RAGASを試す
OpenAI DevDayの以下のセッションでも紹介されていた。
LLamaIndexで試してみた。とてもいい感じ。
LlamaIndexを使わずに素のOpenAI APIもう少しいろいろ試してみたい。
Getting Started
ということでちゃんとGet Startedからやってみる。Colaboratoryで。
インストール
!pip install ragas
ragasのバージョンは0.0.22だった。
Successfully installed dataclasses-json-0.6.3 datasets-2.16.1 dill-0.3.7 h11-0.14.0 httpcore-1.0.2 httpx-0.26.0 jsonpatch-1.33 jsonpointer-2.4 langchain-0.1.4 langchain-community-0.0.16 langchain-core-0.1.17 langsmith-0.0.84 marshmallow-3.20.2 multiprocess-0.70.15 mypy-extensions-1.0.0 openai-1.10.0 pysbd-0.3.4 ragas-0.0.22 tiktoken-0.5.2 typing-extensions-4.9.0 typing-inspect-0.9.0
OpenAI APIキーをセット
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
評価
テストデータは以下を使っている。
このデータは以下の構造になっている。
-
question: list[str]- RAGパイプラインに渡された質問
-
answer: list[str]- 上記の質問に対して、RAGパイプラインでで生成された回答
-
contexts: list[list[str]]- 上記の回答を生成するためにLLMに渡されたコンテキスト情報
-
ground_truths: list[list[str]]- 質問に対する回答、つまり正解データ/教師データ。
-
context_recallを使用する場合のみ必要
from datasets import load_dataset
fiqa_eval = load_dataset("explodinggradients/fiqa", "ragas_eval")
fiqa_eval
DatasetDict({
baseline: Dataset({
features: ['question', 'ground_truths', 'answer', 'contexts'],
num_rows: 30
})
})
pandasで見てみる。
fiqa_eval['baseline'].select(range(5)).to_pandas()

データのサンプル(翻訳済)
question
ビジネス仲間に発行された小切手を自分のビジネス口座に入金する方法を教えてください。
ground_truthes
適切な受取人に小切手を再発行してもらい、小切手の裏面にアソシエイトのサインをもらってから入金してください。これは第三者小切手と呼ばれ、完全に合法です。小切手が決済されなければ、お金は戻ってきません。ただし、小切手が高額であったり、銀行での知名度が低かったりする場合は問題があるかもしれません。その場合は、アソシエイトに銀行に行ってもらい、身分証明書を持って窓口の前で裏書をしてもらうことができます。厳密にはその場にいる必要はない。口座番号さえわかれば、誰でもあなたの口座に入金できる。また、自分の口座に入金し、小切手をビジネス宛に書くこともできる。
answer
あなたのビジネスの同僚に発行された小切手をあなたのビジネス口座に入金する最善の方法は、銀行にビジネス口座を開設することです。その際、郡役所から発行される「dba」証明書と、国税庁から発行される雇用者番号(EIN)が必要になります。ビジネス口座を開設したら、アソシエイトに小切手の裏面にサインをしてもらい、ビジネス口座に入金します。
contexts
アソシエイトに裏面にサインをしてもらい、それを入金するだけです。これは第三者小切手と呼ばれ、完全に合法です。小切手が決済されなければ、お金は戻ってきません。ただし、小切手が高額であったり、銀行での知名度が低かったりする場合は問題があるかもしれません。その場合は、アソシエイトに銀行に行ってもらい、身分証明書を持って窓口の前で裏書をしてもらうことができます。厳密にはその場にいる必要はない。口座番号さえわかれば、誰でもあなたの口座に入金できる。バンク・オブ・アメリカに確認したところ、小切手を現金化する(あるいは入金する、あるいは私のビジネス宛ての小切手にアクセスする)唯一の方法は、ビジネス口座を開設することだという。これは連邦政府の規則で、どの銀行も同じことを言うでしょう。そのためには、州発行の「dba」証明書(郡役場から)とIRS発行の雇用者番号(EIN)が必要だ。そして、一番安いビジネス・バンキング口座は月15ドル。小切手を振り出した銀行に行けば、私が個人事業主であることを示す書類があれば、小切手を現金化してくれると思う。でもよくわからない......。小切手の振り出し先をビジネス名ではなく個人名にしてくれと言われたら、私は赤信号だと思う。正直なところ、それは通常、その人が何らかの理由で自分のビジネス口座にお金を通したくないことを意味する。あなたがそうしているとは言いませんが、よくある問題です。会社が個人宛に小切手を振り出せば、詐欺に遭う危険性がある。さらに悪いことに、会社はあなたが実際に会社を所有しており、支払いを着服して雇用主から金をむしり取っていないというあなたの言葉を信じるだけだ。さらに悪いことに、会社が監査を受けて小切手が見つかった場合、小切手を書いた人は、なぜあなたに小切手を出したのかを正当化して文書化しなければならず、そうでなければ横領罪で起訴されるリスクがある。取引先の会社に小切手を振り出すことは、彼らにとって非常に得策なのだ。そう考えると、ビジネス名義の口座を持つべきだろう。長い目で見れば、その方がずっとシンプルな生活になるだろう。
評価したいデータをDatasets形式で渡して、評価メトリクスを指定して、評価。
from ragas import evaluate
result = evaluate(
