Anthropic「Introducing Contextual Retrieval」
ざっと自分向けメモ
-
ロングコンテキストLLMで収まるならば、そこに全部詰め込むこともできる。
- ただし、コストが課題になる
- Prompt Cachingを使えば、この課題を緩和できる
-
RAG
- チャンク分割して、そのチャンクに対して類似性検索を行う
- 意味的な関係を捉えることに優れている
- 重要な完全一致を見逃すことがある
- BM25で緩和できる
- ハイブリッド検索を使う
- チャンク分割して、そのチャンクに対して類似性検索を行う
-
RAGの課題
- チャンクに十分なコンテキストがない
- チャンクの検索や活用が困難
-
Contextual Retrievalがそれを解決する
- チャンクに、チャンク固有の説明コンテキストを付与する
- 他のアプローチはあまり効果がなかった
- Using Summaries in Document Retrieval : チャンクの要約をチャンクに追加する
- Precise Zero-Shot Dense Retrieval without Relevance Labels: 仮説的なドキュメントの埋め込み、いわゆるHyDE
- Document Summary Index: 要約ベースのインデックス
- 他のアプローチはあまり効果がなかった
- LLMに説明コンテキストを生成させる
- 文書全体とチャンクをプロンプトで渡して、説明コンテキストを生成させる
- Prompt Cachingを活用することでコストを抑えることができる
- チャンクに、チャンク固有の説明コンテキストを付与する
<document>
{{WHOLE_DOCUMENT}}
</document>
ドキュメント全体に配置したいチャンクは次のとおりです。
<chunk>
{{CHUNK_CONTENT}}
</chunk>
このチャンクを検索でより適切に取得できるように、ドキュメント全体におけるこのチャンクの位置づけを簡潔に説明してください。簡潔な説明のみを回答としてください。それ以外は回答しないでください。
- 評価
- 複数の知識ドメイン・埋込モデル・検索戦略・評価メトリクスで実験
- 結果
- Gemini Text 004が全てにおいて高いパフォーマンス
- Contextual Retrievalにより、top-20の検索失敗率が減少(5.7% → 3.7%)
- Contextual RetrievalをContextual BM25と組み合わせるとより検索失敗率が減少(5.7% → 2.9%)
- Contextual Retrieval実装時に考慮すべきこと
- チャンク分割の仕方
- チャンクサイズ・チャンクの境界・オーバーラップが検索性能に影響
- 埋め込みモデルの選択
- GeminiとVoyageが効果的だった
- カスタムコンテキストプロンプト
- 特定のドメイン・ユースケースではそれにあわせたプロンプトを使用すると良い、用語集がある場合など。
- チャンク数
- 入力コンテキストに含めるチャンクを多くすると、関連情報を拾う可能性があがるが、逆にノイズになる場合もある
- 5、10、 20で試してみたが、20が最も効果が高かった
- 必ずテストして判断すべし
- チャンク分割の仕方
- リランキング
- 検索精度に効果はあるが、レスポンス時間とコストに影響する
- リランキングに渡すチャンク数は、多ければ性能向上、少なければレスポンス時間・コストを低減、常にトレードオフ
- 適切なバランスを見つけるためにテストすべし
- 結論
- Embedding+BM25は、Embeddingだけよりも優れている
- VoyageとGeminiのEmbeddingモデルの性能は良い
- コンテキストに含めるチャンク数は20が良い
- チャンクにコンテキストを追加することで検索精度は向上する
- リランニングはしないよりした方が良い
- これらの手法はそれぞれで効果があるが、組み合わせることでより精度があがる
んー、ベクトル検索って、基本的にはクエリとチャンクの文章間の類似性(同じ文章ならばスコア1になる)だと思っているので、コンテキスト情報を追加することで検索精度が上がるってのはちょっと驚き。回答精度が上がるならわかるけど。
試していないので推測だけど、コンテキスト情報が増えればクエリとの文章類似性の差は広くなる気がするので、スコア自体は下がる気がする。ただそれは全てのチャンクに言えることなので、そうなってきた場合にセマンティックな類似性という部分が強くなって、「相対的」にランキング「順」がよくなる、ということなのではないだろうか。知らんけど。
notebookを公開してくれてるようなので、試してみようと思う。
notebookを見てみた。結構ボリュームあるので、ざっとこんな感じ。
使用されているデータセット
チャンク
評価用
90ファイルのRustで書かれたコードをチャンク分割したものと思われる。チャンク分割前はこんな感じ。
//! Executor for differential fuzzing.
