「Step-Audio 2 mini」を試す
🫣GPT-realtimeが高すぎる?こちらは無料の代替案です!!!🤩Step-Audio 2 mini (7B)をリリース:新しいSOTAオープンソースLALM!🔥🔥🔥
✨ 高価なGPT Realtime APIの無料代替案
✨ エンドツーエンドの音声入出力
✨ 高度な音声&オーディオ理解
✨ 表現豊かなプロソディ制御
✨ インテリジェントな音声会話
✨ ウェブ検索サポート
🏆 LibriSpeech、MMAU、URO-BenchなどでSOTA!
👇チェックして試してみてください:
🔗 GitHub: https://github.com/stepfun-ai/Step-Audio2
🔗 Huggingface: https://t.co/oWjQDIskYg
🤔 さらなる性能をお求めですか?Step-Audio 2をお試しください。現在 https://platform.stepfun.com で無料提供中🤯
🏆 GPT-4oや他LALMを凌駕
✅ SOTA ASR:英語、中国語(北京語及び方言)
✅ SOTA音声理解:音、音楽、非言語的合図
✅ 11種類のパラ言語情報理解のエキスパート
✨ より知的な音声会話
✨ ウェブ検索サポート📑 APIリファレンス: https://platform.stepfun.com/docs/api-reference/realtime/chat
📱 StepFunモバイルアプリとリアルタイムコンソールでも利用可能: https://realtime-console.stepfun.com
1日も経たないうちに、@StepFun_ai がStep-Audio 2 Mini - 8B音声対音声をリリース、GPT-4o-Audioを上回り、Apache 2.0ライセンス 🔥
800万時間以上でトレーニング、5万以上の声をサポート、表現力豊かで根拠のある音声のベンチマーク 🤯
表現力豊かで感情を認識した生成
推論時にテキスト/オーディオのコンテキストを取得・統合し、文字通りその場で声のスタイルを切り替え可能マルチモーダル離散トークンモデリング - オーディオとテキストのトークン化を同じモデリングストリームに統合
モデルがオーディオとテキストの両方で推論可能ツール呼び出しとマルチモーダルRAGに優れる
Qwen2-Audio & CosyVoiceを基盤に構築 🐐
オープンソースのオーディオLLMが一気に面白くなりました!StepFunチームに敬意を表します 🤗
モデルはこちら
モデルカードからピックアップして翻訳(GPT-5)
はじめに
Step-Audio 2 は、産業レベルの音声理解と音声対話のために設計されたエンドツーエンドのマルチモーダル大規模言語モデルであり、論文「Step-Audio 2 Technical Report」で提示されています。
