Hugging Face Audio course をやっていく
ふとしたところで見つけた。こんなコースあるんだなー。
Hugging Face オーディオコースへようこそ!
学習者の皆様、
オーディオに transformers を使用する方法に関するこのコースへようこそ。transformers は、自然言語処理、コンピュータビジョン、そして最近ではオーディオ処理など、幅広いタスクにおいて最先端の結果を達成できる、最も強力で汎用性の高いディープラーニングアーキテクチャのひとつとして、その威力を何度も実証してきました。
このコースでは、transformers をオーディオデータに適用する方法を探求します。音声認識、オーディオ分類、テキストから音声を生成するタスクなど、多様なオーディオ関連タスクに取り組むための手法を学びます。transformers とこのコースは、あなたのニーズに応えます。
コースを通じて、オーディオデータ処理の具体的なポイント、さまざまな transformers アーキテクチャについて学び、強力な事前学習済みモデルを活用して独自のオーディオ transformers をトレーニングします。
このコースは、ディープラーニングの背景知識があり、transformers に一般的な知識がある方を対象としています。音声データ処理の専門知識は不要です。transformers の基礎知識を復習したい方は、transformers の基礎を詳しく解説した「NLPコース」をご確認ください。
コースの構成
このコースは、さまざまなトピックを深く掘り下げる複数のユニットで構成されています。
- ユニット1: オーディオデータの処理技術やデータ準備など、オーディオデータの取り扱いに関する具体的な知識を習得します。
- ユニット2: オーディオアプリケーションについて理解し、音声分類や音声認識などのさまざまなタスクに 🤗 Transformers パイプラインを使用する方法を学びます。
- ユニット3: オーディオ transformer のアーキテクチャについて学び、その違いや最適なタスクについて理解します。
- ユニット4: 独自の音楽ジャンル分類器を構築する方法を学びます。
- ユニット5: 音声認識に深く掘り下げ、会議の録音内容を文字起こしするモデルを構築します。
- ユニット6: テキストから音声を生成する方法を学びます。
- ユニット7: transformers を使用して現実世界のオーディオアプリケーションを構築する方法を学びます。
各ユニットには、基礎となる概念や技術を深く理解するための理論的な内容が含まれています。コース全体を通して、知識を確認し、学習内容を強化するためのクイズが用意されています。一部の章では、学んだ内容を実践的に応用できるハンズオン演習も含まれています。
コース修了時には、音声データに transformers を使用するための堅固な基礎を身につけ、これらの技術を多様な音声関連タスクに応用できる能力を養います。
ということでやってみる。
Colaboratoryで行けるようなのでそれで。T4でいけるかな?
なお、学習のお供に今回はGemini-2.5-Pro先生と色々やり取りしながら進める
ユニット1: オーディオデータを取り扱う
このユニットでは、波形、サンプリングレート、スペクトログラムなど、オーディオデータに関連する基 本的な用語を理解します。 また、オーディオデータのロードや前処理、大きなデータセットを効率的にストリーミングする方法など、オーディオデータセットの扱い方を学びます。
オーディオデータ入門
なぜ音をデジタルデータに変換する必要があるのか、そしてその基本的なプロセスとは?
-
音は本来 「連続的 (Continuous)」
- 私たちが普段聞いている「音の波(sound wave)」は「アナログ」信号
- 途切れることなく滑らかに変化している。
- ある時間区間をとってみても、その中には無限個の値が存在する。
- イメージとしては、なだらかな丘の斜面のようなもの。どの地点にも高さ(音の強さ)がある
-
コンピューターは 「離散的 (Discrete)」
- コンピューター(デジタルデバイス)は、無限の値をそのまま扱うことができない。
- コンピューターは、有限個の「点」の集まり(配列など)としてデータを扱う。
- 丘の斜面で例えると、コンピューターは斜面全体を滑らかに記録するのではなく、一定間隔で高さを測って、その測定値だけを記録するイメージ。
-
変換が必要
- コンピューターで音を処理したり、保存したり、送ったりするには、この連続的な音の波を、有限個の点の集まり(離散的な値の系列)に変換する必要がある。
- この変換されたデータ形式をデジタル表現 (digital representation) と呼ぶ。
-
ファイル形式
- デジタル表現されたデータを保存するための形式
.wav.flac-
.mp3、など
- 主にデータをどのように圧縮するか(ファイルサイズを小さくするか)が形式の違いになる。
- デジタル表現されたデータを保存するための形式
-
変換プロセス
- 一般的に以下のステップで行われる。
-
マイク
- 音の波(空気の振動)を電気信号(アナログ信号)に変換。
-
アナログ-デジタル変換器 (ADC: Analog-to-Digital Converter)
- アナログの電気信号を、デジタルの値の系列に変換。
- この変換の中心的な処理が、**サンプリング (Sampling) **
-
マイク
- 一般的に以下のステップで行われる。
まとめ
- 現実の音は滑らかなアナログ信号。
- コンピューターは有限個の値しか扱えないデジタル。
- 音をコンピューターで扱うには、アナログ信号をデジタル信号に変換する必要がある。
- マイクで電気信号にし、ADCでデジタルデータ(数値の列)に変換する。
-
.wavや.mp3は、このデジタルデータを保存するファイル形式。
サンプリングとサンプリングレート
アナログの音の波をデジタルデータに変換する核心的なプロセスであるサンプリングと、その頻度であるサンプリングレートについて。
-
サンプリング (Sampling) とは?
- コンピューターは連続的な値を扱えない。
- そこで、一定の時間間隔でアナログ信号の値(音の強さ/振幅)を測定し、その測定値だけを記録する。
- このプロセスをサンプリングと呼ぶ。
- 図の例
- 滑らかな青い線がアナログ信号
- 一定間隔(横軸が時間)で測定した赤い点の値の集合が、サンプリングされたデジタルデータ(離散信号)
referred from wikipedia: 標本化
-
サンプリングレート (Sampling Rate) とは?
- 1秒間に何回サンプリング(測定)を行うかを示す値
- サンプリング周波数 (Sampling Frequency) とも呼ばれる。
- 単位は ヘルツ (Hz) で表される。
- 例: 16,000 Hz (または 16 kHz) → 1秒間に16,000回、音の値を測定するという意味
- 主な例
- CD音質: 44,100 Hz (1秒間に44,100回)
- ハイレゾ音源: 192,000 Hz (1秒間に192,000回)
- 音声認識モデルでよく使われるレート: 16,000 Hz (1秒間に16,000回)
-
サンプリングレートと音質(周波数)の関係
- サンプリングレートが高いほど、元の音をより細かく記録できるが、データ量も増える
- サンプリングレートが記録できる音の最高周波数(音の高さ)を決めるという点が重要。
-
ナイキスト周波数 (Nyquist limit / Nyquist frequency)
- 理論上、記録できる最高周波数は、サンプリングレートのちょうど半分になる。
- これをナイキスト周波数と呼ぶ。
- 例
- サンプリングレート 16,000 Hz → 最高 8,000 Hz (8 kHz) までの音を記録できる。
- サンプリングレート 44,100 Hz → 最高 22,050 Hz (約 22 kHz) までの音を記録できる。
-
音声認識などのタスクでは、16 kHz が一般的
- 人間の話し声に含まれる周波数は、だいたい 8 kHz 未満
- 16 kHz でサンプリングすれば十分捉えられる
- これ以上高くしても、話し声に関する情報は増えない、計算コストが増えるだけ
- 逆に低すぎると、高い周波数の情報が失われ、音がこもって聞こえる原因になる
- 例: 8 kHz サンプリングの音声
-
データセットにおけるサンプリングレートの統一
- 機械学習で音声を扱う際、データセット内のすべての音声ファイルのサンプリングレートを同じに揃えることが非常に重要。
- サンプリングレートが異なると、同じ長さの音声でもデータの点の数(配列の長さ)が変わってしまいます (例: 5秒の音声が 16kHzなら80,000点、8kHzなら40,000点)。
- Transformer のようなモデルは、データの系列(並び順や長さ)からパターンを学習するため、サンプリングレートがバラバラだと学習がうまくいきません。
-
リサンプリング (Resampling):
- データセット内の音声ファイルのサンプリングレートを特定のレートに変換して統一する処理
- 音声データの前処理 (preprocessing) の一部として行われる。
まとめ
- サンプリングは、アナログ信号を一定時間間隔で測定し、点の集まり(デジタルデータ)にするプロセス。
- サンプリングレートは、1秒間に行うサンプリングの回数 (Hz)。
- サンプリングレートが高いほど、高い周波数の音まで記録できる(最高でサンプリングレートの半分まで)。
- 音声認識などでは 16 kHz がよく使われる。
- 機械学習では、データセット内のサンプリングレートを統一する必要があり、そのためにリサンプリングを行う。
ナイキスト周波数について
なぜサンプリングレートの「半分」までなのか?
