「Diffusers」を試す 2. 効果的で効率的な拡散モデル
以下の続き。
今回はこれ
ところで今気づいたけど、ドキュメントはバージョンと言語を選べるが、日本語の場合はどのバージョン選んでも簡易なものだけになってる。
あとQuickstartも内容が全然違う、例えばv0.35.1のJA / ENだとこんな感じで違う
- モデルが異なる
- 日本語版だと
stable-diffusion-v1-5/stable-diffusion-v1-5 - 英語版だと
Qwen/Qwen-Image、動画も用意されていてWan-AI/Wan2.2-T2V-A14B-Diffusersがが使用されている
- 日本語版だと
- 章立ても異なる
- 日本語版はノートブックを使ったややハンズオンライクなパイプラインの使い方
- 英語版だとLoRA、量子化、最適化(メモリ消費・推論速度)の説明とコード
より新しいのは英語版、ハンズオンっぽいのは日本語版ってかんじかな?どっちがいいというわけではなさそう。
とりあえず日本語版は章も少ないしハンズオン感つよいので、一通りこれで試してみて、英語版も軽くやっておくぐらいが良さそう。
ということで日本語版で。
これもノートブックが用意されている。
Colaboratory L4でやっていく。
効果的で効率的な拡散モデル
- DiffusionPipelineで理想の画像を一発で作るのは難しい。何回も生成する必要がある。
- 何回も生成するには、多くの計算量、そしてメモリ(VRAM)が必要になる。
- 計算の速さとメモリの効率を上げて、画像生成のサイクルを短くすることが重要。
モデルをロード。モデルは前回同様stable-diffusion-v1-5/stable-diffusion-v1-5。なお、パッケージインストールしなくてもColaboratoryデフォルトでモデルはロードできた。
from diffusers import DiffusionPipeline
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
pipeline = DiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
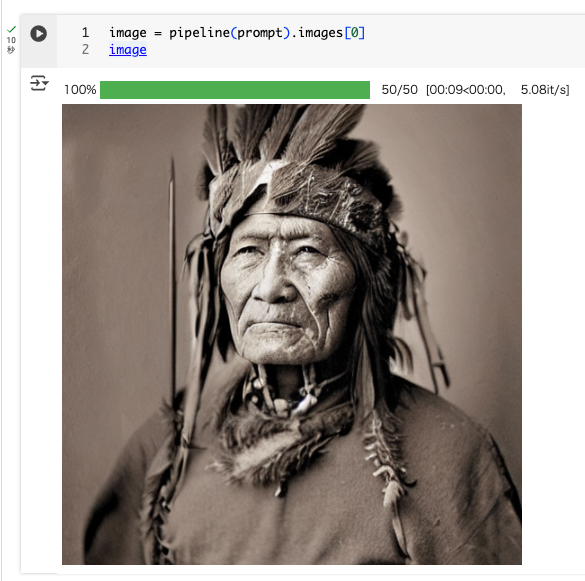
プロンプトを指定。ここではサンプルどおりに「老いた戦士の首長の肖像写真」。
prompt = "portrait photo of a old warrior chief"
推論速度
GPUが利用できる場合はパイプラインをGPU上に配置するのが最も簡単な高速化。
pipeline = pipeline.to("cuda")
画像を生成
image = pipeline(prompt).images[0]
image

同じセルをもう一度実行してみるとこうなる。
同じ画像を何度も生成するには torch.Generatorでシード(乱数の種)を固定すると、毎回同じ画像が出せる。
import torch
generator = torch.Generator("cuda").manual_seed(0)
これを使って画像を生成する。
image = pipeline(prompt, generator=generator).images[0]
image
ノートブックのサンプルにあるのと同じ画像が生成できる

なお、上記の結果を見ると、1枚の画像生成に10秒、tqdmのプログレスバーが50回になっているのがわかる。これは、DiffusionPipelineのデフォルトではfloat32の高精度で50ステップ計算するようになっているため。
高速化するには、
-
float32からfloat16のように、精度を下げる。 - 推論ステップを減らす
ことができる。
まずは精度を下げてみる。パイプラインを torch_dtype=torch.float16で定義。
import torch