fiqa_eval["baseline"].select(range(3)), # 今回は3件に限定している
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result
結果。
evaluating with [context_precision]
100%|██████████| 1/1 [00:02<00:00, 2.08s/it]
evaluating with [faithfulness]
100%|██████████| 1/1 [00:12<00:00, 12.35s/it]
evaluating with [answer_relevancy]
100%|██████████| 1/1 [00:06<00:00, 6.95s/it]
evaluating with [context_recall]
100%|██████████| 1/1 [00:10<00:00, 10.70s/it]
{'context_precision': 0.3333, 'faithfulness': 0.9444, 'answer_relevancy': 0.9756, 'context_recall': 0.7143}
一番最後に出ているのは全体の平均になっている様子。個々のデータごとに確認することもできる。
result.to_pandas()

評価データの作成
ドキュメントは自分で用意する必要がある。サンプルでは LlamaIndexのSemantic Scholor Loaderという論文からドキュメントを作成してくれるLoaderを使っている。
LlamaIndexのインストール
!pip install llama-index
Semantic Scholor Loaderでドキュメントを作成。ここではLLMに関する論文からドキュメントを作成している。
from llama_index import download_loader
SemanticScholarReader = download_loader("SemanticScholarReader")
loader = SemanticScholarReader()
query_space = "large language models"
documents = loader.load_data(query=query_space, limit=10)
読み込まれたドキュメントはこんな感じ。
for d in documents:
print(d.id_)
print(d.get_content().replace("\n","")[:50])
print("-----")
e9fde2b5-1304-4f1f-80bf-1d2aa7bd3459
Chain of Thought Prompting Elicits Reasoning in La
-----
729701ed-b1de-40d3-aeaa-e39a33707500
BLIP-2: Bootstrapping Language-Image Pre-training
-----
f4b7be5f-ce29-47b3-bab2-1f005fdb7db2
LoRA: Low-Rank Adaptation of Large Language Models
-----
248ceb86-02a0-4321-823c-f3a736b0072a
Large Language Models are Zero-Shot Reasoners Pret
-----
cb8e2ef0-1ef5-40bf-b9d5-230bcce965ea
Evaluating Large Language Models Trained on Code W
-----
b49a54e2-0f05-4511-b725-221b55d4a49c
MiniGPT-4: Enhancing Vision-Language Understanding
-----
3c8add89-9a23-4c6e-b970-d50d5127556b
A Survey of Large Language Models Language is esse
-----
8a1d5a87-8689-4275-a56b-95391b7aa9c8
Emergent Abilities of Large Language Models Scalin
-----
9ea50ffd-8d6c-4dfa-a125-77e2c6fe44e1
Training Compute-Optimal Large Language Models We
-----
3150c4a8-ba36-438f-83f3-35d52695ab05
Performance of ChatGPT on USMLE: Potential for AI-
-----
ここから評価データを作成する。
from ragas.testset import TestsetGenerator
testsetgenerator = TestsetGenerator.from_default()
test_size = 10
testset = testsetgenerator.generate(documents, test_size=test_size)
内部的にはLangChainを使って評価データを精製している模様。ちょっとwarningが多いけども。
/usr/local/lib/python3.10/dist-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The class `langchain_community.embeddings.openai.OpenAIEmbeddings` was deprecated in langchain-community 0.1.0 and will be removed in 0.2.0. An updated version of the class exists in the langchain-openai package and should be used instead. To use it run `pip install -U langchain-openai` and import as `from langchain_openai import OpenAIEmbeddings`.
