GUIフロー作成+DSPy最適化が可能なプラットフォーム「LangWatch」を試す
GitHubレポジトリ
LangWatch - LLM最適化スタジオ
LangWatchは、DSPy用のビジュアルインターフェースであり、LLMパイプラインの実験、測定、改善のための完全なLLM Opsプラットフォームです。公正なコード配布モデルを採用しています。
デモ
📺 LangWatchの概要や基本概念の紹介が含まれた短い動画(3分)で、プラットフォームのスニークピークがご覧いただけます。
特徴
🎯 最適化スタジオ
- LLMパイプラインを最適化するドラッグ&ドロップインターフェース
- スタンフォードのDSPyフレームワークに基づいて構築
- 自動プロンプト生成およびFew-shot例の生成
- ビジュアル実験追跡およびバージョン管理
📊 品質保証
- 30以上の既製エバリュエーターを搭載
- カスタム評価作成ツール
- 完全なデータセット管理機能
- コンプライアンスおよび安全性チェック
- DSPyビジュアライザー
📈 モニタリング&分析
- コストおよびパフォーマンスの追跡
- リアルタイムでのデバッグおよびトレース詳細
- ユーザー分析およびカスタムビジネスメトリクス
- カスタムダッシュボードおよびアラート機能
DSPyにGUIをつけてフローを作りながら最適化できる、というものらしい。DSPyとインテグレーションされてるってのが興味深い。レポジトリを見る限りはDockerで試せそう。
ただし、ライセンスはBSLなので注意。
クラウドサービスも提供している様なので、商用で使う場合にはこちらのほうが良さそう。
今回はローカルのMacでDockerを使って試してみる。
レポジトリクローン
git clone https://github.com/langwatch/langwatch && cd langwatch
.envを雛形から作成
cp langwatch/.env.example langwatch/.env
中身はこんな感じ
# LANGWATCH ENV FILE
# ==================
# Copy this file to ".env" and add your secrets according to the instructions below
# to configure the infrastructure and unlock all LangWatch functionality
# BASIC CONFIGURATION
# Define the environment you are running in, you can change this to production for a production deployment
NODE_ENV="development"
# Define the base host for the application, this is the hostname and port of the application, NEXTAUTH_URL should be the same
BASE_HOST="http://localhost:3000"
NEXTAUTH_URL="http://localhost:3000"
# This is a comma separated list of the namespaces of the messages you want to print following npm `debug` library standard
DEBUG=langwatch:*
# AUTHENTICATION
# LangWatch uses next-auth for authentication, configured by default with basic email/password
# You can change this to auth0 by adding the appropriate environment variables
NEXTAUTH_PROVIDER="email"
# This is the key used to encrypt cookie keys, BE SURE TO CHANGE IT before deploying to production
# You can generate a new secret on the command line with `openssl rand -base64 32`
NEXTAUTH_SECRET="please_please_please_change_me_asap"
# If you decide to go with auth0 as a provider instead of, be sure to uncomment and add the follow variables
# AUTH0_CLIENT_ID=""
# AUTH0_CLIENT_SECRET=""
# AUTH0_ISSUER=""
# Salt used to generate JWT tokens for API authentication, be sure to change it before deploying to production as well
API_TOKEN_JWT_SECRET="change me to a random string"
