Soniox の Speech-to-Text を試す
ここで見つけた
公式サイト
ググっても日本語で紹介している記事がまったくないのだが、どうやら正確性・高速性がウリのASRサービスみたい。以下でデモが試せる
新幹線のアナウンスを試してみたのだが、完璧。しかも認識がかなり速い。

以下にベンチマークがある。
比較対象のモデルは以下
| プロバイダー | モデル |
|---|---|
| Soniox | stt-async-preview |
| OpenAI | Whisper large-v3 |
long (サポート対象言語の場合)chirp_2 (他の言語の場合) |
|
| AWS | Best/Default |
| Azure | Best/Default |
| NVIDIA |
conformer-{lang}-asr-offline-asr-bls-ensemble (サポート対象言語の場合)parakeet-1.1b-unified-ml-cs-universal-multi-asr-offline-asr-bls-ensemble(他の言語の場合) |
| Deepgram |
nova-3 (英語の場合)nova-2 (他の言語の場合) |
| AssemblyAI |
best (サポート対象言語の場合)nano (他の言語の場合) |
| Speechmatics | enhanced |
| ElevenLabs | scribe_v1 |
日本語と英語を抜粋(WER)
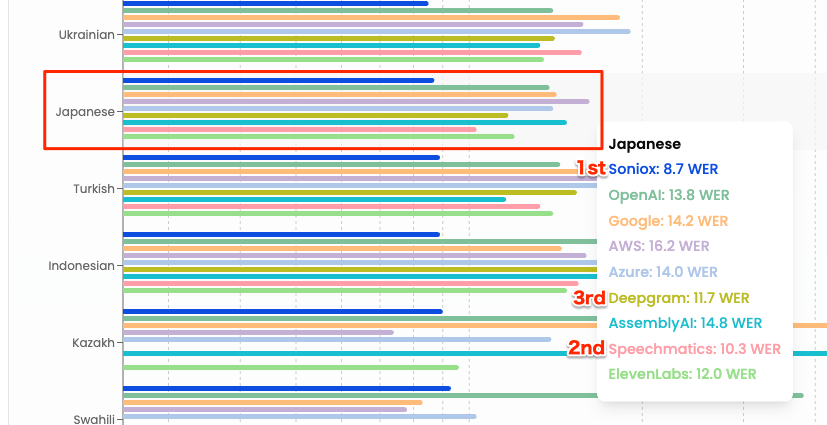

過去、自分が日本語で試した感じだと、ElevenLabsのScribeが一番良いと感じていたのだけど、Scribeはリアルタイムのストリーミング文字起こしに対応していないのと、一般的にはファイルからの文字起こしに比べるとリアルタイムは精度が落ちると思っている。その上で、ベンチ結果と上のデモの印象を踏まえると、かなり期待できそうな気がした。
料金はめちゃめちゃシンプル
- 非同期ファイル: $0.10/時間 ≒ $0.0016/分
- リアルタイム文字起こし: $0.12/時間 ≒ $0.002/分
過去自分が調べたものと比較しても最安クラスでは?
で、無料アカウントを作成すると$200のAPIクレジットがもらえるみたい。
これはちょっと試してみよう。
アカウント作成するとダッシュボードはこんな感じ

支払い方法は設定していなくても$200のクレジットが付いている
プレイグラウンドでは、ダッシュボード上で、WebSocketを使ったリアルタイム文字起こし・REST APIを使ったファイルの文字起こしが試せる


APIキーを作成しておく


ファイルの文字起こし
ではGet Startedに従って進める。今回はローカルのMac上で。
まずファイルの文字起こしから。
Python仮想環境を作成。
uv init -p 3.12.9 soniox-work && cd soniox-work
uv venv
Sonioxでは、一般的なREST APIやWebSocket APIでAPIを提供しており、専用のSDKなどは存在しない。今回はrequestsを使う。loguruは処理時間などをログで見たかったので追加した。
uv add requests loguru
ファイルの文字起こしは、ローカルファイルパスとURLで指定できるが、今回はローカルファイルで。自分が過去に開催した勉強会のYouTube動画から冒頭5分程度の音声を抜き出したをサンプルとして使う。
ファイルからの文字起こしは非同期で行われる。文字起こしをリクエストするとIDが返されるので、このIDのステータスをポーリングして結果が出るまで待つ。
APIキーを環境変数にセット
export SONIOX_API_KEY="XXXXXXXXX"
スクリプトはこんな感じ
import os
import time
import requests
import sys
from loguru import logger
# APIキーを環境変数から取得(SONIOX_API_KEYがセットされていること)
api_key = os.environ["SONIOX_API_KEY"]
api_base = "https://api.soniox.com"
file_to_transcribe = "voice_lunch_jp_5min.wav"
session = requests.Session()
session.headers["Authorization"] = f"Bearer {api_key}"
# 文字起こしが完了するまでポーリングする関数
def poll_until_complete(transcription_id):
while True:
res = session.get(f"{api_base}/v1/transcriptions/{transcription_id}")
res.raise_for_status()
data = res.json()
if data["status"] == "completed":
return
elif data["status"] == "error":
raise Exception(
f"文字起こしに失敗しました: {data.get('error_message', 'Unknown error')}"
)
time.sleep(1)
def main():
logger.info("ファイルをアップロードします...")