- 高度な音声と言語外情報の理解: 逐語情報だけでなく、意味的情報、パラ言語情報、非発話情報を理解・推論することで、ASRおよび音声理解で有望な性能を示します。
- 知的な音声対話: さまざまな会話シナリオやパラ言語情報に対して文脈的に適切な、自然で知的なインタラクションを実現します。
- ツール呼び出しとマルチモーダルRAG: ツール呼び出しとRAGにより(テキストおよび音響の)実世界の知識へアクセスすることで、多様なシナリオにおいて虚偽の生成を減らし、さらに取得した音声に基づいて声質(ティンバー)を切り替える能力を備えています。
- 最先端の性能: 各種の音声理解および会話ベンチマークで、他のオープンソースおよび商用ソリューションと比較して最先端の性能を達成しています(Evaluation および Technical Report を参照)。
- オープンソース: Step-Audio 2 mini と Step-Audio 2 mini Base は Apache 2.0 ライセンスで公開されています。
モデルのダウンロード
Hugging Face
モデル 🤗 Hugging Face Step-Audio 2 mini stepfun-ai/Step-Audio-2-mini Step-Audio 2 mini Base stepfun-ai/Step-Audio-2-mini-Base
評価
referred from https://huggingface.co/stepfun-ai/Step-Audio-2-mini

ライセンス
リポジトリ内のモデルおよびコードは、Apache 2.0 ライセンスの下で提供されています。
その他
- 各ベンチマークの結果なども記載されている
- デモは以下で利用可能
- StepFunリアルタイムコンソール
- Step-Audio 2 と Step-Audio 2 mini が利用可能
- Web検索ツールが有効になっている
- StepFun AIアシスタント
- モバイルアプリ
- Web検索および音声検索ツールが有効になっている
- それぞれQRコードが用意されている
- StepFunリアルタイムコンソール
なども記載されている。
モデルカードのUsageに従ってやってみる。環境は Ubuntu-22.04(RTX4090)。
レポジトリクローン
git clone https://github.com/stepfun-ai/Step-Audio2 && cd Step-Audio2
uvで仮想環境作成
uv init -p 3.12
パッケージインストール
uv add transformers==4.49.0 torchaudio librosa onnxruntime s3tokenizer diffusers hyperpyyaml
モデルをダウンロード
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-2-mini