# SERVICES AND INFRASTRUCTURE
# LangWatch is a composition of multiple services and databases, be sure to have all of them pointing to the right addresses
# Postgres for primary data storage
DATABASE_URL="postgresql://prisma:prisma@localhost:5432/mydb?schema=mydb"
# ElasticSearch for observability, storing traces, spans, events, evaluation results, doing search, filtering and analytics
ELASTICSEARCH_NODE_URL="http://localhost:9200"
ELASTICSEARCH_API_KEY="some-random-password-which-is-greater-than-16-chars-long"
IS_OPENSEARCH="true"
# Redis for queues
REDIS_URL="redis://localhost:6379"
# LangWatch NLP service powers the playground, topic clustering and sentiment analysis
LANGWATCH_NLP_SERVICE="http://localhost:8080"
# LangEvals powers LangWatch evaluators and guardrails: https://github.com/langwatch/langevals/
LANGEVALS_ENDPOINT="http://localhost:8000"
# Google DLP PII Detection is used for automatically redacting PII in traces and spans. This is optional in development
# but mandatory in production. This variable should hold the stringified credentials json.
GOOGLE_APPLICATION_CREDENTIALS=
# Sendgrid is using for sending emails for triggers and new users invites
SENDGRID_API_KEY=
# MODELS
# Below are the optional env vars for different LLM models that are used for multiple LangWatch functionality, like evaluations,
# guardrails, playground, topic clustering and so on. At least Azure or OpenAI are recommended, to be able to generate embeddings.
# OpenAI, for embeddings and GPT-class LLMs
OPENAI_API_KEY=
# Azure, for embeddings and GPT-class LLMs
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
# Google VertexAI for Gemini-class LLMs, be sure to have credentials as a stringified JSON, location can be set to e.g. "europe-west3"
GOOGLE_APPLICATION_CREDENTIALS=
VERTEXAI_PROJECT=
VERTEXAI_LOCATION=
# Anthropic, for Claude-class LLMs
ANTHROPIC_API_KEY=
# Groq, for Llama 3, Mixtral and other open-source LLMs with top inference speed
GROQ_API_KEY=
とりあえず、OpenAIのAPIキーだけセットしておくこととする。
(snip)
# OpenAI, for embeddings and GPT-class LLMs
OPENAI_API_KEY=XXXXXXXXXXXX
(snip)
docker composeで起動
docker compose up --build
色々立ち上がってくる。
[+] Running 22/20
⠸ redis Pulling 11.3s
⠸ opensearch [⣿⠀⠀⣿⠀⣿⣿] Pulling 11.3s
⠸ langevals [⣿⣿⠀⣿⠀⣿⣿⣿⠀⠀⣿⣿] Pulling 11.3s
⠸ langwatch_nlp [⣿⠀⣿⠀⣀⠀⡀⣿⣿] 9.615MB / 263.6MB Pulling 11.3s
⠹ app [⠀⠀⣿⣿⣀⣿⠀⣿⣿⣿⠀] 14.29MB / 805.3MB Pulling 11.3s
⠹ postgres [⣿⣿⣿⠀⣀⣿⣿⣿⣿⣿⣀⣿⣿⣦] 21.38MB / 151.8MB Pulling 11.3s
起動後にブラウザで3000番ポートにアクセスすると、ログイン画面が表示される。アカウントを作成。

