日本語翻訳評価に使えそうな対訳コーパスを色々見てみる
すごくまとまっている
各コーパスについて、詳細は後述しますが、それぞれの大まかな印象は以下のような感じです。
- TED字幕:品質がとてもよく、口語調のサンプルが手に入るのもいい。
- 青空文庫等の小説:データの加工が多少必要だが、文章の品質がいい。後述の処理によって比較的長文のサンプルが手に入ってよかった。
- 京都Wiki:訳文はしっかりしてて件数も多いが、内容が偏り過ぎ。
- 映画字幕:件数が膨大だが、1つ1つが短く、意訳も多いという癖がある。
- 田中コーパス:品質がいいだけに、14万件しかないのが惜しい。
- 法令対訳コーパス:内容が偏るが、品質はとてもいい。あと「長文」サンプルが稼げる。
- JparaCrawl:件数が2500万と大きいが、品質はいまいち。
- Wikimatrix(元データは85万1706件/うち58万0375件使用)*9
- Coursera(元データは5万3166件/うち5万2614件使用)*10
- OSSマニュアル(元データは40万3366件/うち26万2067件使用)*11
- ASPEC(元データは300万8500件/うち165万9318件使用)*12
*9:FacebookがWikipediaから作っている多言語の対訳コーパスのうち、英-日分を抜き出したもの。対訳の品質はけっこう良い。
*10:教育分野の話し言葉の対訳コーパスで、品質的にはとても綺麗。1文1文が短いのと、データ量が少ないのが惜しい。
*11:オープンソースのソフトウェアの説明書の対訳データ
*12:学術論文のアブストラクトのデータ。オンライン申請が必要だがすぐにもらえます。
- LASER/tasks/WikiMatrix at main · facebookresearch/LASER · GitHub
Wikipediaから作られた多言語の対訳データで、英語と日本語の組み合わせをみると85万1000件ある。
これは中身も少し整理してみたが、結構品質は高い。明らかに変なデータも混じっていたり、日本語と英語が対応していないものもあったりするが、全体としては綺麗だと思う。
公式のGitHubによると、両言語の意味の一致度を機械的に判定したスコアがついてて、多くの言語において1.04ぐらいがバランスがいい(一致度とサンプルの多様性を考慮して)と書いてあった。私は、1.45にしてから、日本語と英語の文字量の比率が極端なものや、日本文が句点で終わらないもの、英文が大文字で始まらないものを除いて、40数万件を使おうかなと思う。- 日本語SNLI(JSNLI)データセット - LANGUAGE MEDIA PROCESSING LAB
スタンフォード大がつくっている、自然言語処理による論理的な推論のベンチマークに使われるデータを日本語に機械翻訳したものらしいので、野生の対訳データではない。機械翻訳した後、BLEUスコアの閾値でフィルタリングしたデータが533,005件あって、これで自然言語タスクをやらせたら90%以上の性能があったと書いてある。
人力で訳を確認したものもあるがそれは数千件(devデータとして作られている)。
こっちは、本家SNLIのデータとこのJSNLIのデータを紐付ける作業からやらないといけなくて、加工がけっこうたいへんそうな気がする。
なお、クリーニングで使用したスクリプトも紹介されている。
上記のサイトで使用されている各データの諸元はここが多いように思える。
興味が出たので、実際に触ってみる。
あと、自分の場合はLLMによる翻訳タスクを、いろいろなバリエーションで「個人的」に「評価」したいというのが目的で、学習用途ではない。(とはいえ、評価用データセットとして公開するとかになるとライセンスとかも考慮しないといけないのだけども)
TED字幕
multitarget-ted.tgz(version 0.2)をダウンロード。
$ wget https://www.cs.jhu.edu/~kevinduh/a/multitarget-tedtalks/multitarget-ted.tgz
$ tar zxvf multitarget-ted.tgz && cd multitarget-ted
構成はこんな感じ。日本語はen-ja以下にある。
$ tree
.
├── README.txt
├── en-ar
│ │
| (snip)
├── en-bg
│ │
| (snip)
├── en-cs
│ │
| (snip)
(snip)
├── en-ja
│ ├── raw
│ │ ├── ted_dev_en-ja.raw.en
│ │ ├── ted_dev_en-ja.raw.ja
│ │ ├── ted_test1_en-ja.raw.en
│ │ ├── ted_test1_en-ja.raw.ja
│ │ ├── ted_train_en-ja.raw.en
│ │ └── ted_train_en-ja.raw.ja
│ └── tok
│ ├── ted_dev_en-ja.tok.en
│ ├── ted_dev_en-ja.tok.ja
│ ├── ted_dev_en-ja.tok.seekvideo
│ ├── ted_test1_en-ja.tok.en
│ ├── ted_test1_en-ja.tok.ja
│ ├── ted_test1_en-ja.tok.seekvideo
│ ├── ted_train_en-ja.tok.clean.en
│ ├── ted_train_en-ja.tok.clean.ja
│ ├── ted_train_en-ja.tok.clean.seekvideo
│ ├── ted_train_en-ja.tok.en
│ └── ted_train_en-ja.tok.ja
(snip)
├── stats.txt
└── talkids
├── shared-dev.txt
├── shared-test1.txt
├── ted_en.xml
├── trainid.en-ar
├── trainid.en-bg
(snip)
├── trainid.en-ja
(snip)
├── trainid.en-vi
└── trainid.en-zh
58 directories, 347 files
各言語ペアのディレクトリ配下の各ファイルについてはREADME.txtに記載がある。
en-${lang}/
raw/ # raw sentences: extracted from WIT3 and sentence merged.
ted_train_en-${lang}.raw.$lang # training bitext, foreign side
ted_train_en-${lang}.raw.en # training bitext, english side
ted_dev_en-${lang}.raw.$lang # dev bitext, foreign side
ted_dev_en-${lang}.raw.en # dev english (same regardless of ${lang})
ted_test1_en-${lang}.raw.$lang # test bitext, foreign side
ted_test1_en-${lang}.raw.en # test english (same regardless of ${lang}
tok/ # tokenized version of sentences in raw/
ted_train_en-${lang}.tok.$lang # training bitext, foreign side
ted_train_en-${lang}.tok.en # training bitext, english side
ted_train_en-${lang}.tok.clean.$lang # filtered train above, max 80 words
ted_train_en-${lang}.tok.clean.en # filtered train above, max 80 words
ted_dev_en-${lang}.tok.$lang # dev bitext
ted_dev_en-${lang}.tok.en # dev bitext
ted_test1_en-${lang}.tok.$lang # test bitext
ted_test1_en-${lang}.tok.en # test bitext
en-ja/row/ted_train_en-ja.raw.(ja|en)をみてみると、2ファイルの各行がペアになっているっぽい。
$ head en-ja/raw/ted_train_en-ja.raw.{ja,en}
==> en-ja/raw/ted_train_en-ja.raw.ja <==
(拍手) デイビッド:彼はビル・ラング 私はデイブ・ガロです
ビデオをお見せして海について話をしようと思います
我々はタイタニックの映像の中でも特に素晴らしい物を持っています そしてそれは今日お見せしません
(笑) タイタニックは実際に 興行収入の記録は打ち立てましたが 海洋における最もエキサイティングな話ではないんです
海が当然のものと思われていることが問題です
考えてみれば海は地球の75%を占めており
地球の大半は海です
その深さは平均で約4kmですよ
私の思う問題の一部は 海岸に立ったり 海を想像して 広大な青を臨むと海面はきらめきそして 動いています 波が寄せては返し 流れもあります でもそこに何が眠っているかは知らないのです
海底には地球上最長の山脈があります
==> en-ja/raw/ted_train_en-ja.raw.en <==
(Applause) David Gallo: This is Bill Lange. I'm Dave Gallo.
And we're going to tell you some stories from the sea here in video.
We've got some of the most incredible video of Titanic that's ever been seen, and we're not going to show you any of it.
(Laughter) The truth of the matter is that the Titanic -- even though it's breaking all sorts of box office records -- it's not the most exciting story from the sea.
And the problem, I think, is that we take the ocean for granted.
When you think about it, the oceans are 75 percent of the planet.
Most of the planet is ocean water.
The average depth is about two miles.
Part of the problem, I think, is we stand at the beach, or we see images like this of the ocean, and you look out at this great big blue expanse, and it's shimmering and it's moving and there's waves and there's surf and there's tides, but you have no idea for what lies in there.
And in the oceans, there are the longest mountain ranges on the planet.
ちなみにtokディレクトリ以下はトークンで分割されたものになっている。
$ head en-ja/tok/ted_train_en-ja.tok.{ja,en}
==> en-ja/tok/ted_train_en-ja.tok.ja <==
( 拍手 ) デイビッド : 彼 は ビル ・ ラング 私 は デイブ ・ ガロ で す
ビデオ を お 見せ し て 海 に つ い て 話 を し よう と 思 い ま す
我々 は タイタニック の 映像 の 中 で も 特に 素晴らし い 物 を 持 っ て い ま す そして それ は 今日 お 見せ し ま せ ん
( 笑 ) タイタニック は 実際 に 興行 収入 の 記録 は 打ち立て ま し た が 海洋 に お け る 最も エキサイティング な 話 で は な い ん で す
海 が 当然 の もの と 思 わ れ て い る こと が 問題 で す
考え て み れ ば 海 は 地球 の 75 % を 占め て お り
地球 の 大半 は 海 で す
その 深 さ は 平均 で 約 4 km で す よ
私 の 思 う 問題 の 一部 は 海岸 に 立 っ たり 海 を 想像 し て 広大 な 青 を 臨 む と 海面 は きらめき そして 動 い て い ま す 波 が 寄せ て は 返 し 流れ も あ り ま す で も そこ に 何 が 眠 っ て い る か は 知 ら な い の で す
海底 に は 地球 上 最長 の 山脈 が あ り ま す
==> en-ja/tok/ted_train_en-ja.tok.en <==
-lrb- applause -rrb- david gallo : this is bill lange . i 'm dave gallo .
and we 're going to tell you some stories from the sea here in video .
we 've got some of the most incredible video of titanic that 's ever been seen , and we 're not going to show you any of it .
-lrb- laughter -rrb- the truth of the matter is that the titanic - even though it 's breaking all sorts of box office records - it 's not the most exciting story from the sea .
and the problem , i think , is that we take the ocean for granted .
when you think about it , the oceans are 75 percent of the planet .
most of the planet is ocean water .
the average depth is about two miles .
part of the problem , i think , is we stand at the beach , or we see images like this of the ocean , and you look out at this great big blue expanse , and it 's shimmering and it 's moving and there 's waves and there 's surf and there 's tides , but you have no idea for what lies in there .
and in the oceans , there are the longest mountain ranges on the planet .