これは「サンプリング定理(標本化定理)」と呼ばれる、信号処理の非常に重要な原理に基づいています。厳密な証明は少し複雑になりますが、ここでは直感的なイメージで説明します。
イメージ:波の形を点で再現する
考えてみてください。音の波は、高い音ほど速く振動し、低い音ほどゆっくり振動します。
- 低い周波数の波(ゆっくりした波): 点を打つ間隔(サンプリングの間隔)が多少広くても、波の形をなんとなく再現できそうです。
- 高い周波数の波(速い波): 点を打つ間隔が広いと、波の速い山や谷を捉えきれず、カクカクした線になったり、最悪の場合、元の波の形とは全く違う、もっとゆっくりした波に見えてしまうことがあります。
「最低でも1周期に2回」点を打つ必要がある
ある周波数
の波(1秒間に f 回振動する波)の形を正しく記録するためには、その波の1回の振動(1周期)の間に、最低でも2回、値を測定(サンプリング)する必要がある、というのがサンプリング定理の要点です。 f
- なぜ最低2回か? 一番シンプルな波であるサイン波を考えてみると、波には「山」と「谷」がありますよね。この山と谷の両方を捉えるためには、少なくとも1周期に2つの点が必要になる、とイメージしてください。もし1周期に1点しか取らないと、それが山なのか谷なのか、あるいはその途中なのかすら分かりません。
サンプリングレートとの関係
- サンプリングレートが
(Hz) ということは、1秒間に SR 回サンプリングする、ということです。 SR - 記録したい最高の周波数を
(Hz) とします。 f_{max} - この
の波の形を捉えるためには、この波の1周期( f_{max} 秒)あたりに最低2回サンプリングする必要があります。 1/f_{max} - 言い換えると、1秒間に
の波が f_{max} 回振動するので、全体として最低でも f_{max} 回のサンプリングが1秒間に必要になります。 2 \times f_{max} - つまり、サンプリングレート
は、記録したい最高周波数 SR の 2倍以上 でなければならない、ということです ( f_{max} )。 SR \geq 2 \times f_{max} 結論:
この関係 (
) を逆から見ると、あるサンプリングレート SR \geq 2 \times f_{max} で記録できる最高周波数 SR は、サンプリングレートの半分 f_{max} ) まで、ということになります。この (f_{max} \leq SR / 2 を ナイキスト周波数 と呼びます。 SR / 2 もしサンプリングレートが足りない(記録したい周波数の2倍未満)場合、元の高い周波数の音が、実際には存在しない低い周波数の音として記録されてしまう現象が起こります。これを エイリアシング(折り返し雑音) と呼びます。これが「情報が失われる」「音がこもる」原因の一つです。
まとめ:
- 波の形(特に山と谷)を捉えるには、1周期に最低2回のサンプリングが必要。
- そのため、記録したい最高周波数の2倍以上のサンプリングレートが必要 (
)。 SR \geq 2 f_{max} - 結果として、あるサンプリングレートで記録できる最高周波数は、そのサンプリングレートの半分 (
) になる。 f_{max} \leq SR / 2
振幅とビット深度
サンプリングで 測定した各点の「値」、つまり音の大きさ(振幅)をどのようにデジタルで表現するか、そしてその精度(ビット深度)について。
-
振幅 (Amplitude) とは?
- 音は空気の圧力の変化。
- 振幅とは、ある瞬間の音の圧力のレベル(強さ)を表す。
- 人はこれを音の大きさ (Loudness) として認識する。
- 単位は一般的にデシベル (dB) で表される
- 例
- 日常会話: 約 60 dB 未満
- ロックコンサート: 約 125 dB。
- 例
-
ビット深度 (Bit Depth) とは?
- デジタルオーディオでは、サンプリングで測定した各点の振幅値を記録する。
- この振幅値をどれだけ細かく(何段階で)表現できるかを示すのがビット深度。
- ビット深度が高いほど、元の滑らかなアナログ波形をより忠実にデジタルで再現できる。
- 「ビット」はコンピューターが情報を扱う最小単位で、0か1の値を持つ。
-
N 2^N -
一般的なビット深度
- 16ビット (16-bit): (2^{16} = 65,536) 段階で振幅を表現。CD音質で使われている。
- 24ビット (24-bit): (2^{24} = 16,777,216) 段階で振幅を。より高精度。
-
-
量子化 (Quantization)
- アナログの連続的な振幅値を、ビット深度で決められた離散的な段階値に割り当てる(ある意味で「丸める」)プロセス。
- この過程で、元の値とのわずかな誤差が生じる。これを量子化ノイズ (Quantization noise) と呼ぶ。
- ビット深度が高いほど、量子化の段階が細かくなるため、量子化ノイズは小さくなる。
- ただし、16ビットでも量子化ノイズは通常、人間の耳にはほとんど聞こえないレベル。
-
32ビット浮動小数点 (32-bit Floating-point)
- 16ビットや24ビットは整数 (Integer) で値を記録するが、32ビット浮動小数点形式もある。
- 値を小数点付きの数値 (Floating-point) で記録する。
- 32ビット浮動小数点数の精度は実質的に24ビット整数と同等だが、扱える値の範囲が非常に広くなる。
- 機械学習モデルは通常、浮動小数点データを扱う、ということが重要。
- 音声データをモデルに入力する前に、多くの場合、この形式(特に -1.0 から 1.0 の範囲)に変換する必要がある。(具体的な方法は後の章で)
- 16ビットや24ビットは整数 (Integer) で値を記録するが、32ビット浮動小数点形式もある。
-
デジタルオーディオにおけるデシベル (dB)
- 人間の聴覚は対数的な特性がある
- 小さな音の変化には敏感だが、大きな音の同じ程度の変化には鈍感
- このため、振幅をデシベル (dB) という対数目盛で表すと、人間が感じる音の大きさに近くなる。
-
注意
- 現実世界の音響
- 0 dB が、人間が聞こえる最小の音
- 音が大きいほど、値は大きくなる
-
デジタルオーディオ
- 表現できる最大の振幅値が 0 dB
- それ以外の値はすべてマイナス (例: -6 dB, -12 dB) で表される。
- つまり、0 dB に近いほど音が大きいことを意味する。
- 現実世界の音響
- 目安
- -6 dB で振幅が半分になる
- -60 dB 以下は通常ほとんど聞こえない。
- 人間の聴覚は対数的な特性がある
まとめ
- 振幅は音の大きさ(音圧レベル)を表す。
- ビット深度は、各サンプリング点で記録される振幅値の精度(段階の細かさ)を決める。高いほど高精度だがデータ量も増える。
- 16ビット (65,536段階) や 24ビット (約1677万段階) が一般的。
- 量子化により微小なノイズ(量子化ノイズ)が発生するが、ビット深度が高ければ問題になりにくい。
- 機械学習では 32ビット浮動小数点 (-1.0~1.0) がよく使われる。
- デジタルオーディオの dB 表現では、最大振幅が 0 dB で、それより小さい音は負の値になる。
↑の章はこの時点ではいまいちピンとこないところもあるが、
- データの前処理で、正規化や型変換が必要になる
- 音質とデータ量はトレードオフになる
- 音声の特徴量を解釈する場合に前提の知識となる
あたりになってくるので、まずはこういうものだと思うことにする。
波形としてのオーディオ
音声を視覚的に表現する最も基本的な方法の一つである波形 (Waveform) について。
-
波形 (Waveform) とは?
- 音声データをグラフで表示したもの。
- 横軸 (X軸) が時間、縦軸 (Y軸) がその時点での振幅 (Amplitude) を表す。
- サンプリングによって得られた個々の点の値 (sample values) を時間順にプロットしたもの。
- 音の振幅が時間とともにどのように変化するかを示します。
- 時間軸に沿って音の変化を見ることになるため、音の時間領域 (Time Domain) 表現とも呼ばれる。
- 音声データをグラフで表示したもの。
-
波形の有用性
- 波形を見ることで、音声信号の様々な特徴を視覚的に捉えることができる。
-
個々の音イベントのタイミング
- 例: 拍手や話し始めの瞬間などが、振幅の急激な変化として現れる。
-
全体の音量
- 振幅が大きい(波の上下の振れ幅が大きい)部分は音量が大きく、小さい部分は音量が小さいことがわかる。
- **異常やノイズ
- 音声に含まれる突発的なノイズや歪みなどが、波形の不規則なパターンとして見えることがある。
-
個々の音イベントのタイミング
- 波形を見ることで、音声信号の様々な特徴を視覚的に捉えることができる。
-
波形のプロット方法
- Pythonだと以下を使えば、簡単に波形を表示できる
-
librosa- Python で音声データを扱う際によく使われるライブラリの1つ。
-
matplotlib.pyplot- Pythonでグラフ表示のための標準的なライブラリ
-
- Pythonだと以下を使えば、簡単に波形を表示できる
Colaboratoryで
librosaをインストール
!pip install librosa
!pip freeze | grep -i librosa
librosa==0.11.0
librosaのサンプルオーディオデータ(トランペットの音)を読み込む
import librosa
# オーディオデータを読み込むと以下のタプルが返される
# - 時系列のオーディオデータ(`numpy.ndarray`)
# - サンプリングレート(`int`)
array, sampling_rate = librosa.load(librosa.ex("trumpet"))
librosaのwaveshow()に、オーディオデータとサンプリングレートを渡して波形をグラフで表示。
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)

- 表示されているグラフが波形。横軸が時間(秒)、縦軸が振幅。
- 波が大きく上下に振れている箇所は音が大きく、振れが小さい箇所は音が小さい
- トランペットの音が鳴っている部分と、無音の部分が視覚的に区別できる
-
重要
-
librosaはデフォルトで音声データを浮動小数点数の配列として読み込む。 - その値は通常 -1.0 から 1.0 の範囲に正規化されている(前のセクションで触れた話)
-
ちなみに以下でその場で再生
from IPython.display import Audio
display(Audio(data=array, rate=sampling_rate))

- 波形表示のメリット
- 実際に音を聞くことと波形を見ることを組み合わせれば、扱っているデータをより深く理解できる。
- 信号の全体的な形やパターンを観察できる。
- ノイズや歪みを見つける手がかりになる。
- 正規化やリサンプリングなどの前処理を行った際に、その処理が期待通りに行われたかを目で確認できる。
- 機械学習モデルを訓練した後、モデルが間違えたサンプルの波形を可視化することで、エラーの原因を探るのに役立つ
- 例: 特定のノイズに弱い、など。
まとめ:
- 波形は、横軸を時間、縦軸を振幅として音声データをプロットしたもの(時間領域表現)。
- 音の大きさの変化やイベントのタイミングを視覚的に捉えることができる。
- Python の
librosaライブラリなどで簡単に表示できる。 - データ理解、前処理の確認、モデルのデバッグなどに役立つ。
周波数スペクトル
音を「時間の流れ」で見たものが「波形」だったのに対して、音を**「周波数(音の高さ)の成分」**で見る方法、周波数スペクトル (Frequency Spectrum) について。
-
周波数スペクトルとは?
