データベース向けRAGフレームワーク「Vanna」を試す
Technology Radar October 2024で、「Dynamic Few-shot prompting」の使用例として紹介されていたのが「Vanna」。
ちなみに、Technology Radar April 2024でも「Text to SQL」の例として紹介されている。
GitHubレポジトリ
Vanna
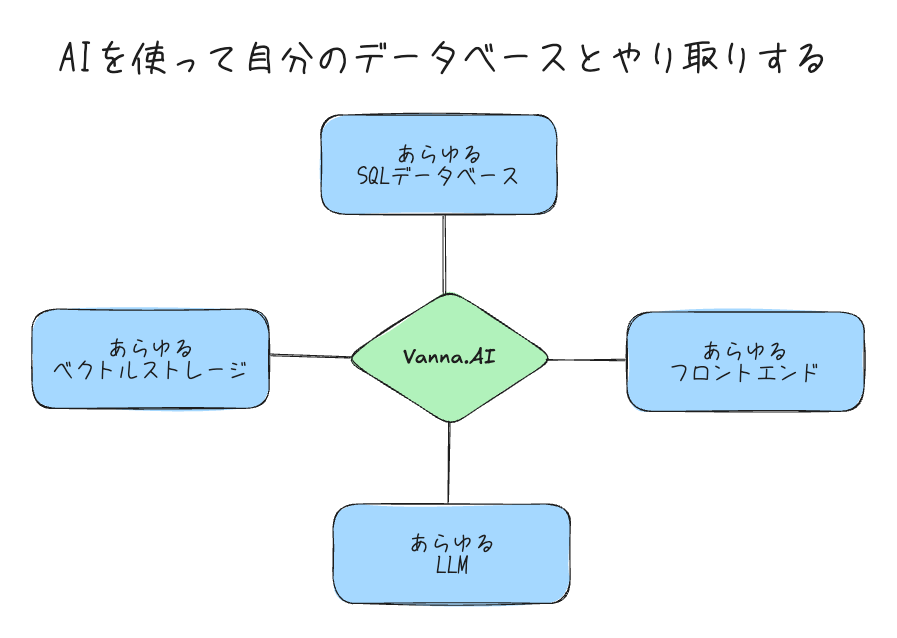
VannaはMITライセンスのオープンソースPython RAG (Retrieval-Augmented Generation)フレームワークで、SQL生成とそれらに関連する機能を提供する。
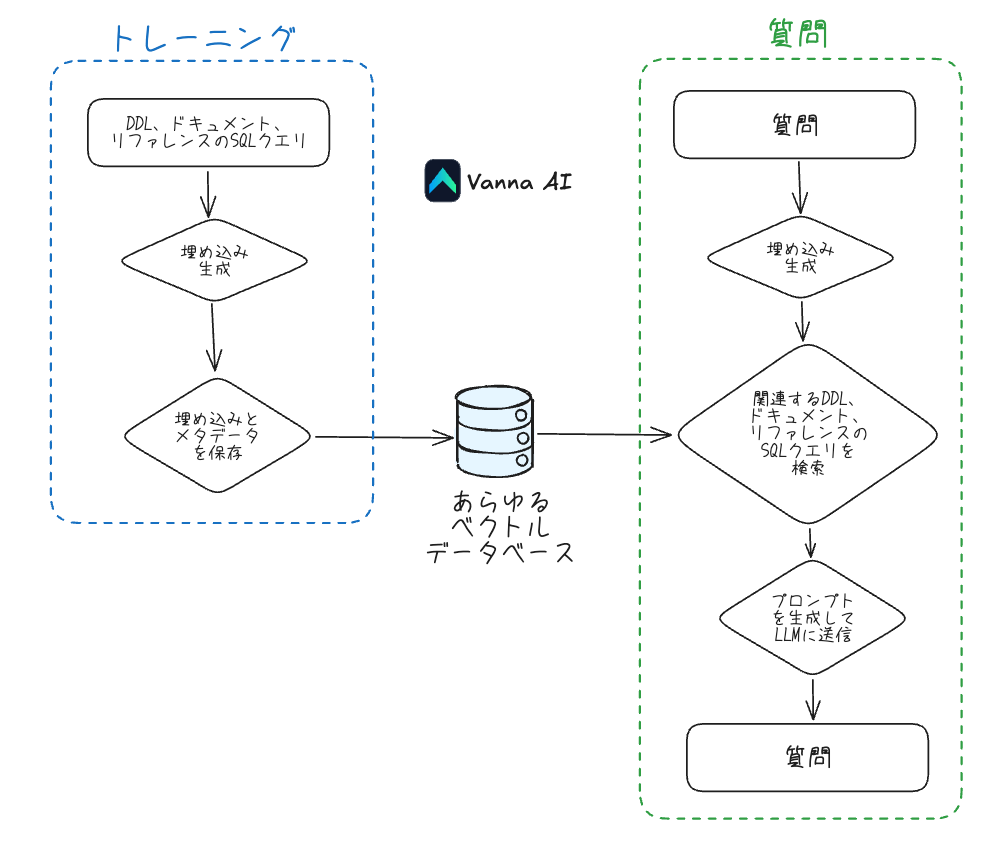
refered from https://github.com/vanna-ai/vanna and translated into Japanese by kun432Vannaの仕組み
refered from https://github.com/vanna-ai/vanna and translated into Japanese by kun432Vannaは2つの簡単なステップで動作します。まず、データに基づいてRAG「モデル」を訓練し、その後、データベースで自動実行されるSQLクエリを返す質問をします。
1. データに基づいてRAG「モデル」を訓練します。
2. 質問をします。
refered from https://github.com/vanna-ai/vanna and translated into Japanese by kun432RAGが何か分からなくても心配いりません。これを使うのに、内部でどのように動作しているかを知る必要はありません。ただ、「モデルを訓練する」ことでメタデータを保存し、その後「質問する」ために使うことを理解していれば十分です。
詳細な仕組みについては、ベースクラスを参照してください。

RAGとファインチューニングの比較
RAG
- LLM間で移植が可能
- 古くなった学習データがあれば簡単に削除できる
- ファインチューニングよりも運用コストが安い
- 将来性が高い — より優れたLLMが登場した場合、簡単に入れ替えることができる
ファインチューニング
- プロンプトのトークンを最小限に抑えたい場合に適している
- 開始が遅い
- 訓練と運用コストが高い(一般的に)
なぜVannaなのか?
- 複雑なデータセットで高い精度
- Vannaの能力は、提供された学習データに依存します。多くのデータを使うほど、大規模で複雑なデータセットでもより高い精度が得られます。
- 安全かつプライベート
- データベースの内容は、LLMやベクトルデータベースに送信されません。SQLの実行はローカル環境で行われます。
- 自己学習
- Jupyterを使う場合、成功したクエリに基づいて「自動学習」を選択できます。その他のインターフェースを使う場合は、インターフェースがユーザーにフィードバックを求めることも可能です。正しい質問と - SQLのペアが保存され、今後の結果の精度が向上します。
- あらゆるSQLデータベースに対応
- このパッケージは、Pythonで接続できる任意のSQLデータベースに接続できます。
- フロントエンドの選択肢