紹介されていたサイトのスクリプトで整形すれば良さそう。
所感
なるほど、たしかに口語調の翻訳データセットは貴重かもしれない。翻訳のガイドラインがきちんと定義されていてレビューなどのプロセスがあることも、一定の品質が担保されていると考えて良さそう。
ただ、見た感じ、
- 字幕で使うというところが目的のようなので、文章が短くなってしまう。
- 複数のTEDの講演が含まれているが、それについての区切りがなく、どの講演の翻訳なのか?がわからない。
- tokにあるseekvideoでおそらく特定はできるのだけど、そうなるとtokファイル以下のトークン分割された翻訳データと突き合わせが必要になる。
- tokの翻訳データはトークン分割されていて、日本語は句読点がない・英語は元々スペース区切りなところにトークン分割されたスペースが入ってしまう、ので、いい感じに結合するのは結構辛い
というところが辛い、というか、もったいない。せっかく、一定のコンテキストで長文にできそうなんだけどな。せめて空行1行挟んでくれていれば、、、元々の目的が「字幕」みたいなのでしょうがないところではある。
文字の長さはこんな感じ。

短いのが悪いというわけじゃないけど、1段落で300文字ぐらいのデータにするとそこそこコンテキスト入りそうなので翻訳も変わってくると思うんだけどな。
いっそ前処理の時点でAIに任せてしまうというのもありなのかもしれない。
ちなみにTEDの翻訳はcaptionhubというプラットフォームを使っている様子
上でも書いた通り、プロセスがきちんとしているし
AIをドラフトに使ってその後人間の手で修正やレビューが行われている様子。
ここが使いやすい形でデータだしてくれるといいんだけどな。
ライセンスはCC-BY-NC-NDなので、商用利用も改変もできない。
あと、talkids/ted_en.xmlを見てみると、こんな感じでデータが入っている。
<file id="942">
<head>
<url>http://www.ted.com/talks/karen_bass_unseen_footage_untamed_nature</url>
<pagesize>79946</pagesize>
<dtime>Thu Jan 28 14:29:16 CET 2016</dtime>
<encoding>UTF-8</encoding>
<content-type>text/html; charset=utf-8</content-type>
<keywords>talks, TED Conference, animals, film, nature, science</keywords>
<speaker>Karen Bass</speaker>
<talkid>1442</talkid>
<videourl>http://download.ted.com/talks/KarenBass_2012.mp4</videourl>
<videopath>talks/KarenBass_2012.mp4</videopath>
<date>2012/03/01</date>
<title>Karen Bass: Unseen footage, untamed nature</title>
<description>TED Talk Subtitles and Transcript: At TED2012, filmmaker Karen Bass shares some of the astonishing nature footage she's shot for the BBC and National Geographic -- including brand-new, previously unseen footage of the tube-lipped nectar bat, who feeds in a rather unusual way …</description>
<transcription>
<seekvideo id="750">I'm a very lucky person.</seekvideo>
<seekvideo id="4059">I've been privileged to see so much of our beautiful Earth</seekvideo>
<seekvideo id="8537">and the people and creatures that live on it.</seekvideo>
<seekvideo id="10865">And my passion was inspired at the age of seven,</seekvideo>
<seekvideo id="14485">when my parents first took me to Morocco,</seekvideo>
<seekvideo id="16820">at the edge of the Sahara Desert.</seekvideo>
<seekvideo id="18946">Now imagine a little Brit</seekvideo>
<seekvideo id="21321">somewhere that wasn't cold and damp like home.</seekvideo>
<seekvideo id="24442">What an amazing experience.</seekvideo>
<seekvideo id="26718">And it made me want to explore more.</seekvideo>
<seekvideo id="29211">So as a filmmaker,</seekvideo>
<seekvideo id="31814">I've been from one end of the Earth to the other</seekvideo>
<seekvideo id="34625">trying to get the perfect shot</seekvideo>
<seekvideo id="37333">and to capture animal behavior never seen before.</seekvideo>
<seekvideo id="41125">And what's more, I'm really lucky,</seekvideo>
<seekvideo id="43757">because I get to share that with millions of people worldwide.</seekvideo>
<seekvideo id="46875">Now the idea of having new perspectives of our planet</seekvideo>
<seekvideo id="52125">and actually being able to get that message out</seekvideo>
<seekvideo id="55958">gets me out of bed every day with a spring in my step.</seekvideo>
<seekvideo id="58816">You might think that it's quite hard</seekvideo>
<seekvideo id="61958">to find new stories and new subjects,</seekvideo>
<seekvideo id="64208">but new technology is changing the way we can film.</seekvideo>
<seekvideo id="68539">It's enabling us to get fresh, new images</seekvideo>
<seekvideo id="72375">and tell brand new stories.</seekvideo>
<seekvideo id="74492">In Nature's Great Events,</seekvideo>
<seekvideo id="77375">a series for the BBC that I did with David Attenborough,</seekvideo>
<seekvideo id="80917">we wanted to do just that.</seekvideo>
<seekvideo id="83167">Images of grizzly bears are pretty familiar.</seekvideo>
<seekvideo id="86208">You see them all the time, you think.</seekvideo>
<seekvideo id="89458">But there's a whole side to their lives that we hardly ever see</seekvideo>
<seekvideo id="93542">and had never been filmed.</seekvideo>
<seekvideo id="95250">So what we did, we went to Alaska,</seekvideo>
<seekvideo id="99500">which is where the grizzlies rely</seekvideo>
<seekvideo id="101868">on really high, almost inaccessible, mountain slopes</seekvideo>
<seekvideo id="104854">for their denning.</seekvideo>
<seekvideo id="106789">And the only way to film that is a shoot from the air.</seekvideo>
<seekvideo id="114304">(Video) David Attenborough: Throughout Alaska and British Columbia,</seekvideo>
<seekvideo id="118917">thousands of bear families are emerging from their winter sleep.</seekvideo>
<seekvideo id="124129">There is nothing to eat up here,</seekvideo>
<seekvideo id="128083">but the conditions were ideal for hibernation.</seekvideo>
<seekvideo id="131583">Lots of snow in which to dig a den.</seekvideo>
<seekvideo id="139450">To find food, mothers must lead their cubs down to the coast,</seekvideo>
<seekvideo id="145440">where the snow will already be melting.</seekvideo>
<seekvideo id="152502">But getting down can be a challenge for small cubs.</seekvideo>
<seekvideo id="185723">These mountains are dangerous places,</seekvideo>
<seekvideo id="189458">but ultimately the fate of these bear families,</seekvideo>
<seekvideo id="192917">and indeed that of all bears around the North Pacific,</seekvideo>
<seekvideo id="196431">depends on the salmon.</seekvideo>
<seekvideo id="201064">KB: I love that shot.</seekvideo>
<seekvideo id="203625">I always get goosebumps every time I see it.</seekvideo>
<seekvideo id="205917">That was filmed from a helicopter</seekvideo>
<seekvideo id="207958">using a gyro-stabilized camera.</seekvideo>
<seekvideo id="210750">And it's a wonderful bit of gear,</seekvideo>
<seekvideo id="213208">because it's like having a flying tripod, crane and dolly all rolled into one.</seekvideo>
<seekvideo id="217167">But technology alone isn't enough.</seekvideo>
<seekvideo id="220375">To really get the money shots,</seekvideo>
<seekvideo id="222875">it's down to being in the right place at the right time.</seekvideo>
<seekvideo id="225917">And that sequence was especially difficult.</seekvideo>
<seekvideo id="228875">The first year we got nothing.</seekvideo>
<seekvideo id="232375">We had to go back the following year,</seekvideo>
<seekvideo id="235958">all the way back to the remote parts of Alaska.</seekvideo>
<seekvideo id="238958">And we hung around with a helicopter for two whole weeks.</seekvideo>
<seekvideo id="241583">And eventually we got lucky.</seekvideo>
<seekvideo id="244625">The cloud lifted, the wind was still,</seekvideo>
<seekvideo id="248958">and even the bear showed up.</seekvideo>
<seekvideo id="250708">And we managed to get that magic moment.</seekvideo>
<seekvideo id="253292">For a filmmaker,</seekvideo>
<seekvideo id="255167">new technology is an amazing tool,</seekvideo>
<seekvideo id="259340">but the other thing that really, really excites me</seekvideo>
<seekvideo id="262546">is when new species are discovered.</seekvideo>
<seekvideo id="265500">Now, when I heard about one animal,</seekvideo>
<seekvideo id="267787">I knew we had to get it for my next series,</seekvideo>
<seekvideo id="270750">Untamed Americas, for National Geographic.</seekvideo>
<seekvideo id="273500">In 2005, a new species of bat was discovered</seekvideo>
<seekvideo id="279811">in the cloud forests of Ecuador.</seekvideo>
<seekvideo id="282083">And what was amazing about that discovery</seekvideo>
<seekvideo id="284167">is that it also solved the mystery</seekvideo>
<seekvideo id="286583">of what pollinated a unique flower.</seekvideo>
<seekvideo id="289620">It depends solely on the bat.</seekvideo>
<seekvideo id="291583">Now, the series hasn't even aired yet,</seekvideo>
<seekvideo id="294317">so you're the very first to see this.</seekvideo>
<seekvideo id="296744">See what you think.</seekvideo>
<seekvideo id="301590">(Video) Narrator: The tube-lipped nectar bat.</seekvideo>
<seekvideo id="310536">A pool of delicious nectar</seekvideo>
<seekvideo id="312877">lies at the bottom of each flower's long flute.</seekvideo>
<seekvideo id="315042">But how to reach it?</seekvideo>
<seekvideo id="319887">Necessity is the mother of evolution.</seekvideo>
<seekvideo id="325083">(Music)</seekvideo>
<seekvideo id="348489">This two-and-a-half-inch bat</seekvideo>
<seekvideo id="351496">has a three-and-a-half-inch tongue,</seekvideo>
<seekvideo id="358221">the longest relative to body length</seekvideo>
<seekvideo id="362119">of any mammal in the world.</seekvideo>
<seekvideo id="364438">If human, he'd have a nine-foot tongue.</seekvideo>
<seekvideo id="376122">(Applause)</seekvideo>
<seekvideo id="378612">KB: What a tongue.</seekvideo>
<seekvideo id="380677">We filmed it by cutting a tiny little hole in the base of the flower</seekvideo>
<seekvideo id="385542">and using a camera that could slow the action by 40 times.</seekvideo>
<seekvideo id="390167">So imagine how quick that thing is in real life.</seekvideo>
<seekvideo id="393250">Now people often ask me, "Where's your favorite place on the planet?"</seekvideo>
<seekvideo id="398462">And the truth is I just don't have one.</seekvideo>
<seekvideo id="400995">There are so many wonderful places.</seekvideo>
<seekvideo id="403542">But some locations draw you back time and time again.</seekvideo>
<seekvideo id="407042">And one remote location --</seekvideo>
<seekvideo id="409790">I first went there as a backpacker;</seekvideo>
<seekvideo id="411810">I've been back several times for filming,</seekvideo>
<seekvideo id="414125">most recently for Untamed Americas --</seekvideo>
<seekvideo id="415875">it's the Altiplano in the high Andes of South America,</seekvideo>
<seekvideo id="420625">and it's the most otherworldly place I know.</seekvideo>
<seekvideo id="425792">But at 15,000 feet, it's tough.</seekvideo>
<seekvideo id="428894">It's freezing cold,</seekvideo>
<seekvideo id="430417">and that thin air really gets you.</seekvideo>
<seekvideo id="435083">Sometimes it's hard to breathe,</seekvideo>
<seekvideo id="437394">especially carrying all the heavy filming equipment.</seekvideo>
<seekvideo id="440437">And that pounding head just feels like a constant hangover.</seekvideo>
<seekvideo id="445042">But the advantage of that wonderful thin atmosphere</seekvideo>
<seekvideo id="449333">is that it enables you to see the stars in the heavens</seekvideo>
<seekvideo id="453271">with amazing clarity.</seekvideo>
<seekvideo id="455710">Have a look.</seekvideo>
<seekvideo id="459896">(Video) Narrator: Some 1,500 miles south of the tropics,</seekvideo>
<seekvideo id="463552">between Chile and Bolivia,</seekvideo>
<seekvideo id="465237">the Andes completely change.</seekvideo>
<seekvideo id="470413">It's called the Altiplano, or "high plains" --</seekvideo>
<seekvideo id="475042">a place of extremes</seekvideo>
<seekvideo id="478925">and extreme contrasts.</seekvideo>
<seekvideo id="482614">Where deserts freeze</seekvideo>
<seekvideo id="487125">and waters boil.</seekvideo>
<seekvideo id="490958">More like Mars than Earth,</seekvideo>
<seekvideo id="494458">it seems just as hostile to life.</seekvideo>
<seekvideo id="505196">The stars themselves --</seekvideo>
<seekvideo id="515065">at 12,000 feet, the dry, thin air</seekvideo>
<seekvideo id="518786">makes for perfect stargazing.</seekvideo>
<seekvideo id="526929">Some of the world's astronomers have telescopes nearby.</seekvideo>
<seekvideo id="532813">But just looking up with the naked eye,</seekvideo>
<seekvideo id="536885">you really don't need one.</seekvideo>
<seekvideo id="540130">(Music)</seekvideo>
<seekvideo id="587140">(Applause)</seekvideo>
<seekvideo id="593167">KB: Thank you so much</seekvideo>
<seekvideo id="596484">for letting me share some images</seekvideo>
<seekvideo id="598958">of our magnificent, wonderful Earth.</seekvideo>
<seekvideo id="601867">Thank you for letting me share that with you.</seekvideo>
<seekvideo id="603764">(Applause)</seekvideo>
</transcription>
<transcribers>
<transcriber href="http://www.ted.com/profiles/809235">Timothy Covell</transcriber>
</transcribers>
<reviewers>
<reviewer href="http://www.ted.com/profiles/1108408">Morton Bast</reviewer>
</reviewers>
<wordnum>978</wordnum>
<charnum>5407</charnum>
</head>
<content>I'm a very lucky person. I've been privileged to see so much of our beautiful Earth and the people and creatures that live on it. And my passion was inspired at the age of seven, when my parents first took me to Morocco, at the edge of the Sahara Desert. Now imagine a little Brit somewhere that wasn't cold and damp like home. What an amazing experience. And it made me want to explore more.
