「ChatLLM.cpp」を試す
先日、llama.cppでTTSが使えるのを試した。
その際に、llama.cppをベースに、TTS特化で派生させたプロジェクトがあった。
あと、llama.cppの実装を元にした他のプロジェクトもある。
Orpheus TTS、OuteTTSをサポート
https://github.com/foldl/chatllm.cppParler TTS、Kokoro、Diaをサポート
https://github.com/mmwillet/TTS.cpp
あとはMeloTTSもあるな
llama.cpp本体では現時点(2025/05/30)ではOuteTTSのみがサポートされており、他のTTSについてはllama.cpp側の対応を待つか、上記のプロジェクトを使う必要がある。
今回は上記のうちChatLLM.cppを試す。先日試したTTS.cppと違って、こちらはTTS特化というわけではなさそう。
GitHubレポジトリ
日本語READMEがある
あなたのコンピュータ(CPU)でリアルタイムチャットを行うための、RAG 対応の多くのモデル(1B未満から300B以上)を推論するための純粋なC++実装です。@ggerganov の ggml に基づいています。
特徴
英語のREADMEの更新履歴を見るとテキストモデル以外にも色々サポートしているみたい。サポートされているモデルは以下に載っている(最新は適宜リンク先を確認)
テキストチャットのモデル以外だとこの辺に対応しているみたい。
TTSモデル
- Orpheus TTS
- 3B: EN、ZH など
SNAC-24kHzがコーデックとして使用されます。変換時には追加コマンドラインオプション--name Orpheus-TTS -a Orpheus-TTS --snac_model /path/to/snac_24kHzを使用してください。- OuteTTS
- 1.0: 1B、0.6B
DAC.speech.v1.0 1.5kbpsがコーデックとして使用されます。変換時には追加コマンドラインオプション--name OuteTTS -a OuteTTS --dac_model /path/to/dacを使用してください。マルチモーダルモデル
- Fuyu(
FuyuForCausalLM)
- Base: 8B
- Gemma(
Gemma3ForConditionalGeneration)
- v3: Instruct-4B、Instruct-12B、Instruct-27B
- MedGemma: Instruct-4B
注意:変換時はtokenizer.modelのみダウンロードし、tokenizer.jsonはダウンロードしないでください。RAGモデル
テキスト埋め込み(
XLMRobertaModel)
- BCE-Embedding
- BGE-M3(
-a BGE-M3)- MiniCPM-Embedding-Light
注:Dense embedding のみ実装済み。QAランキング(
XLMRobertaForSequenceClassification)
- BCE-ReRanker
- BGE-ReRanker-M3(
-a BGE-Reranker-M3)- MiniCPM-Reranker-Light
LoRAモデル
これらのLoRAモデルが動作確認済みです:
特殊モデル
Meta-AI multi-token prediction models チェックポイント
少なくとも1つのmulti-token predictionチェックポイント(例: 7B_1T_4)をダウンロードしてください。/path/to/llama-multi-predict/7B_1T_4に保存されていると仮定し、tokenizer.modelも/path/to/llama-multi-predictに保存されていることを確認してください。
-a llama-multi-token-prediction-ckptで変換するには次のようにします:python convert.py -i /path/to/llama-multi-predict/7B_1T_4 -o llama-multi.bin -a llama-multi-token-prediction-ckptこれはベースモデルなので
--format completionを忘れずに指定してください。
ヒント:--kv n_future_tokens Nで将来トークン数(N = [1, 4])を指定可能です。
モデルやモダリティごとにオプションが変わるようなので、新しいモデルなんかはここを見れば良さそう。
今回はMacでやってみる(M2 Pro)
レポジトリクローンして、サブモジュールも取得
git clone --recursive https://github.com/foldl/chatllm.cpp.git && cd chatllm.cpp
ビルド
cmake -B build
cmake --build build -j --config Release
build/binにあるmainがCLの実行ファイルになる。
ls -lt build/bin/main
-rwxr-xr-x@ 1 kun432 staff 3455864 5 30 09:25 build/bin/main
実行するだけなら上で良いようなのだけど、事前量子化済みモデルのダウンロードや量子化のためのスクリプトも用意されていてこれらはPython環境が必要なので、uvで作成。(バインディングを使う別コマンドがあるようだが後述)
uv init -p 3.12.9
依存ライブラリを追加
uv add -r requirements.txt
ではモデルのダウンロード。ダウンロード用のスクリプトはscripts/model_downloader.pyを使う。引数無しで実行するとダウンロードできるモデルの一覧が表示される。
uv run scripts/model_downloader.py
が出力が長いので抜粋
(snip)
