mycoeiroinkを試してみる
coeiroinkとは
自分の「オリジナルキャラクター」に声をつけたいと思ったことはないでしょうか。
しかし、声を個人で用意することが難しく、断念している方も多いと思います。
そこで、合成音声を使うのはどうでしょう。
COEIROINK(コエイロインク)は「CV(キャラクターボイス)」を無料で提供します。
mycoeiroinkとは
自作のCOEIROINK合成音声「MYCOEIROINK」を作ることができます。
環境
Colaboratoryの手順が用意されているが、手元で作ってみようと思う。
- CPU: Intel Core i9-13900F
- メモリ: 32GB(16GB×2) PC5-38400(DDR5-4800) DDR5 SDRAM
- GPU: NVIDIA GeForce RTX 4090 24GB
- OS: Ubutu 22.04
詳しくは https://zenn.dev/kun432/scraps/8258021c37cc29
どうもmycoeiroinkはVRAM12GB以上あることを前提にしているらしい
参考
手順
仮想環境作成
$ pyenv virtualenv 3.9.16 mycoeiroink
$ mkdir mycoeiroink && cd mycoeiroink
$ pyenv local mycoeiroink
学習済モデル等のデータをダウンロード。
$ mkdir downloads
$ wget 'https://www.dropbox.com/s/k08rz3wwc46vs9e/dummy_speaker_info.zip?dl=1' -O ./downloads/dummy_speaker_info.zip
$ wget 'https://www.dropbox.com/s/uph2t4e19t4bvr9/mycoe_pretrain_model.zip?dl=1' -O ./downloads/mycoe_pretrain_model.zip
$ wget 'https://www.dropbox.com/s/fkv8hvt1y82hsh6/mycoe_pretrain_model_2.zip?dl=1' -O ./downloads/mycoe_pretrain_model_2.zip
$ wget 'https://www.dropbox.com/s/vq9cfizgufdxvry/mycoe_pretrain_model_3.zip?dl=1' -O ./downloads/mycoe_pretrain_model_3.zip
次に、自分の音声データを用意することになるが、まずはお試しのために一旦以下を使わせてもらう。
$ mkdir myvoice
$ wget https://amitaro.net/download/corpus/ITAcorpus_amitaro_forMYCOEIROINK%202.2.zip -O './myvoice/ITAcorpus_amitaro_forMYCOEIROINK 2.2.zip'
音声データの確認と前処理
$ git clone https://github.com/shirowanisan/coeiroink-corpus-manager.git
$ pip install soundfile numpy librosa
以下のスクリプトを実行。
import glob
import shutil
import os
import soundfile as sf
import librosa
from librosa.util import normalize
MAX_WAV_VALUE = 32768.0
sampling_fs = 44100
workspace = './tmp'
if os.path.exists(workspace):
shutil.rmtree(workspace)
os.makedirs(workspace, exist_ok=True)
zip_folder = './myvoice'
if len(glob.glob(zip_folder + '/*.zip')) == 0:
raise Exception(f"zipが見つかりません。")
zip_path = glob.glob(zip_folder + '/*.zip')[0]
workspace_zip_path = workspace + '/wavs.zip'
wavs_folder = workspace + '/wavs'
shutil.copyfile(zip_path, workspace_zip_path)
shutil.unpack_archive(workspace_zip_path, wavs_folder)
wav_paths = sorted(glob.glob(wavs_folder + '/**/*.wav', recursive=True))
wav_names = [wav_path.split('/')[-1].replace('.wav', '') for wav_path in wav_paths]
with open('./coeiroink-corpus-manager/marged-corpus.txt', encoding='utf-8') as f:
text = f.readlines()
ita_corpus_keys = [s.split(':')[0] for s in text]
ita_corpus_values = [s.split(':')[-1] for s in text]
ita_corpus_dict = dict(zip(ita_corpus_keys, ita_corpus_values))
for wav_name in wav_names:
if wav_name not in ita_corpus_keys:
raise Exception(f"「{wav_name}」というwavファイルが含まれており、このファイル名はMYCOEIROINK対象のコーパスに含まれていません。")
if len(wav_names) < 10:
raise Exception(f"wavファイルの数が「{len(wav_names)}」ですが、wavファイルは10以上必要です。")
incorrect_fs_flag = False
incorrect_fs_list = []
for wav_path in wav_paths:
wav, original_fs = sf.read(wav_path)
if len(wav.shape) == 2:
raise Exception(f"「{wav_path.split('/')[-1]}」が、ステレオの可能性があります。モノラルにしてください。")
if original_fs != 44100:
incorrect_fs_list.append(wav_path.split('/')[-1])
incorrect_fs_flag = True
if incorrect_fs_flag:
print("WARNING: 44.1kHz以外の音声が含まれています。MYCOEでは44.1kHz以外の音声は44.1kHzに変換して利用されます。")
print(incorrect_fs_list)
normalized_wavs_path = './normalized_wavs'
if os.path.exists(normalized_wavs_path):
shutil.rmtree(normalized_wavs_path)
os.makedirs(normalized_wavs_path, exist_ok=True)
text = ''
# wavのサンプリング周波数と音量の調整とテキストの作成
for wav_path in wav_paths:
wav_name = wav_path.split('/')[-1].replace('.wav', '')