So as a filmmaker, I've been from one end of the Earth to the other trying to get the perfect shot and to capture animal behavior never seen before. And what's more, I'm really lucky, because I get to share that with millions of people worldwide. Now the idea of having new perspectives of our planet and actually being able to get that message out gets me out of bed every day with a spring in my step.
You might think that it's quite hard to find new stories and new subjects, but new technology is changing the way we can film. It's enabling us to get fresh, new images and tell brand new stories. In Nature's Great Events, a series for the BBC that I did with David Attenborough, we wanted to do just that.
Images of grizzly bears are pretty familiar. You see them all the time, you think. But there's a whole side to their lives that we hardly ever see and had never been filmed. So what we did, we went to Alaska, which is where the grizzlies rely on really high, almost inaccessible, mountain slopes for their denning. And the only way to film that is a shoot from the air.
(Video) David Attenborough: Throughout Alaska and British Columbia, thousands of bear families are emerging from their winter sleep. There is nothing to eat up here, but the conditions were ideal for hibernation. Lots of snow in which to dig a den. To find food, mothers must lead their cubs down to the coast, where the snow will already be melting. But getting down can be a challenge for small cubs. These mountains are dangerous places, but ultimately the fate of these bear families, and indeed that of all bears around the North Pacific, depends on the salmon.
KB: I love that shot. I always get goosebumps every time I see it. That was filmed from a helicopter using a gyro-stabilized camera. And it's a wonderful bit of gear, because it's like having a flying tripod, crane and dolly all rolled into one. But technology alone isn't enough. To really get the money shots, it's down to being in the right place at the right time. And that sequence was especially difficult.
The first year we got nothing. We had to go back the following year, all the way back to the remote parts of Alaska. And we hung around with a helicopter for two whole weeks. And eventually we got lucky. The cloud lifted, the wind was still, and even the bear showed up. And we managed to get that magic moment.
For a filmmaker, new technology is an amazing tool, but the other thing that really, really excites me is when new species are discovered. Now, when I heard about one animal, I knew we had to get it for my next series, Untamed Americas, for National Geographic. In 2005, a new species of bat was discovered in the cloud forests of Ecuador. And what was amazing about that discovery is that it also solved the mystery of what pollinated a unique flower. It depends solely on the bat.
Now, the series hasn't even aired yet, so you're the very first to see this. See what you think. (Video) Narrator: The tube-lipped nectar bat. A pool of delicious nectar lies at the bottom of each flower's long flute. But how to reach it? Necessity is the mother of evolution. (Music) This two-and-a-half-inch bat has a three-and-a-half-inch tongue, the longest relative to body length of any mammal in the world. If human, he'd have a nine-foot tongue. (Applause) KB: What a tongue. We filmed it by cutting a tiny little hole in the base of the flower and using a camera that could slow the action by 40 times. So imagine how quick that thing is in real life.
Now people often ask me, "Where's your favorite place on the planet?" And the truth is I just don't have one. There are so many wonderful places. But some locations draw you back time and time again. And one remote location -- I first went there as a backpacker; I've been back several times for filming, most recently for Untamed Americas -- it's the Altiplano in the high Andes of South America, and it's the most otherworldly place I know. But at 15,000 feet, it's tough. It's freezing cold, and that thin air really gets you. Sometimes it's hard to breathe, especially carrying all the heavy filming equipment. And that pounding head just feels like a constant hangover. But the advantage of that wonderful thin atmosphere is that it enables you to see the stars in the heavens with amazing clarity. Have a look.
(Video) Narrator: Some 1,500 miles south of the tropics, between Chile and Bolivia, the Andes completely change. It's called the Altiplano, or "high plains" -- a place of extremes and extreme contrasts. Where deserts freeze and waters boil. More like Mars than Earth, it seems just as hostile to life. The stars themselves -- at 12,000 feet, the dry, thin air makes for perfect stargazing. Some of the world's astronomers have telescopes nearby. But just looking up with the naked eye, you really don't need one. (Music) (Applause)
KB: Thank you so much for letting me share some images of our magnificent, wonderful Earth. Thank you for letting me share that with you. (Applause)</content>
</file>
rawは文書構造やメタデータ的な要素が全部とんでしまっているので、こっちをうまくつかえないだろうか?という気がした。
田中コーパス
日本語訳
このコーパスは、兵庫大学の田中靖人教授とその学生たちによって編纂されたもので、Pacling2001の論文に記載されている(論文では「過去編纂法」と表現されている)。田中教授はPacling2001でコーパスのコピーを公開し、パブリックドメインであることを表明した。Christian Boitet教授によると、田中教授はこのコレクションがあまり良い水準だとは思っていなかったようだ。(残念ながら、田中教授は2003年初めに亡くなった)。
田中教授の学生たちに与えられた課題は、一人300文型を集めることだった。数年後、212,000組の文が集まった。
調べてみると、文のペアの多くは、日本人の英語学習者が使う教科書などに由来しているようだ。あるものは歌の一節であり、またあるものはポピュラーな本や聖書の一節である。
オリジナル・コレクションには、日本語と英語の両方に多数の誤りがあった。誤りの多くはスペルミスや書き写しミスであったが、日本語と英語に文法的、構文的などの誤りがあったり、訳語がまったく一致しない場合もかなりあった。
前述したように、田中コーパスはWWWJDIC辞書サーバーの中で、辞書の単語に関連する例文のセットとして使用するために編集され、適応された。この役割に適応させるために、コーパスは次のように編集された:
日本語文と英語文の句読点の初期正則化が行われ、重複するペアが削除され、元のファイルは210,000ペアから180,000ペアに減少した;
- 正書法の違い(仮名遣い/漢字遣い、送り仮名の違いなど)、数字、固有名詞、平易な動詞/丁寧な動詞の用法など、文法的に細かい点が異なるだけの文章は、代表的な例文1つに絞った;
- 日本語が短い仮名文で構成されている文章は削除された;
- 誤字脱字、かな漢字変換ミスなどの文章を修正した;
- 英語版と日本語版が一致しない文章は、2つの版が一致するように編集された;
- 文に性別特有の言葉や単語が含まれている場合、英語部分にはそれぞれ[M]または[F]のタグが付けられている;
- 日本語が文字化けしすぎて、英語と同等の表現が導き出せない文章は削除された。
以上のようなプロセスを続け、現在、編集コーパスは15万強の文対を持つに至っている。
$ wget ftp://ftp.edrdg.org/pub/Nihongo/examples.utf.gz
$ gunzip examples.utf.gz
$ head examples.utf
中身はこんな感じ。
A: 彼は忙しい生活の中で家族と会うことがない。 He doesn't see his family in his busy life.#ID=303697_100000
B: 彼(かれ)[01] は 忙しい(いそがしい) 生活 の 中(なか) で(#2028980) 家族 と 会う[01] 事(こと){こと} が 無い{ない}
A: 彼は忙しい人だから、電話でなければ連絡をとれないですよ。 He is a busy man, so you can only get in touch with him by telephone.#ID=303696_100001
B: 彼(かれ)[01] は 忙しい(いそがしい) 人(ひと) だから 電話 でないと{でなければ} 連絡[01] を 取れる{とれない} です よ
A: 彼は忙しいので、君に会えない。 In as much as he is busy, he can't meet you.#ID=303695_100002
B: 彼(かれ)[01] は 忙しい(いそがしい) ので 君(きみ)[01] に 会う[01]{会えない}
A: 彼は忙しいと思ったが、それどころか暇だった。 I thought he was busy, but on the contrary he was idle.#ID=303694_100003
B: 彼(かれ)[01] は 忙しい(いそがしい) と 思う{思った} が それ処か{それどころか} 暇(ひま)[01] だ{だった}
A: 彼は忙しいと言いました。 He said he was busy.#ID=303693_100004
B: 彼(かれ)[01] は 忙しい(いそがしい) と 言う{言いました}
整形してpandasのデータフレームにしてみる。
import pandas as pd
lines = []
ja_sentences = []
en_sentences = []
with open("examples.utf", 'r', encoding='utf-8') as file:
lines = [line.strip() for line in file]
for l in lines:
if l.startswith("B: "):
continue
l = l.replace("A: ","");
ja_sentences.append(l.split("\t")[0])
en_sentences.append(l.split("\t")[1].split("#ID=")[0])
df = pd.DataFrame({'Japanese': ja_sentences, 'English': en_sentences})
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))
df.head(50)
ざっと見た感じ、きれいな訳には見える。

文字数を見てみる。
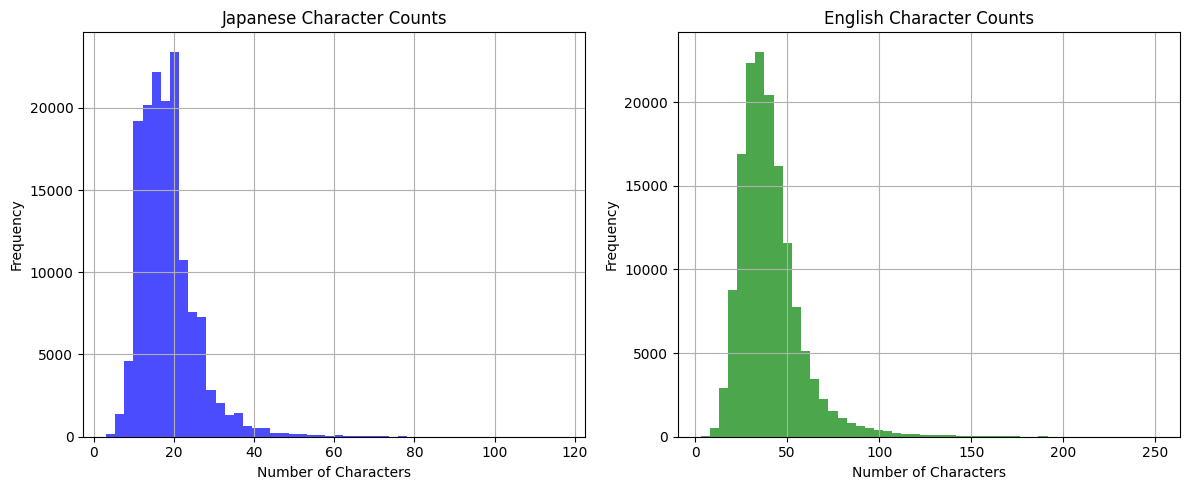
だいぶ短いなぁ。
パブリックドメイン、ってことでいいのかな?
