日本語に特化したOCR・文書画像解析ライブラリ「YomiToku」を試す
Githubレポジトリ
ライセンスについて
本リポジトリ内に格納されているソースコードおよび本プロジェクトに関連する HuggingFaceHub 上のモデルの重みファイルのライセンスは CC BY-NC-SA 4.0 に従います。 非商用での個人利用、研究目的での利用はご自由にお使いください。 商用目的での利用に関しては、別途、商用ライセンスを提供しますので、開発者にお問い合わせください。
Colaboratoryで。L4を使う。
パッケージインストール。ランタイムの再起動が必要になると思う。
!pip install yomitoku
!pip freeze | grep yomitoku
yomitoku==0.5.1
今回は、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを画像に変換して使用する。
これらをダウンロード
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
PDFから画像の変換にはpdf2imageを使用する。
まずpoppler-utilsをインストール
!apt update && apt install -y poppler-utils
pdf2imageをインストール
!pip install pdf2image
ではPDFを画像に変換。
import os
from pdf2image import convert_from_path
kobe_pdf = "r5_doukou.pdf"
kobe_output_dir = "kobe"
def convert_pdf_to_image(pdf_path, output_dir_path):
os.makedirs(output_dir_path, exist_ok=True)
images = convert_from_path(pdf_path)
for i, image in enumerate(images):
output_path = f"{output_dir_path}/page_{i + 1}.png"
image.save(output_path, "PNG")
print(f"Saved: {output_path}")
convert_pdf_to_image(kobe_pdf, kobe_output_dir)
こんな感じで保存される。
Saved: kobe/page_1.png
Saved: kobe/page_2.png
Saved: kobe/page_3.png
Saved: kobe/page_4.png
Saved: kobe/page_5.png
Saved: kobe/page_6.png
Saved: kobe/page_7.png
Saved: kobe/page_8.png
Saved: kobe/page_9.png
Saved: kobe/page_10.png
Saved: kobe/page_11.png
Saved: kobe/page_12.png
Saved: kobe/page_13.png
Saved: kobe/page_14.png
Saved: kobe/page_15.png
Saved: kobe/page_16.png
Saved: kobe/page_17.png
Saved: kobe/page_18.png
Saved: kobe/page_19.png
Saved: kobe/page_20.png
Saved: kobe/page_21.png
準備OK。
ではyomitokuに読み込ませてみる。
まず神戸市観光動向調査結果の方から。CLIのオプションはREADME通りに。
yomitoku kobe -f md -o kobe_results -v --figure
こんな感じで処理されていく。
2024-11-27 04:18:41,754 - yomitoku.base - INFO - Initialize TextDetector
model.safetensors: 100% 102M/102M [00:02<00:00, 42.7MB/s]
2024-11-27 04:18:45,622 - yomitoku.base - INFO - Initialize TextRecognizer
config.json: 100% 256/256 [00:00<00:00, 1.80MB/s]
model.safetensors: 100% 200M/200M [00:04<00:00, 42.4MB/s]
2024-11-27 04:18:52,177 - yomitoku.base - INFO - Initialize LayoutParser
model.safetensors: 100% 172M/172M [00:04<00:00, 42.0MB/s]
2024-11-27 04:18:57,467 - yomitoku.base - INFO - Initialize TableStructureRecognizer
model.safetensors: 100% 172M/172M [00:04<00:00, 41.2MB/s]
2024-11-27 04:19:02,995 - yomitoku.cli.main - INFO - Output directory: kobe_results
2024-11-27 04:19:02,996 - yomitoku.cli.main - INFO - Processing file: kobe/page_7.png
2024-11-27 04:19:03,789 - yomitoku.base - INFO - TextDetector __call__ elapsed_time: 0.6929779052734375
2024-11-27 04:19:03,977 - yomitoku.base - INFO - LayoutParser __call__ elapsed_time: 0.8800938129425049