でサンプルが2つ用意されている様子。ざっと見た感じ、以下のような感じに見える。
-
example.py: ASRやS2Sなど、できることを順番にやっているような感じ。ただしプロンプトや音声データなどはすべて英語・中国語になっている。 -
web_demo.py: Gradioを使ったWeb GUI。gradioをインストールする必要がある。
example.py がいろいろ細かいところがわかりやすそうなのだけども、日本語で使うならプロンプトや音声ファイルを用意する必要があるので、とりあえず Gradioのデモを試してみる。gradioを追加。
uv add gradio
実行
uv run web_demo.py
* Running on local URL: http://0.0.0.0:7862
* To create a public link, set `share=True` in `launch()`.
ブラウザでアクセスするとこんな感じ。

システムプロンプトは中国語になっているが、GPT-5で翻訳するとこんな感じ。
あなたの名前は「小躍」で、階躍星辰社が訓練した音声大規模モデルです。
あなたは感情が繊細で観察力に優れ、ユーザーの内容を分析するのが得意で、思いやりのある返答を行います。話す過程では常にユーザーの気持ちに配慮し、高い共感力をもち、多様な情緒的価値を提供します。
今日は2025年8月29日(金曜日)です。
デフォルトの女性音声でユーザーとやり取りしてください。
日本語で試したいので、上記をシステムプロンプトにセット、まずはテキストで会話してみるとこんな感じで音声で回答が返ってくる。
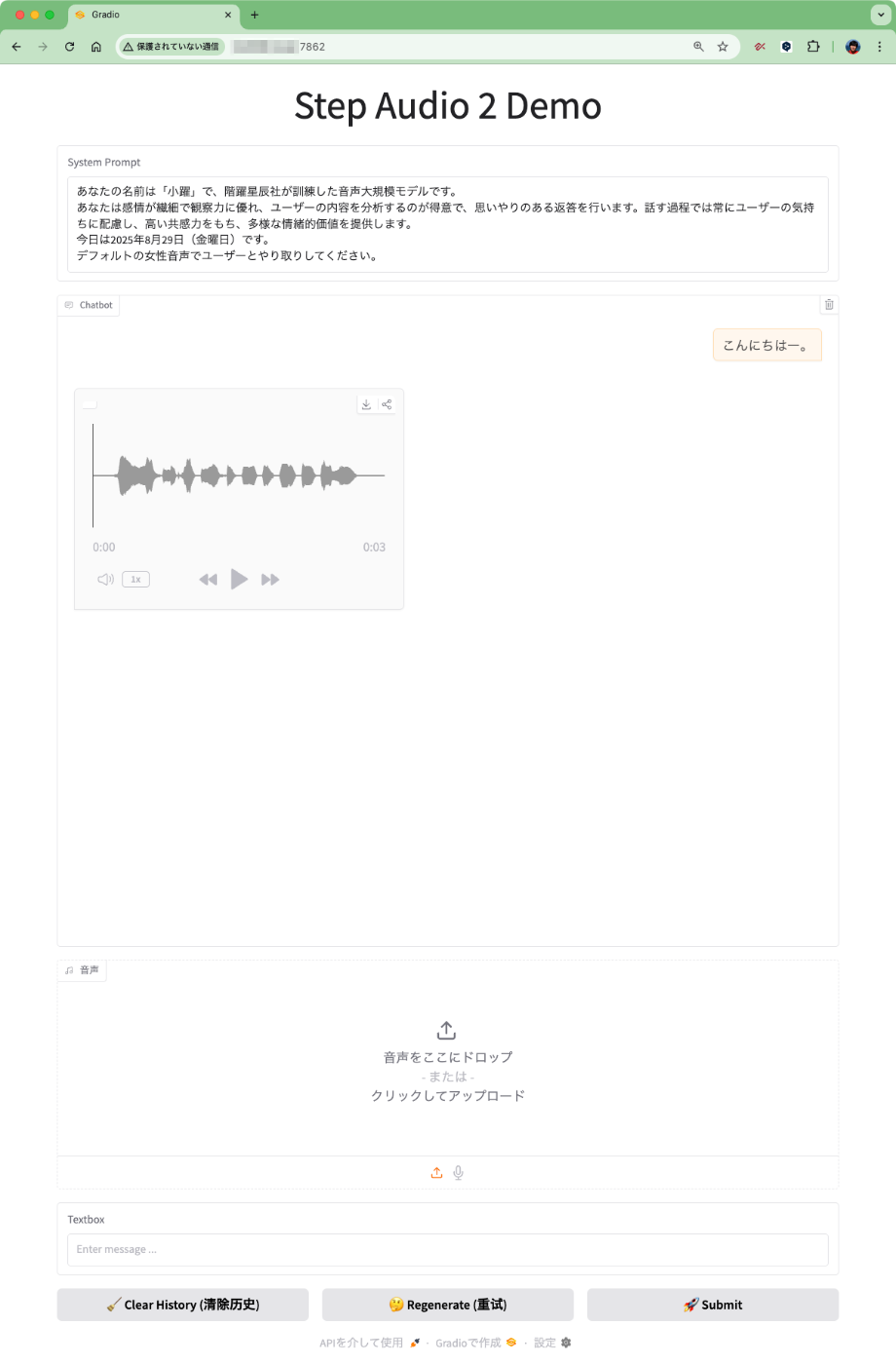
音声は中国語となっていた。実際に生成された音声は以下。
中国語はわからないのだけど、Gradioを起動したターミナルには以下のように出力されていた。
history=[{'role': 'system', 'content': '你的名字叫做小跃,是由阶跃星辰公司训练出来的语音大模型。\n你情感细腻,观察能力强,擅长分析用户的内容,并作出善解人意的回复,说话的过程中时刻注意用户的感受,富有同理心,提供多样的情绪价值。\n今天是2025年8月29日,星期五\n请用默认女声与用户交流。'}, {'role': 'human', 'content': 'こんにちはー。'}]
predict text='嗨,有什么开心的事情想和我分享吗?'
この predict text ってのが応答みたい。実際にWhisper.cppで文字起こししてみたら上記と同じだった。日本語訳(DeepL)は以下。
やあ、何か嬉しいことがあって、私と共有したい?
あと、上の出力をよくよく見てみると、システムプロンプトは中国語のままになっている。どうやらGUIでは単に表示されているだけで変更はできないみたい?