- 多くの人はJupyter Notebookから始めますが、Slackbot、ウェブアプリ、Streamlitアプリ、カスタムフロントエンドを通じてエンドユーザーに提供することも可能です。
Vannaの拡張
Vannaは、任意のデータベース、LLM、ベクトルデータベースに接続するように設計されています。VannaBaseという抽象基底クラスが基本的な機能を定義しており、OpenAIやChromaDBと共に使用するための実装が提供されています。自分のLLMやベクトルデータベースに簡単に拡張できます。詳細はドキュメントを参照してください。
公式ドキュメント
いつものごとくドキュメントのGetting Startedに従って進めるのだが、Vannaはクラウドサービスもやっている様子で、
どうもGetting Startedはこのクラウドサービスを使うようになっているみたい。
ただし、Getting Startedはもう一つあって、こちらは、LLM・ベクトルDB・リレーショナルDBをそれぞれ選択すると、それに合わせたコードが表示されるものとなっていて、またその場合にはVannaのクラウドサービスを使わないコードが表示される。
ということで、今回は以下のパターンでやってみようと思う。
- LLM: OpenAI
- ベクトルDB: Chroma
- リレーショナルDB: SQLite
上記の選択だと以下となる。
ではColaboratory上で進める。
まず、リレーショナルDBを用意する。今回はSQLiteで、Chinookのサンプルデータベースを使う。サンプルデータベースは以下のReleasesからダウンロードできる。SQLiteの場合はデータベースそのものがダウンロード可能。
sqlite3️のOSパッケージをインストール
!apt install sqlite3
ChinookのSQLite用DBファイルをダウンロード
!wget https://github.com/lerocha/chinook-database/releases/download/v1.4.5/Chinook_Sqlite.sqlite
ではVannaのパッケージをインストール。LLM・ベクトルDBごとにextrasが用意されている。
!pip install 'vanna[chromadb,openai]'
Vannaでは使用するLLM・ベクトルDBごとのクラスからサブクラスを作成して、このサブクラスから作成したインスタンスに対して操作を行う。OpenAIとChromaを使う場合はこんな感じになる。
from vanna.openai import OpenAI_Chat
from vanna.chromadb import ChromaDB_VectorStore
from google.colab import userdata
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(
config={'api_key': userdata.get('OPENAI_API_KEY'), 'model': 'gpt-4o-mini'},
)
SQLiteのサンプルデータベースに接続。
vn.connect_to_sqlite('Chinook_Sqlite.sqlite')
で、これだけでも一応簡単な問い合わせはできるようになる。
vn.ask(question="このデータベースにはどんなテーブルがありますか?")
