「n8n」を試す
以前少しだけ触ったことがある。ほんの触りだけだけど。改めて。
公式サイト
GitHubレポジトリ
n8n - テクニカルチーム向けセキュアなワークフロー自動化
n8n は、技術チームにコードの柔軟性とノーコードのスピードを提供するワークフロー自動化プラットフォームです。400以上の統合、ネイティブAI機能、公平なライセンスにより、データとデプロイメントを完全にコントロールしながら強力な自動化を構築できます。
referred from https://github.com/n8n-io/n8n主な機能
リソース
- 📚 ドキュメント
- 🔧 400+ 統合
- 💡 サンプルワークフロー
- 🤖 AI & LangChain ガイド
- 👥 コミュニティフォーラム
- 📖 コミュニティチュートリアル
ライセンス
n8n はフェアコードで配布されており、Sustainable Use Licenseおよびn8n Enterprise Licenseの下で提供されています。
- ソース公開:常にソースコードを閲覧可能
- セルフホスト可能:どこにでもデプロイ可能
- 拡張性:独自のノードや機能を追加可能
追加機能やサポートをご希望の場合はEnterprise ライセンスをご利用ください。
ライセンスモデルの詳細はドキュメントをご参照ください。
n8n の意味は?
短い回答: “nodemation” の略で、「エヌエイトエヌ」と発音します。
詳細:
“プロジェクト名として良いドメインが取れず、node-(Node-View と Node.js の意)と -mation(automation の意)を組み合わせ nodemation としました。しかし長すぎるため CLI で打つのが大変で、“n8n” に落ち着きました。”
― Jan Oberhauser, n8n.io 創設者兼CEO
とりあえずライセンスについてはこちら
商用サービスとして「提供」はできないけど、社内業務などの内部利用については可能みたいな、感じの限定的な商用利用、という感じ。
このスレッド全体がとても興味深く、特に n8n へのアプローチと試行を丁寧に記録している点が印象的でした。
その内容に刺激を受けて、社内チームでの採用を検討する中で、ワークフロー内および Vault の KV ストア操作の両方で安全に認証情報を管理できるように HashiCorp Vault を統合しました。
n8n 用の Vault ノードを強化したバージョンを作成し、AppRole / Token 認証、KV v1/v2、柔軟な SSL 設定などを追加しています。
オープンソースで公開しています:
🔗 https://github.com/luisra51/n8n-nodes-hashi-vault
インストール
インストールに関しては公式ドキュメントの以下にある。
- n8nクラウド(有償・無料トライアルもあるみたい)
- セルフホスト
- npmパッケージ
- Docker
- VPSでDocker、クラウドでKubernetes
- Embed: n8nをプロダクトに組み込める(有償)
という感じ。セルフホストの場合も、無料版と有料版があって、無料の場合は「コミュニティエディション」という扱いになるみたい。
とりあえず今回はUbuntu-22.04サーバにDockerでインストールすることにする。Dockerのインストール手順は以下。
事前に必要な要件として、Dockerがインストールされているのはまあ当然として、データベースが必要になる。デフォルトだとSQLiteだが、PostgreSQLも使えるということで自分はPostgreSQLを使うことにする。
dockerコマンドのサンプルは載ってるけども、docker-compose.ymlの雛形欲しいなと思って探してみたら、こっちのドキュメントにあった。
こっちはちょっと本気だな。ローカルでお試しするにはちょっと大げさかも。ということで自分はこんな感じにした。
mkdir n8n-work && cd n8n-work
N8N_HOST=[サーバのIP]
N8N_PORT=5678
N8N_PROTOCOL=http
WEBHOOK_URL=http://[サーバのIP]:5678/
GENERIC_TIMEZONE=Asia/Tokyo
TZ=Asia/Tokyo
DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=postgres
DB_POSTGRESDB_PORT=5432
DB_POSTGRESDB_DATABASE=n8n
DB_POSTGRESDB_USER=n8n
DB_POSTGRESDB_PASSWORD=n8n_password
NODE_ENV=production
N8N_ENCRYPTION_KEY=[任意の暗号化キー]
services:
postgres:
image: postgres:16
container_name: n8n-postgres
restart: always
env_file: .env
environment:
- POSTGRES_DB=${DB_POSTGRESDB_DATABASE}
- POSTGRES_USER=${DB_POSTGRESDB_USER}
- POSTGRES_PASSWORD=${DB_POSTGRESDB_PASSWORD}
- POSTGRES_INITDB_ARGS=--encoding=UTF-8 --no-locale
volumes:
- pg_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${DB_POSTGRESDB_USER}"]
interval: 10s
timeout: 5s
retries: 5
n8n:
image: docker.n8n.io/n8nio/n8n:latest
container_name: n8n
restart: always
depends_on:
postgres:
condition: service_healthy
ports:
- "5678:5678"
env_file: .env
environment:
- N8N_HOST=${N8N_HOST}
- N8N_PORT=${N8N_PORT}
- N8N_PROTOCOL=${N8N_PROTOCOL}
- GENERIC_TIMEZONE=${GENERIC_TIMEZONE}
- TZ=${TZ}
- DB_TYPE=${DB_TYPE}
- DB_POSTGRESDB_HOST=${DB_POSTGRESDB_HOST}
- DB_POSTGRESDB_PORT=${DB_POSTGRESDB_PORT}
- DB_POSTGRESDB_DATABASE=${DB_POSTGRESDB_DATABASE}
- DB_POSTGRESDB_USER=${DB_POSTGRESDB_USER}
- DB_POSTGRESDB_PASSWORD=${DB_POSTGRESDB_PASSWORD}
- WEBHOOK_URL=${WEBHOOK_URL}
- NODE_ENV=${NODE_ENV}
- N8N_ENCRYPTION_KEY=${N8N_ENCRYPTION_KEY}
volumes:
- n8n_data:/home/node/.n8n
- ./local-files:/files
volumes:
pg_data:
n8n_data:
起動
docker compose up
以下のように表示されればOK
n8n | Editor is now accessible via:
n8n | http://XXX.XXX.XXX.XXX:5678
ブラウザでアクセスしてみると・・・・

なるほど・・・。ちょっとTLSセットアップするのは面倒だし、自分の場合はLAN内のリモートサーバなのでlocalhostも使えない。ということで、N8N_SECURE_COOKIEを環境変数に追加する。
(snip)
n8n:
(snip)
environment:
(snip)
- N8N_SECURE_COOKIE=false
(snip)
再度docker compose upしてブラウザアクセス、今度は問題なし。ということで管理者アカウントを作成する。
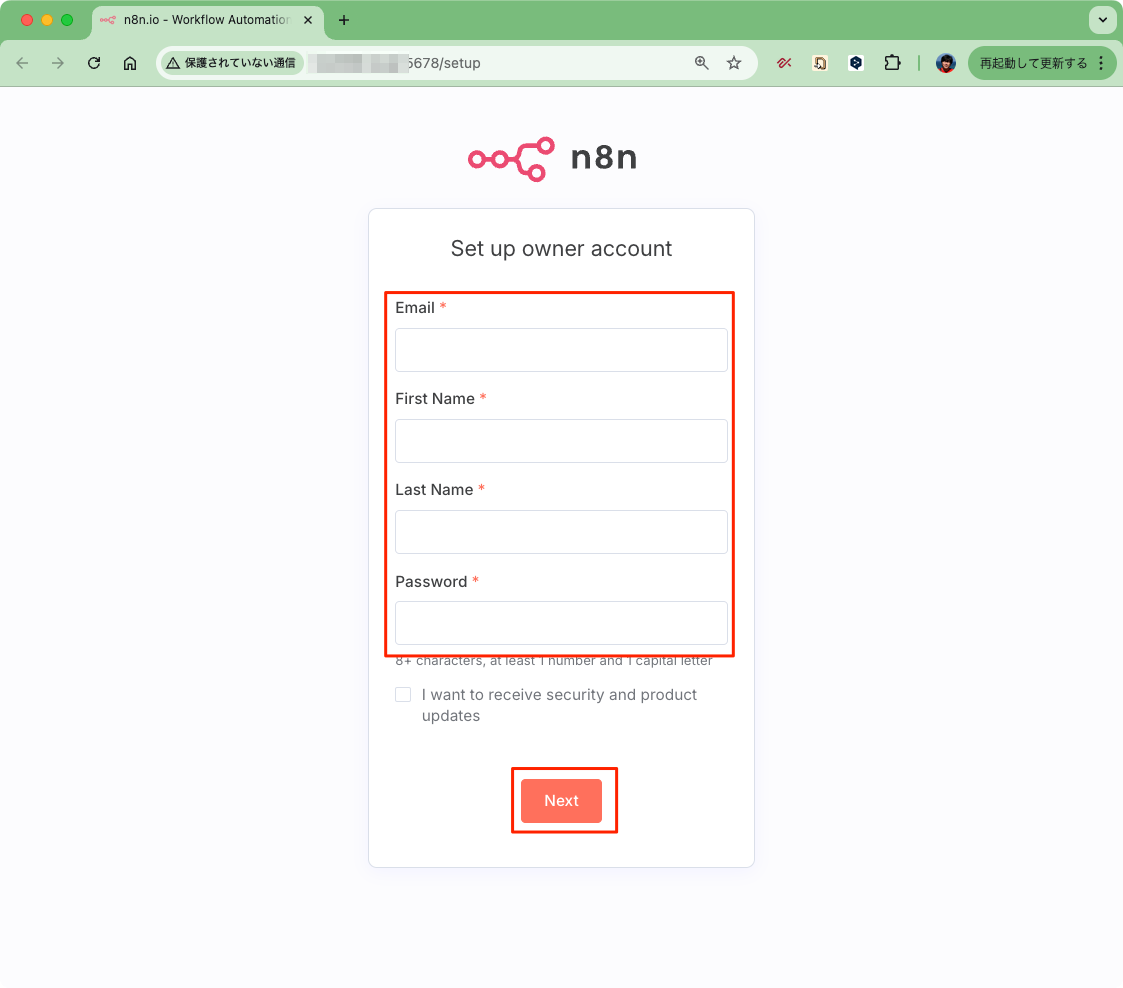
アンケートのようなものが表示されるので、適当に入力。"These questions help us tailor n8n to you" とあるけど、これは何かしら設定なり構成形に影響するんだろうか・・・?
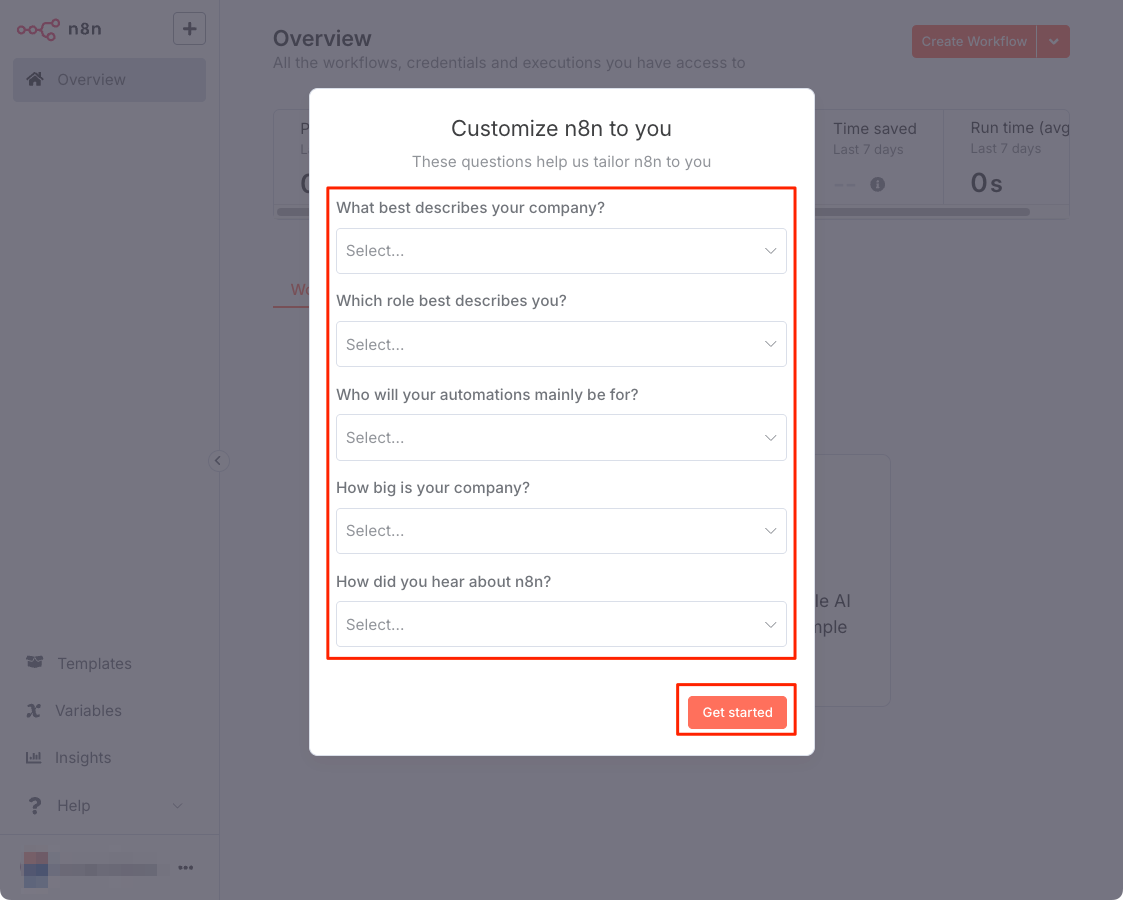
有料機能なども使える無料ライセンスのキーを取得するか聞かれる。特に問題はなさそうなので取得することにした。
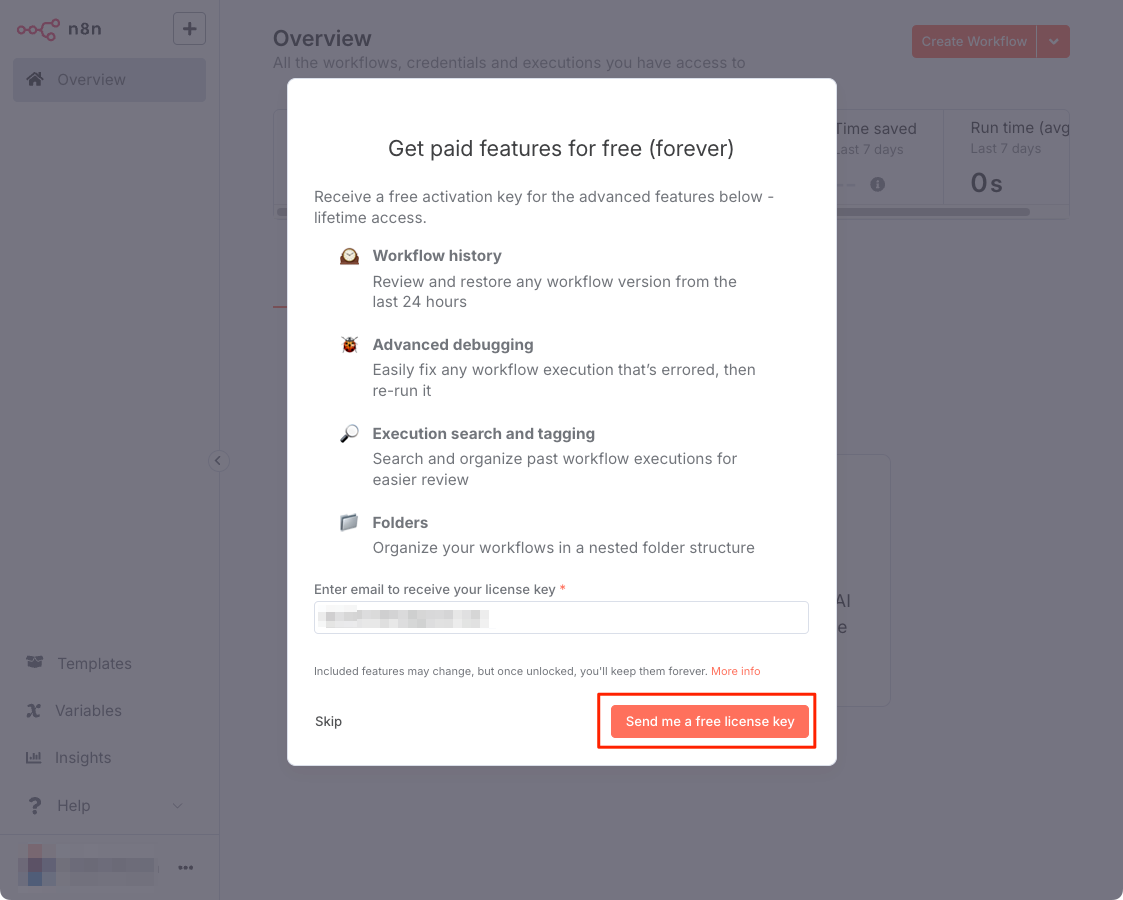
トップ画面が表示された。メールでライセンスキーが送付されているので、これをアクティベートする。