**phi4**: Phi 4 is a 14B parameter, state-of-the-art open model from Microsoft.
License : MIT
Available: phi4:14b, phi4:mini
Default : phi4:14b
(snip)
-------
Total: 1.97 TB (203 models)
2025/05/30時点で203モデルあるみたい。
ダウンロードする際のモデル名の指定は :<model_id>[:<variant>[:<quantization>]] という書式で指定することができるみたい。パラメータサイズや量子化バージョンはオプションになっていて、選べる選択肢は scripts/models.jsonを見ればわかる。
今回はPhi-4-mini-instruct をダウンロードする。
uv run scripts/model_downloader.py -m :phi4:mini
ダウンロードが始まった。
downloading phi4:mini
|------------------------------------------------------------| 0.3%
完了
|████████████████████████████████████████████████████████████| 100.0%
['-m', '../quantized/phi-4-mini.bin']
モデルはどこや・・・と思ったら、一つ上のディレクトリにあった。
ls -l ../quantized/
total 7995520
-rw-r--r--@ 1 kun432 staff 4082416720 5 30 10:30 phi-4-mini.bin
これか・・・
モデルダウンロード時はscriptsディレクトリに移動してやったほうが良さそうね。
とりあえずmvした。
mv ../quantized .
気を取り直して推論。-mでモデル指定、-iでインタラクティブモードになる。
./build/bin/main -m quantized/phi-4-mini.bin -i
________ __ __ __ __ ___
/ ____/ /_ ____ _/ /_/ / / / / |/ /_________ ____
/ / / __ \/ __ `/ __/ / / / / /|_/ // ___/ __ \/ __ \
/ /___/ / / / /_/ / /_/ /___/ /___/ / / // /__/ /_/ / /_/ /
\____/_/ /_/\__,_/\__/_____/_____/_/ /_(_)___/ .___/ .___/
You are served by Phi-4, /_/ /_/
with 3836021760 (3.8B) parameters.
You >
適当に入力してみる。
You > 私の趣味は競馬なんですよ。
A.I. > こんにちは!競馬は非常に興味深い趣味です。あなたはレースを観戦したり、賭けをしたり、馬を飼っているのですか?またはそれらの一つ以上の側面を楽しんでいますか?あなたの経験についてもっと教えてください。私はここにいて、あなたの競馬の旅をサポートするためにここにいます。
You > 日本の総理大臣は誰?
A.I. > 2023年初頭の時点で、日本の総理大臣は岸田文雄です。彼は2021年10月4日に首相に就任しました。政治の役職は時期によって変わることがあるため、最新の情報を得るためには信頼できる情報源を確認することが重要です。
You > 私の趣味ってなんでしたっけ?