/root/.cache/chroma/onnx_models/all-MiniLM-L6-v2/onnx.tar.gz: 100%|██████████| 79.3M/79.3M [00:01<00:00, 50.1MiB/s]
SQL Prompt: [{'role': 'system', 'content': "You are a SQLite expert. Please help to generate a SQL query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions. ===Response Guidelines \n1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question. \n2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql \n3. If the provided context is insufficient, please explain why it can't be generated. \n4. Please use the most relevant table(s). \n5. If the question has been asked and answered before, please repeat the answer exactly as it was given before. \n6. Ensure that the output SQL is SQLite-compliant and executable, and free of syntax errors. \n"}, {'role': 'user', 'content': 'このデータベースにはどんなテーブルがありますか?'}]
Using model gpt-4o-mini for 241.75 tokens (approx)
LLM Response: 提供されたコンテキストには、データベース内のテーブルに関する情報が含まれていないため、SQLクエリを生成することはできません。テーブルの情報を確認するには、データベースのスキーマ情報が必要です。
提供されたコンテキストには、データベース内のテーブルに関する情報が含まれていないため、SQLクエリを生成することはできません。テーブルの情報を確認するには、データベースのスキーマ情報が必要です。
Couldn't run sql: Execution failed on sql '提供されたコンテキストには、データベース内のテーブルに関する情報が含まれていないため、SQLクエリを生成することはできません。テーブルの情報を確認するには、データベースのスキーマ情報が必要です。': near "提供されたコンテキストには、データベース内のテーブルに関する情報が含まれていないため、SQLクエリを生成することはできません。テーブルの情報を確認するには、データベースのスキーマ情報が必要です。": syntax error
Embeddingモデルは"all-MiniLM-L6-v2"が使用される様子。OpenAI Embeddingsのクラスはあるのでいろいろ試してみたのだが、設定できなかった。またそのうち調べる。
で、データベースの情報がないのでわからない、というような回答になっているのがわかる。
そこでデータベースの情報を学習させる、というか、ベクトルDBに登録するのだろうと思う。
run_sqlでDBに対してSQLを発行できる。これでDDLを取得する。
df_ddl = vn.run_sql("SELECT type, sql FROM sqlite_master WHERE sql is not null")
df_ddl

これをVannaで学習する。DDLを学習させる場合はtrainメソッドのddlで指定する。
for ddl in df_ddl['sql'].to_list():
vn.train(ddl=ddl)
Adding ddl: CREATE TABLE [Album]
(
[AlbumId] INTEGER NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
CONSTRAINT [PK_Album] PRIMARY KEY ([AlbumId]),
FOREIGN KEY ([ArtistId]) REFERENCES [Artist] ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [Artist]
(
[ArtistId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_Artist] PRIMARY KEY ([ArtistId])
)
Adding ddl: CREATE TABLE [Customer]
(
[CustomerId] INTEGER NOT NULL,
[FirstName] NVARCHAR(40) NOT NULL,
[LastName] NVARCHAR(20) NOT NULL,
[Company] NVARCHAR(80),
[Address] NVARCHAR(70),
[City] NVARCHAR(40),
[State] NVARCHAR(40),
[Country] NVARCHAR(40),
[PostalCode] NVARCHAR(10),
[Phone] NVARCHAR(24),
[Fax] NVARCHAR(24),
[Email] NVARCHAR(60) NOT NULL,
[SupportRepId] INTEGER,
CONSTRAINT [PK_Customer] PRIMARY KEY ([CustomerId]),
FOREIGN KEY ([SupportRepId]) REFERENCES [Employee] ([EmployeeId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [Employee]
(
[EmployeeId] INTEGER NOT NULL,
[LastName] NVARCHAR(20) NOT NULL,
[FirstName] NVARCHAR(20) NOT NULL,
[Title] NVARCHAR(30),
[ReportsTo] INTEGER,
[BirthDate] DATETIME,
[HireDate] DATETIME,
[Address] NVARCHAR(70),
[City] NVARCHAR(40),
[State] NVARCHAR(40),
[Country] NVARCHAR(40),
[PostalCode] NVARCHAR(10),
[Phone] NVARCHAR(24),
[Fax] NVARCHAR(24),
[Email] NVARCHAR(60),
CONSTRAINT [PK_Employee] PRIMARY KEY ([EmployeeId]),