小説等
日英対訳文対応付けデータ
当研究室では,著作権がクリアな文章について,日本語文と英語文との対訳文対応を付けています.なお,これらの作品の一部には,明示的な許可がない場合の二次配布が禁止されているものがありますので御注意下さい(詳細).
日英対訳文対応付けデータでは,Project Gutenberg や青空文庫やプロジェクト杉田玄白などの,原則として再配布が可能な作品を配布していますが,それ以外の作品についても,以下の人達が,日英対訳文対応付けデータでの作品の利用を許可してくれました.
- 北尾謙治,北尾S.キャスリーン
二次配布が禁止されている作品
以下の作品は,本サイトにおける公開については許可を頂きましたが,本サイト以外においての公開は,著者からの明示的な許可がない場合には,禁止されていますので,御注意下さい.なお,二次配布以外の利用条件については,オリジナルのテキストを御覧下さい.
- 北尾謙治,北尾S.キャスリーン.(1992) 「トラベル英会話」桐原書店.
- ことわざ / 北尾 謙治・北尾S.キャスリーン
$ wget https://www2.nict.go.jp/astrec-att/member/mutiyama/align/download/para.zip
$ unzip para.zip
日本語はShiftJISになってるのでUTF8に変換する。最初変換元エンコーディングにShift_JISを指定したらエラーになったので、試しにcp932にしてみたらエラーが無くなった。
$ !iconv -f cp932 -t utf8 para/ja.txt -o para/ja_utf8.txt
実データをざっと見てみる。
$ head -20 para/{en,ja_utf8}.txt
$ egrep -A 5 "^#" para/{en,ja_utf8}.txt | less # メタデータっぽい箇所を見る
-
#で作品の区切り - その後数行で作品タイトル、作者名といったメタデータになっているが、これが統一されていないので、メタデータを取るのは難しそう。
- 1行目が空行とか、メタデータがなくていきなり文章が始まるものとかがある。。。
- 日本語はトークン分割されているが、句読点はきちんと入っているので、単純にスペースを消せば良さそう。
- 日・英の各行はマッチはしているようだけど、脚注とかは日本語だけ、両方空行みたいなものもある
- 脚注は翻訳的にマッチしていないケースが多い。
という感じ。少なくとも#で区切られているということはまとまった単位のコンテキストが維持されるということではある。メタデータは流石にスクリプトだけじゃ厳しそう。
ということでこんな感じで読み込める。
import pandas as pd
ja_file = "para/ja.txt"
en_file = "para/en.txt"
en_sentences = []
ja_sentences = []
with open(ja_file, 'r', encoding="cp932") as file:
for line in file:
if not line.startswith("#####"):
ja_sentences.append(line.strip().replace(" ",""))
with open(en_file, 'r', encoding="latin1") as file:
for line in file:
if not line.startswith("#####"):
en_sentences.append(line.strip())
df = pd.DataFrame({"Japanese": ja_sentences, "English": en_sentences})
df.replace('', np.nan, inplace=True)
df.dropna(inplace=True)
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))
これで文字数を見るとちょっと異常なものが見られる(y軸が大きすぎてx軸が見えないので対数スケール化している)
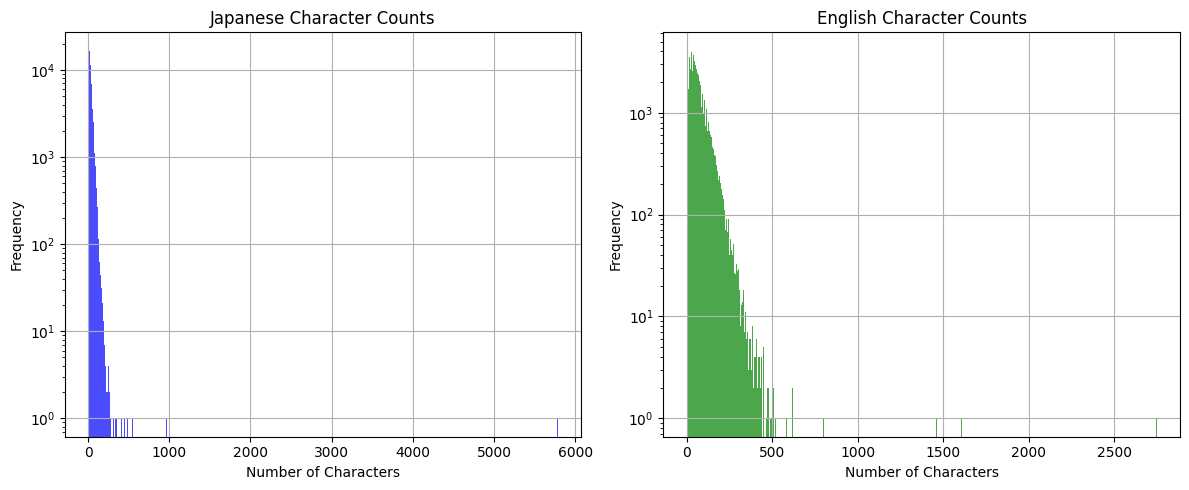
紹介されていたサイトにもある通り、URLが含まれるものは異常なデータが多いようだし、その場合、脚注に多い感がある。この辺を取り除いてやるほうがよさそう。
とりあえず雑に1000文字未満でフィルタしてみる。
df = df[(df["ja_char_len"] < 1000) & (df["en_char_len"] < 1000)]
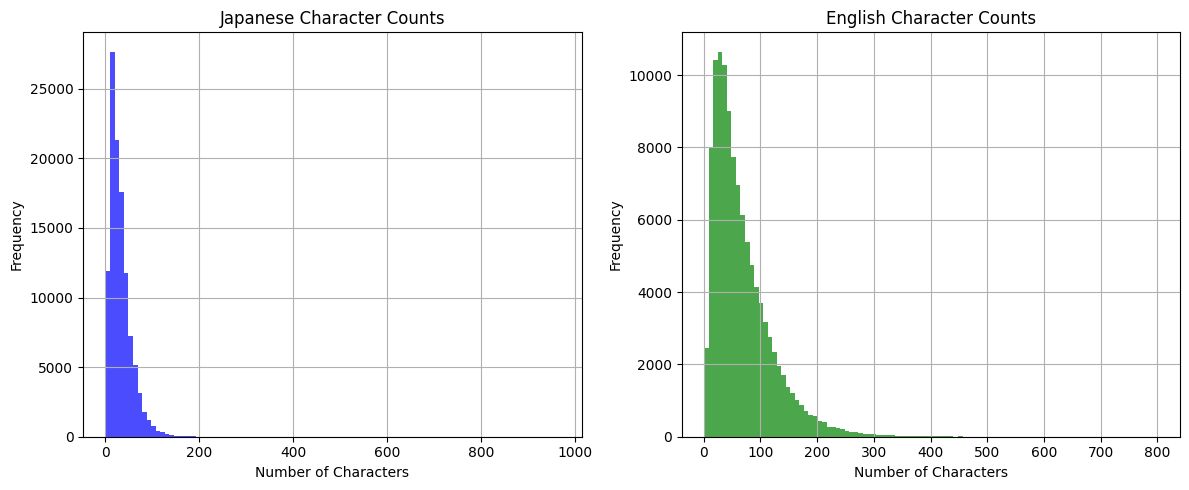
コンテキストはある程度固まってそうなので、紹介サイトにある通り、うまくまとめると長文にしやすそうではある。区切りもあるので。変にまたぐこともなさそうだし。
気になるのは、小説ベースなので日本語文章としての品質は良いのかもしれないけど、青空文庫とかだとちょっと古いものが多くなるのではないか?という気はする。プロジェクト杉田玄白、とかに限ったほうがいいのかもとは思うけど、そうなるとデータ量が少なくなりそう。
ライセンス周りは自分で使う分には問題なさそうだけど、公開データセットにしようと思うと、ちょっとめんどくさそう。
日英法令対訳コーパス
これは日本の法律に関する対訳コーパスです。下記のサイトからクロールしました:>http://www.japaneselawtranslation.go.jp/。約26万の対訳文を含んでいます。
コーパスはサイト上のこの文言に基づいて再配布可能です:
この「日本法令外国語訳データベースシステム」に掲載している全てのデータは、適宜 引用し、複製し、又は転載して差し支えありません。
$ wget https://www.phontron.com/jaen-law/jaen-law.tar.gz
$ tar zxvf jaen-law.tar.gz
law-corpus.{ja,en}の各行がマッチしている様子。
$ head jaen-law/txt/law-corpus.{ja,en}
中身はこんな感じ。
==> jaen-law/txt/law-corpus.ja <==
職業安定法
第一章 総則
(法律の目的)
第一条 この法律は、雇用対策法(昭和四十一年法律第百三十二号)と相まつて、公共に奉仕する公共職業安定所その他の職業安定機関が関係行政庁又は関係団体の協力を得て職業紹介事業等を行うこと、職業安定機関以外の者の行う職業紹介事業等が労働力の需要供給の適正かつ円滑な調整に果たすべき役割にかんがみその適正な運営を確保すること等により、各人にその有する能力に適合する職業に就く機会を与え、及び産業に必要な労働力を充足し、もつて職業の安定を図るとともに、経済及び社会の発展に寄与することを目的とする。
(職業選択の自由)
第二条 何人も、公共の福祉に反しない限り、職業を自由に選択することができる。
(均等待遇)
第三条 何人も、人種、国籍、信条、性別、社会的身分、門地、従前の職業、労働組合の組合員であること等を理由として、職業紹介、職業指導等について、差別的取扱を受けることがない。但し、労働組合法〔昭和二四年六月法律第一七四号〕の規定によつて、雇用主と労働組合との間に締結された労働協約に別段の定のある場合は、この限りでない。
(定義)
第四条 この法律において「職業紹介」とは、求人及び求職の申込みを受け、求人者と求職者との間における雇用関係の成立をあつせんすることをいう。
==> jaen-law/txt/law-corpus.en <==
Employment Security Act
Chapter 1 General Provisions
(Purpose of the Act)
Article 1 The purpose of this Act is, together with the Employment Countermeasures Act (Act No. 132 of 1966), to provide every person with an opportunity to obtain a job conformed to his/her ability and meet the labor needs of industry through the provision of employment placement businesses, etc. by Public Employment Security Offices and other employment security bodies serving the public, with the cooperation of related administrative agencies and related organizations, and through ensuring the appropriate operation of employment placement businesses etc. provided by persons other than employment security bodies in consideration of the role to be fulfilled by such persons in the appropriate and smooth adjustment of demand for and supply of a labor force, thereby achieving security of employment and contributing to the development of the economy and society.