A.I. > 申し訳ありません。あなたが競馬を趣味としていることを尋ねたのは覚えているのですが、あなたの個人的な趣味についてさらに知りたいようでした。競馬以外にも楽しんでいるものはありますか?例えば読書、旅行、スポーツ、芸術など、あなたが特に楽しんでいる他の活動について教えてください。
Usageはこんな感じ。
./build/bin/main -h
Usage: ./build/bin/main [options]
Basic options:
-h, --help show this help message and exit [*]
-m, --model PATH model path
-p, --prompt PROMPT prompt to start generation with (default: 你好)
--prompt_file FN prompt from file
-s, --system SYSTEM system prompt (instruction) (default: model specific)
--sys_file FN system prompt (instruction) from file
--ai_prefix AI prefix for generation (default: empty)
-i, --interactive run in interactive mode [*]
--reversed_role AI becomes `user`, user becomes `AI` [#]
-l, --max_length N max total length including prompt and output (default: model specific)
generally, this is used to reduce KV cache size.
for models that does not show its max context window in `config.json`,
use this to enlarge it (use with caution!).
--layer_spec LAYERS select/redesign layers.
LAYERS=S0,S1,.... where S0/S1/... are like slices of Python, `start:stop[:step]`,
negative values in `start` and `stop` can be used referencing layers in reversed order,
`step` is optional, e.g.
--layer_spec 0:3,1:4 (3 + 3 = 6 layers are selected, layer #1/2 are used twice)
layer structure: 0->1->2->1->2->3
-c, --max_context_length N
max context length (default: 512)
--extending EXT context extending method (EXT = restart | shift | none)
(default: none if `--load_session` is specified, otherwise restart)
--multi enabled multiple lines of input [*]
when enabled, `\.` marks the end of your input.
--format FMT conversion format (model specific, FMT = chat | completion | qa) (default: chat)
Performance options:
-n, --threads N number of threads for inference (default: number of cores)
-ngl, --n_gpu_layers N number of model layers to offload to a backend device (GPU) (default: GPU not used)
N ::= one_spec;...
one_spec ::= [id:]spec, where spec ::= [n|epilog|prolog|all]
+moe_on_cpu alway use CPU for sparse operations (MoE) (default: off)
--rpc_endpoints EP.. RPC endpoints (i.e. servers) for distributed inference (default: empty)
EP1;EP2, where EP ::= host:port
--cache_dtype T cache data type, T ::= f32 | f16 (default: f16)
--batch_size N batch size (default: 4096)
note: trade-off between prompt throughput and memory usage.
--re_quantize Q re-quantize model weights during loading (Q ::= q8_0 | q4_0 | q4_1 | q4_k | ...) (default: no re-quantization)
note: it does not make sense to re-quantize to a larger size.
Sampling options:
--sampling ALG sampling algorithm (ALG = greedy | top_p | tfs) (default: top_p)
where, tfs = Tail Free Sampling
-t, --temp T temperature (default: 0.7) (Note: `-t 0` also sets sampling algorithm to greedy)
--top_k N top-k sampling (default: 20)
--top_p N top-p sampling (default: 0.7)
--tfs_z Z Z param for TFS (default: 0.95)
--presence_penalty N presence repetition penalty (default: 1.0, no penalty)
--seed N seed for random generator (default: random)
--beam_size N beam size for generation (default: -1, disabled)
functionality of beam search limited.
RAG options:
--set_vs_name set vector store name.
all following vector store files are merged into this vector store. (optional. default: `default`)
Note: command line RAG chat will always the first store.
--vector_store FILE append a vector store file (when RAG enabled, at lease one is required)
--embedding_model PATH embedding model path (when set, RAG is enabled)
--distance_strategy DS distance strategy (model dependent, default: MaxInnerProduct)
DS = EuclideanDistance | MaxInnerProduct | InnerProduct | CosineSimilarity
--retrieve_top_n N number of retrieved items using embedding model (default: 2)
--retrieve_rewrite_template ...
prompt template to ask LLM to rewrite a query for retrieving (optional).
(default: "", i.e. disabled, the original prompt is used for retrieving)
macros: {question}. this may NOT WORK. Example:
Extract keywords for querying: {question}
--reranker_model PATH reranker model path (optional)
--rerank_score_thres reranking score threshold (default: 0.35)
items with a lower score are discarded.
