「LocalAI」を試す
GitHubレポジトリ
公式ドキュメント
LocalAI
LocalAIは、無料のオープンソースのOpenAI代替ツールです。LocalAIは、OpenAI API仕様との互換性を備え、既存のシステムにそのまま組み込めるローカル推論向けのREST APIとして機能します。これにより、コンシュマー向けハードウェアで、ローカルまたはオンプレミス環境で、複数のモデルファミリーやアーキテクチャに対応しながら、LLMの実行、画像生成、音声生成(およびそれ以外)を行うことができます。GPUは不要です。Ettore Di Giacintoによって作成・管理されています。
LocalAIとは?
要約すると以下の通りです:
- ローカルで動作する、OpenAIの代替となるREST API。データの所有権はあなたにあります。
- GPUは不要。インターネット接続も不要
- オプションとしてGPUアクセラレーションにも対応しています。ビルドセクションも参照してください。
- 複数のモデルをサポート
- 🏃 初回ロード後はモデルをメモリ上に保持し、推論を高速化
- ⚡ シェル実行せず、バインディングを使用してより高速な推論と高性能を実現
LocalAIは、誰でもAIを利用できるようにすることを目指しています。貢献、フィードバック、プルリクエストは常に歓迎されています!
なお、これはもともと mudler による週末の趣味プロジェクトとして始まりました。
ChatGPTのような完全なAIアシスタントに必要な要素を作ろうとしたのがきっかけです。現在コミュニティは急速に成長しており、私たちはより良く、より安定したものにするために日々努力しています。ご協力いただける方は、ぜひ貢献をご検討ください(詳細は以下に記載)。🚀 機能一覧
- 📖 GPTによるテキスト生成(
llama.cpp、gpt4all.cppなど 📖 その他多数)- 🗣 テキストから音声への変換
- 🔈 音声からテキストへの変換(
whisper.cppによる音声書き起こし)- 🎨 Stable Diffusionによる画像生成
- 🔥 OpenAI関数のサポート 🆕
- 🧠 ベクトルデータベース用の埋め込み生成
- ✍️ 制約付き文法対応
- 🖼️ Huggingfaceからのモデル直接ダウンロード
- 🥽 Vision API対応
- 💾 ストア機能
- 📈 リランカー
- 🆕 P2P推論
LLM・Embeddingはもちろん、画像・音声・リランキングなんかも全部賄えるAPIサーバをこれ1つで建てれるということかな?ちょっと良さそうなので試してみる。
Getting startedに従って進める
Getting Started: Quickstart
インストール
インストール方法は3つ
- ワンライナー(Bash)
- Homebrew(Mac)
- コンテナ(Docker / Kubernetes)
今回はローカルのUbuntuサーバ(GPU: RTX4090)にDockerでインストールしたいと思う。コンテナイメージのインストールドキュメントはこれ。
ドキュメントを見る限り、コンテナの場合は、LLMやEmbeddingなど各機能ごとに事前にモデルが設定されていてすぐに使える、といったものらしい。モデルの追加とかできるのかな?まあそのあたりは後で確認する。
作業ディレクトリを作成
mkdir local-ai-work && cd local-ai-work
以下のようなdocker-compose.yamlを作成
起動。イメージのダウンロード&モデルのダウンロードが行われるので、かなりの時間がかかる・・・
docker compose up
こんな感じでログが表示されれば起動完了。
api-1 | 4:31PM INF LocalAI API is listening! Please connect to the endpoint for API documentation. endpoint=http://0.0.0.0:8080
ブラウザでアクセスするとこんなかんじの画面

何やらgpt-4とかOpenAIのモデル名が表示されるが、以下ドキュメントにある通り、実際は別のモデルが動いているらしい。
今回はGPU向けのイメージを使ったので、
- LLM:
hermes-2-pro-mistral - ビジョン:
llava-1.6-mistral - 画像生成:
dreamshaper-8 - STT:
whisper-base - TTS:
rhassspy/piper - Embeddings:
all-MiniLM-L6-v2
が実際に動いているモデルということになる。
とりあえずチャットしてみる。上のメニューから「Chat」を選択。