- ある瞬間において、その音(信号)がどのような周波数成分(どの高さの音)を、それぞれどれくらいの強さ(振幅)で含んでいるかを示したもの。
- 波形が「時間領域 (Time Domain)」表現だったのに対し、周波数スペクトルは 「周波数領域 (Frequency Domain)」 表現と呼ばれる。
- 周波数スペクトルは 離散フーリエ変換 (DFT: Discrete Fourier Transform) という数学的な計算によって求められる。
- コンピューターでは、これを高速に計算するアルゴリズムである高速フーリエ変換 (FFT: Fast Fourier Transform) が使われる。
- DFTとFFTは実質的に同じものを指すことが多い。
-
スペクトルのプロット
import numpy as np
# 前回のトランペットのオーディオデータの先頭4096サンプルを使用
dft_input = array[:4096]
# DFTを計算
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# 振幅スペクトルをデシベル単位で取得
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# 周波数区分を取得
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")
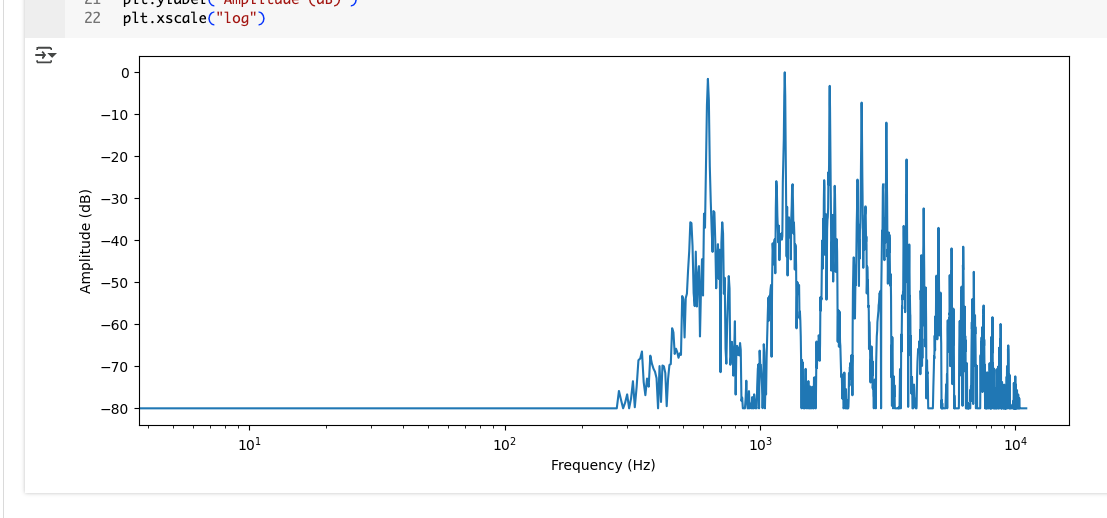
- 前の章のトランペットの音の一部分(最初の4096サンプル分)について計算
- 音全体ではなく、特定の短い区間の周波数成分を見ている。
-
横軸 (X軸) が周波数 (Frequency) を示す。単位はヘルツ (Hz)。
- 多くの場合、低い周波数から高い周波数まで幅広い範囲を表示するため、対数目盛 (log scale) が使われる(目盛の間隔が均等ではない)。
-
縦軸 (Y軸) が各周波数成分の振幅 (Amplitude) を示す。単位はデシベル (dB) 単位。
- dB表示にすることで、弱い成分も見やすくなる。
-
スペクトルプロットの解釈
- グラフにはいくつかの**ピーク(山)**が見える。
- その周波数の音が特に強く含まれていることを示している
- 楽器の音の場合、これらのピークは通常、基音(最も低い周波数のピーク) とその 倍音(Harmonics、基音の整数倍の周波数の音) に対応する。
- 倍音の構成が楽器の「音色」を決める
- この例では、最初のピークが約 620 Hz
- 音楽の音階でいうと E♭(ミのフラット)の音の基音に対応する。
- 上記より高い周波数にあるピークは、その E♭ の倍音。
- 高い倍音ほど振幅が小さく(音が弱く)なっているのがわかる。
- グラフにはいくつかの**ピーク(山)**が見える。
-
計算のポイント (
numpy,librosa)-
dft_input = array[:4096]- 元の音声データ (
array) の最初の4096サンプルを取り出し。
- 元の音声データ (
-
窓関数 (Window function)
-
window = np.hanning(...),windowed_input = dft_input * windowの部分。 - DFT計算の「お作法」のようなもの。
- 短い区間を取り出して分析する際に、区間の端の影響を和らげるために行う。
- (今は詳細を気にしなくても大丈夫)。
-
-
dft = np.fft.rfft(windowed_input)-
numpyライブラリの FFT 機能を使って DFT を計算する。 -
rfftは実数入力用の効率的なバージョン。
-
-
amplitude = np.abs(dft)- DFT の計算結果は複素数 (Complex number) の配列になる。
- ここから振幅情報を取り出すために、絶対値 (
np.abs) を計算する- (複素数の角度成分は位相 (Phase) を表すが、機械学習では捨てられることも多い。)
-
amplitude_db = librosa.amplitude_to_db(...)- 計算した振幅を、見やすいようにデシベル (dB) スケールに変換。
-
frequency = librosa.fft_frequencies(...)- プロットの横軸に対応する周波数の値(各 DFT 結果がどの周波数に対応するか)を計算。
-
plt.plot(frequency, amplitude_db)- 横軸に周波数、縦軸に振幅 (dB) をとってグラフをプロット
-
-
パワースペクトル (Power Spectrum):
- 振幅 (
amplitude) の代わりに、振幅の2乗(パワー、エネルギーに相当)を使ってプロットすることもある - これをパワースペクトルと呼ぶ。
- 振幅 (
-
波形とスペクトルの関係
- 波形(時間領域)と周波数スペクトル(周波数領域)は、同じ音声データの異なる側面を見ているだけであり、基本的には同じ情報を含んでいる。(非常に重要な点)
- 波形は「時間とともに振幅がどう変化するか」を示す
- スペクトルは「ある瞬間にどの周波数成分がどれくらいの強さで存在するか」を示す
- (理論的には、一方から他方へ変換することも可能で)
まとめ:
- 周波数スペクトルは、音がどのような周波数成分(音の高さ)で構成されているかを視覚化したもの(周波数領域表現)。
- DFT (FFT) という計算で求められる。
- グラフは通常、横軸に周波数 (Hz, 対数目盛が多い)、縦軸にその周波数の振幅 (dB) をとる。
- 楽器の音などでは、基音と倍音のピークが見られる。
- 波形(時間領域)とスペクトル(周波数領域)は、同じ情報の異なる表現方法である。
スペクトログラム
周波数スペクトルは、音のある一瞬における周波数成分の内訳を示していたが、音は時間とともに変化する。この時間の経過とともに周波数成分がどのように変化するかを見るためのものがスペクトログラム (Spectrogram) 。
-
スペクトログラムとは?