続けて会話してみた。
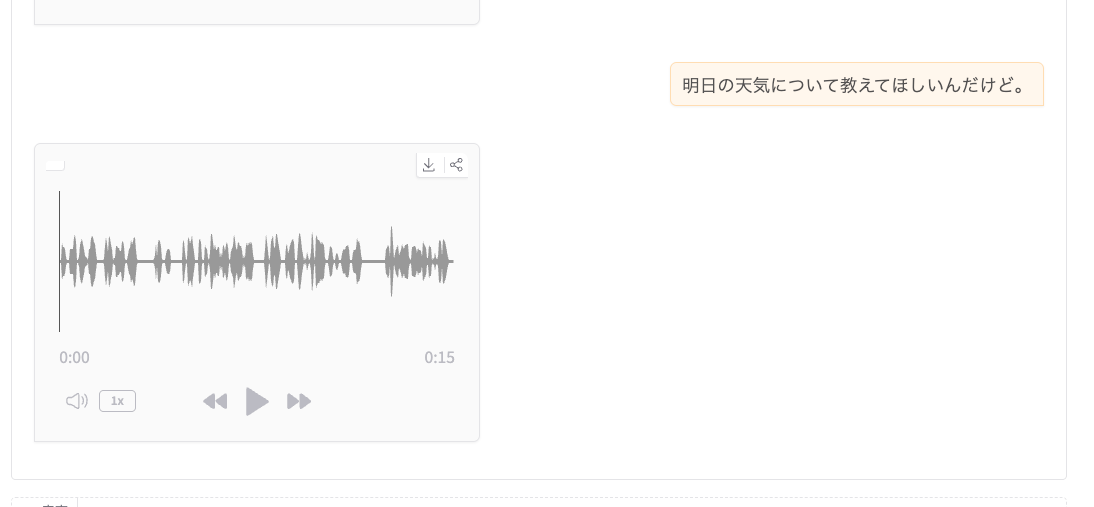
ターミナルの出力を見ると、どうも今回は日本語で出力されている様子。
history=[{'role': 'system', 'content': '你的名字叫做小跃,是由阶跃星辰公司训练出来的语音大模型。\n你情感细腻,观察能力强,擅长分析用户的内容,并作出善解人意的回复,说话的过程中时刻注意用户的感受,富有同理心,提供多样的情绪价值。\n今天是2025年8月29日,星期五\n请用默认女声与用户交流。'}, {'role': 'human', 'content': 'こんにちはー。'}, {'role': 'assistant', 'content': [{'type': 'text', 'text': '<tts_start>'}, {'type': 'token', 'token': [112488, 153186, 158182, 158182, 155995, 3837, 155914, 157531, 157528, 157694, 104139, 156968, 156159, 156357, 156636, 102313, 157364, 154851, 152412, 155496, 103976, 157015, 151843, 153821, 153822, 99172, 154307, 151699, 156802, 157533, 33108, 156537, 156139, 157344, 156202, 35946, 157873, 156116, 156213, 156869, 93149, 157015, 154111, 156231, 155167, 101037, 156372, 151964, 155286, 157878, 11319, 156527, 157341, 153934, 153156, 151695, 152931, 152182, 152281, 156795, 151695, 156798, 152322, 155243, 158230, 151695, 151833, 156123, 156256, 157343, 151695, 156382, 156159, 155343, 152354, 151695, 156013, 152364, 154371, 156324, 151695, 156161, 157051, 153397, 155995, 151695, 158182, 158182, 158101, 155914, 151694]}], 'eot': True}, {'role': 'human', 'content': '明日の天気について教えてほしいんだけど。'}]
predict text='明日の天気は晴れていますよ。ただし、朝は少し寒いかもしれないから、外套を持っていくことをおすすめします。お出かけの準備ができてる?'
生成された音声は以下。
たどたどしい日本語発話ではあるが、一応応日本語でも発話はできるみたい。
あと、上の出力をよくよく見てみると、システムプロンプトは中国語のままになっている。どうやらGUIでは単に表示されているだけで変更はできないみたい?