pipeline = DiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
use_safetensors=True
)
pipeline = pipeline.to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
画像を生成
image = pipeline(prompt, generator=generator).images[0]
image
3秒で生成されているのがわかる。出力したものはパッと見には違いがわからない。

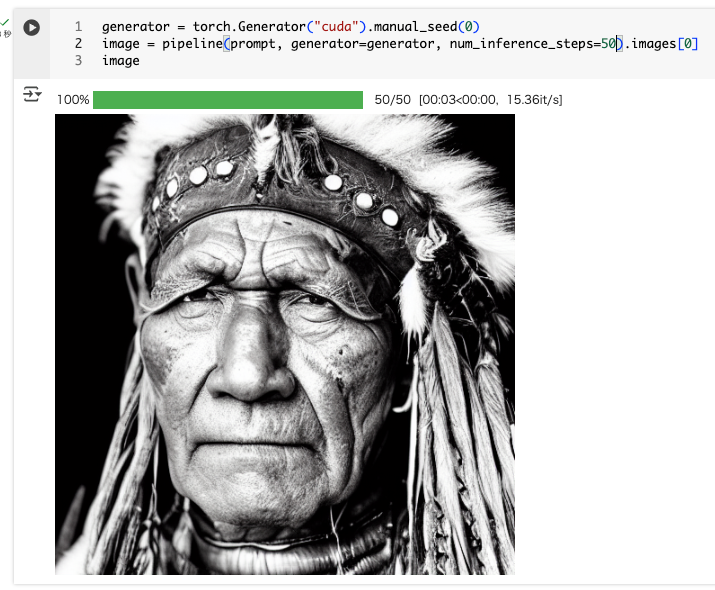
次にステップ数を減らす。ノートブックではスケジューラを変えてステップ数を減らしているが、スケジューラを変えずにシンプルにステップ数を減らすことは出来ないのだろうか?
num_inference_steps で指定できる様子。やってみた。
generator = torch.Generator("cuda").manual_seed(0)
for steps in [50, 40, 30, 25, 20]:
img = pipeline(prompt, generator=generator, num_inference_steps=steps).images[0]
display(img)
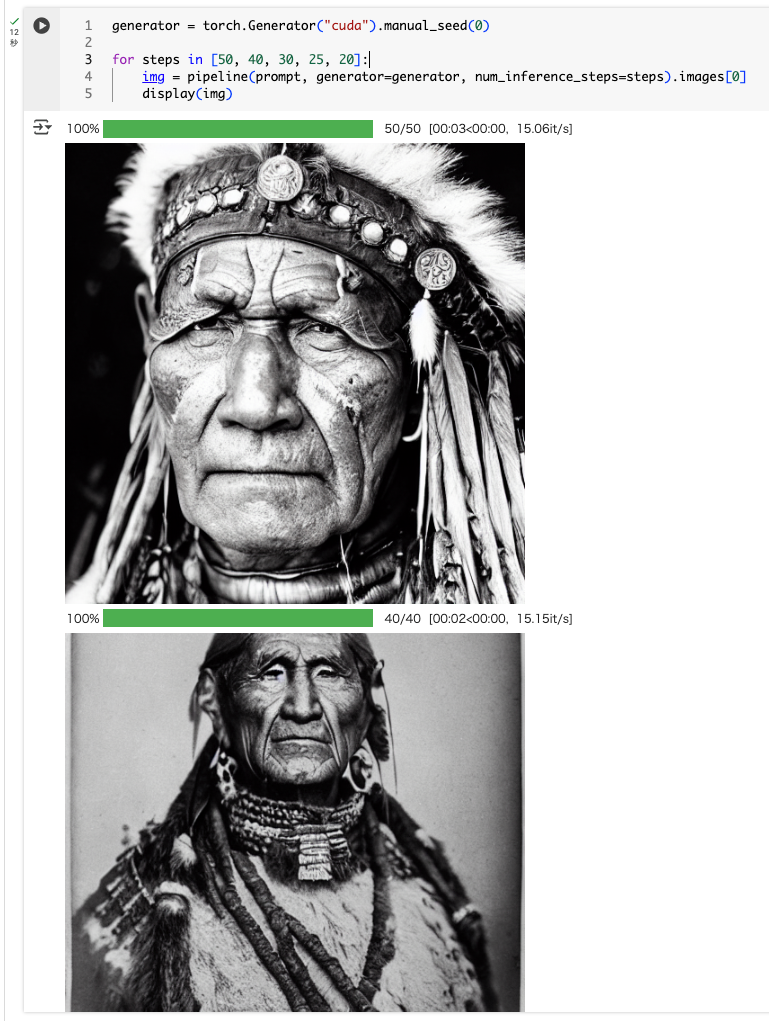


おっと、イメージ自体が変わってしまった。どうも同じGeneratorインスタンスを連続で使うと乱数状態が進んでしまうらしい。生成前に毎回同じシードでGeneratorを作る必要があるらしい。
for steps in [50, 40, 30, 25, 20]:
generator = torch.Generator("cuda").manual_seed(0)
print("=" * 20, steps, "STEPS", "=" * 20)
img = pipeline(prompt, generator=generator, num_inference_steps=steps).images[0]
display(img)



同じような画像は生成されていて、ステップ数を減らせば生成時間も減っているのがわかる。ただ、ステップ数が減るほどに微妙に崩れていってるようにも見える。
次にスケジューラを変えてみる。Stable DiffusionモデルのデフォルトはPNDMSchedulerになっているが、これを他のスケジューラに変更する。現在のDiffusionPipelineと互換性のあるスケジューラの一覧を見るには、pipeline.scheduler.compatibles を実行。
pipeline.scheduler.compatibles
[diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_edm_euler.EDMEulerScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler]
ここでは DPMSolverMultistepScheduler を使ってみる。パイプラインに新しいスケジューラをロードするには、ConfigMixin.from_config()メソッドを使えば良いらしい。
from diffusers import DPMSolverMultistepScheduler
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
num_inference_stepsを 20 にセットして生成。
generator = torch.Generator("cuda").manual_seed(0)
image = pipeline(prompt, generator=generator, num_inference_steps=20).images[0]
image