res = session.post(
f"{api_base}/v1/files",
files={
"file": open(file_to_transcribe, "rb"),
},
)
file_id = res.json()["id"]
logger.info(f"ファイルID: {file_id}")
logger.info("文字起こしを開始します...")
res = session.post(
f"{api_base}/v1/transcriptions",
json={
"file_id": file_id,
"model": "stt-async-preview",
"language_hints": ["ja", "en"],
},
)
res.raise_for_status()
transcription_id = res.json()["id"]
logger.info(f"文字起こしID: {transcription_id}")
poll_until_complete(transcription_id)
# 文字起こし結果を取得
res = session.get(f"{api_base}/v1/transcriptions/{transcription_id}/transcript")
res.raise_for_status()
logger.info("文字起こし: {}", res.json()["text"])
# 文字起こし結果を削除
res = session.delete(f"{api_base}/v1/transcriptions/{transcription_id}")
res.raise_for_status()
# ファイルを削除
res = session.delete(f"{api_base}/v1/files/{file_id}")
res.raise_for_status()
if __name__ == "__main__":
main()
実行
uv run transcribe_from_file.py
2025-05-25 00:57:56.168 | INFO | __main__:main:35 - ファイルをアップロードします...
2025-05-25 00:58:08.087 | INFO | __main__:main:44 - ファイルID: 4bee7eff-5f38-45b8-b079-75368e99bda6
2025-05-25 00:58:08.087 | INFO | __main__:main:46 - 文字起こしを開始します...
2025-05-25 00:58:08.321 | INFO | __main__:main:58 - 文字起こしID: a2bfe68f-9693-4673-a093-0151fb082c35
2025-05-25 00:58:15.877 | INFO | __main__:main:65 - 文字起こし: はい、じゃあ始めます。ちょっとまだ来られてない方もいらっしゃるんですけど、ボイスランチJP始めます。皆さん、日曜日。はい、はい、日曜日にお集まりいただきましてありがとうございます。(snip)
7秒程度で文字起こし結果が生成された。結果は以下
はい、じゃあ始めます。ちょっとまだ来られてない方もいらっしゃるんですけど、ボイスランチJP始めます。皆さん、日曜日。はい、はい、日曜日にお集まりいただきましてありがとうございます。えっと、今日久しぶりにですね、オフラインということで、えっと、今日はですね、スペシャルなゲストをお2人来ていただいております。ということではい、えっと、今日ちょっとトピックにもありますけれども、えっと、ボイスローのCEOであるブレデンリームさんと、あと、えっと、セールスフォースのえっと、カムセジダデザインのディレクターであるグレックベネスさんに来ていただいてます。ということで、日本に来ていただいてありがとうございました。はい、で、今日はちょっとこのお2人にまた後で色々と聞こうというえっと、コーナーがありますので、えっと、そこでまた色々と聞きたいと思います。で、今日のアジェンダなんですけども、えっと、ちょっと時間過ぎちゃいましたが、まず最初にボイスランチJPについてっていうところと、あと会場のとこですね、少しこれ説明させていただいて、1つ目のセッションで、えっと、まず私の方からえっと、ボイスロの2022年のえっと、新機能とかですね、その辺の話を少しさせていただいて、その後、えっと、2つ目のセッションで、えっと、ブレデンさんとグルさんに色々カンバセーショナルデザインですねについて何でも聞こうぜみたいなところを予定しております。で、その後、15時から、えっと、15時で一旦は終了という形でさせていただいて、ちょっと一応ボイスランチJP確か記念撮影は必須ですよね。なので、それだけさせていただいて、その後ちょっと1時間ぐらい、あの、簡単にあの、お菓子と飲み物を用意してますので、懇親会というのをそのままさせていただこうと思っています。で、えっと、ボイスランチJPについてなんですけども、えっと、ボイスランチはボイスUIとか音声関連ですね、そういった技術に、えっと、実際に携わってる人、もしくは興味がある人たちのためのグローバルなコミュニティという形になっていて、えっと、ボイスランチのえっと、日本リージョンという形がボイスランチJPになってます。