(Freedom of Job Selection)
Article 2 Every person may freely choose any job, provided that it does not conflict with the public welfare.
(Equal Treatment)
Article 3 No one shall be discriminated against in employment placement, vocational guidance, or the like, by reason of race, nationality, creed, sex, social status, family origin, previous profession, membership of a labor union, etc.; provided, however, that this shall not apply in the case where the terms of a collective agreement entered into between an employer and a labor union in accordance with the Labor Union Act provide otherwise.
(Definitions)
Article 4 (1) The term "employment placement" as used in this Act means receiving offers for posting job offerings and offers for registering as a job seeker and extending services to establish employment relationships between job offerers and job seekers.
複数の法律文書が含まれているのだけど、法律ごとには分かれていない。ただしっかりしたデータのようでパース処理のようなものはほとんど不要に見える。
import pandas as pd
import numpy as np
ja_file = "jaen-law/txt/law-corpus.ja"
en_file = "jaen-law/txt/law-corpus.en"
en_sentences = []
ja_sentences = []
with open(ja_file, 'r') as file:
ja_sentences = [line.strip() for line in file]
with open(en_file, 'r') as file:
en_sentences = [line.strip() for line in file]
df = pd.DataFrame({"Japanese": ja_sentences, "English": en_sentences})
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))
ただ、めちゃめちゃ長い行が出てくる。
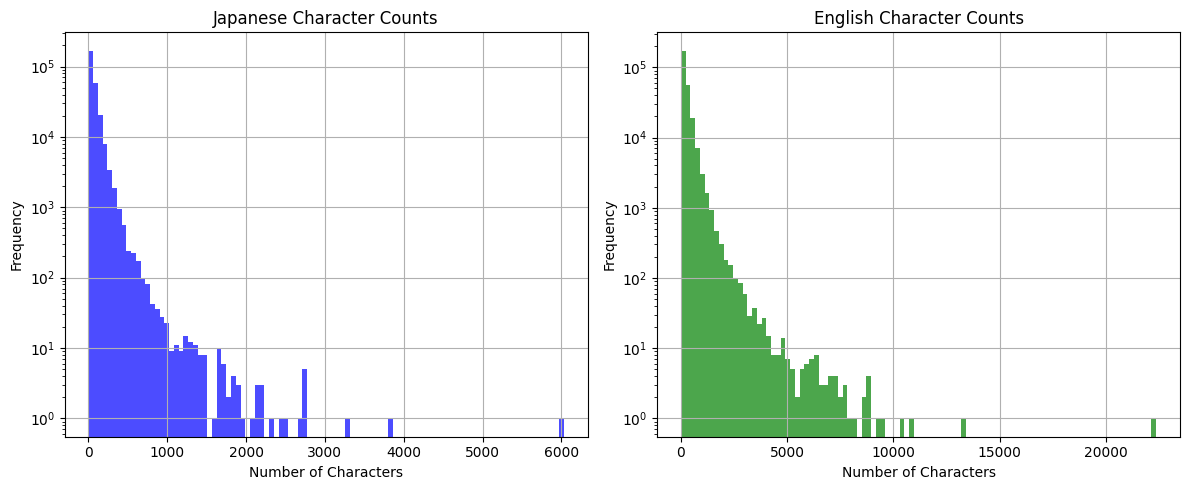
外れ値かと思いきや、「第◯条、第△条、・・・」みたいなのが多数記載されていて、本当に長いのだった。
第二十五条 第十八条第一項から第六項まで、第二十一条、第二十二条第一項及び第六項、第二十三条、第二十四条並びに第二十四条の四から第二十四条の八までの規定は、法第三十三条第一項の許可を受けて行う無料の職業紹介事業及び同項の許可を受けた者について準用する。この場合において、第十八条第一項中「第三十条第二項」とあるのは「第三十三条第四項において準用する法第三十条第二項」と、「有料職業紹介事業許可申請書(様式第一号)」とあるのは「無料職業紹介事業許可申請書(様式第一号)」と、第十八条第二項中「第三十条第二項第五号」とあるのは「第三十三条第四項において準用する法第三十条第二項第五号」と、第十八条第三項中「第三十条第三項」とあるのは「第三十三条第四項において準用する法第三十条第三項」と、第十八条第四項中「第三十条第三項」とあるのは「第三十三条第四項において準用する法第三十条第三項」と、「有料職業紹介事業計画書(様式第二号)」とあるのは「無料職業紹介事業計画書(様式第二号)」と、第十八条第五項中「第三十三条第一項」とあるのは「第三十条第一項」と、「第三十条第一項」とあるのは「第三十三条第一項」と、第十八条第六項中「第三十三条第一項」とあるのは「第三十条第一項」と、「第三十条第一項」とあるのは「第三十三条第一項」と、「無料の職業紹介事業」とあるのは「有料の職業紹介事業」と、第二十一条第一項中「第三十二条の四第一項」とあるのは「第三十三条第四項において準用する法第三十二条の四第一項」と、「有料職業紹介事業許可証(様式第五号。以下「有料許可証」という。)」とあるのは「無料職業紹介事業許可証(様式第五号。以下「無料許可証」という。)」と、第二十一条第二項中「第三十二条の四第三項」とあるのは「第三十三条第四項において準用する法第三十二条の四第三項」と、「有料許可証」とあるのは「無料許可証」と、「有料職業紹介事業許可証再交付申請書(様式第六号)」とあるのは「無料職業紹介事業許可証再交付申請書(様式第六号)」と、第二十一条第三項及び第四項中「有料許可証」とあるのは「無料許可証」と、第二十二条第一項中「第三十二条の六第二項」とあるのは「第三十三条第四項において準用する法第三十二条の六第二項」と、「有料職業紹介事業許可有効期間更新申請書(様式第一号)」とあるのは「無料職業紹介事業許可有効期間更新申請書(様式第一号)」と、第二十二条第六項中「第三十二条の六第二項」とあるのは「第三十三条第四項において準用する法第三十二条の六第二項」と、「有料許可証」とあるのは「無料許可証」と、第二十三条第一項中「第三十二条の七第一項」とあるのは「第三十三条第四項において準用する法第三十二条の七第一項」と、第二十三条第二項中「第三十二条の七第一項」とあるのは「第三十三条第四項において準用する法第三十二条の七第一項」と、「第三十条第二項第四号」とあるのは「第三十三条第四項において準用する法第三十条第二項第四号」と、「有料許可証」とあるのは「無料許可証」と、「有料職業紹介事業変更届出書(様式第六号)」とあるのは「無料職業紹介事業変更届出書(様式第六号)」と、「有料職業紹介事業変更届出書及び有料職業紹介事業許可証書換申請書(様式第六号)」とあるのは「無料職業紹介事業変更届出書及び無料職業紹介事業許可証書換申請書(様式第六号)」と、第二十三条第三項中「第三十二条の七第一項」とあるのは「第三十三条第四項において準用する法第三十二条の七第一項」と、「第二項」とあるのは「第二十五条第一項において準用する第二十三条第二項」と、「有料職業紹介事業変更届出書」とあるのは「無料職業紹介事業変更届出書」と、「有料の職業紹介事業又は無料の職業紹介事業」とあるのは「無料の職業紹介事業又は有料の職業紹介事業」と、第二十三条第四項中「第三十二条の七第一項」とあるのは「第三十三条第四項において準用する法第三十二条の七第一項」と、「第二項」とあるのは「第二十五条第一項において準用する第二十三条第二項」と、「有料職業紹介事業変更届出書」とあるのは「無料職業紹介事業変更届出書」と、「有料職業紹介事業変更届出書及び有料職業紹介事業許可証書換申請書」とあるのは「無料職業紹介事業変更届出書及び無料職業紹介事業許可証書換申請書」と、「有料許可証」とあるのは「無料許可証」と、第二十三条第五項中「第三十条第二項第四号」とあるのは「第三十三条第四項において準用する法第三十条第二項第四号」と、「有料の職業紹介事業又は無料の職業紹介事業」とあるのは「無料の職業紹介事業又は有料の職業紹介事業」と、第二十三条第六項中「第三十二条の七第三項」とあるのは「第三十三条第四項において準用する第三十二条の七第三項」と、第二十四条中「第三十二条の八第一項」とあるのは「第三十三条第四項において準用する法第三十二条の八第一項」と、「有料許可証」とあるのは「無料許可証」と、「有料職業紹介事業廃止届出書(様式第七号)」とあるのは「無料職業紹介事業廃止届出書(様式第七号)」と、第二十四条の四第一項中「第三十二条の十二第一項」とあるのは「第三十三条第四項において準用する法第三十二条の十二第一項」と、「有料職業紹介事業取扱職種範囲等届出書(様式第六号)」とあるのは「無料職業紹介事業取扱職種範囲等届出書(様式第六号)」と、第二十四条の四第二項中「有料許可証」とあるのは「無料許可証」と、第二十四条の四第三項中「第三十二条の十二第三項」とあるのは「第三十三条第四項において準用する法第三十二条の十二第三項」と、第二十四条の五第一項及び第二項中「第三十二条の十三」とあるのは「第三十三条第四項において準用する法第三十二条の十三」と、第二十四条の五第四項中「手数料表及び業務の運営に関する規程」とあるのは「業務の運営に関する規程」と、第二十四条の六中「第三十二条の十四」とあるのは「第三十三条第四項において準用する法第三十二条の十四」と、第二十四条の七第一項中「第三十二条の十五」とあるのは「第三十三条第四項において準用する法第三十二条の十五」と、「求人求職管理簿及び手数料管理簿」とあるのは「求人求職管理簿」と、第二十四条の八第二項中「第三十二条の十六」とあるのは「第三十三条第四項において準用する法第三十二条の十六」と、「有料職業紹介事業報告書(様式第八号)」とあるのは「無料職業紹介事業報告書(様式第八号)」と読み替えるものとする。
ある程度長いものを取り除くとこうなる。
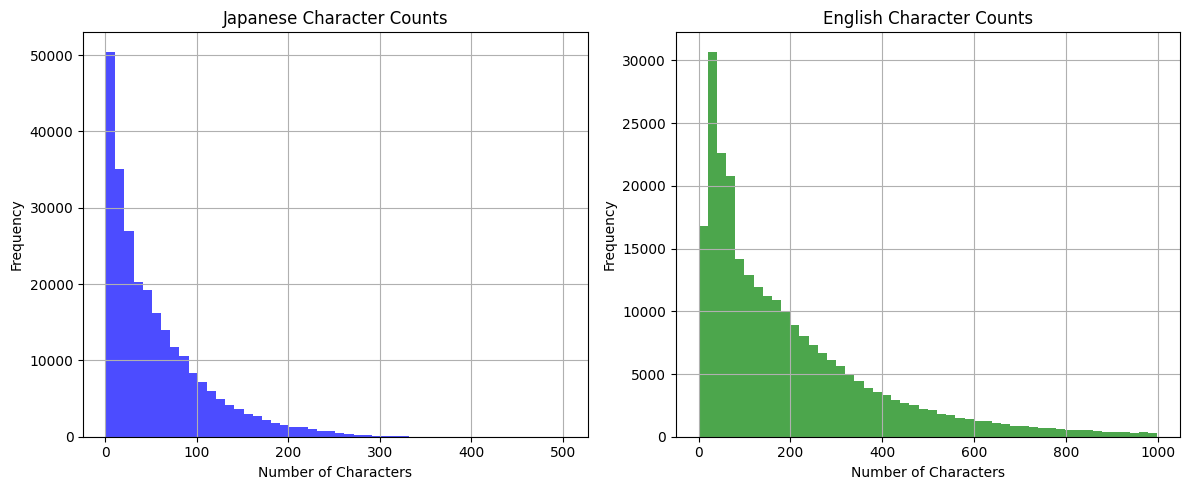
全体としては短いものが多いのだけど、それなりの長さのものもある。法律文書という点、少し領域が限定はされるものの、逆に言うと翻訳の品質はおそらく高いと思う。
Japanese-English Subtitle Corpus
JESCは、機械翻訳、情報抽出及びその他の言語処理技術の研究開発をサポートするために構築されました。
JESCは、スタンフォード大学、グーグルブレイン、RITの共同研究開発による成果であり 、インターネット上からクロールされた映i画とTV番組の字幕データを日英対応させることで構築されています。JESCは、自由に利用できる日英対訳コーパスの中で最大規模のコーパスであり、既存のコーパスではあまり扱われてこなかった口語の対訳も対象しています。
ライセンスもCC BY-SAで比較的使いやすい方ではある。
$ wget https://nlp.stanford.edu/projects/jesc/data/raw.tar.gz
$ tar zxvf raw.tar.gz
$ head -50 raw/raw