FOREIGN KEY ([ReportsTo]) REFERENCES [Employee] ([EmployeeId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [Genre]
(
[GenreId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_Genre] PRIMARY KEY ([GenreId])
)
Adding ddl: CREATE TABLE [Invoice]
(
[InvoiceId] INTEGER NOT NULL,
[CustomerId] INTEGER NOT NULL,
[InvoiceDate] DATETIME NOT NULL,
[BillingAddress] NVARCHAR(70),
[BillingCity] NVARCHAR(40),
[BillingState] NVARCHAR(40),
[BillingCountry] NVARCHAR(40),
[BillingPostalCode] NVARCHAR(10),
[Total] NUMERIC(10,2) NOT NULL,
CONSTRAINT [PK_Invoice] PRIMARY KEY ([InvoiceId]),
FOREIGN KEY ([CustomerId]) REFERENCES [Customer] ([CustomerId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [InvoiceLine]
(
[InvoiceLineId] INTEGER NOT NULL,
[InvoiceId] INTEGER NOT NULL,
[TrackId] INTEGER NOT NULL,
[UnitPrice] NUMERIC(10,2) NOT NULL,
[Quantity] INTEGER NOT NULL,
CONSTRAINT [PK_InvoiceLine] PRIMARY KEY ([InvoiceLineId]),
FOREIGN KEY ([InvoiceId]) REFERENCES [Invoice] ([InvoiceId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([TrackId]) REFERENCES [Track] ([TrackId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [MediaType]
(
[MediaTypeId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_MediaType] PRIMARY KEY ([MediaTypeId])
)
Adding ddl: CREATE TABLE [Playlist]
(
[PlaylistId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_Playlist] PRIMARY KEY ([PlaylistId])
)
Adding ddl: CREATE TABLE [PlaylistTrack]
(
[PlaylistId] INTEGER NOT NULL,
[TrackId] INTEGER NOT NULL,
CONSTRAINT [PK_PlaylistTrack] PRIMARY KEY ([PlaylistId], [TrackId]),
FOREIGN KEY ([PlaylistId]) REFERENCES [Playlist] ([PlaylistId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([TrackId]) REFERENCES [Track] ([TrackId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE TABLE [Track]
(
[TrackId] INTEGER NOT NULL,
[Name] NVARCHAR(200) NOT NULL,
[AlbumId] INTEGER,
[MediaTypeId] INTEGER NOT NULL,
[GenreId] INTEGER,
[Composer] NVARCHAR(220),
[Milliseconds] INTEGER NOT NULL,
[Bytes] INTEGER,
[UnitPrice] NUMERIC(10,2) NOT NULL,
CONSTRAINT [PK_Track] PRIMARY KEY ([TrackId]),
FOREIGN KEY ([AlbumId]) REFERENCES [Album] ([AlbumId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([GenreId]) REFERENCES [Genre] ([GenreId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([MediaTypeId]) REFERENCES [MediaType] ([MediaTypeId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Adding ddl: CREATE INDEX [IFK_AlbumArtistId] ON [Album] ([ArtistId])
Adding ddl: CREATE INDEX [IFK_CustomerSupportRepId] ON [Customer] ([SupportRepId])
Adding ddl: CREATE INDEX [IFK_EmployeeReportsTo] ON [Employee] ([ReportsTo])
Adding ddl: CREATE INDEX [IFK_InvoiceCustomerId] ON [Invoice] ([CustomerId])
Adding ddl: CREATE INDEX [IFK_InvoiceLineInvoiceId] ON [InvoiceLine] ([InvoiceId])
Adding ddl: CREATE INDEX [IFK_InvoiceLineTrackId] ON [InvoiceLine] ([TrackId])
Adding ddl: CREATE INDEX [IFK_PlaylistTrackTrackId] ON [PlaylistTrack] ([TrackId])
Adding ddl: CREATE INDEX [IFK_TrackAlbumId] ON [Track] ([AlbumId])
Adding ddl: CREATE INDEX [IFK_TrackGenreId] ON [Track] ([GenreId])
Adding ddl: CREATE INDEX [IFK_TrackMediaTypeId] ON [Track] ([MediaTypeId])
これでDDLがベクトルDBに登録された。
もう一度聞いてみる。
vn.ask(question="このデータベースにはどんなテーブルがありますか?")