アカウント情報を入力

次に組織を作成

このあと多分アンケートのようなものが2,3あったはずだが、適当に答えていくということで割愛(キャプチャし忘れた)

LangWatchにある2つのソリューションのどちらから始めるかを聞かれる。今回はDSPyとのインテグレーションに興味があるので、左の「Optimization Studio」を選択。

ダッシュボードが表示され、ここからいろんな操作を行うことになる。

LangWatchによるフローの作成・評価・最適化
ドキュメントはこちら
で、ハンズオンとかQuick Start的なものが見当たらないのだけど、このYouTube動画を参考にするしかなさそう。
ワークフローを作成

どうやらRAG向けのテンプレートがあるので、まずはこれを見てみる。

ワークフローの名前や説明を入力。今回はそのまま作成。

こういうフローが作成された。
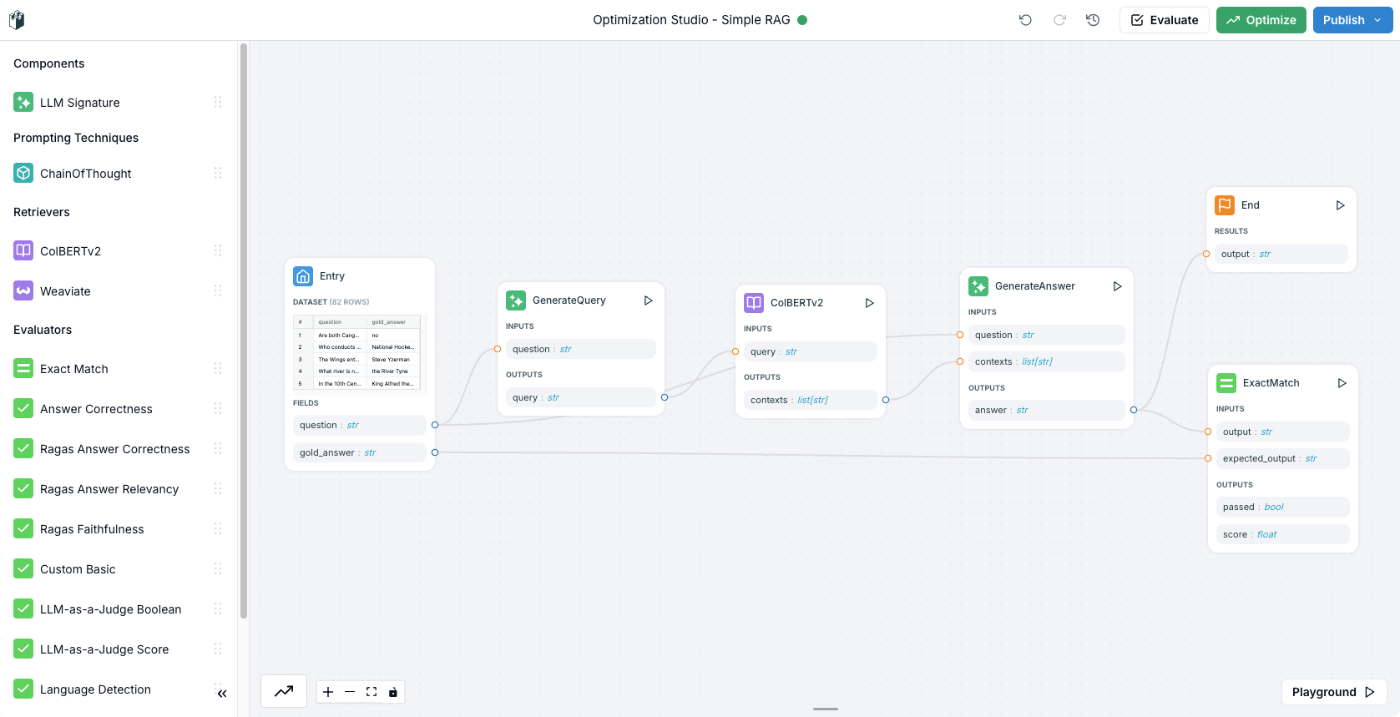
少しフローを見やすく並び替えた。

フローの流れを見てみる。まず最初の「Entry」。

ここには、質問と正しい回答のペアのデータセットが入っていて、このデータのそれぞれの値は変数として次のブロックに引き継がれる様子。あと、最適化時とそのテスト時にどういう割合で分割するか?というようなのも設定できるみたい。
データセットの表をクリックすると、全体が表示されどうやら編集などもできる様子。自分のデータセットを使う事も当然できるだろう。

次に「Generate Query」。ここはLLMへプロンプトを投げてレスポンスを受け取るというものだろう。プロンプトを見ると、入力されたクエリをWikipedia検索用のクエリに書き換えるというようなものになっている。

次に「ColBERTv2」。ここはRetrieverになっていて、ColBERTが使用されている様子。どうやらこのテンプレート用にLangWatch側で公開しているものではないかと思われる。

なお、RetrieverにはWeaviateも使える様子。

「GenerateAnswer」は、Retrieverの検索結果と最初に入力されたクエリを元にLLMが回答を生成する、まあごくごく一般的なRAGである。ここ変数の指定があるんだけど、プロンプトは空になっている。Instructionが指しているのはシステムプロンプト、ってことなのかな?であればどういうユーザプロンプトが投げられるのだろうか?