- 音の周波数成分の時間変化を視覚化したグラフ。
- 時間、周波数、振幅(強さ) の3つの情報を一枚の画像で表現する。
- スペクトログラムの作り方
- 元の音声信号を、非常に 短い時間区間(フレーム) に区切る (例: 数ミリ秒ごと)。
- それぞれの短い区間に対して、周波数スペクトルを計算 (DFT/FFT を使う)。
- 各区間の周波数スペクトルを、時間順に横に並べて表示する。
- この計算プロセス全体を 短時間フーリエ変換 (STFT: Short-Time Fourier Transform) と呼ぶ。
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()

-
スペクトログラムのプロット
- 上がスペクトログラムの例
- 一種の「ヒートマップ」のようなもの。
- 横軸 (X軸): 時間 (Time) を表す。左から右へ時間が進む(波形と同じ)。
- 縦軸 (Y軸): 周波数 (Frequency) をヘルツ (Hz) 単位で表す。下から上へ周波数が高くなる(周波数スペクトルと同じ)。
-
色 (Color): 各時刻、各周波数における成分の強さ(振幅 Amplitude または パワー Power) を表す。
- 通常、色が明るい(または暖かい色)ほど、その成分が強いことを示す。
- 色の濃淡はデシベル (dB) スケールで表示されることが多い。右側のカラーバーが色の強度と dB 値の対応を示している。
- 上の図の見かた
- 画像の一本の縦の線(スライス)は、その時刻における周波数スペクトルに対応する。
- それを時間方向に並べたものがスペクトログラム。
- トランペットが異なる音を演奏すると、明るい色の部分が上下に移動するのがわかる。
- 上がスペクトログラムの例
-
スペクトログラムの有用性
- 音声情報を視覚的に理解するための非常に強力なツール
-
音楽
- 楽器の音色変化、メロディーライン、リズムなどを視覚的に捉えられる。
-
音声
- 話し声の母音や子音の特徴(フォルマントと呼ばれる周波数構造)、声の高さ(ピッチ)の変化などを確認できる。
- 例: 異なる母音は特定の周波数帯域が強くなるパターンを持つため、スペクトログラム上で区別できる。
-
計算のポイント (
librosa)-
D = librosa.stft(array)-
librosaを使って STFT を計算。結果Dは複素数の行列になる。
-
-
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)- STFTの結果(複素数)の絶対値をとって振幅(またはパワー)を計算し、それを dB スケールに変換。
-
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")- 計算した dB スケールのスペクトログラムデータ
S_dbを、横軸を時間、縦軸を周波数 (Hz) として表示。
- 計算した dB スケールのスペクトログラムデータ
-
librosa.stft()はデフォルトで音声を 2048 サンプルのフレームに区切って処理する。- このフレームサイズは、時間分解能(どれだけ細かい時間変化を見られるか)と周波数分解能(どれだけ細かい周波数差を見られるか)のトレードオフに関係する。
-
-
スペクトログラムからの逆変換
- スペクトログラムは元の波形から計算されるため、理論的には逆短時間フーリエ変換 (ISTFT: Inverse STFT) を使ってスペクトログラムから元の波形に戻すことも可能。
- ただし、通常スペクトログラムとして扱われるのは振幅(またはパワー)情報のみで、計算に必要な位相 (Phase) 情報が失われていることが多い。
- 機械学習モデルがスペクトログラムを生成した場合など、位相情報がない場合は、Griffin-Lim アルゴリズムのような古典的な手法や、Vocoder (ボコーダー) と呼ばれるニューラルネットワークを使って位相を推定し、波形を再構築する必要がある
-
機械学習における重要性
- スペクトログラムは単なる可視化ツールではない。
- 多くの音声関連の機械学習モデルでは、生の波形データの代わりに、このスペクトログラムを入力として利用する
- 画像認識の技術を応用しやすいため。
*音声生成モデルの中には、直接波形を生成するのではなく、まずスペクトログラムを生成し、それを後段の Vocoder で波形に変換するものもある。
- 画像認識の技術を応用しやすいため。
- 多くの音声関連の機械学習モデルでは、生の波形データの代わりに、このスペクトログラムを入力として利用する
- スペクトログラムは単なる可視化ツールではない。
まとめ
- スペクトログラムは、音の周波数成分が時間とともにどう変化するかを視覚化したもの。
- 横軸が時間、縦軸が周波数、色がその成分の強さ(振幅/パワー) を表す。
- STFT (短時間フーリエ変換) という計算で作られる。
- 音楽や音声の特徴(メロディー、音色、母音/子音など)を視覚的に捉えるのに非常に有効。
- 機械学習モデルの入力としてよく使われる重要な表現形式。
- スペクトログラム(特に振幅情報のみ)から波形に戻すには、位相推定(Griffin-Lim や Vocoder)が必要になる場合がある。
メルスペクトログラム
メルスペクトログラムは、通常のスペクトログラムを人間の聴覚特性に合わせて少し変形したもの。スペクトログラムの一種で、特に音声認識や話者認識など、人間の聴覚特性が重要になるタスクでよく使われる。
-
メルスペクトログラム とは?
- 通常のスペクトログラムと同様に、音の周波数成分の時間変化を示す。
-
違いは縦軸(周波数軸)のスケール
- 通常のスペクトログラム
- 周波数軸は線形(リニア)で、単位はヘルツ (Hz) 。
- 例えば、100 Hz と 200 Hz の間隔と、1000 Hz と 1100 Hz の間隔はグラフ上では同じ幅で表示される。
-
メルスペクトログラム
- 周波数軸がメル尺度 (Mel scale) という特殊なスケールになっている。
- 通常のスペクトログラム
-
メル尺度 (Mel Scale) とは?
- 人間の耳の周波数に対する感度をモデル化した尺度。
- 人間の耳は、低い周波数の変化には敏感だが、高い周波数の変化には鈍感。
- 例えば、100 Hz と 200 Hz の違いははっきり聞き分けられるが、10000 Hz と 10100 Hz の違いを聞き分けるのはずっと難しい。
- メル尺度はこの特性を反映
- 低い周波数帯域は細かく、高い周波数帯域は大まか に扱う。
- グラフ上では、低い周波数領域が引き伸ばされ、高い周波数領域が圧縮されたように表示される。
-
メルスペクトログラムの作り方
- 基本はスペクトログラムと同じ
- STFT を使って短時間区間ごとの周波数スペクトルを計算。
- 次に、計算された各周波数スペクトルに対して、メルフィルターバンク (Mel Filterbank) と呼ばれる特殊なフィルター群を適用する。
- このフィルターバンクは、人間の聴覚特性を模倣するように設計されていて、複数の周波数帯域(メルバンド)のエネルギーをまとめる。
- 低い周波数帯ではフィルターの間隔が狭く、高い周波数帯では広くなっている。
- このフィルターバンクを通すことで、線形の周波数軸 (Hz) がメル尺度に変換されます。
- 基本はスペクトログラムと同じ
-
メルスペクトログラムのプロット
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()

-
横軸 (X軸): 時間 (Time)
- (スペクトログラムと同じ)
-
縦軸 (Y軸): メル尺度 (Mel) で表された周波数
- 通常のスペクトログラムと比べて、低い周波数領域がより詳細に表示されているのが分かる。
-
色 (Color):
- 各時刻、各メルバンドにおける成分の強さ(パワー Power または 振幅 Amplitude)を dB スケールで示す。
- (スペクトログラムと同じ)
-
計算のポイント (
librosa)-
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)-
librosaを使ってメルスペクトログラムを計算する。 -
n_mels=128- メルフィルターバンクの数(=縦軸の解像度)を指定。
- よく使われるのは 40 や 80、この例では 128。
-
fmax=8000- 考慮する最高の周波数 (Hz) を指定。
- 人間の音声の場合、8000 Hz (8 kHz) あれば十分なことが多い。
-
-
S_dB = librosa.power_to_db(S, ref=np.max)- メルスペクトログラムのパワー値を dB スケールに変換。
- dB スケールに変換したものを特にログメルスペクトログラム (Log-Mel Spectrogram) と呼ぶ。
-
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", ...)- ログメルスペクトログラムを表示。
-
y_axis="mel"と指定することで、縦軸がメル尺度で表示される。
-
-
注意点
- メルスペクトログラムの計算方法は、使用するライブラリや設定(メル尺度の種類、パワーか振幅か、ログの取り方など)によって微妙に異なる場合がある。
- 機械学習モデルが特定の形式のメルスペクトログラムを期待している場合、それに合わせて計算方法を統一する必要がある。
-
メルスペクトログラムからの逆変換
- メルフィルターバンクを適用する過程で情報が失われる(複数の周波数帯をまとめるため)ので、メルスペクトログラムから元の波形に戻すのは、通常のスペクトログラムよりもさらに困難。
- Vocoder (HiFiGAN など) を使うことで、メルスペクトログラムから高品質な波形を生成することが可能。
- ESPnet など、多くの音声合成システムはこのアプローチを採用している。
-
メルスペクトログラムの利点
- 人間の聴覚特性に近い形で音声の特徴を捉えることができます。
- 特に、人間が音を聞いて判断するタスクにおいて、生のスペクトログラムよりも効果的な特徴量となることが多い
- 音声認識 (Speech Recognition)
- 話者認識 (Speaker Identification)
- 音楽ジャンル分類など
- 特に、人間が音を聞いて判断するタスクにおいて、生のスペクトログラムよりも効果的な特徴量となることが多い
- 人間の聴覚特性に近い形で音声の特徴を捉えることができます。
まとめ
- メルスペクトログラムは、スペクトログラムの周波数軸を人間の聴覚特性に合わせて変形(メル尺度)したもの。
- 低い周波数領域の変化をより重視し、高い周波数領域の変化は圧縮して表現する。
- メルフィルターバンクという処理を加えて作られる。
- 縦軸がメル尺度になり、低い周波数帯が引き伸ばされて表示される。
- dBスケールにしたものはログメルスペクトログラムと呼ばれる。
- 音声認識など、人間の聴覚に関連するタスクで非常に有効な特徴量として使われる。
- 波形への逆変換は通常のスペクトログラムより難しく、Vocoder が必要となることが多い。
むずいけど、おいおい理解を深めていくか。
オーディオデータセットの読み込みと探索
実際に音声データセットを読み込んで、その中身を確認していく。Colaboratoryで試す。
🤗 Datasets ライブラリとは?