で、えっと、過去もまずっとやってますけど、オンラインオフラインでいろんな音声のえっと、デザインだったり技術だったりっていうところで情報とかを共有して、みんなで業界盛り上げていこうぜというようなことでやっております。で、今日のえっと、ハッシュタグですね、えっと、シャープボイスランチJPで色々と自分に付き合してください。で、あと会場ですね、えっと、今回、えっと、グラニカ様のご行為で利用させていただいてます。ありがとうございます。で、是非こちらもシェアをお願いしたいです。と、で、今日と配信のところも色々とやっていただいてますので、非常に感謝しております。で、ちょっと今、あの、ごめんなさい、抜けた。今、あの、えっと、コロナで、えっと、会場に来られる方とかもあまりいないということでされてないんですけれども、あの、通常はなんかここでIoT機器のとかガジェットとかを展示されているようなので、えっと、そういったものがある時、今度ですね、また体験してみていただければなと思っています。というとこで、あとすいません、えっと、トイレがこちらで、あとタバコ吸われる方はこちらのところになってますんで、よろしくお願いします。はい、ということで最初の挨拶はこれで、じゃあまず私の方のセッションからさせていただきます。というとこで、ボイスローアップデート2022というところで、えっと、今年の新機能について少しお話をします。えっと、自己紹介です。えっと、清水と申します。えっと、神戸でインフラのエンジニアをやってましたので、えっと、普段はクバネテスとかエラベスとかテラフォンとかをいじってまして、最近ちょっとフリーランスになります。で、えっと、ちょっと調べてみたらボイスフローを1番最初に始めたのが2019年の頭ぐらいなんで、大体4年弱ぐらいですね、色々と触ってまして、あと、えっと、音声関連のコミュニティのとこでは、えっと、ボイスランチJP、今回のやつですね、え、以外に、えっと、AJAG、Amazon、Alexa、Japanユーザーグループとか、あと、えっと、ボイスローの、えっと、日本語ユーザーグループということでVFJUGっていうのをやっています。はい、えっと、日本語コミュニティの方はFacebookの方で、えっと、やってますので、もしよろしければ見ていただければなと思います。と、あと2年ぐらい前にですね、えっと、技術書店の方で、ここに今日スタッフで来ていただいてる皆さんとですね、一緒にあの、同人誌作ろうぜということで、えっと、作ったんですけれども、もうこれちょっと2年ぐらい経って中身がだいぶ古くなってしまっているので、すでにちょっと販売は終了しております。今日ちょっと持ってきたかったんですけど、すいません、忘れてしまいました。はい、なのでこういうこともやっています。
固有名詞などは上手く文字起こしできてないところがあるし、漢字の間違いもあるけど、なんだろう、発話を「発話どおりに確実に」に文字起こししようとしている印象かな。悪くない、というかいいね、個人的には好印象。
リアルタイム文字起こし
次にストリーミングを使ったリアルタイムな文字起こし
ただ上記のドキュメントにある例は、動画ファイルをURLで指定してて、かつ、そのホスト先がストリーミングに対応していると思われる・・・もう少しローカルでシンプルにやりたい。
以下にサンプルコードが多数あった。というか各言語ごとにリアルタイムだけじゃなくていろいろあるのでこちらを見るのが良さそう。
ファイルからのリアルタイム文字起こし(stream_file.py)のサンプルはこんな感じ。WebSocketで接続して、ファイルをチャンク分割して順次送信する形。
import json
import os
import threading
import time
from websockets import ConnectionClosedOK
from websockets.sync.client import connect
# APIキーを環境変数から取得(SONIOX_API_KEYがセットされていること)
api_key = os.environ.get("SONIOX_API_KEY")
websocket_url = "wss://stt-rt.soniox.com/transcribe-websocket"
file_to_transcribe = "voice_lunch_jp_5min.wav"
def stream_audio(ws):
"""
WAVファイルの音声データをWebSocketに送信する
WAVファイルにはヘッダが含まれているため、ヘッダをスキップして生のPCMデータを送信する
"""
with open(file_to_transcribe, "rb") as fh:
# WAVヘッダをスキップ(標準WAVの場合は44バイト)
fh.seek(44)
while True:
data = fh.read(3840) # チャンクサイズは公式のサンプルにあわせた
if len(data) == 0:
break
ws.send(data)
time.sleep(0.12) # 120msスリープ
ws.send("") # ストリームの終了を通知
def main():
print("WebSocket接続を開始...")