最後に生成結果を「End」で出力すると同時に、「ExaxtMatch」で評価する。

評価器は他にもいくつか用意されている。

RAGの評価でよく使いそうなものが並んでいる。
まずはいったん動かしてみる。右下のPlayGroundをクリック。

こういう画面が開いて、ここで試すことができるみたい。

データセットから1つデータをピックアップしておいた。
question: Which Scottish actor sang "Come What May"?
gold_answer: Ewan McGregor
上記の質問を入力してみた結果。

データセット通りではあるのだけど、全然知らないので調べてみたら正解みたい。
本日3月31日は、スコットランド出身の俳優ユアン・マクレガーの52歳の誕生日。
劇中でマクレガーは、エルトン・ジョンの名曲カバー「僕の歌は君の歌(原題:Your Song)」や、キッドマンとのデュエット曲「カム・ホワット・メイ」などを歌唱している。
ただし日本語でやってみると違う回答が返ってきた。まあこれはRetrieverなども含めて想定されない入力なのだと思う。本題ではないのでスルー。

ではまずこのフローを評価する。右上の「Evaluate」をクリック。

なるほど、フローはバージョン管理されている様子。で、データセットのどのデータを使って評価するかを選択できるみたい。


今回はデータセットの20%を使ってテストすることとする。ところで、OpenAIのAPIキーは.envでセットしておいたはずなのだけどなぁ・・・とりあえずセットする。

モデルの管理は別画面になる。一応OpenAIは有効化されているし問題ないのでは?と思ったけど

"Use custom settings"を開いてみるとAPIキーが入ってないように見える。とりあえず入力して保存。

元の画面に戻ってリロードして再度”Evaluate"をクリックするとどうやら進めるみたいなので、説明を入力して実行。

こんな感じでテストが行われた。正解率5%と惨憺たる結果である。

ではこれを「Optimize」してみる。

ここでOptimizerを選択して最適化を行う。
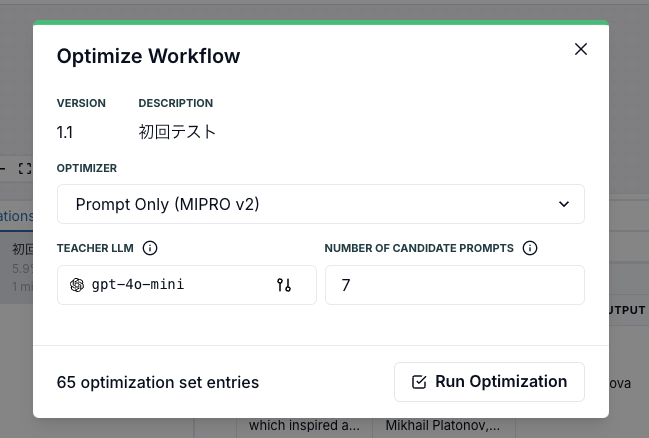
選択できるOptimizerは以下。DSPyで使用できるものがいくつかある、という感じかな、全部は知らないけど。

とりあえずデフォルトで実行。

最適化が開始される。それなりに時間がかかるのではないかなと思う。

"View Logs"をクリックするとログが表示される。

こんな感じで結果が表示された。見た感じ、最初の評価結果からはあまり変化はなさそうに思える。

タブを切り替えると、評価の内容やLLMへのリクエスト内容が確認できるみたい。(ここタブクリックしてから切り替わるまでにちょっと時間がかかる)

では最適化の結果を反映する。"Apply Optimization"をクリック。

どうやら2つのステップがアップデートされたようである。

が、自分が確認できたのはここだけ。もしかするとどこかほかも書き換わっているのかもしれないけど。

もうちょっと使いこなしてみないとわからないし、もう少し実例に近しいデータセットで試してみたいところだけど、DSPyがこういう感じで組み込まれているのはとても使いやすそうに思える。
デフォルトで用意されているブロック一覧。

なぜかChainOfThoughtのブロックだけ、配置できない・・・
ChainOfThoughtはSignatureブロック上にドロップしたら配置できた。なるほね、SignatureをChainOfThoughtでラップする。

そういえば、DSPyでも、SignatureをModuleでラップするのだった。
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
generate_answer = dspy.ChainOfThought(BasicQA)
あとちょいちょいこの画面が表示される。

リロードしたら直るんだけども、自分の環境依存なのかどうかは不明。
あまり改善が見られなかったところについて。
こんな感じで結果が表示された。見た感じ、最初の評価結果からはあまり変化はなさそうに思える。
Optimizerの選択肢を改めて見てみた。
選択できるOptimizerは以下。DSPyで使用できるものがいくつかある、という感じかな、全部は知らないけど。
なるほど、デフォルトだとプロンプトしか最適化されない。Few-shot(Demonstration)を有効にして再度最適化してみた。

最初の結果から29.41%に大幅に改善した!