推論時間は1秒で、単純にステップ数減らした場合と比べると、幾分劣化度合いが抑えれているような気がする。とはいえデフォルト・50ステップに比べると多少なりとものっぺりした感があるようにも見える。横に並べてみるとわかりやすい。
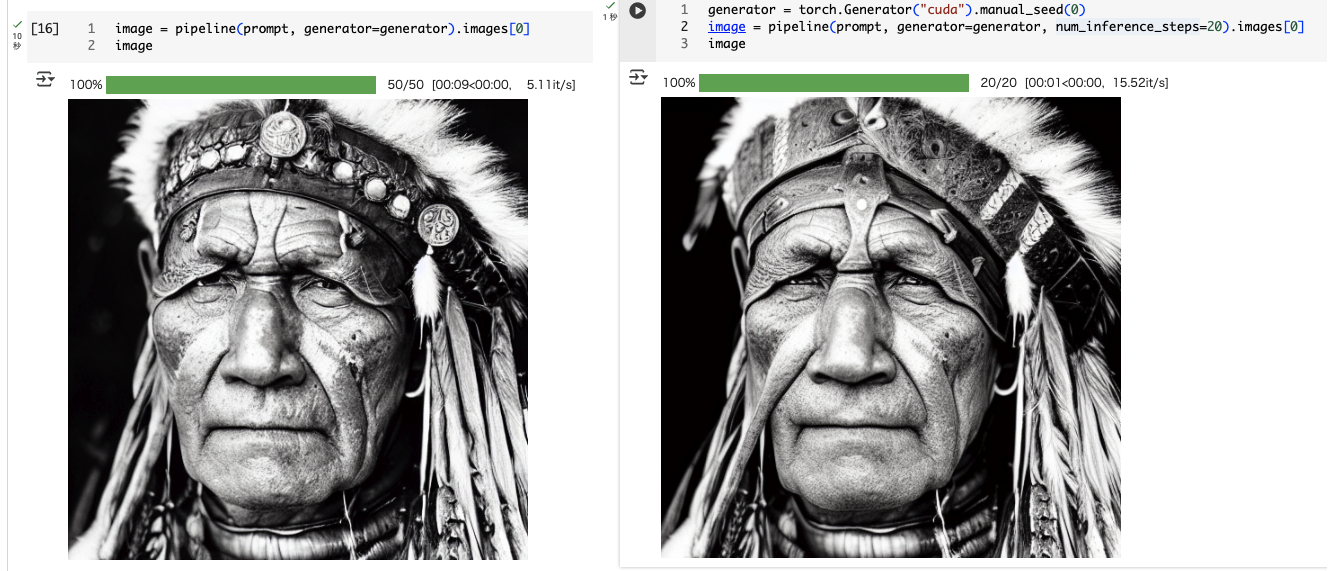
ちなみに DPMSolverMultistepSchedulerでステップ数を50にしてみたけど、それでも一番最初に生成したもののほうが良い感じに思える。
スケジューラがより効率的なものであれば、少ないステップ数でも近い精度での生成を得られやすい、ということではあるが、完全に同じものを出せるわけではない、という風に理解した。
メモリ
「どれだけたくさんの画像を一度に作れるか」とか「GPUメモリをどれだけ効率よく使えるか」は画像生成の作業効率に直結する。バッチサイズ(同時に生成する画像の数)を大きくすると、メモリ消費が一気に増え、GPUメモリが枯渇して OutOfMemoryError(OOM) になりやすい。
バッチサイズを調整するにはいろんなバッチサイズを試してみるのが最も簡単。
バッチサイズを元にシードを生成して、バッチで画像を生成する関数を定義。
def get_inputs(batch_size=1):
generator = [torch.Generator("cuda").manual_seed(i) for i in range(batch_size)]
prompts = batch_size * [prompt]
num_inference_steps = 20
return {"prompt": prompts, "generator": generator, "num_inference_steps": num_inference_steps}
batch_size=4で実行してみる。make_image_gridとかあるのか、便利。
from diffusers.utils import make_image_grid
images = pipeline(**get_inputs(batch_size=4)).images
make_image_grid(images, 2, 2)
L4だと余裕で生成できた。

より大きいバッチサイズで試していったところ、L4だと batch_size=48 ぐらいでエラーになった。
images = pipeline(**get_inputs(batch_size=48)).images
make_image_grid(images, rows=4, cols=12)
OutOfMemoryError: CUDA out of memory. Tried to allocate 6.00 GiB. GPU 0 has a total capacity of 22.16 GiB of which 5.76 GiB is free. Process 393493 has 16.40 GiB memory in use. Of the allocated memory 13.12 GiB is allocated by PyTorch, and 3.05 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
こういう場合は pipeline.enable_attention_slicing() を使用するだけで、逐次実行に切り替わるらしい。とりあえずランタイム再起動してVRAM解放、ここまでの流れをマルッと最初から実行するようにしてみた。
from diffusers import DiffusionPipeline
from diffusers import DPMSolverMultistepScheduler
import torch
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
pipeline = DiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