//! It wraps two executors that will be run after each other with the same input.
//! In comparison to the [`crate::executors::CombinedExecutor`] it also runs the secondary executor in `run_target`.
//!
use core::{cell::UnsafeCell, fmt::Debug, ptr};
use libafl_bolts::{ownedref::OwnedMutPtr, tuples::MatchName};
use serde::{Deserialize, Serialize};
use crate::{
executors::{Executor, ExitKind, HasObservers},
inputs::UsesInput,
observers::{DifferentialObserversTuple, ObserversTuple, UsesObservers},
state::UsesState,
Error,
};
/// A [`DiffExecutor`] wraps a primary executor, forwarding its methods, and a secondary one
#[derive(Debug)]
pub struct DiffExecutor<A, B, OTA, OTB, DOT> {
primary: A,
secondary: B,
observers: UnsafeCell<ProxyObserversTuple<OTA, OTB, DOT>>,
}
impl<A, B, OTA, OTB, DOT> DiffExecutor<A, B, OTA, OTB, DOT> {
/// Create a new `DiffExecutor`, wrapping the given `executor`s.
pub fn new(primary: A, secondary: B, observers: DOT) -> Self
where
A: UsesState + HasObservers<Observers = OTA>,
B: UsesState<State = A::State> + HasObservers<Observers = OTB>,
DOT: DifferentialObserversTuple<OTA, OTB, A::State>,
OTA: ObserversTuple<A::State>,
OTB: ObserversTuple<A::State>,
{
Self {
primary,
secondary,
observers: UnsafeCell::new(ProxyObserversTuple {
primary: OwnedMutPtr::Ptr(ptr::null_mut()),
secondary: OwnedMutPtr::Ptr(ptr::null_mut()),
differential: observers,
}),
}
}
(snip)
こんな感じでチャンク分割されている。(ハイフンのところはわかりやすく自分で入れたもので、実際にはチャンクに含まれていない)
--------- Index: 0, Length: 847, Lines: 26 Words: 90 ----------
//! Executor for differential fuzzing.
//! It wraps two executors that will be run after each other with the same input.
//! In comparison to the [`crate::executors::CombinedExecutor`] it also runs the secondary executor in `run_target`.
//!
use core::{cell::UnsafeCell, fmt::Debug, ptr};
use libafl_bolts::{ownedref::OwnedMutPtr, tuples::MatchName};
use serde::{Deserialize, Serialize};
use crate::{
executors::{Executor, ExitKind, HasObservers},
inputs::UsesInput,
observers::{DifferentialObserversTuple, ObserversTuple, UsesObservers},
state::UsesState,
Error,
};
/// A [`DiffExecutor`] wraps a primary executor, forwarding its methods, and a secondary one
#[derive(Debug)]
pub struct DiffExecutor<A, B, OTA, OTB, DOT> {
primary: A,
secondary: B,
observers: UnsafeCell<ProxyObserversTuple<OTA, OTB, DOT>>,
}
--------- Index: 1, Length: 793, Lines: 22 Words: 70 ----------
impl<A, B, OTA, OTB, DOT> DiffExecutor<A, B, OTA, OTB, DOT> {
/// Create a new `DiffExecutor`, wrapping the given `executor`s.