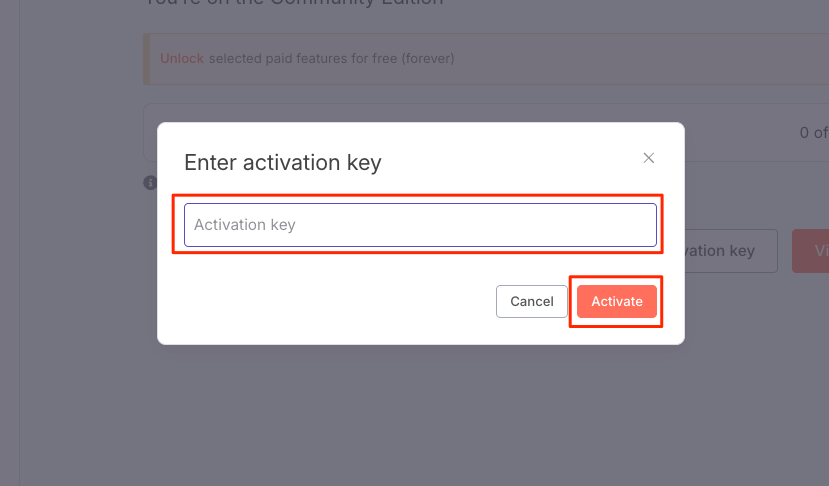
アクティベートできたみたい。
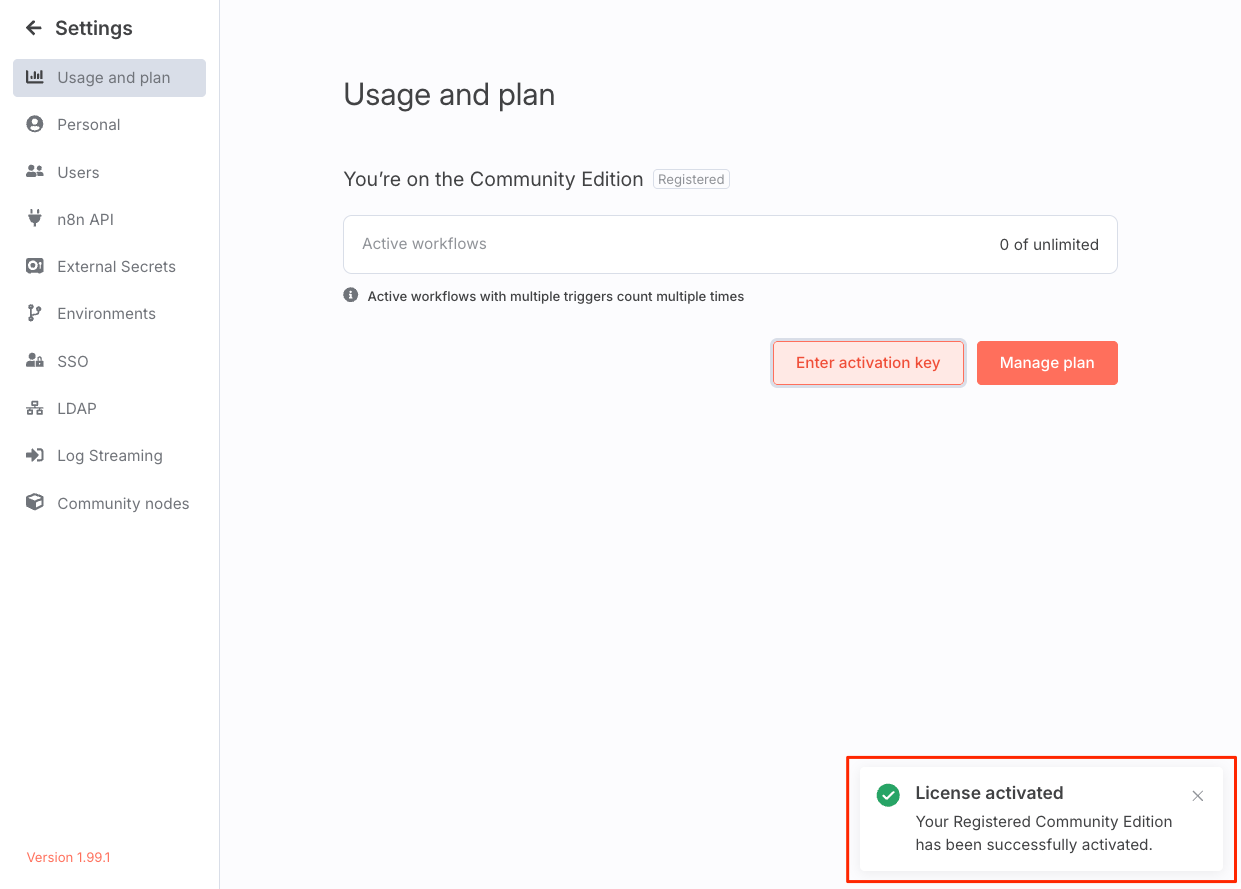
では以降で実際に触っていく。
n8nの公式ドキュメントには "Learning path" が用意されている
Quickstartガイドは3つ用意されている。
-
A very quick quickstart
https://docs.n8n.io/try-it-out/quickstart/ -
A longer introduction
https://docs.n8n.io/try-it-out/tutorial-first-workflow/ -
Build an AI workflow in n8n
https://docs.n8n.io/advanced-ai/intro-tutorial/
また、動画とテキストで学ぶことのできるコースも用意されていて、それぞれビギナー・アドバンスドが用意されていて、最初のステップをとても丁寧に準備されているのだなと感じた。
とりあえずQuickstartをざっと進めてみる。
Quickstart1: The very quick quickstart
ここでは以下の2つの機能について注目する。
- workflow templates: 事前構築済みテンプレートを使ってフローをインポート
- expressions: JavaScriptの式を使って、動的に値を定義する
なお、n8nクラウドが前提のように見えるが、セルフホストでもいけそう。
まず、テンプレートのURLをクリック。ここ。

テンプレートページが開いたら "Use for free" をクリック。
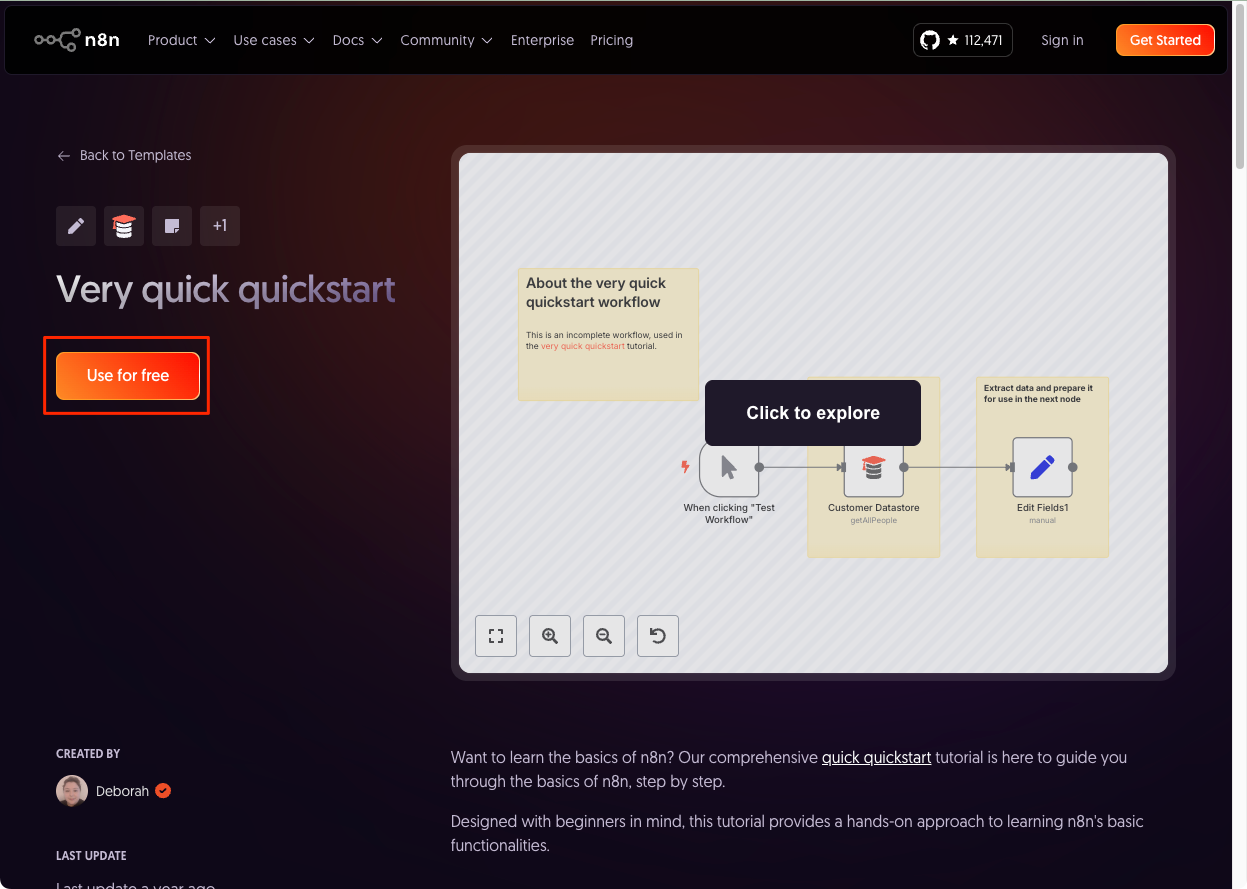
"Copy template to clipboard (JSON)" をクリック。
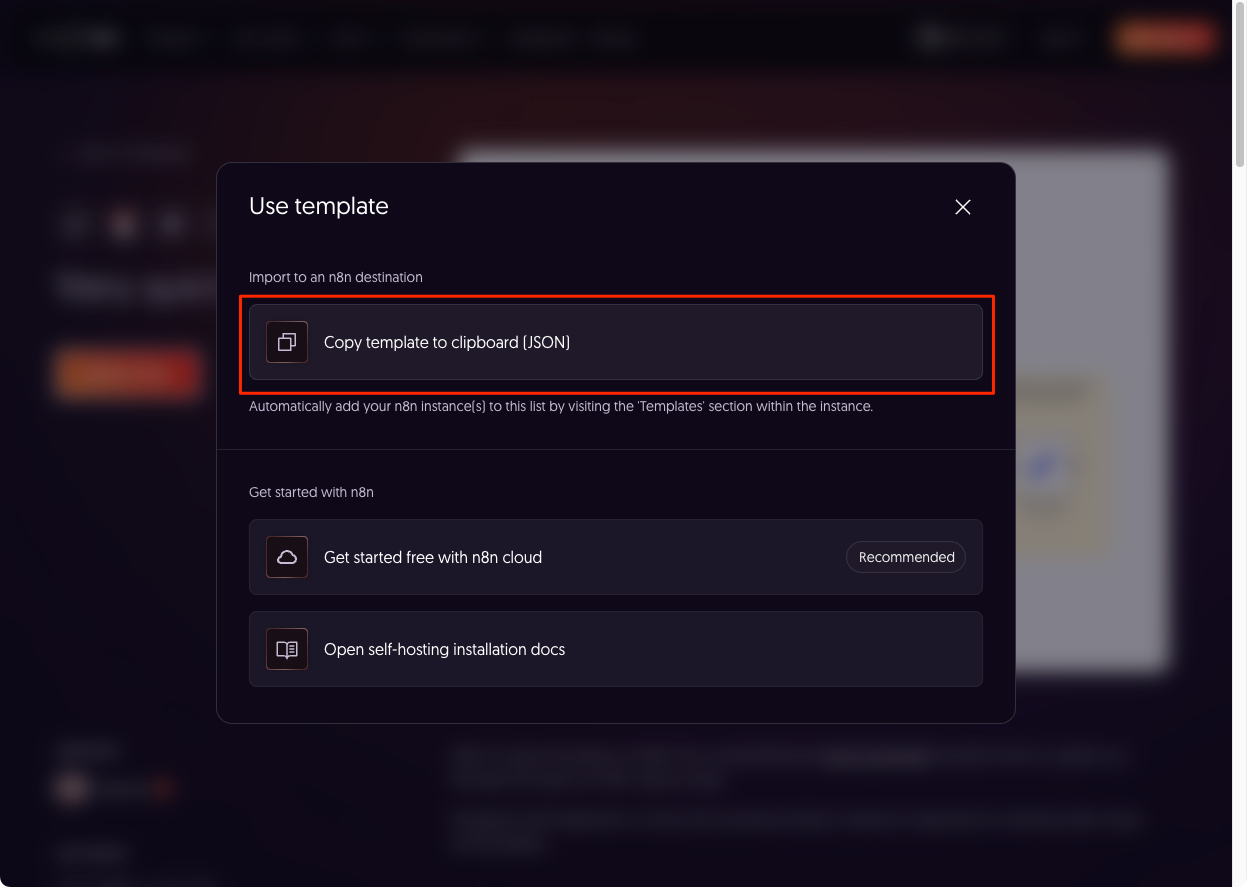
セルフホストしているn8nにログインして、右上の"Create Workflow"をクリック。
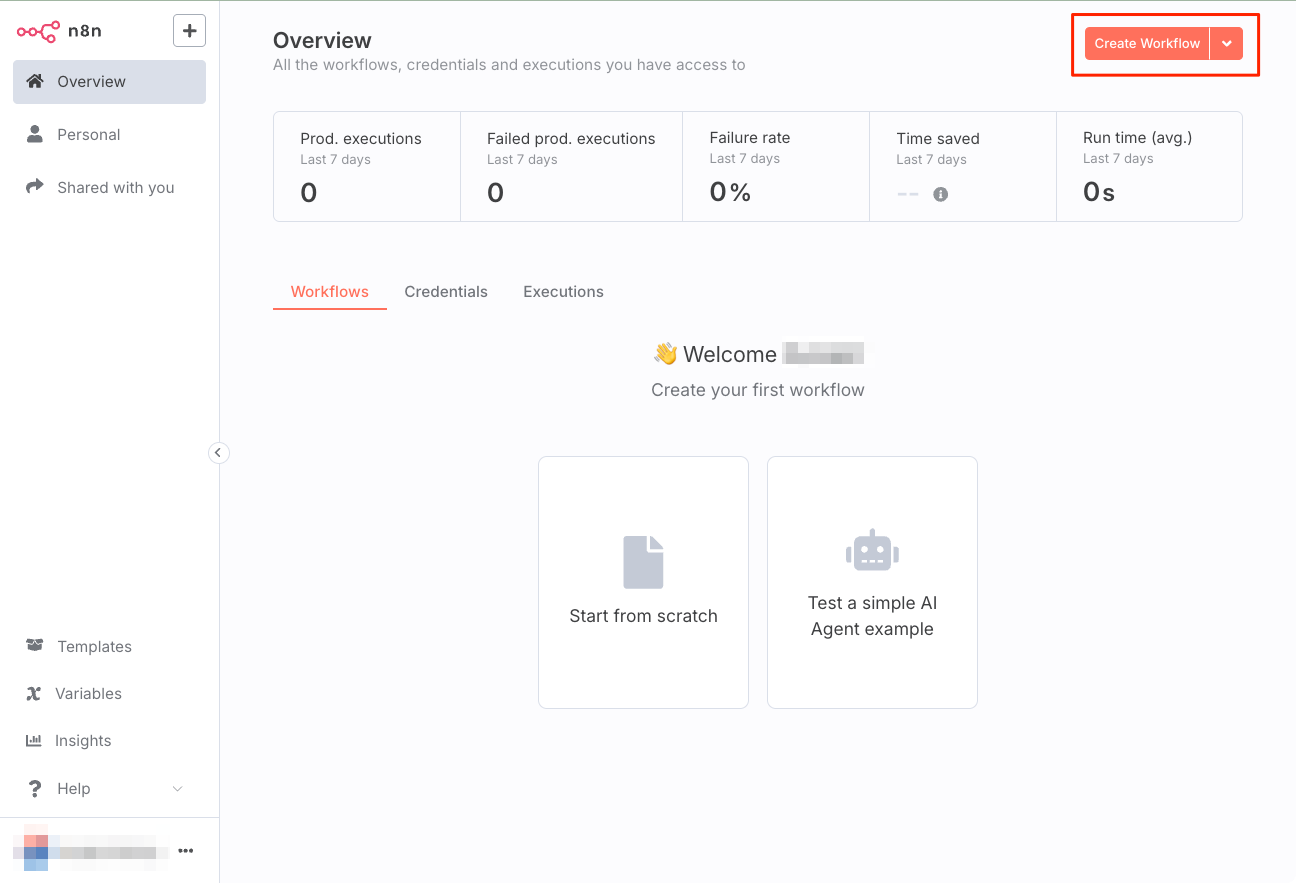
新規ワークフローが作成され、キャンバスが表示される。ここでペースト。