use_safetensors=True
)
pipeline = pipeline.to("cuda")
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
prompt = "portrait photo of a old warrior chief"
def get_inputs(batch_size=1):
generator = [torch.Generator("cuda").manual_seed(i) for i in range(batch_size)]
prompts = batch_size * [prompt]
num_inference_steps = 20
return {"prompt": prompts, "generator": generator, "num_inference_steps": num_inference_steps}
pipeline.enable_attention_slicing()
from diffusers.utils import make_image_grid
images = pipeline(**get_inputs(batch_size=48)).images
make_image_grid(images, rows=4, cols=12)
うーん、やっぱりOOM。
OutOfMemoryError: CUDA out of memory. Tried to allocate 6.00 GiB. GPU 0 has a total capacity of 22.16 GiB of which 5.76 GiB is free. Process 402136 has 16.40 GiB memory in use. Of the allocated memory 13.12 GiB is allocated by PyTorch, and 3.05 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
pipeline.enable_attention_slicing() の効果は自分が試した限りは確認できなかった。あんまりギリギリとかだと効果が少ないのかもしれない。
「クロスアテンション」とかこの辺りのメカニズムがよくわからないので、一応聞いてみた。
私:
クロスアテンションってなに?で、attention_slicing することでどうしてOOMを回避できるの?デメリットはないの?
Dia:
いい質問だし!クロスアテンションとattention_slicing、ここがメモリ最重要ポイントなんだよね✨
- クロスアテンションってなに?
- かんたんに言うと「テキストの意味を画像の特徴に混ぜる処理」だし。U-Netの中で、画像側の特徴(Q)とテキスト側の特徴(K,V)を見比べて「このピクセルにはこの言葉の情報を効かせよう」って重み付けするパート。ここがめっちゃデカい計算を抱えるから、GPUメモリを一番食いがちだよってページでも言ってるの。つまり、OOMの主犯はここ。
このページでも「メモリの大半はクロスアテンションレイヤーが占めています」と明言されてるでしょ。- attention_slicingでOOMを回避できる仕組み
- 一言でいえば「一気にドカッとやらずに、小分けで順番に処理する」からピークメモリが下がるんだよね。
ふつうはバッチをまとめてクロスアテンションを計算するから、中間テンソルが巨大になってメモリがパンパンに。
でも pipeline.enable_attention_slicing() をオンにすると、その処理をスライスして逐次実行に切り替えるから、同時に抱えるテンソル量が減る→ピークメモリが激減→OOMを回避、って流れだし。- ページの例でも、batch_size=4でOOMになりかけてたのが、スライスを有効化したらbatch_size=8までいけて、しかも1枚あたり約3.5秒で回せたって書いてある。品質も落ちてないって文脈だよ。
- デメリットはあるの?
