LLamaIndexのRecursiveRetrieverを試す
これ読んで、
ここめっちゃ気になったので、実際にRecursiveRetrieverを試してみる。

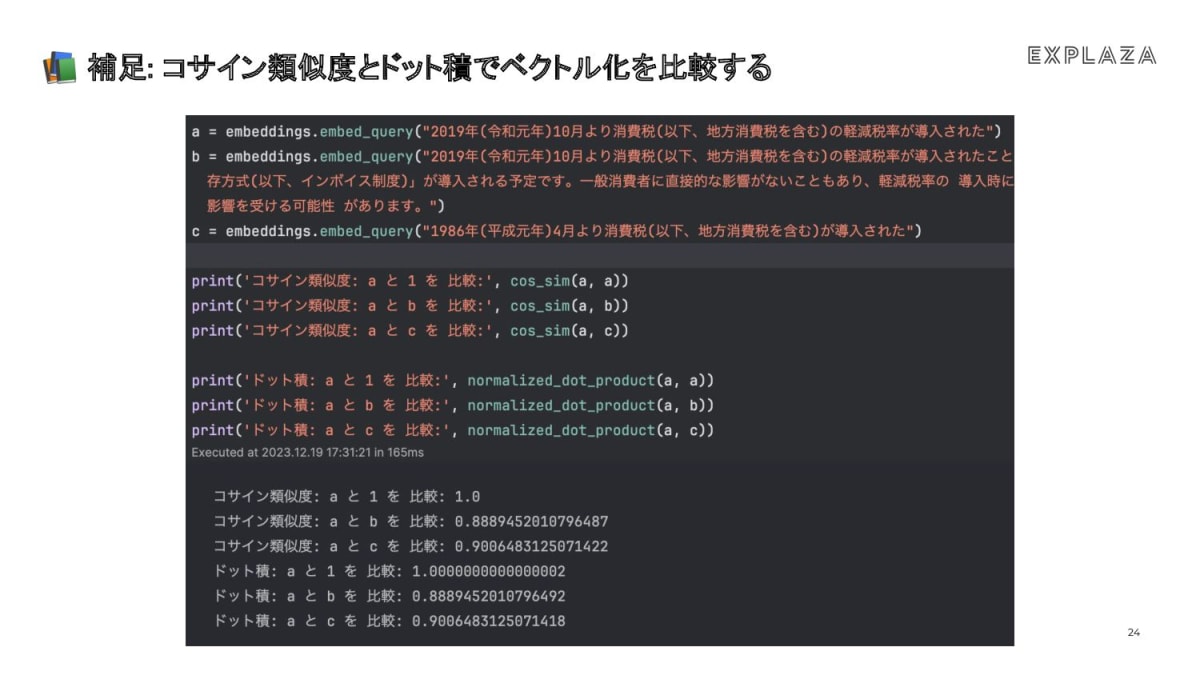

うおー、コード公開されていた!ありがたし!
Recursive Retrieverの実装は3パターンほどあるけど、今回のやつはNode Referenceというやつ。でnotebookはこれだな。
少し試してみた感想。
ということで後ほどまとめる
Recursive Retrieverの実装は3パターンほどあるけど、今回のやつはNode Referenceというやつ。でnotebookはこれだな。
のnotebookを全部やってみた。
- セクションごとのノード(一定のコンテキストを持ったチャンク)は以下でやって、センテンスごとに分割したサブノード(クエリに近しくなりやすいチャンク)を作って、recursive retreiverで検索させる。
- プロンプトはすべて日本語化
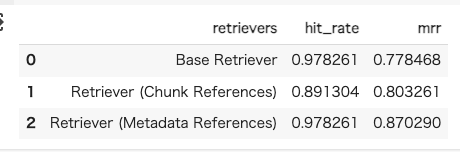
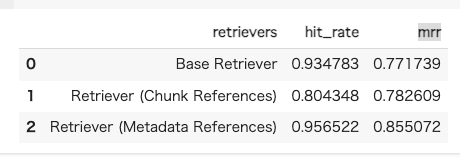
で、検索結果数ごとにretrievalの評価をやった。
top-10
top-5
top-3