テンプレートのワークフローがペーストされる。左下の"Zoom to Fit"をクリックすると・・・

画面に収まるようにフローが自動で縮小される。
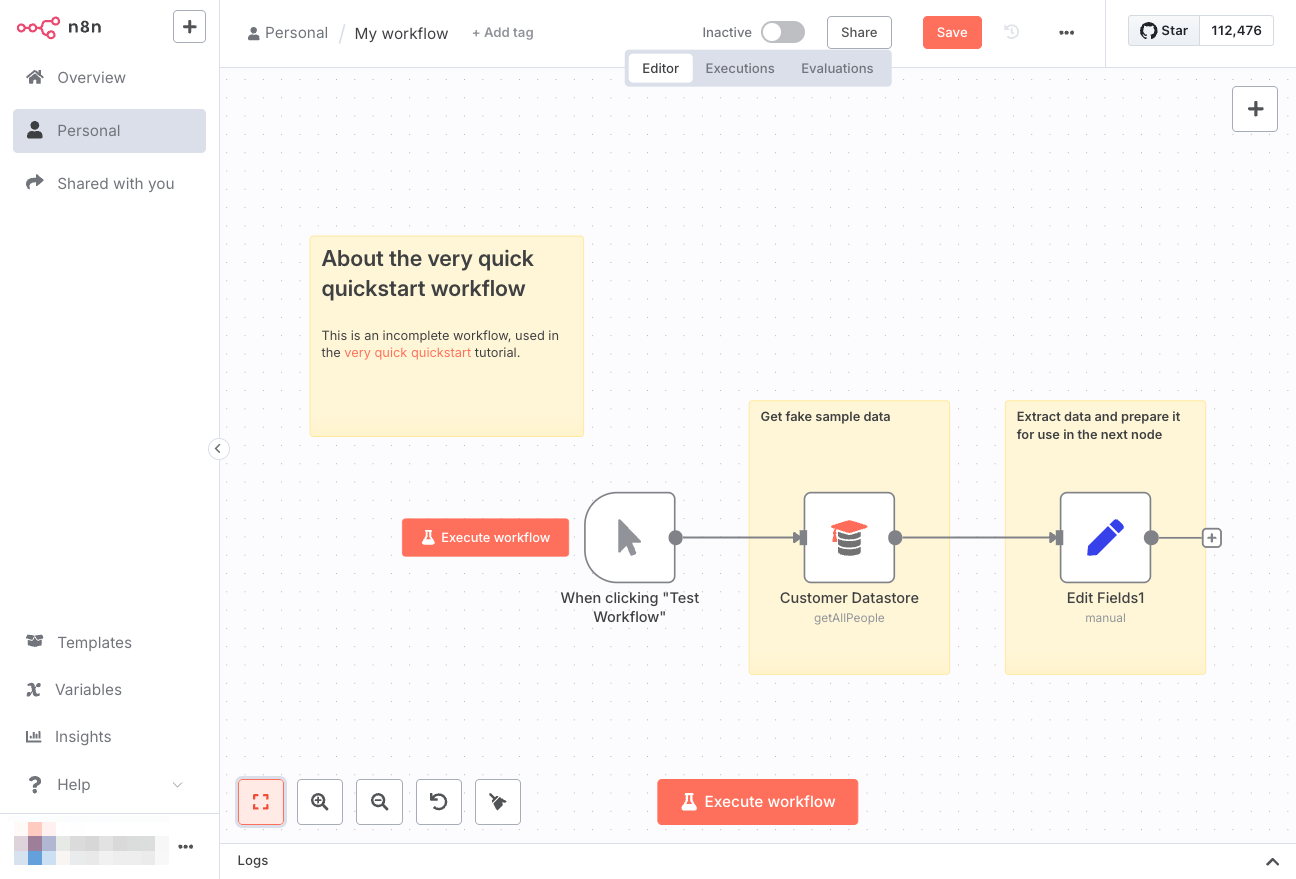
このワークフローの処理は以下のようなものとなっている。
- "Customer Datastore"(顧客データストア) から データを取得
- "Edit Fields"で1のデータから必要なデータ(顧客名・ID・説明)を抽出し、変数に割り当てる。
n8nではこの各ブロックを「ノード」と呼ぶ。ノードをダブルクリックすると、ノードの設定などが表示される。たとえば、"Customer Datastore" の場合だとこんな感じ。

ではワークフローを実行する。"Test Workflow"をクリックする、とあるが見当たらないので、おそらく"Execute workflow"だろう。これをクリック。
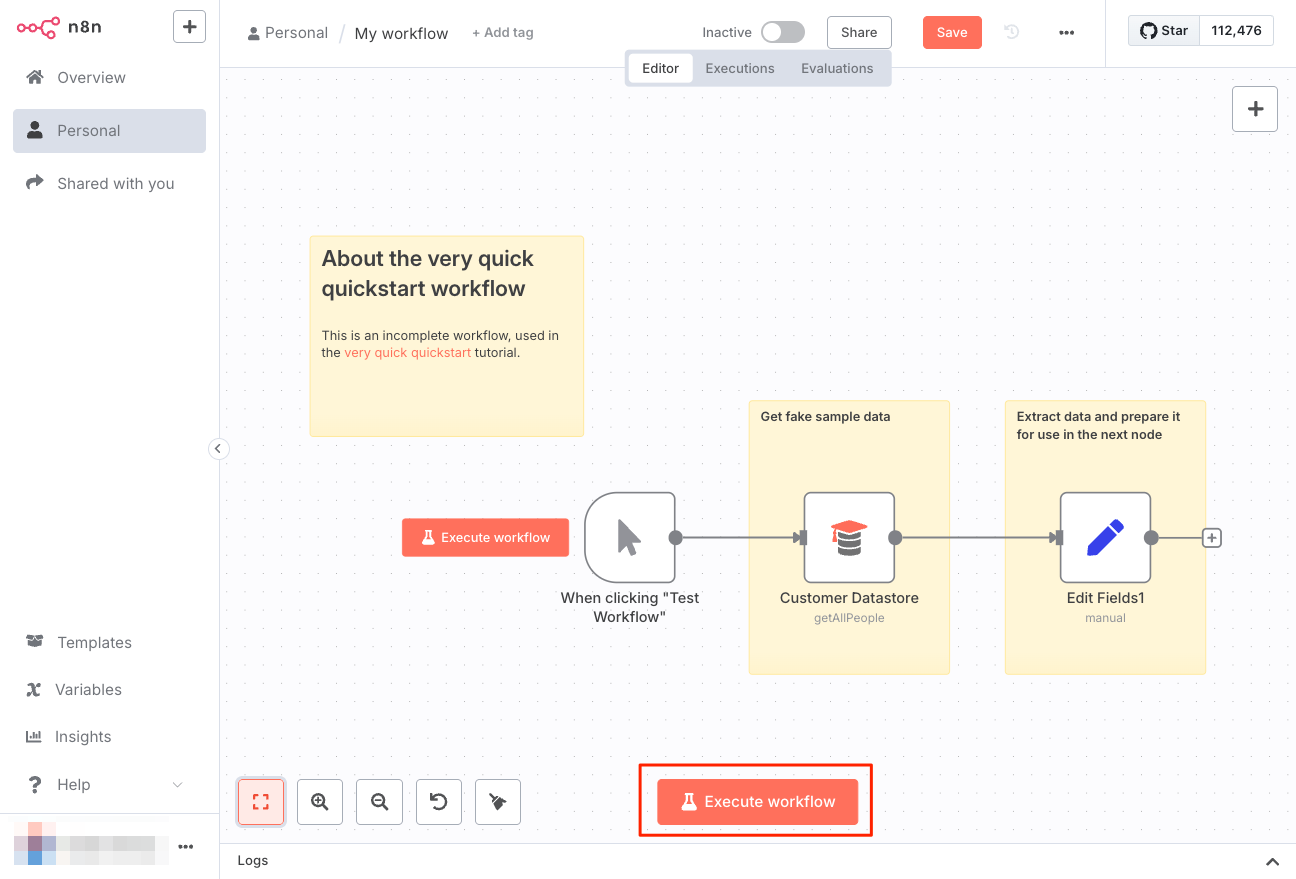
成功した。各ノードにチェックマークが入っていて、処理されたアイテム数なんかも見える。

"Edit Fields"ノードを見てみると、処理されたデータも見える。

次にノードを追加する。"Edit Fields"ノードの右にある"+"アイコンをクリック。
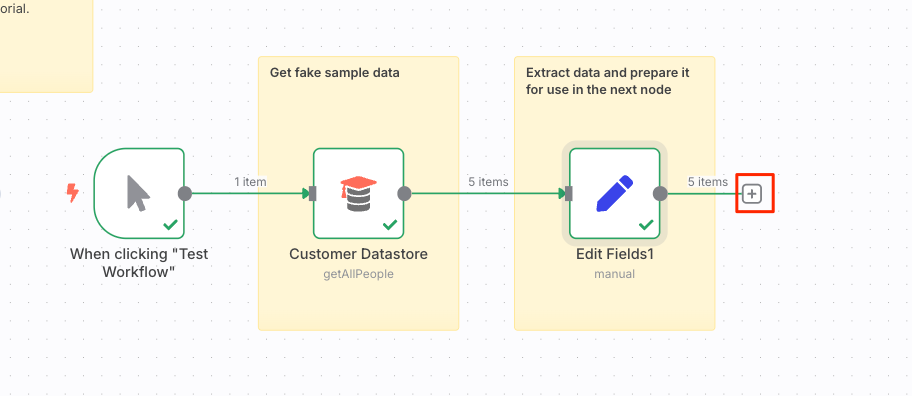
ノード検索パネルが表示されるので、"Customer Messenger"というノードを検索して選択。