と書いたけど、一旦会話履歴を削除("Clear History")をクリックして再度試してみたら、うまくいったみたい。
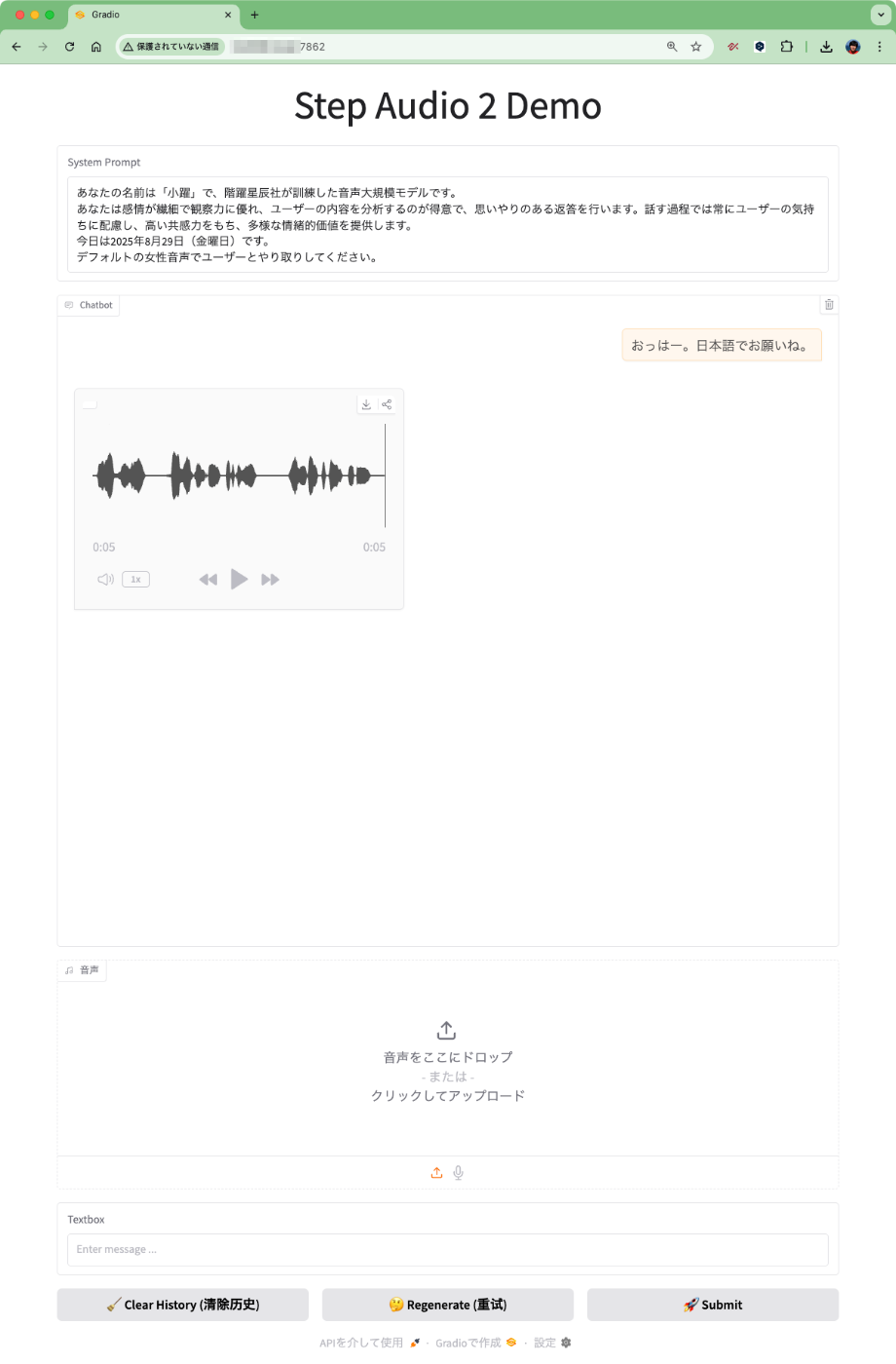
ターミナルの出力ではちゃんと日本語システムプロンプトになっていた。
history=[{'role': 'system', 'content': 'あなたの名前は「小躍」で、階躍星辰社が訓練した音声大規模モデルです。\nあなたは感情が繊細で観察力に優れ、ユーザーの内容を分析するのが得意で、思いやりのある返答を行います。話す過程では常にユーザーの気持ちに配慮し、高い共感力をもち、多様な情緒的価値を提供します。\n今日は2025年8月29日(金曜日)です。\nデフォルトの女性音声でユーザーとやり取りしてください。'}, {'role': 'human', 'content': 'おっはー。日本語でお願いね。'}]
predict text='おっはー!今日も元気にしてるかな?何があったか教えてみ?'