こんな感じでチャットできる。

モデルを変えてみる。

こちらはうまくいかなかった。

同じような感じで、画像生成・TTS・STTもできる様子。各メニューをひと通り見てみる。
画像生成。モデルがいつの間にやら切り替わっているようで、"stable diffusion"を選択しないとエラーになったが、生成できた。
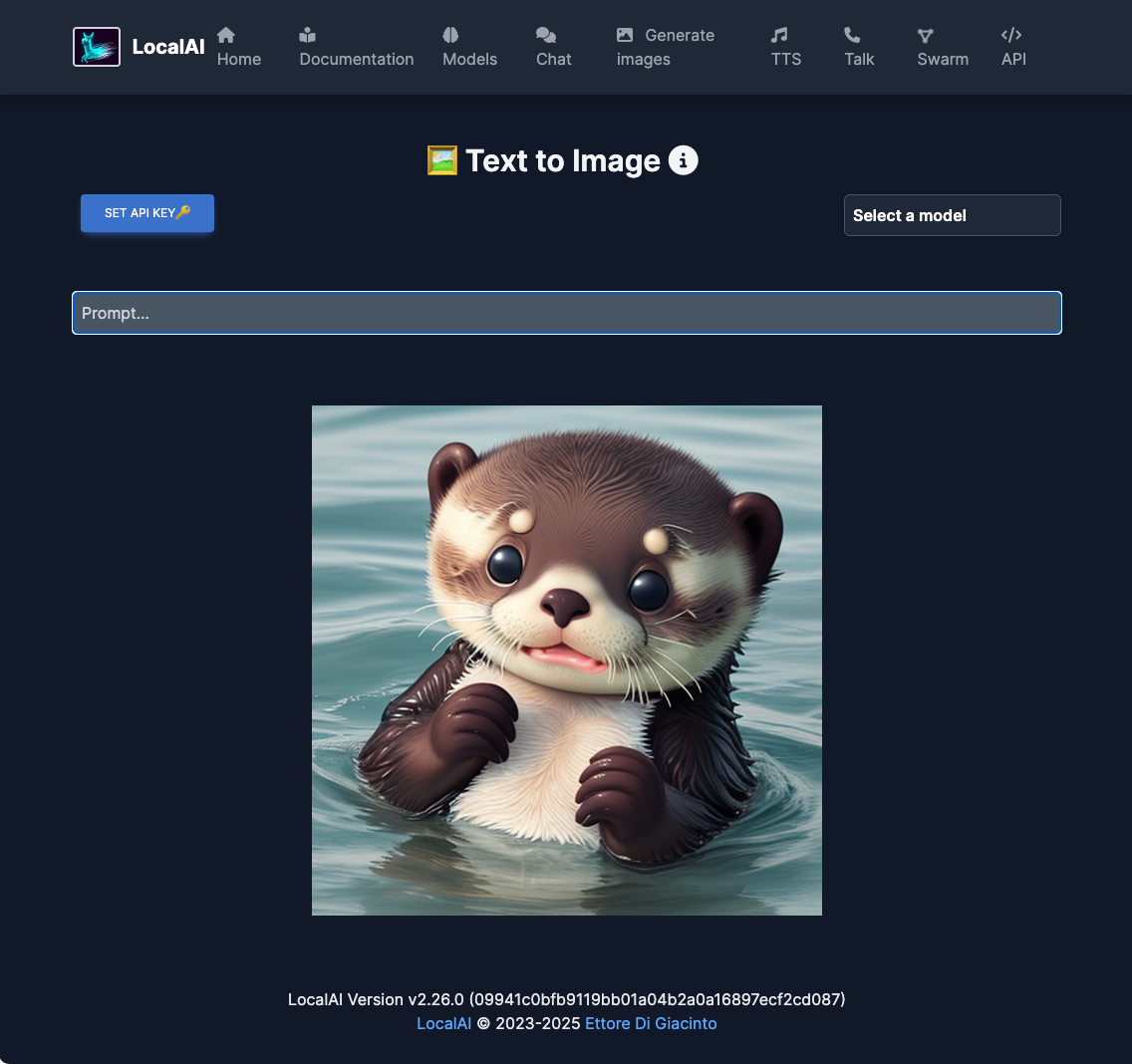
TTS。日本語はダメだった(Piperは日本語非対応のはず)が、英語だとできた。