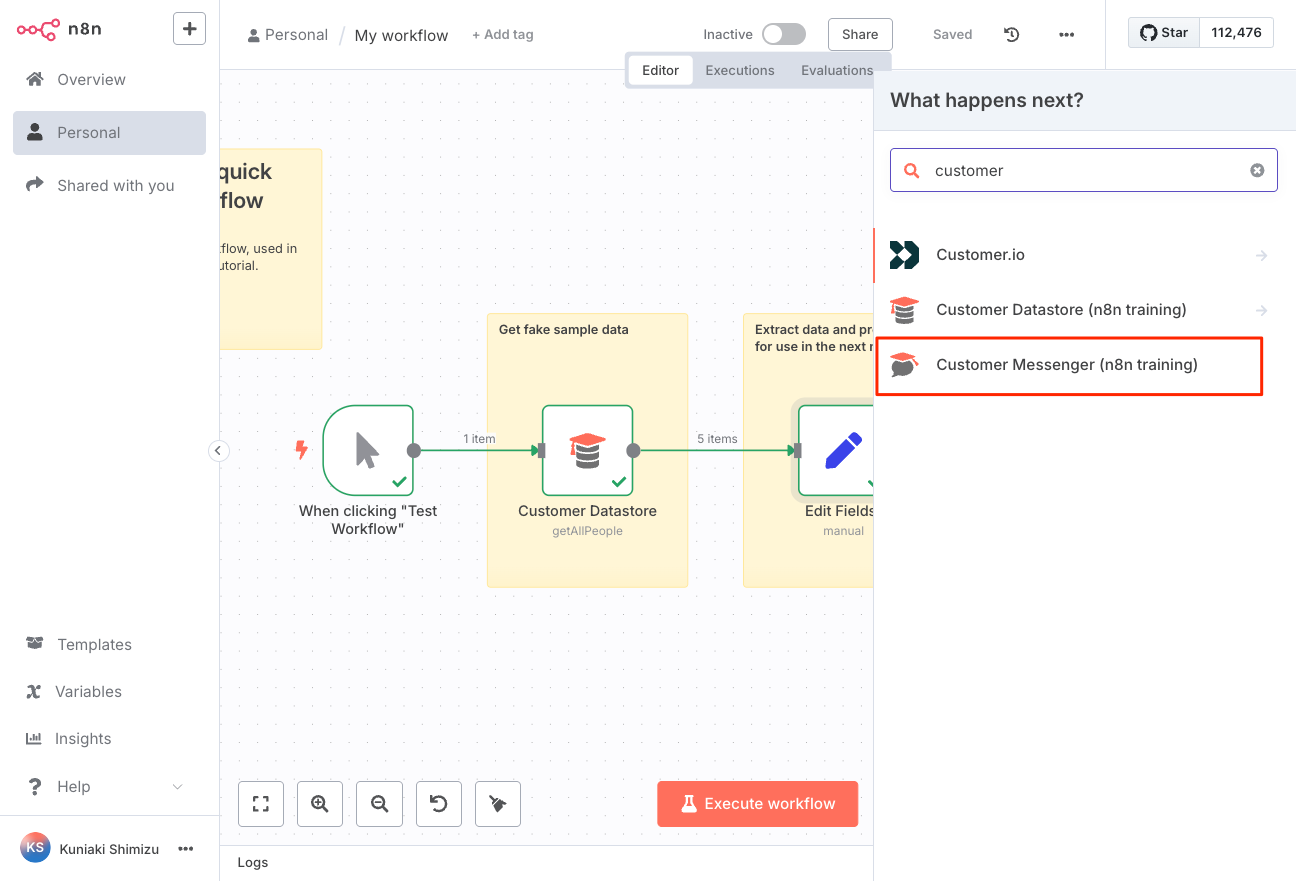
"Customer Messenger"のノード設定画面が表示される。

左の"INPUT"パネルで"Schema"タブが選択されているのを確認して、"Edit Fields1"の"customer_id"を真ん中の"Customer ID"にドラッグ。
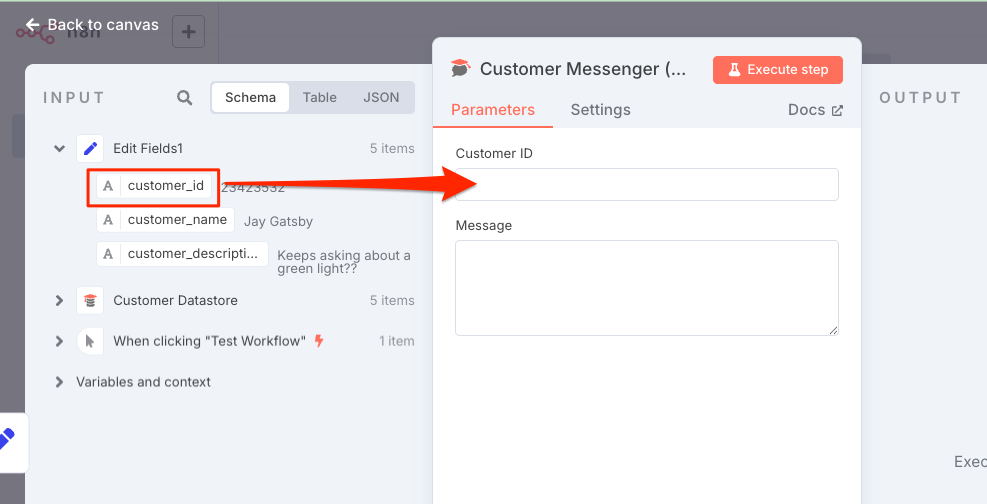
自動的に表示が変わる。
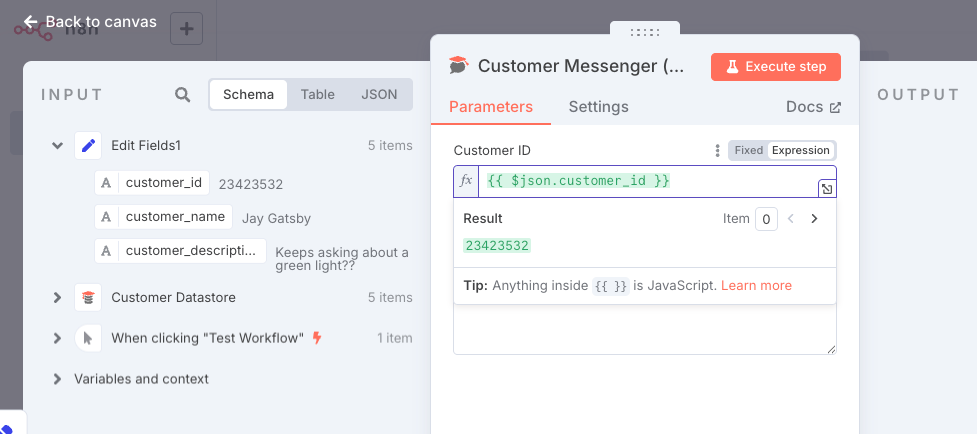
次に真ん中下の "Message" にカーソルを合わせると、右上に "Expression" タブが表示されるのでこれを選択。

入力欄が表示されるので、最大化。
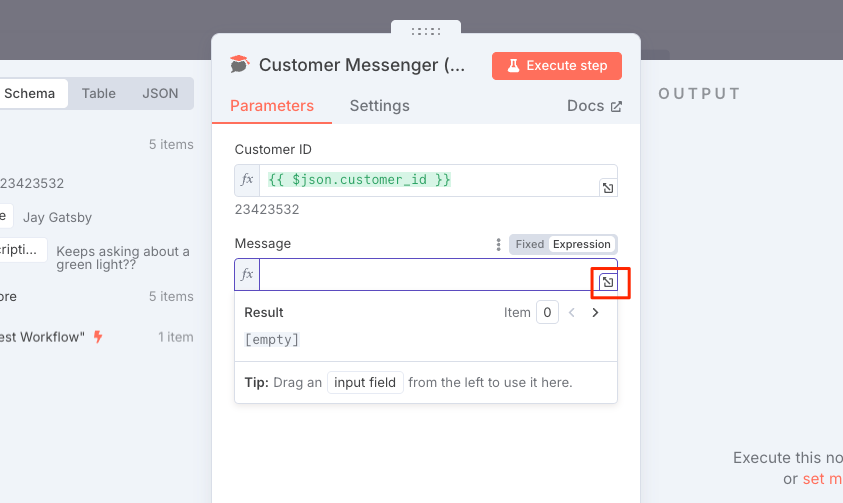
Expression専用のエディタが開くので、上の"Expression"に以下を入力
Hi {{ $json.customer_name }}. Your description is: {{ $json.customer_description }}
テンプレート変数的なところは自動で認識されているのがわかる。

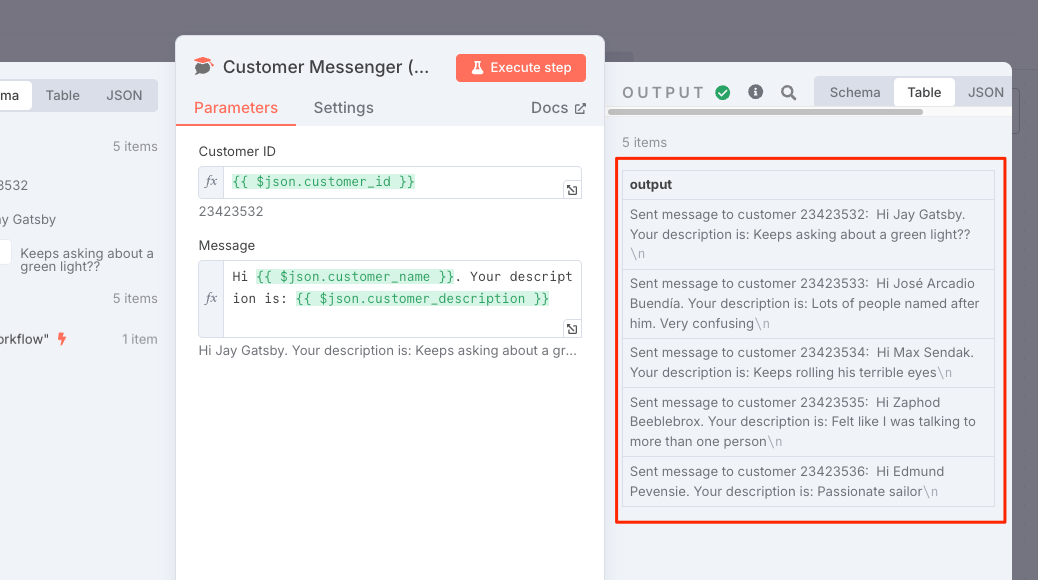
エディタを閉じて、ノードの設定も閉じて、フローまで戻ってきたら、先ほど設定したノードが最後につながっているのがわかる。では、再度フローを実行。

"Customer Messenger"ノードをダブルクリックして開いてみると、OUTPUTにメッセージがそれぞれ出力されているのがわかる。
Quickstarts 2: A longer introduction (Your first workflow)
このQuickstartではスクラッチからフローを作る。ポイントは以下。
- トリガーノードでワークフローを開始する
- クレデンシャルを設定
- データの処理
- ロジックの処理
- expressionsを使う
ワークフローを新規作成

トリガーノードの作成
n8nでワークフローの開始(実行)方法は2つ
- 手動で"Execute workflow" をクリックする
- トリガーノードをワークフローの最初に配置すると、外部イベントや設定などで、ワークフローが実行される
今回はスケジュールに従って実行される「Schedule Trigger」を使う。
"Add first step"をクリック
"Schedule Trigger"を検索して選択。

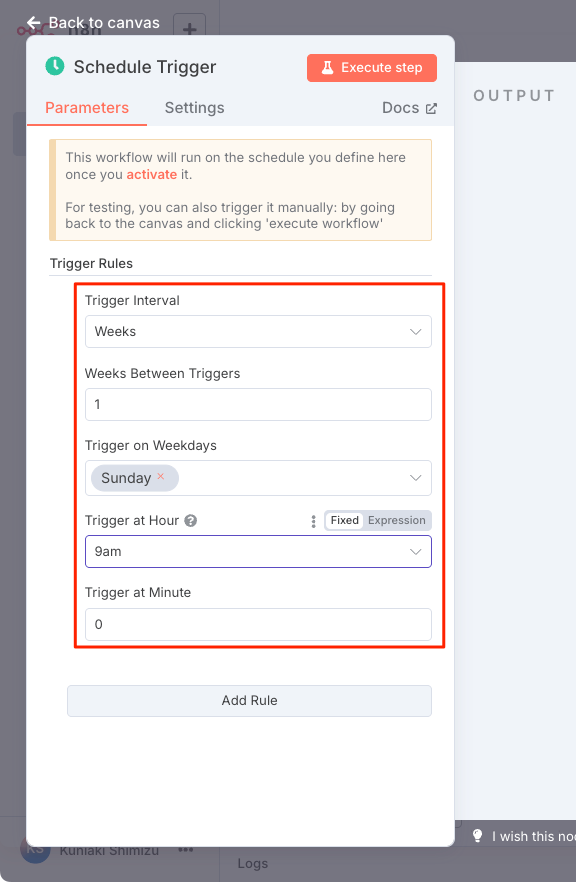
"Schedule Trigger"の設定画面が開くので適当に設定。例えばこんな感じ。
| 設定項目 | 設定内容 |
|---|---|
| Trigger Interval | 実行間隔。今回は週次 に設定。 |
| Weeks Between Triggers | 実行間の週数。例えば隔週なら2に設定する。今回は毎週ということで 1に設定。 |
| Trigger on Weekdays | 実行曜日。日曜日に設定。 |
| Trigger at Hour/Minute | 実行時刻。午前9時0分に設定。 |
クレデンシャルが必要なノードの追加
フローに戻って、"+"をクリックして、更にノード追加。
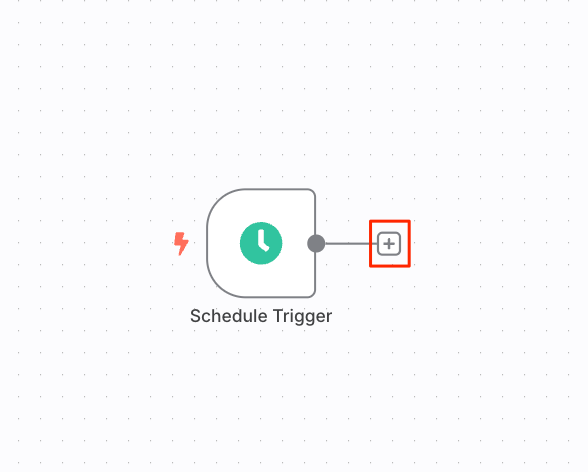
NASAのAPIを使って情報を取得する「NASAノード」を選択
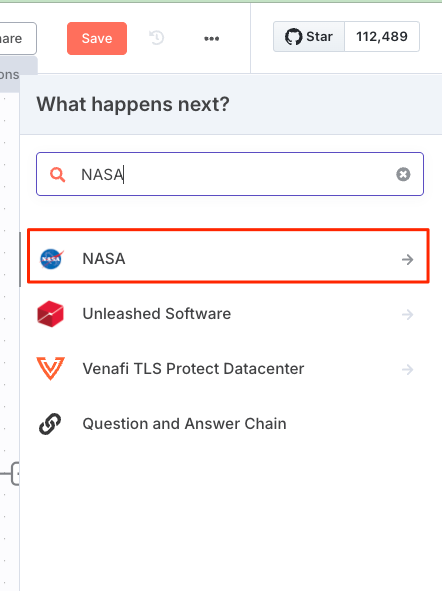
ノードの中には複数のAPIに対応しているものがあるみたい。今回は"Get a DONKI solar flare"(太陽フレアのデータ)を選択。