with connect(websocket_url) as ws:
# 開始リクエストを送信
ws.send(
json.dumps(
{
"api_key": api_key,
"audio_format": "pcm_s16le", # 使用するWAVファイルに合わせて設定
"sample_rate": 16000, # 使用するWAVファイルに合わせて設定
"num_channels": 1, # 使用するWAVファイルに合わせて設定
"model": "stt-rt-preview",
"language_hints": ["ja", "en"],
}
)
)
# 音声ストリーミングをバックグラウンドで開始
threading.Thread(target=stream_audio, args=(ws,), daemon=True).start()
print(f"文字起こしを開始: {file_to_transcribe}")
final_text = ""
try:
while True:
message = ws.recv()
res = json.loads(message)
if res.get("error_code"):
print(f"エラー: {res['error_code']} - {res['error_message']}")
break
non_final_text = ""
for token in res.get("tokens", []):
if token.get("text"):
if token.get("is_final"):
final_text += token["text"]
else:
non_final_text += token["text"]
print(
"\033[2J\033[H" # 画面をクリアして、左上に移動
+ final_text # 確定テキスト(白色)を表示
+ "\033[34m" # 青色に変更
+ non_final_text # 暫定テキスト(緑色)
+ "\033[39m" # 色リセット
)
if res.get("finished"):
print("\n文字起こし完了")
break
except ConnectionClosedOK:
pass
except KeyboardInterrupt:
print("\nユーザにより中断されました")
except Exception as e:
print(f"エラー: {e}")
if __name__ == "__main__":
main()
WebSocketsパッケージを追加
uv add websockets
実行
uv run stream_file.py
実際はこんな感じで動く。
緑が中間認識で白が最終認識なんだけど、まあ中間→最終になるまでの時間は他プロバイダとそんなに違いはないかなぁという気がする。ただ、個人的な印象かもしれないけど、中間→最終で修正される頻度がそんなに高くない気もする。ここは
- 中間認識の精度が高い→最終認識で修正する必要がない
- 中間認識→最終認識でも修正できない(基本的な精度の問題)
の両方が考えられるのだけどどうかな?ざっと見ていた限り、中間認識の精度が結構高い気がするので、それをそのまま使えるならかなり高速な文字起こしができるのではないかという気がしている(一般的には中間認識は最終認識に比べると高速だけど精度が低く、都度修正されたりする)。デモサイト見ててもあのレスポンスは中間認識を表示しているんじゃないか?という気がするしね。
マイクからのリアルタイム文字起こしも。PyAudioを使う。
uv add pyaudio
サンプルコード
import asyncio
import json
import websockets
import pyaudio
import threading
import queue
import signal
import sys
import os
from loguru import logger
# APIキーを環境変数から取得(SONIOX_API_KEYがセットされていること)
api_key = os.environ.get("SONIOX_API_KEY")
websocket_url = "wss://stt-rt.soniox.com/transcribe-websocket"
# オーディオ設定。マイク設定に合わせて変更
SAMPLE_RATE = 16000
CHANNELS = 1
SAMPLE_WIDTH = 2 # 16bit = 2bytes
CHUNK_SIZE = 3840 # 公式サンプルと同じ
# グローバル変数
audio_queue = queue.Queue()
stop_recording = threading.Event()
def audio_callback():
"""マイクから音声データを取得してキューに追加"""
p = pyaudio.PyAudio()
try:
# マイクストリーム開始(デフォルトデバイス使用)
stream = p.open(
format=pyaudio.paInt16,
channels=CHANNELS,
rate=SAMPLE_RATE,
input=True,
frames_per_buffer=CHUNK_SIZE
)
logger.info(f"マイク録音開始 (デフォルトデバイス, {SAMPLE_RATE}Hz, {CHANNELS}ch)")
print(f"録音開始 - Ctrl+Cで停止")
print("=" * 60)
while not stop_recording.is_set():
try:
# 音声データ読み取り
data = stream.read(CHUNK_SIZE, exception_on_overflow=False)