STT。これはLLMとTTSも組み合わさってチャットになってる様子。ただし、"MediaDevices API not supported!"というエラーが出て、全く動かせなかった。

あとどうやらP2Pの分散推論に対応しているらしいが、これはデフォルトだと無効化されている様子。

とりあえず
- モデルが勝手に切り替わっていたりするので、都度都度選択が必要
- 使えないモデルや動かない機能がある様子
あたりで、まあGUIでの推論はおまけかなというのが個人的な印象。
CLI・API
LocalAIはCLIやAPI経由で利用できる。
ワンライナーやHomebrewでインストールした場合は多分そのままCLIが使えるのだと思う。
docker composeの場合、コンテナの中に入ればできるかなーと思いながら、CLIが見つからなかったので、APIでの利用を試す。
なお、APIドキュメントはGUIのメニューからアクセスできる

LLM。モデルにもよるんだろうけど、Function Callingにも対応している。
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"messages":[{"role":"user","content":"こんにちは。"}],
"temperature": 0.7
}' | jq -r .
{
"created": 1743184253,
"object": "chat.completion",
"id": "23db1330-785e-4ffd-a6d0-d559fe202922",
"model": "gpt-4",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "こんにちは!何かお手伝いできることがありますか?"
}
}
],
"usage": {
"prompt_tokens": 11,
"completion_tokens": 14,
"total_tokens": 25
}
}
画像生成。生成した画像のURLが出力される。
curl http://localhost:8080/v1/images/generations \
-H "Content-Type: application/json" -d '{
"prompt": "A cute baby sea otter",
"size": "256x256"
}' | jq -r .
{
"created": 1743186052,
"id": "444f5650-dac1-4050-9c59-a538fab83c8b",
"data": [
{
"embedding": null,
"index": 0,
"url": "http://localhost:8080/generated-images/b641867159540.png"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}

TTS。WAVで出力されたのを再生して問題ないことを確認できた。
curl http://localhost:8080/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{
"model": "tts-1",
"input": "The quick brown fox jumped over the lazy dog.",
"voice": "alloy"
}' \
--output speech.wav
STT。いつも試しているオーディオデータで。
curl -X POST http://localhost:8080/v1/audio/transcriptions \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F model="whisper-1" \
-F file="@$PWD/voice_lunch_jp_1min.wav" | jq -r .text
はいじゃあ始めますちょっとまだこらえてない方もいらっしゃるんですけどポイスランジューでP始めますはい日曜日にお集まりいただきましたありがとうございます 今日下手部員ですねおフラインということで今日はですねスペシャルのゲストを二人 来ていただいておりますということではいときはちょっとトピックにもありますけれどもボイスローの使用であるレデンリームさんとあとセルソースのカムセドラル レザインのディレクターであるグレークベネスさんに来ていただいてますということで日本に来ていただいてありがとうございます
Embeddings。実際のモデルは多分日本語非対応な気がする。
curl http://localhost:8080/embeddings \
-X POST -H "Content-Type: application/json" \
-d '{
"input": "こんにちは。今日はいいお天気ですね。",
"model": "text-embedding-ada-002"
}'
{
"created": 1743187168,
"object": "list",
"id": "9caaf8ee-8e24-4d9b-93ce-d8a7a417b290",
"model": "text-embedding-ada-002",
"data": [
{
"embedding": [
-0.005331782,
0.1366555,
0.08138748,
0.01946513,
-0.034704104,
0.054323412,
0.09842277,
(snip)
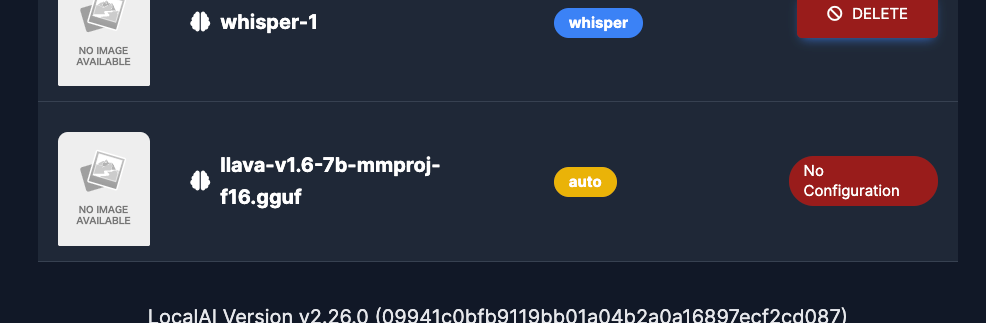
ビジョン(画像認識)はどうしてもうまくいかなかった。GUIからも「No Configuration」とか表示されてるので何かが足りないのかも知れない。
その他、リランキング、VADもAPIからアクセスができると思われる。
これOpenAIのモデルを名乗っているのは、APIとして利用する際にスイッチしやすいように、ってことなんだろうと思うのだけど、実際のモデルが違うのであれば正直わかりにくいように感じた。リランキングとかOpenAIが提供していないものは jina-reranker-v1-base-enってそのままだし、画像生成も普通に"stablediffution"ってなってるし。むしろ混乱しそう。
モデルの追加
CLIだとそのままモデルをダウンロードできるようだけど、コンテナの場合はGUIでやるのかな?一応APIにもありそうではあるが、めんどくさそう。
GUIの上の「Models」メニューを開くとこんな感じ。適合にダウンロードしてみる。

