'stop'},
'finish_reason': None,
'index': 0,
'message': { 'content': 'Certainly! Based on the images '
'provided, which show a sequence of a '
"horse race, here's a compelling "
'description in Japanese that you can '
'use for your video upload:\n'
'\n'
'緑豊かな競馬場を舞台に、速さと興奮の瞬間が息をのむレースで繰り広げられます。この動画では、力強いサラブレッドたちがゲートを飛び出し、勝利を目指して一心不乱に駆け抜ける姿をご覧いただけます。観客たちの盛り上がりとともに、競走馬と騎手の息がぴったり合った息詰まるレースの一部始終をお届けします。見どころ満載のこのレースの動画をお楽しみください。\n'
'\n'
'Roughly translated, this reads:\n'
'\n'
'"Set in a lush green racecourse, '
'moments of speed and thrill unfold '
'in a breathtaking race. In this '
'video, you can see powerful '
'thoroughbreds bursting out of the '
'gates and racing single-mindedly '
'towards victory. Experience every '
'moment of this suspense-filled race '
'in harmony with the excitement of '
'the crowd and the seamless unity '
'between the horses and their '
'jockeys. Enjoy the highlights of '
'this race in the video."\n'
'\n'
'Feel free to adjust the description '
'as needed to match the content and '
'atmosphere of your video more '
'closely.',
'function_call': None,
'role': 'assistant',
'tool_calls': None}}],
'created': 1699518356,
'id': 'chatcmpl-XXXXXXXXXX',
'model': 'gpt-4-1106-vision-preview',
'object': 'chat.completion',
'system_fingerprint': None,
'usage': { 'completion_tokens': 340,
'prompt_tokens': 24344,
'total_tokens': 24684}}
それなりに時間が掛かる。
CPU times: user 509 ms, sys: 139 ms, total: 648 ms
Wall time: 55.1 s
テキストだけ抜き出すとこんな感じ
Certainly! Based on the images provided, which show a sequence of a horse race, here's a compelling description in Japanese that you can use for your video upload:
緑豊かな競馬場を舞台に、速さと興奮の瞬間が息をのむレースで繰り広げられます。この動画では、力強いサラブレッドたちがゲートを飛び出し、勝利を目指して一心不乱に駆け抜ける姿をご覧いただけます。観客たちの盛り上がりとともに、競走馬と騎手の息がぴったり合った息詰まるレースの一部始終をお届けします。見どころ満載のこのレースの動画をお楽しみください。
Roughly translated, this reads:
Set in a lush green racecourse moments of speed and thrill unfold in a breathtaking race. In this 'video, you can see powerful thoroughbreds bursting out of the gates and racing single-mindedly towards victory. Experience every moment of this suspense-filled race in harmony with the excitement of the crowd and the seamless unity between the horses and their jockeys. Enjoy the highlights of this race in the video.
Feel free to adjust the description as needed to match the content and atmosphere of your video more closely.
トークンもざっくり見積もった通りなんだけど、実はちょっと何回かテスト的に実行したりもしてたので、ちょびっとだけでも2ドルぐらい課金されていて、流石に高いなと。。。。
これで会話を続けるとなるとこれ毎回全部のトークン送り続けるんだよね?そうなると、ちょっと課金が怖いのとレスポンス遅くなりそうな気がする。
このへんはAssitant APIのThreadsを使うほうが現実的かもしれない。
サラッと流したけど、画像はURLで渡す以外に、上で書いた通りbase64エンコードして渡す方法もある。
参考: スレにGithHubレポジトリへのパス有り