--rerank_top_n N number of selected items using reranker model (default: 1)
+rerank_rewrite reranker use the rewritten query (default: OFF, i.e. use the original user input)
--emb_rank_query_sep separator for embedding & rerank query (default: "", i.e. disabled)
only used without main model
--hide_reference do not show references (default: false) [*]
--rag_template ... prompt template for RAG (macros: {context}, {question}) (optional).
Support some C escape sequences (\n). Example:
Answer the question according to below information:
---
{context}
---
Question: {question}
--rag_context_sep context separator (default: '\n```\n')
Support some C escape sequences (\n).
--rag_post_extending N extend selected items with pre & post N chunks with same metadata. (default: 0)
this may be useful when context length of embedding/reranker models is limited.
+rag_dump (debug) dump retrieved/re-ranking results
CoT options:
+detect_thoughts turn on detection of thoughts in the output (default: OFF)
--thought_tags O C customize thought tags (Opening & Closing) to override built-in tags
built-in tags:
this options enables detection of thoughts implicitly.
Multi-model options:
--multimedia_file_tags OPENING CLOSING
multimedia file tags. Default: Not set. Example {{ }}: {{TAG:/path/to/image.png}}
where TAG ::= image | video | audio
--tts_export FILE save generated PCM samples into a file. (default: not save) [*]
Session:
--save_session N FILE save session to FILE after N round(s) of chatting (N >= 0) and quit [*]
when N = 0, system prompt is evaluated.
--load_session FILE load session from FILE [*]
Misc:
--init_vs FILE init vector store file from input [*]
--merge_vs FILE merge multiple vector store files into a single one [*]
--tokenize (debug) tokenize `prompt` and exit [*]
--test FILE test against inputs from a file and exit [*]
--hide_banner hide banner [*]
--show show model info and quit [*]
--show_devices show info about backends and devices, then quit [*]
--dump_dot FILE dump sched splits to a DOT file, and exit with -1
--log_level log level. (default: 4 - ERROR)
--serve_rpc [H:]P[@id] as a RPC server on host:port (optional: host default to 127.0.0.1, id defaults to 0) [#]
--ggml_dir DIR specify directory of GGML
--set KEY VALUE set a pair of additional args.
Additional key-value args:
--kv start of additional args. all following options are interpreted as k-v pairs
key value a key-value pair of args
------------------------
*: implemented by front end (i.e. `main.cpp` or apps using bindings)
#: implemented by front end & backend
ところでQuickstartを見ると、mainというCLI 以外にmain_nimというCLIもある様子。
main_nim だとモデルを指定するだけで自動的にダウンロードが行われるようになっているみたい。ちなみにこのCLIコマンドはNimで書かれているみたい。知らなかった。
でこれを使うにはバインディングをビルドする必要がある。
cmake --build build --target libchatllm
(snip)
/Users/kun432/work/chatllm.cpp/src/main.cpp:1366:5: error: constructor for 'Chat' must explicitly initialize the member 'history' which does not have a default constructor
1366 | Chat():
| ^
(snip)
7 warnings and 1 error generated.
make[3]: *** [CMakeFiles/libchatllm.dir/src/main.cpp.o] Error 1
make[2]: *** [CMakeFiles/libchatllm.dir/all] Error 2
make[1]: *** [CMakeFiles/libchatllm.dir/rule] Error 2
make: *** [libchatllm] Error 2
うーん、ここo3とかに聞いて直せるものかを見てみたんだけど、ちょっと自分の手には追えなかった。
バインディングを有効にすると、StreamlitのWebUIやOpenAI互換APIサーバも建てれるようなので、なんとかビルドしたい・・・・
とりあえずIssueあげた→回答が来てて修正されてた。詳細は一番下。
TTS
ということで本題のTTS。ChatLLM.cppではOuteTTSとOrpheus TTSに対応している。まずは両方のモデルをダウンロード。そこそこ時間がかかる。
cd scripts
uv run model_downloader.py -m :oute-tts
uv run model_downloader.py -m :orpheus-tts
OuteTTS
では推論。OuteTTSから。
./build/bin/main -m quantized/oute-tts-1b.bin \
-p "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races."