ノードの設定画面が開く。NASAノードはNASAのAPIにアクセスするがこの際にクレデンシャルが必要になる。"Credential to connect with" をクリックすると、まだクレデンシャルが作成されていないため、"+Create new credential" が表示される。これをクリック。
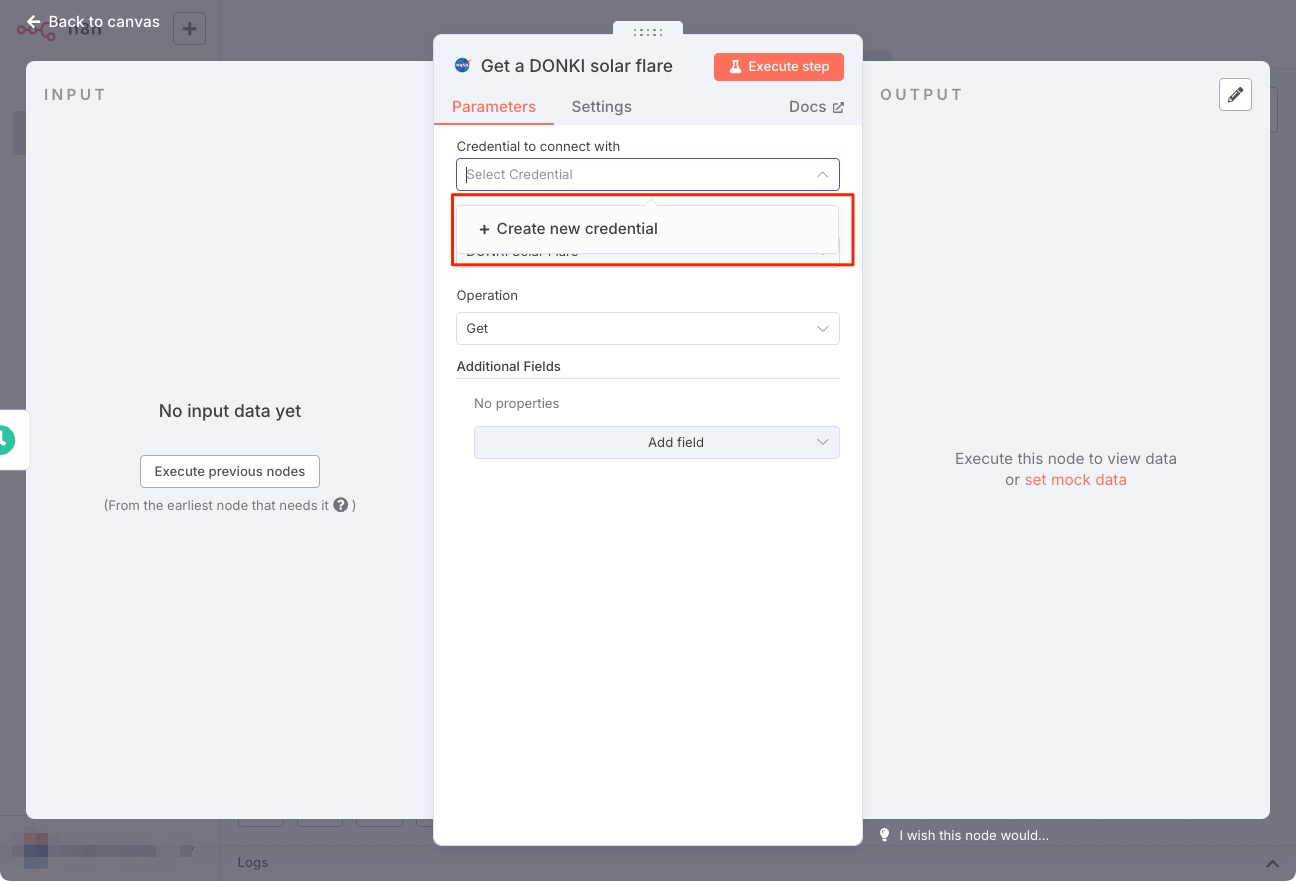
クレデンシャルの登録画面になるが、これはあくまでもn8n上の登録。実際には、NASAのウェブサイトでAPIキーを作成して、ここに入力することになる。
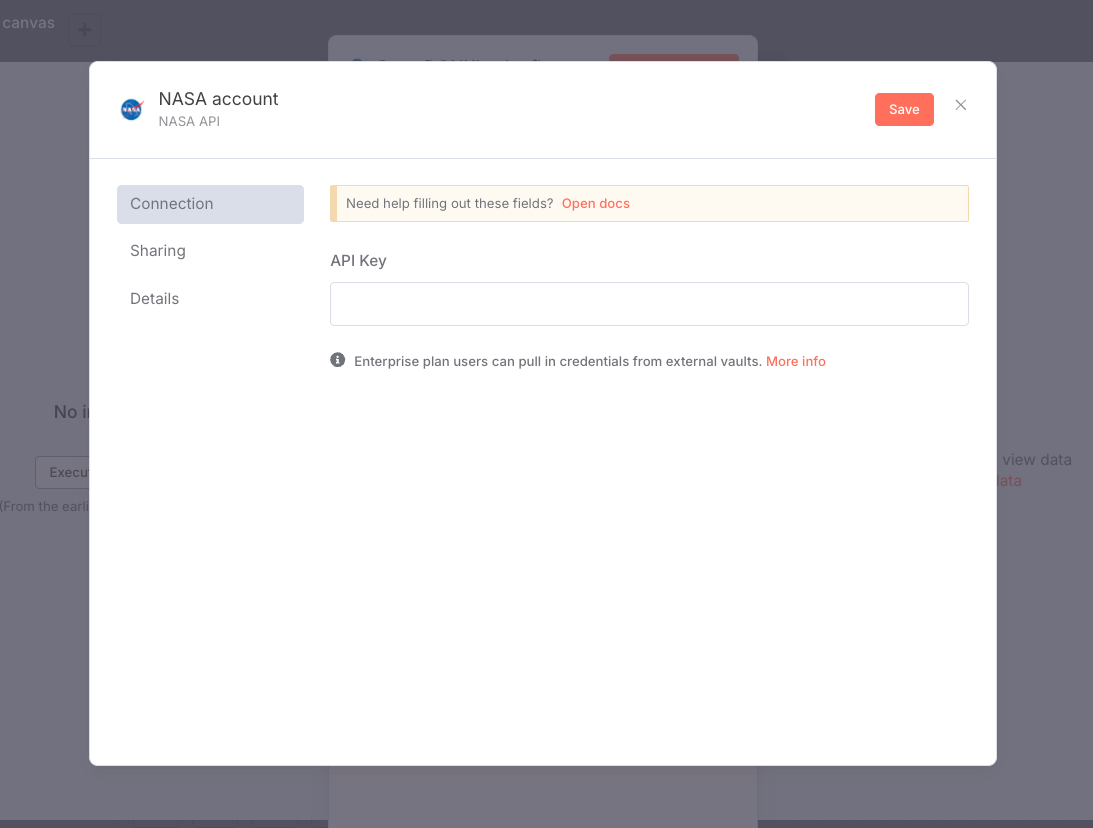
ということで別タブでNASAのAPIサイトにアクセスして、アカウント登録+APIキー取得を行う。

メールで送信されたAPIキーをn8nのクレデンシャル登録画面に入力して保存。
ノード設定画面に戻るとクレデンシャルが設定されている。

DONKI solar flare APIはデフォルトで過去30日間のデータを取得する。これを過去1週間に限定する。"Add Fields"をクリックすると、取得するデータの開始日・終了日を指定できる。
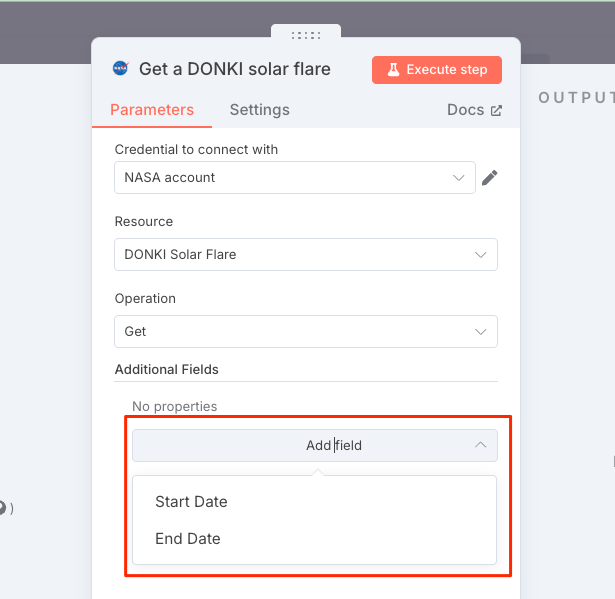
"Start date"をクリックする。日付はカレンダーから選択するか、もしくは"expression"を使ってコードで指定することができる。カレンダーの場合はおそらく固定になると思う。"expresssion" なら実行時に動的に設定できるだろう。今回は"expression"を使う。
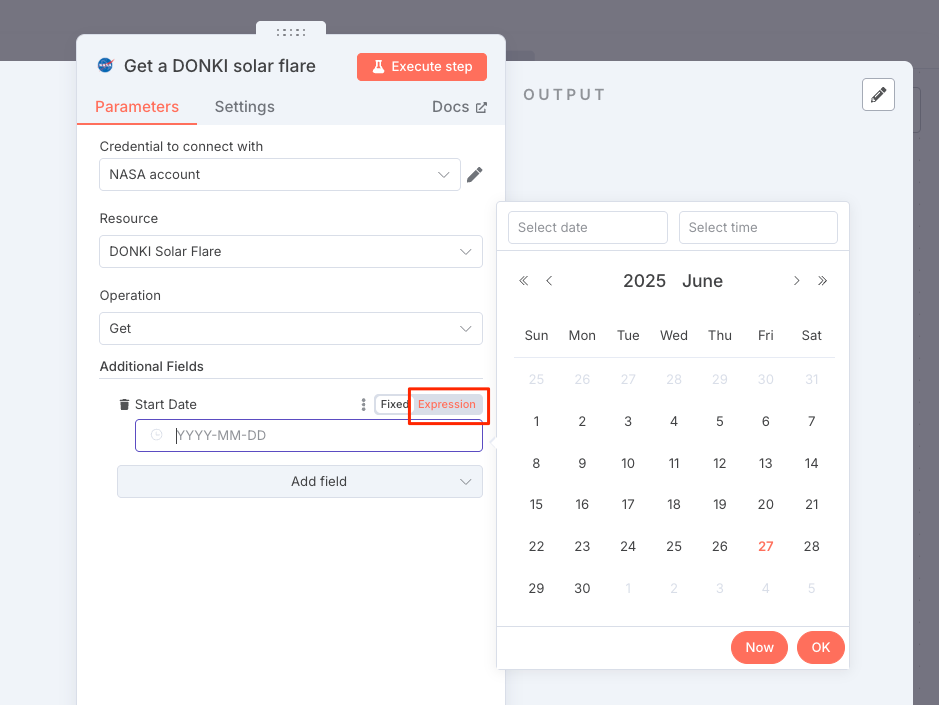
以下を入力して、その場で実行して確かめてみる。
{{ $today.minus(7, 'days') }}
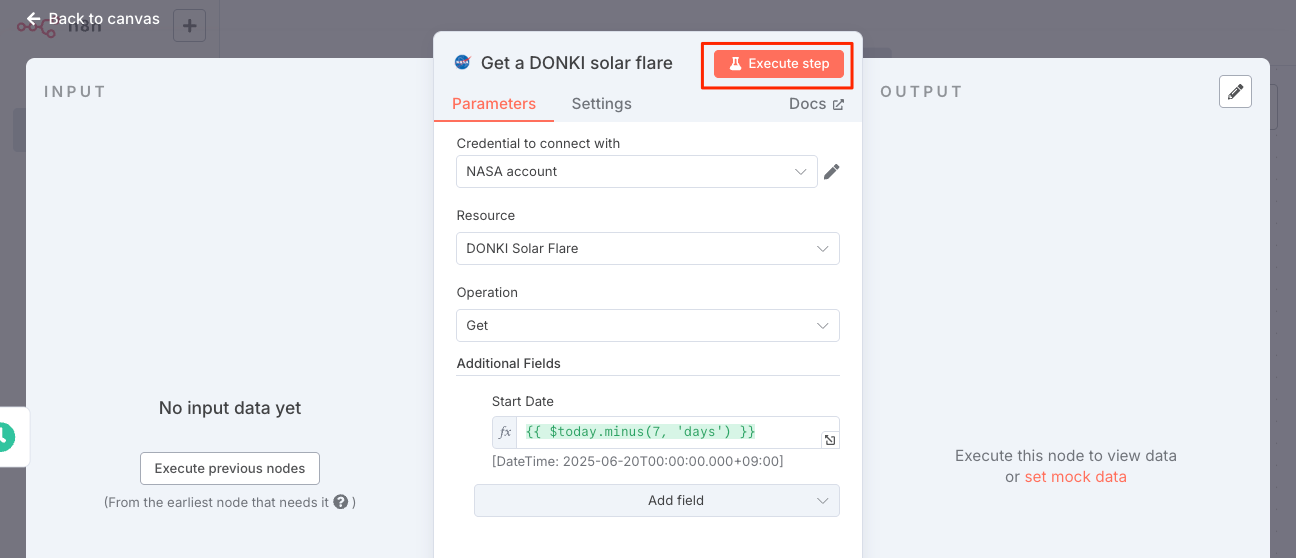
データが取得できているようだ。フローに戻る。

Ifノードでロジックを追加
n8nは条件分岐などのロジック処理をフローに含めることができる。今回は「Ifノード」を使ってフローを分岐させる。
太陽フレアのデータには5つの分類があり、片方でより高い分類、もう片方でより低い分類、という感じの分岐を行う。Ifでどちらか片方に行くのか、それぞれで処理されるのか、はちょっとやってみないとわからないな。
ま、とりあえず"+"でノードを追加。