- Hugging Face が開発しているオープンソースの Python ライブラリ。
- テキスト、画像、音声など、様々な種類のデータセットを簡単にダウンロードしたり、準備したりするために設計されている
- 膨大な数のデータセットを公開しているオンラインプラットフォーム「Hugging Face Hub」に簡単にアクセスできる。
- 特に 音声データセットを扱いやすくするための機能が豊富 に用意されています。
インストール方法
パッケージインストール。音声関連の機能(オーディオファイルの読み込みなど)を使うためには、[audio] という追加オプション(extra)をつけてインストールする必要がある
!pip install datasets[audio]
load_dataset()
- 🤗 Datasets ライブラリの中心的な機能の一つ。
- 多くの場合、1行のコードで Hugging Face Hub からデータセットをダウンロードし、すぐに使える状態にしてくれる
- データセットのダウンロード、展開、キャッシュ(一度ダウンロードしたら次回は高速に読み込めるように保存しておくこと)などを自動で行ってくれる。
4. データセットの読み込み例
以下のデータセットを例に。
MINDS-14 は、様々な言語・方言で、人々が E バンキングシステムに質問している音声を録音したデータセット
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
- 引数
-
"PolyAI/minds14"- 読み込みたいデータセットの ID を指定
- Hugging Face Hub 上で各データセットに付けられている固有の名前
- 通常は「ユーザー名/データセット名」or 「組織名/データセット名」の形式
-
name="en-AU"- MINDS-14 データセットには複数の言語・方言が含まれている
- この引数で、その中の特定のサブセット(ここではオーストラリア英語
en-AU)を指定している - データセットによっては「設定 (configuration)」と呼ばれることもある。
-
split="train"- データセットは通常、以下のような分割(
split)が用意されている- トレーニング用 (
train) - 検証用 (
validation) - テスト用 (
test)
- トレーニング用 (
- ここでは「トレーニング用」のデータだけを読み込むように指定
- データセットは通常、以下のような分割(
-
実行

Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 654
})
load_dataset()は、読み込んだデータセットを表すオブジェクトを返す(ここでは minds変数に格納される)。
- 出力
-
Dataset(...)- 読み込まれたデータが 🤗 Datasets の
Datasetオブジェクトであることを示す。
- 読み込まれたデータが 🤗 Datasets の
-
features: [...]- このデータセットに含まれる情報の種類(列名、特徴量)のリスト。
-
path- 音声ファイルへのパス
-
audio- 音声データそのもの(後ほど)
-
transcription- 音声の書き起こしテキスト
-
english_transcription- 英語への翻訳(このサブセットでは元の書き起こしと同じはず)
-
intent_class- 発話の意図を示す分類ラベル(数値)
-
lang_id- 言語 ID(このサブセットでは全て同じはず)
-
num_rows: 654- このデータセット(
en-AUのtrainスプリット)に含まれるサンプル(行)の数が 654 個であることを示す
- このデータセット(
-
サンプルへのアクセス
example = minds[0] のように、インデックスを指定することで、データセットから特定のサンプルを取り出すことができる
example = minds[0]
example
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0.00024414, 0.0012207 ]),
'sampling_rate': 8000},
'transcription': 'I would like to pay my electricity bill using my card can you please assist',
'english_transcription': 'I would like to pay my electricity bill using my card can you please assist',
'intent_class': 13,
'lang_id': 2}
audioが音声データを格納しており、以下のキーを持つ辞書になっている
-
path- 上と同じファイルパス
-
array- デコード(読み込み)済みの音声データが、NumPy 配列(1次元の数値のリスト)として格納されている。
- この配列の各数値が、サンプリングされた各点の振幅値を表す。
-
dtype=float32とあるように、32ビット浮動小数点数になっていることがわかる
-
sampling_rate- 音声データのサンプリングレート。
- この例では
8000Hz であることがわかる。
なお、🤗 Datasets は、特徴量名が 'audio' である列を特別扱いし、自動的に音声ファイルを読み込んで 'array' と 'sampling_rate' を含む辞書形式にしてくれる。ユーザーはファイルパスを意識せずに、すぐに数値データとサンプリングレートにアクセスできて便利。以下のドキュメントに記載がある。
オーディオデータセットには、3つの重要なフィールドを含む「Audio」というタイプの列があります。
array: 1次元配列として表されるデコードされたオーディオデータ。path: ダウンロードしたオーディオファイルのパス。sampling_rateオーディオデータのサンプリングレート。オーディオデータセットをロードしてオーディオ列を呼び出すと、Audio 機能によってオーディオファイルが自動的にデコードされ、リサンプリングされます。
また、ここではintent_classは分類上のカテゴリとなっているが、ラベルが数値になっていて、直感的ではない。🤗 Datasets では、データセットの情報(メタデータ)を使って、この数値を意味のあるラベル名に変換する int2str メソッドが用意されている。
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
pay_bill
実際にはこういうマッピングがデータセット内にあって、これのインデックス番号が付与されているみたい。
intent_feature_info = minds.features['intent_class']
intent_feature_info
ClassLabel(
names=['abroad', 'address', 'app_error', 'atm_limit', 'balance', 'business_loan', 'card_issues', 'cash_deposit', 'direct_debit', 'freeze', 'high_value_payment', 'joint_account', 'latest_transactions', 'pay_bill'],
id=None
)
データセットには様々な情報が含まれているが、特定のタスク(例えば、このデータを使って音声分類器を訓練する場合)にとっては、必ずしもすべての情報が必要とは限らない。以下のようなケースでは、不要な情報を削除することで、データセットをシンプルにして、処理を効率化できる場合がある。
-
情報が冗長
- ある列の情報が他の列から推測できたり、全く同じだったりする場合。
- 例: この
en-AUサブセットでは、english_transcriptionはtranscriptionと同じ内容になる可能性が高い。
-
情報がタスクに無関係
- ある列の値がすべてのサンプルで同じだったり、訓練するモデルにとって意味のない情報だったりする場合。
- 例:
en-AUサブセットだけを使うなら、lang_idはすべてのサンプルで同じ値2になり、分類の役には立たない。
-
メモリやストレージの節約
- 不要な列を削除することで、データセット全体のサイズを小さくできる。
-
処理の簡略化
- 扱う列が少ない方が、後のデータ処理やモデルへの入力準備がシンプルにできる。
remove_columnsメソッドを使うと指定した列を削除することができる。
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
Dataset({
features: ['path', 'audio', 'transcription', 'intent_class'],
num_rows: 654
})
実際の音声データを聞いてみる。ドキュメントではGradioを使ってランダムな音声データを再生する以下のようなコードが紹介されている。
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
ColaboratoryだとGradioは面倒なので、IPythonで。
from IPython.display import Audio
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["array"],
audio["sampling_rate"],
), id2label(example["intent_class"]), example["transcription"]
for _ in range(4):
audio, label, transcription = generate_audio()
print(f"Transcription: {transcription}")
print(f"Intent: {label}")
display(Audio(data=audio[0], rate=audio[1]))

波形の可視化
データセットの中身を理解するもう一つの方法として、波形 (Waveform) をプロットする。以下のライブラリを使う。
-
librosa: 音声分析と可視化のためのライブラリ。特にlibrosa.display.waveshowを使う。 -
matplotlib.pyplot: グラフ描画のための標準的なライブラリ。librosaの表示機能の背後で使われる。
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)

音声データセットの前処理
前処理のステップ
-
リサンプリング
- データセットに含まれる音声データのサンプリングレート(1秒あたりのサンプル数)を、モデルが期待する値に変換
- 多くのモデルは16kHzを想定しているが、データセットが異なるサンプリングレート(例えば8kHz)の場合、アップサンプリング(またはダウンサンプリング)が必要
- 🤗 Datasets の
cast_columnメソッドを使用。
-
フィルタリング
- 特定の条件に基づいてデータセットから不要なサンプルを除外。
- 例: 長すぎる音声データを取り除く(メモリ不足の原因になることがある)
- 🤗 Datasets の
filterメソッドを使用。
-
モデルの入力形式への変換
- 生の音声データ(数値の配列)を、事前学習済みモデルが処理できる形式(特徴量)に変換
- 🤗 Transformers ライブラリは、モデルごとに専用の Feature Extractor を提供
- これを使えば、音声データをモデルに適した形式(例: Whisperモデルの場合はログメルスペクトログラム)に簡単に変換可能。
1. 音声データのリサンプリング
- なぜリサンプリングが必要?