ffplayが起動してその場で再生される。再生しつつ、ファイルに出力する場合は--tts_exportを使う。
./build/bin/main -m quantized/oute-tts-1b.bin \
-p "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races." \
--tts_export output.pcm
出力を見ているとどうやらPCM S16LE・24 kHz・モノラルで出力されるようなので、ファイルを再生する場合は以下。
ffplay -autoexit -f s16le -ch_layout mono -sample_rate 24000 output.pcm
余談だがWAVへ変換
ffmpeg -f s16le -ch_layout mono -sample_rate 24000 -i output.pcm output.wav
生成されたもの。
オプションがほとんど無いので音声変えたり音声リファレンスとかどうすればいいんだろう?
Orpheus TTS
次にOrpheus TTS。こちらは非言語タグが使える。
./build/bin/main -m quantized/orpheus-tts-en-3b.bin \
-p "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races <chuckle>." \
--tts_export output.pcm
こちらも音声の変え方がわからない。
なお、自分でGGUF変換する場合にはそれぞれのモデルが使用しているコーデックも必要になる。
2025/06/06追記
どうやら音声を指定する事ができるようになったみたい。
OuteTTSの場合は話者プロファイルのJSONファイルが必要になるが、これOuteTTS公式で配布されてるんだっけか?OuteTTSでプロファイルの出力はできるみたいなので、自分で作成しないといけないかも。
./build/bin/main -m quantized/oute-tts-1b.bin \
-p "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races." \
--set speaker some_speaker.json
Orpheus TTSの場合は用意された話者名を指定すれば良いみたい。
./build/bin/main -m quantized/orpheus-tts-en-3b.bin \
-p "Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races <chuckle>." \
--set voice tara
まとめ
Orpheus TTSが使えるってのが一番だよね。ただ、オプションの指定方法がさっぱりわからない・・・
llama.cpp公式の対応を待つほうがいいかな、ここで実装できているならできるだろうし。
バインディングのビルドがコケる件は修正されていた。
ということで一旦再ビルド、ただしmasterの最新(0180f53)だとどうやら別の不具合があったので、上記の修正コミット(fce641d)を使う。レポジトリはイチからクローンし直した。
git clone --recursive https://github.com/foldl/chatllm.cpp.git chatllm.cpp.fix && cd chatllm.cpp.fix
git submodule update --init --recursive
git checkout fce641d
cmake -B build
cmake --build build -j --config Release
バインディングのビルド
cmake --build build --target libchatllm
いけたー
(snip)
3 warnings generated.
[100%] Linking CXX shared library /Users/kun432/work/chatllm.cpp.fix/bindings/libchatllm.dylib
[100%] Built target libchatllm
これで、
-
main_nimを使ったオンデマンドなモデルのダウンロードとチャット - StreamlitのWebUI
- OpenAI互換APIサーバ
が動かせるようになるはず。
ということでやってみる。
main_nimを使ったオンデマンドなモデルのダウンロードとチャット
nimを事前にインストールする必要がありそう。MacだとHomebrewでインストールできる。
brew install nim
bindingsDirectoryに移動してコンパイル。nim全然わかってないけど多分こんな感じ。-d:sslをつけないとモデルダウンロード時にHTTPSが使えなかった。
cd bindings
nim c -d:ssl -d:release main.nim
Hint: used config file '/opt/homebrew/Cellar/nim/2.2.4/nim/config/nim.cfg' [Conf]
Hint: used config file '/opt/homebrew/Cellar/nim/2.2.4/nim/config/config.nims' [Conf]
..................................................................................................................................................................