warn_deprecated(
/usr/local/lib/python3.10/dist-packages/ragas/testset/testset_generator.py:329: UserWarning: Most documents are too short
warnings.warn("Most documents are too short")
10%|█ | 1/10 [00:19<02:56, 19.64s/it]/usr/local/lib/python3.10/dist-packages/ragas/testset/testset_generator.py:279: UserWarning: No neighbors exists
warnings.warn("No neighbors exists")
28it [02:51, 6.13s/it]
一応データはできてる。
testset.to_pandas()

微妙にカラム名とか違うなぁ、、、ということで中身を見てみると、TestsetGenerator.generateはTestDatasetオブジェクトを生成する。
type(testset)
ragas.testset.testset_generator.TestDataset
TestDatasetオブジェクトはtest_dataというキーにDataRowオブジェクトのリストが紐づいている。
DataRowオブジェクトはこんな感じ。
どうもドキュメントが更新されていないような気がするなー、少なくともLLMの回答は含まれていないように思える。
コードはこの辺で変わっている。
んー、これを以て、LLMが生成した回答をground_truth、その時のコンテキストをground_truth_contextとするのはなんかこう腑に落ちない感がある。
ちなみに2024/1/30時点のmainブランチだと、TestDatasetにto_datasetというメソッドが生えている。
最新版だと作成したデータをそのままevaluateに回せるのかも、と思ったりしたんだけど、カラム名が違うのはどうしたものか。
とevaluateのコードを見てみたら、カラム名の変更を設定できる様子。
名前は変えればいいし、テストデータも他に作りようはあるので、それほど問題にはならないと思うけども、ここがシームレスになっていないのは理由がわからないなぁ。。。。
なんとなくコード見てると、レポジトリからインストールしたほうが良いのかなぁという気も。
ただ、結構コードも変わりそうで、となるとドキュメントもかなと。。。悩ましいところ。
そろそろ0.1.0が出そうな雰囲気っぽい。
メトリクス
評価の指標は2つあって、それぞれでメトリクスが異なる。
- Component-Wise Evaluation
- コンポーネントごとの評価、例えば、retrieval(検索)とgeneration(生成)
- retrievalの評価指標
- Context Recall
- Context Precision
- Context Relevancy
- generationの評価指標
- Faithfulnesss
- Answer Relevance
- End-to-End Evaluation
- コンポーネント全体での評価、つまり、ユーザーエクスペリエンスに絡むもの
- 例えば
- Answer Semantic Similarity
- Answer Correctness
順番に見ていく
Component-Wise Evaluation: retrieval
Context Recall
- 検索で得られたコンテキスト(context)が、正解データ(ground truth)とどの程度一致するか?
- 言い換えると、コンテキストが正解データの中のポイント要素をどれぐらい網羅しているか?
- 正解データのすべての文がコンテキストに含まれている状態が理想。
- 0から1までの値で示され、値が高いほど精度が良いことを示す
計算式
紹介されている例。
質問: フランスはどこに存在していますか?また、首都はどこですか?
正解: フランスは西ヨーロッパにあり、首都はパリである。
Context Recallが高いコンテキスト
フランスは西ヨーロッパに位置し、中世の都市、アルプスの村々、地中海のビーチがある。首都パリは、ファッション・ハウス、ルーブル美術館を含むクラシック美術館、エッフェル塔のようなモニュメントで有名である。
Context Recallが低いコンテキスト
フランスは西ヨーロッパに位置し、中世の都市、アルプスの村々、地中海のビーチがある。また、ワインと洗練された料理でも有名だ。ラスコーの古代洞窟壁画、リヨンのローマ劇場、広大なヴェルサイユ宮殿は、その豊かな歴史を証明している。
Context Precision
- コンテキストの精度
- 精度≒正解データ(ground truth)の中の関連するすべての要素がコンテキスト(context)に含まれつつ上位にランクしているか?