audio_queue.put(data)
except Exception as e:
logger.error(f"音声読み取りエラー: {e}")
break
except Exception as e:
logger.error(f"マイクストリーム開始エラー: {e}")
print(f"マイクエラー: {e}")
finally:
if 'stream' in locals():
stream.stop_stream()
stream.close()
p.terminate()
logger.info("マイク録音終了")
async def transcribe_microphone():
"""マイクからの音声をリアルタイム文字起こし"""
try:
# WebSocket接続
async with websockets.connect(websocket_url) as websocket:
logger.info("WebSocket接続成功")
# 文字起こし設定送信
config = {
"api_key": api_key,
"audio_format": "pcm_s16le",
"sample_rate": SAMPLE_RATE,
"num_channels": CHANNELS,
"model": "stt-rt-preview",
"language_hints": ["ja", "en"],
}
await websocket.send(json.dumps(config))
logger.info("文字起こし設定送信完了。発話を開始してください。")
print("=" * 60)
# 音声送信タスク
async def send_audio():
while not stop_recording.is_set():
try:
# キューから音声データ取得(タイムアウト付き)
data = audio_queue.get(timeout=0.1)
await websocket.send(data)
# 120ms間隔でスリープ
await asyncio.sleep(0.12)
except queue.Empty:
continue
except Exception as e:
logger.error(f"音声送信エラー: {e}")
break
# 終了信号送信
try:
await websocket.send("")
logger.info("終了信号送信")
except:
pass
# 結果受信タスク
async def receive_results():
while not stop_recording.is_set():
try:
response = await asyncio.wait_for(websocket.recv(), timeout=1.0)
result = json.loads(response)
# エラーチェック
if result.get("error_code"):
logger.error(f"文字起こしエラー: {result['error_code']} - {result['error_message']}")
print(f"エラー: {result['error_code']} - {result['error_message']}")
break
# 文字起こし結果処理
if "tokens" in result and result["tokens"]:
final_text = ""
non_final_text = ""
for token in result["tokens"]:
if token.get("text"):
if token.get("is_final"):
final_text += token["text"]
else:
non_final_text += token["text"]
if final_text:
logger.info(f"最終: {final_text}")
if non_final_text:
logger.info(f"\033[32m中間: {non_final_text}\033[0m")
# 文字起こし完了チェック
if result.get("finished"):
print("文字起こし完了")
break
except asyncio.TimeoutError:
continue
except websockets.exceptions.ConnectionClosedOK:
logger.info("WebSocket正常終了")
break
except Exception as e:
logger.error(f"結果受信エラー: {e}")
break
# 並行実行
await asyncio.gather(
send_audio(),
receive_results(),
return_exceptions=True
)
except websockets.exceptions.ConnectionClosedError as e:
logger.error(f"WebSocket接続エラー: {e}")
print(f"接続エラー: {e}")
if hasattr(e, 'code') and e.code == 1002:
print("APIキーを確認してください")
except Exception as e:
logger.error(f"文字起こしエラー: {e}")
print(f"文字起こしエラー: {e}")
def signal_handler(signum, frame):
"""Ctrl+C処理"""
print(f"\n停止信号受信...")