2024-11-27 04:19:04,075 - yomitoku.base - INFO - TableStructureRecognizer __call__ elapsed_time: 0.09729456901550293
2024-11-27 04:19:07,044 - yomitoku.base - INFO - TextRecognizer __call__ elapsed_time: 3.2544093132019043
2024-11-27 04:19:07,296 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_7_p1_ocr.jpg
2024-11-27 04:19:07,315 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_7_p1_layout.jpg
2024-11-27 04:19:07,338 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_7_p1.md
2024-11-27 04:19:07,341 - yomitoku.cli.main - INFO - Total Processing time: 4.35 sec
2024-11-27 04:19:07,342 - yomitoku.cli.main - INFO - Processing file: kobe/page_17.png
2024-11-27 04:19:07,529 - yomitoku.base - INFO - LayoutParser __call__ elapsed_time: 0.12876152992248535
2024-11-27 04:19:07,667 - yomitoku.base - INFO - TableStructureRecognizer __call__ elapsed_time: 0.1376194953918457
2024-11-27 04:19:07,702 - yomitoku.base - INFO - TextDetector __call__ elapsed_time: 0.3018374443054199
2024-11-27 04:19:09,452 - yomitoku.base - INFO - TextRecognizer __call__ elapsed_time: 1.7498159408569336
2024-11-27 04:19:09,527 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_17_p1_ocr.jpg
2024-11-27 04:19:09,542 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_17_p1_layout.jpg
2024-11-27 04:19:09,555 - yomitoku.cli.main - INFO - Output file: kobe_results/kobe_page_17_p1.md
2024-11-27 04:19:09,559 - yomitoku.cli.main - INFO - Total Processing time: 2.22 sec
2024-11-27 04:19:09,559 - yomitoku.cli.main - INFO - Processing file: kobe/page_10.png
(snip)
約1分ほどで完了した。出力先ディレクトリを見てみる。(treeは別途インストール)
!tree kobe_results
kobe_results
├── figures
│ ├── kobe_page_10_p1_figure_0.png
│ ├── kobe_page_11_p1_figure_0.png
│ ├── kobe_page_12_p1_figure_0.png
│ ├── kobe_page_14_p1_figure_0.png
│ ├── kobe_page_15_p1_figure_0.png
│ ├── kobe_page_16_p1_figure_0.png
│ ├── kobe_page_17_p1_figure_0.png
│ ├── kobe_page_19_p1_figure_0.png
│ ├── kobe_page_19_p1_figure_1.png
│ ├── kobe_page_20_p1_figure_0.png
│ ├── kobe_page_21_p1_figure_0.png
│ ├── kobe_page_4_p1_figure_0.png
│ ├── kobe_page_4_p1_figure_1.png
│ ├── kobe_page_5_p1_figure_0.png
│ ├── kobe_page_6_p1_figure_0.png
│ ├── kobe_page_6_p1_figure_1.png
│ ├── kobe_page_7_p1_figure_0.png
│ ├── kobe_page_7_p1_figure_1.png
│ ├── kobe_page_8_p1_figure_0.png
│ └── kobe_page_9_p1_figure_0.png
├── kobe_page_10_p1_layout.jpg
├── kobe_page_10_p1.md
├── kobe_page_10_p1_ocr.jpg
├── kobe_page_11_p1_layout.jpg
├── kobe_page_11_p1.md
├── kobe_page_11_p1_ocr.jpg
├── kobe_page_12_p1_layout.jpg
├── kobe_page_12_p1.md
├── kobe_page_12_p1_ocr.jpg
├── kobe_page_13_p1_layout.jpg
├── kobe_page_13_p1.md
├── kobe_page_13_p1_ocr.jpg
├── kobe_page_14_p1_layout.jpg
