Closed3
時系列データのクラスタリング(競馬のラップ)
参考
TARGETから2017〜2023のラップデータをCSVエクスポートして実施することとする。
パッケージインストール
!pip install tslearn
!pip install japanize-matplotlib
ラップデータ読み込み
import pandas as pd
df = pd.read_csv("lap.csv", encoding='cp932')
df

前処理。ここはお好みで。自分は後で条件選択やラベルのためにいろいろ書き換えたりしてる。
# 1着タイム表記を秒に変換
def convert_to_seconds(time_str):
parts = time_str.split('.')
minutes = int(parts[0])
seconds = int(parts[1])
tenmsecs = int(parts[2])
total_seconds = minutes * 60 + seconds + tenmsecs * 0.1
return total_seconds
# 芝コースで内回り・外回りがある場合
def convert_trc_to_uchisoto(row_place, row_distance, row_trc):
# ref: https://targetfaq.jra-van.jp/faq/detail?site=SVKNEGBV&id=707
if row_place not in ["新潟","中山","京都","阪神"]:
return ""
if row_distance == 1000:
return ""
if row_trc == 0:
return "内"
elif row_trc == 8:
return "外"
else:
return ""
def concatenate_strings(*args):
return ''.join(map(str, args))
# 開催文字列から開催場所のマッピング
track_place_mapping = {
"札": "札幌",
"函": "函館",
"福": "福島",
"新": "新潟",
"東": "東京",
"中": "中山",
"名": "中京",
"京": "京都",
"阪": "阪神",
"小": "小倉",
}
# クラスのマッピング。オープン以上は施行数の関係上同一扱い。
class_mapping = {
'新馬': "新馬・未勝利",
'未勝利': "新馬・未勝利",
'500万': "1勝クラス",
'1勝': "1勝クラス",
'1000万': "2勝クラス",
'2勝': "2勝クラス",
'1600万': "3勝クラス",
'3勝': "3勝クラス",
'オープン': "オープン以上",
'OP(L)': "オープン以上",
'重賞': "オープン以上",
'G3': "オープン以上",
'G2': "オープン以上",
'G1': "オープン以上",
}
# 前処理諸々
df.rename(columns={
"レースID(新)":"レースID",
"日付S":"日付",
"TD":"芝ダ",
"区":"コース区分",
"1着タイム":"1着タイム",
"TrC":"トラックコード",
}, inplace=True)
df[['年', '月', '日']] = df['日付'].str.split('.', expand=True)
df['1着タイム(秒)'] = df['1着タイム'].apply(convert_to_seconds)
df["開催回次"], df["開催場所"], df["開催日次"] = zip(*df["開催"].map(list))
df["開催場所"] = df["開催場所"].map(track_place_mapping)
df["内外"] = df.apply(
lambda row: convert_trc_to_uchisoto(row['開催場所'], row['距離'], row['トラックコード']), axis=1
)
df["コース名"] = df.apply(
lambda row: concatenate_strings(row['開催場所'], row['芝ダ'], row['距離'], row['内外']), axis=1
)
df["コース区分"] = df["コース区分"].fillna("")
df["クラス区分"] = df["クラス"].map(class_mapping)
# 余計な列を削除
df.drop(columns=["トラックコード","開催","年齢","日付","クラス"], inplace=True)
df