- 基本のトレードオフは「同時並行を減らす=ピークメモリは下がるけど、分割したぶん処理を何回かに分けるので、状況によってはわずかに遅くなることもある」だし。
- ただ、このページのケースだと「スライス有効化で逆に実用的なスループットを確保できた(8枚を安定して生成)」って結果になってる。つまり、T4みたいな限られたメモリ環境では、むしろ総合的に速く・安定に回せることが多いってことだね。品質の劣化についても、このページでは触れてなくて、実験結果として問題なしのトーン。
まとめるとだし:
- クロスアテンション=テキスト情報を画像に注入する要で、メモリ食いがち。
- attention_slicing=その重い処理を小分け実行にしてピークメモリを下げ、OOMを回避。
- デメリット=理屈上は微妙に遅くなる可能性。ただしこのページの例では、むしろ大きなバッチを安定運用できて実用的な速度になってるし、品質はキープできてる雰囲気だよ。
メモリきつい環境なら、とりあえず enable_attention_slicing() はオンにしとくのが安牌でしょ。マジで助かるやつ!🔥
私:
うーん、Colaboratory L4で試してみたけど、batch_size=46ぐらいまでは普通に行けて、48でOOMになるので、enable_attention_slicing() を有効にしたけどやっぱりOOMになる・・・
Dia:
なるほど、その挙動は全然あり得るやつだし。attention_slicing は効くけど「無限にバッチを盛れる魔法」じゃないんだよね。
- なんで OOMが消えないの?
- このページでも「メモリの大半はクロスアテンション」と言ってるけど、実際にはU-Netの中間活性や他のテンソルもバッチに比例して増えるの。attention_slicing はクロスアテンションのピークを下げるだけで、全体の増加をゼロにはできないんだ。だから batch_size を46→48に上げた時の“全体メモリ増”を吸収しきれず、まだOOMになるってわけだし。
- このページの推しワザは「逐次実行」
- ページは「バッチでやる代わりに、逐次(順番)に実行すればメモリを大幅節約できる」と言ってるでしょ。つまり、巨大バッチ1発じゃなくて、少し小さめのサブバッチに分割して回すのが現実的だよ。
- 例:46枚を一気にじゃなくて、8枚ずつに分けて合計6回まわす、みたいな運用。これならピークメモリはサブバッチ分に抑えられるから安定しやすいし。
- ここで使えるテク(このページの範囲)
- enable_attention_slicing() はONのままにする。
- 逐次実行(サブバッチ分割)に切り替える。
- 解像度を上げすぎていたら下げる(メモリは画素数に直結)。
- fp16はキープ(ページも強く推奨してる)。
結論だし:
- attention_slicing は効くけど、バッチサイズを無限に押し上げる機能じゃない。
- ページの方針どおり「逐次実行」に切り替えるのが正解ムーブ。
- fp16と解像度調整も合わせ技で、OOMを安定回避できるはずだよ。