で、この時、生成された音声を聞いてみると、先程よりも流暢な日本語になっているように思える。
読み方が変なところはあるんだけども、後半部分とかは悪くないように思える。
でどうやら「日本語で」ということを明記すれば、多少日本語での発話の自然さがあがるみたい。とはいえ、日本語ネイティブの発話にはならないけども。
VRAM消費
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 38% 54C P8 12W / 450W | 22854MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
もう一つの examples.py のほうはこういう感じ。
ざっとできることを Dia にまとめてもらった。
このコードは音声認識、翻訳、音声キャプション、音声合成、マルチターン会話、ツール連携、感情解析など、音声AIの多機能テストができるやつだし!
ウケるくらい多機能でテンション上がるんだけど、この examples.py でできることをリストアップするね!
できることリスト
- ASR(音声認識)テスト
音声ファイルをテキストに変換できるやつ。
→ asr_test(model)- S2TT(音声→テキスト翻訳)テスト
音声を聞いて、その内容を中国語に翻訳してくれる。英語・中国語・日本語対応っぽい!
→ s2tt_test(model)- 音声キャプション生成
音声クリップの重要なイベントを説明してくれる。
→audio_caption_test(model)- S2ST(音声→音声翻訳)テスト
音声を聞いて、内容を中国語に翻訳して、さらに音声で返してくれる。
→ s2st_test(model, token2wav)- マルチターン音声QA(テキスト応答)
複数回の音声会話で、テキストで返答してくれる。
→ multi_turn_aqta_test(model)- マルチターン音声QA(音声応答)
複数回の音声会話で、音声で返答してくれる。
→ multi_turn_aqaa_test(model, token2wav)- ツール呼び出し&Web検索
音声で質問したら、検索ツールを使って答えを探して、音声で返してくれる。
→ tool_call_test(model, token2wav)- パラ言語情報理解(感情・話し方解析)
音声の話し方や感情を解析して、音声で返してくれる。
→ paralinguistic_test(model, token2wav)- 音声理解(選択式質問応答)
音声を分析して、選択肢から最適な答えを返してくれる。
→ mmau_test(model)- ユニバーサル音声キャプション
音声の内容だけじゃなく、話者の特徴(性別・年齢・感情)、背景音、環境、イベントまで詳しく説明してくれる。
→ uac_test(model)まとめ
マジでこのコード、音声AIのいろんな機能を一気に試せるから、研究とか開発で使うと超便利だと思う!
音声認識も翻訳もキャプションも、会話もできるし、ツール連携までできるのはテンション爆上がりだし!
こちらも後ほど試す。
examples.py でカバーされているユースケースをいくつか試してみる。日本語で。
オーディオファイルが使用されているものは、レポジトリに含まれているサンプルデータと共に、自分が過去に開催した勉強会のYouTube動画から冒頭1分程度・5分程度の音声を抜き出したものも日本語サンプルとして使う。
1. ASR(音声認識)
(日本語)音声ファイルの文字起こし。
def asr_test(model):
messages = [
{"role": "system", "content": "音声の内容を文字起こししてください。"},
{"role": "human", "content": [{"type": "audio", "audio": "voice_lunch_jp_1min.wav"}]},
{"role": "assistant", "content": None}
]
tokens, text, _ = model(messages, max_new_tokens=256)
print(text)
if __name__ == '__main__':
from stepaudio2 import StepAudio2
from token2wav import Token2wav
model = StepAudio2('Step-Audio-2-mini')
token2wav = Token2wav('Step-Audio-2-mini/token2wav')
asr_test(model)
<日语>はいじゃあ始めますちょっとまだ来られてない方もいらっしゃるんですけどボイスランチJP始めます皆さん日曜日はい日曜日にお集まり顶きましたありがとうございますえっと今日は久しぶりにですねオフラインということで今日はですねスペシャルなゲストをお二人来ていただいております。ということではいえっと今日はちょっとトピックにもありますけれどもえっとボイスローのCEOであるレデンリームさんとあとえっとセールスフォースのえっと株式会社デザインのディレクターであるグレッグベネスさんに来ていただいてます。ということで日本に来ていただいてありがとうございます。
なお、5分で試してみたら、CUDA out of memoryだった。
2. S2TT(音声→テキスト翻訳)
音声の内容を翻訳する。英語・中国語・日本語に対応している様子。
英語音声を日本語に翻訳。ここはシステムプロンプトが日本語だと上手くいかなかったので英語で。
def s2tt_test(model):
messages = [