Hint: [Link]
Hint: mm: orc; threads: on; opt: speed; options: -d:release
82865 lines; 0.749s; 175.809MiB peakmem; proj: /Users/kun432/work/chatllm.cpp.fix/bindings/main.nim; out: /Users/kun432/work/chatllm.cpp.fix/bindings/main [SuccessX]
mainがコンパイル後の実行ファイルになる。
ls -lt main
-rwxr-xr-x@ 1 kun432 staff 688536 6 6 15:10 main
では、試してみる。まだダウンロードしていないGemma3を指定
./main -i -m :gemma3
お、ダウンロードされてる。
Downloading gemma3
gemma3 |██----------------------------------------------------------| 3.9%
ダウンロードが完了するとそのまま使える
Downloading gemma3
|████████████████████████████████████████████████████████████| 100.0% 00.0%
________ __ __ __ __ ___
/ ____/ /_ ____ _/ /_/ / / / / |/ /_________ ____
/ / / __ \/ __ `/ __/ / / / / /|_/ // ___/ __ \/ __ \
/ /___/ / / / /_/ / /_/ /___/ /___/ / / // /__/ /_/ / /_/ /
\____/_/ /_/\__,_/\__/_____/_____/_/ /_(_)___/ .___/ .___/
You are served by Gemma-3, /_/ /_/
with 3880263168 (3.9B) parameters.
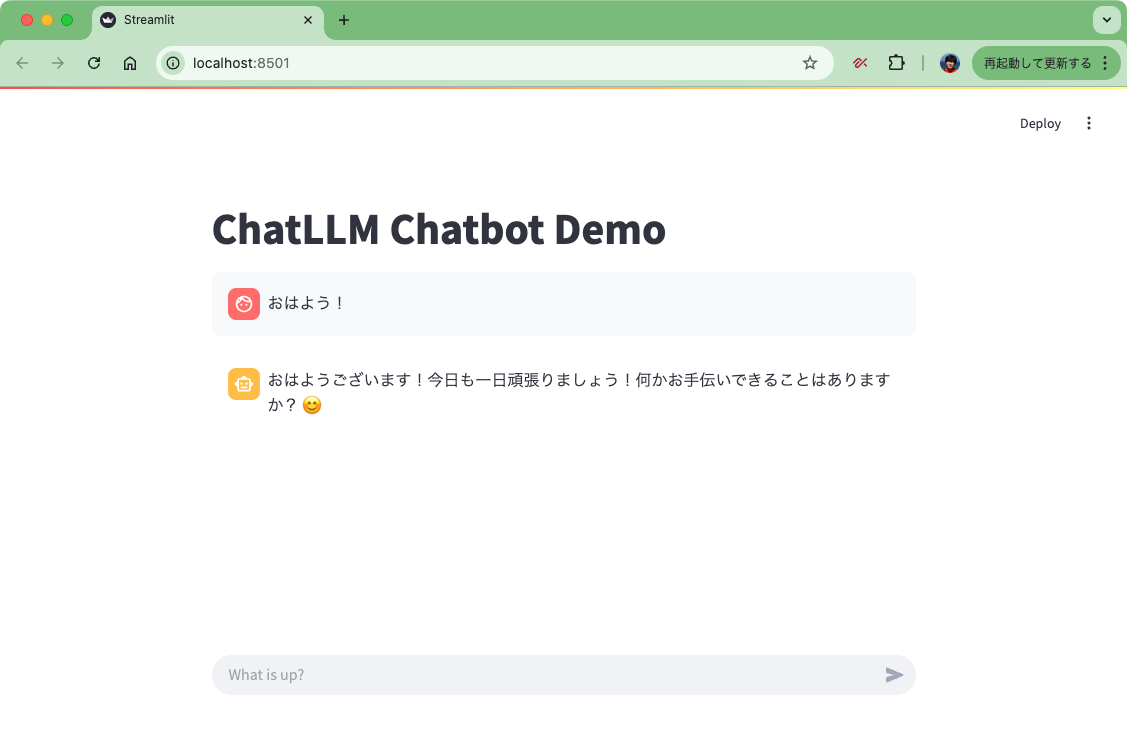
You > おはよう!