反映させてみるとLLMを使うSignatureのステップでDemonstrationsが追加されているのがわかる。


DSPyのOptimizerについては以下に記載があるが、
LangWatchで選択できるのは以下となっている。
- プロンプトのみ最適化
- プロンプトとFew-shotを最適化
- Few-shotのみを最適化
フローの公開
作成・最適化したフローはどうやら公開できる様子。右上の"Publish"から"Publish Current Version"をクリック。

説明を入力して"Publish"

アプリの実行とAPIリファレンスへのリンクがそれぞれ用意される。

アプリはこんな感じで動作する。

APIリファレンスはこんな感じ。

APIキーは"Settings"の"Setup"で確認できる。


これを使ってリクエストを送ってみる。
LANGWATCH_API_KEY="XXXXXXXXXX"
LANGWATCH_ENDPOINT="http://localhost:3000/api/optimization/workflow_XXXXXXXXXX"
curl -X POST "$LANGWATCH_ENDPOINT" \
-H "X-Auth-Token: $LANGWATCH_API_KEY" \
-H "Content-Type: application/json" \
-d @- <<EOF
{
"question": "Which Scottish actor sang \"Come What May\"?"
}
EOF
{"trace_id":"trace_XXXXXXXXXXXX","status":"success","result":{"output":"Ewan McGregor"}}
その他の機能
その他の機能についてもざっくり見ていく。Workflowsはここまでにみてきた機能なので割愛。

Analytics
LLM使用に関する統計情報が出力される。

Messages
Playground、アプリ、API経由でのリクエストが記録されている様子。

Evaluations
評価器やガードレールを自動で設定できる。デフォルトではなにもないので追加してみる。

いろいろ選択できる。クラウドサービスが提供しているものを使うこともできるみたい。

Playground
複数のモデルを並べて、プロンプトを送信して、レスポンスを比較したり、というようなことができる。

Datasets
データセットの管理ができる。ここで登録したデータセットはワークフローで選択できたり、あとは"Evaluations"で有効にした評価器やガードレールでテストができる様子。

Annotations
Messagesに登録された入力・出力にアノテーションを付与することができるみたい。

詳しくは以下。
Experiments
ワークフロー上で行った、評価や最適化の結果の履歴をここで確認できる。


Settings
プロジェクトやチームメンバー、モデルなどの管理など。

まとめ
DSPyは以前に試したことがあるが、自分には「概念」を理解するのがなかなか難しくて(そもそもPyTorchを理解していないというのもあるとは思うけど)、最初のハードルを超えるのが大変だった
LangWatchを使えば、その最初のハードルを乗り越えるのが簡単になると思うし、DSPyを詳しく知らなくてもプロンプト最適化のメリットを享受できると思う。正直ここまで簡単にできるとは思っていなかった。LangWatchを使うこなす上ではやはりある程度DSPyの知識を持っておいたほうが良いとは思うけど、最初の一歩としては格段に入りやすいのではないかと思う。
あと、商用で使う場合にはライセンスのこともあるので、素直にクラウドサービス使うのが良さそうには思う。
余談
たまにDSPyをLangChainやLlamaIndexのようなフレームワークと並列に並べている記事などを見かけることがある。自分は知見がないのでわからないのだけど、果たしてそういうLLMアプリのフレームワークとして使うことはできるんだろうか?
そらやろうと思えばできるんだろうけども、自分が過去触ったときの記憶やドキュメントなどを見る限り、LLMアプリフレームワークとして色々やろうと思うと機能やインテグレーションが少ない気がするんだよね。なので自分の認識としてはプロンプトエンジニアツールの1つというふうに捉えている。
で、そうなってくると成果物は「プロンプト」になるのだけど、LangWatchを見ているとそうではなくて、最適化済みのプロンプトを含むフローをそのまま公開するというのがゴールになっているように思える。まあそれはそれでと思いつつも、プロンプトだけ得たい、という場合にはトレースの中身を見る、みたいなやり方しかないように思えるのだけど、どうなんだろう?