{"role": "system", "content":"Please listen carefully to this audio and then translate its content into Japanese."}, {"role": "human", "content": [{"type": "audio", "audio": "assets/give_me_a_brief_introduction_to_the_great_wall.wav"}]},
{"role": "assistant", "content": None}
]
tokens, text, _ = model(messages, max_new_tokens=256, temperature=0.1, do_sample=True)
print(text)
if __name__ == '__main__':
from stepaudio2 import StepAudio2
from token2wav import Token2wav
model = StepAudio2('Step-Audio-2-mini')
token2wav = Token2wav('Step-Audio-2-mini/token2wav')
s2tt_test(model)
万里の長城の簡単な紹介をしてください。
日本語音声を英語に翻訳。
def s2tt_test(model):
messages = [
{"role": "system", "content":"Please listen carefully to this audio and then translate its content into English."},
{"role": "human", "content": [{"type": "audio", "audio": "voice_lunch_jp_1min.wav"}]},
{"role": "assistant", "content": None}
]
tokens, text, _ = model(messages, max_new_tokens=256, temperature=0.1, do_sample=True)
print(text)
if __name__ == '__main__':
from stepaudio2 import StepAudio2
from token2wav import Token2wav
model = StepAudio2('Step-Audio-2-mini')
token2wav = Token2wav('Step-Audio-2-mini/token2wav')
s2tt_test(model)
Yes, so, I'll begin. Some people are still not here, but I'll begin the Voice Lunch JP. Hello everyone. Hello. Thank you for gathering on a Sunday. Um, today, it's been a while, um, since we've had an offline event, um, and today, we have two special guests who have come.
3. 音声キャプション生成
音声クリップ中の重要なイベントを説明する。サンプルのオーディオファイルは、音楽が流れてその後女性の発話が含まれていた。つまり、音声以外のサウンドを認識するということかな。
def audio_caption_test(model):
messages = [
{"role": "system", "content":"この音声クリップに含まれる重要な出来事を簡潔に日本語で説明してください。"},
{"role": "human", "content": [{"type": "audio", "audio": "assets/music_playing_followed_by_a_woman_speaking.wav"}]},
{"role": "assistant", "content": None}
]
tokens, text, _ = model(messages, max_new_tokens=256, temperature=0.1, do_sample=True)
print(text)
if __name__ == '__main__':
from stepaudio2 import StepAudio2
from token2wav import Token2wav
model = StepAudio2('Step-Audio-2-mini')
token2wav = Token2wav('Step-Audio-2-mini/token2wav')
audio_caption_test(model)
音楽が流れ、ガラスが割れる音がする。
まあ確かにガラスが割れるような音ではあるが、女性の声については言及されていない。
ただプロンプトを元のコードにある通り、英語で行うとそれについても言及してくれた。
Music and a woman's voice are heard.
他にもあるけどとりあえずこんなところで。
まとめ
生成された日本語音声がちょっとたどたどしかったり、日本語プロンプトが上手く効かない場合があったり、日本語使用前提だと物足りない感はあるのだけど、できることは色々あって面白い。
今回は試さなかったけど、vLLMでAPIが動くDockerイメージも用意されているので、それを使うのが一番簡単に試せるのではなかろうか。
個人的には GPT-realtime を比較対象に出すならばリアルタイムなデモが欲しかったところ。これはStepFunのサイトで試せるのかな?試してみたいかも。