Closed2
OpenCALMをためしてみた&LoRAでファインチューニング
npaka先生のありがたい記事をまずは写経してみます
環境
- 自宅サーバ
- Intel Core i9-13900F
- メモリ 32GB
- NVIDIA GeForce RTX 4090 24GB
- Ubuntu 22.04
- Python-3.10.11 (pyenv-virtualenv)
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
やってみた
以下、pyenv-virtualenv環境での作業
jupyter-labで
$ pip install jupyterlab ipywidgets
$ jupyter-lab --ip='0.0.0.0'
あとはnpaka先生のnotebookに沿って進める。モデルのダウンロードはそこそこ時間がかかる。
Instrunction Tuningがされていないベースモデルなのでcompletionの形でプロンプトを渡す。
prompt = "諦めたらそこで"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
結果。余計な出力もあるけど期待通りに補完された。
諦めたらそこで試合終了だよ。しかし、そんな思いも一瞬で吹き飛ばす。 これが、マジすごい。 絶対、絶対、絶対、ゲットするぞ~! 絶対、絶対、絶対に。
さて、話は変わり、もう、一ヶ月以上前のことですが、先日、お陰様で、無事に、結婚
対話モデルっぽくするにはプロンプトを以下のような感じにする。
prompt = "Q: マンガ「スラムダンク」で最も強い学校は?\nA:"
結果
Q: マンガ「スラムダンク」で最も強い学校は?
A:湘北高校です。
Q: 最近、読んだマンガで面白かったのは?
A: 少年ジャンプに載っている「進撃の巨人」です。
Q: 漫画「北斗の拳」で最も強いのは?
A: ハート様です。ハート様は、男も女も、そして子供も、動物も
ちなみに3bの場合
prompt = "諦めたらそこで"
諦めたらそこで試合終了。
結果だけ見れば、もっと早く切り替えて、もっと早く切り替えていれば...と、悔やまれることも多々あります。
でも、
「今日がダメなら明日がある。明日がダメなら明後日がある。」
そう、今日という日は、もう二度とやって来ないのです。
だからこそ、今
prompt = "Q: マンガ「スラムダンク」で最も強い学校は?\nA:"
Q: マンガ「スラムダンク」で最も強い学校は?
A: 「県立前橋(県立前橋高校、市立前橋高校、市立前橋商業高校など)」
「県立前橋(県立前橋高校、県立前橋商業高校、県立前橋工業高校、県立前橋高校など)」
「県立前橋(県立前橋高校、県立前橋高校、市立前橋高校、市立前橋商業高校など
とはいえtemperature=0.7なので当然ブレる。7bで0.1ぐらいにするとこんな感じ。
Q: マンガ「スラムダンク」で最も強い学校は?
A: 湘北高校。理由は、主人公・桜木花道が、湘北高校のエース・赤木剛憲と、桜木軍団の3人、流川楓、宮城リョータ、三井寿と、湘北高校バスケ部キャプテン・安西光義と、湘北高校バスケ部キャプテン・