- 🤗 Datasets ライブラリでデータセットを読み込むと、音声データは元々作成された時の サンプリングレート(1秒間に音の波を何回記録したかを示す数値、単位は Hz または kHz)でダウンロードされる。
- 使いたい事前学習済みモデル(例えば、音声認識モデルなど)は、特定のサンプリングレート(例えば 16 kHz = 1秒間に16,000回)で学習されていることが多い。
- データセットのサンプリングレートと、モデルが期待するサンプリングレートが異なっていると、モデルはうまく音声を処理できない
- データセットの音声データを、モデルが期待するサンプリングレートに変換する必要がある。この変換作業を リサンプリング と呼ぶ
- 具体例:MINDS-14 データセット
- 上で扱った
MINDS-14データセットは、サンプリングレートが 8 kHz - 多くの音声モデルは 16 kHz で学習されている
- 8 kHz の音声データを 16 kHz に変換する アップサンプリング が必要になる。
- 上で扱った
🤗 Datasets でのリサンプリング方法
🤗 Datasets ライブラリの cast_column というメソッドを使うと、簡単にリサンプリングができる。
データセットの読み込み(前回箇所)
!pip install datasets[audio]
!pip freeze | grep datasets
datasets==3.5.1
データセットを読み込み
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 654
})
データの1つを確認。
minds[0]
サンプリングレートが8000Hzになっている。
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0.00024414, 0.0012207 ]),
'sampling_rate': 8000},
'transcription': 'I would like to pay my electricity bill using my card can you please assist',
'english_transcription': 'I would like to pay my electricity bill using my card can you please assist',
'intent_class': 13,
'lang_id': 2}
from datasets import Audio
# 'audio' 列のサンプリングレートを 16 kHz に設定するよう指示
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
データの1つを確認。
minds[0]
サンプリングレートが8000Hzから16000Hzにリサンプリングされている。
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'array': array([2.36119668e-05, 1.92324660e-04, 2.19284790e-04, ...,
9.40907281e-04, 1.16613181e-03, 7.20883254e-04]),
'sampling_rate': 16000},
'transcription': 'I would like to pay my electricity bill using my card can you please assist',
'english_transcription': 'I would like to pay my electricity bill using my card can you please assist',
'intent_class': 13,
'lang_id': 2}
cast_column は、データセットファイル内の音声データを 直接書き換えるわけではなく、データセットから音声データを 読み込むたびに、指定されたサンプリングレート (16 kHz) に 動的に変換 する。これにより、元の音声ファイルを変更することなく、必要なサンプリングレートでデータを扱える。
- リサンプリング後の変化
- リサンプリングを行うと、音声データの配列 (
array) の中身も変わる。 - 例: 8 kHz から 16 kHz にアップサンプリングすると、1秒あたりのサンプル数が2倍になる。
- つまり、元の配列よりも多くの数値が含まれるようになる
- リサンプリングを行うと、音声データの配列 (
- リサンプリングの背景
-
ナイキスト定理
- あるサンプリングレート(例えば 8 kHz)で記録された音声は、その半分の周波数(4 kHz)を超える音を含んでいないことが保証される。
-
アップサンプリング
- サンプリングレートを上げる場合(8 kHz → 16 kHz)、元のサンプル点の間の滑らかなカーブを推測して、新しいサンプル点を計算で補間する。
-
ダウンサンプリング
- サンプリングレートを下げる場合(16 kHz → 8 kHz)、単純にサンプル点を間引く(例えば1つおきに捨てる)だけでは エイリアシング という歪みが発生してしまう。
- そのため、まず新しいナイキスト周波数(8 kHz の場合 4 kHz)を超える周波数成分をフィルターで除去してから、サンプル点を減らす必要がある
- リサンプリングを正しく行うのは少し複雑であり、
librosaや 🤗 Datasets のようなライブラリに任せるのがベスト
-
ナイキスト定理
まとめ
- モデルが期待するサンプリングレートとデータセットのサンプリングレートが異なる場合、リサンプリングが必要。
- 🤗 Datasets の
cast_columnメソッドを使うと、データを読み込む際に動的にリサンプリングできる。 -
cast_columnは元のファイルを変更しない。 - リサンプリング(特にダウンサンプリング)は単純な間引きではなく、適切な処理が必要。
2. データセットのフィルタリング
- なぜフィルタリングが必要か?
- データセットには、モデルの学習や推論に使う上で、不都合なデータが含まれていることがある
- これらのデータを フィルタリング(除外)する必要が出てくる場合がある
- 例: 音声データの長さ に基づいてフィルタリング
- 非常に長い音声データが含まれていると、モデル学習中に メモリ不足エラー が発生する可能性がある
- 一定の長さ(例えば20秒)を超える音声データを除外する
- 例: 音声データの長さ に基づいてフィルタリング
🤗 Datasets でのフィルタリング方法
🤗 Datasets ライブラリの filter メソッドを使うと、条件に合致するデータだけを残す(または除外する)ことができる
フィルタリングを行うには、まず「どのデータを残し、どのデータを除外するか」を判断するための 関数 を定義する。
例:「音声の長さが20秒未満かどうか」を判定する関数
MAX_DURATION_IN_SECONDS = 20.0 # 最大許容時間(秒)
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
- 与えられた
input_length(音声の秒数) がMAX_DURATION_IN_SECONDS(ここでは20.0秒) より短ければTrueを返す - そうでなければ
Falseを返す
filter メソッドを使うには、どの列の値を基準にフィルタリングするかを指定する必要があるが、MINDS-14 データセットには、最初から「音声の長さ」を示す列は含まれていないため、以下の手順でフィルタリングする。
- 音声の長さを計算し、新しい列を追加
- データセット内の各音声ファイルのパス (
path列) を使って、音声の長さを計算-
librosaのget_duration関数を使う
-
- 計算した長さのリストを
new_columnとして作成 -
add_columnメソッドでdurationという名前の新しい列としてデータセットに追加
- データセット内の各音声ファイルのパス (
import librosa # librosa をインポート
# 各音声ファイルのパスから長さを計算しリストに格納
new_column = [librosa.get_duration(path=x) for x in minds["path"]]
# 'duration' という名前で新しい列を追加
minds = minds.add_column("duration", new_column)
minds
Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id', 'duration'],
num_rows: 654
})
minds[0]
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/f9018fd3747971e77d59e6c5da3fdf9d5bb914c495e16c23e1fe47c921d76a7a/en-AU~PAY_BILL/response_4.wav',
'array': array([2.36119668e-05, 1.92324660e-04, 2.19284790e-04, ...,
9.40907281e-04, 1.16613181e-03, 7.20883254e-04]),
'sampling_rate': 16000},
'transcription': 'I would like to pay my electricity bill using my card can you please assist',
'english_transcription': 'I would like to pay my electricity bill using my card can you please assist',
'intent_class': 13,
'lang_id': 2,
'duration': 7.801875} # durationが追加されている
-
filterメソッドでフィルタリング- 定義した
is_audio_length_in_range関数と、新しく追加したduration列を使ってfilterメソッドを呼び出す -
input_columns=["duration"]で、duration列の値をis_audio_length_in_range関数に渡し、結果がTrueのデータだけを残す
- 定義した
# is_audio_length_in_range 関数と duration 列を使ってフィルタリング
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
minds
Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id', 'duration'],
num_rows: 624 # 数が減っている
})
- 不要になった列を削除
- フィルタリング後は
duration列はもう不要 -
remove_columnsメソッドで削除。
- フィルタリング後は
# 'duration' 列を削除
minds = minds.remove_columns(["duration"])
minds
Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 624
})
これにより、minds データセットは、音声の長さが20秒未満のサンプルだけになる。確認してみる。
import matplotlib.pyplot as plt
durations = [librosa.get_duration(path=x) for x in minds["path"]]
plt.hist(durations, bins=20)
plt.xlabel("Duration (seconds)")
plt.ylabel("Frequency")
plt.title("Histogram of Audio Durations")
plt.show()

まとめ
- データセットから特定の条件(例: 音声の長さが20秒以上)に基づいて不要なサンプルを除外することをフィルタリングという。
- 🤗 Datasets の
filterメソッドと、条件を判定する関数を使ってフィルタリングを行う。 - フィルタリングの基準となる列が存在しない場合は、
add_columnで一時的に何らかの列を追加し、フィルタリング後にremove_columnsで削除するという手順が有効
3. 音声データの前処理 (モデル入力への変換)
- なぜ前処理が必要か?
- データをモデルが学習(または推論)できる形式に変換することは、音声データセットを扱う上で最も重要なステップの一つ
- 生の音声データは単なる 数値の配列 (サンプル値の集まり) にすぎない。
- 使いたい事前学習済みモデルが、この生の数値配列をそのまま入力として受け取るわけではない
- モデルは、特定の形式に加工された 特徴量 (features) を入力として期待する
- どのような特徴量が必要かは、モデルのアーキテクチャ(構造)や、そのモデルがどのようなデータで事前学習されたかによって異なる
- 🤗Transformers の Feature Extractor
- 🤗Transformers ライブラリは、サポートされている各音声モデルに対して Feature Extractor (特徴抽出器) というクラスを提供している
- これらは、生の音声データを、そのモデルが期待する入力特徴量に変換してくれる便利なツール
- Feature Extractor は何をするのか?