SQL Prompt: [{'role': 'system', 'content': "You are a SQLite expert. Please help to generate a SQL query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions. \n===Tables \nCREATE TABLE [MediaType]\n(\n [MediaTypeId] INTEGER NOT NULL,\n [Name] NVARCHAR(120),\n CONSTRAINT [PK_MediaType] PRIMARY KEY ([MediaTypeId])\n)\n\nCREATE TABLE [Playlist]\n(\n [PlaylistId] INTEGER NOT NULL,\n [Name] NVARCHAR(120),\n CONSTRAINT [PK_Playlist] PRIMARY KEY ([PlaylistId])\n)\n\nCREATE TABLE [Artist]\n(\n [ArtistId] INTEGER NOT NULL,\n [Name] NVARCHAR(120),\n CONSTRAINT [PK_Artist] PRIMARY KEY ([ArtistId])\n)\n\nCREATE TABLE [Genre]\n(\n [GenreId] INTEGER NOT NULL,\n [Name] NVARCHAR(120),\n CONSTRAINT [PK_Genre] PRIMARY KEY ([GenreId])\n)\n\nCREATE TABLE [Album]\n(\n [AlbumId] INTEGER NOT NULL,\n [Title] NVARCHAR(160) NOT NULL,\n [ArtistId] INTEGER NOT NULL,\n CONSTRAINT [PK_Album] PRIMARY KEY ([AlbumId]),\n FOREIGN KEY ([ArtistId]) REFERENCES [Artist] ([ArtistId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION\n)\n\nCREATE INDEX [IFK_InvoiceLineInvoiceId] ON [InvoiceLine] ([InvoiceId])\n\nCREATE TABLE [PlaylistTrack]\n(\n [PlaylistId] INTEGER NOT NULL,\n [TrackId] INTEGER NOT NULL,\n CONSTRAINT [PK_PlaylistTrack] PRIMARY KEY ([PlaylistId], [TrackId]),\n FOREIGN KEY ([PlaylistId]) REFERENCES [Playlist] ([PlaylistId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION,\n FOREIGN KEY ([TrackId]) REFERENCES [Track] ([TrackId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION\n)\n\nCREATE INDEX [IFK_TrackMediaTypeId] ON [Track] ([MediaTypeId])\n\nCREATE INDEX [IFK_PlaylistTrackTrackId] ON [PlaylistTrack] ([TrackId])\n\nCREATE INDEX [IFK_TrackAlbumId] ON [Track] ([AlbumId])\n\n===Response Guidelines \n1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question. \n2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql \n3. If the provided context is insufficient, please explain why it can't be generated. \n4. Please use the most relevant table(s). \n5. If the question has been asked and answered before, please repeat the answer exactly as it was given before. \n6. Ensure that the output SQL is SQLite-compliant and executable, and free of syntax errors. \n"}, {'role': 'user', 'content': 'このデータベースにはどんなテーブルがありますか?'}]