こんな感じでダウンロードされるので待つ。

ダウンロードできたらチャットしてみる・・・のだが、応答が返ってこない・・・

ログを見るとどうも失敗している様子。
api-1 | 6:59PM INF BackendLoader starting backend=/build/backend/python/diffusers/run.sh modelID=gemma-3-4b-it o.model=gemma-3-4b-it-Q4_K_M.gguf
api-1 | 6:59PM DBG Loading model in memory from file: /build/models/gemma-3-4b-it-Q4_K_M.gguf
api-1 | 6:59PM DBG Loading Model gemma-3-4b-it with gRPC (file: /build/models/gemma-3-4b-it-Q4_K_M.gguf) (backend: /build/backend/python/diffusers/run.sh): {backendString:/build/backend/python/diffusers/run.sh model:gemma-3-4b-it-Q4_K_M.gguf modelID:gemma-3-4b-it assetDir:/tmp/localai/backend_data context:{emptyCtx:{}} gRPCOptions:0xc00018e2c8 externalBackends:map[autogptq:/build/backend/python/autogptq/run.sh bark:/build/backend/python/bark/run.sh coqui:/build/backend/python/coqui/run.sh diffusers:/build/backend/python/diffusers/run.sh exllama2:/build/backend/python/exllama2/run.sh faster-whisper:/build/backend/python/faster-whisper/run.sh kokoro:/build/backend/python/kokoro/run.sh rerankers:/build/backend/python/rerankers/run.sh transformers:/build/backend/python/transformers/run.sh vllm:/build/backend/python/vllm/run.sh] grpcAttempts:20 grpcAttemptsDelay:2 singleActiveBackend:false parallelRequests:false}
api-1 | 6:59PM INF [/build/backend/python/diffusers/run.sh] Fails: failed to load model with internal loader: backend not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/diffusers/run.sh
Phi-4-mini-instructも試してみたけど、同じエラーでダメだった。このあたりはよくわからないな・・・
とりあえずモデルの数は多くあるように見えるんだけど、ざっと見た感じ個人?でファインチューニングされたようなモデルが多いように見える。Gemma-3だとこんな感じ。

まとめ
個人的にはLLM以外も含めたOpenAI互換APIサーバとして使えるかなぁ?というところに期待してたんだけど、自分が確認した範囲だと不安定、というかよくわからない印象。
主要ベンダーからでているモデルがサラッと動かないのであれば、個人のツールとして使うにあたっても、ちょっと厳しい・・・残念。