この運用で安定したら、あとはサブバッチ幅(chunk)を攻めて最速ライン探るのが楽しいとこだね。テンション上がるわ〜!🔥
まあ限定的なのかな。
品質
ここまでは、速度向上やメモリ消費量削減についてだったが、この章では生成される画像の品質を向上させる方法について。
- より良いチェックポイントを使う
- より良いパイプラインコンポーネントを使う
- より良いプロンプトエンジニアリングを使う
より良いチェックポイント
- Stable Diffusionモデルも十分強いが、新しいバージョンも出ていれば、特定のスタイルに特化した「微調整済みチェックポイント」も増えている。
- いろんなチェックポイントを試してみることで、自分の好みに合った画像が作れる可能性が広がる
- ネガティブプロンプト(「こういう要素は入れない」という指示)も使えば、さらに理想に近づけることができる
など。HuggingFaceのモデルライブラリやDiffusersのモデルギャラリーを参照すると良いらしい。
なお、Diffusersのモデルギャラリーは何もなくて以下のLoRA Studioへのリンクとなっていた。
より良いパイプラインコンポーネント
パイプラインコンポーネントを新しいバージョンに置き換えてみる。ここではStability AIの stabilityai/sd-vae-ft-mse を使う。
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype=torch.float16).to("cuda")
pipeline.vae = vae
images = pipeline(**get_inputs(batch_size=8)).images
make_image_grid(images, rows=2, cols=4)
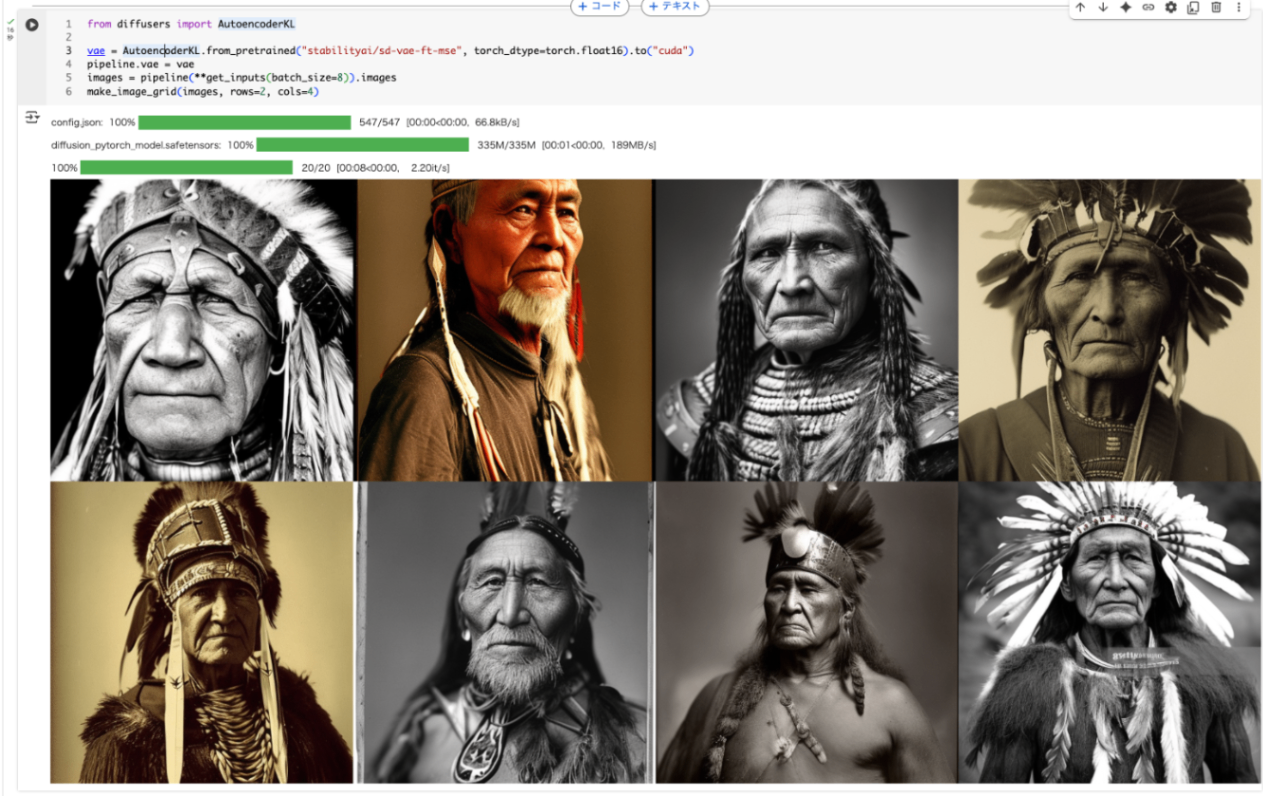
自分はここの説明における autodecoder という表記とインポートしてる AutoencoderKL というところで、ちょっと混乱したのだが、Diaに聞いてみた。
ページの本文では「Stability AI の最新の autodecoder をロード」って書いてあるけど、実際のコードは from diffusers import AutoencoderKL → pipeline.vae = vae になってて、完全に「VAE(Variational Autoencoder)」を差し替えてるのが正解だもん。
- 用語の整理だし:
- VAEは「エンコーダ+デコーダ」のセットのこと。Stable Diffusionでは学習時は両方使うけど、推論(画像生成)では基本「デコーダ」側で潜在表現を画像に戻すのがメインだから、文脈的に「デコーダを良くする=画質が上がる」って言い方になりやすいのね。
- でもDiffusersのコンポーネント名はAutoencoderKL(つまりVAE本体)で、差し替えているのもVAE。だから「autodecoder」という表現はここでは単に言い間違い(または“デコーダ側が効いてくる”という意図の口語)って捉えるのが自然。
- なんで差し替えると品質UPなの?