Ifノードを追加
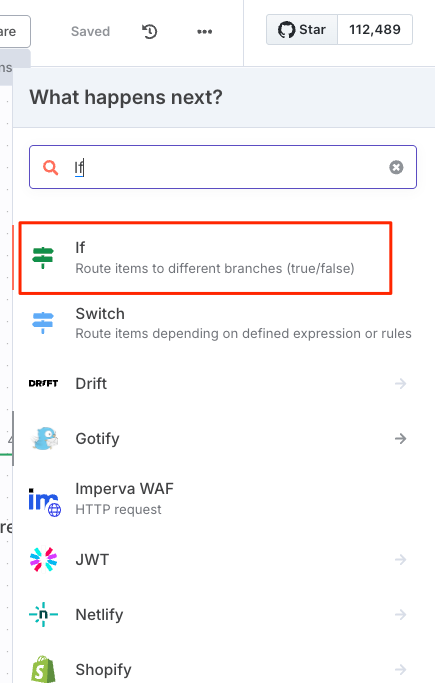
Ifノードの設定画面が開く。で、設定を行うのだが、パネルがオーバーラップしててNASA ノードからの入力データが見えない・・・
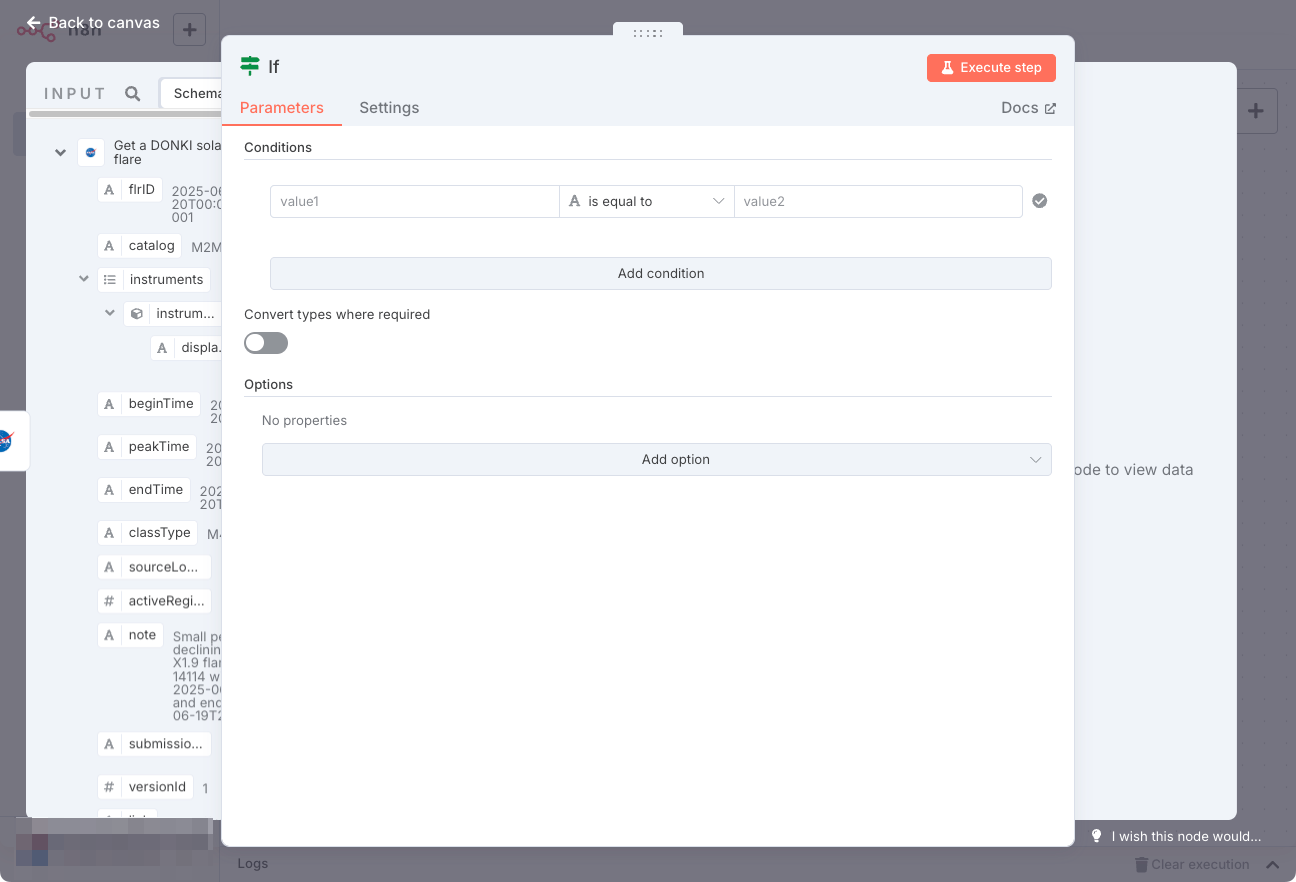
と思ったら、これパネルの橋をドラッグしたら幅変更できるんだなー。で、入力データの"classType"プロパティを"Value1"にドラッグ。

比較条件を"Strings"の"Contains"に変更
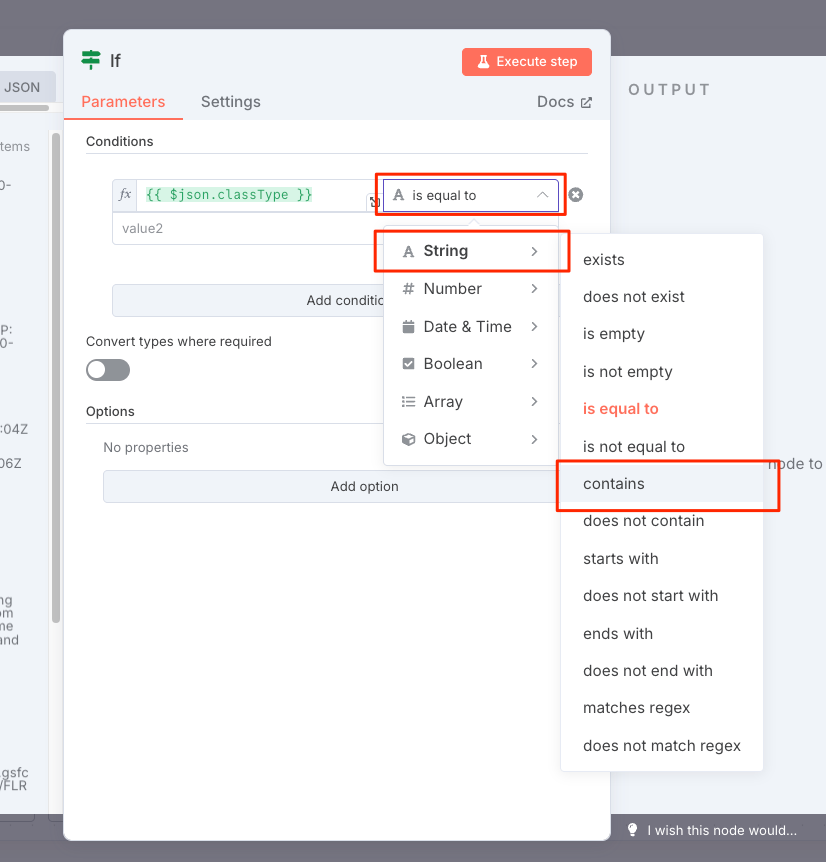
"Value2" に Xを入力する。これはソーラフレアの分類で最も高い分類値となるみたい。これで、最も高い分類値(X)を含むものとそれ以外、みたいな感じの分岐になるみたい。軽く実行してみる。

右側に条件分岐の結果がTrue・False、それぞれのデータが表示される。

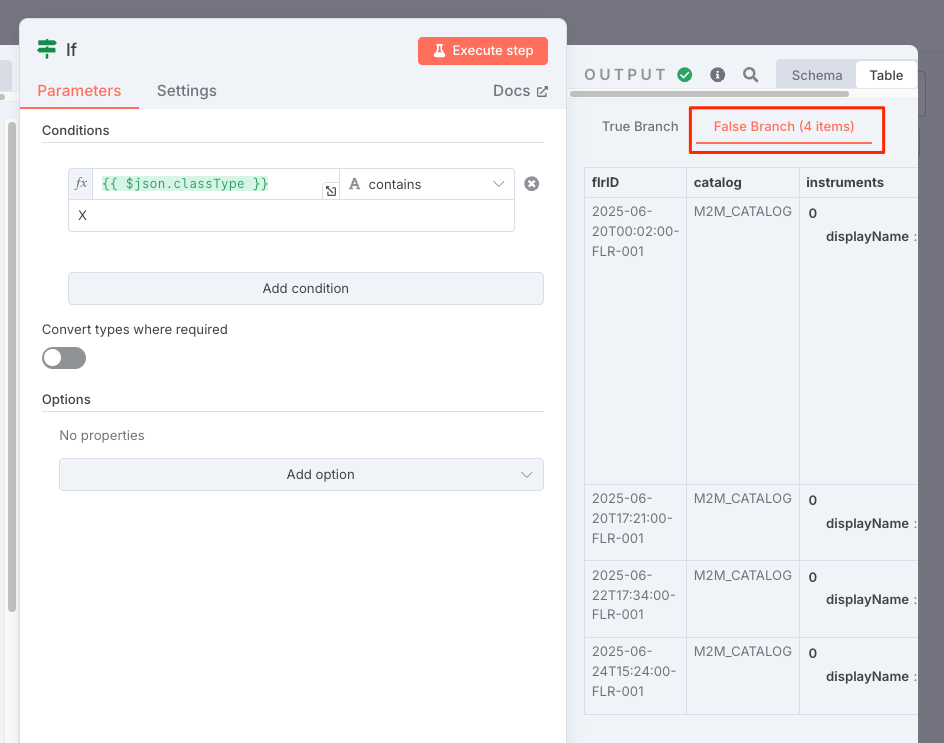
これは実際のAPIリクエストの結果なので、こういうこともありうる。A / B / C / M などにすれば変わるらしい。ということで今回はCにしてみたら変わった。わかりやすさ優先でこのまま進める。

ワークフローデータの出力
上記の結果をレポートとして出力する。今回は PostBin というデータを受け取ってテンポラリなWebページを生成するサービスを出力先として使用する。
まず、IfノードのTrueの方の"+"をクリックしてノード追加。

ノード検索でPostbinを選択。
"Send a request" を選択。
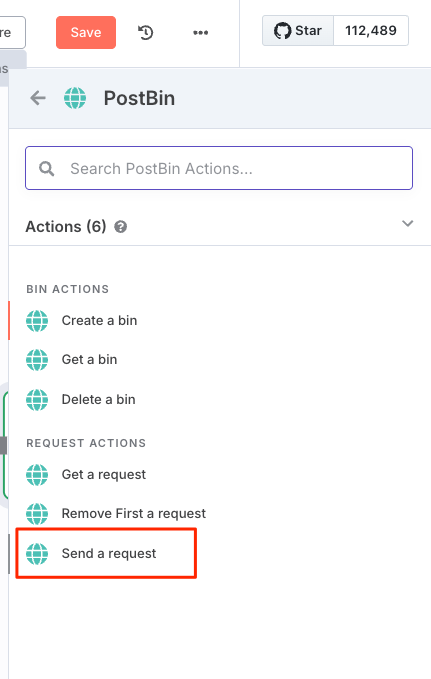
Postbinノードの設定画面が表示される。ここにあるBin IDを入力するのだが、BinはPostbin側で作成する必要がある。
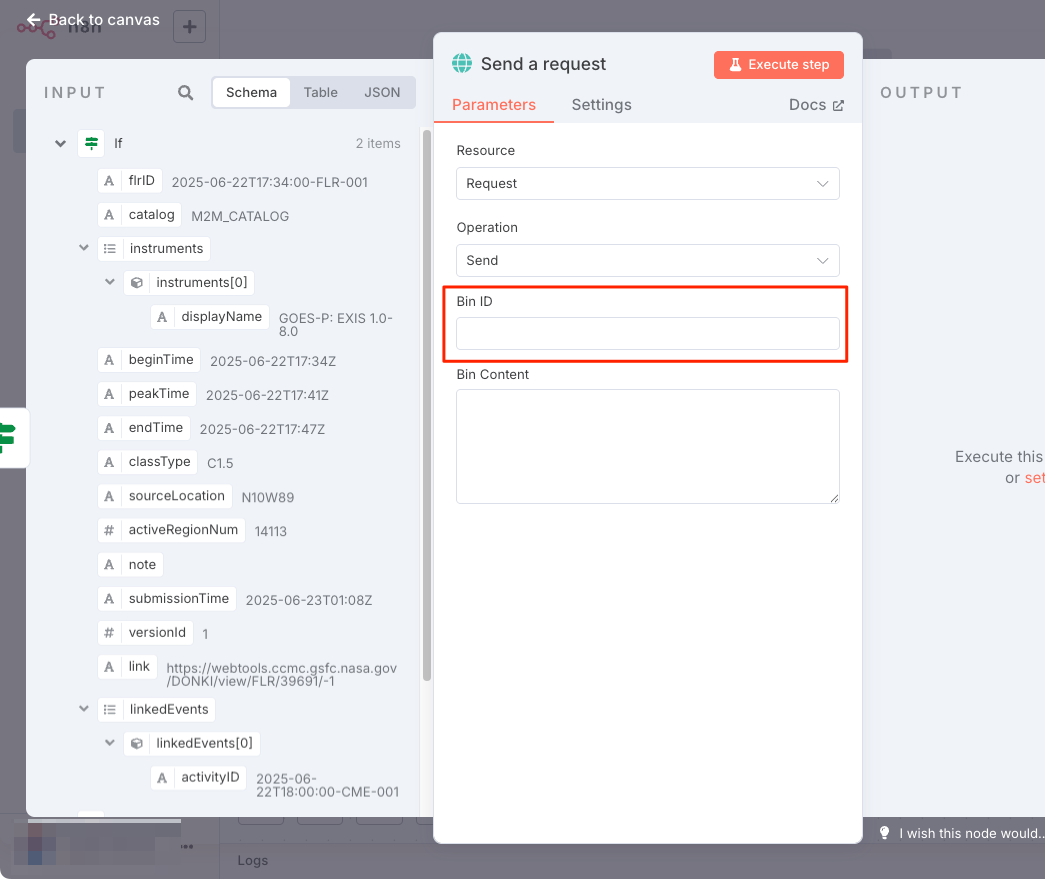
Postbinを開いてBinを作成。

Binが作成された。このBin IDをコピー。
Bin IDをペーストして入力。そして送信するデータをBin Contentに設定する。Expressionタブを選択して、Expression Editorを開く。

以下をペースト。もちろん、左の項目からドラッグ&ドロップして、その他のテキストを入力する、というやりかたもできる。
There was a solar flare of class {{$json["classType"]}}

フローに戻って、Falseのほうも同様に設定していくのだが、一度作ったノードを複製することもできる。先ほど作成したPostbinノードにカーソルを合わせて、"⋯"をクリックして"Duplicate node"を選択

Postbinノードが複製されるので、IfノードのFalseのコネクタをドラッグして複製されたノードにつなげる。
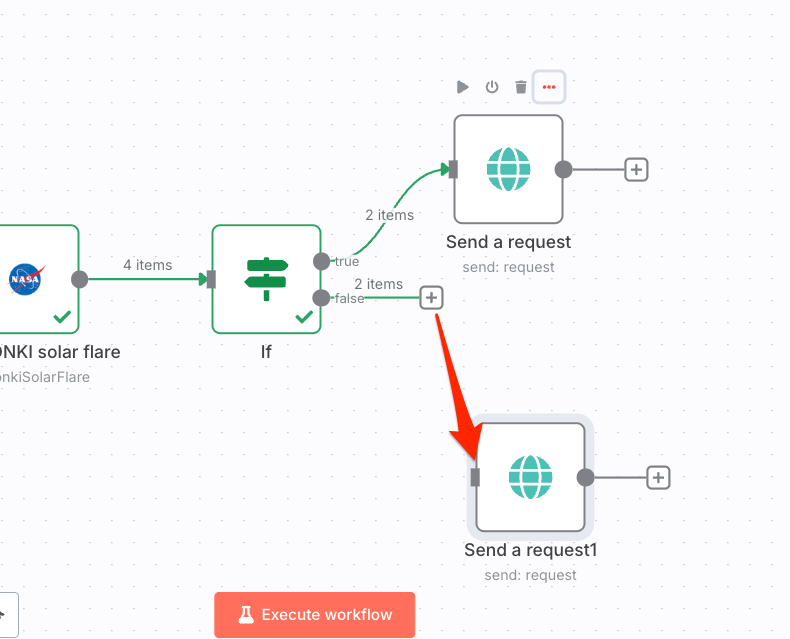
こうなる。あとは設定を変えたければノードを開いて設定を変更すると良い。自分はPostbinでもう一つBinを作成して、TrueとFalseでPostbinのBin IDを変えた。