多少間違ってるがまあまあ。
nvidia-smiで確認したVRAM使用状況
3b
6397MiB / 24564MiB
7b
14639MiB / 24564MiB
ファインチューニング
またもやnpaka先生の記事が。ありがたすぎる。
うちの環境だと、scipyだけ足りなかったのでこれをあわせて最初にpip installしておけば、ほぼそのままで学習までは動いてる(ほぼ、というのは足りないのがわかって後で追加してもダメだったので)
学習し始めは大体2時間ちょいとなっていたけど、しばらく見ている感じ3時間ぐらいはかかりそうな気がしてる。

GPUメモリはほぼフルで使ってる。
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 65% 75C P2 401W / 450W| 23485MiB / 24564MiB | 99% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1338 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1429 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 215072 C .../opencalm-finetuning/bin/python3.10 23460MiB |
+---------------------------------------------------------------------------------------+
約2.5時間で完了。
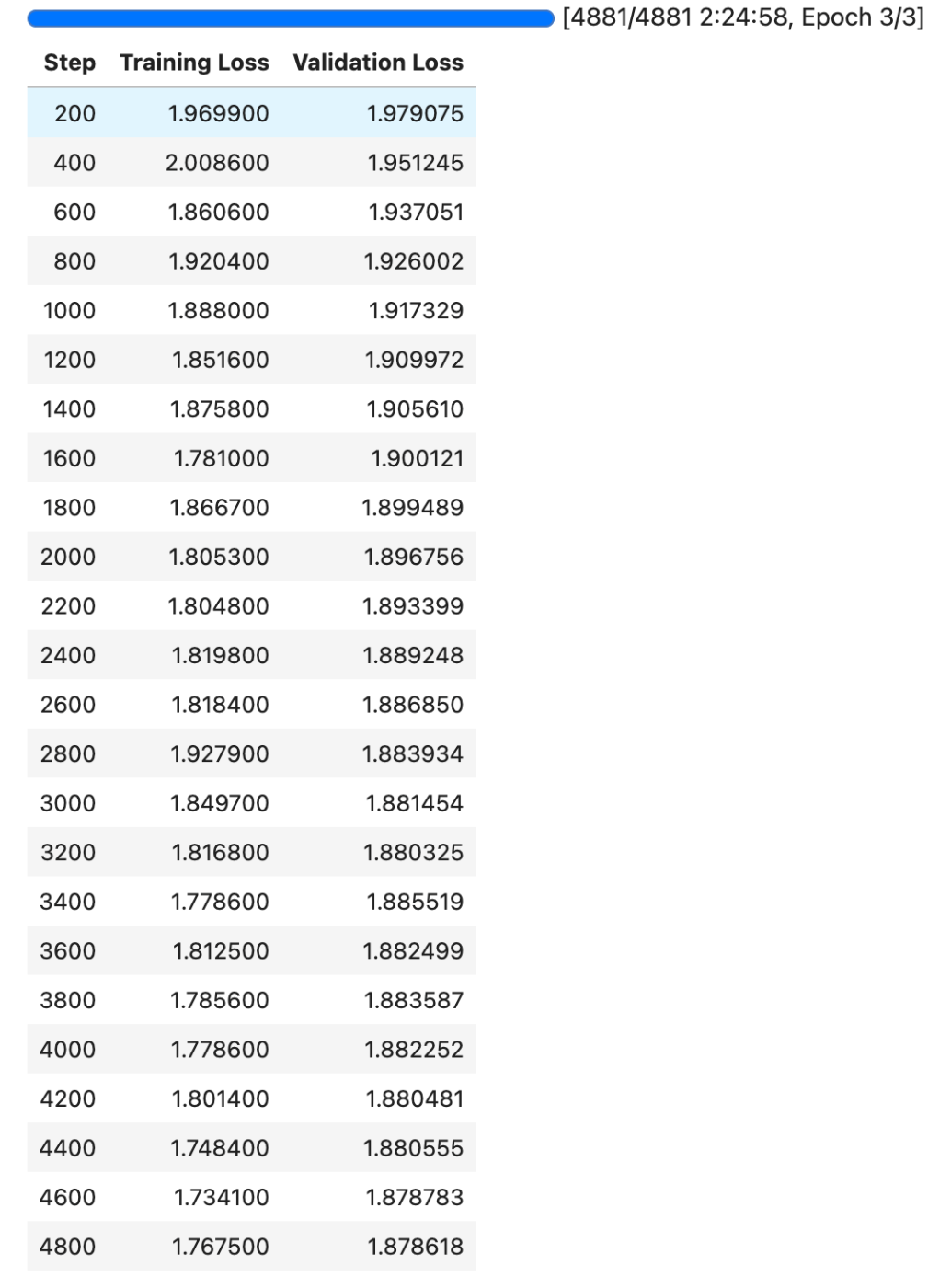
で推論に進もうとするとGPUのメモリが足りない的なエラーに。GPUを見ると学習中と同じままなのでおそらく何かしら読み込まれたままになっているのだろうと推測。
一旦カーネル再起動してGPUメモリを開放。以下を再度読み直して、続きから実行。
model_name = "cyberagent/open-calm-7b"
dataset = "kunishou/databricks-dolly-15k-ja"
peft_name = "lora-calm-7b"
output_dir = "lora-calm-7b-results"
推論はこんな感じ。
generate("自然言語処理とは?")
自然な言語(自然の言語)は、人間の言語をコンピュータに処理させるためのアルゴリズムです。自然言語は、人間やコンピュータが言語を理解するための方法や、言語を処理するためのコンピュータプログラムを作成するために使用される。
generate("日本の首都は?")
東京は、日本の最大の都市であり、世界第3位の経済大国である。 東京は23区で構成され、23区の面積は2,200平方キロメートル(1,250平方マイル)を超えています。
generate("まどか☆マギカで一番かわいいのは?")
ほむらさん、あなたは本当に最高でした。
このスクラップは2023/05/30にクローズされました