├── kobe_page_14_p1.md
├── kobe_page_14_p1_ocr.jpg
├── kobe_page_15_p1_layout.jpg
├── kobe_page_15_p1.md
├── kobe_page_15_p1_ocr.jpg
├── kobe_page_16_p1_layout.jpg
├── kobe_page_16_p1.md
├── kobe_page_16_p1_ocr.jpg
├── kobe_page_17_p1_layout.jpg
├── kobe_page_17_p1.md
├── kobe_page_17_p1_ocr.jpg
├── kobe_page_18_p1_layout.jpg
├── kobe_page_18_p1.md
├── kobe_page_18_p1_ocr.jpg
├── kobe_page_19_p1_layout.jpg
├── kobe_page_19_p1.md
├── kobe_page_19_p1_ocr.jpg
├── kobe_page_1_p1_layout.jpg
├── kobe_page_1_p1.md
├── kobe_page_1_p1_ocr.jpg
├── kobe_page_20_p1_layout.jpg
├── kobe_page_20_p1.md
├── kobe_page_20_p1_ocr.jpg
├── kobe_page_21_p1_layout.jpg
├── kobe_page_21_p1.md
├── kobe_page_21_p1_ocr.jpg
├── kobe_page_2_p1_layout.jpg
├── kobe_page_2_p1.md
├── kobe_page_2_p1_ocr.jpg
├── kobe_page_3_p1_layout.jpg
├── kobe_page_3_p1.md
├── kobe_page_3_p1_ocr.jpg
├── kobe_page_4_p1_layout.jpg
├── kobe_page_4_p1.md
├── kobe_page_4_p1_ocr.jpg
├── kobe_page_5_p1_layout.jpg
├── kobe_page_5_p1.md
├── kobe_page_5_p1_ocr.jpg
├── kobe_page_6_p1_layout.jpg
├── kobe_page_6_p1.md
├── kobe_page_6_p1_ocr.jpg
├── kobe_page_7_p1_layout.jpg
├── kobe_page_7_p1.md
├── kobe_page_7_p1_ocr.jpg
├── kobe_page_8_p1_layout.jpg
├── kobe_page_8_p1.md
├── kobe_page_8_p1_ocr.jpg
├── kobe_page_9_p1_layout.jpg
├── kobe_page_9_p1.md
└── kobe_page_9_p1_ocr.jpg
1 directory, 83 files
各画像ごとに*.md、*_ocr.jpg、*_layout.jpgが出力され、figuresディレクトリに画像が出力されている。
順番に見てみる。まず1ページ目。
Markdown
# 令和5年度 神戸市観光動向調査結果について
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とす<br>調査目的<br>ることを目的に実施。
# 調査方法
# 調査 日
# 調査地点
調査員が対面にてアンケート項目を聞き取りする形で実施。
1 令和5年 5月13日\(土\)·20日\(土\)※
2 令和5年 9月 9日\(土\)
3 令和5年11月25日\(土\)/12月2日\(土\)※
4 令和6年 2月10日\(土\)·17日\(土\)·24日/3月30日\(土\)※
※雨天等により、一部の調査地点については延期して実施。
|地区|NO|調査地点|サンプル数|
|-|-|-|-|
|北野|1|北野町広場|246|
||2|北野工房のまち|154|
|市街地|3|南京町広場|218|
||4|総合インフォメーションセンター|198|
||5|旧居留地|201|
||6|神戸布引ロープウェイハーブ園山麓駅|203|
||7|白鶴酒造資料館内|205|
||8|王子動物園内|235|
||9|県立美術館前|217|
||10|さんちか夢広場|208|
||11|神戸空港屋上階展望ロビー|212|
||12|IKEA神戸|192|
||13|能福寺\(兵庫大仏\)|147|
||14|兵庫津ミュージアム|204|
|神戸港|15|神戸海洋博物館前及び周辺|200|
||16|中突堤中央ターミナル周辺|208|
||17|umie モザイク|201|
||18|ハーバーランド総合インフォメーション前|213|
|六甲 · 摩耶|19|六甲天覧台|209|
||20|摩耶山掬星台広場|200|
||21|六甲山牧場内|215|
||22|六甲ガーデンテラス内|211|
|有馬|23|有馬温泉観光総合案内所前|214|
||24|金の湯前|216|
||25|六甲有馬ロープウェイ有馬温泉駅|232|
|須磨・舞子|26|須磨離宮公園|202|
||27|舞子公園\(舞子海上プロムナード\)|230|
|西北神|28|神戸ワイナリー\(農業公園\)|235|
||29|神戸フルーツ·フラワーパーク大沢園内|209|
||30|神戸三田プレミアム·アウトレット|215|
|合計|||6,250|
OCR

レイアウト。Markdownでどのように各要素が並べられたのかもわかる。

次に4ページ目
Markdown。グラフは画像としてリンクされている。
# 分析の詳細
# \(1\)性別構成
●性別構成としては、全市では「男性」が43\.5%、「女性」が56\.5%となっている。
●地区別にみると、『六甲·摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女<br>性」が30\.0ポイント高く、差が大きくなっている。