text += wav_name + ':' + ita_corpus_dict[wav_name]
wav, original_fs = sf.read(wav_path)
if original_fs != sampling_fs:
wav = librosa.resample(wav, orig_sr=original_fs, target_sr=sampling_fs)
normalized_wav = normalize(wav) * 0.90
sf.write(normalized_wavs_path + '/' + wav_path.split('/')[-1], normalized_wav, sampling_fs, 'PCM_16')
corpus_path = './corpus'
if os.path.exists(corpus_path):
shutil.rmtree(corpus_path)
os.makedirs(corpus_path, exist_ok=True)
with open('./corpus/transcripts_utf8.txt', 'w', encoding='UTF-8') as f:
f.write(text)
print(f"今回の学習に使われる音声の数は全部で「{len(wav_paths)}」個となっています。ご確認ください。")
$ python preprocess.py
今回の学習に使われる音声の数は全部で「424」個となっています。ご確認ください。
こんな感じになればOK。
mycoeiroink配布用のフォルダを作成する。
$ unzip downloads/dummy_speaker_info.zip
解凍されてdummy_speaker_infoディレクトリが作成されるので以下を実行。
import glob
import uuid
import random
import shutil
import json
import os
speaker_info_contents = sorted(glob.glob('./speaker_info/*'))
if len(speaker_info_contents) == 0:
speaker_uuid = str(uuid.uuid1())
speaker_id = random.randint(10001, 2147483647)
shutil.move('./dummy_speaker_info/icons/<speaker_id>.png', f"./dummy_speaker_info/icons/{speaker_id}.png")
shutil.move('./dummy_speaker_info/voice_samples/<speaker_id>_001.wav', f"./dummy_speaker_info/voice_samples/{speaker_id}_001.wav")
shutil.move('./dummy_speaker_info/voice_samples/<speaker_id>_002.wav', f"./dummy_speaker_info/voice_samples/{speaker_id}_002.wav")
shutil.move('./dummy_speaker_info/voice_samples/<speaker_id>_003.wav', f"./dummy_speaker_info/voice_samples/{speaker_id}_003.wav")
shutil.move('./dummy_speaker_info/model/<speaker_id>', f"./dummy_speaker_info/model/{speaker_id}")
metas = {
"speakerName": "MYCOEIROINK",
"speakerUuid": speaker_uuid,
"styles": [
{
"styleName": "のーまる",
"styleId": speaker_id
}
]
}
with open('dummy_speaker_info/metas.json', mode='w', encoding='utf-8') as f:
json.dump(metas, f, indent=4, ensure_ascii=False)
os.makedirs('./speaker_info', exist_ok=True)
shutil.copytree('./dummy_speaker_info', f"./speaker_info/{speaker_uuid}")
speaker_infoディレクトリが作成されていればOK
$ find speaker_info/
speaker_info/
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/voice_samples
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/voice_samples/2140810076_003.wav
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/voice_samples/2140810076_002.wav
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/voice_samples/2140810076_001.wav
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/metas.json
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/icons
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/icons/2140810076.png
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/model
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/model/2140810076
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/portrait.png
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/policy.md
speaker_info/288fe10c-dce3-11ed-b749-2d8dbf2443e9/LICENSE.txt
dummyの方はもう不要なので削除しておく
$ rm -rf dummy_speaker_info/
では学習環境を構築していく。元の手順ではvenvを行うようになっているが、そもそもvenv環境でやってるので、venvの入れ子になっちゃう(できるのか?)。なのでここは気にしないことにする。
$ pip install torch==1.10.2+cu113 torchvision==0.11.3+cu113 torchaudio===0.10.2+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
$ git clone -b 0.10.3 https://github.com/shirowanisan/espnet.git
$ pip install -r espnet/requirements.txt
$ git clone https://github.com/kaldi-asr/kaldi
$ cd espnet/tools; ln -s $(pwd)/../../kaldi .
$ cd ../..