- すべての関連するチャンクがランク上位になっていることが理想。
- 0から1までの値で示され、値が高いほど精度が良いことを示す
- 質問(question)とコンテキスト(question)を使用して計算される。
計算式
例がなかったので、ChatGPTに作ってもらった。
質問: 「フランスの首都はどこですか?」
コンテキスト: 検索エンジンが提供する上位k件の検索結果高いContext Precisionの例: 上位3件の結果すべてが「パリ」に関するものである場合、この時の精度は高く、真陽性は3、偽陽性は0です。Precision@3は1になります。
低いContext Precisionの例: 上位3件のうち、2件が「パリ」に関するもので、1件が関連性が低い内容(例えばフランスのワインについて)である場合、真陽性は2、偽陽性は1となり、Precision@3は2/3になります。
コンテキスト精度@kは、特定のk値での検索結果の精度を示し、この例では検索結果の精度を数値化し、どれだけ正確にユーザーのクエリに対して関連する情報を提供できているかを示しています。
Context Relevancy
- 質問(question)とコンテキスト(context)から、検索されたコンテキストが質問にどの程度関連しているか?
- 検索されたコンテキストが、提供されたクエリに対して必須情報のみを含んでいるのが理想。
- 0か1までの値で示され、値が高いほど精度が良いことを示す
数式
紹介されている例。
質問: フランスの首都は?
高いContext Relevancyの例
フランスは西ヨーロッパに位置し、中世の都市、アルプスの村々、地中海のビーチがある。首都パリは、ファッション・ハウス、ルーブル美術館をはじめとするクラシック美術館、エッフェル塔などのモニュメントで有名である。
低いContext Relevancyの例
フランスは西ヨーロッパに位置し、中世の都市、アルプスの村々、地中海のビーチがある。首都パリは、ファッション・ハウス、ルーブル美術館をはじめとするクラシック美術館、エッフェル塔などのモニュメントで有名である。ワインや洗練された料理でも有名だ。ラスコーの古代洞窟壁画、リヨンのローマ劇場、広大なヴェルサイユ宮殿は、その豊かな歴史を証明している。
なるほど、質問のコンテキストから外れる情報が増えると相対的に下がる、という感じっぽい。
Component-Wise Evaluation: generation
Faithfullnesss
- コンテキスト(context)から生成された回答(answer)が事実としてどれだけ一貫しているか?
- 回答がいかにコンテキストの内容に「忠実」か?
- 生成された回答内の「主張」している要素を特定し、すべての要素がコンテキストから推測できることかを判定。
- すべての主張がコンテキストから推測できるのが理想。
- 0から1までの値で示され、値が高いほど精度が良いことを示す
数式
単純な字面だとなんとなく1よりも大きい数字になりそうだけど、与えられたコンテキストから推測できる主張の数ってのは与えられたコンテキストから推測できる「正しい」主張の数ってことなんだと思う。
紹介されている例
質問: アインシュタインはいつ、どこで生まれたのか?
コンテキスト: アルバート・アインシュタイン(1879年3月14日生まれ)はドイツ生まれの理論物理学者であり、史上最も偉大で最も影響力のある科学者の一人として広く知られている。高いFaithfullnesssの回答: アインシュタインは1879年3月14日にドイツで生まれた。
低いFaithfullnesssの回答: アインシュタインは1879年3月20日にドイツで生まれた。
なんとなく文章を命題で分割・比較して、どれだけ誤りが少なく合致しているか?ってことなのかなと思った。
Answer Relevance
- 質問(question)に対して、回答(answer)がどれだけ妥当性があるか?
- 回答が不完全だったり冗長な情報を含んでいるとスコアが下がる
- ragasでは、回答の事実性は考慮されない、あくまでも質問と回答がマッチしているか?を評価する
- 回答から質問を複数回生成して、質問・回答間のコサイン類似度の平均を取る。
- 正しく回答できていれば元の質問を生成できるはずという前提
- 0から1までの値で示され、値が高いほど精度が良いことを示す
ちなみに数式がないので、コードから数式を精製してみた。
-
\overline{\text{cosine\_sim}} -
q -
Q_g -
N - 非コミット(noncommittal)な回答
- 質問に対して明確な立場を示さず、あいまいな答えを提供するものを指す。
- 生成された回答が質問に対して具体的な情報や明確な回答を提供していない状態を意味する。
- 非コミットな回答がある場合はスコアを0にしている
- 非コミット(noncommittal)な回答
紹介されている例
質問: フランスはどこにあり、首都は?