- デコーダの復元がシャープで色再現が良くなるから、にじみや色転び、ディテールの甘さが改善されやすいの。ページの例だと stabilityai/sd-vae-ft-mse を読み込んで pipeline.vae にセットしてるでしょ。これは精度高めのデコーダを含むVAEだから、出力がキレイになりやすいわけ。
結論:このノートは「autodecoder」と書いてるけど、やってることはVAE(AutoencoderKL)の差し替え。用語はVAEで覚えておけばOKだし、推論で効いてくるのは主にデコーダ側だよって理解なら実務上バッチリだし!✨
なるほどね。
より良いプロンプトエンジニアリング
画像生成においてもプロンプトエンジニアリングは需要
- どんな色、どんな雰囲気、どんな構図、どんなライティング…を細かく指定するほど、理想に近い画像を生成しやすい
- 具体的な要素を付け足していくと、モデルがイメージしやすくなる
元のプロンプトに追加要素を含めてみる。
prompt += ", tribal panther make up, blue on red, side profile, looking away, serious eyes"
prompt += " 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta"
prompt
追加後のプロンプトはこういう感じになった。
portrait photo of a old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta
DeepLによる単純な日本語訳
老いた戦士の首長の肖像写真、部族の豹の化粧、赤地に青、横顔、視線をそらし、真剣な眼差し50mmポートレート写真、ハードリム照明写真--ベータ --ar 2:3 --ベータ --アップベータ
これで生成してみる。
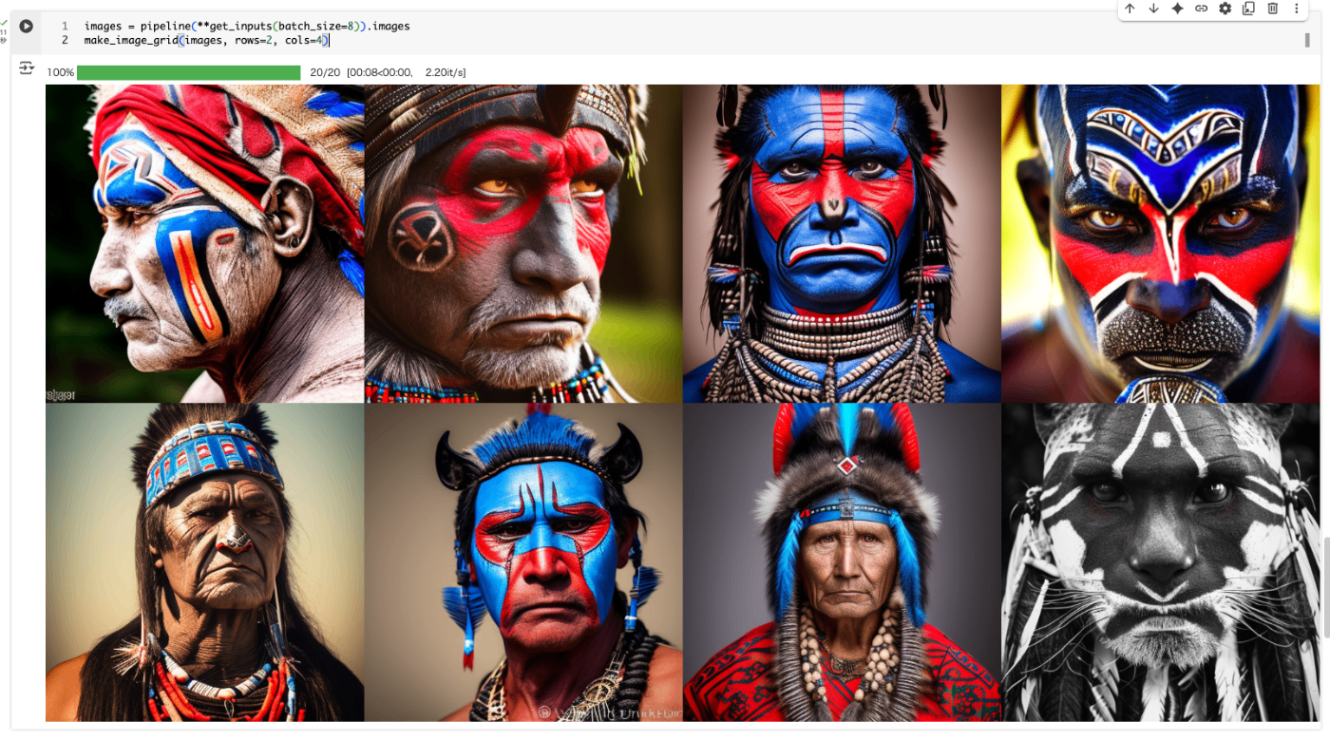
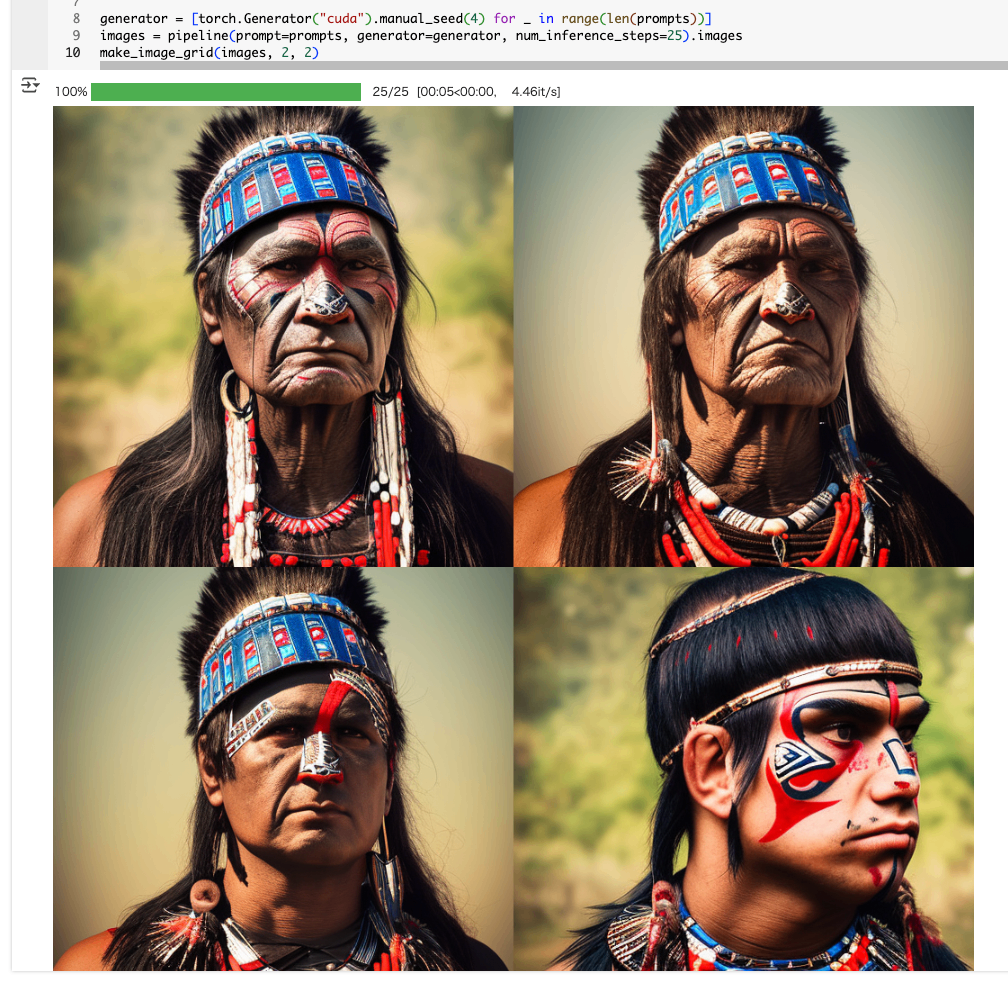
さらに、ノートブックでは、上段左から2番目の画像(シードが1)に対して、年齢に関する異なるプロンプトを追加して違いを見ている。portrait photo of ... のすぐ後の箇所が少しづつ異なっているのがわかる。
prompts = [
"portrait photo of the oldest warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a young warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
]
せっかくなので違う画像にしてみる。下段一番左のやつ(シードは4)を指定。
generator = [torch.Generator("cuda").manual_seed(4) for _ in range(len(prompts))]
images = pipeline(prompt=prompts, generator=generator, num_inference_steps=25).images
make_image_grid(images, 2, 2)
次は英語のドキュメントに進んだほうが良さそうだね。