ベースモデルの設定。以下のスクリプトを実行。
import glob
import shutil
import os
# 音声モデルを選択
# - model_1: つくよみちゃん
# - model_2: おふとんPさん
# - model_3: MANAさん
pretrained_model_tag = 'model_1'
espnet_wavs_dir = './espnet/egs2/mycoe/tts1/downloads/wavs'
os.makedirs(espnet_wavs_dir, exist_ok=True)
wav_paths = sorted(glob.glob('./normalized_wavs/*.wav'))
for wav_path in wav_paths:
shutil.copyfile(wav_path, espnet_wavs_dir + '/' + wav_path.split('/')[-1])
if pretrained_model_tag == 'model_1':
shutil.unpack_archive('./downloads/mycoe_pretrain_model.zip', './')
if pretrained_model_tag == 'model_2':
shutil.unpack_archive('./downloads/mycoe_pretrain_model_2.zip', './')
if pretrained_model_tag == 'model_3':
shutil.unpack_archive('./downloads/mycoe_pretrain_model_3.zip', './')
shutil.copyfile('./mycoe_pretrain_model/100epoch.pth', './espnet/egs2/mycoe/tts1/downloads/100epoch.pth')
shutil.copyfile('./mycoe_pretrain_model/tokens.txt', './espnet/egs2/mycoe/tts1/downloads/tokens.txt')
shutil.copyfile('./corpus/transcripts_utf8.txt', './espnet/egs2/mycoe/tts1/downloads/transcripts_utf8.txt')
$ python setup_env.py
最後の準備
$ cd ./espnet/egs2/mycoe/tts1/
$ ./run.sh \
--stage 1 \
--stop-stage 5 \
--ngpu 1 \
--fs 44100 \
--n_fft 2048 \
--n_shift 512 \
--win_length null \
--dumpdir dump/44k \
--expdir ../../../../exp \
--tts_task gan_tts \
--feats_extract linear_spectrogram \
--feats_normalize none \
--train_config ./conf/finetune.yaml
$ cd ../..
$ mv ./espnet/egs2/mycoe/tts1/dump/44k/token_list/phn_jaconv_pyopenjtalk_prosody/tokens.txt ./espnet/egs2/mycoe/tts1/dump/44k/token_list/phn_jaconv_pyopenjtalk_prosody/tokens.bak.txt
$ cp ./espnet/egs2/mycoe/tts1/downloads/tokens.txt ./espnet/egs2/mycoe/tts1/dump/44k/token_list/phn_jaconv_pyopenjtalk_prosody/tokens.txt
venv周りでエラーが出るけど一旦気にせず回す。
では学習させる
$ cd espnet/egs2/mycoe/tts1/
$ ./run.sh \
--stage 6 \
--stop-stage 6 \