高いAnswer Relevanceの回答
フランスは西ヨーロッパにあり、パリが首都である。
低いAnswer Relevanceの回答
フランスは西ヨーロッパにある。
End-to-End Evaluation
Answer Semantic Similarity
- 生成された回答(answer)と正解データ(ground truth)が意味的に類似しているか?
- 生成された回答の「品質」を示す指標
- 0から1までの値で示され、値が高いほど精度が良いことを示す
数式はないけども、answerとground truthのembeddingsからドット積を使って類似度を計算している
紹介されている例
正解データ: アルバート・アインシュタインの相対性理論は、私たちの宇宙理解に革命をもたらした。
高いAnswer Semantic Similarityの回答
アインシュタインの画期的な相対性理論は、私たちの宇宙に対する理解を一変させた。
低いAnswer Semantic Similarityの回答
アイザック・ニュートンの運動法則は古典物理学に大きな影響を与えた。
Answer Correctness
- 生成された回答と正解データ間の整合性
- 2つの観点から評価する
- 意味的に類似しているか?
- 事実としての類似しているか?
- それぞれの重み付けを変更することもできる。
- 2つの観点から評価する
- 0から1までの値で示され、値が高いほど精度が良いことを示す
ちなみにデフォルトの重み付けは、事実の類似性: 0.75、意味的な類似性: 0.25、になってるようなので、どちらかというと正しくない情報が含まれたほうがスコア的ペナルティは厳しくなる、って感じに読める。
紹介されている例
正解データ: アインシュタインは1879年にドイツで生まれた。
高いAnswer Correctnessの解答例
1879年、ドイツでアインシュタインが生まれた。
低いAnswer Correctnessの解答例
スペインでは、アインシュタインは1879年に生まれた。
その他
Aspect Critique
これだけは評価指標の一覧には含まれていなかったけど一応。
ここまでの評価指標は最終的に検索なり生成なりの「品質」に関わるものだけども、Aspect Critiqueは以下の観点で評価を行うものになっている。要は回答(answer)に対して、一定のガードレールを設けるようなものだと思う。
- harmfulness(有害性)
- 個人、グループ、または社会全体に害を及ぼすか、または及ぼす可能性があるか?
- maliciousness(悪意)
- ユーザーを傷つけたり、欺いたり、搾取したりする意図があるか?
- coherence(一貫性)
- アイデア、情報、議論を論理的かつ整理された方法で提示しているか?
- correctness(正確性)
- 事実上正確で、誤りがないか?
- conciseness
- 不必要または冗長な詳細がなく、情報やアイデアを明確かつ効率的に伝えているか?
0 or 1で値が示されるけど、最終的なスコアには影響しないみたい。
ragasのテストデータ生成
ragasでのテストデータ作成は上の方で一度試しているが、単純なテストデータをLLMに作成させるだけでなく、テストデータに「バリエーション」をもたせるということができる。以下のような観点での作成ができる。
- 論理的判断
- 効果的に答えるための、論理的判断が必要になるように問題を書き直す。
- 条件付け
- 問題を修正して条件要素を導入し、問題に複雑さを加える。
- マルチコンテクスト
- 解答を作成するために、関連する複数のセクションまたはチャンクからの情報を必要とする方法で質問を言い換える。
- 会話形式
- 質問を発展させて会話形式のサンプルに変換することが可能。チャットに基づいた質問とフォローアップの相互作用を模擬し、チャットQ&Aの流れを真似るような質問になるように設計される。
ということでやってみる。
ベースのドキュメントを作成、いつも通りwikipediaから。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["イクイノックス", "ドウデュース"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