Using model gpt-4o-mini for 624.25 tokens (approx)
LLM Response: このデータベースには以下のテーブルがあります:
1. MediaType
2. Playlist
3. Artist
4. Genre
5. Album
6. PlaylistTrack
このデータベースには以下のテーブルがあります:
1. MediaType
2. Playlist
3. Artist
4. Genre
5. Album
6. PlaylistTrack
Couldn't run sql: Execution failed on sql 'このデータベースには以下のテーブルがあります:
1. MediaType
2. Playlist
3. Artist
4. Genre
5. Album
6. PlaylistTrack': near "このデータベースには以下のテーブルがあります:": syntax error
エラーのようなものはえるが、一応各テーブルを取得できるようになった。よく見るとプロンプトの中に先ほど登録したDDLが埋め込まれているのがわかる。プロンプトを日本語にすると以下のようなものになる。
あなたはSQLiteのエキスパートだ。質問に答えるためにSQLクエリを生成するのを手伝ってほしい。あなたの回答は、与えられた文脈にのみ基づき、回答のガイドラインと書式の指示に従うこと。
===テーブル
CREATE TABLE [MediaType]
(
[MediaTypeId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_MediaType] PRIMARY KEY ([MediaTypeId])
)
(snip)
CREATE INDEX [IFK_TrackAlbumId] ON [Track] ([AlbumId])
===出力ガイドライン
1. 提供されたコンテキストが十分であれば、質問に対する説明なしで有効なSQLクエリを生成してください。
2. 提供されたコンテキストがほぼ十分だが、特定の列の特定の文字列に関する知識が必要な場合は、その列の異なる文字列を見つけるための中間SQLクエリを生成してください。クエリの前に intermediate_sql というコメントを付けること。
3. 提供されたコンテキストが不十分な場合は、生成できない理由を説明してください。
4. 最も関連性の高いテーブルを使用してください。
5. 以前に質問され、回答されたことがある場合は、以前と同じように正確に繰り返しください。
6. 出力SQLがSQLiteに準拠し、実行可能で、構文エラーがないことを確認してください。
スキーマ以外に、例えばドキュメントやよく使うSQLなどを学習させることもできる。
vn.train(documentation="このデータベースは、アーティスト、アルバム、メディア・トラック、請求書、顧客のテーブルを含むデジタルメディアストアのデータベースである。11のテーブル、様々なインデックス、主キー制約、外部キー制約、15,000行以上のデータで構成されている。")
Adding documentation....
e82a3be9-40c3-5a31-a508-3d45621ac56f-doc
vn.train(sql="SELECT Title, Name FROM album INNER JOIN artist ON artist.ArtistId = album.ArtistId LIMIT 10")
Using model gpt-4o-mini for 76.75 tokens (approx)
Question generated with sql: What are the titles of albums along with their corresponding artist names?
Adding SQL...
7a1a86dd-b00c-5933-978c-11ad0a7c9b7f-sql
では色々聞いてみる。
vn.ask(question="このデータベースはどういう内容ですか?")
このデータベースは、アーティスト、アルバム、メディア・トラック、請求書、顧客のテーブルを含むデジタルメディアストアのデータベースであり、11のテーブル、様々なインデックス、主キー制約、外部キー制約、15,000行以上のデータで構成されています。
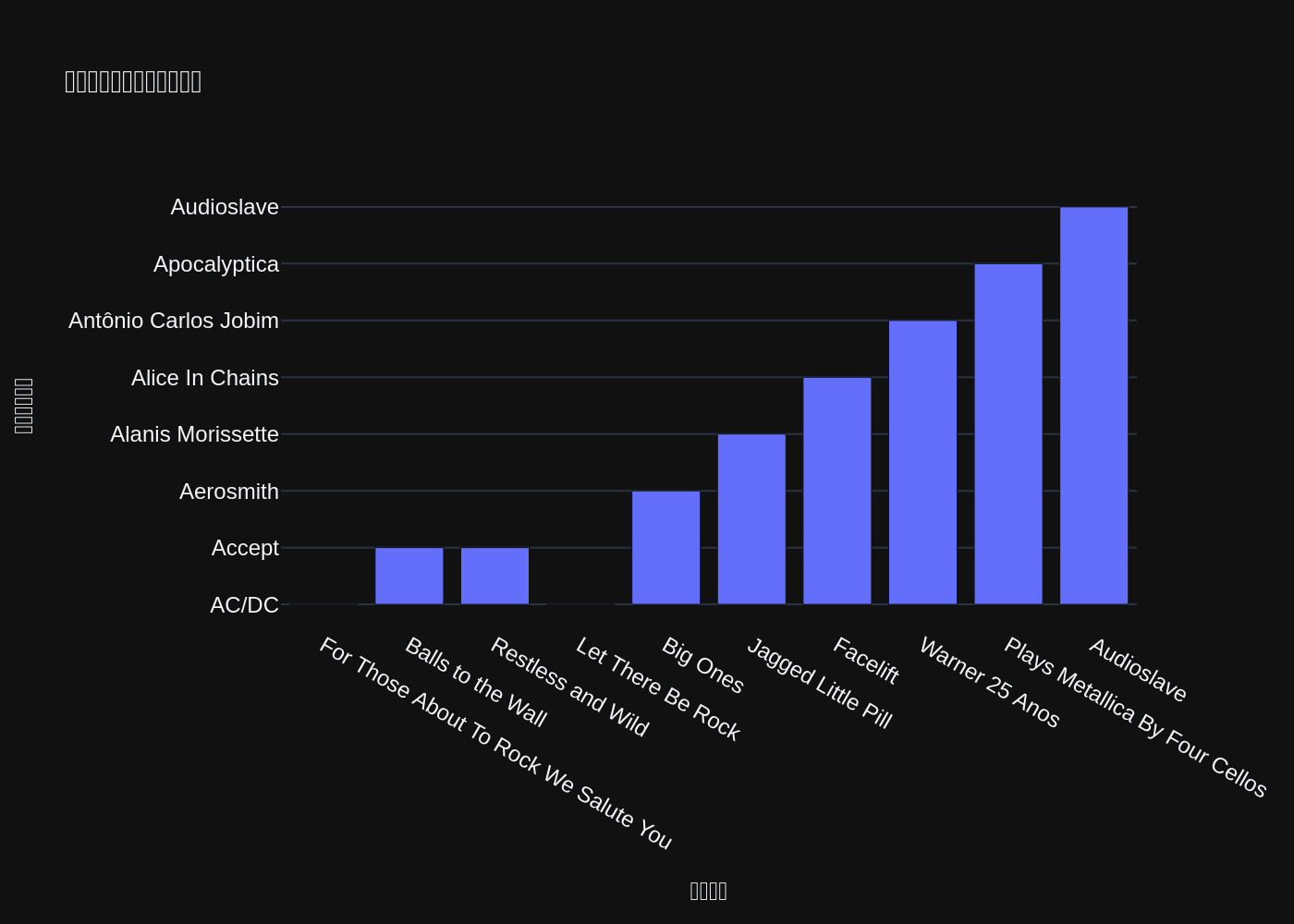