stop_recording.set()
async def main():
"""メイン処理"""
# シグナルハンドラー設定
signal.signal(signal.SIGINT, signal_handler)
# 音声録音スレッド開始
audio_thread = threading.Thread(target=audio_callback, daemon=True)
audio_thread.start()
# 少し待ってから文字起こし開始
await asyncio.sleep(0.5)
try:
# リアルタイム文字起こし実行
await transcribe_microphone()
finally:
# 終了処理
stop_recording.set()
audio_thread.join(timeout=2.0)
print("\n文字起こし終了")
if __name__ == "__main__":
# ログ設定
logger.remove()
logger.add(sys.stderr, level="INFO", format="{time:HH:mm:ss.SSS} | {level} | {message}")
try:
asyncio.run(main())
except KeyboardInterrupt:
print("\nユーザーによる停止")
except Exception as e:
logger.error(f"予期しないエラー: {e}")
print(f"エラー: {e}")
なるほど、中間認識がめちゃめちゃ速くて、最終認識までのタイムラグが結構あるんだな。ただ、上でも書いたけど、中間認識の精度は結構良いのではないだろうか。あと、最終認識結果も前方から順次・・・って感じなんだな。中間認識結果を使って高速化するにはいろいろ工夫が必要かな。
中間認識結果と最終認識結果については以下にドキュメントがある
トークンのバッファに中間認識が積み上がっていって、最終認識になったらバッファがクリアされる、という風に見えるけど、中間認識結果が一気に最終認識結果になるのではなく、部分的に最終認識結果になって、最終認識結果になったトークンは次からは返されない、って感じ。
11:52:18.624 | INFO | 中間: お
11:52:18.865 | INFO | 中間: おは
11:52:18.865 | INFO | 中間: おはよう
11:52:19.103 | INFO | 中間: おはようご
11:52:19.342 | INFO | 中間: おはようござ
11:52:19.343 | INFO | 中間: おはようござい
11:52:19.581 | INFO | 中間: おはようございま
11:52:19.582 | INFO | 中間: おはようございます
11:52:19.827 | INFO | 中間: おはようございます。
11:52:21.026 | INFO | 中間: おはようございます。
11:52:21.985 | INFO | 最終: おはようご
11:52:21.985 | INFO | 中間: ざいます。
11:52:23.186 | INFO | 中間: ざいます。
11:52:23.187 | INFO | 最終: ざいます。
うーん、中間が速くてそこそこ精度ありそうなのでこちらをうまく使いたいのだが・・・
以下を見ると max_non_final_tokens_duration_ms というパラメータがある
概要
リアルタイムの文字起こしでは、遅延と精度の間で自然なトレードオフがあります。Soniox Speech-to-Text AI では、
max_non_final_tokens_duration_msパラメータを使用して、音声が検出されてから最終的なトークンが返されるまでの時間を制御できます。このパラメータを使用すると、単語が話されてから文字起こし応答で確定されるまでの遅延を細かく制御できます。
説明
max_non_final_tokens_duration_msパラメータは、発話トークンの終了から、そのトークンが API レスポンスで最終トークンとして返されるまでの最大遅延(ミリ秒単位)を設定します。設定可能範囲:
最小:
700ミリ秒
最大:6000ミリ秒
デフォルト:4000ミリ秒仕組み
- トークンが最初に認識されると、非最終的な状態として返されます。
max_non_final_tokens_duration_msで指定された遅延時間が経過すると、トークンは最終的な状態として返されます(モデルが追加のコンテキストに基づいてトークンを修正した場合を除く)。- 値を短くすると、最終化遅延が短縮されますが、精度がわずかに低下する可能性があります。
- 値を長くすると、モデルがトークンを最終化する時間/コンテキストが増え、精度が向上しますが、遅延が増加します。
例
max_non_final_tokens_duration_msが1000に設定されている場合:
- 3.0 秒に発話されたトークンは、4.0 秒までに最終化され返される可能性があります。
- これにより、ライブキャプションや音声インターフェースなどに役立つ低遅延表示が実現します。
6000に設定した場合:
- 同じトークンは最大 7.0 秒まで最終化されないため、モデルはより多くの将来の文脈を活用して精度を向上させることができます。
設定は、最初に送信するパラメータで指定すれば良い。
# 文字起こし設定送信
config = {
"api_key": api_key,
"audio_format": "pcm_s16le",