you are back, aren't you, harold? あなたは戻ったのね ハロルド?
my opponent is shark. 俺の相手は シャークだ。
this is one thing in exchange for another. 引き換えだ ある事とある物の
yeah, i'm fine. もういいよ ごちそうさま ううん
don't come to the office anymore. don't call me either. もう会社には来ないでくれ 電話もするな
looks beautiful. きれいだ。
get him out of here, because i will fucking kill him. 連れて行け 殺しそうだ わかったか?
you killed him! 殺したのか!
okay, then who? わぁ~! いつも すみません。 いいのよ~。
it seems a former employee... カンパニーの元社員が
so where are they? じゃアイツラはどこ?
or i don't know, just... 相手を陥れるとか...
no child should ever have to endure that. 必要のない子 耐えるにしている。
i know the visual's incongruous, but... 犯人像とは 違和感のある見た目だが
aw! あ!
let me show you more detailed ones. もっと詳しいの 見せますから。
you're gonna bring that up right now? それ今持ち出すか?
well then, when you're done work, come to the medical office. じゃあ 仕事終わったら 医局に来てよ。
um...please go ahead and eat without me. あの... 皆さんで 先 済ませてください。
rokka is always forever 六花ちゃんは ずっと ずっとずっと
thank you! ほら 別に変なことじゃないでしょ?
that's a funnylooking dress. 変な子供服
the captain asked me to reexamine the dna from the bomb... to see if anyone else might have handled it. 船長から他の誰かが扱った形跡がないか dnaを再調査するように頼まれました
if the rest of the book reads as well when you're done もし 残りも上手く書けたら
more ravishing than ever, big sister. 以前に増して魅力的だ
yes, that's me. 也就是说...该不会是...
because you and i are gonna be friends for a long time. you might as well know now. 長いこと友達なのに 気付かなかったのか?
and bill talbot's tracker fell off the grid five minutes ago. ...taken by a witness here. we can show you these images now. ビルのID信号も5分前に消えたわ
he's got some blood in his mouth. 口の中に血が見える
asamoto won't last like this! "ASAMOTOは このままじゃいけないと思う。"
storm! 嵐には嵐の
i see... it doesn't look easy to get in... なるほど 簡単にゃ入れそうにねえな
and how's that news, exactly, the two of you being in danger, after doing something idiotic? ニュースは? 確かに 二人の危険にさらされて
they make it into a creation ある創作をします
i'll call you in the morning. 朝、電話する
we pioneered all sorts of new 次々に新しい柔軟な勤務体系を 開発していきました
single gunshot victim. ルーズベルト・アイランド橋で
i don't have anywhere else to go. 僕、帰る所が無いんだ
we have one for you. 今度は わしの番だ
why'd you tell? どうして話した
there is no such thing as a curse in this world! 持っているだけで人を不幸にする呪われた本などというものは存在しないのです
i'm sorry, but i have to ask. 悪いと思うけど 聞かなきゃいけないの
any good things to you about this. お前たちを英雄にしたりはしない
now! throw out all the seal tickets! 今だ!ありったけの封印札を 投げつけろ!
and we are paying a cost. その結果犠牲を払うことになります
i was given an education 教育を受け
i'm starting to feel stupid for agonizing over it. 何か 悩むんが アホらしゅうなって来たわ。
with furcifer gone, i can put a cloaking spell on her. 俺が隠している魔法を かけることもできる
this way, please! 帰れ! やだね。
and to the gymnosophist. 裸行者に戻ります
んー、短い上に、前後のつながりもなさそう。コンテキストがわからないので、果たしてその訳で正しいのかも判断できない(「アホらしゅう」ってどういう文脈でこの訳なんだろうか・・・)
その辺をあまり考えずにやるならこう。
import pandas as pd
import re
en_sentences = []
ja_sentences = []
with open("raw/raw", 'r') as file:
for line in file:
line = line.strip()
en_sentence, ja_sentence = line.split("\t")
ja_sentence = ja_sentence.replace(" ","、")
if not ja_sentence.endswith(("。","?","?","!","!", "…","...")):
if en_sentence.endswith(("...")):
ja_sentence = ja_sentence + "…"
elif en_sentence.endswith("."):
ja_sentence = ja_sentence + "。"
elif en_sentence.endswith("?"):
ja_sentence = ja_sentence + "?"
en_sentences.append(en_sentence)
ja_sentences.append(ja_sentence)
df = pd.DataFrame({"Japanese": ja_sentences, "English": en_sentences})
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))

長さも見てみる。

これまた短いなぁ・・・
以下については、フィルタが大変そうなので調べないことにした。
- 京都Wiki
- JparaCrawl
WikiMatrix
ウィキマトリックス:ウィキペディアから1620言語対135Mの並列文をマイニングする
このプロジェクトの目標は、ウィキペディアのテキストコンテンツから、可能な限りの言語ペアについて並列文をマイニングすることである。
採掘データ
- 85の言語、1620の言語ペア
- 1億3400万文の並列文、うち3400万文が英語とアライメントされている
アプローチ
Wikipediaが提供する言語間リンクは使用せず、各言語のWikipediaの全記事を検索する。 並列文のマイニングの前に、文のセグメンテーション、重複排除、言語識別を行う。
データ抽出と閾値の最適化
TSVファイルから並列テキストを抽出するツールを提供する:
python3 extract.py
--tsv WikiMatrix.en-fr.tsv.gz
--bitext WikiMatrix.en-fr.txt
--src-lang en --trg-lang fr
--threshold 1.04
マージンスコアのしきい値を指定することができます。 値が高いほど、文が相互翻訳である可能性が高くなりますが、得られるデータは少なくなります。ほとんどの言語ペアでは、1.04の値が良い選択と思われます。
評価
マイニングされたビットテキストの品質を評価するために、少なくとも25kの並列文をマイニングできたすべての言語ペアに対してニューラルMTシステムをトレーニングした(マージンのしきい値は1.04)。 ソースからターゲット、ターゲットからソースの両方向でシステムをトレーニングし、[4]で提案されたTEDテストセットでBLEUスコアを報告した。 この表は、最も頻度の高い言語ペアのBLEUスコアを示している。 いくつかの言語ペアで30を超えるBLEUスコアを達成している。
ゴールは、各言語ペアに対して最先端のシステムを構築することではなく、自動的にマイニングされたデータの質の指標を得ることである。 もちろん、これらのBLEUスコアは、マイニングされたコーパスのサイズとの関連で評価されるべきである。
ライセンス
採掘されたデータは、クリエイティブ・コモンズ 表示-継承ライセンスの下で配布される。
$ wget https://dl.fbaipublicfiles.com/laser/WikiMatrix/v1/WikiMatrix.en-ja.tsv.gz
$ gunzip WikiMatrix.en-ja.tsv.gz
内容はこんな感じ。
1.244485519646686 Opsaridium ubangiense. 主のものは以下の通り。
1.224694437909713 "Shall I compare thee to a summer's day? (詳細はソネットを参照) Shall I compare thee to a summer’s day?