コースの種類はこんな感じになる
df["コース名"].unique()
array(['新潟芝1000', '函館芝1000', '札幌芝1000', '京都芝1200内', '中京芝1200', '小倉芝1200',
'阪神芝1200内', '福島芝1200', '新潟芝1200内', '函館芝1200', '札幌芝1200',
'中山芝1200外', '中京芝1400', '東京芝1400', '阪神芝1400内', '京都芝1400内',
'新潟芝1400内', '京都芝1400外', '札幌芝1500', '京都芝1600内', '中京芝1600',
'東京芝1600', '中山芝1600外', '京都芝1600外', '阪神芝1600外', '新潟芝1600外',
'小倉芝1700', '中山芝1800内', '東京芝1800', '小倉芝1800', '福島芝1800', '函館芝1800',
'札幌芝1800', '京都芝1800外', '阪神芝1800外', '新潟芝1800外', '中山芝2000内',
'京都芝2000内', '中京芝2000', '東京芝2000', '小倉芝2000', '阪神芝2000内', '福島芝2000',
'新潟芝2000内', '函館芝2000', '札幌芝2000', '新潟芝2000外', '中京芝2200',
'阪神芝2200内', '新潟芝2200内', '中山芝2200外', '京都芝2200外', '東京芝2300',
'東京芝2400', '新潟芝2400内', '京都芝2400外', '阪神芝2400外', '中山芝2500内',
'東京芝2500', '小倉芝2600', '福島芝2600', '函館芝2600', '札幌芝2600', '阪神芝2600外',
'阪神芝3000内', '中京芝3000', '京都芝3000外', '阪神芝3200内', '京都芝3200外',
'東京芝3400', '中山芝3600内', '小倉ダ1000', '函館ダ1000', '札幌ダ1000', '福島ダ1150',
'中山ダ1200', '京都ダ1200', '中京ダ1200', '阪神ダ1200', '新潟ダ1200', '東京ダ1300',
'京都ダ1400', '中京ダ1400', '東京ダ1400', '阪神ダ1400', '東京ダ1600', '小倉ダ1700',
'福島ダ1700', '函館ダ1700', '札幌ダ1700', '中山ダ1800', '京都ダ1800', '中京ダ1800',
'阪神ダ1800', '新潟ダ1800', '京都ダ1900', '中京ダ1900', '阪神ダ2000', '東京ダ2100',
'中山ダ2400', '東京ダ2400', '小倉ダ2400', '函館ダ2400', '札幌ダ2400', '福島ダ2400',
'新潟ダ2500', '中山ダ2500'], dtype=object)
時系列データの長さ=ラップ数は同じである必要がある。今回は特定のコースで絞り込むことにした。例えば"中山芝1200(外)"の場合はラップ数が常に6になる(競馬の場合、基本的には200mごとにラップが取得される)。他の条件も必要であれば設定。
以下は、
- 中山芝1200m(外回り)
- 馬場状態: 良
- クラス: オープンクラス以上
で抽出して、別のデータフレームを作成している。
df_lap_tmp = df[(df["コース名"] == "中山芝1200外") & (df["馬場状態"].isin(["良"])) & (df["クラス区分"] == "オープン以上")]
df_lap = df_lap_tmp["ラップタイム"].str.split('-', expand=True).astype(float)
df_lap.columns = [f'Lap {i+1}' for i in range(df_lap.shape[1])]
df_lap['ID'] = df_lap_tmp['レースID']
df_lap.set_index("ID", inplace=True)
df_lap

ではこれをtslearnを使って時系列データのクラスタリングを行う。tslearnのto_time_series_datasetを使うとデータフレームからtslearnで扱える時系列データのオブジェクトに変換してくれるらしい。それを下にまずはmatplotlibで可視化してみる。
from tslearn.utils import to_time_series_dataset
import matplotlib.pyplot as plt
import japanize_matplotlib
time_np = to_time_series_dataset(df_lap)
fig, ax = plt.subplots(figsize=(10,6))
for i, x in enumerate(time_np):
ax.plot(x, label='race_id_'+str(df_lap.index[i]))
ax.legend(loc='upper left', bbox_to_anchor=(1.05, 1))
plt.gca().invert_yaxis()
plt.show()

次にいくつのクラスタに分けるか?をエルボー法で求める。
from tslearn.clustering import TimeSeriesKMeans
inertia = []
for n_clusters in range(1,12):
km = TimeSeriesKMeans(n_clusters=n_clusters, metric='euclidean', random_state=0)
km.fit(time_np)
inertia.append(km.inertia_)
plt.figure(figsize=(10, 6))
plt.plot(range(1,12), inertia, marker='o')
plt.xlabel('num of clusters')
plt.ylabel('SSE')
plt.title('エルボー法によるクラスタ数算出')
plt.show()