"sample_rate": SAMPLE_RATE,
"num_channels": CHANNELS,
"model": "stt-rt-preview",
"language_hints": ["ja", "en"],
"max_non_final_tokens_duration_ms": 1000
}
await websocket.send(json.dumps(config))
とりあえず1つ前のコードに上記のパラメータ付与(1000)してやってみた。面倒なので動画はなしで出力結果だけ・・・
12:50:47.059 | INFO | マイク録音開始 (デフォルトデバイス, 16000Hz, 1ch)
録音開始 - Ctrl+Cで停止
============================================================
12:50:48.019 | INFO | WebSocket接続成功
12:50:48.020 | INFO | 文字起こし設定送信完了。発話を開始してください。
============================================================
12:50:54.022 | INFO | 中間: お
12:50:54.023 | INFO | 中間: おは
12:50:54.264 | INFO | 中間: おはよう
12:50:54.503 | INFO | 中間: おはようご
12:50:54.503 | INFO | 中間: おはようござい
12:50:54.742 | INFO | 中間: おはようございま
12:50:54.742 | INFO | 中間: おはようございます
12:50:54.985 | INFO | 最終: おはよう
12:50:54.985 | INFO | 中間: ございます。
12:50:55.225 | INFO | 最終: ござい
12:50:55.225 | INFO | 中間: ます。
12:50:55.704 | INFO | 最終: ます。
12:50:55.705 | INFO | 中間:
12:50:55.943 | INFO | 中間: 文
12:50:56.187 | INFO | 中間: 文字
12:50:56.188 | INFO | 中間: 文字起
12:50:56.424 | INFO | 中間: 文字起こ
12:50:56.424 | INFO | 中間: 文字起こし
12:50:56.665 | INFO | 中間: 文字起こしの
12:50:56.665 | INFO | 最終: 文
12:50:56.665 | INFO | 中間: 字起こしのテ
12:50:56.906 | INFO | 中間: 字起こしのテスト
12:50:57.146 | INFO | 最終: 字起こ
12:50:57.147 | INFO | 中間: しのテストを
12:50:57.383 | INFO | 中間: しのテストを開始
12:50:57.383 | INFO | 最終: しのテ
12:50:57.384 | INFO | 中間: ストを開始
12:50:57.625 | INFO | 中間: ストを開始し
12:50:57.626 | INFO | 中間: ストを開始しま
12:50:57.866 | INFO | 最終: ストを
12:50:57.867 | INFO | 中間: 開始します
12:50:57.867 | INFO | 中間: 開始します。
12:50:58.104 | INFO | 最終: 開始
12:50:58.105 | INFO | 中間: します。
12:50:58.583 | INFO | 最終: します
12:50:58.583 | INFO | 中間: 。
12:50:58.826 | INFO | 最終: 。
12:51:00.507 | INFO | 中間:
12:51:00.743 | INFO | 中間: 今
12:51:00.744 | INFO | 中間: 今日
12:51:00.983 | INFO | 中間: 今日も
12:51:01.222 | INFO | 中間: 今日も新
12:51:01.461 | INFO | 最終: 今
12:51:01.461 | INFO | 中間: 日も新幹
12:51:01.703 | INFO | 中間: 日も新幹線
12:51:01.703 | INFO | 最終: 日も
12:51:01.703 | INFO | 中間: 新幹線
12:51:01.944 | INFO | 中間: 新幹線を
12:51:02.187 | INFO | 最終: 新幹
12:51:02.187 | INFO | 中間: 線をご
12:51:02.188 | INFO | 中間: 線をご利用
12:51:02.422 | INFO | 最終: 線
12:51:02.423 | INFO | 中間: をご利用
12:51:02.661 | INFO | 中間: をご利用くだ
12:51:02.662 | INFO | 中間: をご利用くださ
12:51:02.905 | INFO | 最終: をご
12:51:02.905 | INFO | 中間: 利用ください
12:51:02.905 | INFO | 中間: 利用くださいま
12:51:03.141 | INFO | 最終: 利用
12:51:03.141 | INFO | 中間: くださいまして
12:51:03.387 | INFO | 中間: くださいまして、