pub fn new(primary: A, secondary: B, observers: DOT) -> Self
where
A: UsesState + HasObservers<Observers = OTA>,
B: UsesState<State = A::State> + HasObservers<Observers = OTB>,
DOT: DifferentialObserversTuple<OTA, OTB, A::State>,
OTA: ObserversTuple<A::State>,
OTB: ObserversTuple<A::State>,
{
Self {
primary,
secondary,
observers: UnsafeCell::new(ProxyObserversTuple {
primary: OwnedMutPtr::Ptr(ptr::null_mut()),
secondary: OwnedMutPtr::Ptr(ptr::null_mut()),
differential: observers,
}),
}
}
チャンク分割の仕方も性能に影響するとあったので、どういうロジックで分割しているのかなと思って、各チャンクの文字数・行数・単語数で見てみたけども、明確な基準は読み解けなかった。
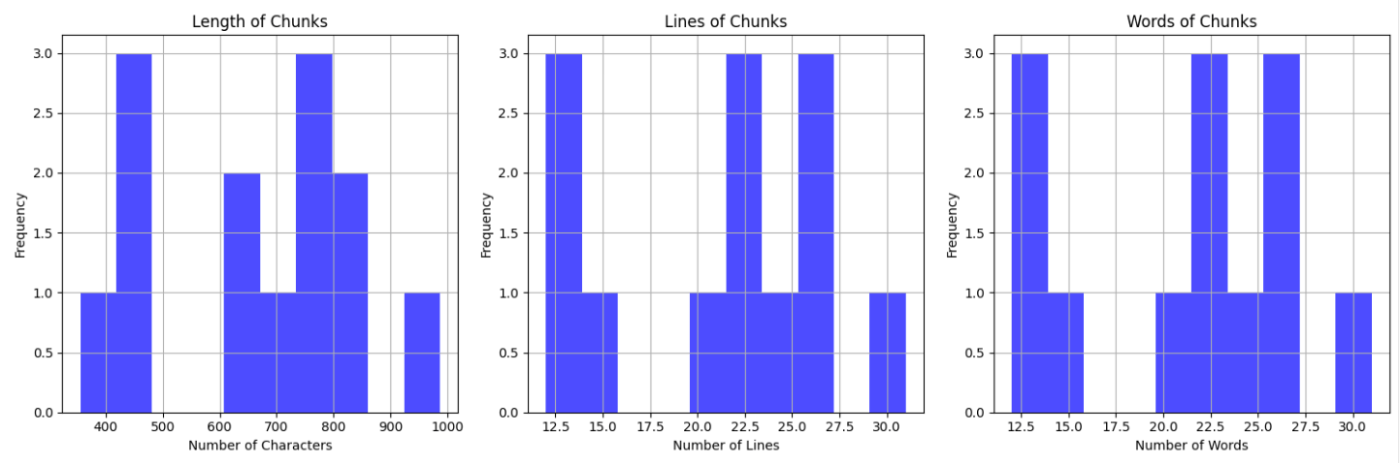
評価用データセットの件数は248件ということは、全部やると248 x top-k 3パターン x 手法 4パターン = 2976回のEmbedding APIリクエストは発生することになる(事前にチャンクデータセットのEmbeddingとContextual EmbeddingのためのLLMアクセスもかかる)ので、それなりにコストは掛かるかな。ほとんどEmbeddingだろうし、LLMもHaikuだから、そこまで大した金額ではないとは思うけど。