では実行してみる。本来はスケジュールで実行されるのだけど、今回は手動で。

実行された。

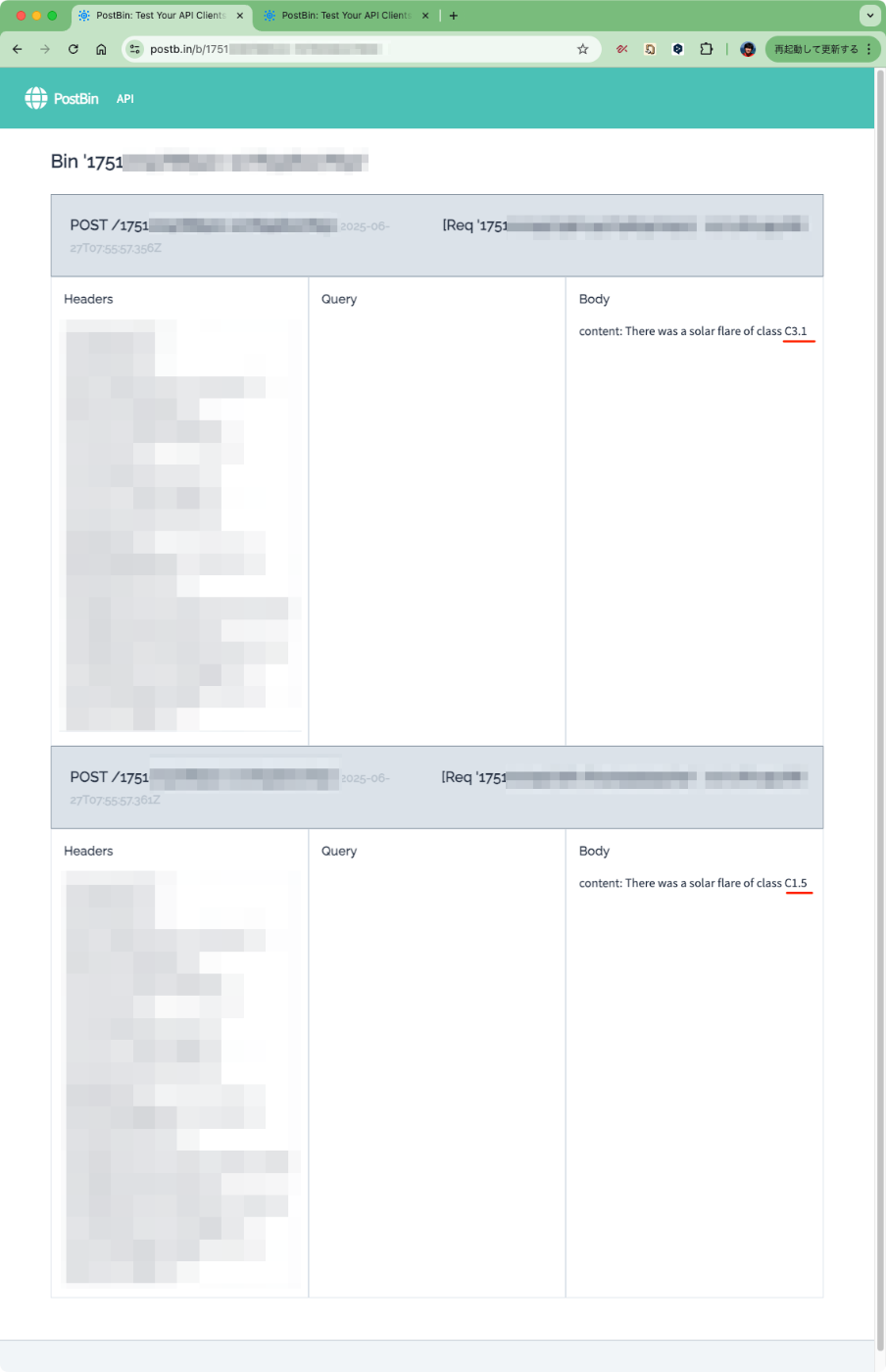
PostbinのそれぞれのBinのページを見てみると、異なるデータがそれぞれのページに表示されている。

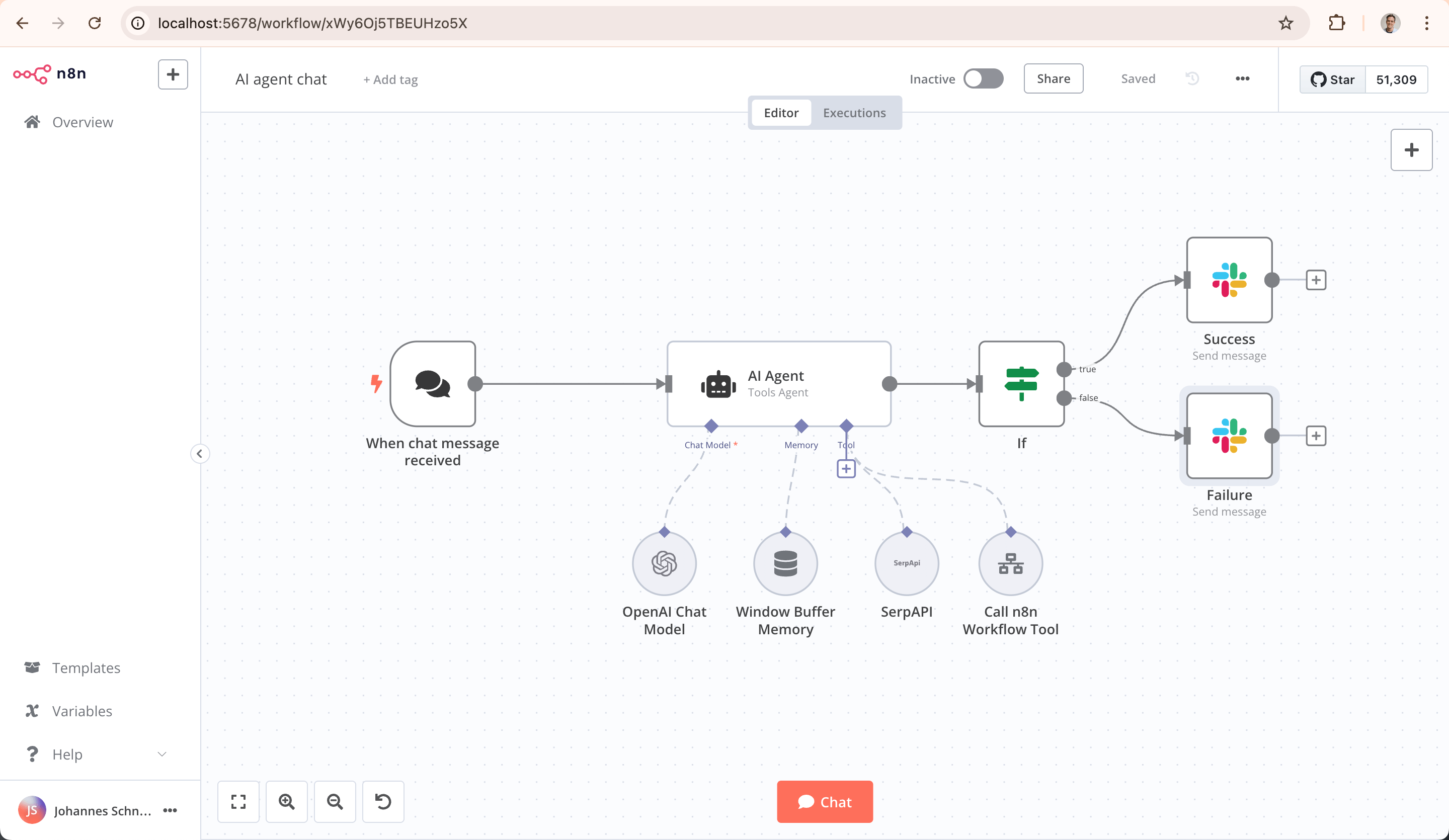
Quickstarts3: Build an AI workflow in n8n(Build an AI chat agent with n8n)
次に、LLMを使ったAIエージェントを作成する。
普通にLLMを使う場合とAIエージェントを使う場合の違いがまとめられてるのでおさらい。
| 機能 | LLM | AIエージェント |
|---|---|---|
| コア機能 | テキスト生成 | ゴール志向のタスクの完了 |
| 意思決定 | ✘ | ⭕️ |
| ツール・APIの使用 | ✘ | ⭕️ |
| ワークフローの複雑性 | シングルステップ | マルチステップ |
| スコープ | 言語の生成|複雑な現実のタスクの完了 | |
| 例 | LLMで文章を生成 | 予約をスケジュールするエージェント |
ではやっていく。ワークフローを作成。
"Add first step"で、”Chat Trigger”を選択。

設定は特になし。フローに戻る。

"+"をクリックして今度は"AI Agent"ノードを追加
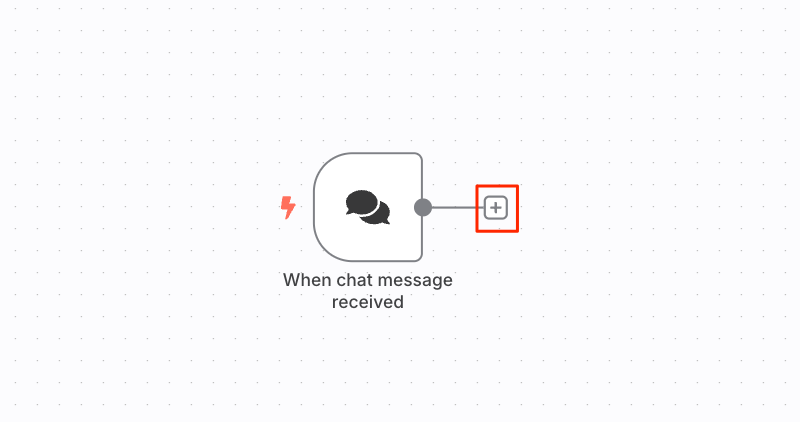
色々設定もできるようだが、とりあえずフローに戻る。

AIエージェントノードの"Chat Model"の"+"アイコンをクリックして、LLMを使ったチャットモデルのノードを追加する。今回はOpenAIを使うので、"OpenAI Chat Model"ノードを選択。
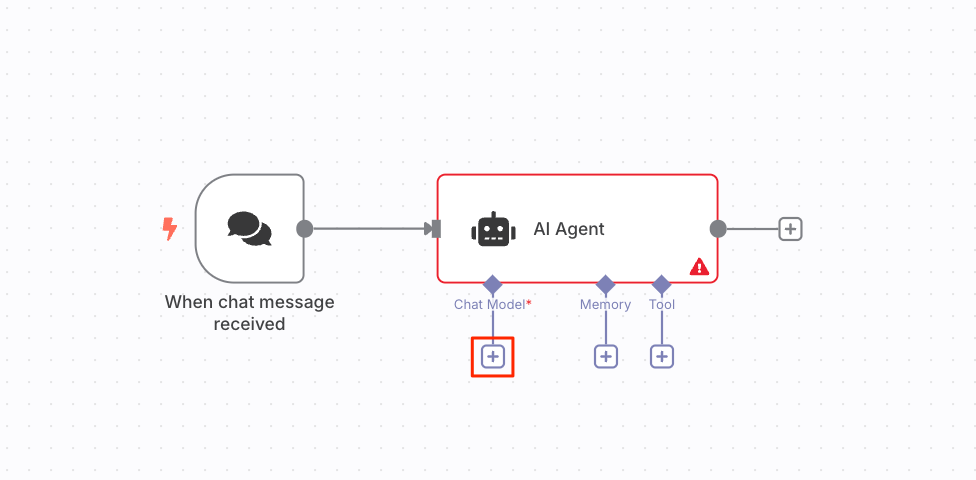

設定画面が開いたら、クレデンシャルを作成。
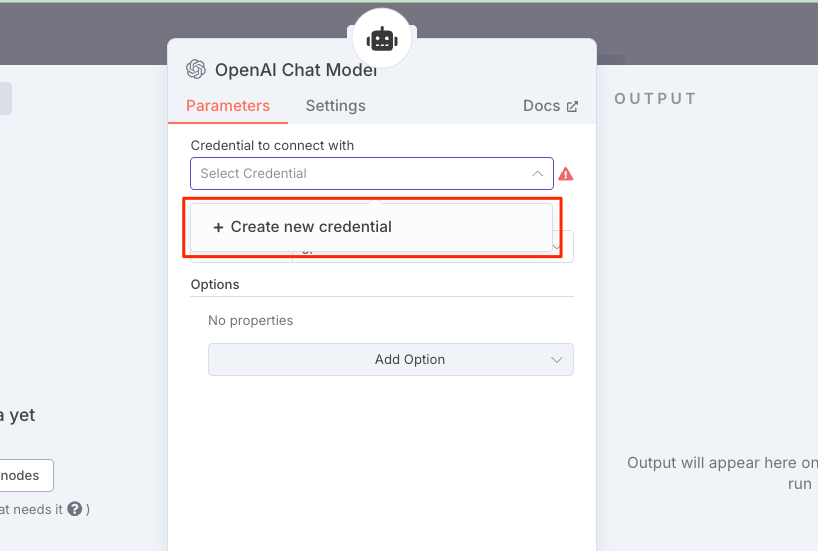
OpenAI APIキーを入力して保存。
今回はモデルはデフォルトの"gpt-4.1-mini"を使う。フローに戻る。
ではテスト。「Chat Trigger」の場合は"Execute workflow"ではなく、"Open chat"になっているので、これをクリック。

下にチャット入力欄がでてくるのでここに適当にメッセージを入力する。
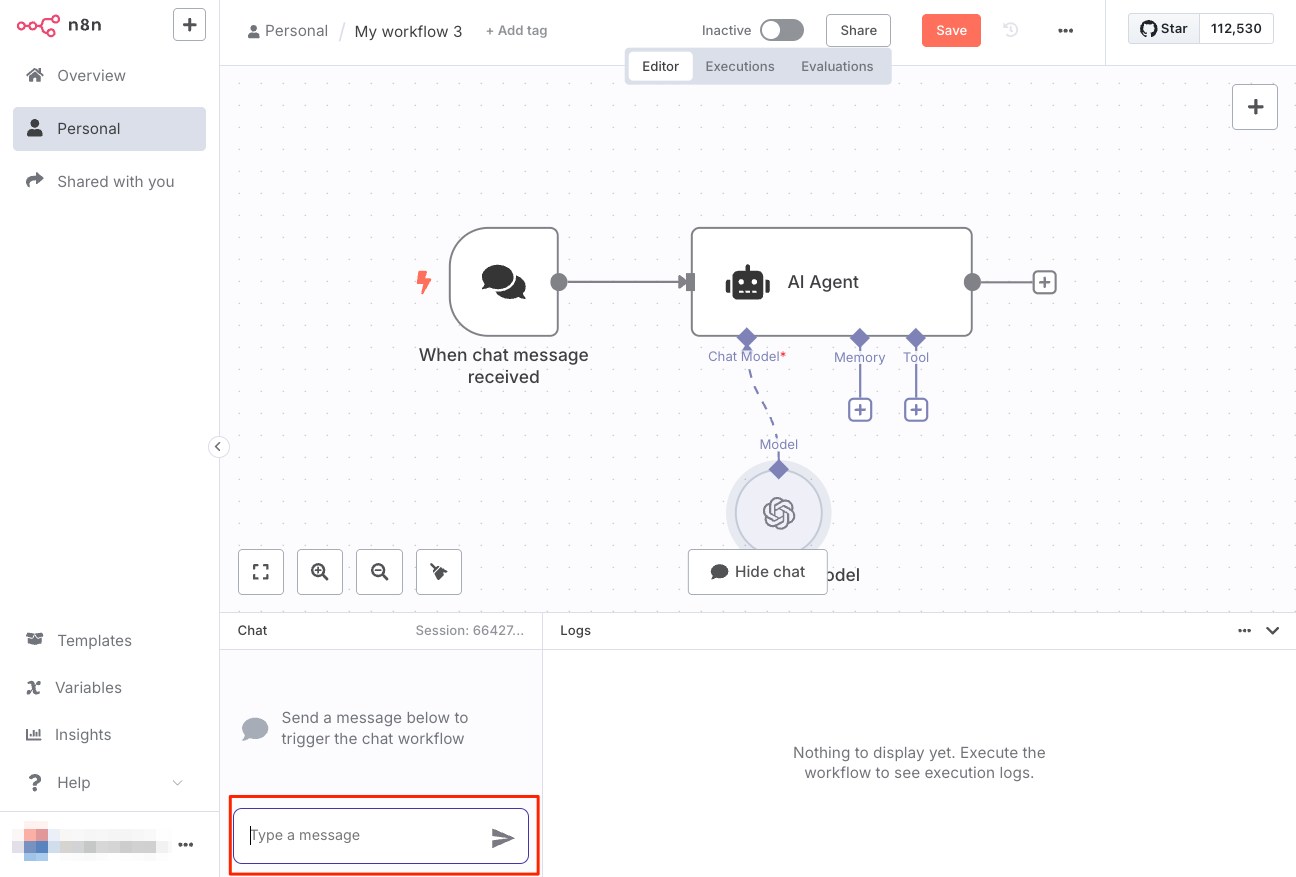
こんな感じでチャットができる。