1.2204652999675554 It will destroy everything at the bidding of its Lord." 主の為なら主にすら嘘をつく。
1.215881954486094 Owain is appointed lord. 一般には後主と称されている。
1.214882744859654 Blessed is he who comes in the name of the Lord! 主の御名によって来られる方を讃えよ。
1.2093175221568597 In The Lord of the Rings, they refer to his kind as Beornings. 魂主の手首には「主の証」として具現化する。
1.2065405437819625 Whoever blasphemes the name of the Lord shall surely be put to death. 主の御名を呪う者は死刑に処せられる。
1.206366100568939 Allah hath upset them for their (evil) deeds. これはかれらの行いに対する、アッラーの見せしめのための懲しめである。
1.2044444185701175 Until the coming (parousia) of the Lord. で主に道外向けに同時配信。
1.2021576465894508 (He will be the last Lord to have resided permanently at the castle). 最期には人主に至るであろう。
1.201763370376776 All life (or unlife) depends on them. 全ての生命(あるいは非生命)はこれらに依存している。
1.201326816146185 And He is The Almighty, The Compassionate." 偉大で慈悲深い人物。
1.1989471982289548 By Him Who is the Lord of mankind! しかしながら人主の患はまた人を信ぜざるにもある。
1.1969704966791581 If we have been made sons of God, we have also been made gods." 『わたしたちはアッラーの子であり,かれに愛でられる。
1.1954036727171884 The food of those who have received the Scripture is lawful for you, and your food is lawful for them. 啓典を授けられた民の食べ物は、あなたがたに合法であり、あなたがたの食べ物は、かれらにも合法である。
1.1924680149292597 There are no records of a Lord of Troussay. ただし城主の実名は記載されていない。
1.192166896820111 Indeed, he who associates others with Allah, then Allah has forbidden him Paradise and his refuge is the Fire. 」凡そアッラーに何ものかを配する者には,アッラーは楽園(に入ること)を禁じられ,かれの住まいは業火である。
1.1920562664693404 Yasseen MUSA (QAT). 『クルアーン』(コーラン)ではアラビア語でムーサー (موسى Mūsā) と呼ばれる。
1.1916526455512477 So proceed through the earth and observe how was the end of the deniers". 大地 緑 (だいち みどり) 声 - 鈴木みえ 翔の母。
1.1903692107887065 They fully trusted and respected one another. お互いに絶対の信頼と思慕を置いていた。
(snip)
1.0200000419008877 Many interviews were done to magazines and internet websites. 雑誌とウェブサイトの連動を売りにしている。
1.0200000403386147 The chemotherapy and the recovery forced Neuenberger out for the rest of the year. マドリードやトレドの取材記などを執筆するも、同年の年末に肺炎のため死去。
1.0200000381769003 John Ball continues to be cited as an example of an English socialist. ジョン・ウィリアムズ(John Williams)は、英語圏の人名。
1.0200000380890712 With the support of an NGO, a driving school for women opened in Herat. その頃、カロライン・ライトの出資により、来徳女学校が教会内に設立された。
1.0200000374407734 By 2010, San Jose was "aggressively wooing" A's owner Lew Wolff. 2013年には、ヒュー・ジャックマン主演の『ウルヴァリン: SAMURAI』を監督した。
1.0200000315913162 Sicily), Russia: Asia: Israel, Turkey, Iran; Azores). ロシア(en:Russia、zh:俄罗斯)、イラン(en:Iran、zh:伊朗)、北朝鮮と友好関係にある。
1.0200000312755935 In 1867 Barnard Clarkson married Isabella Lukin, daughter of Lionel Lukin; they three sons and three daughters. 1678年、ヘルミンガム男爵ライオネル・タルマッシュの娘エリザベスと結婚、3人の子を儲けた。
1.020000029561463 In 1944, Balewa and a few educated teachers in the North was chosen to study abroad at the University of London's Institute of Education, which today forms part of University College London. 1944年、北部の幾人かの教師とともに、ロンドン大学の教育研究所へ送られて一年間留学した。
1.020000024956747 Their shape bears no similarity to the foot of a sheep. 外観は地球の雄ウシに似ていなくもない。
1.0200000249287073 JAMA, 284 (8): 929. doi:10.1001/jama.284.8.929. 2142×1.4=2998.8。
1.0200000232746163 Fostering success, emulation, cooperation and the well-being of all are at the heart of the school's projects. in the 5 February 2009, Reda Laraki, a young 13-year-old collegiate victim of harassment, humiliation and racketeering on the part of his comrades commits suicide. 誠実・勤勉・友愛 平成5年度に、同校創立80周年を記念して、第13代校長長岡四郎の発案・企画により、立派な校訓・校訓碑が建設された。
1.0200000230237862 "Over the moon!". 「月に代わって突き!
1.0200000211644435 The episode is entitled "Punk Meets Traditional". 併演作品は『クラシカル・メニュー』。
1.020000019601506 On September 6, 2011, he was claimed off waivers by the Buffalo Bills. 2010年8月6日の時点で、アップルのExecutive Profilesから削除されている。
1.0200000180494717 "Case File 107UMLA". ^ 『テイクダウン』上巻107頁。
1.0200000146463921 There also exists another village by the same name, in the Dindigul district in Tamil Nadu. 同名の温泉が北海道夕張郡長沼町にも存在する。
1.0200000091754033 Towards the end of his first-class career, when he played for Somerset's second eleven, he also bowled with some success. 『ショー・マスト・ゴー・オン』の初演の際、三谷幸喜の助手をしていたが、急遽役者でも出演。
1.020000006472651 I was home with no job. 夫とともに仕事で自宅を不在がちだった。
1.0200000057425695 Alexandria Hill from Otaku USA enjoyed Boruto's fight against the film's villain and his team-up with Naruto and Sasuke. 田岡一雄は地道行雄の推薦を受け、柳川甲録と小塚斉を若衆とした。
1.0200000032638146 Surplus funds may be invested. 海外送金も可能。
スコアっぽいものが入っているのはいいんだけど、うーん、翻訳があってないものが多数あるように思える。前後の関係もわからないし、判断が難しいな・・・
なんか間違ってるのかなーと思って手順の通りにやってみたり、スコアでフィルタしてみたりもしたけど、やっぱり変な訳がちょいちょいあるように思える。
件数は多いんだけど、パッと見ただけであってない翻訳がちらほら見えるぐらいだと、全部みたらそこそこ誤訳ありそうだし、この件数だともうチェックしてられないので、自分はパスすることにした。
日本語SNLI(JSNLI)データセット
本データセットは自然言語推論 (NLI) の標準的ベンチマークである SNLIを日本語に翻訳したものです。SNLI に機械翻訳を適用した後、評価データにクラウドソーシングによる正確なフィルタリング、学習データに計算機による自動フィルタリングを施すことで構築されています。
データセットは TSV フォーマットで、各行がラベル、前提、仮説の三つ組を表します。前提、仮説は JUMAN++ によって形態素分割されています。以下に例をあげます。
entailment 自転車 で 2 人 の 男性 が レース で 競い ます 。 人々 は 自転車 に 乗って います 。
データセットは学習データを全くフィルタリングしていないものと、フィルタリングした中で最も精度が高かったものの2種類を公開しています。データサイズは、フィルタリング前の学習データが548,014ペア、フィルタリング後の学習データが533,005ペア、評価データは3,916ペアです。詳細は参考文献を参照してください。
翻訳として見る場合には、単体では使えないので、以下と照らし合わせる必要がある。
ということで両方持ってきてまずは比較してみる。
$ wget --content-disposition https://nlp.ist.i.kyoto-u.ac.jp/DLcounter/lime.cgi?down=https://nlp.ist.i.kyoto-u.ac.jp/nl-resource/JSNLI/jsnli_1.1.zip&name=JSNLI.zip
$ wget https://nlp.stanford.edu/projects/snli/snli_1.0.zip
$ unzip jsnli_1.1.zip
$ unzip snli_1.0.zip
$ wc -l */*.{txt,tsv}
10001 snli_1.0/snli_1.0_dev.txt
10001 snli_1.0/snli_1.0_test.txt
550153 snli_1.0/snli_1.0_train.txt
3916 jsnli_1.1/dev.tsv
533005 jsnli_1.1/train_w_filtering.tsv
548014 jsnli_1.1/train_wo_filtering.tsv
行数があわないのでこれをマッチングさせるのは一苦労しそう。まあ用途が違うからしょうがないかな。
これもパス。
オープンコースウェア対訳コーパス/Coursera Parallel Corpus
このリソースには、Courseraから抽出した日英・中英並列データセットが含まれています。音声言語と教育分野のデータセットです。訓練セットは自動的にアライメントされ、開発セットとテストセットは手動で評価されます。
- 日英データセットに含まれるファイルの説明:
- train.ja & train.en:
- 機械翻訳(MT)の学習データとして利用可能な、Courseraから抽出・アライメントされた40,770の並列文。
- dev.ja & dev.en:
- 541の並列文を手動でチェックしたもので、MTのチューニングデータとして利用できる。
- test.ja & test.ja:
- 2,005文の並列文を手動でチェック。
サイトには書いてないけど、Githubを見る限りはApacheライセンス2.0。
$ wget https://github.com/shyyhs/CourseraParallelCorpusMining/raw/master/data/Coursera_En-Ja.zip
$ unzip Coursera_En-Ja.zip
中身はこんな感じ。
$ head */train*
==> Coursera_En-Ja/train.en.txt <==
Hello, Coursera, and welcome to the University of Toronto.
This course is called Communication Strategies for a Virtual Age.
So this is the School of Continuing Studies.
Do you like almonds?
There's a little almond part of your brain that's responsible for whether or not you get bored.
What if I told you that your belly button is the secret to being confident?
What's more important, a story or evidence?
My personal experience or what the world says?
These are the questions we are going to answer in Communication Strategies for a Virtual Age.
We designed this course to challenge your thinking.
==> Coursera_En-Ja/train.ja.txt <==
トロント 大学 へ ようこそ 。
この コース は バーチャル 時代 の コミュニケーション 戦略 です 。
こちら は 継続 的な 学習 の 学校 です 。
アーモンド は 好きです か ?
脳 の 中 に は 小さな アーモンド の 部分 が あって 、 退屈に なら ない ように 責任 を 果たして い ます 。
あなた の お へそ が 自信 を 持つ ため の 秘訣 だ と 言ったら どう でしょう か ?
物語 か 証拠 、 どちら が 重要です か ?
私 の 個人 の 経験 または 、 世界 が 言う こと ?
こういった 質問 に 、 バーチャル 時代 の コミュニケーション で 答えて いき ます 。
この コース は あなた の 考え に 挑戦 する ように デザイン さ れて い ます 。
日本語はトークン分割されてるけど、句読点も入ってるので消すだけで良さそう。
ではpandasのデータフレームに読み込み
import pandas as pd
# rawデータのパス
raw_base_path = "ted/multitarget-ted/en-ja/raw"
# 日本語と英語のファイルパスリスト
ja_file_paths = ['train.ja.txt', 'dev.ja.txt', 'test.ja.txt']
en_file_paths = ['train.en.txt', 'dev.en.txt', 'test.en.txt']
def read_file_to_list(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return [line.strip() for line in file]
# 日本語と英語のデータを読み込む
japanese_lines = [line for path in ja_file_paths for line in read_file_to_list("Coursera_En-Ja/" + path)]
english_lines = [line for path in en_file_paths for line in read_file_to_list("Coursera_En-Ja/" + path)]
# DataFrameを作成
df_japanese = pd.DataFrame({'Japanese': japanese_lines})
df_english = pd.DataFrame({'English': english_lines})
# DataFrameを結合
df = pd.concat([df_japanese, df_english], axis=1)
df["Japanese"] = df["Japanese"].apply(lambda x: x.replace(" ",""))
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))
文字数を見てみる。

最大でもそんなに長くはないけど、極端に短いものばかりというわけでもない感じ?