notebookの流れ
こんな感じで、積み上げていってそれぞれで評価している様子。
- 単純なEmbedding(Voyage voyage-2)での評価
- Contextual Embeddings(Voyage voyage-2+Anthropic claude-3-haiku)での評価
- 2にContextual BM25(ElasticSearch)を組み合わせたハイブリッドでの評価
- 3にリランキング(Cohere rerank-english-v3.0")を組み合わせた上での評価
よって、
- Anthropic APIキー
- Voyage APIキー
- Cohere APIキー
が事前に必要になる。
評価結果
notebookに書かれている評価結果
| No | 手法 | Pass@5 | Pass@10 | Pass@20 |
|---|---|---|---|---|
| 1 | 単純なEmbeddingのみ | 0.8092 | 0.8715 | 0.9006 |
| 2 | Contextual Embeddings | 0.8637 | 0.9281 | 0.9378 |
| 3 | Contextual Embeddings+Contextual BM25 | 0.8643 | 0.9321 | 0.9499 |
| 4 | Contextual Embeddings+Contextual BM25 + Rerank | 0.9124 | 0.9479 | 0.9630 |
Claude Artifactsに可視化してもらった
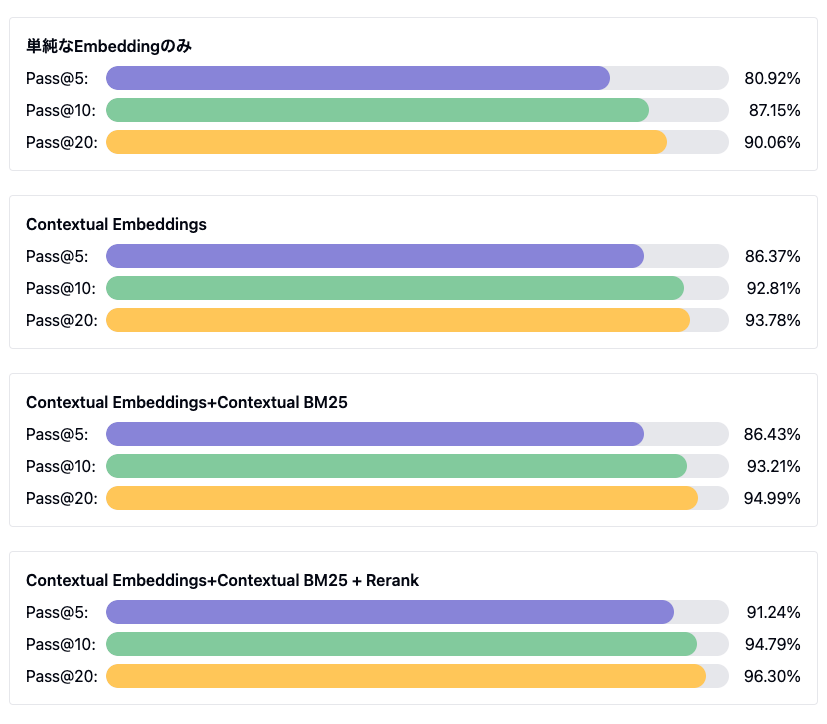
Contextual Embeddingsにするだけでtop-kに関係なく全体的に性能が上がってる。リランキングはpass@5の時の性能向上が高い。BM25は小さな向上という感じだけど、pass@20で一番上ってる感じに見える。
ちなみに少しColaboraotryで試してみたんだけど、
Prompt Caching
ドキュメントのコンテキストを全部含めてチャンクの説明を生成させる際、Prompt Cachingはたしかに効果的
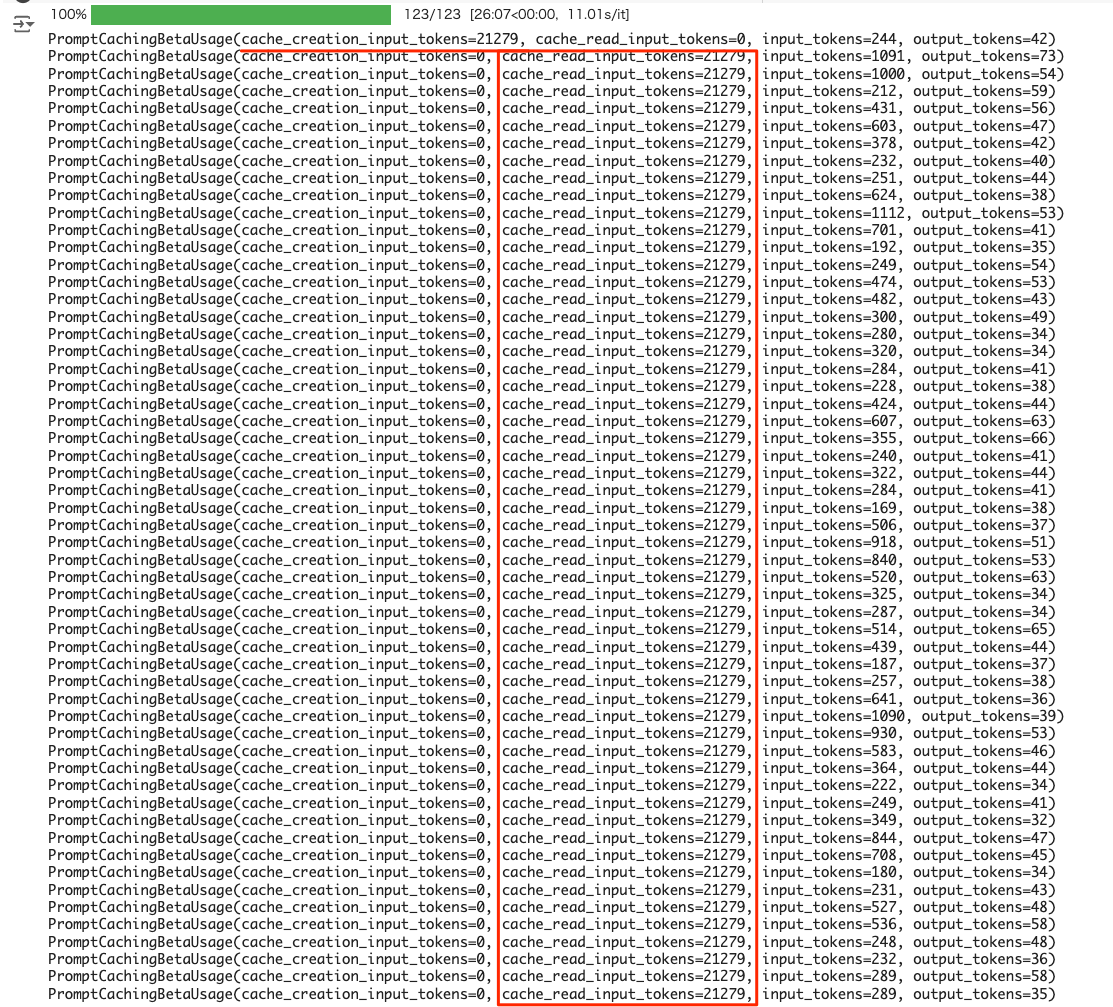
rate limit
どうやって計算しているのかわからないけども、全体コンテキストを常に食わせるとなると、当然ながらトークン処理量は増えると思われる。
自分の場合はTier1だったのだけども、Tier1の「1日あたりのトークン処理量」のrate limitに当たって、課金してTier2に上げたら、それにも当たってしまった。
Tierを上げるための要件
利用プラン クレジット購入 最初の購入後の待ち時間 1か月あたりの最大利用量 Build Tier1 $5 0日 $100 Build Tier2 $40 7日 $500 Build Tier3 $200 7日 $1,000 Build Tier4 $400 14日 $5,000 Scale N/A N/A N/A
Haikuを使ったんだけど、HaikuのTierごとのRate Limitをまとめるとこう
| Tier | 1分あたりのリクエスト数(RPM) | 1分あたりのトークン数(TPM) | 1日あたりのトークン数(TPD) |
|---|---|---|---|
| Tier1 | 50 | 50,000 | 5,000,000 |