- 例: Whisperの Feature Extractor
-
パディング / トランケーション (Padding / Truncation)
- Whisper モデルは、入力される音声が必ず 30秒 の長さであることを期待する。
- これを満たすために、Feature Extractor は、バッチ内の各音声データに対して以下の処理を行う。
- 30秒より 短い 音声の場合
- 末尾に ゼロを追加 して30秒の長さにします (音声信号におけるゼロは無音を表す)。これを パディング と呼ぶ。
- 30秒より 長い 音声の場合
- 30秒を超える部分を カット する。これを トランケーション と呼ぶ。
- 30秒より 短い 音声の場合
- これにより、全ての音声データが同じ長さ (30秒) に揃えられる。
- (補足: Whisper は特殊で、多くの他のモデルではパディングした部分をモデルが無視するように「アテンションマスク」という情報が必要だが、Whisper はマスクなしで処理できるように学習されている)
-
ログメルスペクトログラムへの変換
- 次に、長さを揃えられた音声配列を ログメルスペクトログラム (log-mel spectrogram) に変換する。
- スペクトログラムは、信号の周波数成分が時間とともにどう変化するかを表す図。
- ログメルスペクトログラムは、周波数軸を メル尺度 (人間の聴覚特性に近い尺度) に、振幅軸を デシベル (対数) に変換したもの。より人間の聴覚に近い形で音声の特徴を表現する。
-
パディング / トランケーション (Padding / Truncation)
- 例: Whisperの Feature Extractor
実際の使い方
- Feature Extractor のロード
- まず、使いたいモデルのチェックポイントを指定して、対応する Feature Extractor をロード。
- 例: "openai/whisper-small"の場合
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
feature_extractor
- 前処理関数の定義
- 1つの音声サンプルを受け取り、Feature Extractor を使って前処理を行う関数を定義する
def prepare_dataset(example):
audio = example["audio"]
# Feature Extractor を呼び出して特徴量を計算
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features
- 音声データの配列 (
audio["array"]) とサンプリングレート (audio["sampling_rate"]) を Feature Extractor に渡し、変換後の特徴量を返す -
padding=Trueはパディング/トランケーションを有効にするための設定 (Whisper の場合は常に30秒に揃えられる)。
- データセット全体への適用
- 🤗Datasets の
mapメソッドを使って上記のprepare_dataset関数をデータセットの 全てのサンプル に適用する。 - これにより、データセットに
input_featuresという新しい列が追加され、各サンプルに対応するログメルスペクトログラムが格納される
- 🤗Datasets の
# minds データセットの全サンプルに関数を適用
minds = minds.map(prepare_dataset)
minds

Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id', 'input_features'],
num_rows: 624
})
librosa&matplotlibで可視化
import numpy as np
import matplotlib.pyplot as plt
import librosa.display
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()

横軸が時間、縦軸がメル周波数、色がその強度 (デシベル) を表している。
-
マルチモーダルモデルと言語処理 (Tokenizer と Processor)
- 音声認識のように、音声だけでなくテキストも扱う マルチモーダル なタスクの場合、音声データ用の Feature Extractor に加えて、テキストデータを処理するための Tokenizer (トークナイザー) も必要になる
- 🤗 Transformers では、これらを個別にロードすることもできるし、**Processor (プロセッサー)**クラスを使って、Feature Extractor と Tokenizer をまとめてロードすることもできる。
- さらに
AutoProcessorを使えば、モデル名から適切な Processor を自動で読み込める。
from transformers import AutoProcessor
# Whisper の Feature Extractor と Tokenizer をまとめてロード
processor = AutoProcessor.from_pretrained("openai/whisper-small")
-
カスタム前処理
- 上記の記載は基本的な前処理ステップ
- 実際のデータによっては、さらに複雑な独自の変換が必要になる場合もある
- 独自の処理を Python 関数として書き、
mapメソッドを使えば、データセット全体に簡単に適用できる
まとめ
- モデルは生の音声データではなく、特定の形式に変換された 特徴量 を入力として受け取る。
- 🤗Transformers の Feature Extractor は、生の音声データをモデルに適した特徴量に変換するツール。
- Whisper モデルの Feature Extractor は、音声を30秒に揃え、ログメルスペクトログラム に変換しする。
-
from_pretrainedで Feature Extractor をロードし、mapメソッドでデータセット全体に前処理関数を適用。 - 音声とテキストを扱うモデルでは、Processor (Feature Extractor + Tokenizer) を使うと便利。
オーディオデータのストリーミング
大規模な音声データセットを効率的に扱うための「ストリーミングモード」 について。
ありがとうございます。それでは、最初のセクション「Streaming audio data」について、初心者向けにわかりやすく解説します。
なぜストリーミングが必要なのか?
- 音声データセットは、画像やテキストと比べて非常に大きなサイズになることが多い。
- 例: CD品質(44.1kHz, 16bit)の音声データは、たった1分で5MB以上。
- 数時間分の音声データを集めると、すぐに数十GB、数百GB、場合によっては1TBを超えることも。
- 大規模データセットをすべてダウンロードして保存しようとすると・・・
- パソコンのディスク容量が足りなくなる
- ダウンロードや前処理に膨大な時間がかかる
🤗 Datasets の「ストリーミングモード」とは?
- 上記の課題を解決するために、🤗 Datasets にはストリーミングモードが用意されている
- ストリーミングモードを使うと・・・
- データセット全体をダウンロードせず
- 必要なサンプルだけをその都度インターネット経由で取得し、メモリ上で処理
メリット
- ディスク容量を消費しない : どんなに大きなデータセットでも、ローカルに保存しなくてOK
- ダウンロードや前処理の待ち時間がほぼゼロ: 最初のサンプルが届いた時点ですぐに処理を始められる
- スクリプトの動作確認や実験が簡単: ほんの数サンプルだけ取得して、コードの動作をすぐに試せる
注意点
-
データはローカルにキャッシュされない
- 何度も同じデータを使いたい場合は、その都度ストリーミングが必要になる
-
サンプルへのアクセス方法が通常と異なる
- インデックス指定(
dataset[idx])は使えない - イテレータ(
next(iter(dataset)))やtake()メソッドを使う。
- インデックス指定(
使い方
以下のデータセットを使用する。10000時間・57GBのオーディオデータとなっている。なお、あらかじめデータセットの使用許諾に同意しておく必要がある。
ストリーミングモードでデータセットを読み込むには streaming=True を指定するだけ。
from datasets import load_dataset
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
サンプルを取得してみる。1件だけ取得する場合。
sample = next(iter(gigaspeech["train"]))
sample
{'segment_id': 'YOU0000000315_S0000660',
'speaker': 'N/A',
'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': 'xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294,
0.00036621]),
'sampling_rate': 16000},
'begin_time': 2941.889892578125,
'end_time': 2945.070068359375,
'audio_id': 'YOU0000000315',
'title': 'Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43',
'url': 'https://www.youtube.com/watch?v=zr2n1fLVasU',
'source': 2,
'category': 24,
'original_full_path': 'audio/youtube/P0004/YOU0000000315.opus'}
Colaboratoryで再生する場合
from IPython.display import Audio
display(Audio(data=sample["audio"]["array"], rate=sample["audio"]["sampling_rate"]))

複数件取得したい場合。最初の2件を取得してみる。
head = gigaspeech["train"].take(2)
list(head)
[{'segment_id': 'YOU0000000315_S0000660',
'speaker': 'N/A',
'text': "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
'audio': {'path': 'xs_chunks_0000/YOU0000000315_S0000660.wav',
'array': array([0.0005188 , 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294,
0.00036621]),
'sampling_rate': 16000},
'begin_time': 2941.889892578125,
'end_time': 2945.070068359375,
'audio_id': 'YOU0000000315',
'title': 'Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43',
'url': 'https://www.youtube.com/watch?v=zr2n1fLVasU',
'source': 2,
'category': 24,
'original_full_path': 'audio/youtube/P0004/YOU0000000315.opus'},
{'segment_id': 'AUD0000001043_S0000775',
'speaker': 'N/A',
'text': 'SIX TOMATOES <PERIOD>',
'audio': {'path': 'xs_chunks_0000/AUD0000001043_S0000775.wav',
'array': array([ 1.43432617e-03, 1.37329102e-03, 1.31225586e-03, ...,
-6.10351562e-05, -1.22070312e-04, -1.83105469e-04]),
'sampling_rate': 16000},
'begin_time': 3673.9599609375,
'end_time': 3675.260009765625,
'audio_id': 'AUD0000001043',
'title': 'Asteroid of Fear',
'url': 'http//www.archive.org/download/asteroid_of_fear_1012_librivox/asteroid_of_fear_1012_librivox_64kb_mp3.zip',
'source': 0,
'category': 28,
'original_full_path': 'audio/audiobook/P0011/AUD0000001043.opus'}]
Colaboratoryで再生する場合
from IPython.display import Audio
for h in head:
print("title:", h["title"])
print("text:", h["text"])
display(Audio(data=h["audio"]["array"], rate=h["audio"]["sampling_rate"]))

まとめ
- 音声データセットは非常に大きいため、全ダウンロードは非現実的な場合が多い
- 🤗 Datasets のストリーミングモードを使えば、必要なサンプルだけをその都度取得・処理できる
- ディスク容量やダウンロード時間の制約を気にせず、大規模データセットを扱える
- サンプルへのアクセス方法が通常と異なるので注意
ユニット2: オーディオアプリケーション
この時点で、あなたは🤗 Transformersが処理できるオーディオタスクについて学びたいと思っているかもしれません! オーディオタスクの例をいくつか見てみましょう:
- オーディオ分類: オーディオクリップをさまざまなカテゴリーに簡単に分類できます。 録音が犬の鳴き声なのか猫の鳴き声なのか、または曲がどの音楽ジャンルに属するのかを識別できます。
- 自動音声認識: 音声クリップを自動的に書き起こしてテキストに変換します。 今日の調子はどうですか」のように、誰かが話している録音をテキストで表現することができます。 メモを取るのに便利です!
- 話者ダイアライゼーション: 録音された音声の中で誰が話しているのか疑問に思ったことはありませんか? 🤗 Transformersを使えば、音声クリップの中でどの発言者が話しているのかを特定することができます。 アリス」と「ボブ」が会話している録音を区別できることを想像してみてください。
- 音声合成: 音声ブックを作成したり、アクセシビリティに役立てたり、ゲームのNPCに声を与えたりするために使用できる、テキストのナレーション付きバージョンを作成します。 トランスフォーマーを使えば、それが簡単にできます!