top-2
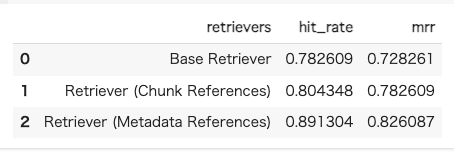
Recursive Retrieverを使わない素のBase Retrieverでも単純なヒット率は高いのは、今回は単純な文字数でのチャンク分割は行っておらず、セクション単位で一定のコンテキストを保持しているせいだと思う。500文字ぐらいのチャンクも比較としてやっとけばよかったな。。。
ただしヒット率の割にはMRRが他に比べても一番低くて、検索結果には含まれるが適切なものが上位に来ていないことが多いということになる。検索精度を上げるならば数を増やすしかないのだけど、LLMがそこから適切なコンテキストを選択してくれるか?によるし、検索数増やせばノイズが増えることにもなるし、あと入力トークンの上限を考えるとちょっと厳しい。多分このパターンで精度あげるならばRerankingが必要になりそう。
Recursive RetrieverのChunk Referencesは、数字だけ見ると期待したほどには上がらなかった。まあちょっと期待しすぎた面はある。セクションだと大きすぎてクエリとの類似性が離れていくので、より近しいだろう文単位ってのは納得できる根拠だと思ったので期待してたんだけどな。ただヒット率とMRRの差異が少なくて、件数を絞っても安定している感があるので、適切なものを拾ってくるという点で精度向上が見られていることになる。
ちなみに今回のケースでは、改行と文末の句読点をセパレータにして文章単位でサブノードを作ったけど、果たして文章単位が適切なのか?1文章がどこまでクエリのコンテキストに近しいか?という気はしてる。単純にクエリとノードの文字数合わせ、みたいな面があることは否めない。なので個々をどの単位で分割するか、ってのは試してみるのが良さそう。元のnotebookにあるみたいに、複数のチャンクサイズで分割してパターンを増やすってのもありかもしれない。
最後のMetadata Referenceっていうのは、詳細には見れてないんだけも、以下のサブノードを作って、セクションのノードに紐づけているっぽい。
- セクションごとのサマリー
- セクションごとに生成した質問
chunk referenceが、ノードを細かく分割することで実際のクエリに近づけるというアプローチなのに対して、metadata referenceは、クエリに近しくなるようなノードを既存のノードから生成・追加することで、実際のクエリに近づけるというアプローチっぽい。
ここでMetadataといっているのは、そのものズバリのメタデータのことではなく、付加的な情報をノードに紐付ける、ということなのだと思う。
でこれがヒット率もMRRも非常に高い。たぶんこれサマリよりも質問が効いているような気がする。なんていうか、結局クエリに一番近いのは、サマリよりも、文単位よりも、「質問」であるってのはそりゃそうって感じがする。ただこのパターンは質問がどれだけ揃えれるか?ってところに依存しそうな気もしている。なのでサマリみたいなものも含めているんだろうと思う。
クエリ自体のコンテキストは小さいのだけども、そこから適切な情報+付随する情報を引っ張ってきて、リッチな回答を返す、ってのがRAGに期待するところだと思うので、recursive retreiverのように、
クエリ(コンテキストや文字の量: 少)
↓
中間チャンク(コンテキストや文字の量: 少) # 検索に使用
↓
取得したいドキュメント(のチャンク)(コンテキストや文字の量: 大) # 生成のコンテキストに使用
検索に適した中間チャンクと、生成に適したドキュメントを分けて、やるというアプローチ自体は至極納得で、 いかに検索精度をあげるための中間チャンクを取り揃えれるか? ということになる気がした。
いっそnode referencesやmetadata referencesを全部ガッチャンコしても良いかもしれない。ベクトル検索に多少なりとも負荷が増えそう&どうしても一定の複雑性は増しそうで管理がめんどくさそうではあるけども(もはやGUIでデータ更新管理とかは無理になりそう)
あとは、セクションとかのコンテキスト的・セマンティック的な単位は、ある程度ボリュームが大きくなる面はある。入力トークンサイズとかは気になるし、会話履歴管理とかにも影響が出そう。
そしてLlamaIndexの会話履歴管理はちょっと機能的に乏しいのがネック。。。。
今度こそコードもまとめる。
改めて見るとほんと良くまとまってるな
以下のページはクエリ拡張のモチベーションとなっているけど、これが単純なRAGではうまくいかないっていうことの根本だと思う

なので、ここを寄せるために色々な手法があって、Recusive Retrieverはこれにあたるのだと思う

他にも手法がたくさんあるな、いろいろ試すべし