# SimpleDirectoryReaderで1ドキュメントとして読み込ませるために.txtにする
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
テストデータ作成。ちょっとコストが気になるので、critic_llmも"gpt-3.5-tubo"に変更して、10件生成させてみる。
from llama_index import SimpleDirectoryReader
from ragas.testset import TestsetGenerator
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from ragas.llms import LangchainLLM
docs = SimpleDirectoryReader(input_dir="data").load_data()
generator_llm = LangchainLLM(llm=ChatOpenAI(model="gpt-3.5-turbo"))
critic_llm = LangchainLLM(llm=ChatOpenAI(model="gpt-3.5-turbo"))
embeddings_model = OpenAIEmbeddings()
testset_distribution = {
"simple": 0.25,
"reasoning": 0.5,
"multi_context": 0.0,
"conditional": 0.25,
}
chat_qa = 0.2
test_generator = TestsetGenerator(
generator_llm=generator_llm,
critic_llm=critic_llm,
embeddings_model=embeddings_model,
testset_distribution=testset_distribution,
chat_qa=chat_qa,
)
testset = test_generator.generate(docs, test_size=10)
testset_distribution のところがテストデータのバリエーション。割合で指定する感じになっている。
では出力されたテストデータをpandasのデータフレームで見てみる。
test_df = testset.to_pandas()
test_df
んー、全部英語になってる。見た感じ、evaluateの場合はプロンプトのカスタマイズや言語を指定できるようになっているみたいみたいなんだけども。
TestsetGeneratorの方は今後の予定、って感じっぽい。
あとtest_sizeが件数なのかなと思うのだけど5件しか出力されていない。。。ちょっといじってみる。
testset = test_generator.generate(docs, test_size=2)
test_df = testset.to_pandas()
test_df.shape[0]
3
testset = test_generator.generate(docs, test_size=20)
ValueError: Maximum possible number of samples exceeded,
reduce test_size or add more documents
んー、ドキュメント数によるのかも。今回のドキュメント数は2なので、もうちょっと分割したら変わるんだろうか。
と思ったらissue上がってた。
ちなみに5件出力された時の割合を見てみた。
import seaborn as sns
sns.set(rc={'figure.figsize':(9,6)})
test_data_dist = test_df.question_type.value_counts().rename('count').reset_index().rename(columns={'index': 'question_type'})