12:51:03.625 | INFO | 最終: ください
12:51:03.626 | INFO | 中間: まして、あ
12:51:03.626 | INFO | 中間: まして、あり
12:51:03.861 | INFO | 中間: まして、ありが
12:51:03.862 | INFO | 最終: まして
12:51:03.862 | INFO | 中間: 、ありがと
12:51:04.105 | INFO | 中間: 、ありがとう
12:51:04.105 | INFO | 中間: 、ありがとうご
12:51:04.342 | INFO | 最終: 、あ
12:51:04.342 | INFO | 中間: りがとうござ
12:51:04.342 | INFO | 中間: りがとうござい
12:51:04.583 | INFO | 中間: りがとうございま
12:51:04.583 | INFO | 最終: りがと
12:51:04.583 | INFO | 中間: うございます
12:51:04.824 | INFO | 中間: うございます。
12:51:05.066 | INFO | 最終: うござ
12:51:05.066 | INFO | 中間: います。
12:51:05.304 | INFO | 最終: います
12:51:05.304 | INFO | 中間: 。
12:51:05.783 | INFO | 最終: 。
12:51:06.023 | INFO | 中間: この
12:51:06.505 | INFO | 中間: この電
12:51:06.747 | INFO | 中間: この電車
12:51:06.748 | INFO | 最終: この
12:51:06.748 | INFO | 中間: 電車
12:51:06.986 | INFO | 中間: 電車は
12:51:07.223 | INFO | 中間: 電車はの
12:51:07.466 | INFO | 中間: 電車はのぞ
12:51:07.466 | INFO | 最終: 電車
12:51:07.466 | INFO | 中間: はのぞみ
12:51:07.709 | INFO | 中間: はのぞみ号
12:51:07.947 | INFO | 最終: は
12:51:07.948 | INFO | 中間: のぞみ号
12:51:08.183 | INFO | 中間: のぞみ号東京
12:51:08.183 | INFO | 最終: のぞみ
12:51:08.183 | INFO | 中間: 号東京
12:51:08.664 | INFO | 最終: 号
12:51:08.664 | INFO | 中間: 東京行
12:51:08.664 | INFO | 中間: 東京行き
12:51:08.903 | INFO | 中間: 東京行きです
12:51:08.903 | INFO | 最終: 東京
12:51:08.903 | INFO | 中間: 行きです。
12:51:09.387 | INFO | 最終: 行
12:51:09.387 | INFO | 中間: きです。
12:51:09.623 | INFO | 最終: きです。
^C
停止信号受信...
12:51:14.648 | INFO | 終了信号送信
文字起こし完了
12:51:15.026 | INFO | マイク録音終了
文字起こし終了
最終認識結果までが300msぐらいまで短縮された。ここは精度とのトレードオフになるところなので、文字起こしする発話の内容なども踏まえて考える必要はあるが、こういうパラメータが用意されているというところにちょっと好印象。
中間と最終のどちらを使うにせよ、他のストリーミング対応ASR・TTSとは最終が来るタイミングが違う(他のやつは最終≒発話の終わりという風に扱える印象だけど、Sonioxの場合は最終が逐次的にやってくるのでなにかしらで判定しないといけない)ので、使い方に工夫が必要な点は変わらないかな。
その他の機能について
話者ダイアライゼーション
単語レベルタイムスタンプ
キーワードスポッティング(あらかじめ専門用語などを指定しておくことで、文字起こしの精度が上がる)
まとめ
たまたま見つけたのだが、リアルタイム性が必要なケースで十分精度ありそうな印象でかなり使えそうな気がしている。2020年創業でそこそこ古いのだけど、ググっても全くと良いほどでてこないのが不思議。
改めて見直してみたけど、やっぱり中間→最終までの遅延が大きいな。中間の精度が良い印象があるので、うまく使えればかなり速くなりそうなんだけど・・・
v3が出た。
冒頭にもコメントを追加したが、本記事の初稿はおそらくモデルのバージョンがv1で、当時と比較すると、多少APIパラメータやレスポンスなどが変更されているように思える。
これは改めて確認したい。
v3 軽く試してみた。
-
[LIVE]と表示されているのが中間認識、ないのが最終認識が確定
Sonioxのストリーミングのレスポンスは、GoogleやAWSなどと比べるとちょっとクセがあるのは相変わらずで、このあたりは見せ方とか使い方を少し工夫する必要がある。ただ、ドキュメントなども更新されてわかりやすくなったし、レイテンシーのパラメータ調整なんかも多分いらなくなってるように思える。
実際に試してみた感じ、中間認識の精度は変わらず高いし速度も速い、中間認識→最終認識確定までのラグも以前と比べるとほとんど感じなくなってて、かなり速い印象。ただ必ず1回目の文字起こしだけ最終確定に少し時間がかかるのは謎。
別途記事でまとめる予定。
v3はこちらで試す