ざっと見た感じ、複数のテーマが異なる講義が含まれているようだけど、その境界はデータセットには定義されていない。ただ「ようこそ」とか「こんにちは」とかで始まることが多いみたいだし、上から順に並んでるように見えるので、複数まとめればコンテキストを持った長文の翻訳としてまとまりそうな気はする。翻訳の質もいい感じに見える。
ただ件数自体は5万ちょっとと少なめなので、学習データとしては足りないかもね。
NICTの各種データセット/ASPEC
OSSマニュアルのリンク先が間違ってるようで、あと、以下のサイトのリンクもどうやら変更されている。
で、NICTのトップから辿っていくとここにいくつかあった。
そういえば小説のやつもここだったな。それ以外で公開されているものは以下。
各種OSSの対訳マニュアル。CC BY-SA 3.0。ただし本文・訳文のライセンスは各OSSごとに確認が必要。
日化辞パラレルコーパス。化学物質名の対訳データらしい。CC BY 4.0。
wikinewsの対訳コーパスなのかな?CC BY 4.0。
科学論文の対訳データっぽい。CC BY 4.0。
NICTじゃないけど、ASPEにも科学論文の対訳データがある様子。申請が必要。商用・再配布は不可っぽい。
まあちょっと気が向けば調べてみる。
BSD(Business Scene Dialogue)corpus
ビジネス上の会話の対訳コーパス。ちょいちょい使ってるけど、総じて非常に短いのと、会話の流れ≒コンテキストが訳文に含まれているものがチラホラあって(対訳ペアだけだとわかりようがない)、何回か使ってみたけどちょっと使いにくいなーと思ってるところ。
JSICK
SNLI/JSNLIと同じような感じのもの。SICKの日本語訳がJSICKみたいだけど、こちらは英語もいっしょ含まれている。まあこれも文が短い。
以下のサイトのような感じで、いろいろなカテゴリで比較するといいなと思う。それ以外もめちゃめちゃ参考になるな。
Asian Language Treebank (ALT) Project
NICTのリンクにあったうちの1つ。wikinewsの対訳コーパスらしい。
日本語訳
ALTプロジェクトは、ALTの開発と利用のためのオープンなコラボレーションを通じて、最先端のアジアの自然言語処理(NLP)技術を発展させることを目的としている。Ye Kyaw Thu, Win Pa Pa, Masao Utiyama, Andrew Finch and Eiichiro Sumita (2016)に記載されているように、NICTとUCSYによって最初に実施されました。その後、このウェブページに記載されているように、ASEAN IVOの下で開発された。ALTの構築プロセスは、まず英語のWikinewsから約2万文をサンプリングし、それを他の言語に翻訳することから始まった。ALTには現在13の言語があります: ベンガル語、英語、フィリピン語、ヒンディー語、インドネシア語、日本語、クメール語、ラオス語、マレー語、ミャンマー語(ビルマ語)、タイ語、ベトナム語、中国語(簡体字)である。
最初、ALT-Parallel-Corpus-20191206.zipの方を試したのだけど、日本語の翻訳漏れが5件ほどあった。Japanese-ALT-20210218.zip の方では修正されているように思える。こちらの方が日付も最新だし。
$ wget https://www2.nict.go.jp/astrec-att/member/mutiyama/ALT/Japanese-ALT-20210218.zip
$ unzip Japanese-ALT-20210218.zip
中身はこんな感じ。
$ head Japanese-ALT-20210218/word-alignment/data_ja.{en,ja}-raw
==> Japanese-ALT-20210218/word-alignment/data_ja.en-raw <==
SNT.80188.1 Italy have defeated Portugal 31-5 in Pool C of the 2007 Rugby World Cup at Parc des Princes, Paris, France.
SNT.80188.2 Andrea Masi opened the scoring in the fourth minute with a try for Italy.
SNT.80188.3 Despite controlling the game for much of the first half, Italy could not score any other tries before the interval but David Bortolussi kicked three penalties to extend their lead.
SNT.80188.4 Portugal never gave up and David Penalva scored a try in the 33rd minute, providing their only points of the match.
SNT.80188.5 Italy led 16-5 at half time but were matched by Portugal for much of the second half.
SNT.80188.6 However Bortolussi scored his fourth penalty of the match, followed by tries from Mauro Bergamasco and a second from Andrea Masi to wrap up the win for Italy.
SNT.80188.7 Currently third in Pool C with eight points, Italy face a tough match against second placed Scotland on 29 September.
SNT.80188.8 New Zealand lead the group with ten points, ahead of Scotland on points difference.
SNT.80188.9 Portugal are bottom of the group with no points, behind Romania with one.
SNT.87564.10 Some personal details of 3 million British learner drivers who had applied for the 'theory test' component of their Driving licence have been lost in Iowa, in the USA.
==> Japanese-ALT-20210218/word-alignment/data_ja.ja-raw <==
SNT.80188.1 フランスのパリ、パルク・デ・プランスで行われた2007年ラグビーワールドカップのプールCで、イタリアは31対5でポルトガルを下した。
SNT.80188.2 アンドレア・マージが開始4分後のトライでイタリアにとって最初の得点を入れた。
SNT.80188.3 イタリアは試合前半のほとんどをコントロールしていながら、その後インターバルまでのトライでは得点できなかったが、デビッド・ボルトルッシがペナルティキックで3点を入れリードを広げた。
SNT.80188.4 ポルトガルはあきらめることなく、デビッド・ペナルバが33分でトライを決め、試合中唯一の得点をあげた。
SNT.80188.5 イタリアはハーフタイムの時点で16対5とリードしていたが、後半ではポルトガルと互角になった。
SNT.80188.6 だがボルトルッシがこの試合で4つめとなるペナルティキックを成功させ、さらにマウロ・ベルガマスコのトライとアンドレア・マージの2回めのトライでイタリアの勝利が確定的になった。
SNT.80188.7 現在8ポイントとプールCでは3位のイタリアは、9月29日に2位のスコットランドとの厳しい戦いに臨む。
SNT.80188.8 ニュージーランドが10ポイントでグループをリードし、勝ち点差でスコットランドに勝っている。
SNT.80188.9 ポルトガルはポイントなしでグループ最下位、1ポイントでルーマニアの下位にいる。
SNT.87564.10 アメリカアイオワ州で、運転免許の筆記試験に申し込んだイギリスの運転講習教習生300万人分の個人の詳細情報が紛失された。
最初の部分が、記事ID+行IDのような感じになっていて、1つの記事を複数行にわけて翻訳している用に見えるので、うまく使えば長い文章の翻訳データになりそう。
翻訳としては、全部は見てないけど、可もなく不可もなくという印象で、やや直訳っぽさを感じるところもあるけど、多分個々の文の対訳になってるからなのかなと思う。
pandasデータフレームに読み込み
import pandas as pd
import numpy as np
dir_path = "Japanese-ALT-20210218/word-alignment"
ja_file = "data_ja.ja-raw"
en_file = "data_ja.en-raw"
def read_file_to_list(file_path):
lines = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip()
# ALT-Parallel-Corpus-20191206だと日本語データは一部翻訳されていないものがあった
# Japanese-ALT-20210218だと問題ないけど一応チェック
if len(line.split("\t")) == 1:
lines.append(np.nan)
else:
lines.append(line.split("\t")[1])
return lines
# 日本語と英語のデータを読み込む
ja_lines = read_file_to_list("{}/{}".format(dir_path, ja_file))
en_lines = read_file_to_list("{}/{}".format(dir_path, en_file))
# DataFrameを作成
df = pd.DataFrame({'Japanese': ja_lines, 'English': en_lines})
df.dropna(inplace=True)
df["ja_char_len"] = df["Japanese"].apply(lambda x: len(x))
df["en_char_len"] = df["English"].apply(lambda x: len(x))
df.isna().sum
文字数を見てみる。
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].hist(df['ja_char_len'], bins=50, color='blue', alpha=0.7)
axes[0].set_title('Japanese Character Counts')
axes[0].set_xlabel('Number of Characters')
axes[0].set_ylabel('Frequency')
axes[0].grid(True)
axes[1].hist(df['en_char_len'], bins=50, color='green', alpha=0.7)
axes[1].set_title('English Character Counts')
axes[1].set_xlabel('Number of Characters')
axes[1].set_ylabel('Frequency')
axes[1].grid(True)
plt.tight_layout()
plt.show()
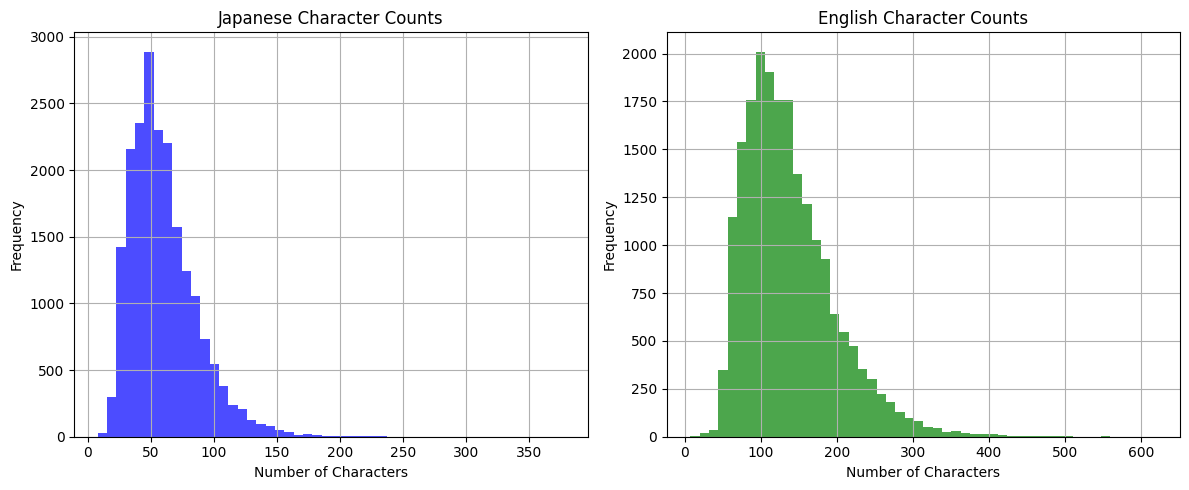
1文は短いけど、上で書いた通り、IDで結合してやれば長めの文章は作れそうな気がする。ただそもそもの件数は少ないかな。
ライセンスがちょっとよくわからないのだけど、ALT-Parallel-CorpusだとCC BY 4.0で、Japanese-ALTだとCC BY-NC-SA 4.0で別のライセンスになってるのかな?上に書いた通り日本語翻訳漏れがあるんだけど、そこだけ直せばALT-Parallel-Corpusのほうがライセンス的には使いやすくはある。