| Tier2 | 1,000 | 100,000 | 25,000,000 |
| Tier3 | 2,000 | 200,000 | 50,000,000 |
| Tier4 | 4,000 | 400,000 | 100,000,000 |
Prompt Cachingを使っている場合に、このあたりが緩和されて計算されたり、みたいなのがあるのかないのかもわからないけど、ドキュメント量によっては、課金してTier上げておかないとちょっと難しい場合があるかもしれない。
レスポンス速度
自分が試したときはシーケンシャルに処理してたのだけども、Prompt Cachingを使用している場合でも、キャッシュサイズによってレスポンス時間が変わってくる。当然、キャッシュサイズが大きいほうが時間がかかる感じ。
これぐらいのキャッシュ量だと、1リクエストに1秒かかっていない
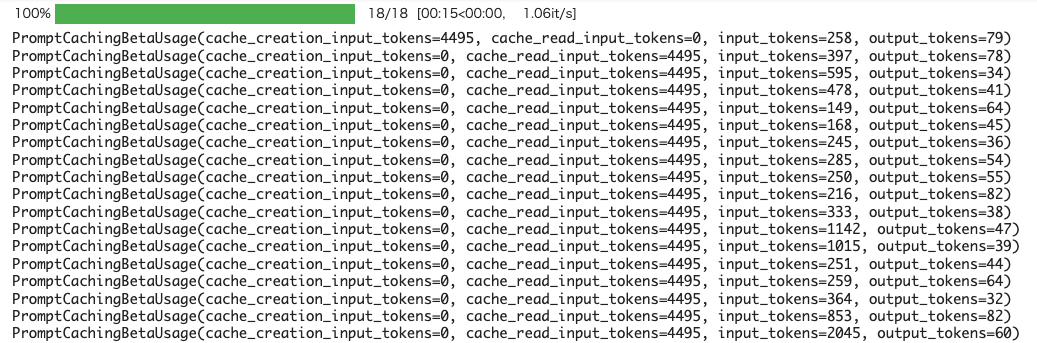
キャッシュ量が増えると1リクエストあたりの時間が伸びている。以下だと12秒ぐらい。
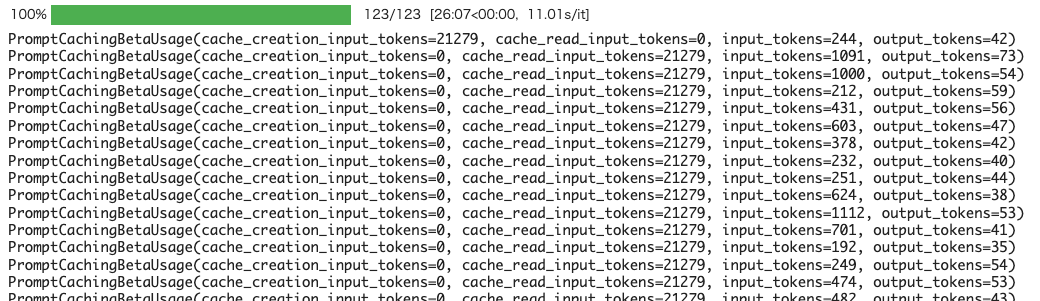
更に増えるとより時間が伸びる。以下だと30秒以上かかっている
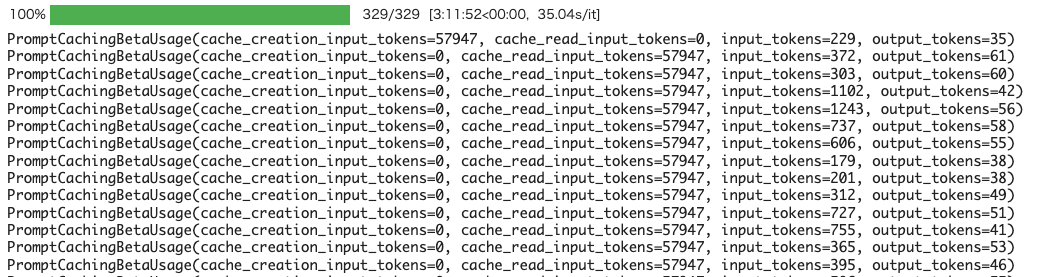
キャッシュを踏まえつつ、並列でやるようにしたほうが良さそう。
とりあえず日本語での評価した結果を見てみたいところだけど、こういうのにマッチするような日本語の文書検索データセットないかな???
Prompt Cachingのユースケースとしては確かに合ってるけど、retrievalの精度を上げる仕組みとしての評価は、日本語での評価結果を見てみないと判断できない気がする。