# 【図表1 性別構成】
|\(%\)|全市||||||||
|-|-|-|-|-|-|-|-|-|
|||北野|市街地|神戸港|六甲·摩耶|有馬|須磨・舞子|西北神|
|男性|43\.5|35\.0|42\.4|41\.4|53\.8|42\.4|42\.8|44\.3|
|女性|56\.5|65\.0|57\.6|58\.6|46\.2|57\.6\]|57\.2|55\.7|
<img src="figures/kobe_page_4_p1_figure_0.png" width="200px"><br>
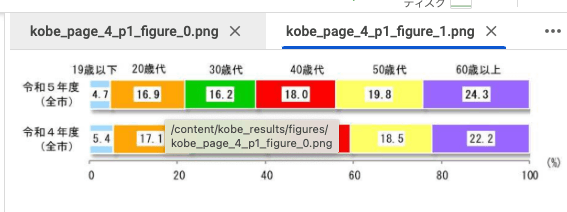
# \(2\)年齢構成
●年齢構成としては、全市では「60歳以上」が24\.3%で最も高く、次いで「50歳代」\(19\.8%\)、<br>「40歳代」\(18\.0%\)、「20歳代」\(16\.9%\)、「30歳代」\(16\.2%\)の順となっており、40歳代以<br>上が6割を超える。
●地区別にみると、『須磨·舞子』では「60歳以上」\(35\.9%\)が他の地区と比較して高くなっ<br>ている。
【図表2 年齢構成】
|\(%\)|全市||||||||
|-|-|-|-|-|-|-|-|-|
|||北野|市街地|神戸港|六甲・摩耶|有馬|須磨・舞子|西北神|
|19歳以下|4\.7|6\.3|3\.6|5\.6|5\.0|6\.2|2\.3|6\.2|
|20歳代|16\.9|24\.5|13\.7|18\.1|23\.0|22\.4|12\.0|12\.6|
|30歳代|16\.2|13\.3|17\.9|17\.5|15\.3|13\.6|15\.3|14\.7|
|40歳代|18\.0|14\.3|18\.6|18\.4|18\.0|14\.5|16\.9|22\.0|
|50歳代|19\.8|20\.5|19\.8|18\.9|20\.0|20\.7|17\.6|21\.2|
|60歳以上|24\.3|21\.3|26\.4|21\.5|18\.7|22\.7|35\.9|23\.2|
<img src="figures/kobe_page_4_p1_figure_1.png" width="200px"><br>
3
OCR

レイアウト

figuresディレクトリには図が保存されている。4ページにあるグラフはそれぞれ画像として保存されていた。

Usageを見てみる
!yomitoku --help
usage: yomitoku [-h] [-f FORMAT] [-v] [-o OUTDIR] [-d DEVICE] [--td_cfg TD_CFG] [--tr_cfg TR_CFG]
[--lp_cfg LP_CFG] [--tsr_cfg TSR_CFG] [--ignore_line_break] [--figure]
[--figure_letter] [--figure_width FIGURE_WIDTH] [--figure_dir FIGURE_DIR]
arg1
positional arguments:
arg1 path of target image file or directory
options:
-h, --help show this help message and exit
-f FORMAT, --format FORMAT
output format type (json or csv or html or md)
-v, --vis if set, visualize the result
-o OUTDIR, --outdir OUTDIR
output directory
-d DEVICE, --device DEVICE
device to use
--td_cfg TD_CFG path of text detector config file
--tr_cfg TR_CFG path of text recognizer config file
--lp_cfg LP_CFG path of layout parser config file
--tsr_cfg TSR_CFG path of table structure recognizer config file
--ignore_line_break if set, ignore line break in the output
--figure if set, export figure in the output
--figure_letter if set, export letter within figure in the output
--figure_width FIGURE_WIDTH
width of figure image in the output
--figure_dir FIGURE_DIR
directory to save figure images
READMEにも書いてあるけど、
--ignore_line_break: 画像の改行位置を無視して、段落内の文章を連結して返します。(デフォルト:画像通りの改行位置位置で改行します。)
Markdownの出力を踏まえると、つけておいても良さそう。
あと、レイアウト解析結果を見ていると、図内の文字もテキストとしては認識しているようなので、
--figure_letter: 検出した図表に含まれる文字も出力ファイルにエクスポートします。
は図の内容によっては有効にしたほうがいいユースケースがもしかするとあるかも。
まとめ
日本語特化だけ識字についてはかなり良好な印象。自分が試した感じで唯一イマイチだったのは、1ページ目の見出しが少しデザイン的になってるせいか、見出しとしては認識できているんだけど、その中身の順番がズレていた点だけかな。テーブルも読み取れていて、Markdownをレンダリングした結果を見てても見やすいと思う。
実例がいろいろ上がってるが、レイアウトが複雑なPOPや、縦書き文書、レシートや商品パッケージの記載のようなアスペクト比が歪んでいるようなものでも、いい感じに読み取れているように思えるので参考まで。