ちょうど折れ曲がってるところの頂点が適切らしいのだけども、今回はちょっとわかりにくいかも。4あたりにする。
クラスタごとに表示。
import numpy as np
n = 4
km_euclidean = TimeSeriesKMeans(n_clusters=n, metric='euclidean', random_state=0)
labels_euclidean = km_euclidean.fit_predict(time_np)
fig, axes = plt.subplots(n, figsize=(10,n*6))
plt.subplots_adjust(hspace=0.5)
for i in range(n):
ax = axes[i]
for x in time_np[labels_euclidean == i]:
ax.plot(x.ravel(), 'k-', alpha=0.2)
ax.plot(km_euclidean.cluster_centers_[i].ravel(), 'r-')
datanum = np.count_nonzero(labels_euclidean == i)
centroids = km_euclidean.cluster_centers_[i].ravel()
centroids_str = '-'.join(f"{v:.1f}" for v in centroids)
sum_f3 = sum(centroids[0:3])
sum_l3 = sum(centroids[-3:])
sum_min = int(sum(centroids) // 60)
sum_sec = sum(centroids) % 60
sum_str = f"{sum_min}:{sum_sec:04.1f}"
ax.set_title(f"中山芝1200外・OP以上 ラップクラスタリング(Cluster{(i+1)} : n = {datanum})\n{centroids_str} = {sum_str}(前3F:{sum_f3:.1f}、後3F:{sum_l3:.1f})")
ax.invert_yaxis()
plt.show()
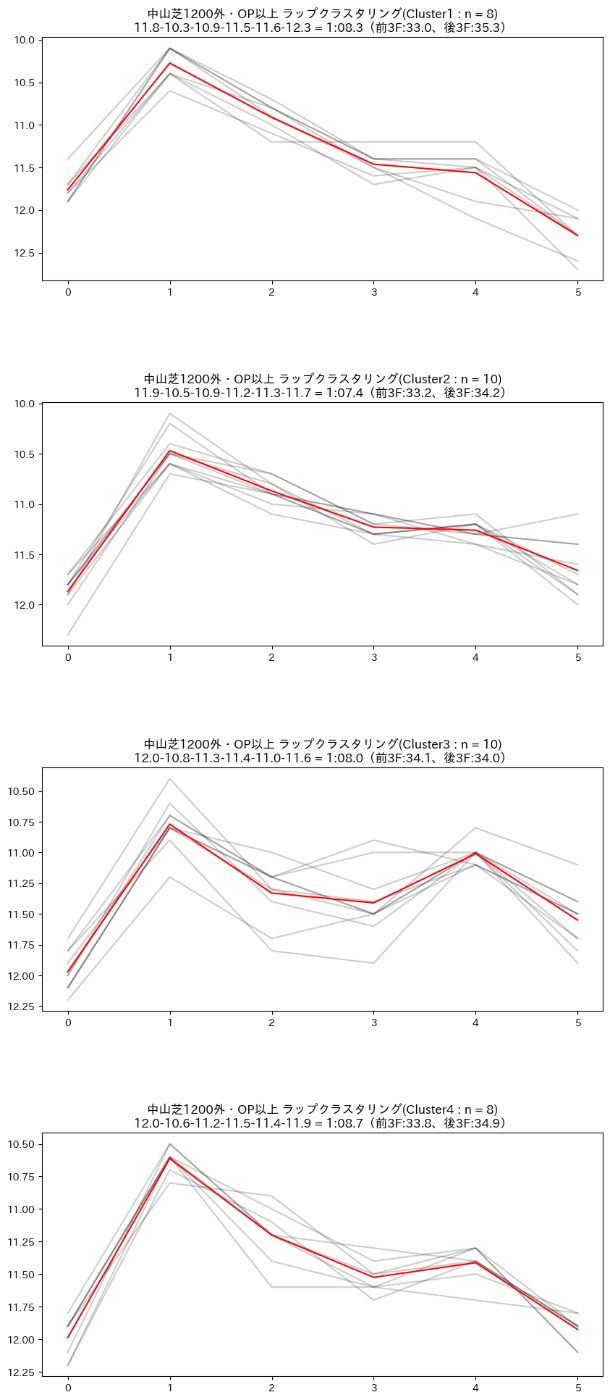
余談だが、中山芝1200m外回りの特徴は以下にある。
- スタートしてから最終コーナーまでずっと緩やかな右回りで下り坂が続く。
- コーナーらしいコーナーは最終コーナーのみ。
- 中山競馬場の最終直線は短く最後に急な上り坂がある
ということで基本的に先行してどんどん速度を上げて最後は惰性で坂を登りきって最後まで頑張る、というペースになるので、上記のような前傾ラップに自然になりやすい。
が、その中でも中間のラップが緩むようなケースというのが半分ぐらいはあるのだということがわかる。
全部まとめて表示
n = 4
km_euclidean = TimeSeriesKMeans(n_clusters=n, metric='euclidean', random_state=0)
labels_euclidean = km_euclidean.fit_predict(df_lap)
colors = {0: 'red', 1: 'green', 2: 'blue', 3: 'black'}
plt.figure(figsize=(10, 6))
for label in np.unique(labels_euclidean):
cluster_indices = np.where(labels_euclidean == label)[0]
for idx in cluster_indices:
plt.plot(df_lap.iloc[idx], color=colors[label], alpha=0.5, linewidth=1, label=f'Cluster {label}' if f'Cluster {label}' not in plt.gca().get_legend_handles_labels()[1] else "")
for i in range(n):
plt.plot(km_euclidean.cluster_centers_[i], color=colors[i], linewidth=2, label=f'Centroid {i}' if f'Centroid {i}' not in plt.gca().get_legend_handles_labels()[1] else "")
plt.gca().invert_yaxis()
plt.title('中山芝1200外・OP以上 ラップクラスタリング')
plt.legend(loc='upper left', bbox_to_anchor=(1.05, 1))
plt.show()

次は時系列データの類似度を取ってみたい。
このスクラップは2024/06/13にクローズされました