vn.ask(question="アルバムとアーティスト名を10件抽出してください")
('SELECT Album.Title, Artist.Name \nFROM Album \nINNER JOIN Artist ON Artist.ArtistId = Album.ArtistId \nLIMIT 10;', Title Name
0 For Those About To Rock We Salute You AC/DC
1 Balls to the Wall Accept
2 Restless and Wild Accept
3 Let There Be Rock AC/DC
4 Big Ones Aerosmith
5 Jagged Little Pill Alanis Morissette
6 Facelift Alice In Chains
7 Warner 25 Anos Antônio Carlos Jobim
8 Plays Metallica By Four Cellos Apocalyptica
9 Audioslave Audioslave, Figure({
'data': [{'alignmentgroup': 'True',
'hovertemplate': 'アルバム=%{x}<br>アーティスト=%{y}<extra></extra>',
'legendgroup': '',
'marker': {'color': '#636efa', 'pattern': {'shape': ''}},
'name': '',
'offsetgroup': '',
'orientation': 'v',
'showlegend': False,
'textposition': 'auto',
'type': 'bar',
'x': array(['For Those About To Rock We Salute You', 'Balls to the Wall',
'Restless and Wild', 'Let There Be Rock', 'Big Ones',
'Jagged Little Pill', 'Facelift', 'Warner 25 Anos',
'Plays Metallica By Four Cellos', 'Audioslave'], dtype=object),
'xaxis': 'x',
'y': array(['AC/DC', 'Accept', 'Accept', 'AC/DC', 'Aerosmith', 'Alanis Morissette',
'Alice In Chains', 'Antônio Carlos Jobim', 'Apocalyptica', 'Audioslave'],
dtype=object),
'yaxis': 'y'}],
'layout': {'barmode': 'relative',
'legend': {'tracegroupgap': 0},
'template': '...',
'title': {'text': 'アルバムとアーティスト名'},
'xaxis': {'anchor': 'y', 'domain': [0.0, 1.0], 'title': {'text': 'アルバム'}},
'yaxis': {'anchor': 'x', 'domain': [0.0, 1.0], 'title': {'text': 'アーティスト'}}}
}))
こんな感じで回答が返ってくる。なお、SQLが実行された場合、どうやらビジュアルも生成される様子(ただし、このグラフである必要性がまったくないのだけども)
上の例だとDBのテーブルに含まれているデータにアクセスできているが、例えばこんな感じの質問を投げてみると・・・
vn.ask(question="顧客テーブルの顧客名をリストアップして")
Couldn't run sql: Execution failed on sql 'The LLM is not allowed to see the data in your database. Your question requires database introspection to generate the necessary SQL. Please set allow_llm_to_see_data=True to enable this.': near "The": syntax error
こんな感じで拒否される場合がある。この場合はメッセージにある通り、allow_llm_to_see_data=Trueパラメータを付与すればいいようなのだが、
vn.ask(question="Customerテーブルから名前をリストアップして")
とすると上記のパラメータなしでも普通に検索して回答が返ってきたりする。このあたりはちょっと謎。