このユニットでは、🤗 Transformersのpipeline()関数を使用して、これらのタスクのいくつかに事前学習済みモデルを使用する方法を学びます。 具体的には、音声分類、自動音声認識、音声生成のために、事前に訓練されたモデルをどのように使うかを見ていきます。
オーディオ分類パイプライン
オーディオ分類とは?
オーディオ分類は、オーディオデータの内容に応じて「ラベル(カテゴリ)」を自動で割り当てるタスク。主な例は以下。
- 音声が「音楽」か「会話」か「ノイズ」かを判別
- 動物の鳴き声(犬/猫/鳥など)を分類
- 銀行の自動応答システムへの問い合わせ内容(「残高照会」「振込」「カード停止」など)を分類
🤗 Transformers の pipeline で音声分類
- Hugging Face の 🤗 Transformers ライブラリには、事前学習済みの音声分類モデルが多数公開されている
-
pipeline()関数を使えば、数行のコードで音声分類が実現できる
使い方
MInDS−14データセットを使う。
- 銀行の自動応答に対する問い合わせ音声(多言語)と、その「意図(intent)」ラベルが付与されたデータセット。
-
en-AU(オーストラリア英語)のサブセットを使う。
データセットをロード
from datasets import load_dataset, Audio
# MInDS-14データセットのen-AUサブセットをロード
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
# サンプリングレートを16kHzに変換(多くの音声モデルが16kHzを想定)
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
オーディオ分類タスク用パイプラインの準備
from transformers import pipeline
classifier = pipeline(
"audio-classification",
model="anton-l/xtreme_s_xlsr_300m_minds14", # MInDS-14のインテント分類にファインチューニングされたモデル
)
1件目のサンプルを使って推論。パイプラインにオーディオデータを渡すだけ。
import json
example = minds[0]
result = classifier(example["audio"]["array"])
print(json.dumps(result, indent=4))
[
{
"score": 0.9625312685966492,
"label": "pay_bill"
},
{
"score": 0.028672603890299797,
"label": "freeze"
},
{
"score": 0.0033497854601591825,
"label": "card_issues"
},
{
"score": 0.0020057973451912403,
"label": "abroad"
},
{
"score": 0.0008484313148073852,
"label": "high_value_payment"
},
{
"score": 0.0007367939106188715,
"label": "direct_debit"
},
{
"score": 0.0004056981997564435,
"label": "latest_transactions"
},
{
"score": 0.0003397068358026445,
"label": "joint_account"
},
{
"score": 0.0003312783665023744,
"label": "address"
},
{
"score": 0.00032886461121961474,
"label": "balance"
},
{
"score": 0.00014877464855089784,
"label": "app_error"
},
{
"score": 0.00014772477152291685,
"label": "atm_limit"
},
{
"score": 8.815666660666466e-05,
"label": "cash_deposit"
},
{
"score": 6.512476102216169e-05,
"label": "business_loan"
}
]
pay_billの確率が最も高い。
実際のデータのインテントと文字起こしを見てみる。
id2label = minds.features["intent_class"].int2str
print(id2label(example["intent_class"]))
print(example["transcription"])
pay_bill
I would like to pay my electricity bill using my card can you please assist
まとめ
-
pipeline()を使えば、前処理も含めて全て自動で音声分類ができる - 音声分類は「音声→ラベル」の自動判定タスク
- 🤗 Transformers の audio-classification パイプラインで、すぐに試せる
- モデルが対応しているラベルと自分の目的が一致しない場合は、ファインチューニングが必要
- まずは「既存モデルでどこまでできるか」を試してみるのがオススメ
- そのうえで必要ならばファインチューニングも視野に
音声認識パイプライン
音声認識(ASR)とは?
-
音声認識(ASR: Automatic Speech Recognition)
- 音声データを自動的にテキストに変換する技術
- 例
- 動画の自動字幕
- スマートスピーカーや音声アシスタントのコマンド認識
- 会議の議事録作成、など
🤗 Transformers の pipeline で音声認識
- Hugging Face の 🤗 Transformers ライブラリを使えば、多数公開されている事前学習済み音声認識モデルを利用可能
-
pipeline()関数を使えば、数行のコードで音声→テキスト変換が実現できる。
使い方
引き続き、MInDS-14 データセットを使用する。
パイプラインの準備。デフォルトだとfacebook/wav2vec2-base-960hがモデルとして使用される。
from transformers import pipeline
asr = pipeline("automatic-speech-recognition")
推論を実行
example = minds[0]
result = asr(example["audio"]["array"])
print(result)
{'text': 'I WOULD LIKE TO PAY MY ELECTRICITY BILL USING MY CAD CAN YOU PLEASE ASSIST'}
データセットの文字起こしを見てみる。
print(example["english_transcription"]) # transcriptionでもOK
I would like to pay my electricity bill using my card can you please assist
英語以外の言語で音声認識をしたい場合は、HuggingFace Hub でそれぞれの言語向けASRモデルを使って、model で指定する。ドイツ語の場合。
MInDS-14 データセットのドイツ語データを使用
from datasets import load_dataset
from datasets import Audio
minds = load_dataset("PolyAI/minds14", name="de-DE", split="train")
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
example = minds[0]
example["transcription"]
ich möchte gerne Geld auf mein Konto einzahlen
ドイツ語モデルを使用して文字起こし
from transformers import pipeline
asr = pipeline(
"automatic-speech-recognition",
model="maxidl/wav2vec2-large-xlsr-german"
)
result = asr(example["audio"]["array"])
print(result)
{'text': 'ich möchte gerne geld auf mein konto einzallen'}
まとめ
- 音声認識(ASR)は「音声→テキスト」変換のタスク
- 🤗 Transformers の
automatic-speech-recognitionパイプラインで、すぐに試せる- 前処理・後処理も自動でやってくれる、音声データをそのまま渡すだけでOK
- 既存モデルで十分な精度が出る場合は、すぐに実用可能
- 精度が足りない場合も、ファインチューニングのベースラインとして活用できる
- 多言語対応モデルも豊富に公開されている
音声合成パイプライン
音声生成(Text-to-Speech, TTS)
- テキストを自然な音声に変換する技術
- 例
- バーチャルアシスタントの読み上げ
- アクセシビリティ(視覚障害者向けの読み上げ)
- オーディオブック作成、など
🤗 Transformers の TTSパイプライン
-
"text-to-speech"または"text-to-audio"パイプラインを使う - 例:
suno/bark-small- 多言語に対応、英語・フランス語など様々な言語のテキストを自然な音声に変換できるモデル
TTSパイプラインの使い方
パイプラインを定義してモデルをロード
from transformers import pipeline
pipe = pipeline("text-to-speech", model="suno/bark-small")
音声を合成
text = "Ladybugs have had important roles in culture and religion, being associated with luck, love, fertility and prophecy."
output = pipe(text)
Colaboratory上で再生するには以下
from IPython.display import Audio
display(Audio(output["audio"], rate=output["sampling_rate"]))
生成された音声をファイルに出力するには以下
import numpy as np
from scipy.io.wavfile import write
# scipy.io.wavfile.write は、デフォルトで以下を期待する
# - 整数型(int16やuint16など)の配列
# - 1次元配列(N,)(モノラル)または2次元配列(N, 2)(ステレオ)
# output["audio"] は
# - float32型(-1.0〜1.0の範囲)のNumPy配列であることが多い
# - shapeが(1, N)(2次元配列、1行N列)になることがありWAVには不向き
# ため以下が必要
# - float32 → int16 に変換してから保存する
# - (N,) または (N, 2) に変換する
audio = output["audio"].squeeze()
sampling_rate = output["sampling_rate"]
audio_int16 = np.int16(audio / np.max(np.abs(audio)) * 32767)
write("output.wav", sampling_rate, audio_int16)
実際に生成されたものはこちら
日本語でもやってみる
text = "てんとう虫は、幸運、愛、豊穣、予言と関連付けられ、文化や宗教において重要な役割を果たしてきました。"
output = pipe(text)
また、Barkモデルは歌声や非言語音(例: ♪や感嘆詞)も生成できる。
song = "♪ In the jungle, the mighty jungle, the ladybug was seen. ♪ "
output = pipe(song)
Audio(output["audio"], rate=output["sampling_rate"])
日本語でも。
song = "♪ 夕やけ、小やけの、赤とんぼ ♪"
output = pipe(song)
Audio(output["audio"], rate=output["sampling_rate"])
音楽生成(Text-to-Music)
- テキストで音楽の特徴を指定し、AIが音楽を自動生成する技術
- 例
- ゲームや動画のBGM
- クリエイティブな音楽制作、など
🤗 Transformers の音楽生成パイプライン
-
"text-to-audio"パイプラインを使い、facebook/musicgen-smallなどのモデルを利用する。
text-to-audioパイプラインの使い方
- テキストで「どんな音楽を作りたいか」を自由に指定できる。
from transformers import pipeline
music_pipe = pipeline("text-to-audio", model="facebook/musicgen-small")
text = "90s rock song with electric guitar and heavy drums"
output = music_pipe(text, forward_params={"max_new_tokens": 512})
Audio(output["audio"][0], rate=output["sampling_rate"])
まとめ
- テキスト→音声、テキスト→音楽も、🤗 Transformers の pipeline で簡単に体験できる
- モデルによって、対応言語や生成できる音の種類が異なるため、用途に合わせて選択
- Barkモデルは多言語・歌声・非言語音も対応
- MusicGenはテキストで音楽ジャンルや雰囲気を細かく指定可能