sns.set_theme(style="whitegrid")
g = sns.barplot(y='count',x='question_type', data=test_data_dist)
g.set_title("Question type distribution",fontdict = { 'fontsize': 20})
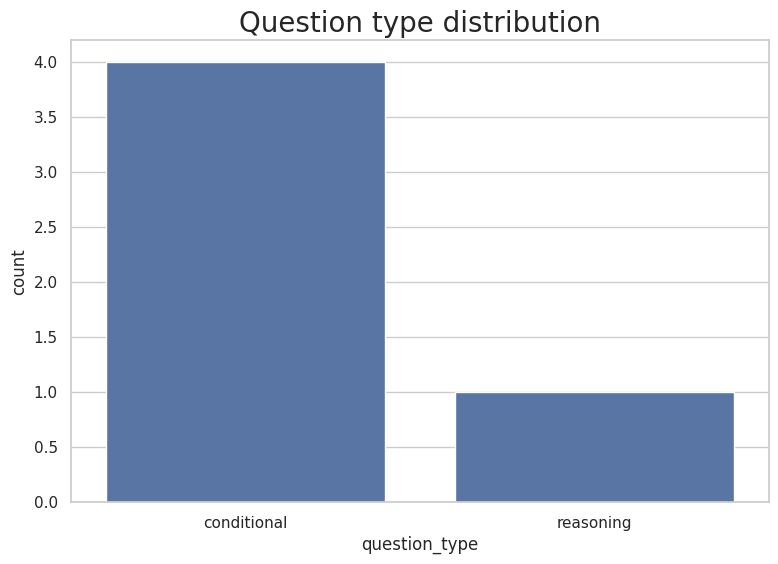
んー、ここも微妙だけども、そもそもtest_sizeが効いてないのが良くないような気はする。
とりあえずTestsetGeneratorは、まだちょっとbuggy、かつ、mainブランチで色々変わってるっぽいので、今後に期待。まあ他のフレームワークでも作成自体はできるので、現時点では「評価のみ」専用として割り切ったほうが良い気はしてる。
その他、How-to Guidesで気になったのはこの辺。
LLM/Embeddingsのモデルの変更とか。
- デフォルトはgpt-3.5-turbo
- LangChainのllmモジュールをラップしているLangchainLLMモジュールで変更するっぽい
- EmbeddingsでFastEmbed使えるのは良さそう
- Bedrock使えるのも良さそう
でLLMやEmbeddingsのモデル比較、これは結構良さそう。見た感じ、LlamaIndexでQuery Engine作って比較してるっぽいので、LlamaIndexに慣れてると使い勝手良さそう。
LlamaIndexやLangChainとかのフレームワークとのインテグレーションだけじゃなくて、LangSmithやLangFuseとかのプラットフォームとのインテグレーションもある。LangFuseだとローカルでも建てれそうなので、LangFuse含めてちょっと試してみたい。
とりあえず雰囲気はだいぶ掴めた。
データセット作成のところはやや混沌としてる感もあるけど、評価はやっぱりお手軽で良いんじゃないかなと思う。最近はLlamaIndexずっと触ってるので、そのあたりと親和性高そうなのも良さげ。
データセットはHuggingFaceのDatasets形式なのだけど、あまり触ってないのでこっちも触っていかないと、ってのは感じた。
あと日本語データでも評価してみないとね。
2024/1/31時点のmainブランチで再度TestsetGenerator動かしてみた。ちなみにv0.1.0rc1だと全然動かなかった。
from ragas.testset import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
generator_llm = "gpt-3.5-turbo"
critic_llm = "gpt-3.5-turbo"
embeddings_model = "text-embedding-ada-002"
distributions = {
simple: 0.4,
reasoning: 0.4,
multi_context: 0.2
}
test_generator = TestsetGenerator.with_openai(
generator_llm=generator_llm,
critic_llm=critic_llm,
embeddings=embeddings_model,
)
# generate_with_llamaindex_docsで、LlamaIndexのdocumentsかnodesを渡せる
testset = test_generator.generate_with_llamaindex_docs(nodes, 10, distributions)
だいぶスッキリ書ける。テストデータを見てみる。
testset.to_pandas()
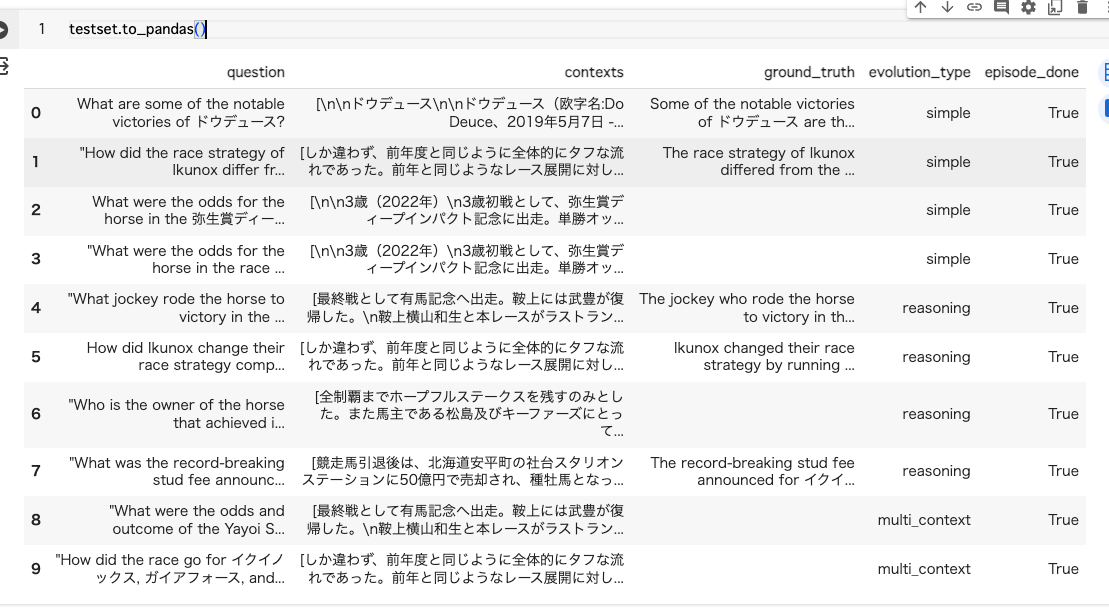
ちゃんとtest_sizeも問題の割合も制御できてるのに、肝心の回答が得られてい無いものがチラホラある。惜しいな。
プロンプトを渡すようなインタフェースは最新のブランチでも見当たらないけど、一応ToDoに上がってるみたいだから、v0.1.0を期待しておこう。
v0.1.0が出た