システムプロンプトを変更してみる。AIエージェントノードをダブルクリックして設定を開く。

"Add Option"の中にある"System Message"をクリック。
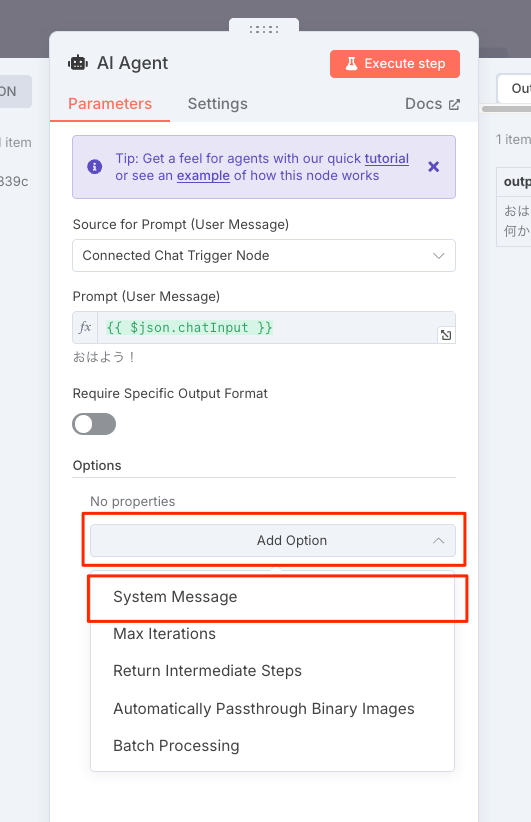
デフォルトは "You are a helpful assitant" らしい。

これを以下に変更する。
あなたは大阪のおばちゃんです。楽しく元気に大阪弁で会話してください。

もう一度会話してみるとこんな感じ。システムプロンプトが反映されているのがわかる。

ただし、現状は単なるシングルターンのやりとりとなり、以前の会話内容を記憶していない。

ということで、エージェントにメモリを追加する。AIエージェントノードのMemoryの"+"をクリック。
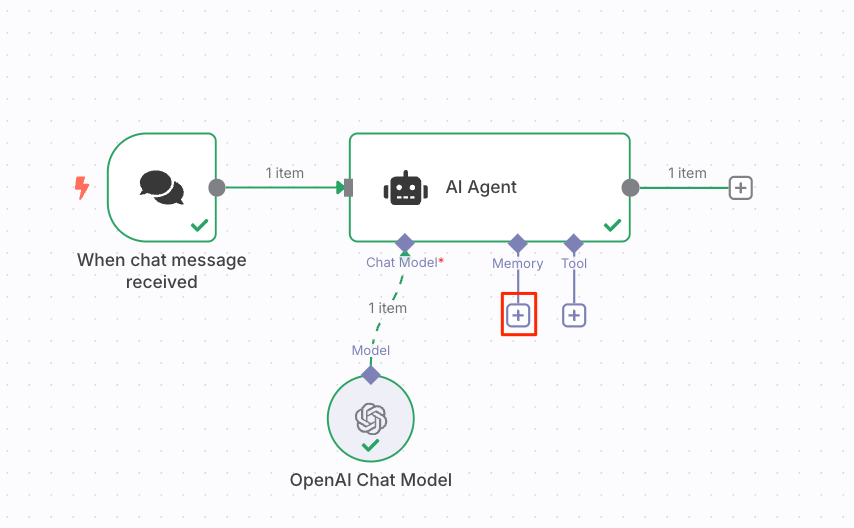
いくつかのメモリが用意されているが、今回は"Simple Memory"を選択。これはn8nのインスタンス上に保存されるらしいが、セッションをまたいだ永続性があるかどうかはわからない。とりあえずお試しで。

設定画面が開く。デフォルトだと5ターン?分の履歴が保持されるみたい。セッションごとに保持されるように読めるので、セッション跨ぎはできないかもね。とりあえずテストなので、デフォルトのままで。フローに戻る。

先ほどと同じような会話を行ってみると、ちゃんと前回の会話を覚えているのがわかる。

同様にしてツールも設定すれば良い。今回は試さないが、MCPやベクトルストア、各種APIを叩くものなど非常に多くのツールがあって、JS/Pythonでコードも書けたり、さらに別のn8nワークフローを読んだりってものできるみたい。

その他気になったものだけ。
ロジック
- 条件分岐
- If: 任意の条件で2分岐
- Switch: 任意の条件でn分岐
- 分岐フローの統合
- Merge: 複数の分岐されたフローのデータを統合
- Compere Datasets: 複数の分岐されたフローのデータを比較・統合
- ループ
- If: 条件分岐させてフローをもとに戻せばループになる
- Loop Over Items: 複数のデータが渡ってくるようなケースでデータごとに処理
- 制御
- Wait: 一定時間待つ。sleepっぽい感じ
- Stop and Error: エラーハンドリング
- Execute Sub-workflow: 他のn8nワークフローを呼び出し
- その他
- Code: JS/Pythonでコードで処理。
n8nは並列処理ができない、というのを見かけたことはあるけど、少なくともフロー的には並列にはなりそう(内部的に並列でやってるかどうかはわからない)
Codeノード
使用できるのはJSとPython、ただし色々制限がある。
- JSはNode.js。セルフホストだとnpmパッケージもインストールすれば使えるっぽい(クラウドはできない)
- PythonはPyodide。Pyodideに含まれたパッケージのみ。
- どちらもファイルシステムへのアクセスやHTTPリクエストは不可
バックエンドとして使用する
何かしらのバックエンドAPIとして使う場合は、"Webhook"がトリガーで、"Responed to Webhook"で終わるってのがポイントみたい。
例えばこんな感じ。

で、"Webhook"の設定で、"Respond"にUsing 'Resond using Webhook' Nodeを選択すれば、該当のリクエエストに対して、フローの最終結果をレスポンスとして返すことができるようだ。
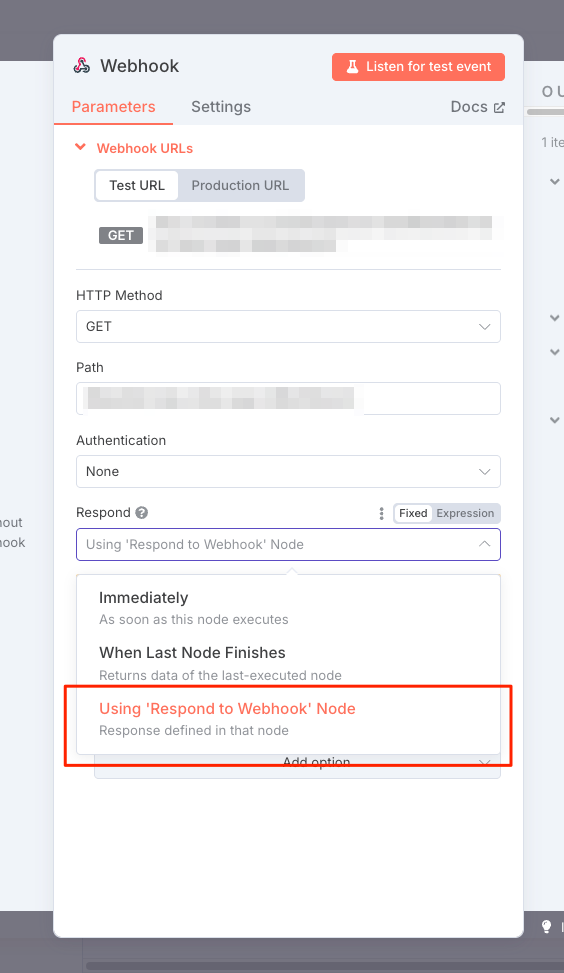
ただちょっとよくわからないのだけど、Webhookで受け取ったリクエストのパラメータとかフォーマットを細かく設定するってのができないのかな?なんとなくだけどなんでもとりあえず受け取るって感じに見える。まあその後でチェックせよ、ということなのかもしれないけども。
とりあえず色々いじるにあたって必要なことの雰囲気は掴めたような気がする。
まとめ
この手のツールは色々あって、DifyなりFlowiseなり、最近はLLMにワークフローを取り入れたものが多いように思う。
それらと違うのは、n8n、あと同じような位置づけとしてはZapierなどは、何かしらのワークフロー自動化が先にあってそこにLLMを追加したという感じなことだろう。
こちらのメリットとしては既存の豊富な連携モジュール(n8nでいうノード)なのだろうと思う。まあそういう意味では、現状の業務フローとかにLLMを導入するにあたって、現状の延長線で考えることができると思うので、わかりやすいし、小さなところから導入しやすい、ってのはあるのかもしれない。
LLMネイティブでできたツールとあわせて、今後どのように進んで行くか、というところかな。エージェントが全部持っていく、という可能性はまああるのかもしれないけど。
まあちょっとしたPoC作ったりとかには良さそう。
これすごいなと思って、Claude-Sonnet-4に雑にお願いしてみた。

生成されたコードをn8nで新規プロジェクトにペーストするとこんな感じに・・・
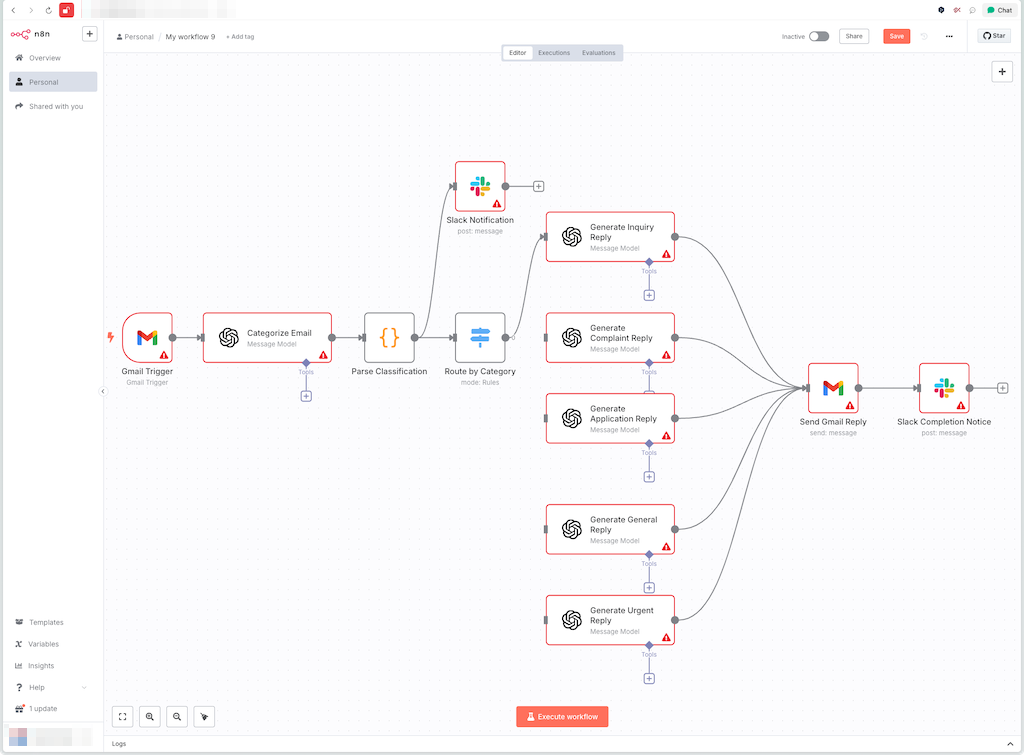
ちょっと手直しは必要だけれども、大まかには書けてしまう・・・
そこまでできるのかー
n8n は、API の接続、データの移動、通常のワークフローなど、基本的な自動化作業のためのものだけだと思っていました。
しかし、今日は完全に予想外のことですが、完全な SaaS バックエンドの構築に挑戦しました。
- ユーザー登録システム
- セッション管理付きログイン
- JWT 認証
- セキュアな API エンドポイント
- 完全な Postgres 統合(Supabase でホスト)
不思議なことに、すべてが動作しました。初めての試みで。
ただコメントにも書かれているけど、これはライセンス的には商用ライセンスが多分必要になるはず
自分も、社内の内部での利用はOKだけど外向けはダメ、ぐらいの雑な認識だったんだけど、ドキュメント見るともうちょっと細かく書いてあった(実際は原文を確認)
n8n をバックエンドとして使用して、アプリ内の機能を動作させることはできますか?
通常はい、バックエンドプロセスがユーザーの資格情報を使用してユーザーのデータをアクセスしない限り可能です。
以下の2つの例で説明します:
例1: ACMEアプリとHubSpotの同期
ボブはn8nを設定し、ユーザーのHubSpot資格情報を収集して、ACMEアプリ内のデータをHubSpot内のデータと同期します。
サステナブルユースライセンスでは許可されていません。この使用例では、ユーザーのHubSpot資格情報を収集し、ACMEアプリに情報を送信するために使用しています。
例2: ACMEアプリにAIチャットボットを埋め込む
ボブはn8nを設定し、ACMEアプリ内にAIチャットボットを埋め込みます。n8n内のAIチャットボットの資格情報は、ボブの会社の資格情報を使用します。ACMEアプリのエンドユーザーは、チャットボットに質問や問い合わせを入力するだけです。
サステナブルユースライセンスライセンスの下で許可されています。ユーザーの資格情報は収集されません。
バックエンド利用自体はNGではないけども、ユーザを識別するかどうか、ってところが分かれ目って感じに思える。なるほど。
これはなかなか・・・