A.I. > おはようございます!今日も一日頑張りましょう!何かお手伝いできることはありますか? 😊
You >
StreamlitのWebUI
クローンしたレポジトリのルートで
uv init -p 3.12.9
uv add -r requirements.txt
streamlitをインストール
uv add streamlit
scriptsディレクトリに移動
cd scripts
streamlitで起動
uv run streamlit run chatllm_st.py -- -i -m :gemma3
OpenAI互換APIサーバ
同じくscriptsディレクトリ内で。モデルの指定するオプションはハイフン3つってのがクセモノなのと、あと、チャットとコード補完(---fim)でそれぞれモデルを指定できるみたい。コード補完の場合はそれに対応したベースモデルを選択する必要があるらしい。
uv run openai_api.py ---chat :gemma3
のだが、openai_api.py の中身を覗くと、
(snip)
http_server = HTTPServer(('0.0.0.0', 11434), HttpHandler)
http_server.serve_forever()
11434番ポートは、自分の環境ではOllamaとバッティングしていたので、これを別のポートに変える。今回は11435にした。
起動してみると、以下となって起動完了しているかどうかがわかりにくいのだが、起動しているっぽい。
{'chat': {'active_param_num': 3880263168, 'capabilities': ['Text'], 'context_length': 131072, 'name': 'Gemma-3-3.9B', 'param_num': 3880263168, 'purpose': 'Chat'}}
LLM Loaded. Starting server...
エンドポイントの最後が /completions で終わっていればチャットモデル、/generate ならコード補完モデルが選択されるらしい。
curl http://localhost:11435/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Gemma-3-3.9B",
"messages": [
{
"role": "system",
"content": "あなたは親切な日本語のアシスタントです。"
},
{
"role": "user",
"content": "こんにちは!"
}
]
}' | jq -r .
{
"id": "_chatllm_4",
"created": 1749193013,
"model": "Gemma-3-3.9B",
"choices": [
{
"delta": {
"role": "assistant",
"content": "こんにちは!何かお手伝いできることはありますか? 😊\n"
},
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"object": "chat.completion.chunk",
"system_fingerprint": "fp_xxx"
}
ということで一旦再ビルド、ただしmasterの最新(
0180f53)だとどうやら別の不具合があったので、上記の修正コミット(fce641d)を使う。レポジトリはイチからクローンし直した。
git clone --recursive https://github.com/foldl/chatllm.cpp.git chatllm.cpp.0180f53 && cd chatllm.cpp.0180f53
git submodule update --init --recursive
git log --oneline | head -1
0180f53 more xxxx_penalty options
cmake -B build
cmake --build build -j --config Release
ちょっとダウンロードは手間なので、すでにダウンロード済みのモデルを持ってくる
cp -pir ../chatllm.cpp/quantized .
./build/bin/main -i -m ./quantized/gemma-3-4b-lm.bin
________ __ __ __ __ ___
/ ____/ /_ ____ _/ /_/ / / / / |/ /_________ ____
/ / / __ \/ __ `/ __/ / / / / /|_/ // ___/ __ \/ __ \
/ /___/ / / / /_/ / /_/ /___/ /___/ / / // /__/ /_/ / /_/ /
\____/_/ /_/\__,_/\__/_____/_____/_/ /_(_)___/ .___/ .___/
You are served by Gemma-3, /_/ /_/
with 3880263168 (3.9B) parameters.
You > おはよう!
A.I. > おはようございます!今日も一日頑張りましょう!何かお手伝いできることはありますか? 😊
Trace/BPT trap: 5
1ターン目で終了してしまう・・・・これもIssue上げておいた。
けど環境依存かなぁ・・・という感じ。Linuxだと起きないけど、Macでだけ起きる。