なお、この時のシステムプロンプトは以下。プロンプトに含まれているテーブル情報が最初とは異なっている。なるほど、Dynamic Few-shot promptingはここで使用されているのだと思われる。
You are a SQLite expert. Please help to generate a SQL query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
CREATE INDEX [IFK_InvoiceLineInvoiceId] ON [InvoiceLine] ([InvoiceId])
CREATE INDEX [IFK_InvoiceLineTrackId] ON [InvoiceLine] ([TrackId])
CREATE TABLE [InvoiceLine]
(
[InvoiceLineId] INTEGER NOT NULL,
[InvoiceId] INTEGER NOT NULL,
[TrackId] INTEGER NOT NULL,
[UnitPrice] NUMERIC(10,2) NOT NULL,
[Quantity] INTEGER NOT NULL,
CONSTRAINT [PK_InvoiceLine] PRIMARY KEY ([InvoiceLineId]),
FOREIGN KEY ([InvoiceId]) REFERENCES [Invoice] ([InvoiceId])
\t\tON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([TrackId]) REFERENCES [Track] ([TrackId])
\t\tON DELETE NO ACTION ON UPDATE NO ACTION
)
(snip)
===Additional Context
このデータベースは、アーティスト、アルバム、メディア・トラック、請求書、顧客のテーブルを含むデジタルメディアストアのデータベースである。11のテーブル、様々なインデックス、主キー制約、外部キー制約、15,000行以上のデータで構成されている。
===Response Guidelines
1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question.
2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql
3. If the provided context is insufficient, please explain why it can't be generated.
4. Please use the most relevant table(s).
5. If the question has been asked and answered before, please repeat the answer exactly as it was given before.
6. Ensure that the output SQL is SQLite-compliant and executable, and free of syntax errors.
自分は試していないが、WebのGUIインタフェースがビルトインされている様子。
画像を見る限りはデータの学習みたいなこともできるように思える。またこれ以外にも、
- Streamlit
- Chainlit
- Flask/API
- Slack
でのフロントエンドのサンプルが用意されている。
あと公式レポジトリ以外にサンプルのノートブックを集めたレポジトリが別に用意されている。
Getting Startedで選択できる構成は全部用意されているようなので参考になるのではないかと思う。
まとめ
ちょっと動きをきちんと把握できていないところもあるけど、自分的にはDynamic Few-shot promptingの実例としての確認はできたので、一応試した目的は果たせたかな。精度的なところはあまりいいとは感じなかったけど、
- all-MiniLM-L6-v2だと日本語が多分ダメなのでは?
- あまり根拠がないけど、この手のタスクは性能の高いモデルでやるほうがいいような気がする
ので参考まで。プロンプトも日本語に寄せてないし。
あと実際に試してはいないが、Web GUIの動画の印象や、あと、ドキュメントにある図からも、フィードバックループのようなものをやろうとしているのは読み取れる。個人的な考えだが、精度の高いRAGを作ることも重要だが、結果を踏まえて精度を上げていくための仕組みを作ることのほうがRAGには重要だと思う。
その点で、この仕組みをフレームワークとして最初から用意しているという点はVannaのメリットなのだと思う。