--ngpu 1 \
--fs 44100 \
--n_fft 2048 \
--n_shift 512 \
--win_length null \
--dumpdir dump/44k \
--expdir ../../../../exp \
--tts_task gan_tts \
--feats_extract linear_spectrogram \
--feats_normalize none \
--train_config ./conf/finetune.yaml \
--train_args "--init_param downloads/100epoch.pth:tts:tts" \
--tag mycoe_model
うちのスペックでだいたい6時間ぐらいかかった。
GPUの使用率はこの辺。conf/finetune.yamlをもう少しいじれば時間短縮できるのかな。
10977MiB / 24564MiB
ちなみに100epochまで処理が行われるけど、プロセスは終わらないので、Ctrl+Cで止める。どこまで進んでるかは
$ grep "100 epochs" exp/tts_mycoe_model/train.log
(snip)
[kun432-rtx4090] 2023-04-17 21:38:52,258 (trainer:450) INFO: The training was finished at 100 epochs
とかで確認すればよい。
coeiroinkで読み込んで使う
coeiroinkで学習したモデルを読み込む。先程学習させたデータで必要なのは以下。
-
speaker_info/XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXXディレクトリ -
exp/tts_mycoe_model/100epoch.pthファイル(XXXepoch.pthの一番数字が大きいもの) -
exp/tts_mycoe_model/config.yamlファイル
これをcoeiroinkがインストールされてる端末に持ってくる。以下のようにまとめておいてscpで持ってくれば良い。
$ cp -pir speaker_info/XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX /tmp
$ cp -pi exp/tts_mycoe_model/{100epoch.pth,config.yaml} /tmp/XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/model/YYYYYYYYYY/. # YYYYYYYYYYは数字だけのディレクトリ
でcoeiroinkのプログラムディレクトリに組み込む。うちの場合はMacなので、
- Findeで「アプリケーション」を開く→「coeiroink」を右クリック→「パッケージの内容を表示」
- 中身が表示されたら「MacOS」→「speaker_info」の中にさっきのディレクトリをコピーする
でcoeiroinkを起動。
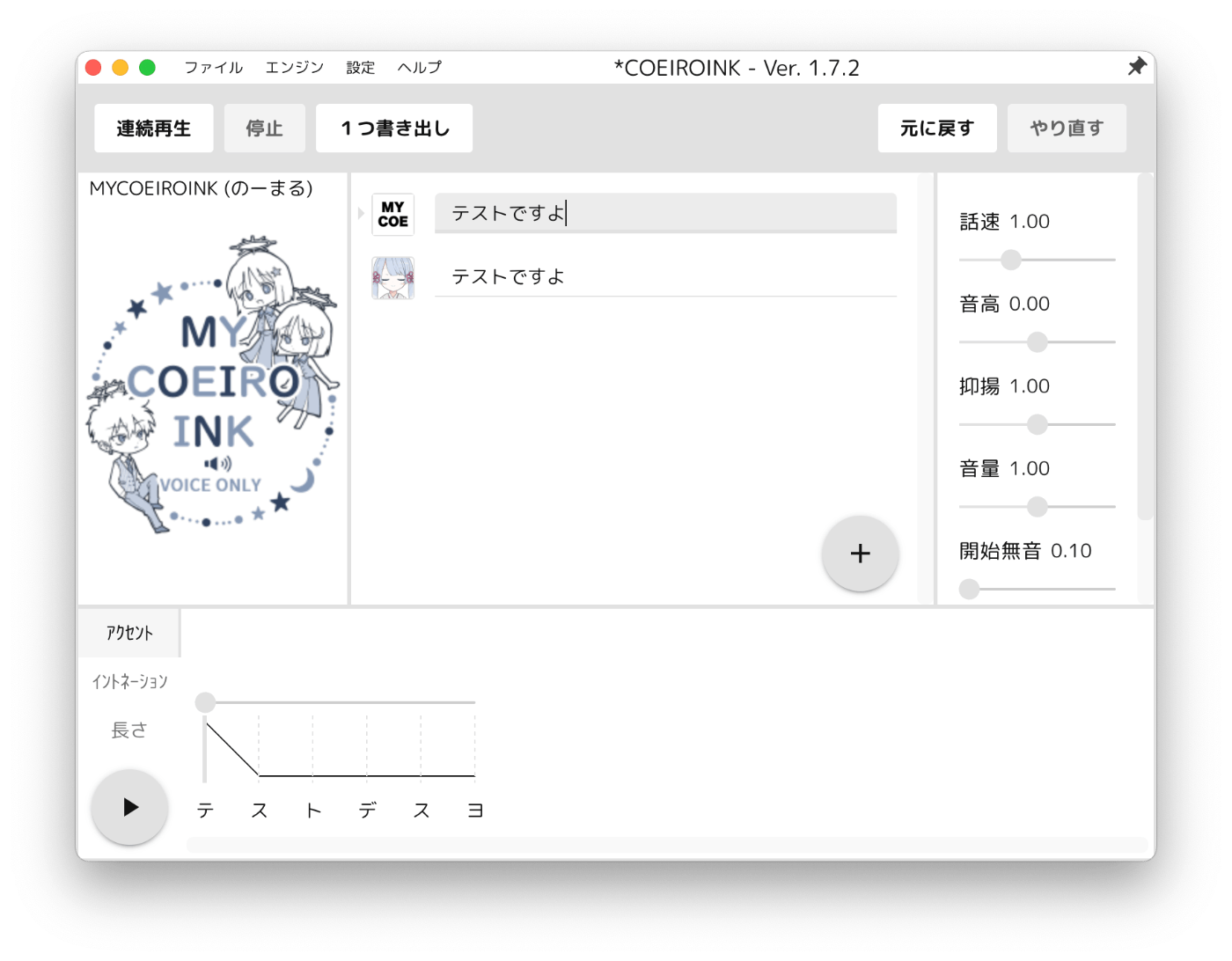
mycoeiroinkが追加されている。「完了」をクリック。

mycoeiroinkを選んで喋らせたいテキストを入力すれば良い。

ちゃんと喋りました。
まとめ
- スペック的にどんなものかなーというのが目的だったけど、RTX4090なら24GBあるし余裕。12GBだとギリっぽいけど、ググってみた感じはRTX3060(12GB?)でも動いている様子。パラメータ変えればいけるのかな?
- 元々venv使ってるところに手順でもvenv使う流れになってるので、docker使うほうがいいかも。それか頑張って手順を自分で組み直すか。
- 環境用意するのも手間なので、notebookも用意されてるGoogle Colaboratoryを使うほうが手っ取り早い。ただGoogleドライブの容量も必要(7GB)だし、無料だと12時間で切断される。学習に10時間ぐらいかかるみたいなので、Colaboratory Proにするほうが安心(有料)。
colaboratoryでもなかなか大変そう。